oracle 19c 创建物化视图并测试logminer进行日志挖掘


1、创建物化视图
alter session set container=pdb;
grant create materialized view to scott;
create materialized view 物化视图名 -- 1. 创建物化视图
build [immediate | deferred] -- 2. 创建方式,默认 immediate
refresh [force | fast | complete | never] -- 3. 物化视图刷新方式,默认 force
on [commit | demand] -- 4. 刷新触发方式
start with 开始时间 -- 5. 设置开始时间
next 间隔时间 -- 6. 设置间隔时间
with [primary key | rowid] -- 7. 类型,默认 primary key
[enable | disable] query rewrite -- 8. 是否启用查询重写
as -- 9. 关键字
查询语句; -- 10. select 语句创建语法解释
1. "创建 build" 的方式(1) 'immediate':立即生效,默认。(2) 'deferred' : 延迟至第一次 refresh 时才生效
2. "刷新 refresh" 的方式(1) force :默认。如果可以 '快速刷新' 就 '快速刷新',否则执行 '完全刷新'(2) fast :'快速刷新'。只刷新 '增量' 部分(前提:创建 '物化日志')(3) complete: '完全刷新'。刷新时更新全部数据,包括视图中已经生成的原有数据(4) never : 从不刷新
3. "触发" (请注意,on demand 中,才需要设置 '开始时间' 和 '间隔时间') -- 冲突(1) on commit:基表有 commit 动作时,刷新刷图("不能跨库执行")(2) on demand:在需要时刷新[1] 根据后面设定的 '开始时间' 和 '结束时间' 进行刷新[2] 手动调用 dbms_mview 包中的过程进行刷新
4. 基于基表的 primary key 或 rowid 创建(1) 如果是基于 rowid,则不能对基表执行 '分组函数'、'多表连接' 等需要把多个 rowid 合成一行的操作(理由很简单:到底以哪个 rowid 为准呢?)
5. enable query rewrite 启用查询重写(请注意, '开始时间' 和 '间隔时间' 不支持)-- 冲突(1) 不支持的理由也很简单。所谓的 '重写',就是讲对基表的查询定位到物化视图上,而 '开始时间' 和 '间隔时间' 会造成物化视图上部分数据延迟,所以,不能重写(2) 参数: query_rewrite_enabled (可通过 v$parameter 视图查询)测试延时刷新
scott用户创建表
CREATE TABLE person_info (person_no VARCHAR2(10),NAME VARCHAR2(30),create_date DATE
);
INSERT INTO person_info(person_no, NAME, create_date) VALUES('001', '瑶瑶', SYSDATE);
INSERT INTO person_info(person_no, NAME, create_date) VALUES('002', '倩倩', SYSDATE);
COMMIT;创建1分钟刷新一次物化视图
CREATE MATERIALIZED VIEW mvw_person_info
BUILD IMMEDIATE
REFRESH FORCE
ON DEMAND
START WITH SYSDATE
NEXT SYSDATE + 1/1440
AS
SELECT pi.person_no, pi.name,pi.create_dateFROM person_info pi;测试语句:先查询,等个十几秒再执行insert,再等1分钟左右,观察前后数据
SELECT * FROM mvw_person_info;
INSERT INTO person_info(person_no, NAME, create_date) VALUES('003', '美眉', SYSDATE);
commit;
select * from mvw_person_info;查询物化视图
1. 查询物化视图,非 DBA 用户,请查询 all_mviews 或 user_mviews
SELECT *FROM dba_mviews tWHERE t.owner = 'SCOTT'AND t.mview_name = 'MVW_PERSON_INFO';
2. 查询一般视图
SELECT * FROM dba_views;修改物化视图
alter materialized view 物化视图名
refresh [force | fast | complete | never]
on [commit | demand]
start with 开始时间
next 间隔时间删除物化视图
drop materialized view 物化视图名;手动刷新
BEGINdbms_mview.refresh(list => '视图名',method => 'fast', -- 增量刷新refresh_after_errors => TRUE);
END;
2、创建物化视图日志
1. 适用于 'fast' 增量刷新
2. with primary key
3. with rowid 测试with primary key
CREATE TABLE student_info (
student_no VARCHAR2(10),
NAME VARCHAR2(30)
);
ALTER TABLE student_info ADD CONSTRAINT pk_student_info_student_no
PRIMARY KEY(student_no);创建物化视图日志
create materialized view log on student_info with primary key
[including new values];
-- including new values 允许 Oracle 将数据库 新、旧值都保存在物化视图日志中
-- 即 update 前 和 update 后都保存,按需设置即可插入一条数据
INSERT INTO student_info(student_no, NAME) VALUES('001', '小优子');
UPDATE student_info t SET t.name = '小游子' WHERE t.student_no = '001';
COMMIT;查询物化视图日志信息
SELECT * FROM all_mview_logs;
SELECT * FROM mlog$_student_info;with rowid 测试
创建 'fast' 增量模式的物化视图条件:
(1) select 语句中包含到的每一个表都需要创建 '物化日志'
(2) select 中必须包含涉及到所有表的 'rowid'
(3) select 中必须明确具体的列,不允许使用 '*'创建表
CREATE TABLE test_a (a_id VARCHAR(10),NAME VARCHAR2(30)
);
ALTER TABLE test_a ADD CONSTRAINT pk_test_a_a_id PRIMARY KEY(a_id);
CREATE TABLE test_b (b_id VARCHAR(10),NAME VARCHAR2(30)
);
ALTER TABLE test_b ADD CONSTRAINT pk_test_b_b_id PRIMARY KEY(b_id);创建物化视图日志
create materialized view log on test_a with rowid including new values;
create materialized view log on test_b with rowid including new values;fast增量测试
创建表
CREATE MATERIALIZED VIEW mvw_test_ab
REFRESH FAST WITH ROWID
ON DEMAND
START WITH SYSDATE
NEXT SYSDATE + 3/1440
AS
SELECT t1.a_id,t1.name a_name,t1.rowid a_rowid,t2.b_id,t2.name b_name,t2.rowid b_rowidFROM test_a t1, test_b t2WHERE t1.a_id = t2.b_id;查询此时没有数据
SELECT * FROM mvw_test_ab;
SELECT * FROM all_mview_logs;
SELECT * FROM mlog$_test_a;
SELECT * FROM mlog$_test_b;插入数据
INSERT INTO test_a(a_id, NAME) VALUES('1', 'a1');
INSERT INTO test_a(a_id, NAME) VALUES('2', 'a2');
INSERT INTO test_a(a_id, NAME) VALUES('3', 'a3');
INSERT INTO test_b(b_id, NAME) VALUES('1', 'b1');
INSERT INTO test_b(b_id, NAME) VALUES('2', 'b2');
INSERT INTO test_b(b_id, NAME) VALUES('3', 'b3');
COMMIT;再次查询有数据
SQL> SELECT * FROM mlog$_test_b;M_ROW$$
--------------------------------------------------------------------------------
SNAPTIME$ D O CHANGE_VECTOR$$ XID$$
--------- - - -------------------- ----------
AAASHJAAaAAAAEdAAA
01-JAN-00 I N FE 1.9704E+15AAASHJAAaAAAAEdAAB
01-JAN-00 I N FE 1.9704E+15AAASHJAAaAAAAEdAAC
01-JAN-00 I N FE 1.9704E+15
3、进行日志挖掘
查看当前日志
SQL> select max(SEQUENCE#) from v$archived_log;MAX(SEQUENCE#)
--------------187日志切换
alter system archive log current;安装LogMiner
@$ORACLE_HOME/rdbms/admin/dbmslm.sql
@$ORACLE_HOME/rdbms/admin/dbmslmd.sql这两个脚本必须均以 DBA 用户身份运行。其中第一个脚本用来创建 DBMS_LOGMNR 包,该包用来分析日志文件。第二个脚本用来创建 DBMS_LOGMNR_D 包,该包用来创建数据字典文件。
创建完毕后将包括如下过程和视图:
| 类型 | 过程名 | 用途 |
| 过程 | Dbms_logmnr_d.build | 创建一个数据字典文件 |
| 过程 | Dbms_logmnr.add_logfile | 在类表中增加日志文件以供分析 |
| 过程 | Dbms_logmnr.start_logmnr | 使用一个可选的字典文件和前面确定要分析日志文件来启动 LogMiner |
| 过程 | Dbms_logmnr.end_logmnr | 停止 LogMiner 分析 |
| 视图 | V$logmnr_dictionary | 显示用来决定对象 ID 名称的字典文件的信息 |
| 视图 | V$logmnr_logs | 在 LogMiner 启动时显示分析的日志列表 |
| 视图 | V$logmnr_contents | LogMiner 启动后,可以使用该视图在 SQL 提示符下输入 SQL 语句来查询重做日志的内容 |
创建数据字典文件
LogMiner 工具实际上是由两个新的 PL/SQL 内建包( (DBMS_LOGMNR 和 DBMS_LOGMNR_D)和四个 V$动态性能视图(视图是在利用过程 DBMS_LOGMNR.START_LOGMNR启动 LogMiner 时创建)组成。在使用 LogMiner 工具分析 redo log 文件之前,可以使用DBMS_LOGMNR_D 包将数据字典导出为一个文本文件。该字典文件是可选的,但是如果没有它, LogMiner 解释出来的语句中关于数据字典中的部分(如表名、列名等)和数值都将是 16进制的形式,我们是无法直接理解的。例如,下面的 sql 语句:
INSERT INTO dm_dj_swry (rydm, rymc) VALUES (00005, '张三');
insert into Object#308(col#1, col#2) values (hextoraw('c30rte567e436'),hextoraw('4a6f686e20446f65'));
CREATE DIRECTORY utlfile AS '/home/oracle/LOGMNR';
alter system set utl_file_dir='/home/oracle/LOGMNR' scope=spfile;这个方式放弃等后续问问别人
直接分析方式
exec dbms_logmnr.add_logfile(logfilename => '/home/oracle/arch11/1_189_1106805210.dbf',options=>dbms_logmnr.new);
exec dbms_logmnr.add_logfile(logfilename => '/home/oracle/arch11/1_189_1106805210.dbf',options=>dbms_logmnr.addfile);
exec dbms_logmnr.start_logmnr(options => dbms_logmnr.dict_from_online_catalog);set linesize 200
alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
select timestamp,commit_timestamp,sql_redo from v$logmnr_contents where table_name like '%PER%' and operation='INSERT';查看分析结果如下
2023-02-14 21:56:22
insert into "SCOTT"."PERSON_INFO"("PERSON_NO","NAME","CREATE_DATE") values ('003','hrz',TO_DATE('2023-02-14 21:56:21', 'yyyy-mm-dd hh24:mi:ss'));注意:logmnior最大表字符支持最大30,字段也是字符最大30个
The tables or column names selected for mining must not exceed 30 characters.
相关文章:
oracle 19c 创建物化视图并测试logminer进行日志挖掘
1、创建物化视图 alter session set containerpdb; grant create materialized view to scott; create materialized view 物化视图名 -- 1. 创建物化视图 build [immediate | deferred] -- 2. 创建方式,默认 immediate refre…...
2.1 黑群晖驱动:10代u核显硬解驱动(解决掉IP、重启无法连接问题)
本文提供了两种10代核显驱动方式:1)第一种(本文:二、仅修改i915.ko驱动10代u核显方法)为网上流传最多但是对主板兼容性要求很高,网上评论常会出现操作后无法识别IP(掉IP)的问题。因此,采用第一种…...

二、CSS
一、CSSHTML的结合方式 1、第一种:在标签的style属性上设置"key:value value;",修改标签样式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title>…...
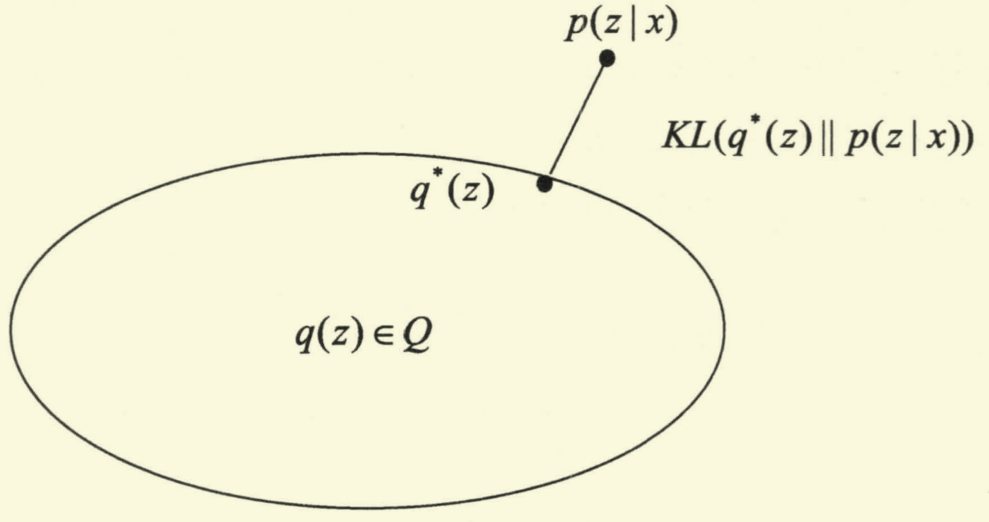
变分推断 (Variational Inference) 解析
前言 如果你对这篇文章可感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 变分推断 在贝叶斯方法中,针对含有隐变量的学习和推理,通常有两类方式,其一是马尔可…...

27. 移除元素
题目链接:https://leetcode.cn/problems/remove-element/给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输…...

hive临时目录清理
hive运行失败会导致临时目录无法自动清理,因此需要自己写脚本去进行清理 实际发现hive临时目录有两个: /tmp/hive/{user}/* /warehouse/tablespace//hive/**/.hive-staging_hive 分别由配置hive.exec.scratchdir和hive.exec.stagingdir决定: 要注意的…...

如何创建发布新品上市新闻稿
推出新产品对任何企业来说都是一个激动人心的时刻,但向潜在客户宣传并围绕您的新产品引起轰动也可能是一个挑战。最有效的方法之一就是通过发布新品上市新闻稿。精心制作的新闻稿可以帮助我们通过媒体报道、吸引并在目标受众中引起关注。下面,我们将讲述…...

关于.bashrc和setup.bash的理解
在创建了ROS的workspace后,需要将workspace中的setup.bash文件写入~/.bashrc 文件中,让其启动: source /opt/ros/melodic/setup.bash这句话的目的就是在开新的terminal的时候,运行这个setup.bash,而这个setup.bash的作…...
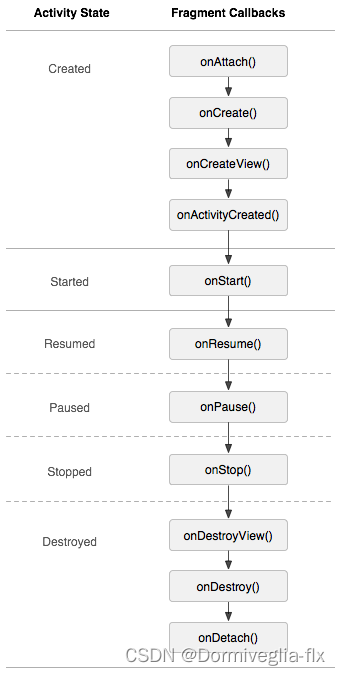
03 Android基础--fragment
03 Android基础--fragment什么是fragment?fragment生命周期?动态的fragment与静态的fragmentfragment常用的两个类与APIFragment与Activity通信什么是fragment? 碎片,一个activity中可以使用多个fragment,可以把activi…...
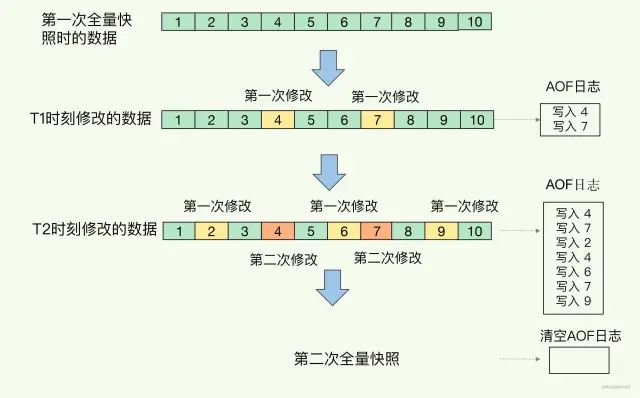
Redis使用,AOF、RDB
前言 如果有人问你:"你会把 Redis 用在什么业务场景下?" 我想你大概率会说:"我会把它当作缓存使用,因为它把后端数据库中的数据存储在内存中,然后直接从内存中读取数据,响应速度会非常快。…...
SOLIDWORKS Premium 2023 SP1.0 三维设计绘图软件
SOLIDWORKS 中文完美正式版提供广泛工具来处理最复杂的问题,并提供深层技术完成关键细节工作。新功能可助您改善产品开发流程,以更快地将创新产品投入生产。Solidworks 是达索公司最新推出的三维CAD系统,它可让设计师大大缩短产品的设计时间,让产品得以快速、高效地投向市场…...

PyQGIS开发--自动化地图布局案例
前言创建地图布局是 GIS 作业结束时的一项常见任务。 它用于呈现最终结果的输出,作为与用户交流的一种方式,以便从地图中获取信息、知识或见解。 在包括 QGIS 在内的任何 GIS 软件中制作地图布局都非常容易。 但另一方面,当我们必须生成如此大…...

严格模式和非严格模式下的this指向问题
一、全局环境 1.函数调用 非严格模式:this指向是Window // 普通函数 function fn () { console.log(this, this); } fn() // 自执行函数 (function fn () { console.log(this, this); })() 严格模式:this指向是undefined //…...

vue2、vue3组件传值,引用类型,对象数组如何处理
vue2、vue3组件传值,引用类型,对象数组如何处理 Excerpt 所有的 prop 都使得其父子 prop 之间形成了一个单向下行绑定:父级 prop 的更新会向下流动到子组件中,但是反过来则不行。这样会防止从子组件意外变更父… 下述组件传值指引…...

165. 小猫爬山
Powered by:NEFU AB-IN Link 文章目录165. 小猫爬山题意思路代码165. 小猫爬山 题意 翰翰和达达饲养了 N只小猫,这天,小猫们要去爬山。 经历了千辛万苦,小猫们终于爬上了山顶,但是疲倦的它们再也不想徒步走下山了(呜咕…...

ECharts教程(详细)
ECharts教程(详细) 非常全面的ECharts教程,非常全面的ECharts教程,目前线条/节点颜色、线条粗细、线条样式、线条阴影、线条平滑、线条节点大小、线条节点阴影、线条节点边框、线条节点边框阴影、工具提醒、工具提醒样式、工具自定义提醒、工具提醒背景…...

pinia
目录一、介绍二、快速上手1.安装2.基本使用与state3.actions的使用4.getters的使用5.storeToRefs的使用6.pinia模块化三、数据持久化1.安装2.使用插件3.模块开启持久化4.按需缓存模块的数据一、介绍 pinia从使用角度和之前Vuex几乎是一样的,比Vuex更简单了。 在Vu…...

mysql中insert语句的五种用法
文章目录前言一、values参数后单行插入二、values参数后多行插入三、搭配select插入数据四、复制旧表的信息到新表五、搭配set插入数据总结前言 insert语句是标准sql中的语法,是插入数据的意思。在实际应用中,它也演变了很多种用法来实现特殊的功能&…...

YOLOV7模型调试记录
先前的YOLOv7模型是pytorch重构的,并非官方提供的源码,而在博主使用自己的数据集进行实验时发现效果并不理想,因此生怕是由于源码重构导致该问题,此外还需进行对比实验,因此便从官网上下载了源码,进行调试运…...
)
模拟光伏不确定性——拉丁超立方抽样生成及缩减场景(Matlab全代码)
光伏出力的不确定性主要源于预测误差,而研究表明预测误差(e)服从正态分布且大概为预测出力的10%。本代码采用拉丁超立方抽样实现场景生成[1,2]、基于概率距离的快速前代消除法实现场景缩减[3],以此模拟了光伏出力的不确定性。与风电不确定性模拟不同之处在于——光伏存在0出…...

BilibiliVideoDownload故障排查指南:从登录失败到下载中断的全面解决方案
BilibiliVideoDownload故障排查指南:从登录失败到下载中断的全面解决方案 【免费下载链接】BilibiliVideoDownload Cross-platform download bilibili video desktop software, support windows, macOS, Linux 项目地址: https://gitcode.com/gh_mirrors/bi/Bilib…...

本地部署9B代码智能体:基于vLLM与CoPaw-Flash的实践与深度评估
1. 项目概述:在本地部署与评估一个9B参数的代码智能体最近在折腾一个挺有意思的项目,尝试在单张NVIDIA H100 GPU上,部署并评估一个名为CoPaw-Flash-9B的本地代码智能体。这个模型基于Qwen3.5-9B微调而来,专门针对自主智能体任务进…...

自我提升智能体的自进化原理和实践
自我提升智能体skill赋予了AI助手从错误中反思、学习并自动繁衍新通用技能的持续进化能力。 1 实际案例 帮我运行测试,看看为什么登录模块失败。 流程如下: 第一步,任务开始前,Hook 触发 activator.sh(通过 UserPromptSubmit 触发)。它不会输出一大堆规则,只是提醒 AI 一…...
)
客观现实源于波函数坍缩:意识内源测量与智能外源投影一体化统一理论(世毫九实验室原创理论)
客观现实源于波函数坍缩:意识内源测量与智能外源投影一体化统一理论(世毫九实验室原创理论) 方见华 世毫九实验室 摘要:本文首次建立了贯通量子力学、认知科学与人工智能的意识-智能-现实一体化统一理论,从第一性原理出发证明:客观现实不是独立于意识的先验存在,而是意…...

网盘直链解析工具完整指南:跨平台文件获取解决方案
网盘直链解析工具完整指南:跨平台文件获取解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

法律条款时间逻辑的DSL与状态机实现:从概念到工程实践
1. 项目概述:当法律条款遇上时间逻辑最近在做一个挺有意思的项目,叫“Clause-Logic/exoclaw-temporal”。光看名字,可能有点摸不着头脑,但如果你接触过合同、协议或者任何带有法律效力的文书,并且尝试过用代码去处理它…...

JAVA:类和对象完全解析
一、编程世界的乐高积木在面向对象编程(OOP)的宇宙中,类(Class)和对象(Object)如同乐高积木的基础模块。如果把程序看作一个虚拟城市,类就是建筑设计图,而对象则是根据图…...

5个颠覆性技巧:用GanttProject开源甘特图工具让你的项目管理效率提升200%
5个颠覆性技巧:用GanttProject开源甘特图工具让你的项目管理效率提升200% 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 你是否曾为项目延期而焦虑?是否在任务分配…...

为什么你的项目需要Remix Icon?3200+免费矢量图标的完整解决方案
为什么你的项目需要Remix Icon?3200免费矢量图标的完整解决方案 【免费下载链接】RemixIcon Open source neutral style icon system 项目地址: https://gitcode.com/gh_mirrors/re/RemixIcon 你是否曾为寻找合适的图标而烦恼?设计界面时图标风格…...
)
仅限内部测试者知晓:Midjourney未公开的--detail boost隐式指令(实测使睫毛/织物/金属反光细节识别率提升3.2倍)
更多请点击: https://intelliparadigm.com 第一章:Midjourney图像放大与细节增强 Midjourney v6 及后续版本原生支持高分辨率图像生成与智能细节增强,其核心能力不仅依赖于模型权重,更通过 --zoom 2、--style raw 和 --s 750 等参…...