LeetCode105.从前序和中序遍历序列构造二叉树
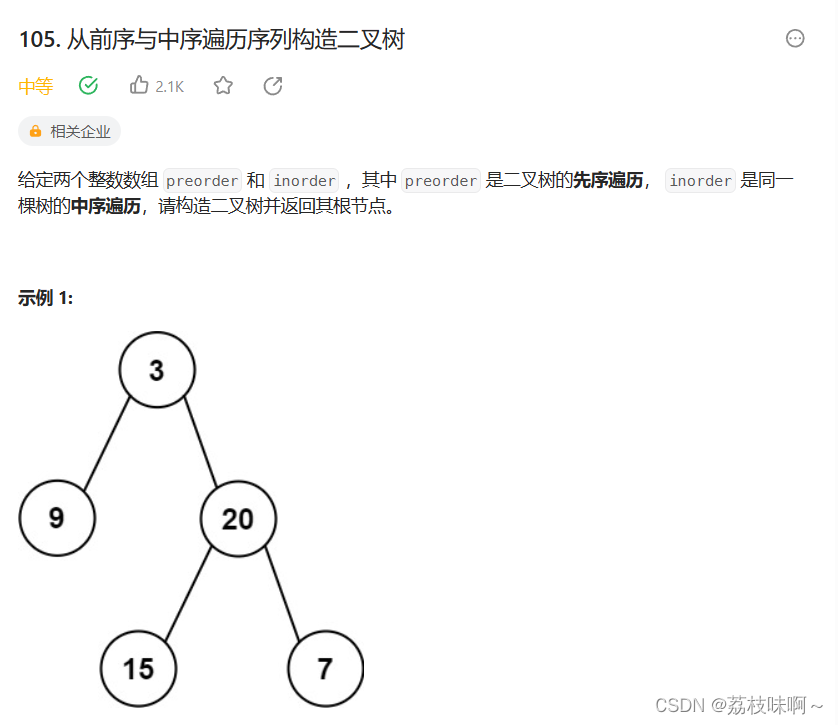

这道题看完题想了几分钟就想到大概的思路了,但是在写的时候有很多细节没注意出了很多问题,然后写了1个多小时,其实这道题挺简单的。
首先,最基本的知识,先序遍历是根左右,中序遍历是左根右,那么我们一眼可以知道:根节点是先序遍历的第一个节点,然后又可以在中序遍历中找到这个根节点(树中每个val都不相等),中序遍历中根节点的左变是左子树,根节点的右遍是右子树。
那么这个题目应该怎么解呢?首先,对于树的题目要么递归要么用队列或栈,我选择用递归。根据上面发现的几个点,我想到了递归函数:
public TreeNode dfs(int[] preorder, int[] inorder)通过这两个遍历序列我们可以创建出根节点,然后我们在从preorder和inorder中找出来左子树的leftPreorder和leftInorder以及右子树的rightPreorder和rightInorder,然后利用递归
root.left=dfs(leftPreorder, leftInorder);
root.right = dfs(rightPreorder, rightInorder);大体上的思路就是这样,那么我们如何找出左右子树的前序和中序的遍历序列呢?
首先中序遍历是非常简单的,中序遍历是左根右的顺序,它对于每颗树都是根左右的顺序,所以‘左’就是左子树的中序遍历结果,所以我们在inorder中根节点左边就是leftInorder,根节点右边就是rightInorder。
前序遍历也不难,前序遍历是根左右,preorder第0个数是根节点,后面是左和右,而我们在中序遍历中已经知道了左子树的长度leftLength和右子树的长度rightLength,所有从第1个数往后数leftLength就是左子树的前序遍历leftPreorder,剩下的就是右子树的前序遍历rightPreorder。
然后需要注意的就是,递归的结束,如果左子树的长度小于0就不用递归的创建左子树了,右子树同理,最后返回root。以下是我的代码:
class Solution {public TreeNode buildTree(int[] preorder, int[] inorder) {if(preorder.length == 0){return null;}else{return dfs(preorder, inorder);}}public TreeNode dfs(int[] preorder, int[] inorder){TreeNode root = new TreeNode(preorder[0]);int leftInorderIndex = 0;int rightInorderIndex = 0;int leftPreorderIndex = 0;int rightPreorderIndex = 0;//在中序遍历中找到根节点for(int i=0;i<inorder.length;i++){if(inorder[i] == root.val){leftInorderIndex = i-1;rightInorderIndex = i+1;break;}}//找到左子树长度和右子树长度int leftLength = leftInorderIndex+1;int rightLength = inorder.length - rightInorderIndex;if(leftLength > 0){//创建leftInorderint[] leftInorder = new int[leftLength];for(int i=0;i<leftInorder.length;i++){leftInorder[i] = inorder[i];}//创建leftPreorderint[] leftPreorder = new int[leftLength];int index =1;for(int i=0;i<leftPreorder.length;i++){leftPreorder[i] = preorder[index];index++;}//递归出根节点的左子树root.left = dfs(leftPreorder, leftInorder);}if(rightLength > 0){//创建出rightInorderrightPreorderIndex = leftLength+1;int[] rightInorder = new int[rightLength];int index0= rightInorderIndex;for(int i=0;i<rightInorder.length;i++){rightInorder[i] = inorder[index0];index0++;}//创建出rightPreorderint[] rightPreorder = new int[rightLength];int index1 = rightPreorderIndex;for(int i=0;i<rightPreorder.length;i++){rightPreorder[i] = preorder[index1];index1++;}//递归出根节点的右子树root.right = dfs(rightPreorder, rightInorder);}return root;}
}看看官方题解做法:
题解的方法一用的也是递归,但是他用了一个HashMap来快速定位根节点,还有就是他没有去创建左右子树的前中遍历序列数组,他直接传前序,中序遍历在inorder中的起始下标和终止下标,因为他们在数组中是连续的,这样全局只需要用这个最大的inorder和preorder就可以,不用花费时间和空间去创建数组,以下是题解方法一代码:
class Solution {private Map<Integer, Integer> indexMap;public TreeNode myBuildTree(int[] preorder, int[] inorder, int preorder_left, int preorder_right, int inorder_left, int inorder_right) {if (preorder_left > preorder_right) {return null;}// 前序遍历中的第一个节点就是根节点int preorder_root = preorder_left;// 在中序遍历中定位根节点int inorder_root = indexMap.get(preorder[preorder_root]);// 先把根节点建立出来TreeNode root = new TreeNode(preorder[preorder_root]);// 得到左子树中的节点数目int size_left_subtree = inorder_root - inorder_left;// 递归地构造左子树,并连接到根节点// 先序遍历中「从 左边界+1 开始的 size_left_subtree」个元素就对应了中序遍历中「从 左边界 开始到 根节点定位-1」的元素root.left = myBuildTree(preorder, inorder, preorder_left + 1, preorder_left + size_left_subtree, inorder_left, inorder_root - 1);// 递归地构造右子树,并连接到根节点// 先序遍历中「从 左边界+1+左子树节点数目 开始到 右边界」的元素就对应了中序遍历中「从 根节点定位+1 到 右边界」的元素root.right = myBuildTree(preorder, inorder, preorder_left + size_left_subtree + 1, preorder_right, inorder_root + 1, inorder_right);return root;}public TreeNode buildTree(int[] preorder, int[] inorder) {int n = preorder.length;// 构造哈希映射,帮助我们快速定位根节点indexMap = new HashMap<Integer, Integer>();for (int i = 0; i < n; i++) {indexMap.put(inorder[i], i);}return myBuildTree(preorder, inorder, 0, n - 1, 0, n - 1);}
}题解的第二种方法是迭代,
class Solution {public TreeNode buildTree(int[] preorder, int[] inorder) {if (preorder == null || preorder.length == 0) {return null;}TreeNode root = new TreeNode(preorder[0]);Deque<TreeNode> stack = new LinkedList<TreeNode>();stack.push(root);int inorderIndex = 0;for (int i = 1; i < preorder.length; i++) {int preorderVal = preorder[i];TreeNode node = stack.peek();if (node.val != inorder[inorderIndex]) {node.left = new TreeNode(preorderVal);stack.push(node.left);} else {while (!stack.isEmpty() && stack.peek().val == inorder[inorderIndex]) {node = stack.pop();inorderIndex++;}node.right = new TreeNode(preorderVal);stack.push(node.right);}}return root;}
}相关文章:
LeetCode105.从前序和中序遍历序列构造二叉树
这道题看完题想了几分钟就想到大概的思路了,但是在写的时候有很多细节没注意出了很多问题,然后写了1个多小时,其实这道题挺简单的。 首先,最基本的知识,先序遍历是根左右,中序遍历是左根右,那么…...
flutter-一个可以输入的数字增减器
效果 参考文章 代码 在参考文章上边,主要是改了一下样式,逻辑也比较清楚,对左右两边添加增减方法。 我在此基础上加了_numcontroller 输入框的监听。 加了数字输入框的控制 keyboardType: TextInputType.number, //设置键盘为数字 inputF…...

抑郁症中西医治疗对比?
抑郁症是一种常见的心理障碍,治疗方法包括中医和西医两种。下面就抑郁症中西医治疗进行对比: 治疗方法:中医治疗抑郁症强调整体观念和辨证论治,通过调理身体各部分的功能,达到治疗抑郁症的目的。中医治疗抑郁症多采用天…...
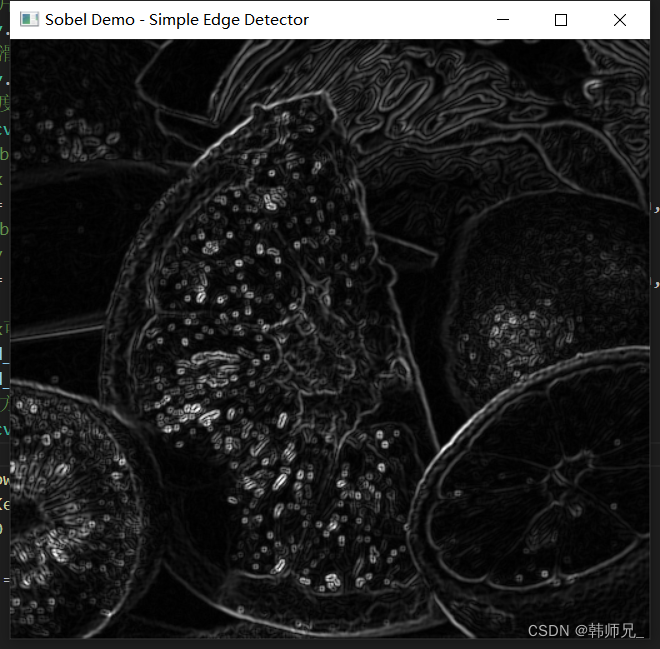
012 OpenCV sobel边缘检测
目录 一、环境 二、soble原理介绍 三、源码实验 一、环境 本文使用环境为: Windows10Python 3.9.17opencv-python 4.8.0.74 二、soble原理介绍 Sobel边缘检测是一种广泛应用于图像处理领域的边缘检测算法,它通过计算图像灰度函数在水平方向和垂直…...

【开源视频联动物联网平台】libmodbus 写一个modbus tcp客户端
libmodbus 是一个用于 Modbus 通信协议的 C 语言库,可以用来创建 Modbus TCP 客户端。以下是一个简单的示例代码,演示如何使用 libmodbus 创建一个 Modbus TCP 客户端。 首先,确保你已经安装了 libmodbus 库。你可以从 libmodbus 的官方网站…...
安装以及使用 stylepro_artistic 所遇问题解决
根据https://github.com/PaddlePaddle/PaddleHub/blob/develop/docs/docs_ch/get_start/windows_quickstart.md 安装 hub install stylepro_artistic1.0.1 出现ImportError: cannot import name ‘Constant’ from ‘paddle.fluid.initializer’,提示在File: "…...
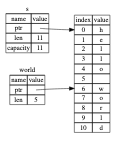
【Rust】所有权的认识
所有权 所有权的认识移动,克隆,拷贝所有权与函数返回值与作用域 引用与借用可变引用悬垂引用(Dangling References) Slice类型 所有权的认识 所有程序都必须管理其运行时使用计算机内存的方式。一些语言中具有垃圾回收机制&#…...
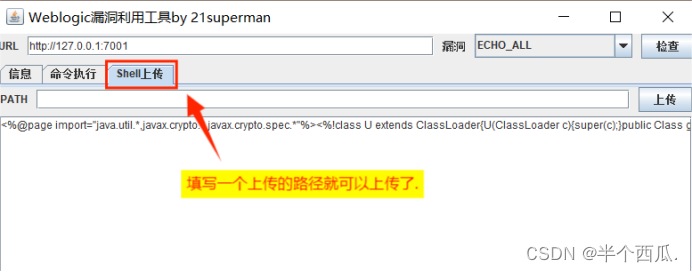
中间件安全:Weblogic 漏洞.(使用工具可以利用多种类型漏洞)
中间件安全:Weblogic 漏洞.(使用工具可以利用多种类型漏洞) WebLogic 是美国 Oracle 公司出品的一个 application server,确切的说是一个基于 JAVA EE 架构的中间件,WebLogic 是用于开发、集成、部署和管理大型分布式…...

matlab操作方法(一)——向量及其操作
1.向量及其操作 matlab是英文Matrix Laboratory(矩阵实验室)的简称,是基于矩阵运算的操作环境。matlab中的所有数据都是以矩阵或多维数组的形式存储的。向量和标量是矩阵的两种特殊形式 向量是指单行或者单列的矩阵,它是构成矩阵…...
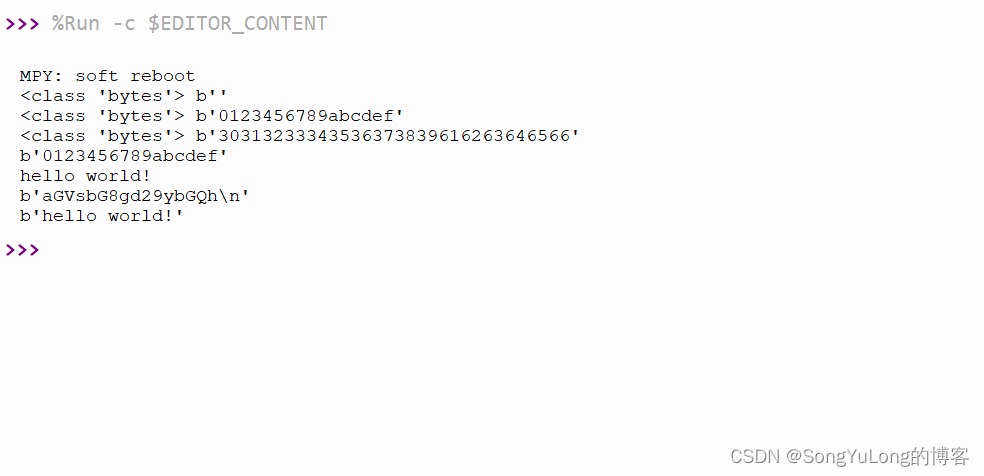
MicroPython标准库
MicroPython标准库 arraybinascii(二进制/ASCII转换)builtins – 内置函数和异常cmath – 复数的数学函数collections – 集合和容器类型errno – 系统错误代码gc – 控制垃圾收集器hashlib – 散列算法heapq – 堆队列算法io – 输入/输出流json – JSON 编码和解码math – 数…...
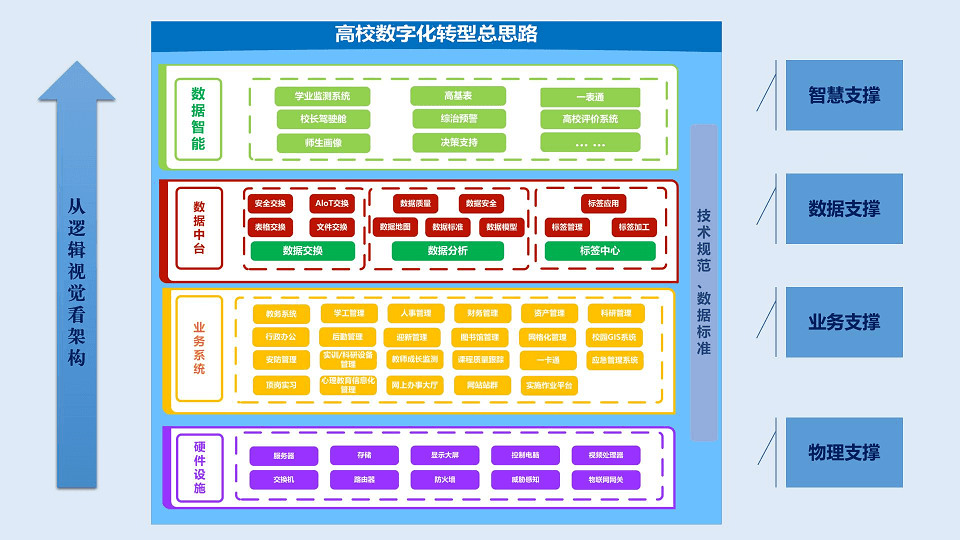
2023年产业数据价值化峰会暨数栖大会-核心PPT资料下载
一、峰会简介 本次大会由主论坛和3场分论坛组成,嘉宾阵容强大,内容丰富多彩。来自政企学界的百名专家从产学研用多种维度对企业数据管理、产业数据资源化建设等视角展开。大会围绕“产业数据价值化”为主题,秉持“让数据用起来”的使命&…...

深入理解 Vue 组件:构建优雅的前端应用
🍂引言: Vue.js 是一款流行的 JavaScript 框架,以其简单易用和高度灵活的特性而受到了广泛的欢迎。其中的一个重要概念就是组件,它使我们能够将用户界面划分为可重用的、独立的部分。本文将深入探讨 Vue 组件的概念、使用和最佳实…...
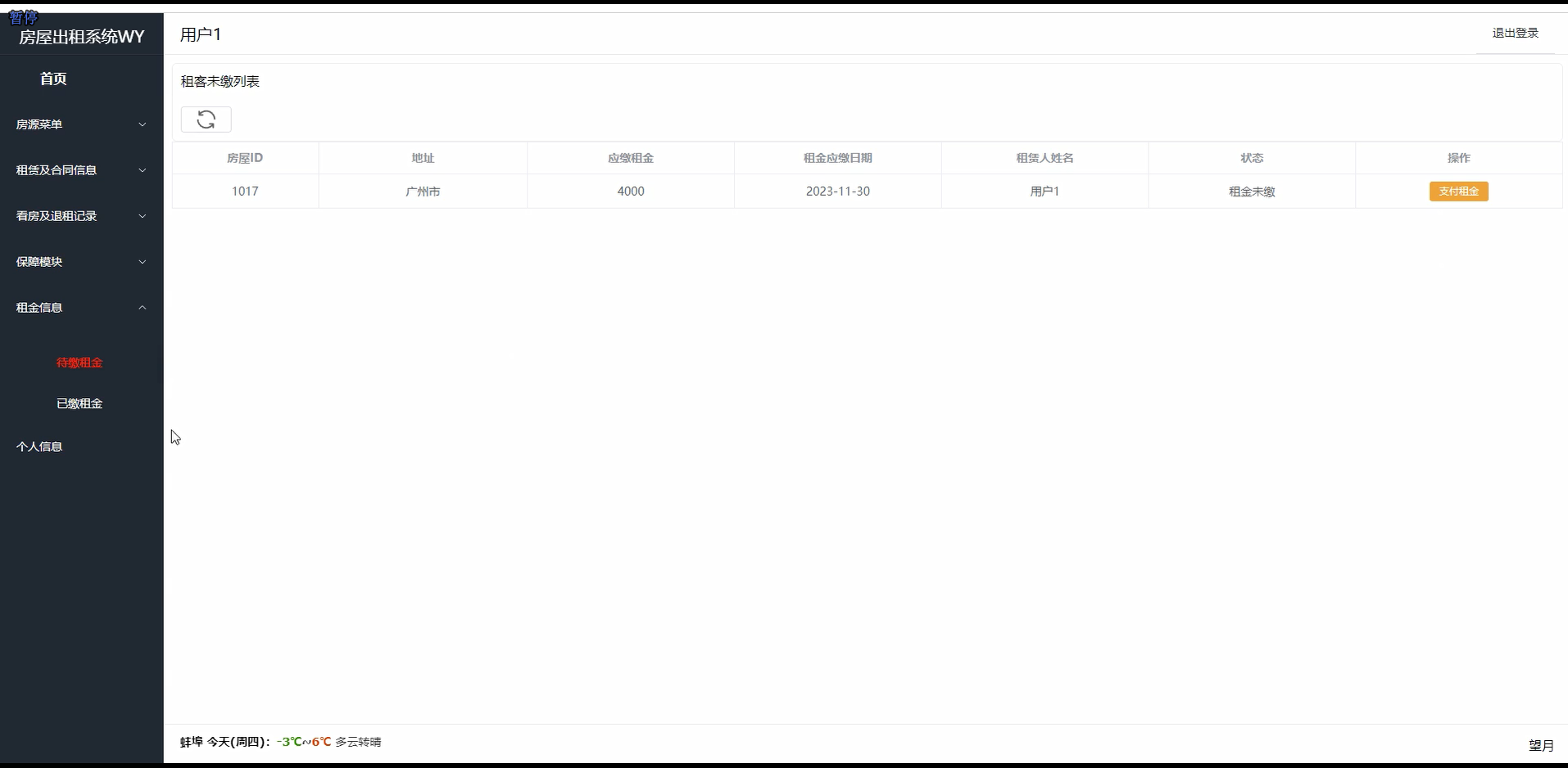
基于SpringBoot+Vue的前后端分离的房屋租赁系统2
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 开发过程中࿰…...
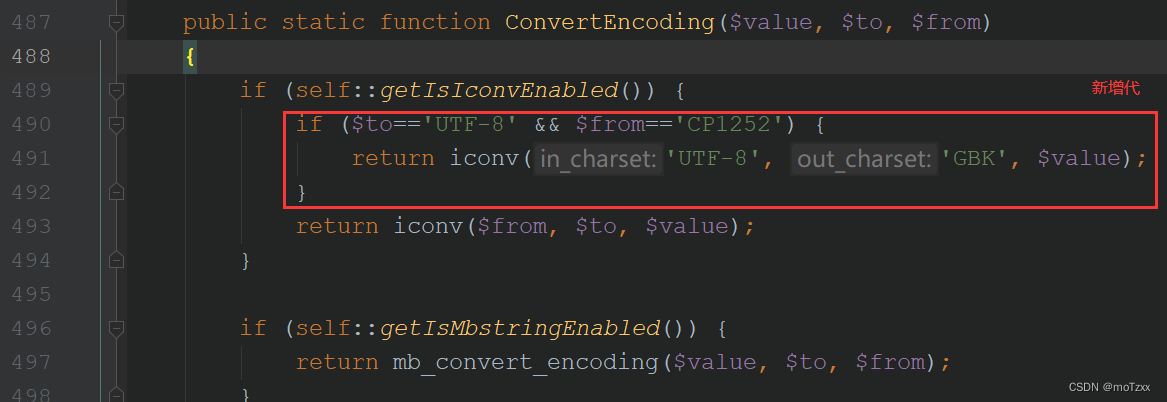
PHPExcel 导出Excel报错:PHPExcel_IOFactory::load()
背景 近期在做 excel文件数据导出时,遇到如下报错: iconv(): Detected an illegal character in input string场景:计划任务后台,分步导出 大数据 excel文件发现在加载文件时,会有报错 报错信息 如下: {&q…...
Jmeter-分布式压测(远程启动服务器,windows)
1 前提条件 JDK已部署,版本一致Jmeter已部署,版本一致多台服务器连接的同一网络(例如:同一wifi)防火墙处于关闭状态(或者对应默认端口处于开放状态)虚拟网络适配器都处于关闭状态查找到每一台服务器的IP 2 主服务器配…...
【C++】string类模拟实现过程中值得注意的点
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》《C》《Linux》 🌝每一个不曾起舞的日子,都是对生命的辜负 目录 前言 1.有关const的使用 &#x…...

大数据湖项目建设方案:文档全文101页,附下载
关键词:大数据解决方案,数据湖解决方案,数据治理解决方案,数据中台解决方案 一、大数据湖建设思路 1、明确目标和定位:明确大数据湖的目标和定位是整个项目的基础,这可以帮助我们确定项目的内容、规模、所…...
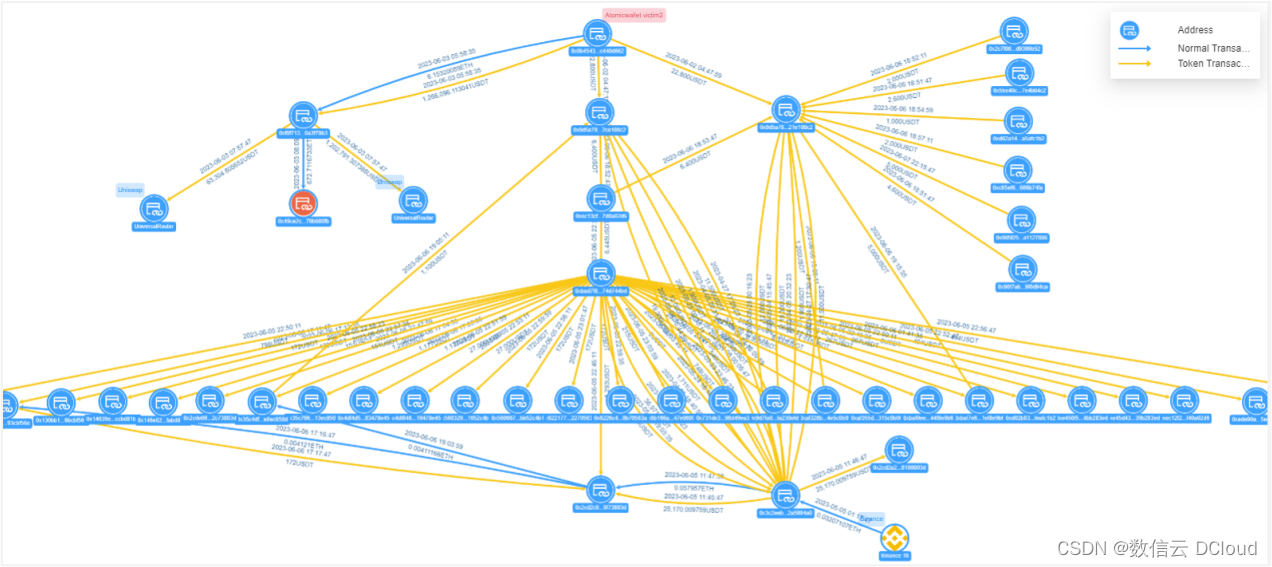
通付盾Web3专题 | SharkTeam:起底朝鲜APT组织Lazarus Group,攻击手法及洗钱模式
国家级APT(Advanced Persistent Threat,高级持续性威胁)组织是有国家背景支持的顶尖黑客团伙,专门针对特定目标进行长期的持续性网络攻击。朝鲜APT组织Lazarus Group就是非常活跃的一个APT团伙,其攻击目的主要以窃取资…...

<蓝桥杯软件赛>零基础备赛20周--第8周第1讲--十大排序
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集 20周的完整安排请点击:20周计划 每周发1个博客,共20周(读者可以按…...

数据增强让模型更健壮
在做一些图像分类训练任务时,我们经常会遇到一个很尴尬的情况,那就是: 明明训练数据集中有很多可爱猫咪的照片,但是当我们给训练好的模型输入一张戴着头盔的猫咪进行测试时,模型就不认识了,或者说识别精度很低。 很明显,模型的泛化能力太差,难道戴着头盔的猫咪就不是猫…...

SpringbootWeb【入门】+Mysql【安装】
今天这个是很重要的先从认识spring开始后面认识springboot 这是www.spring.io官网 这就是创说中的spring全家桶 打开idea创建一个Sringboot工程出来 这就创建好了 现在开始装Mysql【安装】 MySQL :: Download MySQL Community Serverhttps://dev.mysql.com/downloads/m…...

02. 基本类型
02. 基本类型 1. 概述 TypeScript 的核心特性是静态类型系统。基本类型是 TypeScript 类型系统的基础,包括 JavaScript 原有的原始类型和 TypeScript 新增的特殊类型。 // TypeScript 类型系统概览 ┌──────────────────────────────…...

体验Taotoken官方折扣与Token Plan带来的实际费用节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken官方折扣与Token Plan带来的实际费用节省 对于开发者个人或小团队而言,在项目开发或日常工作中使用大模型…...

5分钟上手Real-ESRGAN:让模糊图片瞬间清晰的AI图像增强神器
5分钟上手Real-ESRGAN:让模糊图片瞬间清晰的AI图像增强神器 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN 你是否曾为…...

Multiverse 引擎3.0:大屏、移动、AR三端覆盖,AR交互功能详解
在Multiverse 3.0版本中,我们首次实现了移动端、大屏端与AR端的全覆盖。基于“一模双擎”架构,用户在Web端可视化编辑器(支持“拖、拉、拽”搭建场景)中创建的数字孪生场景,可在像素流中直接加载,自动适配到…...

ncmdumpGUI终极指南:3步轻松解锁网易云音乐NCM加密文件
ncmdumpGUI终极指南:3步轻松解锁网易云音乐NCM加密文件 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经遇到过这样的烦恼?在…...

技术从业者的面试技巧:如何通过大厂的技术面试
在软件行业的招聘生态中,大厂的技术面试如同一场严苛的专业试炼,尤其对于软件测试从业者而言,不仅要展现扎实的技术功底,更要体现出符合大厂标准的工程思维与问题解决能力。想要在竞争激烈的面试中脱颖而出,需要从面试…...

孤胆英雄的黄昏,社会化智能的黎明:一文看透 Multi-Agent 架构底层逻辑
在过去的一两年里,我们见证了单体大语言模型(LLM)的疯狂进化。我们给它穿上基建外骨骼(Harness),给它挂载无数的函数工具(Skills),试图把它打造成一个无所不能的“全栈超…...
)
RuoYi-Cloud项目导入避坑指南:从Maven配置到依赖下载的完整流程(附常见错误解决)
RuoYi-Cloud项目导入避坑指南:从Maven配置到依赖下载的完整流程 1. 项目准备与环境检查 在开始导入RuoYi-Cloud项目之前,确保你的开发环境已经准备就绪。这个微服务架构项目基于Spring Cloud Alibaba体系,对开发环境有特定要求: 基…...
)
手把手教你用树莓派4B搭建个人服务器(保姆级图文教程,含SSH与远程桌面配置)
树莓派4B打造高性能个人服务器的终极指南 在当今数字化时代,拥有一个24小时在线的个人服务器不再是企业或技术巨头的专利。树莓派4B以其惊人的性价比和低功耗特性,正在重新定义个人服务器的可能性。想象一下,你的书架上安静运行着一台耗电仅5…...