基于Spark对消费者行为数据进行数据分析开发案例
原创/朱季谦

本文适合入门Spark RDD的计算处理。
在日常工作当中,经常遇到基于Spark去读取存储在HDFS中的批量文件数据进行统计分析的案例,这些文件一般以csv或者txt文件格式存在。例如,存在这样一份消费者行为数据,字段包括消费者姓名,年龄,性别,月薪,消费偏好,消费领域,购物平台,支付方式,单次购买商品数量,优惠券获取情况,购物动机。
基于这份消费者行为数据,往往会有以下一些分析目标:
- 用户统计学分析:针对性别、年龄等属性进行统计分析,了解消费者群体的组成和特征。
- 收入与购买行为的关系分析:通过比较月薪和单次购买商品数量之间的关系,探索收入水平对消费行为的影响。
- 消费偏好和消费领域的分析:查看不同消费者的消费偏好(例如性价比、功能性、时尚潮流等)和消费领域(例如家居用品、汽车配件、美妆护肤等),以了解他们的兴趣和偏好。
- 购物平台和支付方式的分析:研究购物平台(例如天猫、淘宝、拼多多等)和支付方式(例如微信支付、支付宝等)的选择情况,了解消费者在电商平台上的偏好。
- 优惠券获取情况和购物动机的关系:观察优惠券获取情况和购物动机之间的联系,探索消费者是否更倾向于使用优惠券进行购物。
针对这些需求,就可以使用Spark来读取文件后,进一步分析处理统计。
接下来,就是针对以上分析目标,设计一番Spark代码计算逻辑,由此可入门学习下Spark RDD常用用法。
获取一份具备以下字段的csv随机假样本,总共5246条数据,包括“消费者姓名,年龄,性别,月薪,消费偏好,消费领域,购物平台,支付方式,单次购买商品数量,优惠券获取情况,购物动机”。
Amy Harris,39,男,18561,性价比,家居用品,天猫,微信支付,10,折扣优惠,品牌忠诚
Lori Willis,33,女,14071,功能性,家居用品,苏宁易购,货到付款,1,折扣优惠,日常使用
Jim Williams,61,男,14145,时尚潮流,汽车配件,淘宝,微信支付,3,免费赠品,礼物赠送
Anthony Perez,19,女,11587,时尚潮流,珠宝首饰,拼多多,支付宝,5,免费赠品,商品推荐
......
将样本存放到项目目录为src/main/resources/consumerdata.csv,然后新建一个Scala的object类,创建一个main方法, 模拟从HDSF读取数据,然后通过.map(_.split(","))将csv文件每一行切割成一个数组形式的RDD
def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("consumer")val ss = SparkSession.builder().config(conf).getOrCreate()val filePath: String = "src/main/resources/consumerdata.csv"val consumerRDD = ss.sparkContext.textFile(filePath).map(_.split(","))
可以写一段代码打印看一下consumerRDD结构——
consumerRDD.foreach(x => {x.foreach(y => print(y +" "))println()})
打印结果如下——

这个RDD相当于把每一行当作里一个Array[]数组,第一行的Array0是消费者姓名,即Amy Harris,Array1是年龄,即39,以此类推。
| 消费者姓名 | 年龄 | 性别 | 月薪 | 消费偏好 | 消费领域 | 购物平台 | 支付方式 | 单次购买商品数量 | 优惠券获取情况 | 购物动机 |
|---|---|---|---|---|---|---|---|---|---|---|
| Amy Harris | 39 | 男 | 18561 | 性价比 | 家居用品 | 天猫 | 微信支付 | 10 | 折扣优惠 | 品牌忠诚 |
| Lori Willis | 33 | 女 | 14071 | 功能性 | 家居用品 | 苏宁易购 | 货到付款 | 1 | 折扣优惠 | 日常使用 |
| 。。。 |
获取到该RDD后,就可以进行下一步的统计分析了。
一、统计消费者支付方式偏好分布
这行代码意思,x.apply(7)表示取每一行的第八个字段,相当数组Array[7],第八个字段是【支付方式】。
- map(x=>(x.apply(7),1))表示是对RDD里每一行出现过的支付方式字段设置为1个,例如,第一行把原本数组格式Array的RDD做了转换,生成(微信支付,1)格式的新RDD,表示用微信支付的用户出现了1次。
- reduceByKey(_ + _)表示按RDD的key进行聚合统计,表示统计微信支付出现的次数,支付宝出现的次数等。最后,通过
- sortBy(_._2,false)表示按照key-value当中的value进行倒序排序,false表示倒叙,true表示升序。
因此就可以按照以上格式,对文本数据里的每一个字段做相应分析,后文其他计算逻辑也是类似。
consumerRDD.map(x => (x.apply(7),1)).reduceByKey(_ + _).sortBy(_._2, false).foreach(println)
打印结果如下:

二、统计购物平台偏好分布
x.apply(5)表示取每一行的第六个字段,相当数组Array[5],第六个字段是【购物平台】。
同前文的【统计消费者支付方式偏好分布】一样,通过map(x=>(x.apply(5),1))生成(购物平台,1)格式的RDD,然后再通过reduceByKey算子针对相同的key做统计,最后倒序排序。
consumerRDD.map(x => (x.apply(5), 1)).reduceByKey(_ + _).sortBy(_._2, false).foreach(println)
打印结果——

三、统计购物偏好方式分布
x.apply(4)表示取每一行的第五个字段,相当数组Array[4],第五个字段是【消费领域】。
consumerRDD.map(x => (x.apply(4), 1)).reduceByKey(_ + _).sortBy(_._2, false).foreach(println)
打印结果:

四、统计购物动机分布
x.apply(10)表示取每一行的第十个字段,相当数组Array[10],第10个字段是【购物动机】。
consumerRDD.map(x => (x.apply(10), 1)).reduceByKey(_ + _).sortBy(_._2, false).foreach(println)
打印结果——

五、消费者年龄分布
该需求通过将RDD映射成DataFrame数据集,方便用SQL语法处理,按照年龄区间分区,分别为"0-20","21-30","31-40"
......这个分区字符串名,就相当key,value表示落在该分区的用户数量。这时,就可以分组做聚合统计了,统计出各个年龄段的消费者数量。
//取出consumerRDD每一行数组需要的字段
val rowRDD = consumerRDD.map{x => Row(x.apply(0),x.apply(1).toInt,x.apply(2),x.apply(3).toInt,x.apply(4),x.apply(5),x.apply(6),x.apply(7),x.apply(8).toInt,x.apply(9),x.apply(10))
}//设置字段映射
val schema = StructType(Seq(StructField("consumerName", StringType),StructField("age", IntegerType),StructField("gender", StringType),StructField("monthlyIncome", IntegerType),StructField("consumptionPreference", StringType),StructField("consumptionArea", StringType),StructField("shoppingPlatform", StringType),StructField("paymentMethod", StringType),StructField("quantityOfItemsPurchased", IntegerType),StructField("couponAcquisitionStatus", StringType),StructField("shoppingMotivation", StringType)))
val df = ss.createDataFrame(rowRDD, schema).toDF()
//按年龄分布计算
val agedf = df.withColumn("age_range",when(col("age").between(0, 20), "0-20").when(col("age").between(21, 30), "21-30").when(col("age").between(31, 40), "31-40").when(col("age").between(41, 50), "41-50").when(col("age").between(51, 60), "51-60").when(col("age").between(61, 70), "61-70").when(col("age").between(81, 90), "81-90").when(col("age").between(91, 100), "91-100").otherwise("Unknow")
)
//分组统计
val result = agedf.groupBy("age_range").agg(count("consumerName").alias("Count")).sort(desc("Count"))
result.show()
打印结果:

六、统计年龄分布
类似年龄分布的操作。
val sexResult = agedf.groupBy("gender").agg(count("consumerName").alias("Count")).sort(desc("Count"))
sexResult.show()
打印结果:

除了以上的统计分析案例之外,还有优惠券获取情况和购物动机的关系、消费领域方式等统计,可以进一步拓展分析。
本文基于分析消费者行为数据,可以入门学习到,Spark如何读取样本文件,通过map(_.split(","))处理样本成一个数组格式的RDD,基于该RDD,可以进一步通过map、reduceByKey、groupBy等算子做处理与统计,最后获取该样本的信息价值。
相关文章:
基于Spark对消费者行为数据进行数据分析开发案例
原创/朱季谦 本文适合入门Spark RDD的计算处理。 在日常工作当中,经常遇到基于Spark去读取存储在HDFS中的批量文件数据进行统计分析的案例,这些文件一般以csv或者txt文件格式存在。例如,存在这样一份消费者行为数据,字段包括消费…...

Docker镜像制作与推送
目录 Docker镜像制作 搭建私服 将本地镜像推送到私有库 Docker镜像制作 以创建一个新ubuntu镜像,并安装vim命令示例 运行一个ubuntu镜像,发现在镜像里面无法使用vim命令,因为该ubuntu镜像只包括了其最基本的内核命令 [rootlocalhost ~]…...
Pandas时序数据分析实践—基础(1)
目录 1. Pandas基本结构2. Pandas数据类型2.1. 类型概述2.1.1. 整数类型(int):2.1.2. 浮点数类型(float):2.1.3. 布尔类型(bool):2.1.4. 字符串类型(object&a…...
5.C转python
新始: 13.列表可被改变(数据),元组不可被改变(数据),二者皆与C中的数组的大致相同 14.创建列表方法: 1.一个[ ]就是一个空的列表 2.使用list函数来创建列表 如: 15.可以在[ ]内部指定列表的初始值,打印方法: 如: 16.在python中,在同一个列表中,可以放不同类型的变量(也可…...

输出SearchFacesResponse对象的JSON格式字符串回包乱码解决方案
输出SearchFacesResponse对象的JSON格式字符串设置响应内容类型为"application/json;charsetutf-8"获取响应的字符输出流将SearchFacesResponse对象转化为JSON字符串并输出。 代码片段 System.out.println(SearchFacesResponse.toJsonString(resp)); response.setC…...

P7 链表 链表头前方插入新节点
目录 前言 01 链表头插入数据 示例代码 02 指定节点前方插入新节点 测试代码 前言 🎬 个人主页:ChenPi 🐻推荐专栏1: 《C》✨✨✨ 🔥 推荐专栏2: 《 Linux C应用编程(概念类)_ChenPi的博客-CSDN博客》✨…...

SCAU:主对角线上的元素之和
主对角线上的元素之和 Time Limit:1000MS Memory Limit:65535K 题型: 编程题 语言: G;GCC 描述 输入一个3行4列的整数矩阵,计算并输出主对角线上的元素之和输入格式 3行4列整数矩阵输出格式 主对角线上的元素之和输入样例 1 2 3 4 5 6 7 8 9 10 11 12输出…...

c语言——简单客户端demo
以下是一个简单的C语言客户端示例,用于连接到服务器并发送和接收数据: #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <arpa/inet.h> #include <unistd.h…...

日志检索场景ES->Doris迁移最佳实践:函数篇
函数列表 函数:term函数功能说明:查询某个字段里含有某个关键词的文档参数说明:返回值说明:ES使用示例: {"query": {"term": {"title": "blog"}} }Doris使用示例…...

【高效开发工具系列】jackson入门使用
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
深入理解网络非阻塞 I/O:NIO
🔭 嗨,您好 👋 我是 vnjohn,在互联网企业担任 Java 开发,CSDN 优质创作者 📖 推荐专栏:Spring、MySQL、Nacos、Java,后续其他专栏会持续优化更新迭代 🌲文章所在专栏&…...

Hdoop学习笔记(HDP)-Part.07 安装MySQL
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...
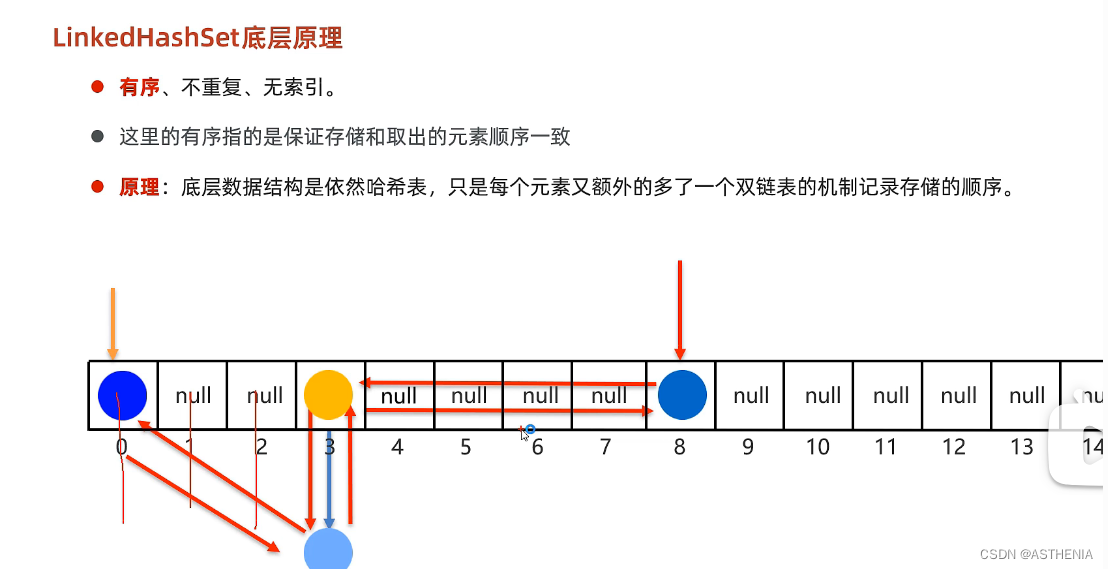
[数据结构]HashSet与LinkedHashSet的底层原理学习心得
我们区分list和set集合的标准是三个:有无顺序,可否重复,有无索引。 list的答案是:有顺序,可重复,有索引。这也就是ArrayList和LinkedList的共性 set的答案是:顺序内部再区分,不可以重复…...

使用unity开发Pico程序,场景中锯齿问题
1、问题 使用unity【非HDR】开发Pico程序,场景中锯齿问题,设置了unity的抗锯齿和渲染方式,及悬挂抗锯齿的脚本,都不能很好的解决项目中图片、文字的锯齿问题,通过摸索找到了妥善的方法 1、修改项目中图片的 GenerateMIpMaps 为勾…...

Spring | Spring的基本应用
目录: 1.什么是Spring?2.Spring框架的优点3.Spring的体系结构 (重点★★★) :3.1 Core Container (核心容器) ★★★Beans模块 (★★★) : BeanFactoryCore核心模块 (★★★) : IOCContext上下文模块 (★★★) : ApplicationContextContext-support模块 (★★★)SpE…...
)
项目开发维护技术文档(梳理总结中)
目录 项目名称——惠誉灵境 一、项目背景 二、架构设计 1.技术栈 2.架构图 3.代码结构 三、模块划分 1.平台首页 2.登录模块 3.系统模块 (1)系统首页 (2)组织架构 (3)权限管控 ①角色管理 (4&am…...
【接口测试】Apifox实用技巧干货分享
前言 不知道有多少人和我有着这样相似的经历:从写程序只要不报错就不测试😊,到写了程序若是有bug就debug甚至写单元测试,然后到了真实开发场景,大哥和你说,你负责的功能模块的所有接口写完要测试一遍无误在…...
_消息平台的搭建)
车联网架构设计(一)_消息平台的搭建
车联网是物联网的一个主要应用方向,车辆通过连接车联网平台,实时进行消息的交互,平台可以提供车辆远程控制,故障检测,车路协同等各方面的功能。 我在车联网行业从事了很长时间的技术工作,参与了整个车联网…...

(蓝桥杯)1125 第 4 场算法双周赛题解+AC代码(c++/java)
题目一:验题人的生日【算法赛】 验题人的生日【算法赛】 - 蓝桥云课 (lanqiao.cn) 思路: 1.又是偶数,又是质数,那么只有2喽 AC_Code:C #include <iostream> using namespace std; int main() {cout<<2;return 0; …...
也可Adobe Animate
Animate CC 由原Adobe Flash Professional CC 更名得来,2015年12月2日:Adobe 宣布Flash Professional更名为Animate CC,在支持Flash SWF文件的基础上,加入了对HTML5的支持。并在2016年1月份发布新版本的时候,正式更名为…...

极简黑魔法:用 gh gist 搭建我们的私有配置分发 CDN
在多端协作的时代,我们经常需要在 PC、手机和路由器之间同步一些私密的订阅配置(如应用服务配置文件,凭据等)。 如果使用公共 Gist 会有隐私泄露风险;维护一个私有 Git 仓库又需要处理复杂的 API Token 鉴权࿰…...

Live Server深度解析:如何用实时重载技术提升前端开发效率300%
Live Server深度解析:如何用实时重载技术提升前端开发效率300% 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-se…...

解放CPU!用STM32G4的FMAC硬核加速器做实时滤波,代码实测与性能对比
解放CPU!用STM32G4的FMAC硬核加速器做实时滤波,代码实测与性能对比 在嵌入式系统中,实时信号处理一直是工程师面临的挑战之一。无论是电机控制中的电流采样,还是环境监测中的传感器数据采集,滤波算法往往是不可或缺的一…...
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题 计算机视觉领域正经历一场由Transformer架构引领的革命。从最初的图像分类任务到如今的复杂场景理解,Transformer以其强大的全局建模能力不断刷新着各项基准。而在天气…...

MySQL复合查询与内外连接
1:笛卡尔积1:什么是笛卡尔积笛卡尔积就是两张表所有记录的所有可能组合。举个最简单的例子:表 A 有 2 条记录:[苹果,香蕉]表 B 有 3 条记录:[红色,黄色,绿色]它们的笛卡尔积就是 236…...

MacType终极指南:彻底解决Windows字体模糊问题的免费神器
MacType终极指南:彻底解决Windows字体模糊问题的免费神器 【免费下载链接】mactype Better font rendering for Windows. 项目地址: https://gitcode.com/gh_mirrors/ma/mactype 你是否厌倦了Windows系统上模糊不清的字体显示?长期面对锯齿边缘的…...

合并报表的10个基本逻辑原理,0基础也能看懂
合并报表真正的门槛不在分录,而在思维方式。单体报表做久了,容易不自觉地站在一家公司的视角去看业务,但合并报表要求你立刻跳出来,用一个“虚构的大集团”的眼睛去重新审视所有交易。这种视角切换,往往比具体的抵销技…...

如何用NHSE动物森友会存档编辑器快速打造梦想岛屿:终极完整指南
如何用NHSE动物森友会存档编辑器快速打造梦想岛屿:终极完整指南 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》中收集稀有物品而烦恼吗&#…...

5个关键场景掌握openpilot:开源自动驾驶系统的实战指南
5个关键场景掌握openpilot:开源自动驾驶系统的实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trendi…...

Midjourney v7艺术风格跃迁路径:从基础写实到超现实叙事的5阶能力模型,含GPT-4o协同提示链模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney v7艺术风格跃迁路径总览 Midjourney v7 并非简单迭代,而是以扩散模型架构重构与多模态风格理解为内核的范式跃迁。其核心突破在于引入「语义风格锚点(Semantic Style…...