Python抓取数据具体流程
之前看了一段有关爬虫的网课深有启发,于是自己也尝试着如如何过去爬虫百科“python”词条等相关页面的整个过程记录下来,方便后期其他人一起来学习。
抓取策略
确定目标:重要的是先确定需要抓取的网站具体的那些部分,下面实例是咦抓取百科python词条页面以及python有关页面的简介和标题。
分析目标:分析要抓取的url的格式,限定抓取范围。分析要抓取的数据的格式,本实例中就要分析标题和简介这两个数据所在的标签的格式。分析要抓取的页面编码的格式,在网页解析器部分,要指定网页编码,然后才能进行正确的解析。
编写代码:在网页解析器部分,要使用到分析目标得到的结果。
执行爬虫:进行数据抓取。
分析目标
1、url格式
进入百科python词条页面,页面中相关词条的链接比较统一,大都是/view/xxx.htm。
2、数据格式
标题位于类lemmaWgt-lemmaTitle-title下的h1子标签,简介位于类lemma-summary下。
3、编码格式
查看页面编码格式,为utf-8。
经过以上分析,得到结果如下:
代码编写
项目结构
在sublime下,新建文件夹baike-spider,作为项目根目录。
新建spider_main.py,作为爬虫总调度程序。
新建url_manger.py,作为url管理器。
新建html_downloader.py,作为html下载器。
新建html_parser.py,作为html解析器。
新建html_outputer.py,作为写出数据的工具。
具体代码示例:
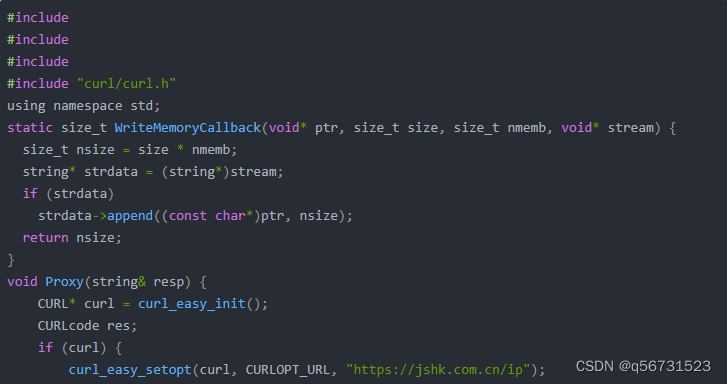
spider_main.py
# coding:utf-8
import url_manager, html_downloader, html_parser, html_outputerclass SpiderMain(object):def __init__(self):self.urls = url_manager.UrlManager()self.downloader = html_downloader.HtmlDownloader()self.parser = html_parser.HtmlParser()self.outputer = html_outputer.HtmlOutputer()def craw(self, root_url):count = 1self.urls.add_new_url(root_url)while self.urls.has_new_url():try:new_url = self.urls.get_new_url()print('craw %d : %s' % (count, new_url))html_cont = self.downloader.download(new_url)new_urls, new_data = self.parser.parse(new_url, html_cont)self.urls.add_new_urls(new_urls)self.outputer.collect_data(new_data)if count == 10:breakcount = count + 1except:print('craw failed')self.outputer.output_html()if __name__=='__main__':root_url = 'http://baike.baidu.com/view/21087.htm'obj_spider = SpiderMain()obj_spider.craw(root_url)
url_manger.py
# coding:utf-8
class UrlManager(object):def __init__(self):self.new_urls = set()self.old_urls = set()def add_new_url(self, url):if url is None:returnif url not in self.new_urls and url not in self.old_urls:self.new_urls.add(url)def add_new_urls(self, urls):if urls is None or len(urls) == 0:returnfor url in urls:self.add_new_url(url)def has_new_url(self):return len(self.new_urls) != 0def get_new_url(self):new_url = self.new_urls.pop()self.old_urls.add(new_url)return new_url
html_downloader.py
# coding:utf-8
import urllib.requestclass HtmlDownloader(object):def download(self, url):if url is None:return Noneresponse = urllib.request.urlopen(url)if response.getcode() != 200:return Nonereturn response.read()
html_parser.py
# coding:utf-8
from bs4 import BeautifulSoup
import re
from urllib.parse import urljoinclass HtmlParser(object):def _get_new_urls(self, page_url, soup):new_urls = set()# /view/123.htmlinks = soup.find_all('a', href=re.compile(r'/view/\d+\.htm'))for link in links:new_url = link['href']new_full_url = urljoin(page_url, new_url)# print(new_full_url)new_urls.add(new_full_url)#print(new_urls)return new_urlsdef _get_new_data(self, page_url, soup):res_data = {}# urlres_data['url'] = page_url# <dd class="lemmaWgt-lemmaTitle-title"> <h1>Python</h1>title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')res_data['title'] = title_node.get_text()# <div class="lemma-summary" label-module="lemmaSummary">summary_node = soup.find('div', class_='lemma-summary')res_data['summary'] = summary_node.get_text()# print(res_data)return res_datadef parse(self, page_url, html_cont):if page_url is None or html_cont is None:returnsoup = BeautifulSoup(html_cont, 'html.parser')# print(soup.prettify())new_urls = self._get_new_urls(page_url, soup)new_data = self._get_new_data(page_url, soup)# print('mark')return new_urls, new_data
html_outputer.py
# coding:utf-8
class HtmlOutputer(object):def __init__(self):self.datas = []def collect_data(self, data):if data is None:returnself.datas.append(data)def output_html(self):fout = open('output.html','w', encoding='utf-8')fout.write('<html>')fout.write('<body>')fout.write('<table>')for data in self.datas:fout.write('<tr>')fout.write('<td>%s</td>' % data['url'])fout.write('<td>%s</td>' % data['title'])fout.write('<td>%s</td>' % data['summary'])fout.write('</tr>')fout.write('</table>')fout.write('</body>')fout.write('</html>')fout.close()
运行
在命令行下,执行python spider_main.py。
编码问题
问题描述:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa0’ in position …
使用Python写文件的时候,或者将网络数据流写入到本地文件的时候,大部分情况下会遇到这个问题。网络上有很多类似的文章讲述如何解决这个问题,但是无非就是encode,decode相关的,这是导致该问题出现的真正原因吗?不是的。很多时候,我们使用了decode和encode,试遍了各种编码,utf8,utf-8,gbk,gb2312等等,该有的编码都试遍了,可是仍然出现该错误,令人崩溃。
在windows下面编写python脚本,编码问题很严重。将网络数据流写入文件时,我们会遇到几个编码:
1、#encoding=’XXX’
这里(也就是python文件第一行的内容)的编码是指该python脚本文件本身的编码,无关紧要。只要XXX和文件本身的编码相同就行了。
比如notepad++”格式”菜单里面里可以设置各种编码,这时需要保证该菜单里设置的编码和encoding XXX相同就行了,不同的话会报错。
2、网络数据流的编码
比如获取网页,那么网络数据流的编码就是网页的编码。需要使用decode解码成unicode编码。
3、目标文件的编码
将网络数据流写入到新文件,写文件代码如下:
fout = open('output.html','w')
fout.write(str)
在windows下面,新文件的默认编码是gbk,python解释器会用gbk编码去解析我们的网络数据流str,然而str是decode过的unicode编码,这样的话就会导致解析不了,出现上述问题。 解决的办法是改变目标文件的编码:
fout = open('output.html','w', encoding='utf-8')
相关文章:
Python抓取数据具体流程
之前看了一段有关爬虫的网课深有启发,于是自己也尝试着如如何过去爬虫百科“python”词条等相关页面的整个过程记录下来,方便后期其他人一起来学习。 抓取策略 确定目标:重要的是先确定需要抓取的网站具体的那些部分,下面实例是…...
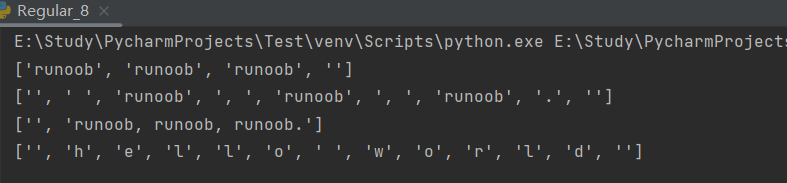
【Python学习笔记】第二十四节 Python 正则表达式
一、正则表达式简介正则表达式(regular expression)是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特…...
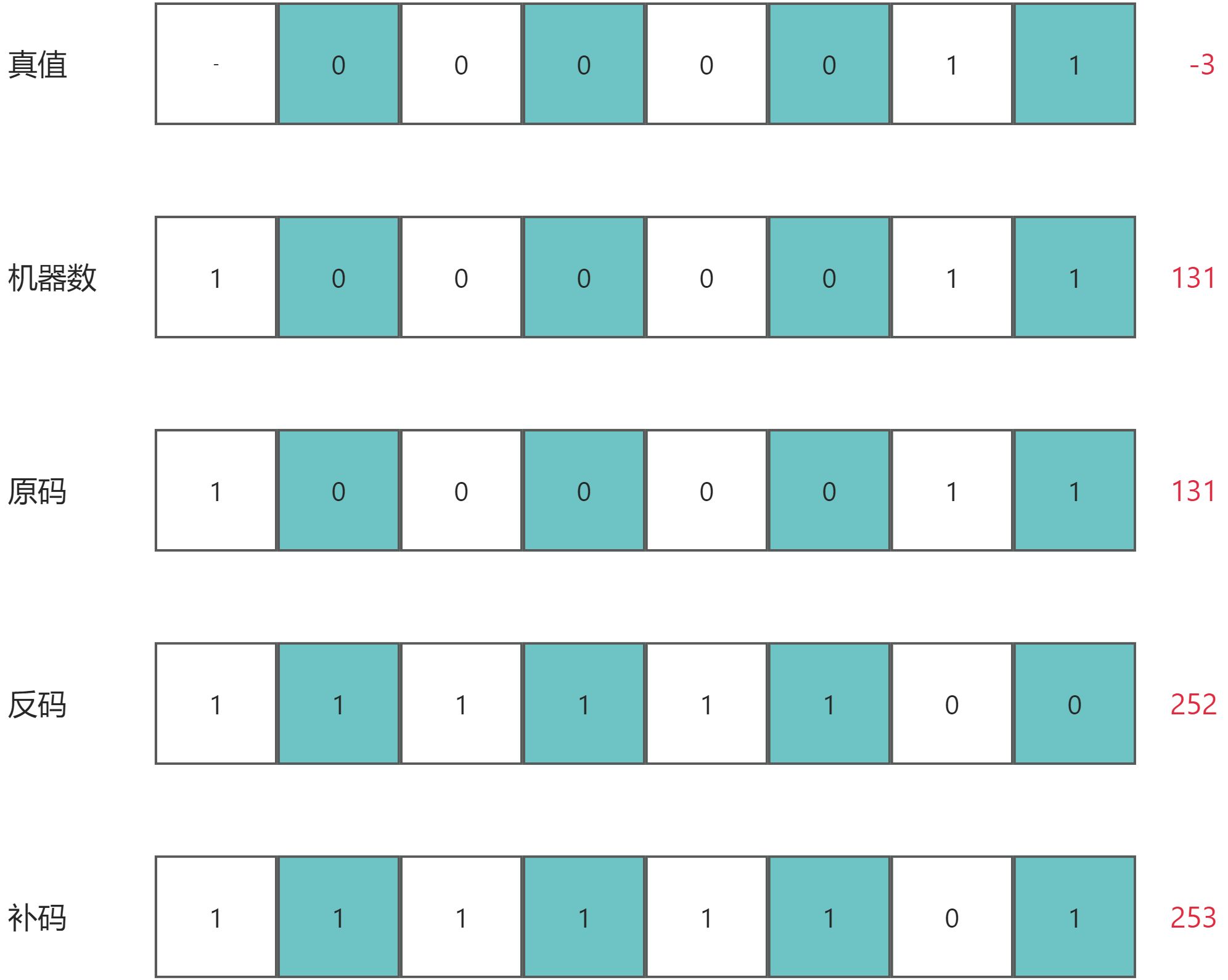
数字逻辑基础:原码、反码、补码
时间紧、不理解可以只看这里的结论 正数的原码、反码、补码相同。等于真值对应的机器码。 负数的原码等于机器码,反码为原码的符号位不变,其余各位按位取反。补码为反码1。 三种码的出现是为了解决计算问题并简化电路结构。 在原码和反码中,存…...

有限差分法-差商公式及其Matlab实现
2.1 有限差分法 有限差分法 (finite difference method)是一种数值求解偏微分方程的方法,它将偏微分方程中的连续变量离散化为有限个点上的函数值,然后利用差分逼近导数,从而得到一个差分方程组。通过求解差分方程组,可以得到原偏微分方程的数值解。 有限差分法是一种历史…...

高校就业信息管理系统
1引言 1.1编写目的 1.2背景 1.3定义 1.4参考资料 2程序系统的结构 3登录模块设计说明一 3.1程序描述 3.2功能 3.3性能 3.4输人项 3.5输出项 3.6算法 3.7流程逻辑 3.8接口 3.10注释设计 3.11限制条件 3.12测试计划 3.13尚未解决的问题 4注册模块设计说明 4.…...

【Java|golang】2373. 矩阵中的局部最大值
给你一个大小为 n x n 的整数矩阵 grid 。 生成一个大小为 (n - 2) x (n - 2) 的整数矩阵 maxLocal ,并满足: maxLocal[i][j] 等于 grid 中以 i 1 行和 j 1 列为中心的 3 x 3 矩阵中的 最大值 。 换句话说,我们希望找出 grid 中每个 3 x …...
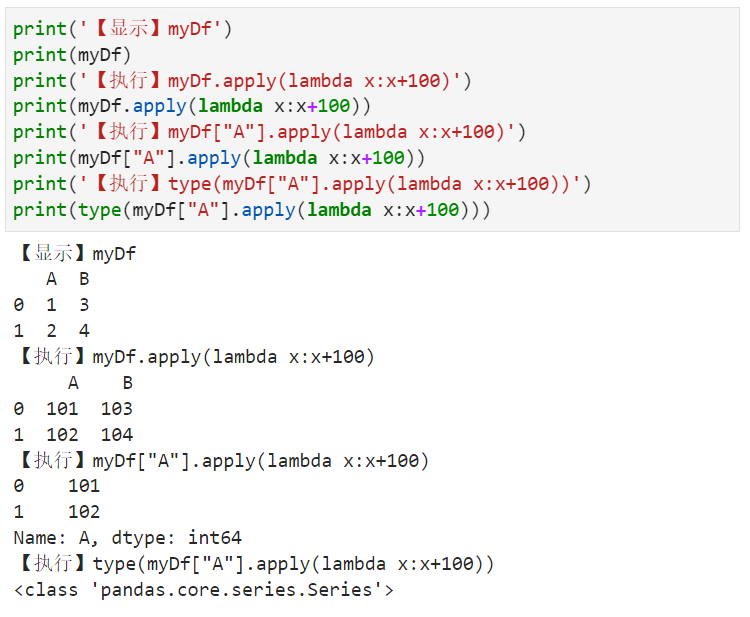
根据指定函数对DataFrame中各元素进行计算
【小白从小学Python、C、Java】【计算机等级考试500强双证书】【Python-数据分析】根据指定函数对DataFrame中各元素进行计算以下错误的一项是?import numpy as npimport pandas as pdmyDict{A:[1,2],B:[3,4]}myDfpd.DataFrame(myDict)print(【显示】myDf)print(myDf)print(【…...

【蓝桥杯集训·每日一题】AcWing 3502. 不同路径数
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴一、题目 1、原题链接 3502. 不同路径数 2、题目描述 给定一个 nm 的二维矩阵,其中的每个元素都是一个 [1,9] 之间的正整数。 从矩阵中的任意位置出发…...
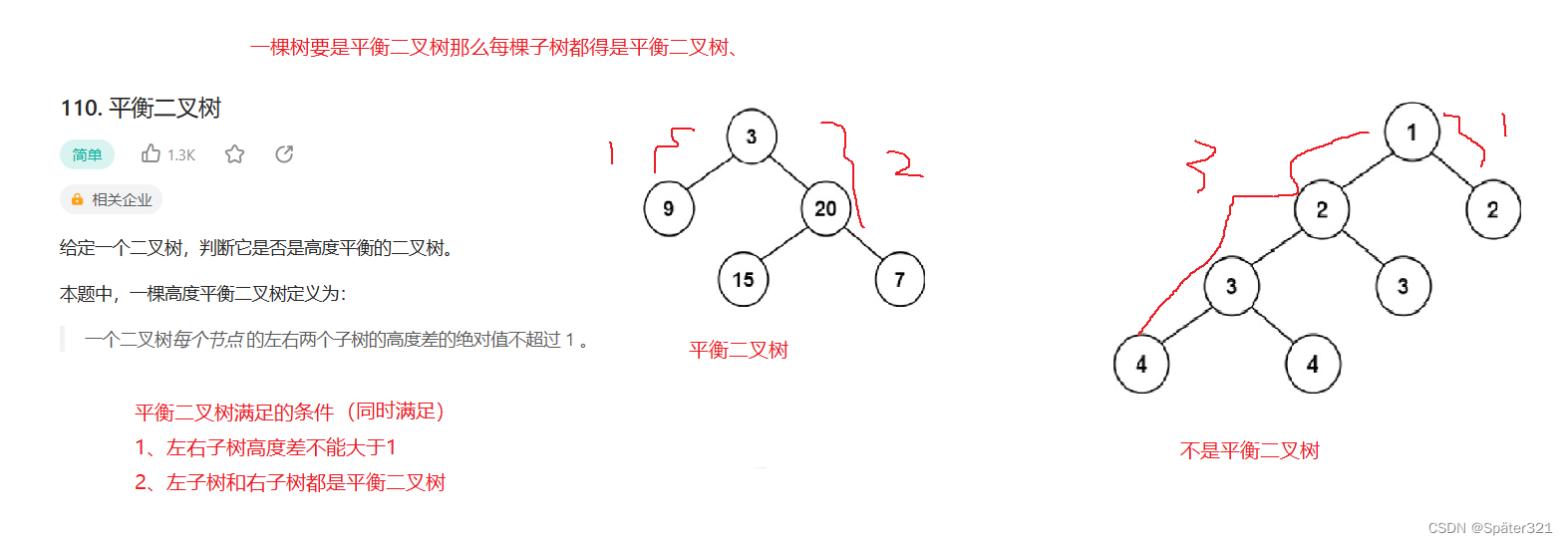
Java - 数据结构,二叉树
一、什么是树 概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点: 1、有…...
模拟QQ登录-课后程序(JAVA基础案例教程-黑马程序员编著-第十一章-课后作业)
【案例11-3】 模拟QQ登录 【案例介绍】 1.案例描述 QQ是现实生活中常用的聊天工具,QQ登录界面看似小巧、简单,但其中涉及的内容却很多,对于初学者练习Java Swing工具的使用非常合适。本案例要求使用所学的Java Swing知识,模拟实…...
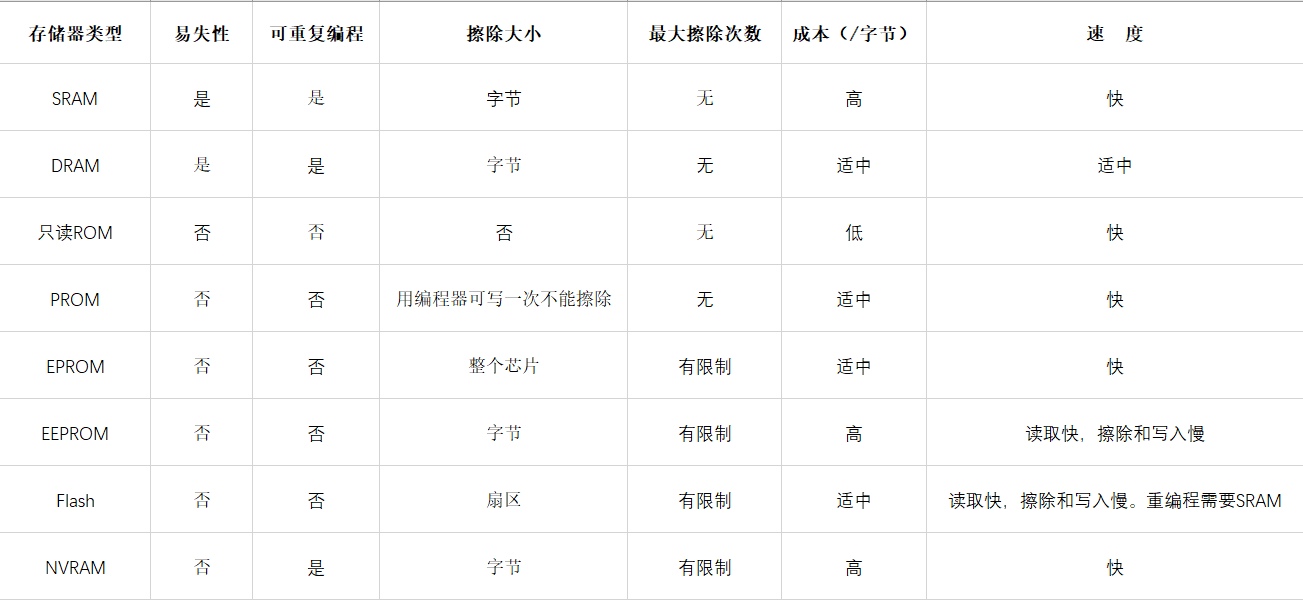
【壹】嵌入式系统硬件基础
随手拍拍💁♂️📷 日期: 2023.2.28 地点: 杭州 介绍: 日子像旋转毒马🐎,在脑海里转不停🤯 🌲🌲🌲🌲🌲 往期回顾 🌲🌲🌲…...
当参数调优无法解决kafka消息积压时可以这么做
今天的议题是:如何快速处理kafka的消息积压 通常的做法有以下几种: 增加消费者数增加 topic 的分区数,从而进一步增加消费者数调整消费者参数,如max.poll.records增加硬件资源 常规手段不是本文的讨论重点或者当上面的手段已经使…...
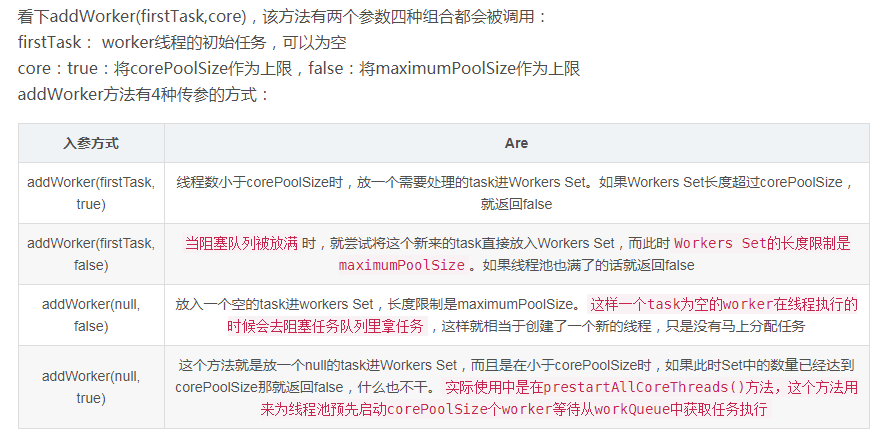
Java线程池源码分析
Java 线程池的使用,是面试必问的。下面我们来从使用到源码整理一下。 1、构造线程池 通过Executors来构造线程池 1、构造一个固定线程数目的线程池,配置的corePoolSize与maximumPoolSize大小相同, 同时使用了一个无界LinkedBlockingQueue存…...
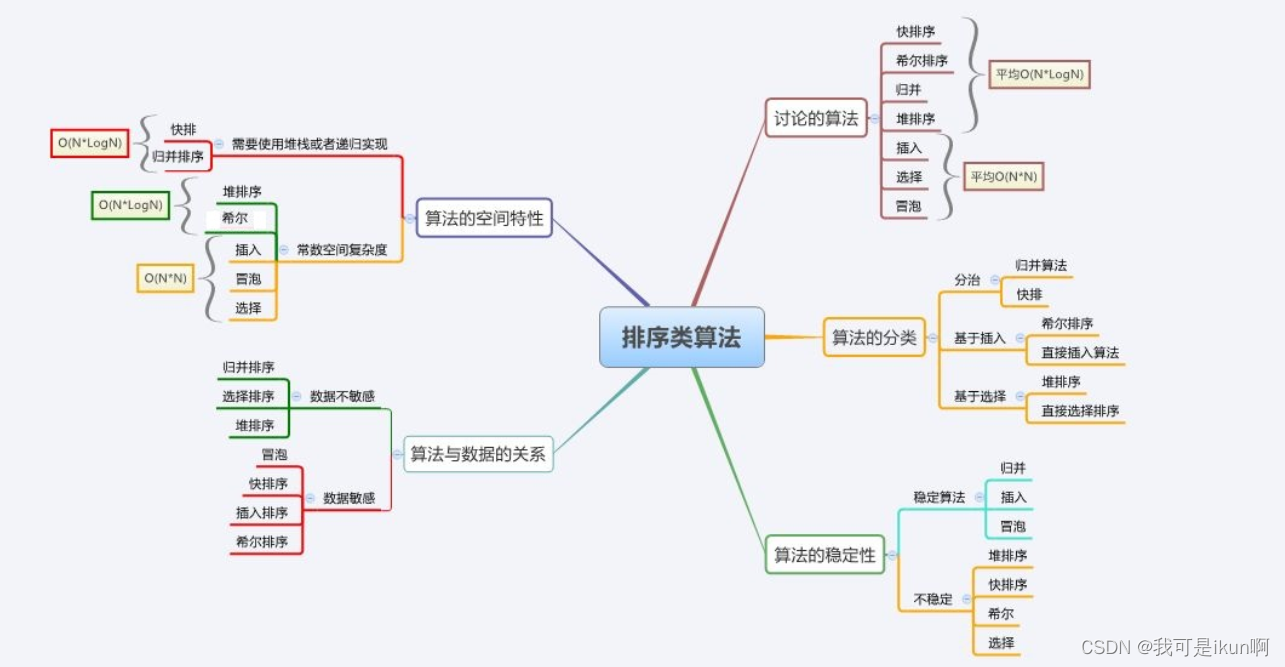
手撕八大排序(下)
目录 交换排序 冒泡排序: 快速排序 Hoare法 挖坑法 前后指针法【了解即可】 优化 再次优化(插入排序) 迭代法 其他排序 归并排序 计数排序 排序总结 结束了上半章四个较为简单的排序,接下来的难度将会大幅度上升&…...
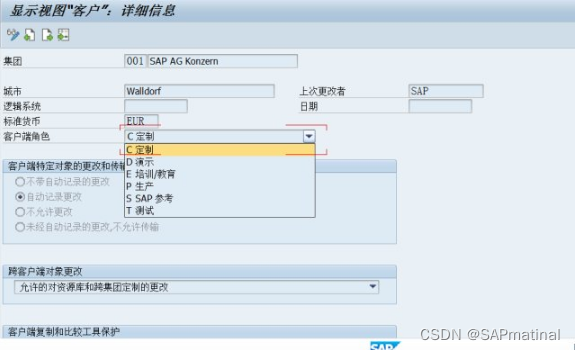
SAP 详细解析SCC4
事务代码:SCC4,选择一个客户端,点击进入,如图: 一、客户端角色 客户控制:客户的角色(生产性,测试,...) 此属性表示 R/3 系统中的客户端角色。其中可能包括…...
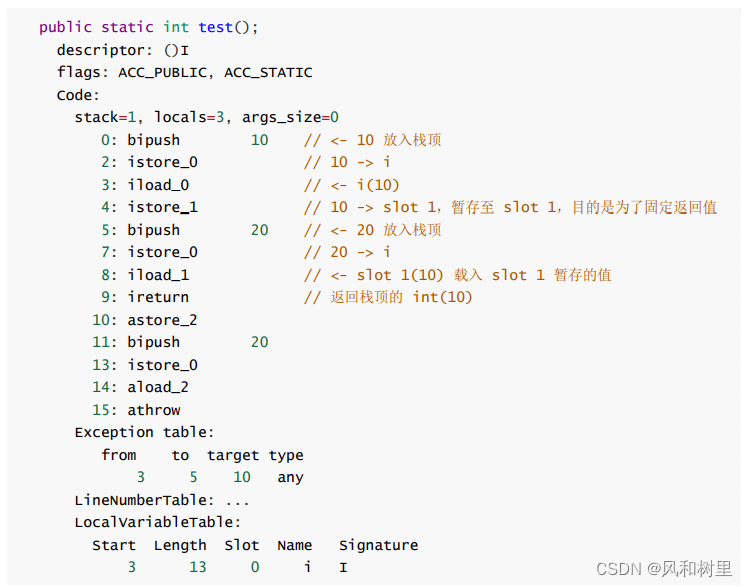
java异常分类和finally代码块中return语句的影响
首先看一下java中异常相关类的继承关系: 引用 1、分类 异常可以分为受查异常和非受查异常,Error和RuntimeException及其所有的子类都是非受查异常,其他的是受查异常。 两者的区别主要在: 受检的异常是由编译器(编译…...

【链表OJ题(二)】链表的中间节点
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:数据结构 🎯长路漫漫浩浩,万事皆有期待 文章目录链表OJ题(二)1. 链表…...
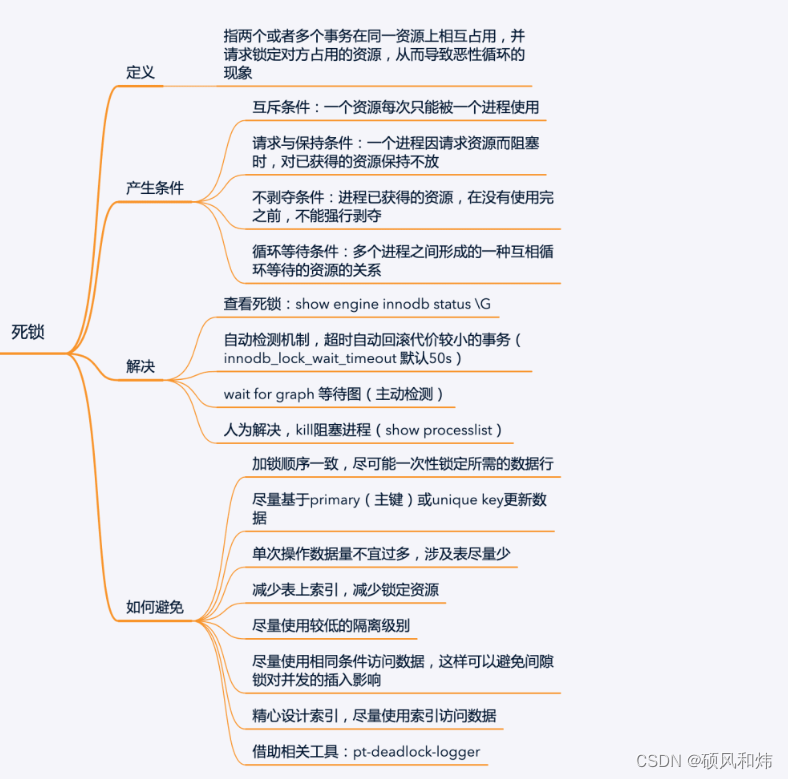
【强烈建议收藏:MySQL面试必问系列之并发事务锁专题】
一.知识回顾 上节课我们一起学习了MySQL面试必问系列之事务,没有学习的同学可以看一下上一篇文章,肯定对你会有帮助,学习过的同学肯定知道,上节课我们留了一个小尾巴,这个小尾巴是什么呢?就是没有详细展开…...
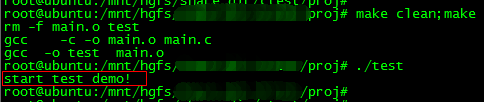
Linux下使用Makefile实现条件编译
在Linux系统下Makefile和C/C语言都有提供条件选择编译的语法,就是在编译源码的时候,可以选择性地编译指定的代码。这种条件选择编译的使用场合有好多,例如我们开发一个兼容标准版本与定制版本兼容的项目,那么,一些与需…...
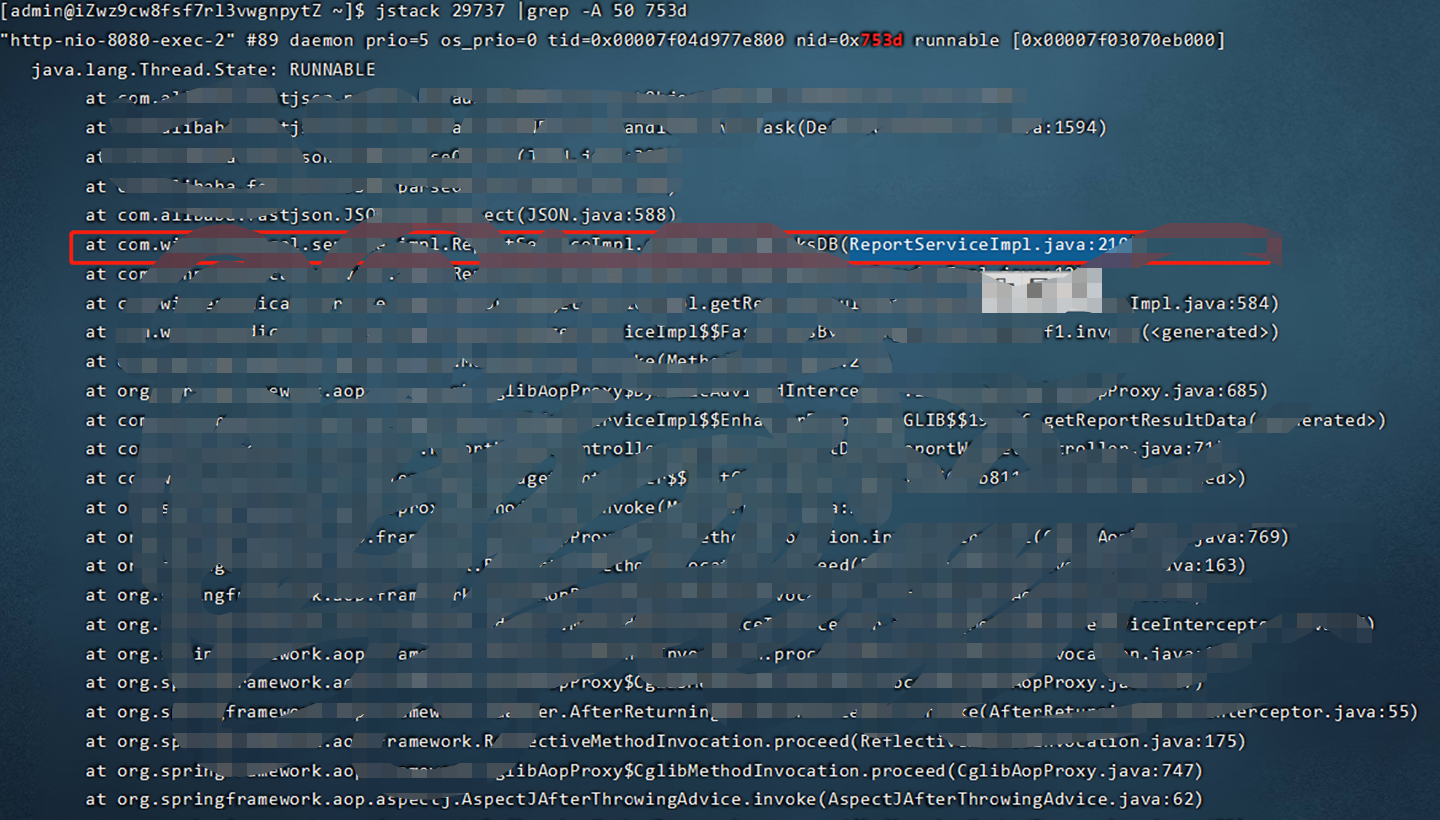
java 应用cpu飙升(超过100%)故障排查
前言害。。。昨天刚写完一份关于jvm问题排查相关的博客,今天线上项目就遇到了一个突发问题。现象是用户反映系统非常卡,无法操作。然后登录服务器查看发现cpu 一直100%以上。具体排查步骤:1,首先top命令查看服务器cpu等情况&#…...
)
玩转OurBMC第二十六期:OpenBMC固件远程更新原理与实践(下)
栏目介绍:“玩转OurBMC” 是OurBMC社区开创的知识分享类栏目,主要聚焦于社区和BMC全栈技术相关基础知识的分享,全方位涵盖了从理论原理到实践操作的知识传递。OurBMC社区将通过 “玩转OurBMC” 栏目,帮助开发者们深入了解到社区文…...

基于ASR与NLP的法庭音频智能分析系统:架构、微调与法律场景实践
1. 项目概述:当法庭记录“开口说话” 在司法与法律科技领域,数据正以前所未有的方式重塑工作流程。传统的法庭记录,无论是书记员手写的笔录,还是后来普及的录音录像,其核心价值在于“记录”本身——它们是静态的、被动…...

私有云时代来临:AI NAS如何重塑你的数字生活?
超越传统存储,打造你的私人云端 在信息爆炸的时代,随着个人存储需求的激增和变化,以及个体对数据隐私和安全性的日益重视,外加AI的技术加持,一种大家也许并不熟知的存储解决方案——NAS迎来了发展机遇。 NAS是Network …...

构建离线优先应用终极指南:Material Components Web 与 Service Worker 完美集成
构建离线优先应用终极指南:Material Components Web 与 Service Worker 完美集成 【免费下载链接】material-components-web Modular and customizable Material Design UI components for the web 项目地址: https://gitcode.com/gh_mirrors/ma/material-compone…...

Sonic搜索集群终极指南:从单机到高可用的完整部署方案
Sonic搜索集群终极指南:从单机到高可用的完整部署方案 【免费下载链接】sonic 🦔 Fast, lightweight & schema-less search backend. An alternative to Elasticsearch that runs on a few MBs of RAM. 项目地址: https://gitcode.com/gh_mirrors/…...
)
DataX实战避坑:手把手教你用Shell脚本搞定MySQL多表同步(附完整脚本)
DataX多表同步实战:从脚本优化到生产级部署的全链路指南 MySQL数据同步是数据仓库建设中的基础环节,而DataX作为阿里巴巴开源的高效数据同步工具,在实际生产环境中却常常因为脚本设计不当导致维护成本激增。本文将从一个真实电商平台的订单系…...
)
告别手动拷贝!用Qt Creator远程调试嵌入式Linux应用(保姆级配置流程)
告别手动拷贝!用Qt Creator远程调试嵌入式Linux应用(保姆级配置流程) 嵌入式开发中,最令人头疼的莫过于反复的"编译-拷贝-运行/调试"循环。每次修改代码后,都需要手动将可执行文件拷贝到开发板,再…...

131.详解YOLO损失函数+网格划分原理,附v1-v8演进脉络+YOLOv8实战代码
摘要 目标检测是计算机视觉的核心任务之一。YOLO(You Only Look Once)系列以其极致的检测速度与良好的精度平衡,成为工业界和学术界最广泛应用的检测框架。本文以理工科严谨逻辑,从YOLO的核心思想出发,覆盖从v1到v8的关键演进,并通过一个完整的可运行案例,带领读者从零…...

英特尔无人机芯片战略:从RealSense到异构计算的技术博弈与市场挑战
1. 从移动梦碎到天空野心:英特尔为何押注无人机芯片?2016年5月,当英特尔在加州棕榈泉的夜空中点亮100架编队飞行的无人机时,这场名为“Drone 100”的灯光秀,其意义远不止一场炫目的营销。它更像是一份宣言,…...
)
基于 DWT 的盲数字水印实现(嵌入与提取)
一、原理 盲数字水印(Blind Watermarking)指提取水印时无需原始载体图像,仅依靠含水印图像和密钥即可完成。 DWT(离散小波变换) 将图像分解为: LL:低频近似分量(能量集中,…...