动手学深度学习(三)---Softmax回归
文章目录
- 一、理论知识
- 1.图像分类数据集
- 2.softmax回归的从零开始实现
- 3.Softmax简洁实现
- 【相关总结】
- torch.sum()
- torch.argmax()
- isinstance():[python]
softmax回归
一、理论知识
- 回归估计一个连续值
- 分类预测一个离散类别
回归 - 单连续数值输出
- 自然区间R
- 跟真实值的区别作为损失

分类 - 通常多个输出
- 输出i是预测为第i类的置信度

一般我们使用交叉熵用来衡量两个概率的区别

将它作为损失

其梯度是真实概率和预测概率的区别:

其梯度是真实概率和预测概率的区别
损失函数
(1)L2 Loss

(2)L1 Loss

(3)Huber’s Robust Loss

优点:当预测值与真实值相差较远时候,梯度还是按照均匀的变化,在比较靠近的时候,梯度绝对值会变小,保证优化比较平滑。
1.图像分类数据集
MNIST数据集是图像分类中广泛使用的数据集之一,但其较为简单,我们将使用Fashion-MNIST数据集
1.导入需要的包
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2ld2l.use_svg_display() #通过svg显示图片,清晰度更高
2.通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中
Fashion-MNIST由10个类别的图像组成
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
# 并处以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans,download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False,transform=trans,download=True)len(mnist_train), len(mnist_test)
(60000, 10000)
mnist_train[0][0].shape #第0个example
torch.Size([1, 28, 28])
3.两个可视化数据集的函数
def get_fashion_mnist_labels(labels): """返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): """绘制图像列表"""figsize = (num_cols * scale, num_rows * scale)
# 创建一个包含多个子图的图形
# 下划线表示我们对图形本身不感兴趣,只关心返回的子图像_,axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
# print(_)
# print(axes)
# print(type(axes)) #numpy
# 使用NumPy中的flatten()函数,将axes数组从多维数组变成一维数组
# axes:原本是一个包含多个子图对象的二维数组axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):# 图片张量ax.imshow(img.numpy())else:# PIL图片ax.imshow(img)
# 设置子图的X轴和Y轴刻度标签不可见ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:
# print(titles)
# 给每个子图设置相应的标题ax.set_title(titles[i])return axes# iter():函数生成迭代器
# next():返回迭代器的下一个项目,一般与iter()结合使用
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))# 拿到第一个小批量的数据X和y标签y
# print(y)
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));
# 绘制两行图片,每一行有9张图片
# titles是每张图片的标号

4.读取一小批数据,大小为batch_size
batch_size = 256def get_dataloader_workers():"""使用4个进程来读取数据"""return 4train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=4)
# num_workers = 0代表单进程而不是没有进程timer = d2l.Timer() # Timer函数用于测试速度
# print(train_iter)batch = next(iter(train_iter))
print(batch)# for X,y in train_iter:
# # print(train_iter)# # for X, y in train_iter:
# continue
f'{timer.stop():.2f} sec' # 输出读取数据所用的秒数,精度为2位小数
‘3.51 sec’
❗❗❗
如果运行出现此种报错,一般是由于taLoader的多进程造成的,我们可以通过设置num_workers=0代表单进程加载.

5.定义load_data_fashion_mnist函数
为了方便后续使用,我们可以把上面的各个实现数据读取的操作,写在函数中
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.inserts(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data",train=True,transform=trans,download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data",train=True,transform=trans,download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=True,num_workers=get_dataloader_workers()))
2.softmax回归的从零开始实现
1.导入相关包
import torch
from IPython import display
from d2l import torch as d2lbatch_size = 256
# 返回训练数据和测试数据的迭代器
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)2.将展平每个图像,将它们视为长度为784的向量。因为数据有10个类别,所以网格输出维度为
# 28*28 = 784
num_inputs = 784
num_outputs = 10W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
3.给定一个矩阵X,对所有元素求和
X = torch.tensor([[1.0, 2.0, 3.0], [4.0,5.0,6.0]])
# 按照维度为0进行,将行数变为1,按照维度为1进行求和,把列数变为1,keepdim表示保持维度
X.sum(0, keepdim=True), X.sum(1, keepdim=True)
(tensor([[5., 7., 9.]]),tensor([[ 6.],[15.]]))
4.实现softmax
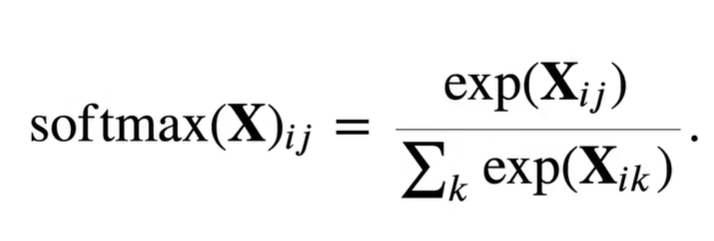
def softmax(X):X_exp = torch.exp(X)
# 按行求和print('----------------X_exp------------')print(X_exp)partition = X_exp.sum(1, keepdim=True)print('-------------partition------------')print(partition)
# 运用广播机制print('----------X_exp / partition--------')print(X_exp / partition)return X_exp / partition
5.将每个元素变成一个非负数,依据概率原理,每行总和为1
X = torch.normal(0, 1, (2, 5))
print(X)
X_prob = softmax(X)
X_prob, X_prob.sum(1)
tensor([[-0.0477, -0.8353, 0.6251, -0.0551, -1.3545],[ 1.9616, -0.2592, -1.7372, 1.6476, -0.1598]])
----------------X_exp------------
tensor([[0.9534, 0.4337, 1.8684, 0.9464, 0.2581],[7.1107, 0.7717, 0.1760, 5.1943, 0.8523]])
-------------partition------------
tensor([[ 4.4600],[14.1051]])
----------X_exp / partition--------
tensor([[0.2138, 0.0972, 0.4189, 0.2122, 0.0579],[0.5041, 0.0547, 0.0125, 0.3683, 0.0604]])
(tensor([[0.2138, 0.0972, 0.4189, 0.2122, 0.0579],[0.5041, 0.0547, 0.0125, 0.3683, 0.0604]]),tensor([1., 1.]))
1
6.实现softmax回归模型
def net(X):return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
7.创建一个数据y_hat,其中包含2个样本在3个类别的预测概率,使用y作为y_hat中概率的索引
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
# y0 = 0 = 0.1 y1 = 2 = 0.5
y_hat[[0, 1], y]
tensor([0.1000, 0.5000])
8.实现交叉熵损失函数
def cross_entropy(y_hat, y):return -torch.log(y_hat[range(len(y_hat)), y])cross_entropy(y_hat, y)
tensor([2.3026, 0.6931])
9.将预测类别与真实y元素进行比较
def accuracy(y_hat, y):"""计算预测正确的数量"""
# print(y_hat.shape) 列数大于1if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
# 将每一行元素值最大的下标存下来y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == y
# 转成和y同样的形状并求和return float(cmp.type(y.dtype).sum())# 预测正确的样本数/y的长度
accuracy(y_hat, y) / len(y)
0.5
10.评估在任意模型net的准确率
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
11.Accumulator实例中创建了2个变量,用于分别存储正确预测的数量和预测的总数量
class Accumulator:"""在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]evaluate_accuracy(net, test_iter)
0.1285
12.Softmax回归的训练
def train_epoch_ch3(net, train_iter, loss, updater): #@save"""训练模型一个迭代周期(定义见第3章)"""if isinstance(net, torch.nn.Module):net.train() # Accumulator(3)创建3个变量:训练损失总和、训练准确度总和、样本数metric = Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y)# 判断updater是否为优化器if isinstance(updater, torch.optim.Optimizer):# 使用PyTorch内置的优化器和损失函数updater.zero_grad() #把梯度设置为0l.mean().backward() #计算梯度updater.step() #自更新else:# 使用定制的优化器和损失函数# 自我实现的话,l出来是向量,先求和再求梯度l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度,metric的值由Accumulator得到return metric[0] / metric[2], metric[1] / metric[2]13.定义一个在动画中绘制数据的使用程序类
class Animator: """在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使用lambda函数捕获参数self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()display.display(self.fig)display.clear_output(wait=True)14.训练函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): """训练模型(定义见第3章)"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])# num_epochs:训练次数for epoch in range(num_epochs):# train_epoch_ch3:训练模型,返回准确率和错误度train_metrics = train_epoch_ch3(net, train_iter, loss, updater)# 在测试数据集上评估精度test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metrics15.小批量随机梯度下降来优化模型的损失函数
lr = 0.1def updater(batch_size):return d2l.sgd([W, b], lr, batch_size)16.模型训练10个迭代周期
num_epochs = 10if __name__ == "__main__":train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)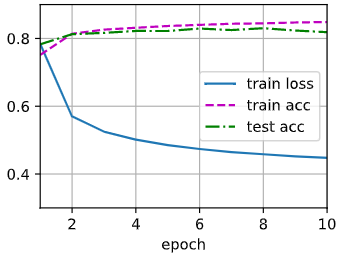
17.预测
def predict_ch3(net, test_iter, n=6): """预测标签"""for X, y in test_iter:breaktrues = d2l.get_fashion_mnist_labels(y) # 实际标签preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1)) #预测标签,取最大化概率titles = [true +'\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])# predict_ch3(net, test_iter)if __name__ == "__main__":predict_ch3(net, test_iter)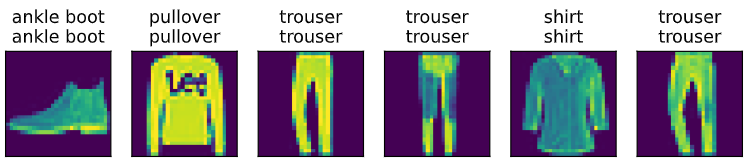
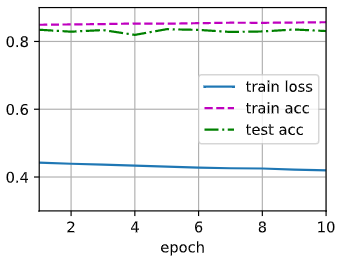
3.Softmax简洁实现
import torch
from torch import nn
from d2l import torch as d2lbatch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
train_iter.num_workers = 0
test_iter.num_workers = 0
1.softmax回归的输出层是一个全连接层
# PyTorch不会隐式地调整输入的形状
# 因此,我们定义了展平层 在线形层前调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);
2.在交叉熵损失函数中传递未归一化的预测,并同时计算softmax及其对数
loss = nn.CrossEntropyLoss(reduction='none')
3.使用学习率为0.1的小批量随机梯度下降作为优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
num_epoches = 10
train_ch3(net, train_iter, test_iter, loss, num_epoches, trainer)
【相关总结】
torch.sum()
(1)torch.sum(input, *, dtype=None):返回输入张量input所有元素的和。
(2)torch.sum(input,dim,keepdim=False, *,dtype=None):返回指定维度进行求和
import torch
x = torch.ones((2, 3))x_sum = torch.sum(a)
x_0 = torch.sum(a, dim=0)
x_1 = torch.sum(a, dim=1)print(x)
print(x_0)
print(x_1)
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([2., 2., 2.])
tensor([3., 3.])
torch.argmax()
import torch
x = torch.rand(3, 2)
print(x)
y0 = torch.argmax(x, dim=0) #dim=0,返回每一列最大值的索引
print(y0)
y1 = torch.argmax(x, dim=1) #dim=1,返回每一行最大值的索引
print(y1)
tensor([[0.9407, 0.8543],
[0.4057, 0.6790],
[0.0154, 0.3698]])
tensor([0, 0])
tensor([0, 1, 1])
isinstance():[python]
函数isinstance()可以判断一个变量的类型。
相关文章:
动手学深度学习(三)---Softmax回归
文章目录 一、理论知识1.图像分类数据集2.softmax回归的从零开始实现3.Softmax简洁实现 【相关总结】torch.sum()torch.argmax()isinstance():[python] softmax回归 一、理论知识 回归估计一个连续值分类预测一个离散类别 回归单连续数值输出自然区间R跟真实值的区别作为损失 …...

爬虫代理技术与构建本地代理池的实践
爬虫中代理的使用: 什么是代理 代理服务器 代理服务器的作用 就是用来转发请求和响应 在爬虫中为何需要使用代理? 隐藏真实IP地址:当进行爬取时,爬虫程序会发送大量的请求到目标网站。如果每个请求都使用相同的IP地址ÿ…...
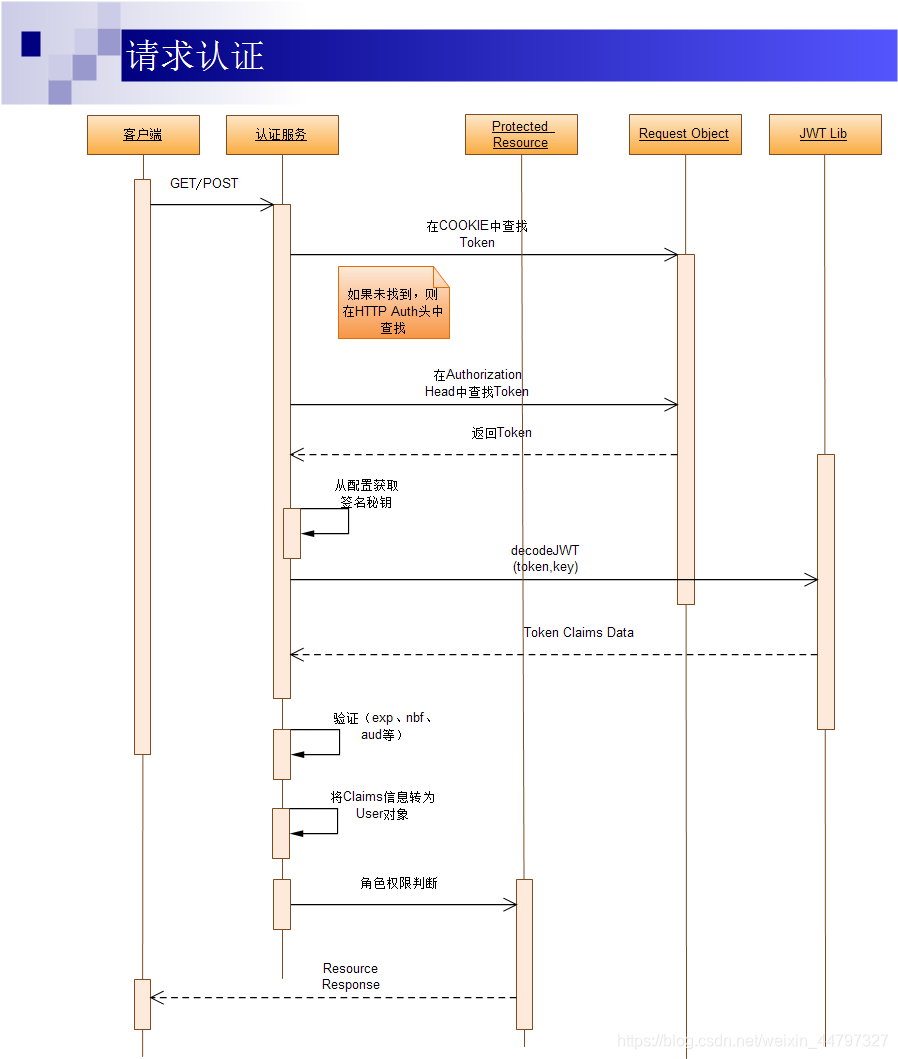
token认证机制,基于JWT的Token认证机制实现,安全性的问题
文章目录 token认证机制几种常用的认证机制HTTP Basic AuthOAuthCookie AuthToken AuthToken Auth的优点 基于JWT的Token认证机制实现JWT的组成认证过程登录请求认证 对Token认证的五点认识JWT的JAVA实现 基于JWT的Token认证的安全问题确保验证过程的安全性如何防范XSS Attacks…...

什么是计算机病毒?
计算机病毒 1. 定义2. 计算机病毒的特点3. 计算机病毒的常见类型和攻击方式4. 如何防御计算机病毒 1. 定义 计算机病毒是计算机程序编制者在计算机程序中插入的破坏计算机功能或者破坏数据,影响计算机使用并且能够自我复制的一组计算机指令或程序代码。因其特点与生…...
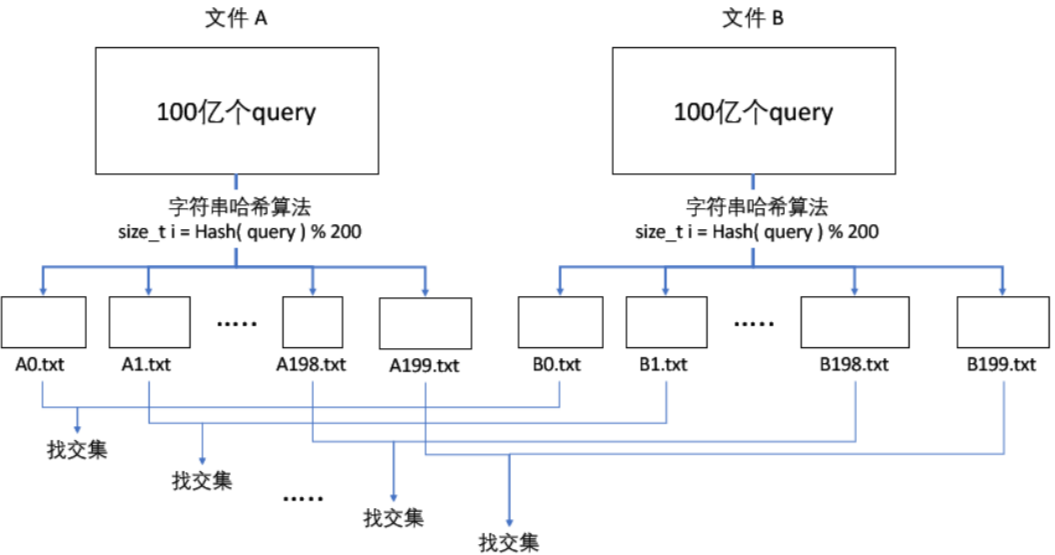
【C++】哈希(位图、布隆过滤器)
一、哈希的应用(位图和布隆过滤器) 1、位图(bitset) (1)位图概念 【题目】 给 40亿 个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这 40亿 个数中。…...

LeetCode198.打家劫舍
打家劫舍和背包问题一样是一道非常经典的动态规划问题,只要做过几道动态规划的题,这道题简直就非常容易做出来。我应该花了10来分钟左右就写出来了,动态规划问题最重要的就是建立状态转移方程,就是说如何从上一个状态转移到下一个…...
Appium PO模式UI自动化测试框架——设计与实践
1. 目的 相信做过测试的同学都听说过自动化测试,而UI自动化无论何时对测试来说都是比较吸引人的存在。相较于接口自动化来说,它可以最大程度的模拟真实用户的日常操作与特定业务场景的模拟,那么存在即合理,自动化UI测试自然也是广…...
使用VUE3实现简单颜色盘,吸管组件,useEyeDropper和<input type=“color“ />的使用
1.使用vueuse中的useEyeDropper来实现滴管的功能和使用input中的type"color"属性来实现颜色盘 效果: 图标触发吸管 input触发颜色盘 组件代码部分 :<dropper> ---- vueuse使用 <template><div class"sRGBHexWrap fbc…...
)
matlab提取特征(医学图像)
乳腺肿瘤图片提取特征: %形态特征 %周长 面积 周长面积比 高度 宽度 纵横比 圆度 矩形度 伸长度 拟合椭圆长轴长 拟合椭圆短轴长 %拟合椭圆长轴与皮肤所夹锐角 最小外接凸多边形面积 最小外接凸多边形面积与肿瘤区面积比 %小叶树 叶指数 %纹理特征 %方差 熵 最小边差异 四个方…...
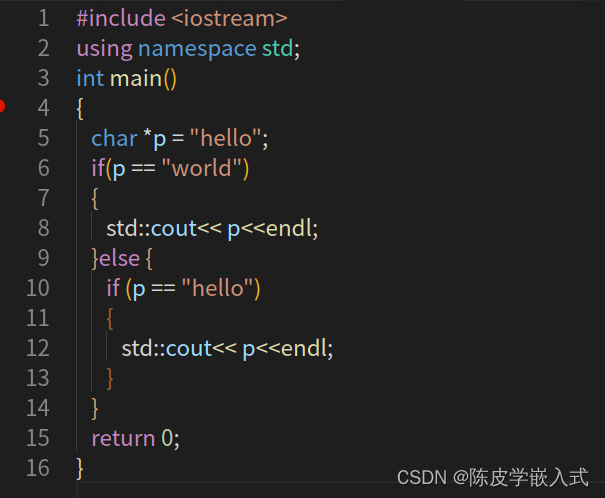
P4 C++ 条件与分支(if)
前言 今天我们来看看条件语句,换句话说,也就是 if 语句、if else 和 else if 等等这写语句。 我知道大家基本上已经非常了解 if 语句和所有 C 中的分支语句,但我还是鼓励你们继续看完这一讲,这里可能包含一些新东西。我们还会深入…...
django+drf+vue 简单系统搭建 (4) 用户权限
权限控制是web中的重要组成部分。与以往的博客系统不同,本次工具页面仅支持注册用户。 每个注册用户都能访问到工具页面,并且提交自己的task来选择具体的工具来处理自己提交的文件。每个注册用户都只能访问到自己提交的task,而管理员则可以查…...

stm32 计数模式
计数模式 但是对于通用定时器而言,计数器的计数模式不止向上计数这一种。上文基本定时器中计数器的计数模式都是向上计数的模式。 向上计数模式:计数器从0开始,向上自增,计到和自动重装寄存器的目标值相等时,计数器清…...
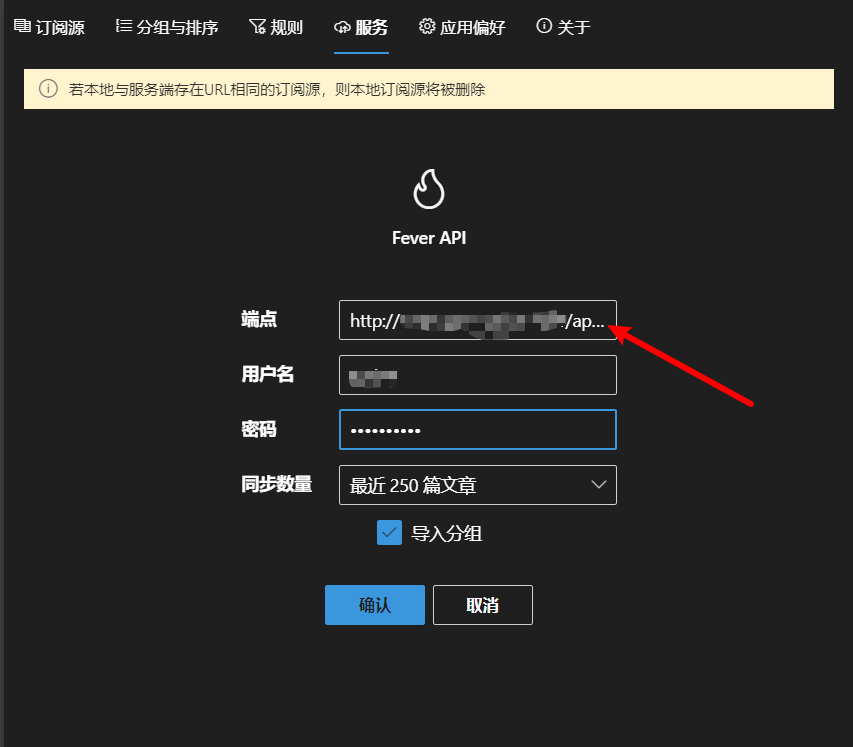
rss服务搭建记录
layout: post title: RSS subtitle: vps搭建RSS服务 date: 2023-11-27 author: Sprint#51264 header-img: img/post-bg-universe.jpg catalog: true tags: - 折腾 文章目录 引言RSShub-dockerRSS-radarFreshrssFluent reader获取fever api配置Fluent Reader同步 结语 引言 一个…...

GEE 23:基于GEE实现物种分布模型之随机森林法
基于GEE实现物种分布模型之随机森林法 1.物种分布数据2.研究区绘制3.预测因子选择 1.物种分布数据 根据研究目的和需要导入物种数据: // Load presence data var Data ee.FeatureCollection("users/************736/Distribution"); print(Original da…...
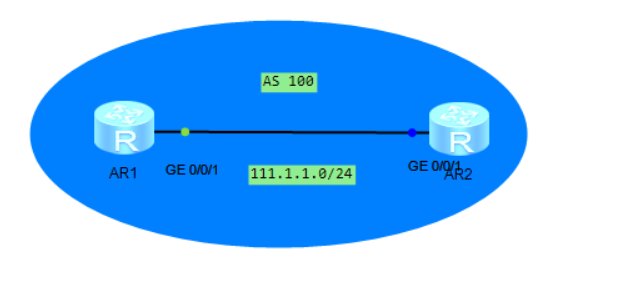
HCIE 01:基于前缀列表的BGP ORF功能
当运行BGP协议的某台设备上,针对入方向配置了基于ip-prefix的路由过滤,过滤了邻居发送的路由; 目前想,通过在peer关系的两端设备上都配置ORF功能,实现路由发送端只能送路由接收端过滤后的路由; ORF功能的说…...
基于SSM的云鑫曦科技办公自动化管理系统设计与实现
基于SSM的云鑫曦科技办公自动化管理系统设计与实现 摘 要: 随着时代的发展,单位办公方式逐渐从传统的线下纸张办公转向了使用个人pc的线上办公,办公效率低下的传统纸质化办公时代的淘汰,转型到信息化办公时代,面对当今数据逐渐膨…...

Angular项目中如何管理常量?
在Angular项目中,你可以使用不同的方式来管理常量。以下是一些常见的方法: 1、常量文件: 创建一个单独的 TypeScript 文件,其中包含你的常量。例如,创建一个名为 constants.ts 的文件,并在其中定义你的常量…...

【机器学习 | 可视化】回归可视化方案
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...

树与二叉树堆:链式二叉树的实现
目录 链式二叉树的实现: 前提须知: 前序: 中序: 后序: 链式二叉树的构建: 定义结构体: 初始化: 构建左右子树的指针指向: 前序遍历的实现: 中序…...

C++面试的一些总结day1:指针和引用的区别
文章目录 指针和引用的区别和作用定义区别作用 指针和引用的区别和作用 定义 指针:指针是一个变量,其值为指向对象的内存地址,而不是值本身。引用:可以理解为对象的别名,是另外一个变量的直接别名,用于创…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析
DeTikZify:基于AI的TikZ图形程序自动生成技术深度解析 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify DeTikZify是一款革命性的多模态…...

如何永久备份微信聊天记录:3步完成数据导出的终极指南
如何永久备份微信聊天记录:3步完成数据导出的终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...