MySQL 学习笔记(刷题篇)
SQL进阶挑战
聚合分组查询
SQL123
select tag, difficulty, round((sum(score) - max(score) - min(score) ) / (count(score) - 2) ,1)
as clip_avg_score
from examination_info as ei, exam_record as er
where ei.exam_id = er.exam_id
and ei.tag = 'SQL'
and ei.difficulty = 'hard'
and er.score is not null;
SQL124
IF(expr1 , expr2 , expr3),expr1的值为TRUE 返回 expr2,否则返回 expr3
使用 distinct 是需要考虑 null 的,它会把 null 也算成一种情况
但是使用 count(字段) 是不用考虑 null 的,它不会计 null 为一种情况
select count(id) as total_pv,
count(submit_time) as complete_pv,
count(distinct if(submit_time is not null, exam_id, null)) as complete_exam_cnt
from exam_record
select count(id) as total_pv,
count(submit_time) as complete_pv,
count(distinct exam_id and score is not null) as complete_exam_cnt
from exam_record
SQL125
# 这样写为什么就错?
select min(score) as min_score_over_avg
from exam_record #这样写没有保证查询的试卷类型是SQL
where score >= (select avg(score)from exam_record as er , examination_info as eiwhere ei.tag = 'SQL'and ei.exam_id = er.exam_idand er.score is not null
);
# correct
select min(score) as min_score_over_avg
from exam_record as er , examination_info as ei
where ei.tag = 'SQL'
and ei.exam_id = er.exam_id
and er.score is not null
and score >= (select avg(score)from exam_record as erwhere er.exam_id = ei.exam_idand er.score is not null
);
SQL126
题目:按年月进行分组,统计每组的用户id个数(也就是这个月有多少活跃用户),统计每组的用户活跃天数的平均值(总天数/总人数)
总天数计算方法: ∑ i = 1 i = l a s t − u s e r 第 i 个用户一个月内的登录天数之和 \sum_{i=1}^{i=last-user} 第i个用户一个月内的登录天数之和 ∑i=1i=last−user第i个用户一个月内的登录天数之和
DATE_FORMAT(date,fmt) 按照字符串 fmt 格式化日期 date 值
YEAR(date) / MONTH(date) / DAY(date) 返回具体的日期值
count( distinct uid, date_format(submit_time, '%y%m%d') ),这里的知识点:count函数内本只能接收一个参数,distinct 修饰是所有字段的,并不是修饰一个字段
语句含义:去掉一个用户在一天内的多次登录计数的重复计数,保证如果同一用户在同一天进行了多次活动,只有一次会被计数。
select date_format(submit_time, '%Y%m') as month, # %Y四位年份,%m两位数字月份round( count(distinct uid, date_format(submit_time, '%y%m%d') ) / count(distinct uid) , 2) as avg_active_days,count(distinct uid) as mau #统计组内不同用户id数量
from exam_record
where submit_time is not null
and year(submit_time) = 2021
group by date_format(submit_time, '%Y%m') # 按照年月分组
SQL127
select date_format(submit_time, '%Y%m') as submit_month,count(distinct uid, submit_time) as month_q_cnt,round(count(distinct uid, submit_time) / max(DAY(LAST_DAY(submit_time))) #这里必须用一个聚合函数,由于汇总时的天数按31算,因此用max最为合适,day+lasy_day一起得到当月的天数, 3) as avg_day_q_cnt
from practice_record
where year(submit_time) = '2021' #过滤字段写到分组前
group by submit_monthunionselect '2021汇总' as submit_month,
count(distinct uid, submit_time) as month_q_cnt,
round(count(distinct uid, submit_time) / 31, 3) as avg_day_q_cnt
from practice_record
where year(submit_time) = '2021'order by submit_month;
COALESCE 是一个函数,coalesce (expression_1, expression_2, …,expression_n) ,依次检验,返回第一个不是 null 的值
MySQL5.7之后,sql_mode中ONLY_FULL_GROUP_BY模式默认设置为打开状态。
ONLY_FULL_GROUP_BY的语义就是确定select target list中的所有列的值都是明确语义,因此这里的coalesce是不好使的,可以通过any_value()函数来抑制ONLY_FULL_GROUP_BY值被拒绝,any_value()会选择被分到同一组的数据里第一条数据的指定列值作为返回数据
GROUP BY中使用WITH ROLLUP
WITH ROLLUP,使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和
注意:当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
SELECTany_value(coalesce(DATE_FORMAT(submit_time,"%Y%m"),'2021汇总')) as submit_month,count(submit_time) as month_q_cnt,# 因为汇总除的数也是31,因此这里取max聚合round(count(submit_time) / max(day(last_day(submit_time))),3) as avg_day_q_cnt
FROM practice_record
WHERE year(submit_time) = '2021'
GROUP BY date_format(submit_time,"%Y%m") with rollup;
SQL 128
使用 count() 函数实现条件统计的基础是:对于值为NULL的记录不计数,利用这个性质我们可以轻松统计出值不为 NULL 的记录,再统计总记录,即可得到值为 NULL 的记录。
# 统计num大于200的记录
select count(num > 200 or null) from a;
# or null 作用就是当条件不满足时,函数变成了count(null)不会统计数量
# 但是 num > 200 这个条件不成立时的 false 是会被统计到的
GROUP_CONCAT() 函数是mysql中非常实用的聚合函数,将给分组内的值连接为一个字符串。其完整语法:
GROUP_CONCAT([DISTINCT] 要连接的字段 [ORDER BY 排序字段 ASC/DESC] [SEPARATOR ‘分隔符’])
select uid,count(uid) - count(submit_time) as incomplete_cnt,count(submit_time) as complete_cnt,group_concat(distinct date_format(start_time, '%Y-%m-%d'), ':', tagOrder BY start_time ASC #排序字段SEPARATOR ';') as detail
from exam_record as er
inner join examination_info as ei
on er.exam_id = ei.exam_id
where year(start_time) = '2021' #过滤字段写到分组前
group by uid
having incomplete_cnt < 5 and incomplete_cnt > 1
and complete_cnt >= 1
order by incomplete_cnt desc;
多表查询
SQL 129
先考虑简单的,找出 “当月均完成试卷数”不小于3的用户们,然后按 tag 分组统计存在 start_time 的作答记录个数即可
select tag, count(start_time) as tag_cnt
from examination_info as ei
inner join exam_record as er
on ei.exam_id = er.exam_id
where uid in (select uidfrom exam_record as erinner join examination_info as eion er.exam_id = ei.exam_idgroup by uid, date_format(start_time, '%Y%m')having count(date_format(submit_time, '%Y%m')) >= 3
)
group by tag
order by tag_cnt desc;
SQL 130
select ei.exam_id as exam_id,count(distinct uid) as uv,# round(avg(score) ,1) as avg_scoreround(sum(score) / count(score) , 1) as avg_score
from examination_info as ei
inner join exam_record as er
on ei.exam_id = er.exam_id
where date_format(start_time, '%Y%m%d') in ( # 时间select date_format(release_time, '%Y%m%d') # 先弄出SQL试卷的发出的时间字段from examination_infowhere tag = 'SQL'
)
and uid in ( # 用户select uid # 再弄出等级大于5的用户的uidfrom user_infowhere level > 5
)
and tag = 'SQL' # SQL试卷
group by ei.exam_id #所有的SQL试卷按exam_id分组
order by uv desc, avg_score;
SQL 131
select level, count(level) as level_cnt
from user_info as ui, (select uidfrom exam_record as erinner join examination_info as eion er.exam_id = ei.exam_idwhere tag = 'SQL' && score > 80
) as tmp
where ui.uid = tmp.uid
group by level
order by level_cnt desc;
SQL 132
再套一个 select 来使得子查询的排序独立
select * from (
select exam_id as tid, count(distinct uid) as uv,count(start_time) as pv
from exam_record
group by exam_id
order by uv desc, pv desc
) as t1unionselect * from (
select question_id as tid,count(distinct uid) as uv,count(submit_time) as pv
from practice_record
group by question_id
order by uv desc, pv desc
) as t2
SQL 133
TIME_TO_SEC() 将时间差转换为秒
select uid, 'activity1' as activity
from exam_record
group by uid
having min(score) >= 85unionselect uid, 'activity2' as activity
from examination_info as ei
inner join exam_record as er
on er.exam_id = ei.exam_id
where score > 80
and difficulty = 'hard'
and TIME_TO_SEC(timediff(submit_time, start_time)) < duration * 30order by uid;
其他操作
SQL 146
select uid,floor(avg(any_value(coalesce(score, 0)))) as avg_score,round(avg(if(submit_time is not null, timestampdiff(minute, start_time, submit_time), duration)), 1) as avg_time_took
from examination_info as ei
inner join exam_record as er
on ei.exam_id = er.exam_id
where difficulty = 'hard'
and uid in (select uidfrom user_infowhere level = 0
)
group by uid
SQL 147
select uid, nick_name, achievement
from user_info
where nick_name like '牛客%'
and nick_name like '%号'
and achievement between 1200 and 2500
and uid in (select uidfrom exam_recordgroup by uidhaving max(date_format(start_time, '%Y%m')) = '202109'union select uidfrom practice_recordgroup by uidhaving max(date_format(submit_time, '%Y%m')) = '202109'
)
select uid, nick_name, achievement
from user_info
where nick_name like '牛客%'
and nick_name like '%号'
and achievement between 1200 and 2500
and (uid in(select uidfrom exam_recordgroup by uidhaving max(date_format(start_time, '%Y%m')) = '202109')or uid in(select uidfrom practice_recordgroup by uidhaving max(date_format(submit_time, '%Y%m')) = '202109')
)
SQL 148(正则表达式)
用正则表达式匹配纯数字或者中间纯数字
select uid, er.exam_id,round(avg(score) ,0) as avg_score
from examination_info as ei
inner join exam_record as er
on ei.exam_id = er.exam_id
where uid in (select uidfrom user_infowhere nick_name regexp '^牛客[0-9]+号$'or nick_name regexp '^[0-9]+$'
)
and ei.exam_id in (select exam_idfrom examination_infowhere tag regexp '^[Cc]'
)
and score is not null
group by uid, exam_id
order by uid, avg_score
SQL 149(WITH AS)
比较复杂的一个题,需要用 WITH AS 存一下查询
with t as (select ui.uid as uid,count(start_time) - count(submit_time) as incomplete_cnt,round(if(count(start_time) - count(submit_time) > 0,(count(start_time) - count(submit_time)) / count(start_time),0),3) as incomplete_rate,level,count(start_time) as total_cnt # 作答个数from user_info as uileft join exam_record as eron ui.uid = er.uidgroup by uid
)select uid, incomplete_cnt, incomplete_rate
from t
where exists(select uid from t where level = 0 and incomplete_cnt > 2
)
and level = 0
union
select uid, incomplete_cnt, incomplete_rate
from t
where not exists (select uid from t where level = 0 and incomplete_cnt > 2
)
and total_cnt > 0 # 有作答记录的用户
order by incomplete_rate
SQL150(CASE WHEN THEN)
很烂但有用的代码
select ui.level,case when score >= 90 then '优'when score >= 75 then '良'when score >= 60 then '中'when score >= 0 then '差' end as score_grade,round(count( case when score >= 90 then '优'when score >= 75 then '良'when score >= 60 then '中'when score >= 0 then '差' end) / num, 3) as ratio
from exam_record as er, user_info as ui, (select level, count(level) as numfrom exam_record as erinner join user_info as uion er.uid = ui.uidwhere score is not nullgroup by levelorder by level desc
) as tmp
where er.uid = ui.uid
and tmp.level = ui.level
and score is not null
group by level, score_grade
order by level desc, ratio desc
SQL 152
select er.uid, level, register_time, score as max_score
from exam_record as er
inner join user_info as ui
on er.uid = ui.uid
where exam_id in ( # 把exam_record筛的只剩下job为算法的人做的算法试卷记录select exam_idfrom examination_infowhere tag = '算法'
)
and er.uid in (select uidfrom user_infowhere job = '算法'
)
and score is not null # 还得做完
order by score desc
limit 6, 3;
SQL 153(substring_index)
substring_index(str,delim,count),str:要处理的字符串,delm:分隔符
SELECT exam_id,substring_index(tag, ',', 1) AS tag,substring_index(substring_index(tag, ',', 2), ',', -1) AS difficulty,substring_index(tag, ',', -1) AS duration
FROM examination_info
WHERE tag LIKE '%,%';
SQL 154(IF)
简单的 IF 应用
select uid, (if(char_length(nick_name) > 13, concat(substring(nick_name, 1, 10), '...'),nick_name)
) as nick_name
from user_info
where char_length(nick_name) > 10;
SQL 155
这个题写的我脑子有点乱
select t1.tag, t2.total_num
from (select tag, num # 查询试卷作答数小于3的exam_id对应的tag和个数from examination_info as ei, ( select exam_id, count(exam_id) as num #按exam_id分组,并统计个数from exam_recordgroup by exam_id) as tmpwhere ei.exam_id = tmp.exam_id # 多表查询and num < 3
) as t1, (select tag, sum(num) as total_num #按tag分类,把大写的tag聚合起来统计个数from examination_info as ei, (select exam_id, count(exam_id) as numfrom exam_recordgroup by exam_id) as tmpwhere ei.exam_id = tmp.exam_idgroup by tag
) as t2
where upper(t1.tag) = t2.tag # 小写的t1.tag匹配大写的t2.tag
and t1.tag != t2.tag
相关文章:
)
MySQL 学习笔记(刷题篇)
SQL进阶挑战 聚合分组查询 SQL123 select tag, difficulty, round((sum(score) - max(score) - min(score) ) / (count(score) - 2) ,1) as clip_avg_score from examination_info as ei, exam_record as er where ei.exam_id er.exam_id and ei.tag SQL and ei.diffi…...

windows系统如何配置yarn环境变量
启动前端项目,突然遇到报错: 原因在于没有安装yarn,或没有配置环境变量。 全局安装 yarn 可在vsCode中输入,也可在命令行输入(winR,输入cmd) npm install -g yarn添加环境变量 找到yarn的安…...

视频中的文字水印怎么去除?这三招学会轻松去视频水印
短视频与我们生活,工作息息相关,日常在在刷短视频时,下载保存后发现带有文字logo水印,如果直接拿来进行二次创作,不仅影响观看效果,平台流量还会受限制。怎么去除视频中的文字水印就成为了当下热门话题之一…...

Java项目学生管理系统二查询所有
学生管理 近年来,Java作为一门广泛应用于后端开发的编程语言,具备了广泛的应用领域和丰富的开发资源。在前几天的博客中,我们探讨了如何搭建前后端环境,为接下来的开发工作打下了坚实的基础。今天,我们将进一步扩展我…...

27.Spring如何避免在并发下获取不完整的Bean?
Spring如何避免在并发下获取不完整的Bean? 1、为什么获取不到完整的Bean? 我们知道, 如果spring容器已经加载完了, 那么肯定所有bean都是完整的了, 但如果, spring没有加载完, 在加载的过程中, 构建bean就有可能出现不完整bean的情况 2、如何解决读取到不完整bean的问题. …...

浅析SD-WAN企业组网部署中简化网络运维的关键技术
网络已经成为现代企业不可或缺的基础设施,它为企业提供了连接全球的桥梁。随着全球化和数字化转型的加速推进,企业面临着越来越多的网络挑战和压力。传统的网络组网方式往往无法满足企业规模扩大、分支机构增多、上云服务等需求,导致网络性能…...

【Rust】快速教程——自定义类型、数字转枚举、Cargo运行
前言 超过一定的年龄之后,所谓人生,无非是一个不断丧失的过程而已。宝贵的东西,会像梳子豁了齿一样从手中滑落下去。你所爱的人会一个接着一个,从身旁悄然消逝。——《1Q84》 \;\\\;\\\; 目录 前言自定义类型数字转枚举Cargo.tom…...

python 实现 AIGC 大语言模型中的概率论:生日相同问题的代码场景模拟
对深度学习本质而言,它实际上就是应用复杂的数学模型对输入数据进行建模,最后使用训练好的模型来预测或生成新的数据,因此深度学习的技术本质其实就是数学。随着大语言模型的发展,人工智能的数学本质被进一步封装,从业…...
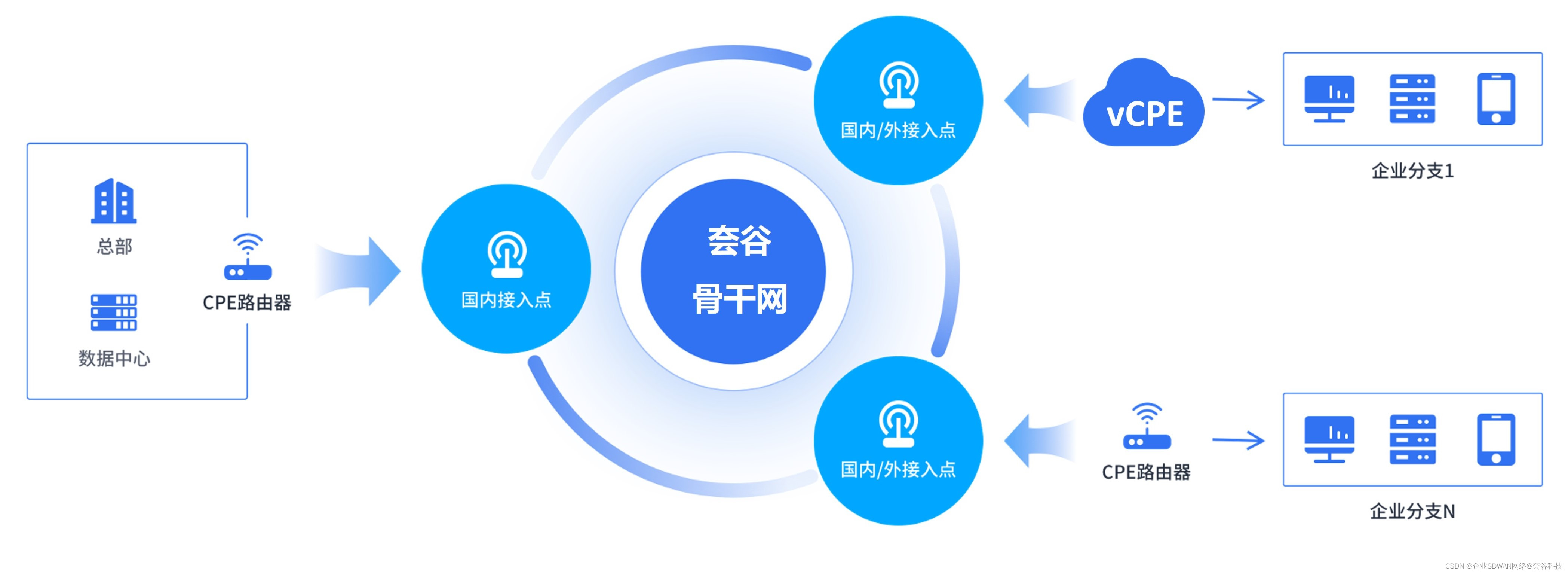
SD-WAN组网中的CPE及云服务CPE部署方法
什么是CPE? CPE全称为Customer Premises Equipment,即客户端设备,在SD-WAN中通常为路由器,部署在中心点和分支上,提供连接和路由、协议转换、流量监控等功能。一般可分为硬件CPE和虚拟化CPE(virtual CPE&a…...
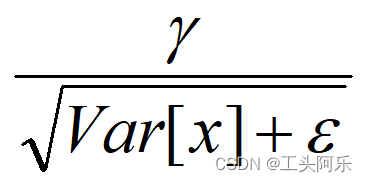
理解BatchNormalization层的作用
深度学习 文章目录 深度学习前言一、“Internal Covariate Shift”问题二、BatchNorm的本质思想三、训练阶段如何做BatchNorm四、BatchNorm的推理(Inference)过程五、BatchNorm的好处六、机器学习中mini-batch和batch有什么区别 前言 Batch Normalization作为最近一年来DL的重…...
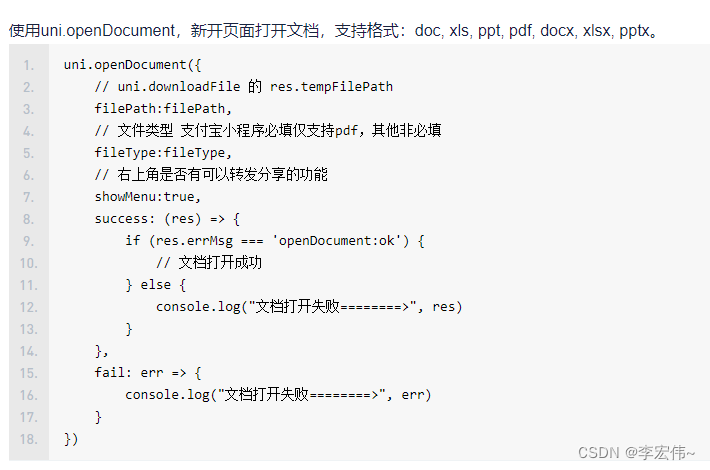
uniapp实现文件预览过程
H5实现预览 <template><iframe :src"_url" style"width:100vw; height: 100vh;" frameborder"0"></iframe> </template> <script lang"ts"> export default {data() {return {_url: ,}},onLoad(option…...

深度学习-学习笔记记录
1、点云语义分割方法分类 分为5类:点、二维投影、体素、融合、集成 2、融合与集成的区别 融合: 概念:主要是将不同来源、类型的模型,例如深度学习、传统机器学习等,的结果或特征进行结合,以得到一个更好的模…...

程序员养生之道:延寿不忘初心——延寿必备
文章目录 每日一句正能量前言如何养生饮食篇运动篇休息篇后记 每日一句正能量 现代社会已不是大鱼吃小鱼的年代,而是快鱼吃慢鱼的年代。 前言 在IT行业中,程序员是一个重要的职业群体。由于长时间的繁重编程工作,程序员们常常忽略了身体健康…...
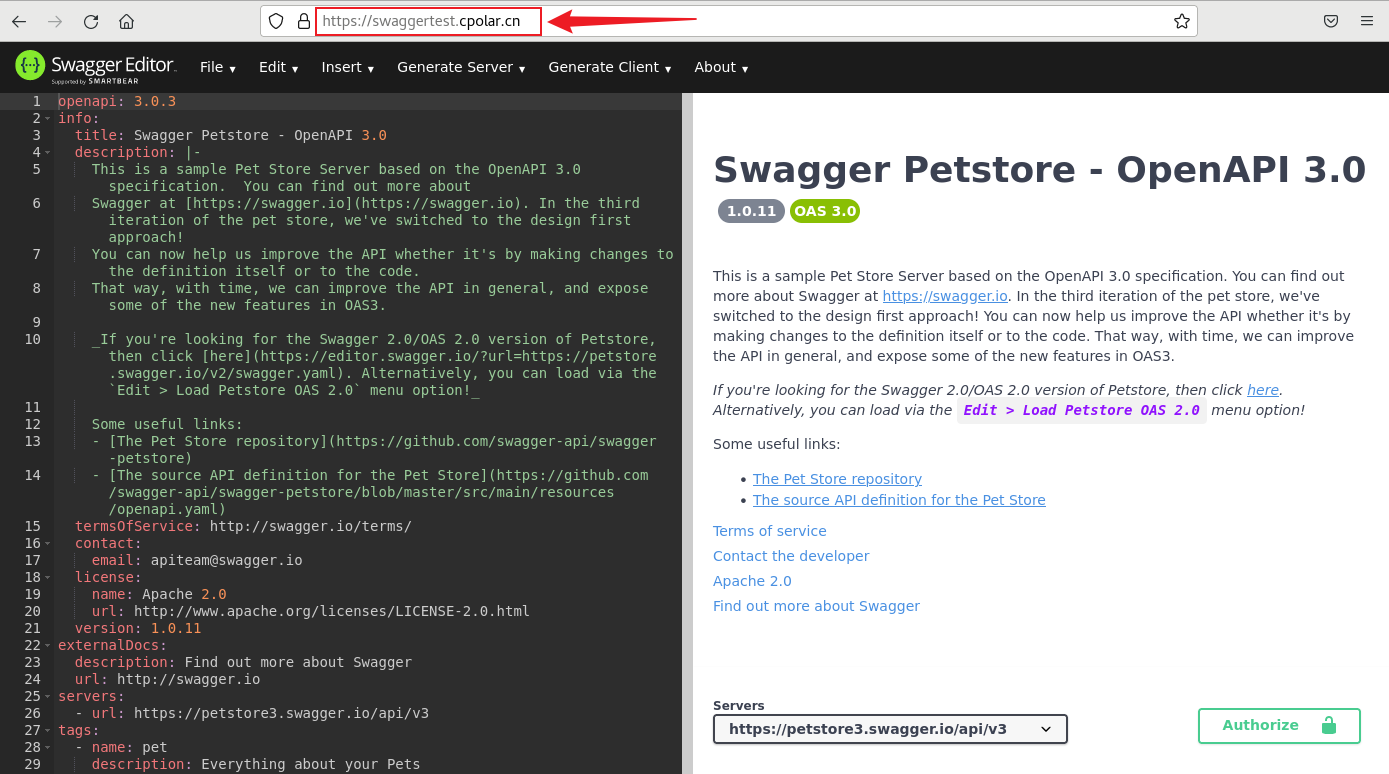
使用Docker安装部署Swagger Editor并远程访问编辑API文档
文章目录 Swagger Editor本地接口文档公网远程访问1. 部署Swagger Editor2. Linux安装Cpolar3. 配置Swagger Editor公网地址4. 远程访问Swagger Editor5. 固定Swagger Editor公网地址 Swagger Editor本地接口文档公网远程访问 Swagger Editor是一个用于编写OpenAPI规范的开源编…...
Nacos 2.X核心架构源码剖析
概述 注册中心并发处理,1.4.x 写时复制,2.1.0 读写分离;nacos 一般使用 AP 架构,即临时实例,1.4.x 为 http 请求,2.1.0 优化为 gRPC 协议;源码中使用了大量的事件通知机制和异步定时线程池&…...
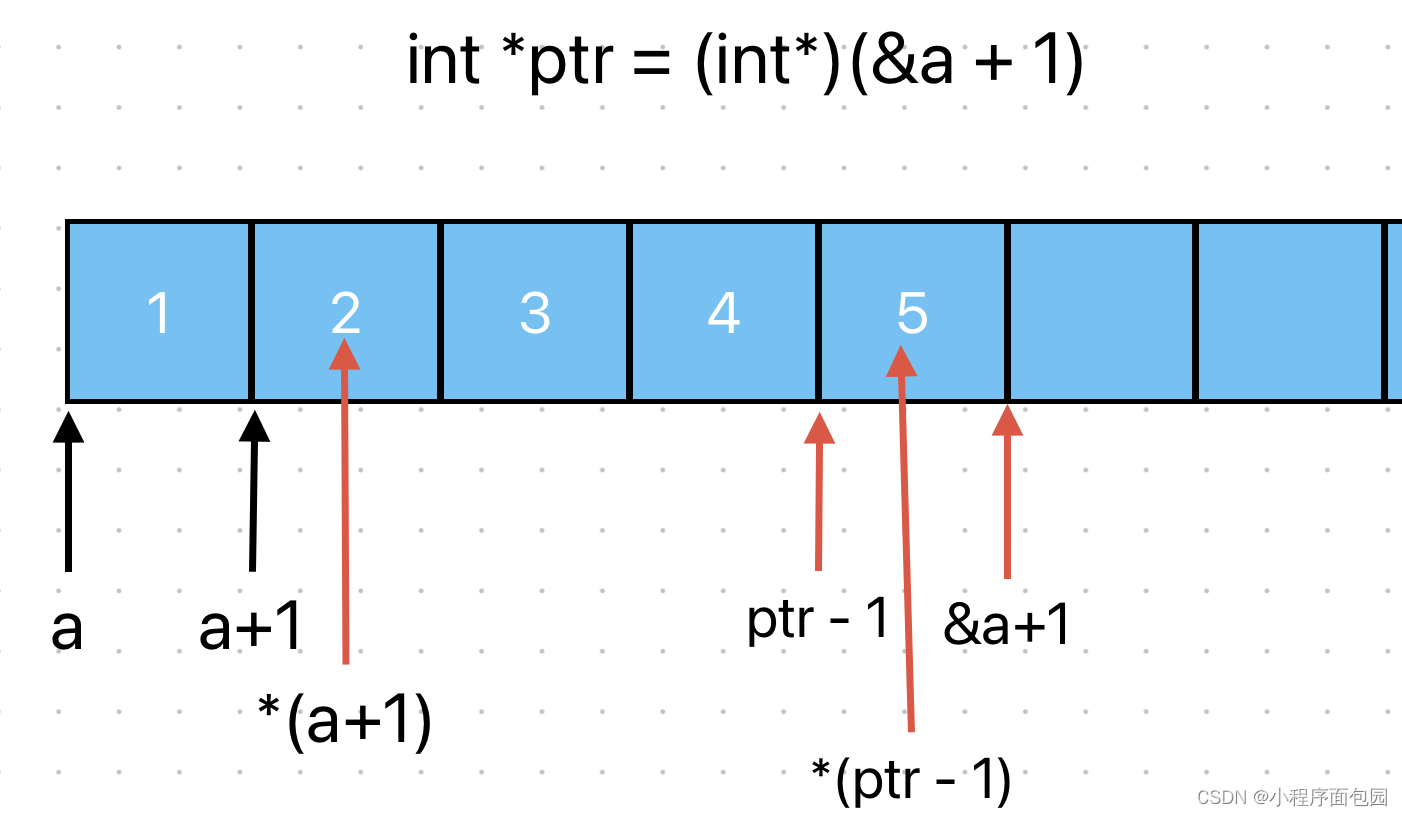
C语言--每日选择题--Day31
第一题 1. 下面程序 i 的值为() int main() {int i 10;int j 0;if (j 0)i; elsei--; return 0; } A:11 B:9 答案及解析 B if语句中的条件判断为赋值语句的时候,因为赋值语句的返回值是右操作数; …...

chrome vue devTools安装
安装好后如下图所示: 一:下载vue devTools 下载链接https://download.csdn.net/download/weixin_44659458/13192207?spm1001.2101.3001.6661.1&utm_mediumdistribute.pc_relevant_t0.none-task-download-2%7Edefault%7ECTRLIST%7EPaid-1-13192207…...

Spring Security 6.x 系列(7)—— 源码分析之Builder设计模式
一、Builder设计模式 WebSecurity、HttpSecurity、AuthenticationManagerBuilder 都是框架中的构建者,把他们放到一起看看他们的共同特点: 查看AuthenticationManagerBuilder的继承结构图: 查看HttpSecurity的继承结构图: 查看W…...

PyQt6 中自定义浮点型滑块类
介绍: 在PyQt6中,滑块(Slider)是常用的用户界面元素之一,用于选择数值范围。然而,有时候我们可能需要使用浮点数值,而标准的滑块仅支持整数。为了解决这个问题,我们可以创建一个自定…...

笔记,B+树
B树面对的场景,是一个有10亿行的表,希望某一列是有序的。这么大的数据量,内存里放不下,需要放在硬盘里。结果,原本运行于内存的二叉树,就升级为B树了。 在二叉树中,每个节点存储着一个数字&…...

职教高考及高职分类招生控制线 API 接口
职教高考及高职分类招生控制线 API 接口 接口详情官网地址: https://www.gugudata.com/api/details/vocationalcontrollines 职教高考及高职分类招生控制线 API 支持查询职教高考及高职分类招生控制线数据,覆盖年份、省份、招生类别、考生类型、录取批次和科类等筛…...

视频号视频下载去水印方法全是坑?全网视频一键拿捏!2026封神玩法!
日常视频号视频,遇到优质内容总想留存下来,不管是日常收藏翻阅,还是剪辑创作取用都十分合适。可现如今各大平台管控严格,直接保存功能尽数受限,自带水印遮挡画面观感,导出画质大打折扣。网上流传的各类存视…...

Harness 中的令牌级流控与字符级计费
Harness 中的令牌级流控与字符级计费:从原理到落地的全指南 关键词:Harness CI/CD, 令牌级流控, 字符级计费, 微服务流量治理, 用量计量, 云原生成本优化, 网关限流 摘要:作为全球领先的智能软件交付平台,Harness 每天要处理来自数千家企业客户的上亿次 API 调用、数百万次…...

技术人被裁员时,除了N+1还有哪些权益可以争取?
一、 核心概念澄清:你的赔偿基准是 N、N1 还是 2N?在挖掘附加权益之前,我们必须像制定测试策略一样,先明确基准。很多测试同学对赔偿的理解存在“Bug”,必须优先修复。N:指经济补偿金,计算方式是…...

Java学习笔记——DAY3
目录 1、Java方法 2、方法的定义 3、方法调用 4、方法的重载 5、命令行传参 6、可变参数 7、递归 1、Java方法 Java方法是语句的集合,它们在一块执行一个功能。 方法是解决一类问题的步骤的有序集合方法包含与类或对象中方法在程序中被创建,在其…...
)
数据史话|Dashboard 仪表板的进化史:从马车挡泥板,到企业战略工具(海外见解版)
今天我们来聊聊仪表板(Dashboard)的奇妙进化史。想象一下:马车前挡泥的木板,和你浏览器里满是 KPI、迷你图表、筛选器的仪表盘 —— 它们用的是同一个词,同一个核心使命,只是再也没有泥点子了。这就是仪表盘…...

Kemono-scraper完整指南:从批量下载到智能管理的艺术收藏工具
Kemono-scraper完整指南:从批量下载到智能管理的艺术收藏工具 【免费下载链接】Kemono-scraper Kemono-scraper - 一个简单的下载器,用于从kemono.su下载图片,提供了多种下载和过滤选项。 项目地址: https://gitcode.com/gh_mirrors/ke/Kem…...

AI绘画的三重危机:颜料、像素与剽窃
1. 这不是技术讨论,而是一场正在发生的行业地震“Paint, Pixels, and Plagiarism”——光看这个标题,你就能闻到火药味。它没说“AI绘画工具使用指南”,也没写“Stable Diffusion参数调优手册”,而是把颜料(Paint&…...

小爱音箱音乐解锁终极指南:简单三步实现智能音箱音乐自由
小爱音箱音乐解锁终极指南:简单三步实现智能音箱音乐自由 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否曾经对小爱音箱说"播放周杰伦"…...
)
ChatGPT API安全调用规范,如何防止Prompt注入、数据泄露与越权访问(附OWASP合规检查清单)
更多请点击: https://kaifayun.com 第一章:ChatGPT API安全调用规范总览 安全调用ChatGPT API是保障系统稳定性、数据隐私与合规运营的前提。开发者必须在身份认证、请求构造、响应处理及密钥生命周期管理等各环节建立防御性实践,避免因配置…...