Python的正则表达式使用
Python的正则表达式使用
- 定义
- 使用场景
- 查
- 替换
- 分割
- 常用的正则表达符号
- 查原字符
- 英文状态的句号点 .
- 反斜杠 \
- 英文的[]
- 英文的()
- 英文的?
- 加号 +
- 星号 *
- 英文状态的大括号 {}
- 案例
定义
正则表达式是指专门用于描述或刻画字符串内在规律的表达式。
使用场景
无法通过切片,将字符串的子串返回。
借助于replace方法,无法完成非固定值或非固定位置值的替换。
借助于split方法,无法按照多种值实现字符串的分割。
查
findall(pattern, string, flags=0)
pattern:指定需要匹配的正则表达式。
string:指定待处理的字符串。
flags:指定匹配模式,常用的值可以是re.I、re.M、re.S和re.X。re.I的模式是让正则表达式对大小写不敏感;re.M的模式是让正则表达式可以多行匹配;re.S的模式指明正则符号,即可以匹配任意字符,包括换行符\n;re.X模式允许正则表达式可以写得更加详细,如多行表示、忽略空白字符、加入注释等。
替换
sub(pattern, repl, string, count=0, flags=0)
pattern:同findall函数中的pattern。
repl:指定替换成的新值。
string:同findall函数中的string。
count:用于指定最多替换的次数,默认为全部替换。
flags:同findall函数中的flags。
分割
split(pattern, string, maxsplit=0, flags=0)
pattern:同findall函数中的pattern。
maxsplit:用于指定最大分割次数,默认为全部分割。
string:同findall函数中的string。
flags:同findall函数中的flags。
常用的正则表达符号
使用这些函数,需要导入re功能包
查原字符
指代直接存在于字符串内部的子串。
# 导入第三方包
import re
# 提取出字符串中的Python子串
s1 = '看了博主的Python的文章,感觉Python很简单,学会了!'
out1 = re.findall('Python', s1)
print(out1)
输出:
[‘Python’, ‘Python’]
英文状态的句号点 .
英文的:‘.’ 指代任意字符(如数字、字母、标点符号、汉字等),但除了换行符\n。
# 导入第三方包
import re
# 提取出动力的值
s2 = '此次宝马主要搭载了1.5L和1.5T两种动力的发动机。凯迪拉克则搭载了1.0T和1.8T的动力。'
out2 = re.findall('1...',s2)
out3 = re.findall('1\...',s2) # \. 代表小数点(转义一下)
print(out2)
print(out3)
[‘1.5L’, ‘1.5T’, ‘1.0T’, ‘1.8T’]
[‘1.5L’, ‘1.5T’, ‘1.0T’, ‘1.8T’]
反斜杠 \
反斜杠 \ 表示转义符,用于转换含义的符号。
\n:指代换行;
\t:指代Tab制表符;
\d:指代0~9中的任一数字;
\s:指代任意一种空白(如空格、Tab、换行等);
\w:指代字母、数字和下划线中的任意一种;(52:大小字 + 10:数字0-9 + 1下划线 = 63种)
. :指代句号点本身;
若是想打 \ 则用\\
# 导入第三方包
import re
# 剔除字符串中的所有空白
s3 = ('距离2019北京马拉松开跑只有两周时间了,\n今年的北京马拉松预报名人数超过16万人,\t 媒体公布的中签率只有16%左右,再创历年来的新低。\n')
print(s3)
out4 = re.sub('\s','',s3)
print(out4)
输出:
距离2019北京马拉松开跑只有两周时间了,
今年的北京马拉松预报名人数超过16万人,(这有个tab长度) 媒体公布的中签率只有16%左右,再创历年来的新低。
(这有个空白行)
距离2019北京马拉松开跑只有两周时间了,今年的北京马拉松预报名人数超过16万人,媒体公布的中签率只有16%左右,再创历年来的新低。
英文的[]
指代字符集合,当需要特定字符匹配时,可以选择中括号。
# 导入第三方包
import re
# 取出手机号信息
s4 = '用户联系方式:13612345566,用户编号为11011254321'
out5 = re.findall('1[356789]\d\d\d\d\d\d\d\d\d', s4) # 第二位为356789中的一个
print(out5)
# 提取出动力
s5 = '通过对比新朗逸1.5L和1.5T两种动力在1.5年行驶期后的数据。发现1.5T的口碑相对较好!'
out6 = re.findall('1.5[a-zA-Z]',s5) # 取出a-z或A-Z
print(out6)
# 或
out7 = re.findall('1.5[TL]',s5) # 取出a-z或A-Z
print(out7)
输出:
[‘13612345566’]
[‘1.5L’, ‘1.5T’, ‘1.5T’]
[‘1.5L’, ‘1.5T’, ‘1.5T’]
英文的()
指代特定内容的截取(抠)。
# 导入第三方包
import re
# 提取出用户的年龄
s6 = 'id:1, name:Tom, age:3, gender:1; id:2, name:Lily, age:5, gender:0'
print(re.findall('\d',s6))
print(re.findall('age:\d',s6))
print(re.findall('age:(\d)',s6))
输出:
[‘1’, ‘3’, ‘1’, ‘2’, ‘5’, ‘0’]
[‘age:3’, ‘age:5’]
[‘3’, ‘5’]
英文的?
表示匹配前一个字符匹配,0次或1次。
# 超链接的匹配
URL1 = 'https://www.baidu.com/'
URL2 = 'http://www.gov.cn/'
pattern = 'https?://www\..*?'
这样https和http都能匹配上了。
加号 +
表示匹配前一个字符匹配,1次及以上。
# 邮箱地址的匹配
email1 = 'Lsxxx2011@163.com'
email2 = '654088115@qq.com'
pattern = '[0-9a-zA-Z_\.\-]+@[a-zA-Z0-9_\-]+\.com'
星号 *
表示匹配前一个字符0次及以上。
# 提取出产品名称中含奶粉字样的产品
prod = ['婴儿袜', '亨氏奶粉', '奶粉勺', '多功能奶瓶', '幼儿奶粉量筒', '磨牙棒']
res = []
for i in prod:res.extend(re.findall('.*奶粉.*', i))
print(res)
输出:
[‘亨氏奶粉’, ‘奶粉勺’, ‘幼儿奶粉量筒’]
英文状态的大括号 {}
表示匹配前一个字符特定的次数或范围。
{m}:匹配前一个字符m次;
{m,}:匹配前一个字符至少m次;
{m,n}:匹配前一个字符m~n次;
{,n} :匹配前一个字符之多n次;
# 手机号码的匹配
pattern = '1[356789]\d{9}'
# 至少6个长度的密码
pattern = '\w{6,}'
# 区号信息
pattern = '0\d{2,3}'
案例
# 导入用于正则表达式的re模块
import re
# 取出字符中所有的天气状态
string1 = "{ymd:'2018-01-01',tianqi:'晴',aqiInfo:'轻度污染'},{ymd:'2018-01-02',tianqi:'阴~小雨',aqiInfo:'优'},{ymd:'2018-01-03',tianqi:'小雨~中雨',aqiInfo:'优'},{ymd:'2018-01-04',tianqi:'中雨~小雨',aqiInfo:'优'}"
print(re.findall("tianqi:'(.*?)'", string1)) # ?为了防止盲目匹配(非贪婪式)
输出:
[‘晴’, ‘阴~小雨’, ‘小雨~中雨’, ‘中雨~小雨’]
# 导入用于正则表达式的re模块
import re
# 取出所有含O字母的单词
string2 = 'Together, we discovered that a free market only thrives when there are rules to ensure competition and fair play, Our celebration of initiative and enterprise'
print(re.findall('\w*o\w*',string2, flags = re.I)) # re.I大小写不敏感
# 将标点符号、数字和字母删除
string3 = '据悉,这次发运的4台蒸汽冷凝罐属于国际热核聚变实验堆(ITER)项目的核二级压力设备,先后完成了压力试验、真空试验、氦气检漏试验、千斤顶试验、吊耳载荷试验、叠装试验等验收试验。'
print(re.sub('[,。、a-zA-Z0-9()]','',string3))
输出:
[‘Together’, ‘discovered’, ‘only’, ‘to’, ‘competition’, ‘Our’, ‘celebration’, ‘of’]
据悉这次发运的台蒸汽冷凝罐属于国际热核聚变实验堆项目的核二级压力设备先后完成了压力试验真空试验氦气检漏试验千斤顶试验吊耳载荷试验叠装试验等验收试验
# 导入用于正则表达式的re模块
import re
# 将每一部分的内容分割开
string4 = '2室2厅 | 101.62平 | 低区/7层 | 朝南 \n 上海未来 - 浦东 - 金杨 - 2005年建'
split = re.split('[-\|\n]', string4) # \|转义下表示竖杠本身,split函数是用来分割的
print(split)
split_strip = [i.strip() for i in split] # 循环列表去除前后的空格
print(split_strip)
输出:
['2室2厅 ', ’ 101.62平 ', ’ 低区/7层 ', ’ 朝南 ', ’ 上海未来 ', ’ 浦东 ', ’ 金杨 ‘, ’ 2005年建’]
[‘2室2厅’, ‘101.62平’, ‘低区/7层’, ‘朝南’, ‘上海未来’, ‘浦东’, ‘金杨’, ‘2005年建’]
相关文章:

Python的正则表达式使用
Python的正则表达式使用 定义使用场景查替换分割 常用的正则表达符号查原字符英文状态的句号点 .反斜杠 \英文的[]英文的()英文的?加号 星号 *英文状态的大括号 {} 案例 定义 正则表达式是指专门用于描述或刻画字符串内在规律的表达式。 使用场景 无法通过切片,…...
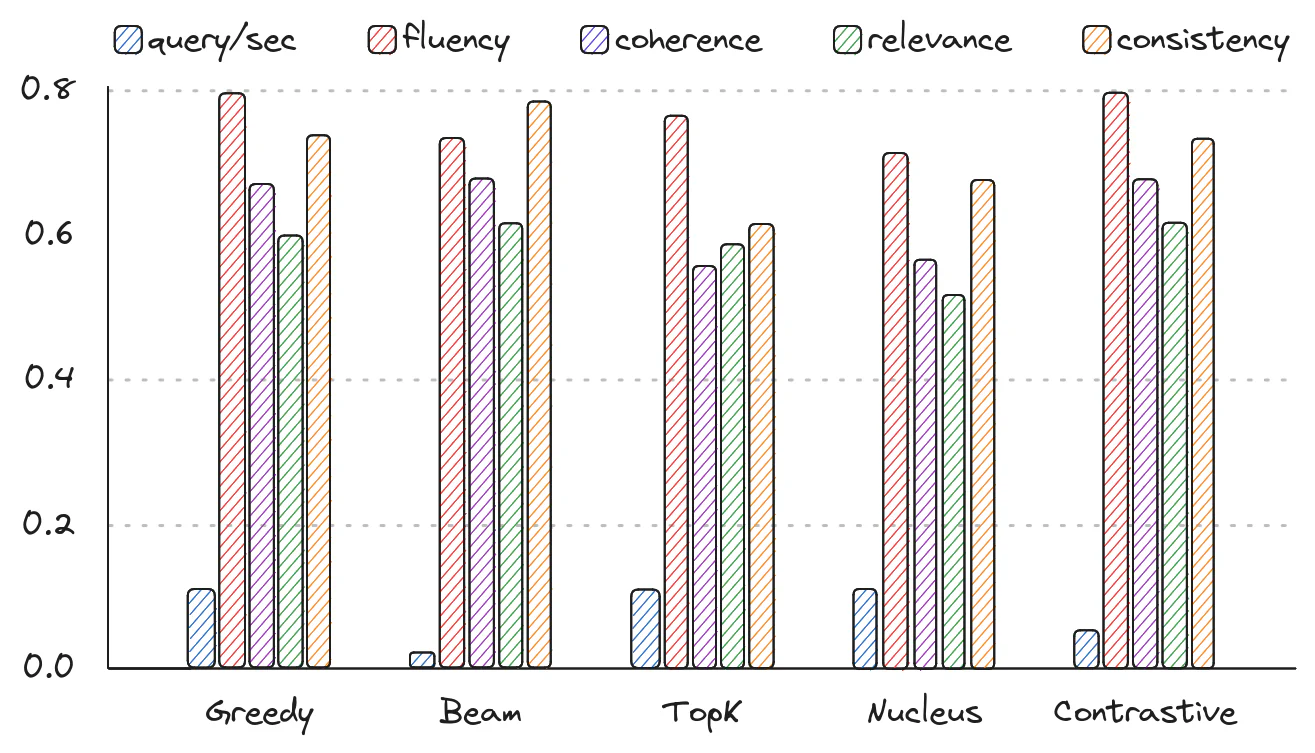
Elasticsearch:评估 RAG - 指标之旅
作者:Quentin Herreros,Thomas Veasey,Thanos Papaoikonomou 2020年,Meta发表了一篇题为 “知识密集型NLP任务的检索增强生成” 的论文。 本文介绍了一种通过利用外部数据库将语言模型 (LLM) 知识扩展到初始训练数据之外的方法。 …...

【2023.12.4练习】数据库知识点复习测试
概论 数据表:用于存储现实中数据的联系。 储存信息联系。 字段:又称列,如姓名、年龄、编号等。 记录:又称元组,为数据表中的一行,代表了一个实体的信息。 数据库(DB)࿱…...
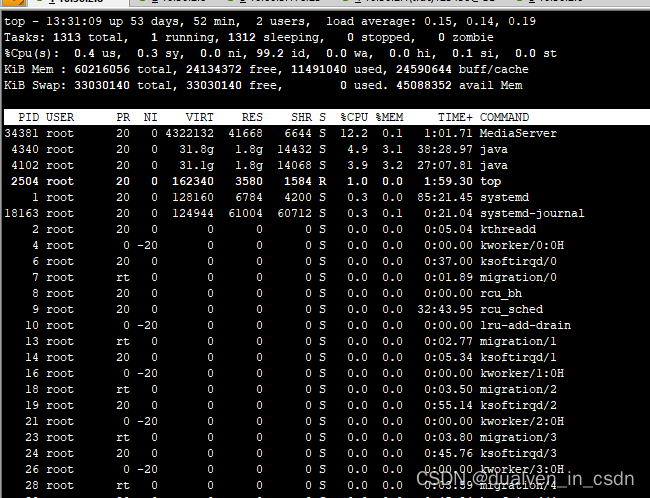
【wvp】测试记录
ffmpeg 这是个莫名其妙的报错,通过排查,应该是zlm哪个进程引起的 会议室的性能 网络IO也就20M...
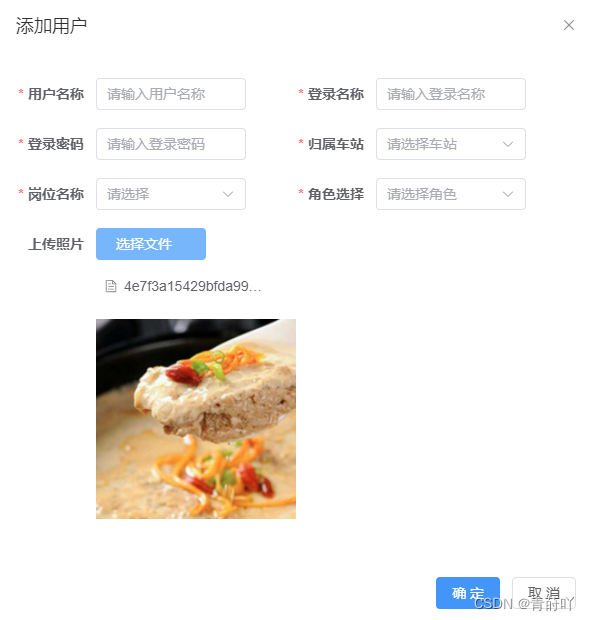
【若依框架实现上传文件组件】
若依框架中只有个人中心有上传图片组件,但是这个组件不适用于el-dialog中的el-form表单页面 于是通过elementui重新写了一个上传组件,如图是实现效果 vue代码 <el-dialog :title"title" v-model"find" width"600px"…...

玩转大数据5:构建可扩展的大数据架构
1. 引言 随着数字化时代的到来,大数据已经成为企业、组织和个人关注的焦点。大数据架构作为大数据应用的核心组成部分,对于企业的数字化转型和信息化建设至关重要。我们将探讨大数据架构的基本要素和原则,以及Java在大数据架构中的角色&…...

【华为数据之道学习笔记】非数字原生企业的特点
非数字原生企业的数字化转型挑战 软件和数据平台为核心的数字世界入口,便捷地获取和存储了大量的数据,并开始尝试通过机器学习等人工智能技术分析这些数据,以便更好地理解用户需求,增强数字化创新能力。部分数字原生企业引领着云计…...

Kubernetes学习笔记-Part.01 Kubernets与docker
目录 Part.01 Kubernets与docker Part.02 Docker版本 Part.03 Kubernetes原理 Part.04 资源规划 Part.05 基础环境准备 Part.06 Docker安装 Part.07 Harbor搭建 Part.08 K8s环境安装 Part.09 K8s集群构建 Part.10 容器回退 第一章 Kubernets与docker Docker是一种轻量级的容器…...

k8s学习
文章目录 前言一、k8s部署方式二、学习k8s的方式今天主要配置k8s环境的方式今天遇到的是一个在k8s进行初始化的方式,但是发现k8s不能正常初始化总是出现错误,或者在错误中有问题的方式,在网上查询挺多资料需要重新启动kub文件,删除…...

测试:JMeter和LoadRunner比较
比较 JMeter和LoadRunner是两款常用的软件性能测试工具,它们在功能和性能上有一定的相似性和差异。下面从几个方面对它们进行比较: 1. 架构和原理: JMeter和LoadRunner的架构和原理基本相同,都是通过中间代理监控和收集并发客户…...
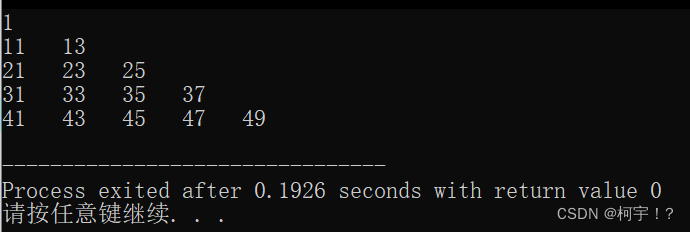
(C语言)通过循环按行顺序为一个矩阵赋予1,3,5,7,9,等奇数,然后输出矩阵左下角的值。
#include<stdio.h> int main() {int a[5][5];int n 1;for(int i 0;i < 5;i ){for(int j 0;j < 5;j ){a[i][j] n;n 2;}}for(int i 0;i < 5;i ){for(int j 0;j < i;j )printf("%-5d",a[i][j]);printf("\n");}return 0; } 运行截图…...
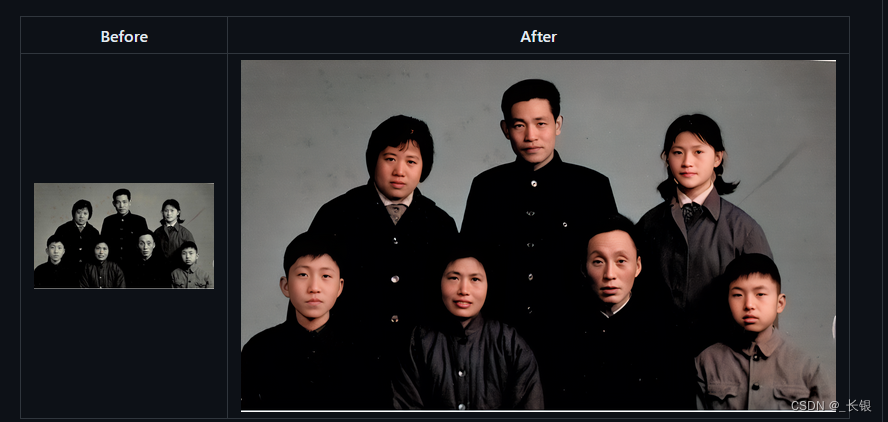
GitHub项目推荐-Deoldify
有小伙伴推荐了一个老照片上色的GitHub项目,看了简介,还不错,推荐给大家。 项目地址 GitHub - SpenserCai/sd-webui-deoldify: DeOldify for Stable Diffusion WebUI:This is an extension for StableDiffusions AUTOMATIC1111 w…...

微前端qiankun示例 Umi3.5
主应用配置(基座) 安装包 npm i umijs/plugin-qiankun -D 配置 qiankun 开启 {"private": true,"scripts": {"start": "umi dev","build": "umi build","postinstall": "…...
熬夜会秃头——beta冲刺Day7
这个作业属于哪个课程2301-计算机学院-软件工程社区-CSDN社区云这个作业要求在哪里团队作业—beta冲刺事后诸葛亮-CSDN社区这个作业的目标记录beta冲刺Day7团队名称熬夜会秃头团队置顶集合随笔链接熬夜会秃头——Beta冲刺置顶随笔-CSDN社区 一、团队成员会议总结 1、成员工作…...
IntelliJ IDEA设置中文界面
1.下载中文插件 2. 点击重启IDE 3.问题就解决啦!...
RTSP流媒体播放器
rtsp主要还是运用ffmpeg来搭建node后端转发到前端,前端再播放这样的思路。 这里讲的到是用两种方式,一种是ffmpeg设置成全局来实现,一种是ffmpeg放在本地目录用相对路径来引用的方式。 ffmpeg下载地址:http://www.ffmpeg.org/do…...

使用正则表达式时-可能会导致性能下降的情况
目录 前言 正则表达式引擎 NFA自动机的回溯 解决方案 前言 正则表达式是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机&a…...
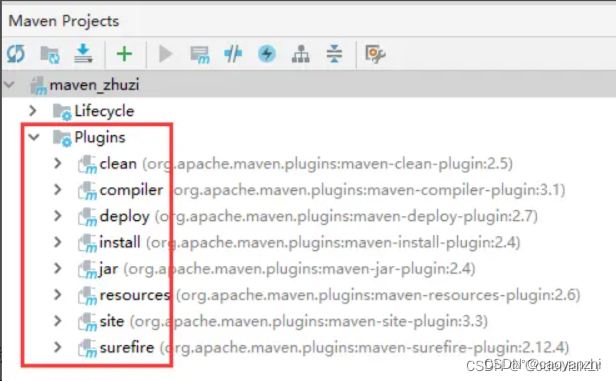
Maven生命周期
Maven生命周期 通过IDEA工具的辅助,能很轻易看见Maven的九种生命周期命令,如下: 双击其中任何一个,都会执行相应的Maven构建动作,为啥IDEA能实现这个功能呢?道理很简单,因为IDEA封装了Maven提供…...

深度学习(五):pytorch迁移学习之resnet50
1.迁移学习 迁移学习是一种机器学习方法,它通过将已经在一个任务上学习到的知识应用到另一个相关任务上,来改善模型的性能。迁移学习可以解决数据不足或标注困难的问题,同时可以加快模型的训练速度。 迁移学习的核心思想是将源领域的知识迁…...

面试官:说说synchronized与ReentrantLock的区别
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...

猫抓插件:让网页资源捕获变得高效简单的浏览器扩展解决方案
猫抓插件:让网页资源捕获变得高效简单的浏览器扩展解决方案 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字时代,我们每天浏览网页时都会遇到各种有价值的媒体资源——可…...

LFM2.5-1.2B-Thinking-GGUF部署指南:ss端口监听+curl health检测标准化运维流程
LFM2.5-1.2B-Thinking-GGUF部署指南:ss端口监听curl health检测标准化运维流程 1. 平台简介 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,特别适合在资源有限的环境中快速部署和使用。这个镜像内置了GGUF模型文件和llama.cpp运行时…...

如何用QuickRecorder解决macOS录屏痛点:高效专业的从入门到精通实践指南
如何用QuickRecorder解决macOS录屏痛点:高效专业的从入门到精通实践指南 【免费下载链接】QuickRecorder A lightweight screen recorder based on ScreenCapture Kit for macOS / 基于 ScreenCapture Kit 的轻量化多功能 macOS 录屏工具 项目地址: https://gitco…...

实测2公里矿用电缆跑网络:用电力载波模块替代光纤,在井下到底靠不靠谱?
井下网络传输技术突围:电力载波在恶劣环境中的实战评估 矿场深处,昏暗潮湿的巷道里,一组工程师正为数据传输问题焦头烂额。传统光纤在煤尘弥漫的环境中频频失效,而工期又迫在眉睫。这时,有人提出了一个大胆的方案——利…...

FOC算法避坑指南:克拉克变换的‘等幅值’与‘等功率’到底选哪个?基于AS5600编码器的实测对比
FOC算法避坑指南:克拉克变换的‘等幅值’与‘等功率’到底选哪个?基于AS5600编码器的实测对比 在无刷电机控制领域,FOC(Field Oriented Control)算法因其优异的动态性能和效率表现,已成为工业驱动和高精度…...

OpenClaw数据安全实践:Qwen3-32B+RTX4090D本地化处理敏感财报
OpenClaw数据安全实践:Qwen3-32BRTX4090D本地化处理敏感财报 1. 为什么金融从业者需要本地化AI处理 去年我在帮一家私募基金做季度财报分析时,遇到了一个尴尬场景:当我把客户PDF财报上传到某公有云AI平台提取关键指标后,第二天就…...

解锁智能导航核心:从基础到进阶的路径规划实践指南
解锁智能导航核心:从基础到进阶的路径规划实践指南 【免费下载链接】PathPlanning Common used path planning algorithms with animations. 项目地址: https://gitcode.com/gh_mirrors/pa/PathPlanning 路径规划算法是机器人导航、自动驾驶和游戏AI等领域的…...

突破软件授权限制:基于注册表权限控制的持久化使用方案——以下载工具为例
突破软件授权限制:基于注册表权限控制的持久化使用方案——以下载工具为例 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 一、场景痛点:…...

OpenClaw技能商店:基于nanobot开发并分享自定义模块
OpenClaw技能商店:基于nanobot开发并分享自定义模块 1. 为什么要开发OpenClaw技能 去年夏天,我发现自己每天要花大量时间处理重复性的文件整理工作——下载各种技术文档,按日期和项目分类存储,再手动生成目录索引。当我第三次在…...

基于 Kinova Gen3 机械臂的家庭人机交互安全算法研究
随着服务机器人逐步进入家庭场景,人机交互(HRI)的安全性成为影响机器人普及的关键因素。相较于工业环境,家庭空间布局多变、人员活动随机,对机械臂的感知、规划与控制提出了更高要求。本文以7自由度Kinova Gen3机械臂为…...