sharding-jdbc实现分库分表
shigen日更文章的博客写手,擅长Java、python、vue、shell等编程语言和各种应用程序、脚本的开发。记录成长,分享认知,留住感动。
😅😅最近几天的状态有点不对,所以有几天没有更新了。
当我们的数据量比较大(没接触过)就会考虑一下分库分表的策略。当然分库分表又分为多种策略:
- 拆分数据库,做到数据的分离(多租户的设计)
- 水平拆分表:类似于数据的分片
- 垂直拆分表:某些不常用的字段放在另外一张表,我们通过主键关联,在之前的文章mysql表设计规范中也有提到:

在去年疫情的时候,其实shigen就研究了一下这个,只不过当时用的是apache-shardingsphere,采用的是官方的资源包,需要各种安装和配置:
最近发现它其实可以和springboot结合起来使用,于是研究了一下,最后发现很好用。
官方配置文档在这里,需要详细步骤的可以去看下官网的案例和解释。
首先我们创建两个数据库,每个数据库两张表:
-- 数据库1中的user表
CREATE TABLE ds0.user0
(id INT PRIMARY KEY COMMENT '用户ID',name VARCHAR(50) COMMENT '用户姓名',age INT COMMENT '用户年龄'
);CREATE TABLE ds0.user1
(id INT PRIMARY KEY COMMENT '用户ID',name VARCHAR(50) COMMENT '用户姓名',age INT COMMENT '用户年龄'
);-- 数据库2中的user表
CREATE TABLE ds1.user0
(id INT PRIMARY KEY COMMENT '用户ID',name VARCHAR(50) COMMENT '用户姓名',age INT COMMENT '用户年龄'
);CREATE TABLE ds1.user1
(id INT PRIMARY KEY COMMENT '用户ID',name VARCHAR(50) COMMENT '用户姓名',age INT COMMENT '用户年龄'
);
对应关系是这样的:
| 数据库 | 数据表 | 备注 |
|---|---|---|
| Ds0 | User0 | 数据源1的分表1 |
| Ds0 | User1 | 数据源1的分表2 |
| Ds1 | User0 | 数据源2的分表1 |
| Ds1 | User1 | 数据源2的分表2 |
在shigen之前创建的数据库和数据表用到了类似这样的名字:
demo-ds-0, user_1,发现配置起来老有问题了,直接炸了啊。
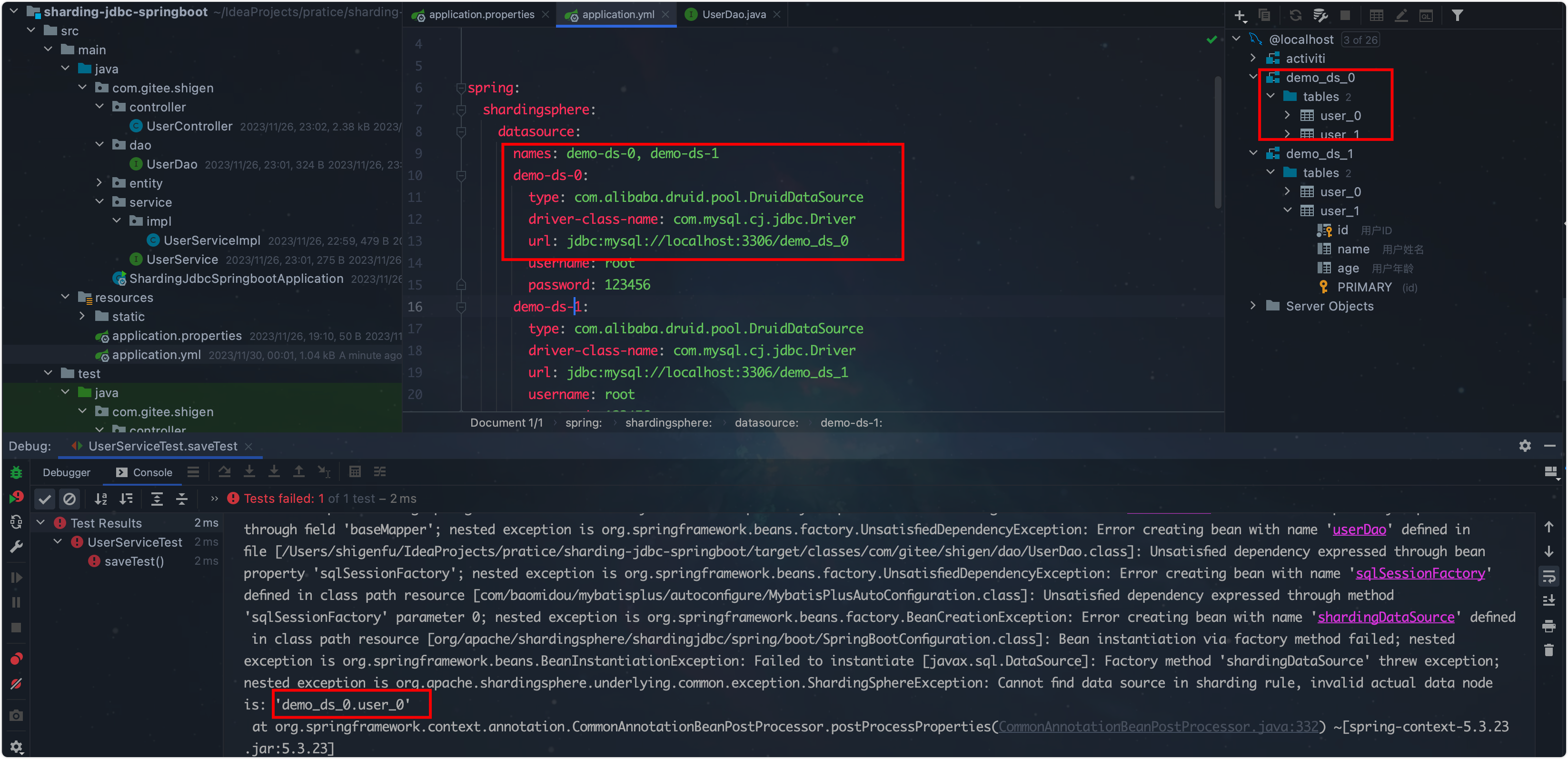
最后改成不要下划线的才算正常。
在一切准备好之后,我们开始今天的案例。
基于sharding-jdbc实现数据水平切分
引入依赖
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.1</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version></dependency>
这是最核心的依赖,当然,mysql的驱动、mybatis-plus这里也是需要的。
生成基础代码
我们用魔法生成对应的controller、service、dao。
编写配置文件
这里我就直接贴上我的配置了,更多的配置可以参考官网。
spring:shardingsphere:datasource:names: ds0, ds1ds0:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/ds0username: rootpassword: 123456ds1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/ds1username: rootpassword: 123456sharding:tables:user:actual-data-nodes: ds$->{0..1}.user$->{0..1}table-strategy:inline:sharding-column: idalgorithm-expression: user$->{id % 2}key-generator:column: idtype: SNOWFLAKEbinding-tables: userbroadcast-tables:default-database-strategy:inline:sharding-column: agealgorithm-expression: ds$->{age % 2}props:sql:show: true
mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl其实看起来也很有意思的:
-
采用了druid作为数据库的连接池工具,它自带后台,可以监控我们的sql
-
我们表的拆分根据的是user.id,id是偶数就放在user0,奇放在user1
-
数据库的拆分根据的是user.age,这里的age是偶数,放在ds0,反之放在ds1
-
打印详细的sql执行语句
就这些,其实已经帮我们把复杂的配置简单了。现在,我们写一个测试类测试吧。
测试类测试
@Testpublic void saveTest() {for (int i = 100; i < 120; i++) {User user = new User().setId(i+10000).setName("shigen-" + i).setAge(RandomUtil.randomInt(5, 100));userMapper.insert(user);}}
1-99的我已经测试了。
观察一下运行的结果:
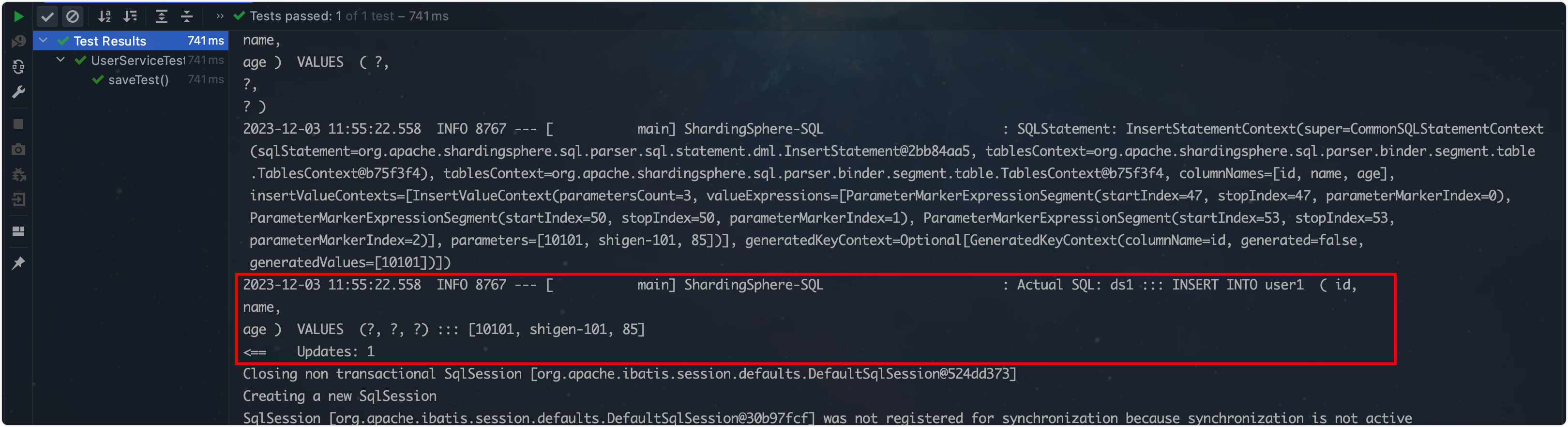
我们再到数据库看一下:
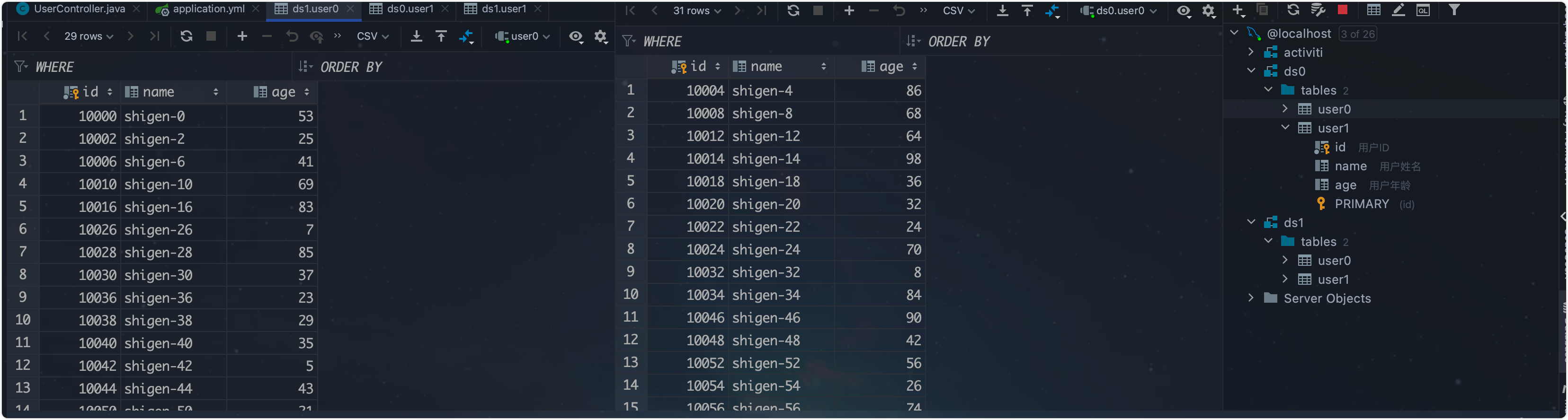
很符合预期啊,年龄为奇数的在ds0,id为偶数的在user0;表明我们的测试顺利。
其实还是那句话,具体场景具体的分析,没有这么大的数据量,分库分表反而是复杂、完全没必要的设计。也希望提供一种技术选型和参考。
当然,sharding-jdbc还支持读写分离,正好shigen之前也有一个文章是关于springboot+mybtais-plus实现读写分离的,那就期待下期的文章吧!
以上就是今天分享的全部内容了,觉得不错的话,记得点赞 在看 关注支持一下哈,您的鼓励和支持将是shigen坚持日更的动力。同时,shigen在多个平台都有文章的同步,也可以同步的浏览和订阅:
| 平台 | 账号 | 链接 |
|---|---|---|
| CSDN | shigen01 | shigen的CSDN主页 |
| 知乎 | gen-2019 | shigen的知乎主页 |
| 掘金 | shigen01 | shigen的掘金主页 |
| 腾讯云开发者社区 | shigen | shigen的腾讯云开发者社区主页 |
| 微信公众平台 | shigen | 公众号名:shigen |
与shigen一起,每天不一样!
相关文章:
sharding-jdbc实现分库分表
shigen日更文章的博客写手,擅长Java、python、vue、shell等编程语言和各种应用程序、脚本的开发。记录成长,分享认知,留住感动。 😅😅最近几天的状态有点不对,所以有几天没有更新了。 当我们的数据量比较大…...
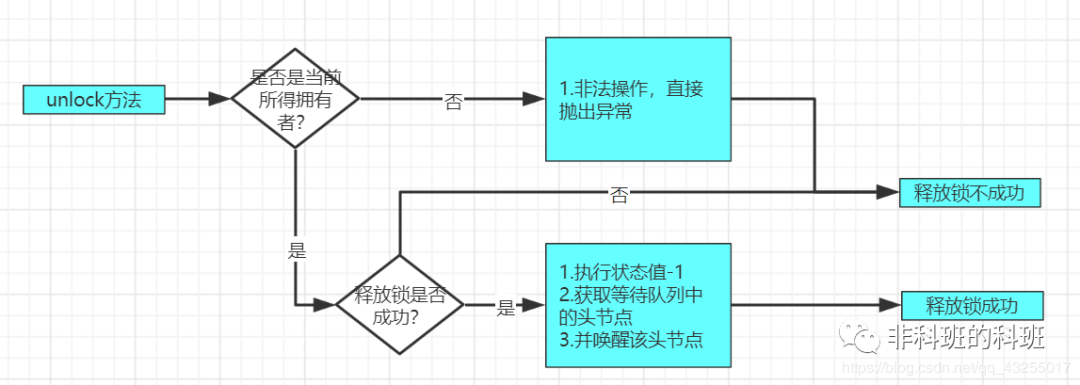
JDK中lock锁的机制,其底层是一种无锁的架构实现的,公平锁和非公平锁
简述JDK中lock锁的机制,其底层是一种无锁的架构实现的,是否知道其是如何实现的 synchronized与lock lock是一个接口,而synchronized是在JVM层面实现的。synchronized释放锁有两种方式: 获取锁的线程执行完同步代码,…...

c++通过serial库进行上下位机通信
编辑 风紊 现役大学牲,半退休robomaster视觉队员 写在前面 本文章主要介绍的是如何通过开源的serial库和虚拟串口实现上位机和下位机通信。 需求 假设下位机有这样一个数据报发送给上位机 struct DataRecv {char start s;TeamColor color TeamColor::Blu…...
【傻瓜级JS-DLL-WINCC-PLC交互】7.C#直连PLC并读取PLC数据
思路 JS-DLL-WINCC-PLC之间进行交互,思路,先用Visual Studio创建一个C#的DLL控件,然后这个控件里面嵌入浏览器组件,实现JS与DLL通信,然后DLL放入到WINCC里面的图形编辑器中,实现DLL与WINCC的通信。然后PLC与…...
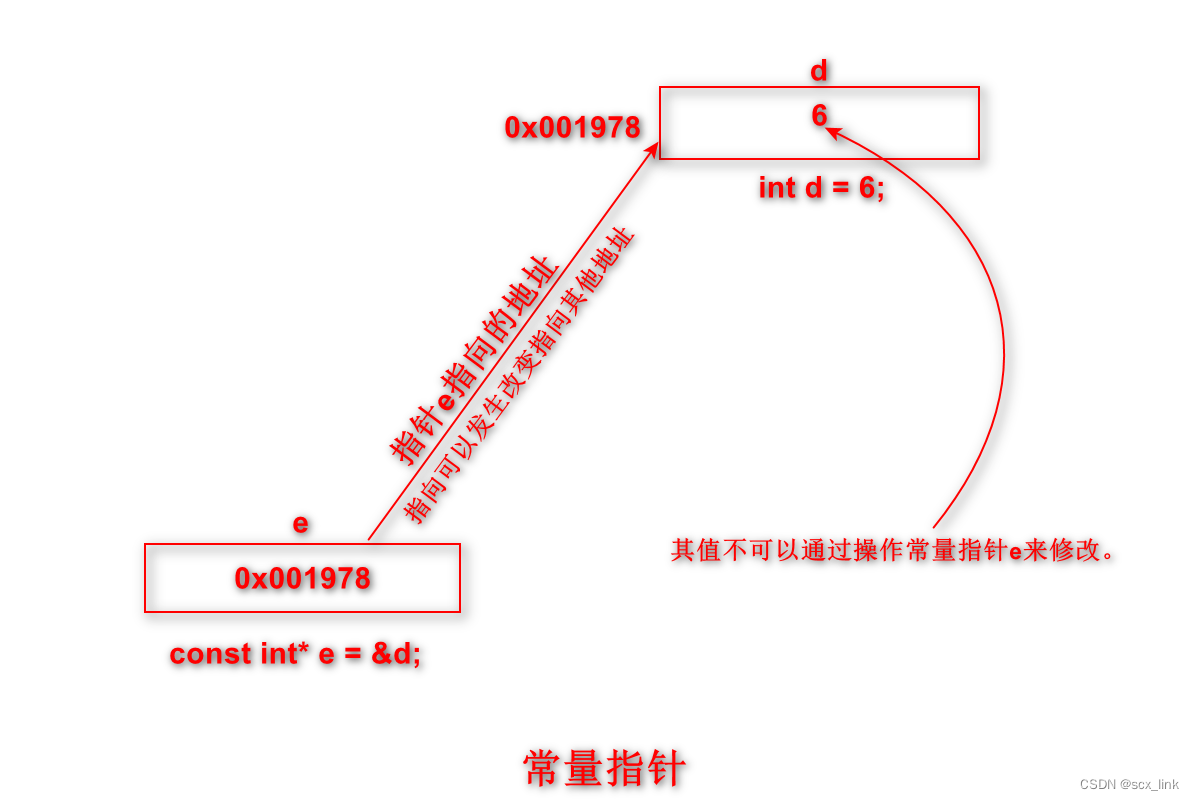
指针常量和常量指针的区别
文章目录 指针常量常量指针即是指针常量又是常量指针 指针常量 指针常量的本质是常量,表示的是 这个指针所指向的地址不能发生改变。即指针变量的值(即地址值)不能发生修改。但是指针所指向的那块内存里的值是可以修改的。 注意:…...

离散化算法总结
离散化是将大范围的数字映射到小范围的区间内,适用于稀疏的区间。 两个问题需要考虑: 1. 原数组中可能有重复元素,需要去重。 2. 如何算出离散化后的值(离散化后保序,使用二分)。 题目链接: …...

【海思SS528 | VO】MPP媒体处理软件V5.0 | VO模块编程总结
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
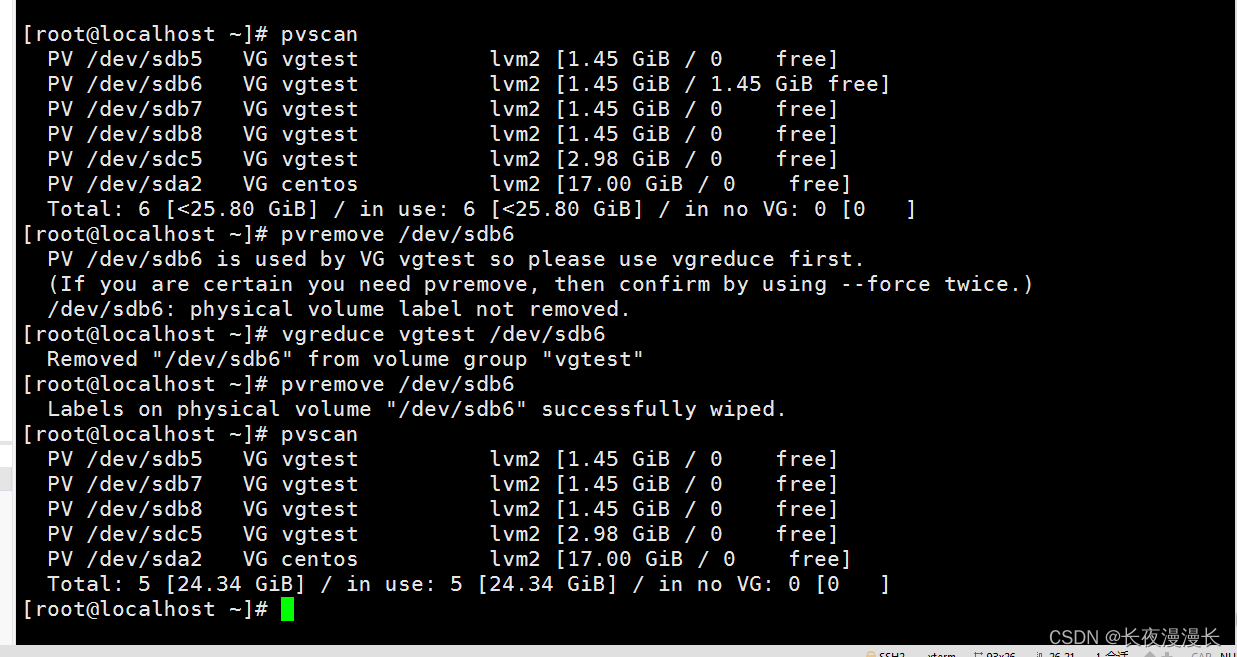
逻辑卷管理器lvm
啥意思,个人理解就是可以将物理分区合并一起组成大的磁盘,也可以移除其中的某个分区。 有四个概念需要了解下 PV,物理卷,VG 卷用户组,PE物理扩展块,LV逻辑卷 p物理,v卷,g用户组&a…...

函数声明后的“ - >”是什么?
这种语法的优势之一是可以在函数的返回类型中使用函数参数,使得返回类型更灵活。 先来看一个使用尾返回类型的例子: #include <iostream> auto add(int a, int b) -> int {return a b; }int main() {std::cout << add(3, 4) <<…...

51爱心流水灯32灯炫酷代码
源代码摘自远眺883的文章,大佬是30个灯的,感兴趣的铁汁们可以去看看哦~(已取得原作者的许可):基于STC89C51单片机设计的心形流水灯软件代码部分_单片机流水灯代码_远眺883的博客-CSDN博客 由于博主是个小菜鸡ÿ…...
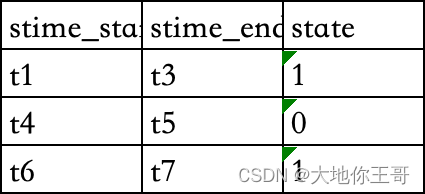
将不同时间点的登录状态记录转化为不同时间段的相同登录状态SQL求解
题目 有不同时间点的登录状态记录表state_log如下 请使用sql将其转化为如下表的不同时间段的相同登录状态记录 思路分析: 此类问题需要用到lag或lead函数取上下行对应的数据,然后对前后结果做比较打标签(0或1),再…...

正则表达式与SQL数据库教程
使用正则表达式通过用例查询 Postgres 数据库: 正则表达式(又名 Regex) 正则表达式是一个强大的工具,广泛用于模式匹配和文本操作。 几乎所有编程语言都支持它们,并且经常用于文本提取、搜索和匹配文本等用例。 正则…...

HTML_web扩展标签
1.表格标签 2.增强表头表现 4.表格属性(实际不常用) 结构标签: 合并单元格: 更多请查看主页...
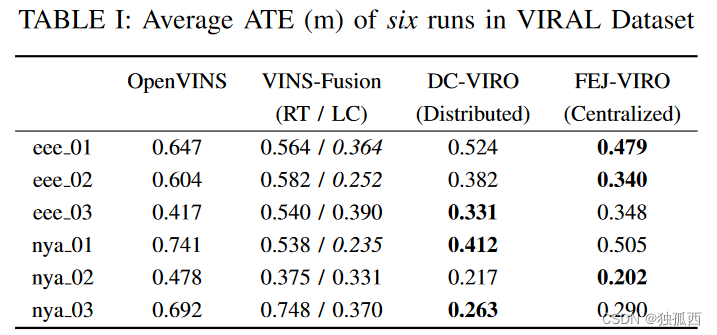
论文阅读:Distributed Initialization for VVIRO with Position-Unknown UWB Network
前言 Distributed Initialization for Visual-Inertial-Ranging Odometry with Position-Unknown UWB Network这篇论文是发表在ICRA 2023上的一篇文章,本文提出了一种基于位置未知UWB网络的一致性视觉惯性紧耦合优化测距算法( DC-VIRO )的分布式初始化方法。 对于…...

scrapy爬虫中间件和下载中间件的使用
一、关于中间件 之前文章说过,scrapy有两种中间件:爬虫中间件和下载中间件,他们的作用时间和位置都不一样,具体区别如下: 爬虫中间件(Spider Middleware) 作用: 爬虫中间件主要负…...
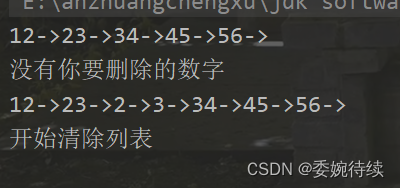
手敲单链表,简单了解其运行逻辑
1. 链表 1.1 结构组成 链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。 链表的结构如下图所示,是由很多个节点相互通过引用来连接而成的;每一个节点由两部分组成,分别数据域&…...

Redis RDB
基于内存的 Redis, 数据都是存储在内存中的。 那么如果重启的话, 数据就会丢失。 为了解决这个问题, Redis 提供了 2 种数据持久化的方案: RDB 和 AOF。 RDB 是 Redis 默认的持久化方案。当满足一定条件的时候, 会把当前内存中的数据写入磁盘, 生成一个快照文件 dump.rdb。Redi…...

Elasticsearch一些函数查询
1. 根据价格分组统计数量,每组区间为2000, filter_pathaggregations 设置查询结果只展示函数结果 也有date_histogram函数根据日期分组等等 GET order/_search?filter_pathaggregations {"aggs": {"hist_price": {"histogr…...

竞赛选题 : 题目:基于深度学习的水果识别 设计 开题 技术
1 前言 Hi,大家好,这里是丹成学长,今天做一个 基于深度学习的水果识别demo 这是一个较为新颖的竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/pos…...
Linux expect命令详解
在Linux系统中,expect 是一款非常有用的工具,它允许用户自动化与需要用户输入进行交互的程序。本文将深入探讨expect命令的基本语法、使用方法以及一些最佳实践。 什么是Expect命令? expect 是一个用于自动化交互式进程的工具。它的主要功能…...

2026年冰袋吸水粉厂家大揭秘:选择指南与行业趋势题
随着冷链物流行业的快速发展,冰袋吸水粉作为冷链运输中不可或缺的保冷材料,其市场需求持续增长。然而,市场上冰袋吸水粉的质量参差不齐,如何选择一家值得信赖的厂家成为许多采购商关注的重点。本文将从行业背景、技术特点及市场趋…...

【作品集】OpenClaw-AgentOps企业级多智能体贵金属交易分析平台
项目名称:OpenClaw-AgentOps 企业级多智能体贵金属交易分析平台 展示方式:保留原有项目架构图,同时加入系统真实页面切片,用“设计图 实物图”的方式完整展示项目。1. 项目一句话介绍OpenClaw-AgentOps 是一个面向贵金属交易研究…...
)
Jetson Nano玩家必看:Windows下用Diskpart彻底格式化SD卡(解决烧录后不识别问题)
Jetson Nano玩家必备技能:Windows下彻底格式化SD卡的终极指南 当你兴奋地将Linux系统镜像烧录到SD卡,准备在Jetson Nano上大展拳脚时,却发现Windows资源管理器里那张卡"消失"了——这不是灵异事件,而是分区表变化导致的…...

Hugging Face Tokenizer的padding、truncation参数详解:如何让你的BERT/RoBERTa输入不出错?
Hugging Face Tokenizer的padding与truncation实战指南:BERT输入处理的深度解析 当你第一次将文本输入BERT模型时,是否遇到过这样的报错:"RuntimeError: The size of tensor a (512) must match the size of tensor b (128)"&#…...

终极M3U8视频下载神器:3步搞定加密流媒体!
终极M3U8视频下载神器:3步搞定加密流媒体! 【免费下载链接】m3u8-downloader 一个M3U8 视频下载(M3U8 downloader)工具。跨平台: 提供windows、linux、mac三大平台可执行文件,方便直接使用。 项目地址: https://gitcode.com/gh_mirrors/m3u8d/m3u8-do…...

从0到1搭建AI心理健康预警系统:我是如何用BERT+BiLSTM捕捉情绪拐点的
一、 痛点:为什么通用大模型干不了这活?首先声明,我们不是大模型黑。但在心理预警这个场景下,直接用GPT-4或者文心一言的API,有三个致命伤:成本炸裂: 每天几万条的学生/员工咨询日志ÿ…...

第一章-04-路径参数_Path类型注解
1.路径参数出现在什么位置URL 路径的一部分 /book/{id}2.如何为路径参数添加类型注解Python 原生注解 和 Path 注解3.练习需求:定义两个接口,携带路径参数,并使用 Path 来实现类型注解 具体如下: 接口1:以 新闻分类 …...

从warmup_csaw_2016看栈溢出利用的本质:绕过NX/ASLR?不,这次我们先学‘计算’
从warmup_csaw_2016看栈溢出利用的本质:计算的艺术 在二进制安全领域,栈溢出常被初学者视为"魔法攻击"——只需覆盖返回地址就能获得控制权。但当我们剥开NX/ASLR等现代保护机制的外衣,会发现精确计算才是漏洞利用的永恒核心。2016…...

JavaScript逆向工程的架构演进:Jsxer如何重新定义二进制脚本反编译
JavaScript逆向工程的架构演进:Jsxer如何重新定义二进制脚本反编译 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer 在Adobe创意生态系统中,ExtendScript脚本的JSXBIN二进制格…...
引发的音素错位故障)
ElevenLabs旁遮普语TTS突然失真?3步定位Gurmukhi Unicode变体(U+0A02/U+0A3C/U+0A4D)引发的音素错位故障
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs旁遮普文语音合成异常现象综述 ElevenLabs 目前官方文档明确标注支持旁遮普语(Gurmukhi script, language code: pa),但在实际调用其 REST API 进行语音合…...