Kafka KRaft 版本集群部署详细教程(附配置文件详细解释)
版本说明
- Ubuntu 18.04.6
- Kafka 3.6.0
- JDK8
集群配置
| 操作系统 | ip | 域名 | Kafka Broker 端口 | Kafka Controller 端口 |
|---|---|---|---|---|
| Ubuntu 18.04.6 | 192.168.50.131 | kafka1.com | 9092 | 9093 |
| Ubuntu 18.04.6 | 192.168.50.132 | kafka2.com | 9092 | 9093 |
| Ubuntu 18.04.6 | 192.168.50.133 | kafka3.com | 9092 | 9093 |
安装 vim, curl
sudo apt update
sudo apt install vim
sudo apt install curl
配置静态 ip 和 hosts
为了使用域名,更加方便的进行配置,这里将虚拟机的 DHCP 改成了静态分配 IP,所以需要手动设置一下每台机器 IP 地址,这里以 192.168.50.131 为例。
-
找到网络接口名称,运行以下命令:
ip addr查找以
ens或eth开头的接口名称。例如,ens33或eth0。hedon@ubuntu:~$ ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 00:0c:29:82:9e:69 brd ff:ff:ff:ff:ff:ffinet 192.168.50.133/24 brd 192.168.50.255 scope global dynamic noprefixroute ens33valid_lft 1644sec preferred_lft 1644secinet6 fe80::c367:c7cc:3ad4:23b3/64 scope link valid_lft forever preferred_lft forever可以找到
ens33,其中inet 192.168.50.133/24表示 IP 地址为192.168.50.133,子网掩码为/24(等于255.255.255.0)。这个 IP 地址是 DHCP 动态分配的,说明宿主机分配给虚拟机的 IP 范围就在
192.168.50.xxx,所以我们会将静态 IP 配置在这个范围内。 -
获取网关地址
ip route | grep default输出:
hedon@ubuntu:~$ ip route | grep default default via 192.168.50.2 dev ens33 proto dhcp metric 100说明默认网关是
192.168.50.2, -
编辑
/etc/network/interfaces文件,配置静态 IP 地址,内容如下:auto ens33 iface ens33 inet staticaddress 192.168.50.131netmask 255.255.255.0gateway 192.168.50.2dns-nameservers 8.8.8.8 8.8.4.4 -
重启
su reboot -
再次查看 ip 地址
ip addr有以下输出便说明静态 IP 配置成功了。
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 00:0c:29:82:9e:69 brd ff:ff:ff:ff:ff:ffinet 192.168.50.131/24 brd 192.168.50.255 scope global ens33valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe82:9e69/64 scope link valid_lft forever preferred_lft forever -
配置域名
sudo vim /etc/hosts追加内容如下:
192.168.50.131 kafka1.com 192.168.50.132 kafka2.com 192.168.50.133 kafka3.com -
ping 一下
hedon@ubuntu:~$ ping kafka1.com PING kafka1.com (192.168.50.131) 56(84) bytes of data. 64 bytes from kafka1.com (192.168.50.131): icmp_seq=1 ttl=64 time=0.024 ms 64 bytes from kafka1.com (192.168.50.131): icmp_seq=2 ttl=64 time=0.021 ms 64 bytes from kafka1.com (192.168.50.131): icmp_seq=3 ttl=64 time=0.029 ms ^C --- kafka1.com ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2029ms rtt min/avg/max/mdev = 0.021/0.024/0.029/0.006 ms -
ping 一下百度,看看能不能访问外网
hedon@ubuntu:~$ ping baidu.com ping: baidu.com: Name or service not known如果这里可以访问,则直接跳过进入下一步,不可以的话,需要配置一下域名解析系统。
-
配置域名解析系统
Ubuntu 系统使用
systemd-resolved服务来管理 DNS,你可以在/etc/systemd/resolved.conf文件中进行 DNS 配置。sudo vim /etc/systemd/resolved.conf取消或添加
DNS的注释,并修改为:[Resolve] DNS=8.8.8.8 8.8.4.4重启启动
systemd-resolved:sudo systemctl restart systemd-resolved再尝试 ping 一下百度:
hedon@ubuntu:~$ ping www.baidu.com PING www.a.shifen.com (153.3.238.110) 56(84) bytes of data. 64 bytes from 153.3.238.110 (153.3.238.110): icmp_seq=1 ttl=128 time=15.9 ms 64 bytes from 153.3.238.110 (153.3.238.110): icmp_seq=2 ttl=128 time=15.9 ms 64 bytes from 153.3.238.110 (153.3.238.110): icmp_seq=3 ttl=128 time=16.1 ms 64 bytes from 153.3.238.110 (153.3.238.110): icmp_seq=4 ttl=128 time=15.3 ms ^C --- www.a.shifen.com ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 14104ms rtt min/avg/max/mdev = 15.368/15.850/16.145/0.291 ms
{% note info %}
补充说明:/etc/network/interfaces 文件的配置
这是一个用于配置 Linux 系统上网络接口的文件。在这个示例中,我们为名为 ens33 的网络接口配置了静态 IP 地址和相关的网络设置。下面是各行的解释:
-
auto ens33: 这一行表示在系统启动时自动激活ens33网络接口。auto关键字后面跟着接口名称。 -
iface ens33 inet static: 这一行定义了ens33网络接口的配置。iface关键字后面跟着接口名称,inet表示我们正在配置 IPv4 地址,static表示我们要为接口分配一个静态 IP 地址(而不是通过 DHCP 获得)。 -
address 192.168.50.131: 这一行设置了网络接口的静态 IP 地址。在这个例子中,我们为ens33接口分配了192.168.50.131IP 地址。IP 地址是 Internet 协议(IP)用于在网络中唯一标识设备的数字标签。每个连接到网络的设备都需要一个唯一的 IP 地址,以便其他设备可以找到并与之通信。IP 地址通常分为两种版本:IPv4 和 IPv6。在此示例中,我们使用了一个 IPv4 地址。
-
netmask 255.255.255.0: 这一行定义了子网掩码。在这个例子中,子网掩码是255.255.255.0,表示前三个字节(24 位)是网络地址,最后一个字节(8 位)是主机地址。子网掩码用于划分 IP 地址的网络部分和主机部分。子网掩码与 IP 地址进行按位与操作,从而得到网络地址。这有助于确定哪些 IP 地址属于同一子网,以便正确地将数据包路由到目的地。子网划分有助于组织网络、提高安全性和管理性。
-
gateway 192.168.50.2: 这一行设置了默认网关。在这个例子中,我们将默认网关设置为192.168.50.2。默认网关是用于将数据包发送到其他网络的路由器或设备的 IP 地址。网关是一个充当网络中数据包传输的中继点的设备,通常是一个路由器。当一个设备需要将数据包发送到不同子网的另一个设备时,它会将数据包发送到网关。网关负责将数据包路由到正确的目的地。默认网关是设备用于将数据包发送到其他网络的首选网关。
-
dns-nameservers 8.8.8.8 8.8.4.4: 这一行指定了 DNS 服务器的 IP 地址。在这个例子中,我们使用了谷歌的公共 DNS 服务器8.8.8.8和8.8.4.4。DNS 服务器用于将主机名解析为 IP 地址。域名系统(DNS)是将人类可读的域名(例如 www.baidu.com)IP 地址的系统。DNS 服务器是负责执行此解析过程的服务器。当您在浏览器中输入一个网址时,计算机会向 DNS 服务器查询该域名对应的 IP 地址,然后将请求发送到该 IP 地址以获取网页内容。
配置文件中的这些设置将在系统启动时生效。要立即应用更改,您可以使用以下命令重启网络服务:
sudo systemctl restart networking
{% endnote %}
安装 jdk
sudo apt update
sudo apt install openjdk-8-jdk
验证 java8 是否已经安装成功:
java -version
有以下类似输出的话则表明安装成功:
openjdk version "1.8.0_362"
OpenJDK Runtime Environment (build 1.8.0_362-8u372-ga~us1-0ubuntu1~18.04-b09)
OpenJDK 64-Bit Server VM (build 25.362-b09, mixed mode)
安装 Kafka
-
下载并解压 Kafka
wget https://archive.apache.org/dist/kafka/3.6.0/kafka_2.13-3.6.0.tgz tar -zxvf kafka_2.13-3.6.0.tgz -
将解压缩后的文件夹移动到
/opt目录中:sudo mv kafka_2.13-3.6.0 /opt/kafka-3.6.0 -
使用 Kafka 提供的脚本生成一个 ClusterID
export KAFKA_CLUSTER_ID="$(/opt/kafka-3.6.0/bin/kafka-storage.sh random-uuid)"输出 ClusterID
hedon@ubuntu:/opt/kafka-3.6.0$ echo $KAFKA_CLUSTER_ID XiMRcbJ-QEO694L7sfDdBQ在其他节点上将
KAFKA_CLUSTER_ID设置为上面的值:export KAFKA_CLUSTER_ID=XiMRcbJ-QEO694L7sfDdBQ -
备份配置文件,注意这里的配置文件是
config/kraft/server.properties,在config目录下的kraft目录中:cp /opt/kafka-3.6.0/config/kraft/server.properties /opt/kafka-3.6.0/config/kraft/server.properties.bak -
修改配置
vim /opt/kafka-3.6.0/config/kraft/server.properties主要修改内容如下:
# 节点 ID,分别为 1,2,3 node.id=1 # 日志目录 log.dirs=/opt/kafka-3.6.0/kafka-combined-logs # 可以成为控制器的节点和它们的端口 controller.quorum.voters=1@kafka1.com:9093,2@kafka2.com:9093,3@kafka3.com:9093 # 定义 Kafka Broker 如何向外部公布它的地址。 # 这是 Kafka Broker 通知 Producer 和 Consumer 如何连接到自己的方式。 # 例如,如果你设置 advertised.listeners=PLAINTEXT://my.public.ip:9092, # 那么 Kafka Broker 将告诉 Producer 和 Consumer 它的公共 IP 地址是 my.public.ip,并且它在 9092 端口上监听连接。 # 这里我们需要在 3 个节点分别设置对应的地址 advertised.listeners=PLAINTEXT://kafka1.com:9092 -
格式化日志目录
/opt/kafka-3.6.0/bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c /opt/kafka-3.6.0/config/kraft/server.properties输出:
Formatting /opt/kafka-3.6.0/kraft-combined-logs with metadata.version 3.6-IV2. -
三个节点都启动 Kafka
/opt/kafka-3.6.0/bin/kafka-server-start.sh -daemon /opt/kafka-3.6.0/config/kraft/server.properties -
选择任意一个节点创建一个新 topic
/opt/kafka-3.6.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test --replication-factor 1 --partitions=2输出:
Created topic test. -
在其他节点获取
test这个topic的信息/opt/kafka-3.6.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic test可以看到关于
test这个topic的信息是可以获取到的,说明集群之前信息是互通的,集群搭建完毕。Topic: test TopicId: svJClTUpSFa9Z6FWDvkARg PartitionCount: 2 ReplicationFactor: 1 Configs: segment.bytes=1073741824Topic: test Partition: 0 Leader: 2 Replicas: 2 Isr: 2Topic: test Partition: 1 Leader: 3 Replicas: 3 Isr: 3 -
随便选择一个节点,往
test里面写入数据:/opt/kafka-3.6.0/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test输入数据后按回车即发送一条数据,可以随时按
Ctrl + C退出:hedon@ubuntu:~/Downloads$ /opt/kafka-3.6.0/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test >msg1 >msg2 >msg 3 >^ -
随便选择一个节点,启动消费者消费
topic中的数据:/opt/kafka-3.6.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning输出:
hedon@ubuntu:/opt/kafka-3.6.0$ /opt/kafka-3.6.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning msg1 msg2 msg 3 ^CProcessed a total of 3 messages
至此,Kafka 的 KRaft 版本集群就部署完毕了!
补充说明 - KRaft 配置文件
下面是 Kafka KRaft 版本配置文件每个配置项的解释:
| 配置项 | 说明 |
|---|---|
| process.roles | Kafka 服务器的角色,设置此项将 Kafka 置于 KRaft 模式。可能的值包括 “broker” 和 “controller”。 |
| node.id | 与此实例关联的节点 ID。 |
| controller.quorum.voters | 控制器选举的投票节点,格式为 node-id@host:port。 |
| listeners | 服务器监听的地址,格式为 listener_name://host_name:port。 |
| inter.broker.listener.name | 用于 broker 之间通信的监听器名称。 |
| advertised.listeners | 服务器向客户端宣告的监听器名称、主机名和端口。 |
| controller.listener.names | 控制器使用的监听器名称列表。 |
| listener.security.protocol.map | 监听器名称到安全协议的映射。默认情况下,它们是相同的。 |
| num.network.threads | 服务器用于从网络接收请求和向网络发送响应的线程数。 |
| num.io.threads | 服务器用于处理请求(可能包括磁盘 I/O)的线程数。 |
| socket.send.buffer.bytes | 服务器用于发送数据的缓冲区大小。 |
| socket.receive.buffer.bytes | 服务器用于接收数据的缓冲区大小。 |
| socket.request.max.bytes | 服务器接受的请求的最大大小(用于防止内存溢出)。 |
| log.dirs | 用于存储日志文件的目录列表。 |
| num.partitions | 每个主题的默认日志分区数。 |
| num.recovery.threads.per.data.dir | 每个数据目录在启动时用于日志恢复和关闭时用于刷新的线程数。 |
| offsets.topic.replication.factor | 内部主题 “__consumer_offsets” 和 “__transaction_state” 的复制因子。 |
| transaction.state.log.replication.factor | 事务状态日志的复制因子。 |
| transaction.state.log.min.isr | 事务状态日志的最小同步副本数。 |
| log.flush.interval.messages | 强制将数据刷新到磁盘之前接受的消息数。 |
| log.flush.interval.ms | 消息在日志中停留的最大时间,超过这个时间就会强制刷新到磁盘。 |
| log.retention.hours | 由于年龄而使日志文件有资格被删除的最小年龄。 |
| log.retention.bytes | 基于大小的日志保留策略。 |
| log.segment.bytes | 日志段文件的最大大小。 |
| log.retention.check.interval.ms | 检查日志段是否可以根据保留策略被删除的间隔。 |
请注意,这只是 Kafka 配置的一部分,Kafka 配置的完整列表可以在 Kafka 的官方文档中找到。
相关文章:
)
Kafka KRaft 版本集群部署详细教程(附配置文件详细解释)
版本说明 Ubuntu 18.04.6Kafka 3.6.0JDK8 集群配置 操作系统ip域名Kafka Broker 端口Kafka Controller 端口Ubuntu 18.04.6192.168.50.131kafka1.com90929093Ubuntu 18.04.6192.168.50.132kafka2.com90929093Ubuntu 18.04.6192.168.50.133kafka3.com90929093 安装 vim, cur…...

在龙蜥 anolis os 23 上 源码安装 PostgreSQL 16.1
在龙蜥 OS 23上,本来想使用二进制安装,结果发现没有针对龙蜥的列表: 于是想到了源码安装,下面我们列出了PG源码安装的步骤: 1.安装准备 1.1.创建操作系统组及用户 groupadd postgres useradd -g postgres -m postgr…...

UDP的不可靠性可以用来做什么
User Datagram Protocol(UDP,用户数据报协议)是互联网协议套件中的一种传输层协议。与TCP不同,UDP是一种无连接的、不可靠的协议。 要知道UDP可以用来做什么,首先我们要知道它有何特点: 1,无连接: UDP是一…...
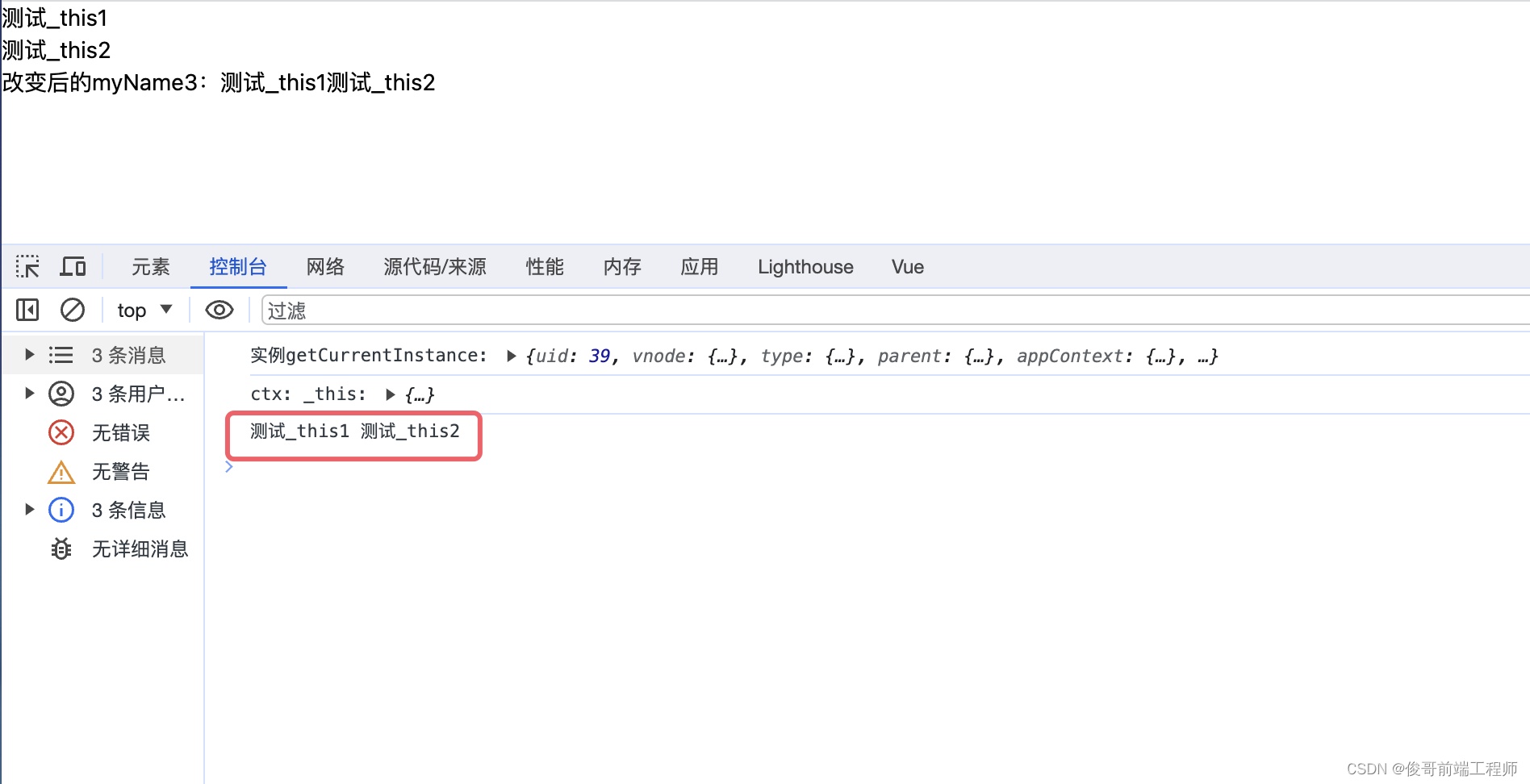
vue3还用this吗?getCurrentInstance获取当前组件实例
在 Vue 2 中,this 关键字代表当前组件实例。在组件的选项对象中,this 可以用于访问组件实例的属性、方法以及 Vue 实例的一些特定方法。 在Vue3中,我们发现this是undefined,那我们真的没法使用this了吗?vu3给我们提供…...

高校学生宿舍公寓报修维修生活管理系统 微信小程序b2529
本课题要求实现一套基于微信小程序宿舍生活管理系统,系统主要包括(管理员,学生、维修员和卫检员)四个模块等功能。 使用基于微信小程序宿舍生活管理系统相对传统宿舍生活管理系统信息管理方式具备很多优点:首先可以大幅…...

C++类与对象(7)—友元、内部类、匿名对象、拷贝对象时编译器优化
目录 一、友元 1、定义 2、友元函数 3、友元类 二、内部类 1、定义 2、特性: 三、匿名对象 四、拷贝对象时的一些编译器优化 1、传值&传引用返回优化对比 2、匿名对象作为函数返回对象 3、接收返回值方式对比 总结: 一、友元 1、定义…...
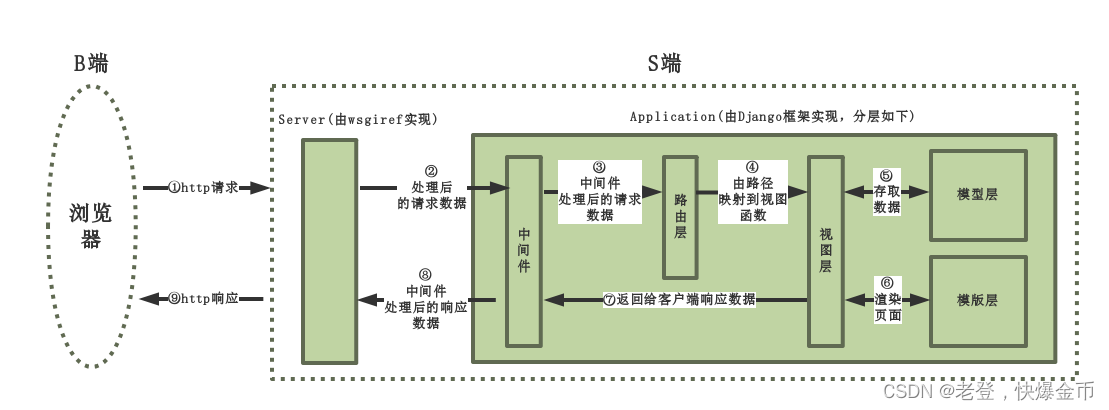
Django回顾2
目录 一.HTTP 1.URL介绍 2.格式: 3.补充: 二.web框架 1.什么是框架 2.什么是web框架 3.wsgi协议 基于wsgi协议的web服务器: 4.协议是怎么规定的 三.Django 1.MVC与MTV模型(所有框架其实都遵循MVC架构) 2.…...
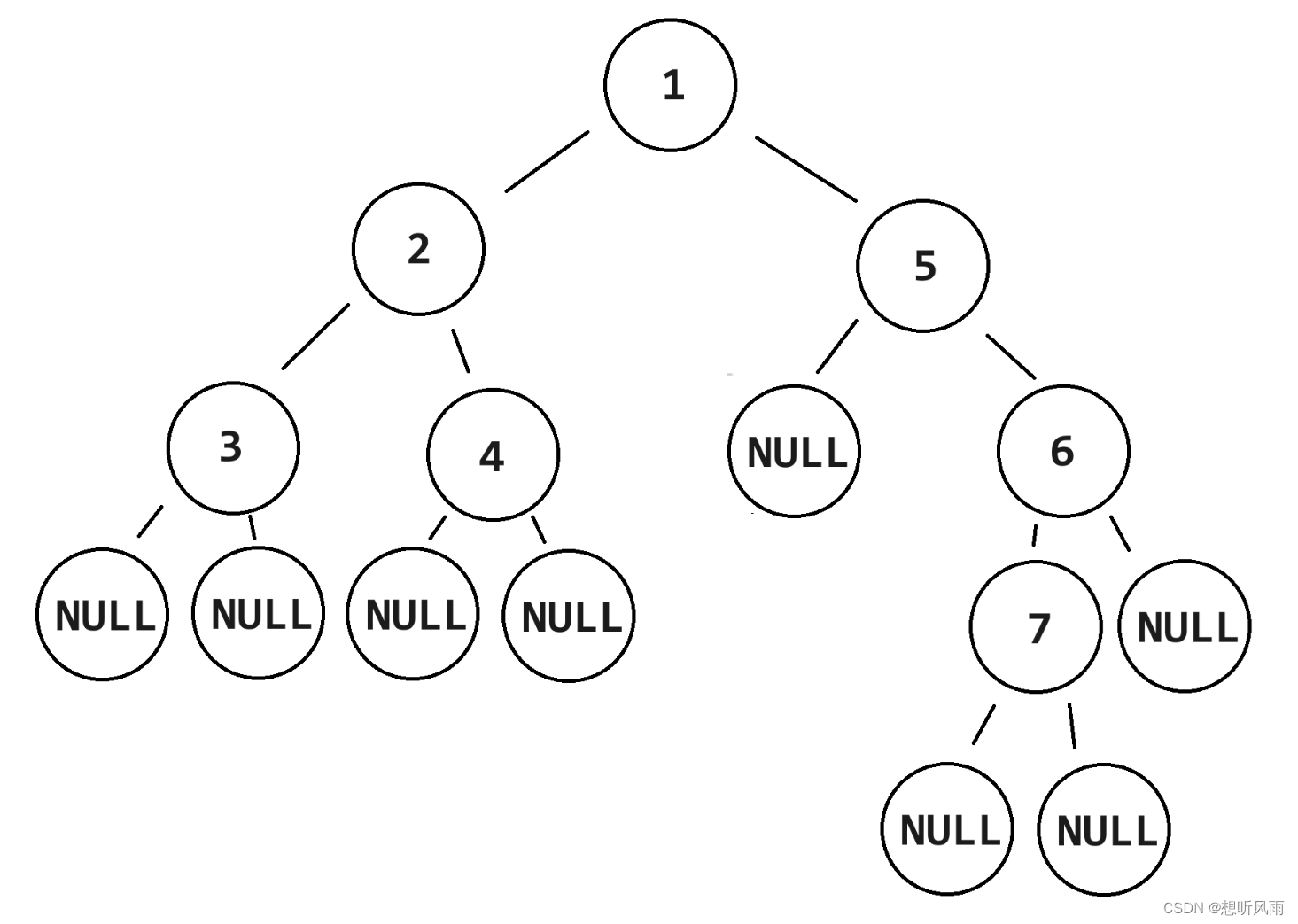
<JavaDS> 二叉树遍历各种遍历方式的代码实现 -- 前序、中序、后序、层序遍历
目录 有以下二叉树: 一、递归 1.1 前序遍历-递归 1.2 中序遍历-递归 1.3 后序遍历-递归 二、递归--使用链表 2.1 前序遍历-递归-返回链表 2.2 中序遍历-递归-返回链表 2.3 后序遍历-递归-返回链表 三、迭代--使用栈 3.1 前序遍历-迭代-使用栈 3.2 中序遍…...
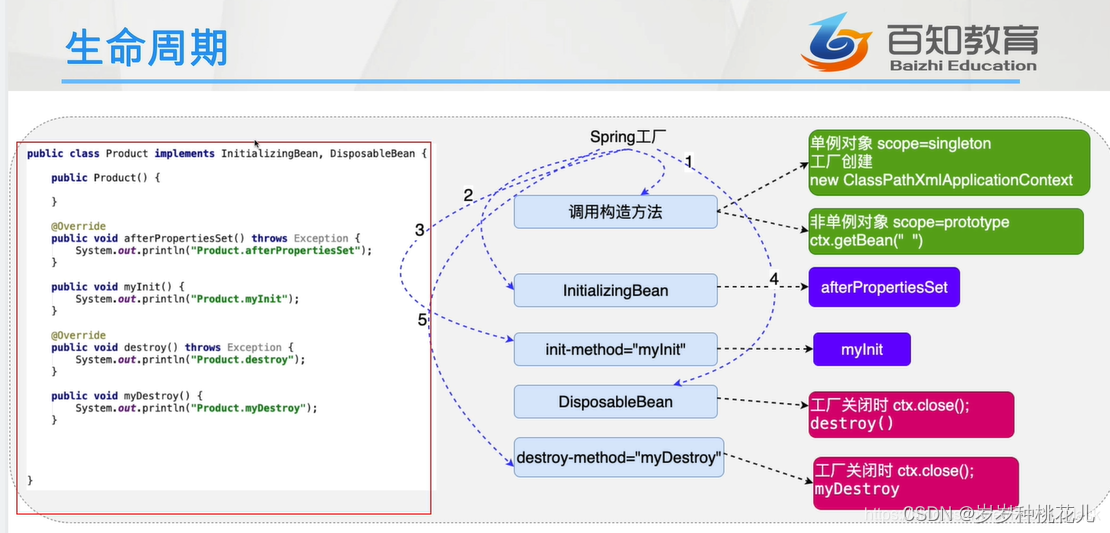
如何控制Spring工厂创建对象的次数?详解Spring对象的声明周期!
😉😉 学习交流群: ✅✅1:这是孙哥suns给大家的福利! ✨✨2:我们免费分享Netty、Dubbo、k8s、Mybatis、Spring...应用和源码级别的视频资料 🥭🥭3:QQ群:583783…...
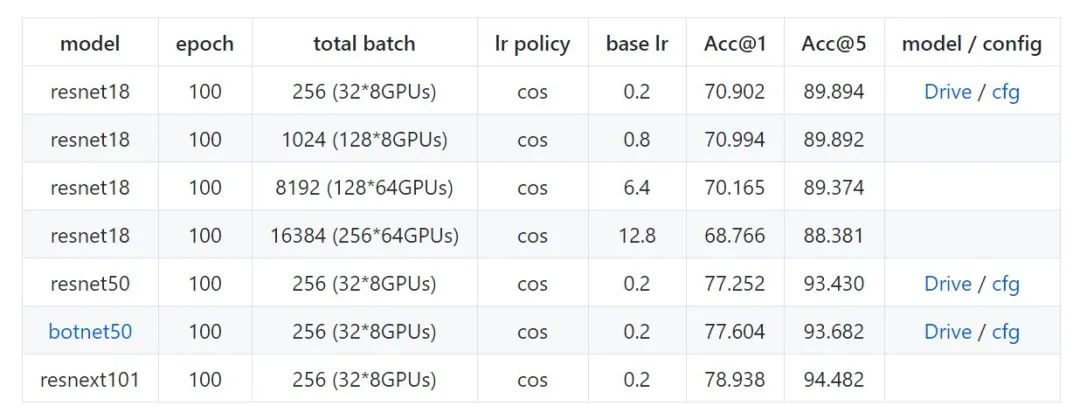
计算机杂谈系列精讲100篇-【计算机应用】PyTorch部署及分布式训练
目录 C平台PyTorch模型部署流程 1.模型转换 1. 不支持的操作 2. 指定数据类型 2.保存序列化模型 3.C load训练好的模型 4. 执行Script Module PyTorch分布式训练 分布式并行训练概述 Pytorch分布式数据并行 手把手渐进式实战 A. 单机单卡 B. 单机多卡DP C. 多机多卡DDP D. L…...

Opencv-C++笔记 (19) : 分水岭图像分割
文章目录 一、基于距离变换与分水岭的图像分割1、图像分割2、距离和变换与分水岭距离变换常见算法有两种分水岭变换常见的算法 3、距离变换API函数接口4、watershed 分水岭函数API接口步骤 5、代码 一、基于距离变换与分水岭的图像分割 1、图像分割 图像分割(Image Segmentat…...

Linux以nohup方式运行jar包
1、在需要运行的jar包同级目录下建立启动脚本文件: 文件内容: #! /bin/bash #注意:必须有&让其后台执行,否则没有pid生成 jar包路径为绝对路径 nohup java -jar /usr/local/testDemo/jdkDemo-0.0.1-SNAPSHOT.jar >/us…...
【c++|SDL】开始使用之---demo
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 SDL 记录 1. hello word #include<SDL2/SDL.h>SDL_Window* g_pWindow 0; SDL_Renderer* g_pRenderer 0;int main(int argc, char* args[]) {//…...
leetcode:有效的括号
题目描述 题目链接:20. 有效的括号 - 力扣(LeetCode) 题目分析 题目给了我们三种括号:()、{ }、[ ] 这里的匹配包括:顺序匹配和数量匹配 最优的思路就是用栈来解决: 括号依次入栈…...

使用STM32微控制器实现光电传感器的接口和数据处理
光电传感器在许多领域中被广泛应用,例如工业自动化、智能家居等。本文将介绍如何使用STM32微控制器实现光电传感器的接口和数据处理的方案,包括硬件设计、引脚配置、数据采集、滤波和阈值判断等关键步骤,并给出相应的代码示例。 一、引言 光…...
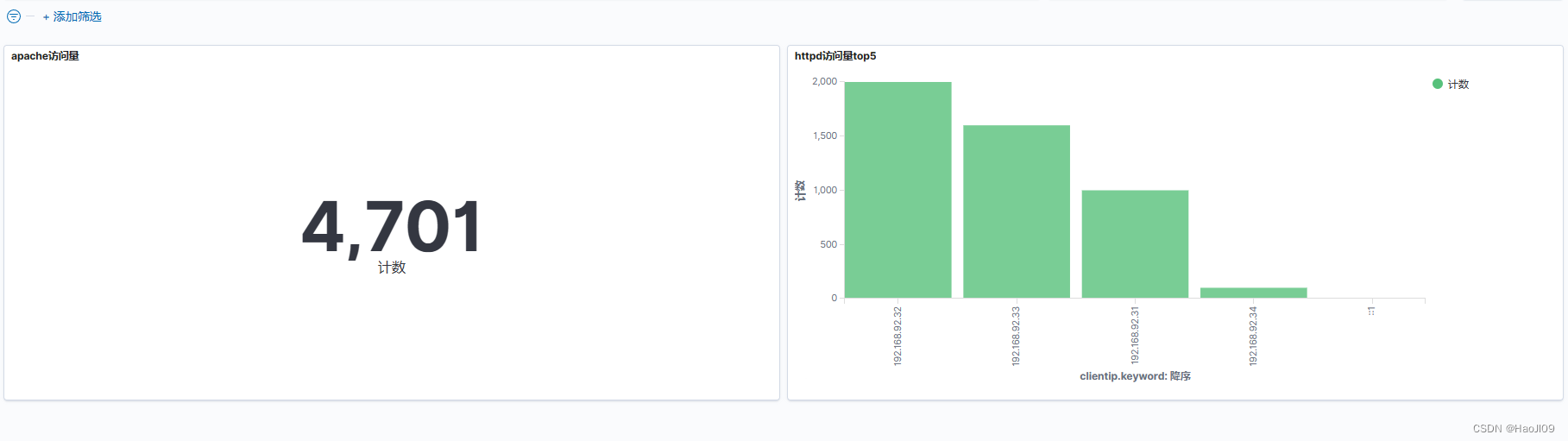
ELK企业级日志分析平台——kibana数据可视化
部署 新建虚拟机server5,部署kibana [rootelk5 ~]# rpm -ivh kibana-7.6.1-x86_64.rpm [rootelk5 ~]# cd /etc/kibana/[rootelk5 kibana]# vim kibana.ymlserver.host: "0.0.0.0"elasticsearch.hosts: ["http://192.168.56.11:9200"]i18n.local…...
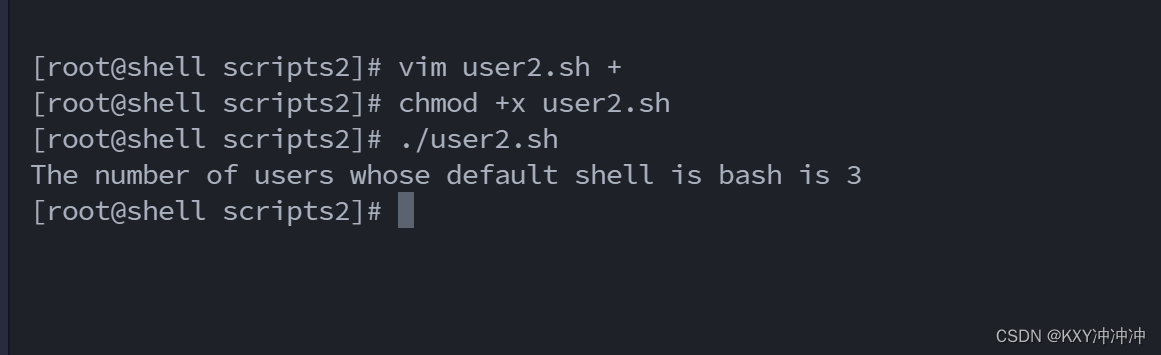
Shell条件变量练习
1.算数运算命令有哪几种? (1) "(( ))"用于整数运算的常用运算符,效率很高 [rootshell scripts]# echo $((24*5**2/8)) #(( ))2452814 14 (2) "$[ ] "用于整数运算 [rootshell scripts]# echo $[24*5**2/8] #[ ]也可以运…...

【PHP】MySQL简介与MySQLi函数(含PHP与MySQL交互)
文章目录 一、MySQL简介二、MySQLi函数1. 开启mysqli扩展:2. PHP MySQLi扩展的常用函数 三、PHP与MySQL交互0. 准备1. 创建连接(mysqli_connect() )连接mysql语法 2. 选择数据库(mysqli_select_db())3. 在php中操作数据…...

vscode在Windows上安装插件提示错误xhr failed
问题描述: 在Windows下,在vscode里搜索扩展时发现无法搜索,报如下错:”Error while fetching extensions. XHR failed“。 问题定位: 在vscode界面下键入ctrlshiftp, 然后输入:Developer: T…...
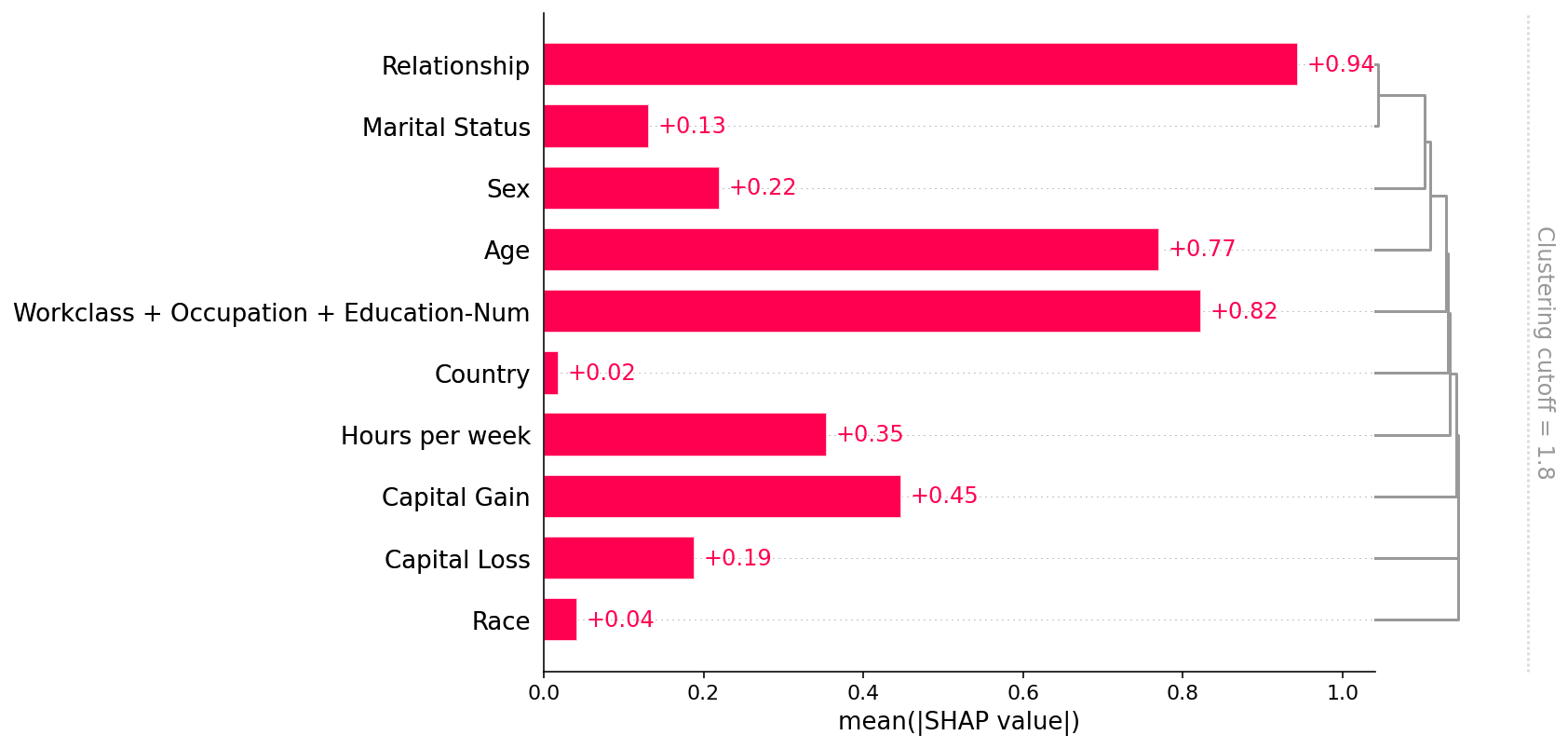
SHAP(一):具有 Shapley 值的可解释 AI 简介
SHAP(一):具有 Shapley 值的可解释 AI 简介 这是用 Shapley 值解释机器学习模型的介绍。 沙普利值是合作博弈论中广泛使用的方法,具有理想的特性。 本教程旨在帮助您深入了解如何计算和解释基于 Shapley 的机器学习模型解释。 我…...

Golang如何做Helm Chart_Golang Helm教程【秒懂】
Go二进制在scratch/alpine镜像报“no such file or directory”是因CGO默认启用导致动态链接libc,需禁用CGO并静态编译;Helm配置须统一管理探针路径、环境变量、镜像tag等四端一致。Go二进制进镜像总报 no such file or directory?不是镜像没…...

雪女-斗罗大陆-造相Z-Turbo在元宇宙中的应用:为用户虚拟化身生成个性化动漫形象
雪女-斗罗大陆-造相Z-Turbo在元宇宙中的应用:为用户虚拟化身生成个性化动漫形象 想象一下,你正准备进入一个热闹的虚拟世界,参加一场线上聚会。别人都顶着一个系统默认的、千篇一律的方块人形象,而你,却拥有一个完全根…...

Nunchaku FLUX.1 CustomV3批量处理技巧:高效生成1000+图像的方法
Nunchaku FLUX.1 CustomV3批量处理技巧:高效生成1000图像的方法 1. 引言 如果你正在使用Nunchaku FLUX.1 CustomV3生成图像,可能会遇到这样的困扰:每次只能生成几张图片,想要大批量产出内容时,需要反复手动操作&…...

2026年公考备战:呼和浩特这3家培训机构凭何领跑行业口碑榜?
呼和浩特这3家培训机构凭何领跑行业口碑榜?随着2026年公考备战季悄然拉开序幕,呼和浩特众多备考生的目光再次聚焦于如何选择一家靠谱的培训机构。近期,一份基于学员真实反馈、上岸数据及行业教研深度的本土公考机构口碑榜引发关注。榜单显示&…...

从零构建ReAct Agent:完整代码实现解析
从零构建ReAct Agent 说实话,当我第一次看到 ReAct 这个名词的时候,还以为是某个新出的前端框架。直到折腾了半天才发现,这玩意儿是解决 LLM “一本正经胡说八道” 的神器。 作为一个在 LLM 应用开发里踩过无数坑的人,我可以负责任…...

理解Android AOT编译与内存映射:从Zygote启动到页表权限隔离
引言:Android启动加速的奥秘在Android系统启动过程中,有一个至关重要的优化机制:AOT(Ahead-Of-Time)预编译。这种机制让Android应用启动速度大幅提升,其核心在于Zygote进程启动时,通过mmap()将预…...

知识资产沉睡率高达68%?重构AI原生研发知识平台的4步激活法,立即见效
第一章:知识资产沉睡率的现状与AI原生重构必要性 2026奇点智能技术大会(https://ml-summit.org) 企业知识资产正经历一场静默的流失危机。据Gartner 2025年《组织记忆健康度报告》显示,平均47%的内部文档、会议纪要、代码注释、实验日志和领域专家隐性经…...

动态规划之【树形DP】第2课:树形DP应用案例实践1
动态规划之【树形DP】第2课:树形DP应用案例实践1 二叉苹果树 题目描述 有一棵苹果树,如果树枝有分叉,一定是分二叉(就是说没有只有一个儿子的结点) 这棵树共有 NNN 个结点(叶子点或者树枝分叉点…...

Calico IPIP 使用指南芈
本课概览 Microsoft Agent Framework (MAF) 提供了一套强大的 Workflow(工作流) 框架,用于编排和协调多个智能体(Agent)或处理组件的执行流程。 本课将以通俗易懂的方式,帮助你理解 MAF Workflow 的核心概念…...

wso~.升级到.需要更新的数据表戳
1. 架构背景与演进动力 1.1 从单体到碎片化:.NET 的开源征程 在.NET Framework 时代,构建系统主要围绕 Windows 操作系统紧密集成,采用传统的封闭式开发模式。然而,随着.NET Core 的推出,微软开启了彻底的开源与跨平台…...