LangChain 9 模型Model I/O 聊天提示词ChatPromptTemplate, 少量样本提示词FewShotPrompt
LangChain系列文章
- LangChain 实现给动物取名字,
- LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字
- LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄
- LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieve
- LangChain 5易速鲜花内部问答系统
- LangChain 6根据图片生成推广文案HuggingFace中的image-caption模型
- LangChain 7 文本模型TextLangChain和聊天模型ChatLangChain
- LangChain 8 模型Model I/O:输入提示、调用模型、解析输出
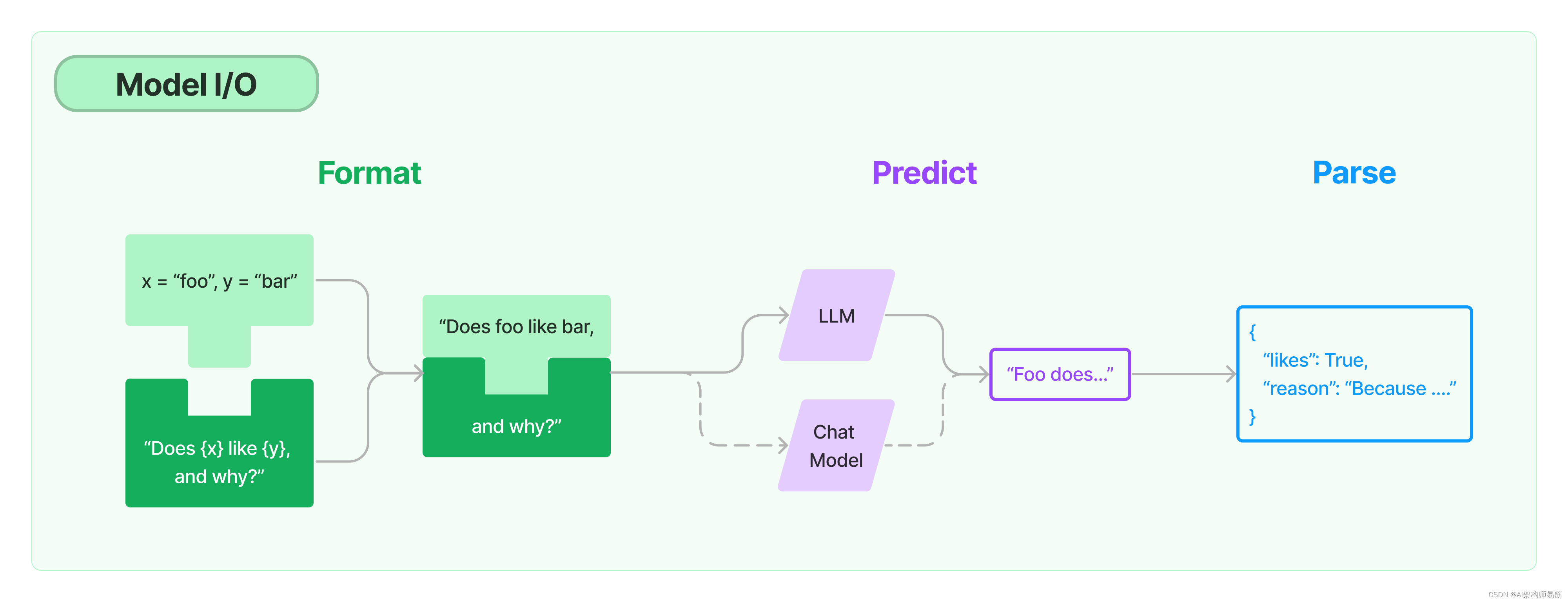
语言模型的提示是用户提供的一组指令或输入,用于指导模型的响应,帮助它理解上下文并生成相关和连贯的基于语言的输出,比如回答问题、完成句子或参与对话。
LangChain提供了几个类和函数来帮助构建和处理提示。
- Prompt templates提示模板:参数化模型输入
- Example selectors示例选择器:动态选择要包含在提示中的示例
提示模板是预定义的配方,用于生成语言模型的提示。
模板可能包括说明、少量示例,以及适用于特定任务的具体背景和问题。
LangChain提供工具来创建和使用提示模板。
LangChain致力于创建模型无关的模板,以便轻松地在不同的语言模型之间重用现有的模板。
通常,语言模型期望提示要么是一个字符串,要么是一个聊天消息列表。
1. ChatPromptTemplate
聊天模型的提示是一系列聊天消息。
每条聊天消息都与内容和一个称为角色的额外参数相关联。例如,在OpenAI Chat Completions API中,聊天消息可以与AI助手、人类或系统角色相关联。
文件名字chat_prompt_template.py(代码参考了黄佳老师的课程Demo,如需要知道代码细节请读原文)
# 导入Langchain库中的OpenAI模块,该模块提供了与OpenAI语言模型交互的功能
from langchain.llms import OpenAI # 导入Langchain库中的PromptTemplate模块,用于创建和管理提示模板
from langchain.prompts import PromptTemplate # 导入Langchain库中的LLMChain模块,它允许构建基于大型语言模型的处理链
from langchain.chains import LLMChain # 导入dotenv库,用于从.env文件加载环境变量,这对于管理敏感数据如API密钥很有用
from dotenv import load_dotenv # 导入Langchain库中的ChatOpenAI类,用于创建和管理OpenAI聊天模型的实例。
from langchain.chat_models import ChatOpenAI# 调用dotenv库的load_dotenv函数来加载.env文件中的环境变量。
# 这通常用于管理敏感数据,如API密钥。
load_dotenv() # 创建一个ChatOpenAI实例,配置它使用gpt-3.5-turbo模型,
# 设定温度参数为0.7(控制创造性的随机性)和最大令牌数为60(限制响应长度)。
chat = ChatOpenAI(model="gpt-3.5-turbo",temperature=0.7,max_tokens=120
)
# 导入Langchain库中的模板类,用于创建聊天式的提示。
from langchain.prompts import (ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate
)# 定义一个系统消息模板,用来设定AI的角色和任务(这里是起名字专家)。
template = "你是一位起名字专家,负责为专注于{product}的公司起名。"
system_message_prompt = SystemMessagePromptTemplate.from_template(template)# 定义一个人类消息模板,用来模拟用户的提问(这里是请求为公司起名)。
human_template = "请为我们的公司起个名字,我们专注于{product_detail}。"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)# 将系统消息和人类消息的模板组合成一个聊天提示模板。
prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])# 使用聊天提示模板生成具体的聊天提示,这里指定产品为“水果”和产品细节为“高端送礼设计”。
prompt = prompt_template.format_prompt(product="水果", product_detail="高端送礼设计").to_messages()# 使用chat函数(需要事先定义)发送生成的提示,获取结果。
result = chat(prompt)# 打印聊天结果。
print(result)
运行输出
zgpeaces-MBP at ~/Workspace/LLM/langchain-llm-app ±(feature/textAndChat) ✗ ❯ python chat_prompt_template.py
content='果香珍品'
zgpeaces-MBP at ~/Workspace/LLM/langchain-llm-app ±(feature/textAndChat) ✗ ❯ python chat_prompt_template.py
content='水果佳礼'
zgpeaces-MBP at ~/Workspace/LLM/langchain-llm-app ±(feature/textAndChat) ✗ ❯ python chat_prompt_template.py
content='果香尚礼'
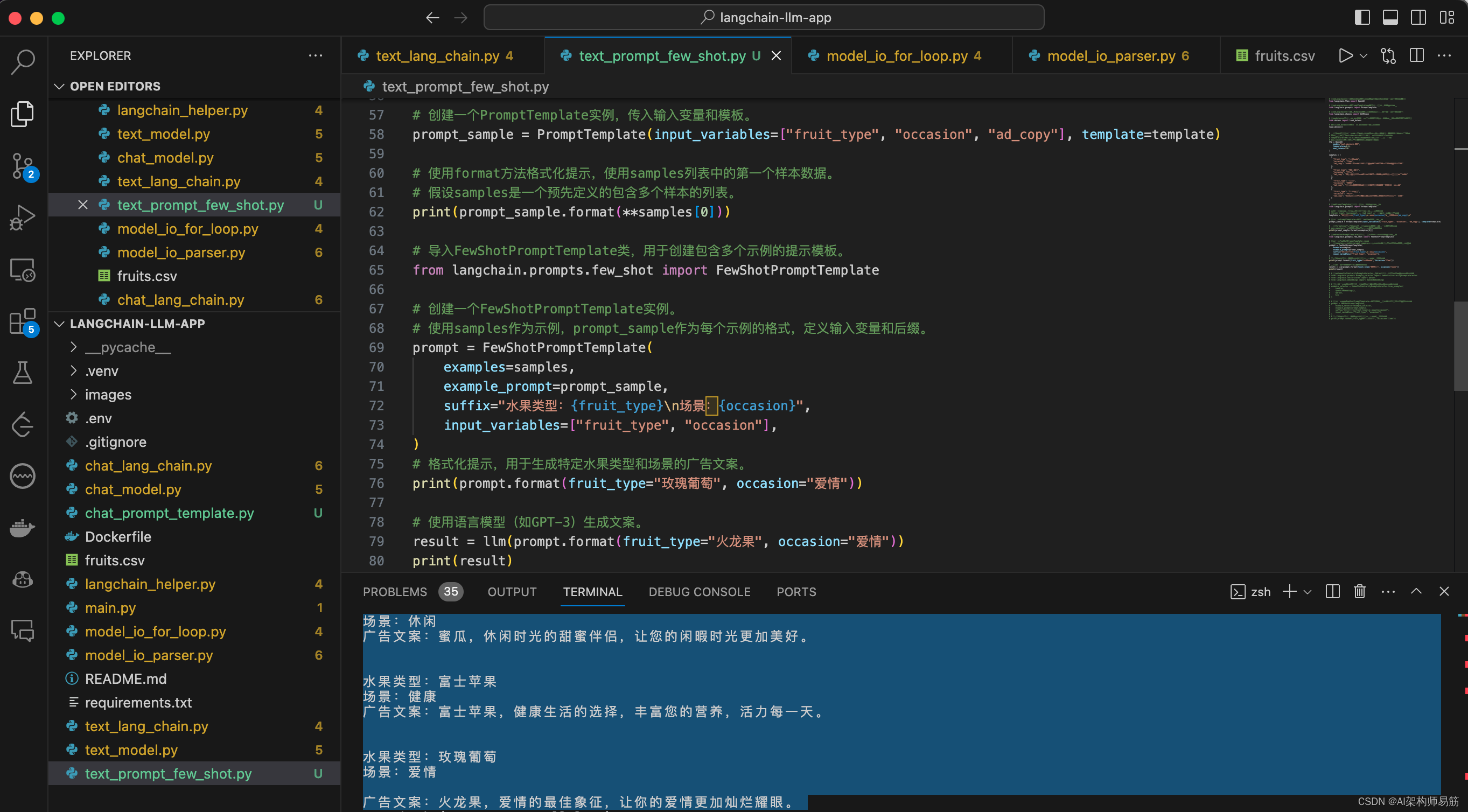
2. Few Shot Prompt
文件名text_prompt_few_shot.py
# 导入Langchain库中的OpenAI模块,该模块提供了与OpenAI语言模型交互的功能
from langchain.llms import OpenAI # 导入Langchain库中的PromptTemplate模块,用于创建和管理提示模板
from langchain.prompts import PromptTemplate # 导入Langchain库中的LLMChain模块,它允许构建基于大型语言模型的处理链
from langchain.chains import LLMChain # 导入dotenv库,用于从.env文件加载环境变量,这对于管理敏感数据如API密钥很有用
from dotenv import load_dotenv # 调用load_dotenv函数来加载.env文件中的环境变量
load_dotenv() # 使用OpenAI类创建一个名为llm的实例。这个实例配置了用于生成文本的模型参数。
# 模型使用的是"text-davinci-003",这是一个高级的GPT-3模型。
# temperature设置为0.8,这决定了生成文本的随机性和创造性。
# max_tokens设置为60,限制生成文本的最大长度。
llm = OpenAI(model="text-davinci-003",temperature=0.6,max_tokens=120
)samples = [{"fruit_type": "玫瑰葡萄","occasion": "爱情","ad_copy": "玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。"},{"fruit_type": "金钻菠萝","occasion": "庆祝","ad_copy": "金钻菠萝,庆祝的完美伴侣,为您的特别时刻增添甜蜜与奢华。"},{"fruit_type": "蜜瓜","occasion": "休闲","ad_copy": "蜜瓜,休闲时光的甜蜜伴侣,让您的闲暇时光更加美好。"},{"fruit_type": "富士苹果","occasion": "健康","ad_copy": "富士苹果,健康生活的选择,丰富您的营养,活力每一天。"}
]# 导入PromptTemplate类,用于创建和管理提示模板。
from langchain.prompts import PromptTemplate# 定义一个提示模板,包括水果类型、场景和广告文案。
# {fruit_type}, {occasion}, 和 {ad_copy} 是占位符,稍后将被替换。
template = "水果类型:{fruit_type}\n场景:{occasion}\n广告文案:{ad_copy}\n"# 创建一个PromptTemplate实例,传入输入变量和模板。
prompt_sample = PromptTemplate(input_variables=["fruit_type", "occasion", "ad_copy"], template=template)# 使用format方法格式化提示,使用samples列表中的第一个样本数据。
# 假设samples是一个预先定义的包含多个样本的列表。
print(prompt_sample.format(**samples[0]))# 导入FewShotPromptTemplate类,用于创建包含多个示例的提示模板。
from langchain.prompts.few_shot import FewShotPromptTemplate# 创建一个FewShotPromptTemplate实例。
# 使用samples作为示例,prompt_sample作为每个示例的格式,定义输入变量和后缀。
prompt = FewShotPromptTemplate(examples=samples,example_prompt=prompt_sample,suffix="水果类型:{fruit_type}\n场景:{occasion}",input_variables=["fruit_type", "occasion"],
)
# 格式化提示,用于生成特定水果类型和场景的广告文案。
print(prompt.format(fruit_type="玫瑰葡萄", occasion="爱情"))# 使用语言模型(如GPT-3)生成文案。
result = llm(prompt.format(fruit_type="火龙果", occasion="爱情"))
print(result)
运行
zgpeaces-MBP at ~/Workspace/LLM/langchain-llm-app ±(feature/textAndChat) ✗ ❯ python text_prompt_few_shot.py
水果类型:玫瑰葡萄
场景:爱情
广告文案:玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。水果类型:玫瑰葡萄
场景:爱情
广告文案:玫瑰,浪漫的象征,是你向心爱的人表达爱意的最佳选择。水果类型:金钻菠萝
场景:庆祝
广告文案:金钻菠萝,庆祝的完美伴侣,为您的特别时刻增添甜蜜与奢华。水果类型:蜜瓜
场景:休闲
广告文案:蜜瓜,休闲时光的甜蜜伴侣,让您的闲暇时光更加美好。水果类型:富士苹果
场景:健康
广告文案:富士苹果,健康生活的选择,丰富您的营养,活力每一天。水果类型:玫瑰葡萄
场景:爱情广告文案:火龙果,爱情的最佳象征,让你的爱情更加灿烂耀眼。
3. 提示工程(Prompt Engineering)
是指在与大型语言模型(如GPT-3或GPT-4)交互时,精心设计输入(即“提示”)的过程,以获得最佳的输出结果。这一过程对于充分利用大型语言模型的能力至关重要。以下是进行有效提示工程的几个关键原则:
1. 明确目标
- 具体目标:在设计提示之前,要明确你想从模型中获取什么类型的信息或响应。
- 明确指令:确保提示清晰、具体,避免模糊不清的要求。
2. 理解模型的能力和限制
- 能力范围:了解模型的强项和弱点,以及它在处理特定类型的任务时的性能。
- 避免误解:避免提问模型无法准确回答的问题,例如关于未来的预测、过于复杂或专业的主题。
3. 使用清晰、简洁的语言
- 简洁性:避免冗长和复杂的句子结构。简洁的提示有助于模型更好地理解意图。
- 无歧义:确保语言明确,避免可能产生歧义的表述。
4. 结构化提示
- 逻辑流程:如果问题涉及多个步骤或要点,使用有逻辑顺序和清晰结构的提示。
- 上下文信息:如果需要,提供足够的背景信息或上下文,帮助模型更好地理解和回应。
5. 迭代和调整
- 试错法:可能需要多次尝试和调整提示,以获得最佳结果。
- 分析响应:基于模型的响应对提示进行微调。
6. 利用范例和模板
- 使用示例:提供具体示例可以帮助模型理解预期输出的格式和风格。
- 模板化:对于常见任务,可以创建并复用有效的提示模板。
7. 考虑伦理和偏见
- 避免偏见:设计提示时要意识到潜在的偏见和不准确性。
- 伦理使用:确保使用模型的方式符合伦理标准,避免伤害和误导。
8. 实验和反馈
- 持续测试:不断测试和优化提示,以提高响应的质量和相关性。
- 学习和调整:根据实验结果和用户反馈调整策略。
9. 适应特定用途
- 针对性:根据特定应用场景或行业需求定制提示。
- 多样性应用:对于不同的任务和目标,采用不同的提示策略。
通过遵循这些原则,可以更有效地利用大型语言模型,提高其在各种任务和应用中的性能和准确性。

代码
- https://github.com/zgpeace/pets-name-langchain/tree/feature/textAndChat
- https://github.com/huangjia2019/langchain/tree/main/03_%E6%A8%A1%E5%9E%8BIO
参考
https://python.langchain.com/docs/modules/model_io/
参考
- https://platform.openai.com/docs/guides/prompt-engineering
相关文章:
LangChain 9 模型Model I/O 聊天提示词ChatPromptTemplate, 少量样本提示词FewShotPrompt
LangChain系列文章 LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索I…...

使用 Vue3 + Pinia + Ant Design Vue3 搭建后台管理系统
Vue3 & Ant Design Vue3基础 nodejs版本要求:node-v18.16.0-x64 nodejs基础配置 npm -v node -vnpm config set prefix "D:\software\nodejs\node_global" npm config set cache "D:\software\nodejs\node_cache"npm config get registry …...

SpringCloud核心组件
Eureka 注册中心,服务的注册与发现 Feign远程调用 Ribbon负载均衡,默认轮询 Hystrix 熔断 降级 Zuul微服务网关(这个组件负责网络路由,可以做统一的降级、限流、认证授权、安全) Eureka 微服务的功能主要有以下几…...

基于C++11实现将IP地址、端口号和连接状态写入文件
要基于C11实现将IP地址、端口号和连接状态写入文件,您可以使用std::ofstream类来打开文件并进行写入操作。以下是一个示例: #include <iostream> #include <fstream>void writeConnectionStatus(const std::string& ip, int port, bool…...

非空断言,
先看下TypeScript基础之非空断言操作符、可选链运算符、空值合并运算符-CSDN博客 我没有复现出来,但是我知道了它的作用 用 let str: string arg!; 代替 let str: string; if (arg) { str arg; } 非空断言(!)和不使用的区别在于对于…...

Spark---创建DataFrame的方式
1、读取json格式的文件创建DataFrame 注意: 1、可以两种方式读取json格式的文件。 2、df.show()默认显示前20行数据。 3、DataFrame原生API可以操作DataFrame。 4、注册成临时表时,表中的列默认按ascii顺序显示列。 df.createTempView("mytab…...

瑜伽学习零基础入门,各种瑜伽教学方法全集
一、教程描述 练习瑜伽的好处多多,能够保证平衡健康的身体基础,提升气质、塑造形体、陶冶情操,等等。本套教程是瑜伽的组合教程,共由33套视频教程组合而成,包含了塑身纤体,速效瘦身,四季养生&a…...

pycharm编译报错处理
1.c生成工具下载 https://visualstudio.microsoft.com/visual-cpp-build-tools/ 在这里插入图片描述 pip install pycocotools...
)
“华为杯”研究生数学建模竞赛2019年-【华为杯】E题:基于多变量的全球气候与极端天气模型的构建与应用(附python代码实现)
目录 摘 要: 一.问题重述 1.1 问题背景 1.2 问题提出 二.模型假设及符号设定...
)
冒泡排序(适合编程新手的体质)
冒泡排序:简单而高效的排序技巧 欢迎来到我们今天的博客,我们将一起探索计算机科学中最基本但同时也非常重要的概念之一:冒泡排序。无论你是编程新手还是有一些编程经验的读者,这篇博客都将帮助你更好地理解冒泡排序的原理和应用…...

pdfjs,pdf懒加载
PDF.js是一个使用JavaScript实现的PDF阅读器,它可以在Web浏览器中显示PDF文档。PDF.js支持懒加载,也就是说,它可以在用户滚动页面时才加载PDF文档的某些部分,从而减少初始加载时间和内存占用。 注意点:如果要运行在多留…...
K8s 多租户方案的挑战与价值
在当今企业环境中,随着业务的快速增长和多样化,服务器和云资源的管理会越来越让人头疼。K8s 虽然很强大,但在处理多个部门或团队的业务部署需求时,如果缺乏有效的多租户支持,在效率和资源管理方面都会不尽如人意。 本…...
单链表相关经典算法OJ题:移除链表元素
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 题目:移除链表元素 解法一: 解法一的代码实现: 解法二: 解法二代码的实现: 总结 前言 世上有两种耀眼的…...

【JUC】十九、volatile与内存屏障
文章目录 1、volatile的两大特性2、volatile的四大内存屏障3、分类4、happens-before之volatile变量重排规则5、读写屏障插入策略 1、volatile的两大特性 被volatile修饰的变量有两大特点: 可见性有序性 关于volatile的可见性,也即volatile的内存语义…...
下载MySQL JDBC驱动的方法
说明 java代码通过JDBC访问MySQL数据库,需要MySQL JDBC驱动。 例如,下面这段代码,因为找不到JDBC驱动,所以执行会报异常: package com.thb;public class JDBCDemo {public static void main(String[] args) throws …...
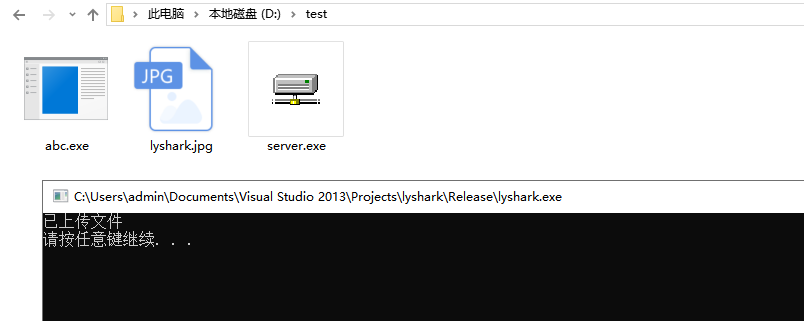
C/C++ 实现FTP文件上传下载
FTP(文件传输协议)是一种用于在网络上传输文件的标准协议。它属于因特网标准化的协议族之一,为文件的上传、下载和文件管理提供了一种标准化的方法,在Windows系统中操作FTP上传下载可以使用WinINet库,WinINetÿ…...

第十三章 python之爬虫
Python基础、函数、模块、面向对象、网络和并发编程、数据库和缓存、 前端、django、Flask、tornado、api、git、爬虫、算法和数据结构、Linux、设计题、客观题、其他 第十三章 爬虫 1. 写出在网络爬取过程中, 遇到防爬问题的解决办法。 在网络爬取过程中,可能会遇…...

scrum 敏捷开发
scrum 敏捷开发 Scrum 是一种敏捷软件开发方法,旨在通过迭代、增量和协作的方式提高团队的效率和产品质量。下面是关于 Scrum 的一些重要概念和实践: 1. Scrum 团队角色 Scrum 团队通常由以下角色组成: 产品负责人(Product Ow…...

亚信科技AntDB数据库完成中国信通院数据库迁移工具专项测试
近日,在中国信通院“可信数据库”数据库迁移工具专项测试中,湖南亚信安慧科技有限公司(简称:亚信安慧科技)数据库数据同步平台V2.1产品依据《数据库迁移工具能力要求》、结合亚信科技AntDB分布式关系型数据库产品&…...

深度学习(一):Pytorch之YOLOv8目标检测
1.YOLOv8 2.模型详解 2.1模型结构设计 和YOLOv5对比: 主要的模块: ConvSPPFBottleneckConcatUpsampleC2f Backbone ----->Neck------>head Backdone 1.第一个卷积层的 kernel 从 6x6 变成了 3x3 2. 所有的 C3 模块换成 C2f,可以发现…...

跨平台串口调试终极指南:SSCom让硬件开发更简单
跨平台串口调试终极指南:SSCom让硬件开发更简单 【免费下载链接】sscom Linux/Mac版本 串口调试助手 项目地址: https://gitcode.com/gh_mirrors/ss/sscom 作为硬件开发的必备工具,串口调试工具SSCom凭借其跨平台特性和高效性能,为Lin…...

终极解决方案:三步彻底卸载Windows系统中顽固的Microsoft Edge浏览器
终极解决方案:三步彻底卸载Windows系统中顽固的Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRem…...

2026年最新亲测3款亲子教育免费AI工具,再也不用为辅导作业头大了
作为一个天天跟音频、视频打交道的IT技术博主,同时也是一位二年级小学生的家长,我这两年踩过的“教育工具坑”真不少。孩子上课注意力不集中、回家记不住重点、家长会信息记不全、辅导作业时自己讲得口干舌燥孩子却一脸懵……这些场景,估计有…...
)
2026年数据驱动经济与信息管理国际学术会议(DDEMI 2026)
2026年数据驱动经济与信息管理国际学术会议(DDEMI 2026)会议时间:2026年8月07日-09日会议地点:江苏-南京截稿日期:2026年7月31日录用结果:投稿后1周内收录检索:EI Compendex, Scopus【大会简介】…...

AI时代什么建站软件功能强大?从GEO流量重构看CMS的智慧进化
2026年,互联网的底层逻辑正在发生一场“静默革命”。如果你的思维还停留在“建一个网站只是为了有个官网给客户看”,那么你可能正在被时代抛弃。当下的AI已经不仅仅是一个聊天工具,它正在重构整个信息的传播秩序。传统的SEO(搜索引…...

四川资产盘活实战教培|从业者真实学习感悟
深耕资管行业多年,我发现四川不少企业长期受不良债权积压、存量资产沉淀困扰。自主催收效率低、回款周期长,再加上缺乏专业尽调、估值及司法处置能力,极易造成资产贬值、合规风险增加。在此背景下,本土实战型资产盘活教培…...

测试工程师如何进行测试计划制定?这5个步骤让你的计划更合理
对于软件测试从业者而言,一份合理可行的测试计划是项目测试工作的核心纲领,它不仅决定了测试活动的范围、方向与资源分配,更直接影响着项目的交付质量与进度管控。很多初级测试工程师常常将测试计划等同于测试时间列表,要么写得过…...

工作中常用的注解梳理
注解是贴在类、方法、变量上的标记标签,以开头,本身不执行业务代码。作用主要有以下几点:代码标识说明替代配置文件自动生成代码框架识别驱动数据约束与校验单元测试序列化转换日常工作中常用的注解主要有以下十三类:JDK原生注解J…...

Tokenizer与Embedding
Transformers 系列文章目录 第一章 Transformers 简介 第二章 Transformers 模型推理; 第三章 Tokenizer 与 Embedding 文章目录Transformers 系列文章目录前言Tokenizer与Embedding一、Tokenizer(分词器)和Embedding(词嵌入&a…...

平均 CPU 利用率指标为何该摒弃?多个案例揭示真相!
1. 作者信息与文章背景Jeremy Theocharis 是《平凡即卓越》作者、UMH 联合创始人兼首席技术官。文章基于其在 2026 年 4 月云原生亚琛聚会上的演讲,探讨为何应摒弃平均 CPU 利用率指标。2. 应用程序问题引出我们应用程序中的一个 Go 函数在生产环境总是被取消执行。…...