Python基础:推导式(Comprehensions)详解

1. 推导式概念
Python推导式(comprehensions)是一种简洁而强大的语法,用于从已存在的数据(列表、元组、集合、字典等)中创建新的数据结构。推导式包括:
- 列表推导式
- 元组推导式
- 字典推导式
- 集合推导式
2. 列表推导式
列表推导式创建列表的方式更简洁。常见的用法为,对序列或可迭代对象中的每个元素应用某种操作,用生成的结果创建新的列表;或用满足特定条件的元素创建子序列。
例如:创建平方值的列表
squares = []
for x in range(10):squares.append(x**2)
print(squares)
这段代码创建(或覆盖)变量 x,该变量在循环结束后仍然存在。
下述方法可以无副作用地计算平方列表:
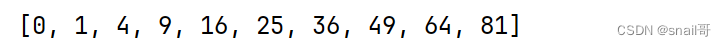
# 1)第一种方式
squares = list(map(lambda x : x**2 in range(10)))# 2) 第二种方式
squares = [x**2 for x in range(10)]
2.1 语法格式
列表推导式(List comprehension)是一种在一行代码中创建和操作列表的简洁方式。
它的基本语法形式如下:
[expression for item in iterable if condition]
expression是对item的操作或表达式,可以是有返回值的函数。
2.item是迭代变量,表示可迭代对象中的每个元素。iterable是可迭代对象,如列表、元组、字符串等。condition是一个可选的条件,用于过滤元素。
注意:列表推导式的方括号内包含以下内容:一个表达式,后面为一个 for 子句,然后,是零个或多个for或 if 子句。结果是由表达式依据 for 和if 子句求值计算而得出一个新列表。
[(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
"""上述推导式等同于:combs = []for x in [1,2,3]:for y in [3,1,4]:if x != y:combs.append((x, y))combs
"""
# 输出 [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
2.2 示例及应用
"""
筛选和转换数据:
列表推导式允许你根据特定的条件从一个列表中选择或转换元素,从而创建一个新的列表。例如,你可以过滤出所有的偶数或将列表中的字符串转换为大写。
"""
# 筛选偶数
even_numbers = [x for x in range(10) if x % 2 == 0]
print(even_numbers)# 过滤出字符串列表中长度大于3的单词
words = ['python', 'is', 'awesome', 'and', 'fun']
long_words = [word for word in words if len(word)>=3]
print(long_words)# 转换字符串为大写
words = ['hello', 'world', 'python']
upper_words = [word.upper() for word in words]
print(upper_words)
运行效果:

"""
生成序列:
通过列表推导式,你可以用一行代码生成各种序列,如数字序列、字符序列等。
"""
# 生成平方序列
squares = [x**2 for x in range(5)]
print(squares)# 生成字符序列
chars = [char for char in 'python']
print(chars)
运行效果:
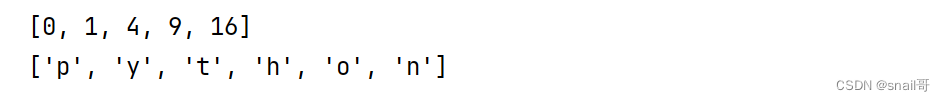
"""
嵌套迭代:
列表推导式支持嵌套,可以用来创建嵌套结构的数据,例如二维列表。
"""
# 创建二维列表
matrix = [[i * j for j in range(1, 4)] for i in range(1, 4)]
print(matrix)# 生成一个包含 3 行 4 列的二维列表,每个元素都是其行索引和列索引的和
matrix_o = [[row + col for col in range(4)] for row in range(3)]
print(matrix_o)
运行效果:
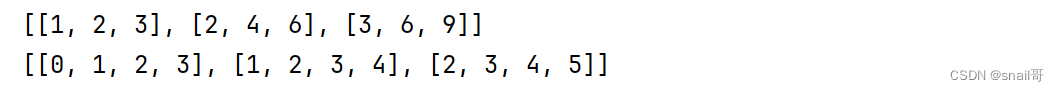
"""使用复杂的表达式和嵌套函数
"""
from math import pi
[str(round(pi,i)) for i in range(1,6)]
运行效果:
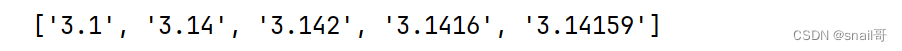
3. 元组推导式
在Python中,元组推导式(Tuple Comprehension)是一种用于创建元组的紧凑语法。它的语法结构与列表推导式类似,但使用圆括号()而不是方括号[]。
3.1 语法格式
tuple_variable = (expression for item in iterable if condition)
1.expression 是生成元组元素的表达式。
2.item 是可迭代对象中的每个元素。
3.iterable是一个可迭代对象,例如列表、字符串等。
4. condition是一个可选的条件,用于过滤元素。
3.2 示例及应用
"""
创建元组序列:
当需要生成一个元组序列时,元组推导式是一种简洁的方式。例如,可以使用元组推导式创建包含某种规律的数字、字符串或其他元素的元组序列。
"""
# 生成包含平方数的元组序列
squares_tuple = tuple(x**2 for x in range(5))
print(squares_tuple)
运行效果:

"""
转换数据:
当有一个可迭代的对象,并希望将其转换为元组时,可以使用元组推导式。这在处理数据时很常见。
"""
# 将字符串长度转换为元组
words = ['apple', 'banana', 'orange']
lengths_tuple = tuple(len(word) for word in words)
print(lengths_tuple)
运行效果:

"""
过滤数据:通过添加条件语句,可以使用元组推导式从可迭代对象中选择特定的元素。
"""
# 生成包含偶数平方数的元组序列
even_squares_tuple = tuple(x**2 for x in range(5) if x % 2 == 0)
print(even_squares_tuple)
运行效果:

"""
函数返回多个值:
在某些情况下,可能希望从函数中返回多个值作为元组,而元组推导式可以用于在函数中快速生成这样的元组。
"""
def get_coordinates():x_values = [1, 2, 3]y_values = [4, 5, 6]return tuple((x, y) for x, y in zip(x_values, y_values))coordinates = get_coordinates()
print(coordinates)
运行效果:

3.3 与生成器表达式区别
元组推导式(Tuple Comprehension)和生成器表达式(Generator Expression)在语法上很相似,但有一些关键的区别。以下是它们之间的主要区别:
3.3.1 返回类型
- 元组推导式返回一个元组(tuple)。
- 生成器表达式返回一个生成器对象(generator)。
3.3.2 语法
- 元组推导式使用圆括号 ()。
- 生成器表达式使用圆括号 (),但是在语法上可以省略,这与列表推导式不同。
# 元组推导式
tuple_comp = tuple(x**2 for x in range(5))# 生成器表达式
generator_expr = (x**2 for x in range(5))
3.3.3 内存占用
- 元组推导式会生成一个完整的元组对象,占用相应的内存。
- 生成器表达式生成一个生成器对象,它是一个惰性计算的序列,只在需要时生成元素,因此在内存上更为高效。
3.3.4 迭代方式
- 元组推导式一次性生成所有元素,可以直接进行索引、切片等操作。
- 生成器表达式是惰性的,只在每次迭代时生成一个元素,因此不能直接进行索引和切片等操作。
总体而言,如果需要一个一次性的、完整的序列,可以使用元组推导式;而如果想要一个惰性计算的序列,以节省内存,可以使用生成器表达式。选择取决于具体需求。
4. 字典推导式
字典推导式(Dictionary Comprehension)是一种在一行代码中创建字典的方法,类似于列表推导式。它允许你以简洁的方式从一个可迭代对象中创建一个字典.
4.1 语法格式
可以有0个或多个条件表达式,根据具体的需求决定是否使用条件。
{key_expression: value_expression for item in iterable if condition}
1.key_expression 是用于生成字典键的表达式。
2. value_expression 是用于生成字典值的表达式。
3.item 是可迭代对象中的每个元素。
4. if condition是一个可选的条件表达式,用于过滤元素。
4.2 示例及应用
字典推导式在许多场景下都是一种方便且简洁的方式来创建和操作字典。以下是一些常见的字典推导式的应用场景:
"""
转换数据格式:
当有一个可迭代对象,想要将其转换为字典形式时,字典推导式是一种便捷的方式。
例如,将元组列表转换为字典:
"""
tuple_list = [('a', 1), ('b', 2), ('c', 3)]
my_dict = {key: value for key, value in tuple_list}
print(tuple_list)
运行效果:

"""
过滤数据:
通过在字典推导式中添加条件表达式,可以过滤可迭代对象的元素,从而创建一个满足特定条件的字典。
例如,只选择某个范围内的元素
"""
original_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
filtered_dict = {key: value for key, value in original_dict.items() if value > 2}
print(filtered_dict)
运行效果:

"""
键或值的转换:
可以使用字典推导式来对字典的键或值进行某种转换。
例如,将字典的键和值交换:
"""
original_dict = {'a': 1, 'b': 2, 'c': 3}
swapped_dict = {value: key for key, value in original_dict.items()}
print(swapped_dict)
运行效果:

"""
处理嵌套结构:
当有一个嵌套的可迭代对象,想要将其展平为字典时,字典推导式也很有用。
例如,展平嵌套的字典:
"""
nested_dict = {'a': {'x': 1, 'y': 2}, 'b': {'x': 3, 'y': 4}}
flattened_dict = {outer_key: inner_value for outer_key, inner_dict in nested_dict.items() for inner_key, inner_value in inner_dict.items()}
print(flattened_dict)
运行效果:

"""
默认值处理:
在字典推导式中,可以使用字典的 get 方法或 default 关键字处理不存在的键,从而设置默认值。这在构建字典时非常有用。
"""
original_dict = {'a': 1, 'b': 2, 'c': 3}
keys = ['a', 'b', 'c']
default_value = 0
my_dict = {key: original_dict.get(key, default_value) for key in keys}
print(my_dict)
运行效果:

5. 集合推导式
在Python中,可以使用集合推导式来创建集合。集合推导式的语法与列表推导式类似,但是使用大括号{} 表示集合。
5.1 语法格式
{expression for item in iterable if condition}
expression是一个表达式,用于计算集合中的元素。
2.item是可迭代对象(如列表、元组等)中的每个元素。
3.iterable是一个可迭代对象,例如 range(1, 11)。condition是一个可选的条件,用于筛选满足条件的元素。
5.2 示例及应用
集合推导式在Python中是一个强大而灵活的工具,适用于多种应用场景。以下是一些常见的集合推导式的应用场景:
"""
过滤数据:
可以使用集合推导式从一组数据中筛选出满足特定条件的元素。
例如,从一个列表中选择所有大于某个阈值的数字。
"""
numbers = [1, 5, 8, 10, 15, 20]
filtered_numbers = {x for x in numbers if x > 10}
print(filtered_numbers)
运行效果:

"""
映射转换:
使用集合推导式可以对数据进行转换,生成一个新的集合。例
如,将字符串列表转换为它们的长度集合。
"""
words = ["apple", "banana", "orange"]
word_lengths = {len(word) for word in words}
print(word_lengths)
运行效果:

"""
去重:
创建一个不包含重复元素的集合。这对于从列表或其他可迭代对象中移除重复项非常有用。
"""
numbers_with_duplicates = [1, 2, 2, 3, 4, 4, 5]
unique_numbers = {x for x in numbers_with_duplicates}
print(unique_numbers)
运行效果:

"""
集合运算:
使用集合推导式进行集合运算,如并集、交集等。
例如,找到两个集合的交集。
"""
set1 = {1, 2, 3, 4, 5}
set2 = {3, 4, 5, 6, 7}
intersection = {x for x in set1 if x in set2}
print(intersection)
运行效果:

"""
条件化处理:
在集合推导式中,可以根据特定条件对元素进行处理。
例如,将列表中的奇数平方加倍。
"""
numbers = [1, 2, 3, 4, 5]
doubled_odd_squares = {x**2 * 2 for x in numbers if x % 2 != 0}
print(doubled_odd_squares)
运行效果:

6. 使用推导式的优点
-
简洁性
推导式允许以一种紧凑的方式表示数据转换和过滤,减少了冗余的代码行数。这使得代码更加简洁、清晰,同时减少了错误的可能性。 -
可读性
推导式提高了代码的可读性,尤其是对于简单的转换和过滤操作。它们可以帮助将复杂的操作用一行或几行代码清晰地表达出来,使得代码更易于理解。 -
效率
推导式通常比传统的迭代方式更高效。它们背后的实现在一些情况下可以提供更好的性能,因为它们是由底层的高效数据结构实现的。 -
功能性
推导式支持丰富的功能,包括条件过滤、多个迭代器的组合、元素的映射转换等。这使得推导式成为一种灵活而强大的工具,适用于各种不同的场景。 -
一致性
推导式提供了一种统一的语法结构,使得在不同的数据类型(列表、集合、字典等)上进行转换和过滤变得一致。这种一致性使得代码更易于维护和修改。 -
减少临时变量
使用推导式可以减少在代码中引入不必要的临时变量。这有助于保持代码的简洁性和可读性。 -
支持多种数据结构
不仅可以在列表中使用推导式,还可以在集合、字典等数据结构上使用,扩展了推导式的适用范围。
7. 参考
| 参考列表 |
|---|
| 官网:https://docs.python.org/zh-cn/3/tutorial/datastructures.html#list-comprehensions |
| 菜鸟教程:https://www.runoob.com/python3/python-comprehensions.html |

相关文章:
Python基础:推导式(Comprehensions)详解
1. 推导式概念 Python推导式(comprehensions)是一种简洁而强大的语法,用于从已存在的数据(列表、元组、集合、字典等)中创建新的数据结构。推导式包括: 列表推导式元组推导式字典推导式集合推导式 2. 列表…...
安防监控视频融合平台EasyCVR定制化页面开发
安防监控EasyCVR视频汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发、视频集中存储等。安防视频平台EasyCVR拓展性强,视频能力丰富,具体可实现视频监控直播、视频轮播、视频录像、云存储、回放与检索…...
Roll-A-Ball 游戏
Roll-A-Ball 游戏 1)学习资料 b站视频教程:https://www.bilibili.com/video/BV18W411671S/文档: * Roll-A-Ball 教程(一), * Roll-A-Ball 教程(二)线上体验roll-a-ball成品 * http://www-personal.umich.e…...
医疗影像数据集—CT、X光、骨折、阿尔茨海默病MRI、肺部、肿瘤疾病等图像数据集
最近收集了一大波关于CT、X光等医疗方面的数据集包含骨折、阿尔茨海默病MRI、肺部疾病等类型的医疗影像数据,废话不多说,给大家逐一介绍!! 1、彩色预处理阿尔茨海默病MRI(磁共振成像)图像数据集 彩色预处理阿尔茨海默病MRI(磁共…...
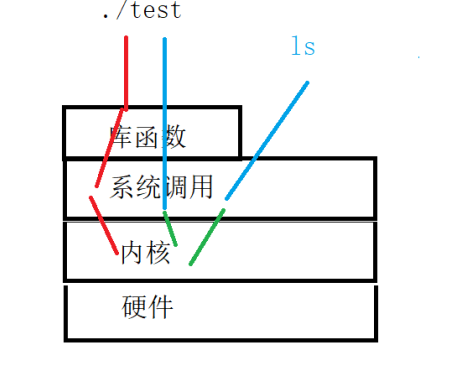
Linux僵死进程及文件操作
1.僵死进程(僵尸进程): 1.僵死进程产生的原因或者条件: 什么是僵死进程? 当子进程先于父进程结束,父进程没有获取子进程的退出码,此时子进程变成僵死进程. 简而言之,就是子进程先结束,并且父进程没有获取它的退出码; 那么僵死进程产生的原因或者条件就是:子进…...

用Python写一个浏览器集群框架
更多Python学习内容:ipengtao.com 在分布式爬虫和大规模数据采集的场景中,使用浏览器集群是一种有效的方式,可以提高数据采集的速度和效率。本文将介绍如何用Python编写一个简单但强大的浏览器集群框架,以应对需要使用多个浏览器实…...

【Github】git安装
我们经常需要对github上的项目进行复现或者使用,git指令可以方便我们更好地实现他们。 Part 0. 准备 配置代理IP 面对问题:关于登陆github网站网速慢、下载git项目网速慢。 解决:无论是windows还是linux系统,都可以找到/etc/ho…...
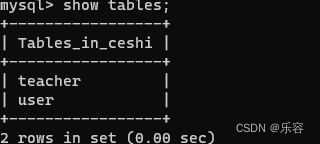
sql语法大全
1,创建数据库 create database 数据库名字; 2,查看所有的数据库名称 show databases; MySQL服务器已有4个数据库,这些数据库都是MySQL安装时自动创建的。 information_schema 和 performance_schema 数据库分别是 MySQL 服务器的数据字典(…...

小红书API接口测试 | 小红书笔记详情 API 接口测试指南
一、引言 随着互联网的发展,越来越多的应用开始使用API接口来提供服务。而API接口的测试也变得越来越重要。本文将介绍如何使用Python语言进行小红书笔记详情API接口的测试。 二、小红书笔记详情API接口介绍 小红书笔记详情API接口是用于获取指定笔记详细信息的接…...

实验六:Java流式编程与网络程序设计
一、字节输入/输出流实现数据的保存和读取 编程要求 根据提示,在右侧编辑器补充代码。 编写应用程序(SortArray.java),使用字节输入/输出流实现数据的保存和读取。 要求功能如下: 输入1~100之间的整型数据保存到数组…...

金字塔原理
金字塔原理 来自于麦肯锡公司的第一位女性咨询顾问芭芭拉•明托的著作《金字塔原理》。 原理介绍 此原理是一种重点突出、逻辑清晰、主次分明的逻辑思路、表达方式和规范动作。 金字塔的基本结构是:中心思想明确,结论先行,以上统下ÿ…...

VR全景技术助力政务服务大厅数字化,打造全新政务服务体验
引言: 随着科技的飞速发展,虚拟现实(VR)技术逐渐走进人们的视野。VR全景技术作为VR领域的一项重要应用,以其沉浸式、交互式的特点,正逐渐渗透到各行各业。政务服务大厅作为相关部门与民众之间的桥梁&#…...

使用Python实现SVM来解决二分类问题
下面是一个使用Python实现SVM来解决二分类问题的例子: # 导入所需的库 from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split from sklearn.svm import SVC import matplotlib.pyplot as plt# 生成一个二分类数据集 X, …...

合并PDF出现OOM异常
优化方法一:使用PdfSmartCopy类代替PdfCopy类。这个类可以在合并PDF文件时,检测并消除重复的对象,从而减少内存的占用。您可以参考以下代码示例: //创建一个Document对象 Document document new Document();//创建一个PdfSmartC…...

c语言-数据结构-链式二叉树
目录 1、二叉树的概念及结构 2、二叉树的遍历概念 2.1 二叉树的前序遍历 2.2 二叉树的中序遍历 2.3 二叉树的后序遍历 2.4 二叉树的层序遍历 3、创建一颗二叉树 4、递归方法实现二叉树前、中、后遍历 4.1 实现前序遍历 4.2 实现中序遍历 4.3 实现后序遍历 5、…...

DelayQueue介绍
5.1 DelayQueue介绍&应用 DelayQueue就是一个延迟队列,生产者写入一个消息,这个消息还有直接被消费的延迟时间。 需要让消息具有延迟的特性。 DelayQueue也是基于二叉堆结构实现的,甚至本事就是基于PriorityQueue实现的功能。二叉堆结构…...

centos8 redis 6.2.6源码安装+主从哨兵
文章目录 centos8 redis 6.2.6源码安装主从哨兵下载解压编译安装配置配置systemd服务启停及开机启动登录验证主从同步配置哨兵哨兵注册systemd centos8 redis 6.2.6源码安装主从哨兵 单机安装 下载解压 cd /data wget http://download.redis.io/releases/redis-6.2.6.tar.gz…...

机器学习之危险品车辆目标检测
危险品的运输涉及从离开仓库到由车辆运输到目的地的风险。监控事故、车辆运动动态以及车辆通过特定区域的频率对于监督车辆运输危险品的过程至关重要。 在线工具推荐: 三维数字孪生场景工具 - GLTF/GLB在线编辑器 - Three.js AI自动纹理化开发 - YOLO 虚幻合成数…...
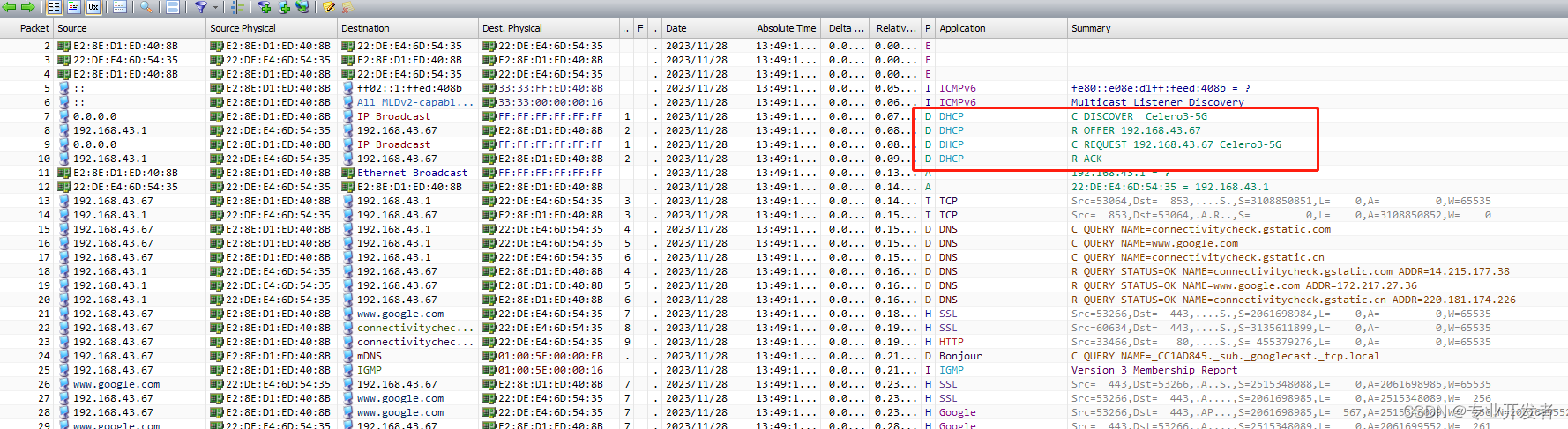
DHCP协议及实验omnipeek抓包工具分析 IPv4协议
一 抓包命令 adb shell tcpdump -i wlan0 -w /data/tcpdump.pcap 抓包后截图如下 二 DHCP是什么 2.1 DHCP定义 DHCP( Dynamic Host Configuration Protocol, 动态主机配置协议)定义: 存在于应用层(OSI) 前身是BOOTP(Bootstrap Protocol)协议 是一个使用UDP(User …...

考过了PMP,面试的时候应该怎么办?
近期喜番在后台收到了很多同学们的私信,表示自己已经过了8月份的PMP考试,开始着手往项目管理岗位转型,但是对于项目管理岗位的面试却一筹莫展。放轻松,大家的需求喜番都了解了,喜番给大家总结了一些项目经理在面试的时…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

简单学习 --> SSE
我们使用AI时,AI对我们说的话不会一次性把全部内容弹出来,而是会像流水一样,一点点吐出来,那么这种丝滑的交互体验,背后的核心就是 SSE (Server-Sent Events)。 什么是 SSE? SSE(Server-Sent …...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...

使用libusb-win32驱动复活老旧USB硬件:以Elektor Magic Eye为例
1. 项目概述:让老硬件在新时代焕发新生手头有一台十多年前的《Elektor》杂志上刊登的“Magic Eye EM84”复古VFD显示屏项目,想把它接到Windows 10电脑上当个酷炫的CPU占用率显示器,却发现官方提供的“AVR309”USB驱动在新系统上彻底罢工了。这…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...

终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代
终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为电脑无法直接运行手机应用…...