线性表——(2)线性表的顺序存储及其运算的实现

归纳编程学习的感悟,
记录奋斗路上的点滴,
希望能帮到一样刻苦的你!
如有不足欢迎指正!
共同学习交流!
🌎欢迎各位→点赞 👍+ 收藏⭐ + 留言📝
看到美好,感受美好,屏蔽阴霾!
一起加油!

目录
一、顺序表:
二、顺序表基本运算的实现:
💦顺序表的初始化:
💦插入运算 :
☘️顺序表的数据元素的插入算法:
💦删除运算:
☘️顺序表的数据元素的删除算法:
💦按值查找 :
☘️顺序表的数据元素查找算法:
三、顺序表的其他运算举例:
💦例1:
☘️顺序表的划分算法:
💦例2:
☘️顺序表的合并算法:
💦例3:
☘️两个顺序表的比较算法:
四、总结:
五、共勉:
一、顺序表:
线性表的顺序存储是指在内存中用地址连续的一块存储空间顺序存放线性表中的各数据元素,用这种存储形式存储的线性表称为顺序表。因为内存中的地址空间是线性的,所以用物理位置关系上的相邻性实现数据元素之间的逻辑相邻关系既简单又自然。线性表的顺序存储示意图如图 A所示,设 a 的存储地址为 Loc(a),每个数据元素占 d 个存储单元,则第 i个数据元素的地址为:
Loc(a
)=Loc(a
)+(i-1)*d 1<=i<=n
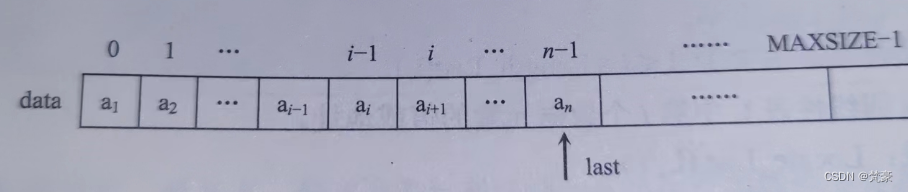
图A 线性表的顺序存储示意图 这就是说,只要知道顺序表首地址和每个数据元素所占存储单元的个数就可求出第 i 个数据元素的地址,这也是顺序表具有按数据元素的序号随机存取的特点。
在程序设计语言中,一维数组在内存中占用的存储空间就是一组连续的存储区域,因此,用一维数组来表示顺序表的数据存储区域是再合适不过的了。考虑到线性表有插入、删除等运算,即表长是可变的,因此,数组的容量要设计得足够大,设用 data[MAXSIZE]来表示,其中 MAXSIZE是一个根据实际问题定义的足够大的整数,线性表中的数据元素从 data[0]开始依次顺序存放,但当前线性表中的实际数据元素个数可能未达到 MAXSIZE 个,因此需用变量 last 记录当前线性表中最后一个数据元素在数组中的位置,即 last 具有指针的作用,始终指向线性表中最后一个数据元素,因此,表空时 last =-1。这种存储思想的具体描述可以是多样的,如可以是:datatype data[MAXSIZE];int last;这样表示的顺序表如图 A 所示,表长为 last+1,数据元素分别存放在 data[0]到 data[last]中这样使用简单方便,但有时不便于管理。
从结构性上考虑,通常将 data 和 last 封装成一个结构,作为顺序表的数据类型:
typedef struct{datatype data[MAXSIZE];int last; }SeqList;定义一个顺序表:
SeqList L这样表示的线性表如图(a) 所示。表长 = L.last+1,线性表中的数据元素 a1至 an分别存放在 L.data[0]至 L.data[L.last]中.其实有时定义一个指向 SeqList 类型的指针更为方便:
SeqList *LL是一个指针变量,线性表的存储空间通过 L=malloc(sizeof(SeqList)运算来获得。L 中存放的是顺序表的地址,这样表示的线性表如图 (b) 所示。表长表示为(*L).last+1 或 L->last+1,线性表的存储区域为 L->data,线性表中数据元素的存储空间为:
L->data[0] ~ L->data[L->last]


二、顺序表基本运算的实现:
根据以上线性表顺序存储结构定义,确定了其存储方式之后,就可以讨论其基本运算的实现方法(即实现算法)了,同时还要对算法进行初步的分析。
💦顺序表的初始化:
顺序表的初始化即构造一个空表,这对顺序表是一个加工型的运算,因此,将L设为指针参数,首先动态分配存储空间,然后将表中 last 指针置为-1,表示顺序表中没有数据元素。算法如下:
SeqList *init_SeqList(){ SeqList *L;L=malloc(sizeof(SeqList));L->last=-1;return L; }设调用函数为主函数,主函数对初始化函数的调用如下:
main(){SeqList *L;L=init_SeqList();…… }
💦插入运算 :
线性表的插入是指在表的第 i个位置上插入一个值为x 的新数据元素,插入后使原表长为 n的线性表 (ai, a2,…,ai-1,ai, ai+1,…,an) 成为表长为n+1 的线性表 (a1,a2,…,ai-1,x,ai, ai+1,…,an)。i的取值范围为1<=i<=n+1。
在顺序表上完成插入运算通过以下步骤进行:
✨将 ai~an顺序向后移动,为新数据元素让出位置;
✨将x置入空出的第i个位置;
✨修改 last 指针 (相当于修改表长),使之仍指向最后一个数据元素。
图B所示为顺序表中的插入运算示意图。
图B 顺序表中的插入运算示意图 ☘️顺序表的数据元素的插入算法:
int Insert_SeqList(SeqList *L,int i,datatype x){int j;if(L->last==MAXSIZE-1){printf("表满");return -1;//表空间已满,不能插入 }if(i>L->last+2||i<1){//检查插入位置的正确性 printf("位置错");return 0; } for(j=L->last;j>=i-1;j--){L->data[j+1]=L->data[j];//节点移动 } L->data[i-1]=x;//新数据元素插入 L->last++;//last指针仍指向最后一个数据元素 return 1; }在本算法中应注意以下问题:
- ⚡顺序表中数据区域有 MAXSIZE 个存储单元,所以向顺序表中插入新数据元素时应先检查表空间是否满了,在表满的情况下不能再进行插入运算,否则会产生溢出错误。
- ⚡要检验插入位置的有效性,这里i的有效范围是 1<=i<=n+1,其中 n 为原表长。
- ⚡注意数据的移动方向。
🔑插入算法的时间复杂度分析:顺序表的插入运算,时间主要消耗在数据的移动上,在第i个位置上插入X,从ai到an都要向后移动一个位置,共需要移动n-i+1个数据元素,而i的取值范围为1<=i<=n+1,即有n +1个位置可以插入。设在第i个位置上进行插入运算的概率为 pi,则平均移动数据元素的次数为:
假设在第i个位置进行插入运算的可能性为等概率情况,即pi=1/(n+1),则
这说明在顺序表上进行插入运算,需平均移动表中一半的数据元素。显然其时间复杂度为O(n).
💦删除运算:
线性表的删除运算是指将表中第i个数据元素从线性表中去掉,删除后使原表长为 n的线性表 (a1,a2,…,ai-1,ai,ai+1,…,an)成为表长为n-1的线性表 (a1,a2,…,ai-1,ai+1,…,an),i的取值范围为1<=i<=n。
在顺序表上完成删除运算的步骤如下:✨将ai+1~an顺序向前移动;
✨修改 last 指针(相当于修改表长),使之仍指向最后一个数据元素。
图C所示为顺序表中的删除运算示意图。
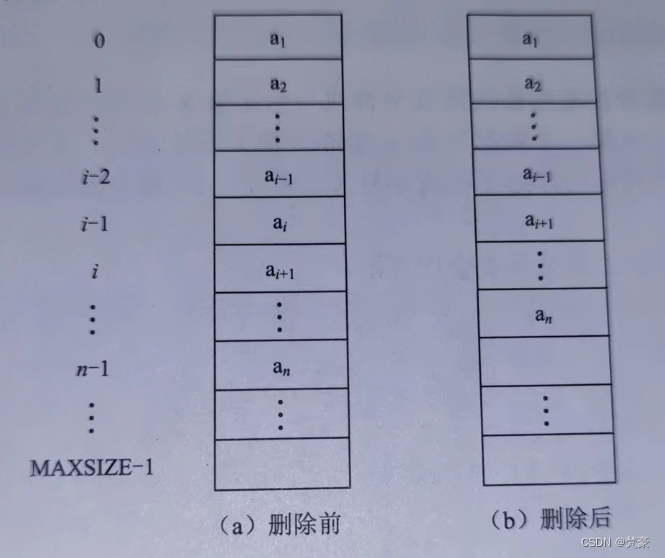
图C 顺序表中的删除运算示意图 ☘️顺序表的数据元素的删除算法:
int Delete_SeqList(SeqList *L,int i){int j;if(i<1||i>L->last+1){printf("不存在第i个数据元素");return 0;//检查空表及删除位置的合法性 }for(j=i;j<L->List;j++){L->data[i-1]=L->data[i];//向上移动 }L->last--;return 1;//删除成功 }本算法注意以下问题:
⚡删除第i个数据元素,i的取值为1<=i<=n,否则第个数据元素不存在,因此,要检查删
除位置的有效性。⚡当表空时不能进行删除运算,因表空时 L->last 的值为-1,条件(1 >L->last+1)也包括了对表空的检查。
⚡删除a之后,该数据已不存在,如果需要,先取出 a,再进行删除。
🔑删除算法的时间复杂度分析: 与插入运算相同,删除运算的时间主要消耗在移动表中数据元素上,删除第i个数据元素时,其后面的数据元素 ai+1~an都要向前移动一个位置,共移动了n-i 个数据元素,所以平均移动数据元素的次数为:
同样,在删除位置等概率情况下,pi=1/n,则
这说明在顺序表上做删除运算时大约平均需要移动表中一半的数据元素。显然,该算法的时间复杂度为 O(n)。
💦按值查找 :
线性表中的按值查找是指在线性表中查找与给定值 x 相等的数据元素。在顺序表中完成该运算最简单的方法是:从第一个数据元素 a 起依次和x进行比较,直到找到一个与x相等的数据元素,则返回它在顺序表中的存储下标或序号(二者差一);或者查遍整个表都没有找到与x相等的数据元素,返回-1。
☘️顺序表的数据元素查找算法:
int Location_SeqList(SeqList *L,datatype x){int i=0;while(i<=L.last&&L->data[i]!=x){i++;}if(i>L->last){return -1; }else return i;//返回的是存储位置 }本算法的主要运算是比较,显然比较的次数与 x 在表中的位置有关,也与表长有关。当 a1=x时,比较一次成功。当 an=x 时,比较n 次成功。其平均比较次数为(n+1)/2,时间复杂度为 O(n)。
三、顺序表的其他运算举例:
💦例1:
将顺序表 (a1, a2,…,an)重新排列为以a1为界的两部分: a1前面的值均比 a1 小,a1后面的值均比 a1大(这里假设数据元素的类型具有可比性,不妨设为整型),运算前后如图D
所示。这一运算称为划分,a1称为基准。划分的方法有多种,下面介绍的划分算法思路简单,但性能较差。
基本思路:从第二个数据元素开始到最后一个数据元素,逐一向后扫描。
✨当前数据元素 ai比 a1大时,表明它已经在 a1的后面,不必改变它与 a1之间的位置,继续比较下一个。
✨若当前数据元素比 a1小,说明它应该在 a1的前面,此时将它前面的数据元素依次向后移动一个位置,然后将它置于最前面。
☘️顺序表的划分算法:
void partition(SeqList *L){int i,j;datatype x,y;x=L->data[0];//将基准置于x中 for(i=1;i<L->last;i++){if(L->data[i]<x){//当前数据元素小于基准 y=L->data[i];for(j=i-1;j>0;j--){//移动 L->data[j+1]=L->data[j];}L->data[0]=y;}} }
💦例2:
设有顺序表 A 和 B,其数据元素均按从小到大的顺序排列,将它们合并成一个顺序表 C,要求C的数据元素也从小到大排列。
算法思路:依次扫描 A和B 的数据元素,比较 A、B 当前数据元素的值,将值较小的数据元素赋给 C,如此直到一个线性表扫描完毕,最后将未扫描完顺序表中的余下部分赋给 C 即可。C的容量要能够容纳 A、B两个线性表长度的和。☘️顺序表的合并算法:
void merge(SeqList A,SeqList B,SeqList *C){int i,j,k;i=j=k=0;while(i<=A.last&&j<=B.last){if(A.data[i]<B.data[i]){C->data[k++]=A.data[i++];}else{C->data[k++]=B.data[j++];}}while(i<=A.last){C->data[k++]=A.data[i++];}while(j<B.last){C->data[k++]=B.data[j++];}C->last=k-1; }上述算法的时间复杂度是 O(m+n),其中,m是A的表长,n是 B 的表长。
💦例3:
两个线性表的比较运算。假定两个线性表的比较方法如下:设A、B 是两个线性表,表长分别为 m和n。A'和 B'分别为 A 和B 中除去最大共同前缀后的子表。例如,A= (x,y,y,z,x,z),B= (x,y,y,z,y,x,x,z),两表最大共同前缀为 (x,y,y,z)。则A'=(x,z),B'= (y,x,x,z)。若A'=B'=空表,则A=B。若A'=空表且B!=空表,或两者均不为空表且A'的首数据元素小于 B’的首数据元素,则A<B;否则,A>B。
算法思路: 首先找出A、B 的最大共同前缀,然后求出 A'和 B,再按比较规则进行比较,A>B函数返回1;A=B 返回0:A<B 返回-1。
☘️两个顺序表的比较算法:
int compare(int A[],int B[],int m,int n){int i=0,j,AS[],BS[],ms=0,ns=0;//AS,BS作为A'B' while(A[i]=B[i]){//找出最大共同前缀 i++;}for(j=i;j<m;j++){//求A',ms为A'的长度 AS[j-i]=A[j];ms++;}for(j=i;j<n;j++){//求B',ns为B'的长度 BS[j-i]=B[j];ns++;}if(ms==ns&&ms==0){return 0;}else if(ms==0&&ns>0||ms>0&&ns>0&&AS[0]<BS[0]){return -1;}else{return 1;} }上述算法的时间复杂度是 O(m+n)。
四、总结:
学会顺序标的初始化,熟练掌握顺序表各种算法了基本结构。
五、共勉:
以上就是我对线性表——(2)线性表的顺序存储及其运算的实现的理解,希望本篇文章对你有所帮助,也希望可以支持支持博主,后续博主也会定期更新学习记录,记录学习过程中的点点滴滴。如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对线性表的理解,请持续关注我哦!!!
相关文章:
线性表——(2)线性表的顺序存储及其运算的实现
归纳编程学习的感悟, 记录奋斗路上的点滴, 希望能帮到一样刻苦的你! 如有不足欢迎指正! 共同学习交流! 🌎欢迎各位→点赞 👍 收藏⭐ 留言📝 看到美好,感受美好&a…...
数据结构 -- 图论之最小生成树
目录 1.最小生成树算法 1.Kruskal算法 2.Prim算法 1.最小生成树算法 定义:最小生成树算法:连通图有n个顶点组成,那么此时的图的每一个点都能相互连接并且边的个数为n-1条,那么此时该图就是最小生成树. 下面量算法有几个共同的特点: 1.只能使用图中权值最小的边来构造生成树 …...

【已解决】游戏缺少xinput1_3.dll的详细解决方案与详情解析
在现代科技日新月异的时代,电脑已经成为我们生活和工作中不可或缺的工具。然而,由于各种原因,电脑可能会出现一些问题,其中之一就是xinput1_3.dll文件的缺失。本文将详细介绍xinput1_3.dll丢失对电脑的影响以及丢失的原因…...
华天动力-OA8000 MyHttpServlet 文件上传漏洞复现
0x01 产品简介 华天动力OA是一款将先进的管理思想、 管理模式和软件技术、网络技术相结合,为用户提供了低成本、 高效能的协同办公和管理平台。 0x02 漏洞概述 华天动力OA MyHttpServlet 存在任意文件上传漏洞,未经身份认证的攻击者可上传恶意的raq文件…...

小航助学题库蓝桥杯题库c++选拔赛(23年8月)(含题库教师学生账号)
需要在线模拟训练的题库账号请点击 小航助学编程在线模拟试卷系统(含题库答题软件账号) 需要在线模拟训练的题库账号请点击 小航助学编程在线模拟试卷系统(含题库答题软件账号)...

[Ubuntu 18.04] RK3399搭建NFS服务实现共享目录
NFS(Network File System)是一种分布式文件系统协议,允许远程计算机通过网络访问存储在另一台计算机上的文件。它使得多台计算机可以共享文件,并且可以在不同计算机之间实现文件的透明访问和共享。 以下是 NFS 服务器的一些特点和介绍: 文件共享:NFS 服务器允许将存储在…...

Java---抽象类讲解
文章目录 1. 抽象类概述2. 抽象类特点3. 抽象类的成员特点4. 抽象类猫狗应用 1. 抽象类概述 在Java中,一个没有方法体的方法应该定义为抽象方法;而类中如果有抽象方法,该类必须定义为抽象类。 2. 抽象类特点 1. 抽象类和抽象方法必须使用abst…...

CNAS认可是什么?CNAS软件测试报告如何获取?
一、CNAS认可是什么? CNAS认可是指中国合格评定国家认可委员会的认可程序。CNAS是中国最高级别的认可机构,负责审核和认可符合国家标准的实验室、检测机构和认证机构。通过CNAS认可,机构可以获得国际公认的认可证书,证明其测试结果和认证…...

Tomcat 修改版本号
lib 目录下增加文件 /lib/org/apache/catalina/util/ServerInfo.properties ServerInfo.properties文件里面只需要输入server.info显示的版本号 其他可配置信息 server.infonginx server.number22.0 server.builtMay 11 2023 08:22:10 UTC 显示效果...

Python算法——霍夫曼编码树
Python中的霍夫曼编码树 霍夫曼编码是一种用于数据压缩的技术,通过构建霍夫曼编码树(Huffman Tree)来实现。这篇博客将详细讲解霍夫曼编码树的原理、构建方法和使用方式,并提供相应的Python代码实现。 霍夫曼编码原理 霍夫曼编…...

hql面试题之上海某资深数仓开发工程师面试题-求不连续月份的月平均值
1.题目 A,B两组产品的月平均值,月平均值是当月的前三个月值的一个平均值,注意月份是不连续的,如果当月的前面的月份不存在,则为0。如A组2023-04的月平均值为2023年1月的数据加2023-02月的数据的平均值,因为没有其他月…...
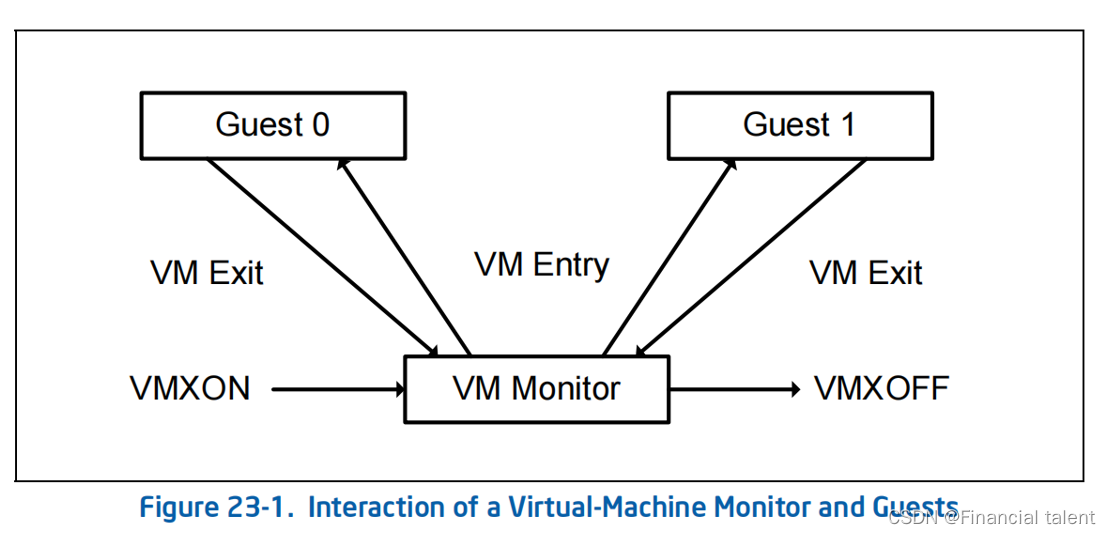
VT驱动开发
VT技术(编写一个VT框架) 1.VT技术介绍 1.技术介绍 1.VT技术 VT技术是Intel提供的虚拟化技术,全称为Intel Virtualization Technology。它是一套硬件和软件的解决方案,旨在增强虚拟化环境的性能、可靠性和安全性。VT技术允许在一台物理计算机上同时运…...

火柴人版王者-Java
主类 package com.sxt; import com.sxt.beast.Beast; import java.awt.Component; import java.awt.Graphics; import java.awt.Image; import java.awt.Toolkit; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.event.KeyAdapter…...

docker 中的–mount 和-v 参数有啥区别
docker 中的–mount 和-v 参数有啥区别 --mount 和 -v 是 Docker 中用于挂载卷(Volumes)的两种不同的方式。 --mount 参数: 这是一种更为灵活和强大的挂载方式,允许你指定多个选项。 使用 --mount 参数,你可以指定挂…...
设计规则:模块化的力量
这是一本比较冷门的书**《设计规则:模块化的力量》**,虽然豆瓣上只有58个评价,但是确实能学到很多东西。 这本书对我非常深远。不是是投资,创业,还是其他领域,模块化思想都能帮上你。这本书告诉我们生万物…...
)
数据结构与算法之递归: LeetCode 78. 子集 (Typescript版)
子集 https://leetcode.cn/problems/subsets/ 描述 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 示例 1 输入:nums [1,2,3]…...
C# 使用 Fody 监控方法执行时间
写在前面 在做性能调优的时候,经常需要跟踪具体方法的执行时间;通过插入Stopwatch的方案对代码的侵入性太高了,所以引入了 MethodTimer.Fody 类库,采用编译时注入的方式给方法动态加上Stopwatch 跟踪代码,只需要在目标…...
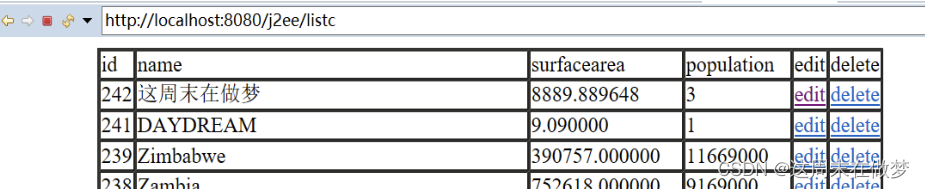
J2EE征程——第一个纯servletCURD
第一个纯servletCURD 前言在此之前 一,概述二、CURD1介绍2查询并列表显示准备实体类country编写 CountryListServlet配置web.xml为web应用导入mysql-jdbc的jar包 3增加准备增加的页面addc.html编写 CAddServlet配置web.xml测试 4删除修改CountryListServlet…...
BatchOutput PDF for Mac(PDF 批量处理软件)
BatchOutput PDF是一款适用于 Mac 的 PDF 批量处理软件。它可以帮助用户将多个 PDF 文件进行异步处理,提高工作效率。 BatchOutput PDF 可以自动化执行许多任务,包括 PDF 文件的打印、转换、分割、压缩、加密、重命名等,而且它还可以将自定义…...

记一次oracle错误处理
16:00:05 SQL> alter database open; alter database open * 第 1 行出现错误: ORA-01589: 要打开数据库则必须使用 RESETLOGS 或 NORESETLOGS 选项 16:00:49 SQL> startup ORA-01081: 无法启动已在运行的 ORACLE - 请首先关闭它 16:02:56 SQL> shutdown immediate O…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...