Transformer 简介
Transformer 是 Google 在 2017 年底发表的论文 Attention Is All You Need 中所提出的 seq2seq 模型。Transformer 模型的核心是 Self-Attention 机制,能够处理输入序列中的每个元素,并能计算其与序列中其他元素的交互关系的方法,从而能够更好地理解序列中的上下文关系。
Transformer 模型能够处理不同长度的序列,捕捉长距离依赖关系,并在大规模数据上进行高效训练。这使得它成为自然语言处理领域取得重大突破的关键模型之一,逐渐取代了 CNN 和 RNN。
目录
- 一. 预备知识
- 1. Attention 机制
- 2. Self-Attention 机制
- 3. Cross-Attention 机制
- 4. Multi-Head Attention
- 5. 位置编码
- 二. Transformer
- 1. Input Block
- 2. Encoder Block
- 3. Decoder Block
- 4. Output Block
一. 预备知识
1. Attention 机制
Attention 机制 1 也叫注意力机制,是一种用于改善神经网络 对输入序列中不同部分的关注度 的机制。在传统的神经网络中,所有输入信息都被平等对待,无论其在序列中的位置或重要性。而 Attention 机制允许网络在处理输入序列时更加关注其中的特定部分,使网络能够更灵活地学习输入之间的关系。
Attention 机制的基本思想是:对于每个输出位置,网络都动态地计算一个权重分布,以指示输入序列中哪些位置更重要。这个权重分布是通过计算 Query(即用户提出的问题)与 Key(即模型中的知识摘要)之间的关联度,然后 softmax 归一化取最大概率的结果,最后查询得到 Value(即与 Key 相关联的知识)输出。

Attention 机制解决了先前 RNN 不能并行计算的问题,节省了训练时间,并且能够获取到局部的关键信息。但 Attention 机制也有一些缺点:
- 只能在 Decoder 阶段实现并行运算,Encoder 部分依旧采用的是 RNN、LSTM 等按照顺序编码的模型,无法实现并行运算;
- 因为 Encoder 部分仍依赖 RNN,所以中长距离之间的两个词相互之间的关系没有办法很好的获取;
为了改进 Attention 机制的缺点,出现了 Self-Attention。
2. Self-Attention 机制
Self-Attention(自注意力)机制是 Attention 的一种特殊形式,它允许一个 序列中的不同位置之间进行交互,而不是像 Attention 机制那样仅仅对输入序列的不同部分进行关注。在 Self-Attention 中,对于序列中的每个元素,都会计算该元素与序列中所有其他元素之间的关联度,然后利用这些关联度为每个元素分配一个权重。这样,每个元素都能够考虑到整个序列的信息,能够与序列中的所有其他位置进行交互,而不仅仅是局部信息,从而更好地捕捉长距离依赖关系。
Self-Attention 最为突出的应用就是在 Transformer 模型中,它允许模型在处理序列数据时,不受到固定的感受野大小的限制,而能够根据任务的需要自适应地捕捉不同位置的信息。这使得 Self-Attention 成为了处理序列数据的强大工具,被广泛用于自然语言处理和其他领域的任务。

如图所示,X 是嵌入了 Positional Encoding 的 Input Embedding,每一行都是一个词向量;WQ、WK、WV 分别是用于计算 Query、Keys、Values 的权值矩阵;Q、K、V 分别是 Input Embedding 与权值矩阵计算所得的 Query、Keys、Values 向量,用于计算 Attention 值。
3. Cross-Attention 机制
Cross-Attention(交叉注意力)机制是 Attention 机制的一种扩展,它主要应用于 处理两个不同序列之间的关系,使得模型能够对一个序列中的元素关注另一个序列中的相关部分,从而更好地捕捉两个序列之间的关联信息。
Cross-Attention 机制的引入使得模型能够在处理两个序列时,动态地关注源序列的不同部分,从而更好地理解源序列与目标序列之间的关系。这在处理序列对之间的任务时非常有用,比如在问答、机器翻译等任务中。
Transformer 的 Decoder 部分使用 Cross-Attention 机制来处理输入序列和输出序列之间的关系。具体来说,Decoder 在生成目标序列的每个位置时,能够动态地关注输入序列的不同部分,更好地对应输入和输出之间的对应关系,尤其在翻译等任务中效果显著。
4. Multi-Head Attention
Multi-Head Attention 是 Transformer 模型中的一种注意力机制,它是对单一 Attention 头的扩展。通过使用多个独立的 Attention 头,模型能够并行地学习不同的关注权重,从而更好地捕捉序列中的不同关系。这有助于提高模型的表达能力和学习复杂关系的能力。
Multi-Head Attention 使用多个独立的 Attention 头,对于每个Attention头,学习三个线性变换,分别用于生成各自的 Query、Key 和 Value;然后使用每个头的 Query、Key 和 Value 并行计算关联度和权重;再将多个头的输出拼接在一起以增加模型对不同关系和特征的表达能力;最后将拼接后的输出通过线性变换生成最终的 Multi-Head Attention 的输出。

通过使用多个 Attention 头,模型能够学习到数据不同方面的表示,从而更全面地捕捉序列中的关系。这种多头机制在提高模型的性能、泛化能力和处理复杂任务方面都发挥了重要作用。
5. 位置编码
位置编码 (Positional Encoding) 2 是为了在 Transformer 等无法处理序列顺序信息的模型中引入位置信息而设计的一种技术。由于 Transformer 没有像循环神经网络 RNN 那样的内在顺序感知,因此位置编码的目的是为模型提供有关输入序列中元素位置的信息。

位置编码的一种常见形式是通过将位置信息嵌入到输入向量中来实现,这个向量的设计通常基于三角函数或正弦余弦函数,以确保模型能够学到有关序列位置的有用信息。以正弦余弦函数为例,对 Input Embedding 中每个位于 p o s pos pos 的字符和字符中的位置 i i i,位置编码的计算方式如下 3:
PE ( p o s , 2 i ) = sin ( p o s 10000 2 i / d ) PE ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d ) \text{PE}(pos, 2i) = \sin\left(\frac{pos}{{10000}^{2i/d}}\right)\\ \text{PE}(pos, 2i+1) = \cos\left(\frac{pos}{{10000}^{2i/d}}\right) PE(pos,2i)=sin(100002i/dpos)PE(pos,2i+1)=cos(100002i/dpos)
其中, PE \text{PE} PE 是位置编码, p o s pos pos 是当前字符在输入文本中的位置, i i i 是当前字符编码某一位置的索引, d d d 是 Input Embedding 中每个字符编码的维度。这种位置编码的设计允许模型在不同位置和不同维度上学到有关位置的信息。
在训练过程中,这些位置编码与输入嵌入相加,从而将位置信息引入模型。位置编码的选择是可学习的,因此模型可以根据任务学到最适合的位置表示。通过引入位置编码,Transformer 能够更好地处理序列中元素的顺序关系,从而更好地捕捉长距离的依赖关系。
二. Transformer
Transformer4 是一种神经网络架构,引入了 Self-Attention 机制,允许模型同时处理输入序列中的所有位置信息,而无需使用循环神经网络或卷积神经网络。Transformer 的核心部分是 Encoder 和 Decoder 块:编码器接收一段输入序列,进行一系列的自注意力和全连接网络操作,并输出一段连续的表示;解码器部分接受编码器的输出以及之前解码器的输出,生成新的输出。

1. Input Block
Transformer 将输入文本分词然后编码为词向量序列,也就是 Input Embedding。词向量可以是 word2vec、GloVe、one-hot 等编码形式,不同词向量都具有相同的维度。处理好 Input Embedding 后需要给每个词向量添加位置编码,来保留输入文本内部的相对位置信息。以输入文本 “Tom chase Jerry” 为例,Input Block 内部如下:

Input Embedding 和 Output Embedding 都属于 Input Block,只有在训练期间才会接收 Output Embedding 输入,进行预测时 Output Embedding 不接受输入。
2. Encoder Block
Encoder Block 由多个 Encoder 堆叠而成,每个 Encoder 内部包括 Multi-Head Attention 和 Feed Forward:

Multi-Head Attention 就是在 Self-Attention 的基础上,使用多组 WQ、WK、WV 得到多组 Query、Keys、Values,然后每组分别计算得到一个 Z 矩阵,最后进行拼接。

Feed Forward 是一个普通的全连接网络,依次做线性、ReLU 非线性等变换。
Multi-Head Attention 和 Feed Forward 后面都加入了 Add 和 Normalize 层:Add 层就是在 Z 的基础上添加残差块 X(其实就是 Multi-Head Attention 的输入 X),防止在深度神经网络训练中发生退化问题;Normalize 层用于对输入数据 Normalize 归一化,从而加快训练速度、提高训练的稳定性。
3. Decoder Block
Decoder 的输入分训练和预测两种:训练时的输入就是已经准备好的 target 数据,例如翻译任务中 Encoder 输入"Tom chase Jerry",Decoder 输入 “汤姆追逐杰瑞”;预测时的输入则是上一时刻 Transformer 的输出。
Decoder Block 相较于 Encoder Block 只增加了 Masked Multi-Head Attention:

Masked Multi-Head Attention 就是在 Multi-Head Attention 的基础上多加了一个 mask 码,对部分值进行掩盖使其在参数更新时不产生效果。
4. Output Block
Output Block 结构简单:先经过一次线性变换,然后 Softmax 就可以得到输出的概率分布。
史上最小白之Attention详解 ↩︎
transformer学习笔记:Positional Encoding(位置编码) ↩︎
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30. ↩︎
史上最小白之Transformer详解 ↩︎
相关文章:
Transformer 简介
Transformer 是 Google 在 2017 年底发表的论文 Attention Is All You Need 中所提出的 seq2seq 模型。Transformer 模型的核心是 Self-Attention 机制,能够处理输入序列中的每个元素,并能计算其与序列中其他元素的交互关系的方法,从而能够更…...
)
LLVM学习笔记(64)
4.4.3.3.3. 设置寄存器类对类型的行为 1679行调用computeRegisterProperties()来计算寄存器类的衍生属性。TargetLoweringBase的容器RegisterTypeForVT、RegClassForVT以及NumRegistersForVT用于记录原生支持每个ValueType目标机器寄存器类的信息,即类型对应的寄存…...
深度学习TensorFlow2基础知识学习前半部分
目录 测试TensorFlow是否支持GPU: 自动求导: 数据预处理 之 统一数组维度 定义变量和常量 训练模型的时候设备变量的设置 生成随机数据 交叉熵损失CE和均方误差函数MSE 全连接Dense层 维度变换reshape 增加或减小维度 数组合并 广播机制&#…...
Linux系统---简易伙伴系统
顾得泉:个人主页 个人专栏:《Linux操作系统》 《C/C》 《LeedCode刷题》 键盘敲烂,年薪百万! 一、题目要求 1.采用C语言实现 2.伙伴系统采用free_area[11]数组来组织。要求伙伴内存最小为一个页面,页面大小为4KB…...

Redis使用Lua脚本
Lua脚本 redis可以支持lua脚本,可以使用lua脚本来将几个命令整合为一个整体来执行,这样可以使得多个命令原子操作,且可以减少网络开销 Lua的数据类型 Lua是一个动态类型的语言,一个变量可以存储任何类型的值,类型有&am…...

macos安装metal 加速版 pytorch
categories: [Python] tags: Python MacOS 写在前面 试试 m3 的 metal 加速效果如何 Mac computers with Apple silicon or AMD GPUsmacOS 12.3 or laterPython 3.7 or laterXcode command-line tools: xcode-select --install 安装 Python: conda-forge brew install minif…...

【学习笔记】lyndon分解
摘抄自quack的ppt。 这部分和 s a sa sa的关联比较大,可以加深对 s a sa sa的理解。 Part 1 如果字符串 s s s的字典序在 s s s以及 s s s的所有后缀中是最小的,则称 s s s是一个 lyndon \text{lyndon} lyndon串。 lyndon \text{lyndon} lyndon分解&a…...

21、命令执行
文章目录 一、命令执行概述1.1 基本定义1.2 原理1.3 两个条件1.4 命令执行漏洞产生的原因1.5 管道符号和通用命令符 二、远程命令执行2.1 远程命令执行相关函数2.2 远程命令执行漏洞的利用 三、系统命令执行3.1 相关函数3.2 系统命令执行漏洞利用 四、命令执行漏洞防御 一、命令…...
Qexo博客后台管理部署
Qexo博客后台管理部署 个人主页 个人博客 参考文档 https://www.oplog.cn/qexo/本地部署 采用本地Docker部署管理本地Hexo 下载代码包 若无法下载使用科学工具下载到本地在上传到服务器 wget https://github.com/Qexo/Qexo/archive/refs/tags/3.0.1.zip# 解压 unzip Qexo…...

最小生成树prim
最小生成树(三)Prim算法及存储结构_哔哩哔哩_bilibili 311 最小生成树 Prim 算法_哔哩哔哩_bilibili #include <iostream> #include <queue> #include <string> #include <stack> #include <vector> #include <set…...
实用篇 | 一文学会人工智能中API的Flask编写(内含模板)
----------------------- 🎈API 相关直达 🎈-------------------------- 🚀Gradio: 实用篇 | 关于Gradio快速构建人工智能模型实现界面,你想知道的都在这里-CSDN博客 🚀Streamlit :实用篇 | 一文快速构建人工智能前端展…...
Si24R03—低功耗 SOC 芯片(集成RISC-V内核+2.4GHz无线收发器)
Si24R03是一款高度集成的低功耗SOC芯片,其集成了基于RISC-V核的低功耗MCU和工作在2.4GHz ISM频段的无线收发器模块。 MCU模块具有低功耗、Low Pin Count、宽电压工作范围,集成了13/14/15/16位精度的ADC、LVD、UART、SPI、I2C、TIMER、WUP、IWDG、RTC等丰…...

C# Winform 日志系统
目录 一、效果 1.刷新日志效果 2.单独日志的分类 3.保存日志的样式 二、概述 三、日志系统API 1.字段 Debug.IsScrolling Debug.Version Debug.LogMaxLen Debug.LogTitle Debug.IsConsoleShowLog 2.方法 Debug.Log(string) Debug.Log(string, params object[]) …...

【Java 基础】27 XML 解析
文章目录 1.SAX 解析器1)什么是 SAX2)SAX 工作流程初始化实现事件处理类解析 3)示例代码 2.DOM 解析器1)什么是 DOM2)DOM 工作流程初始化解析 XML 文档操作 DOM 树 3)示例代码 总结 在项目开发中࿰…...

地图服务 ArcGIS API for JavaScript基础用法全解析
地图服务 ArcGIS API for JavaScript基础用法全解析 前言 在接触ArcGIS之前,开发web在线地图时用过Leaflet来构建地图应用,作为一个轻量级的开源js库,在我使用下来Leaflet还有易懂易用的API文档,是个很不错的选择。在接触使用Ar…...
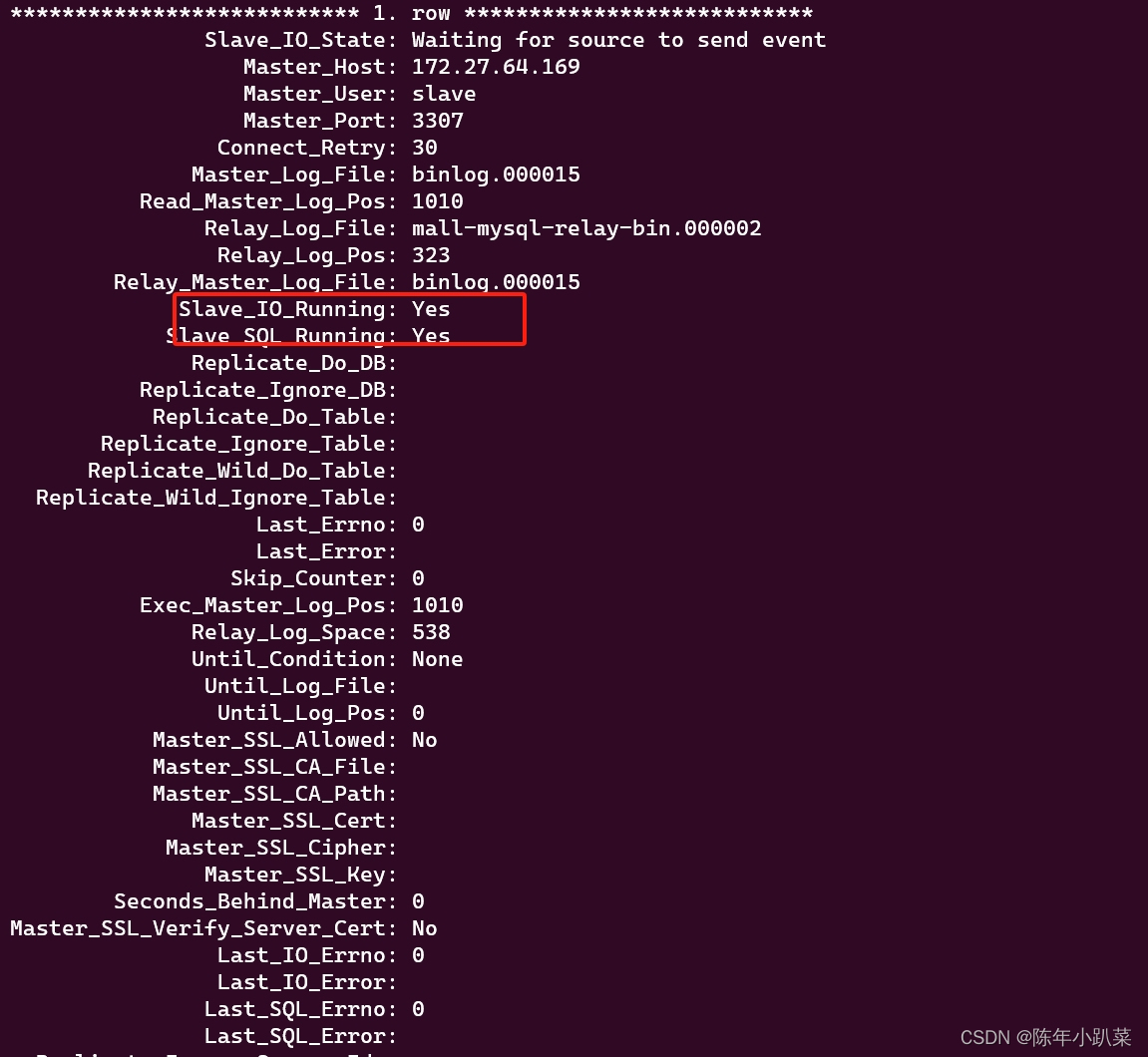
docker学习(八、mysql8.2主从复制遇到的问题)
在我配置主从复制的时候,遇到了一直connecting的问题。 起初可能是我ip配置的不对,slave_io_running一直connecting。(我的环境:windows中安装了wsl,是ubuntu环境的,在wsl中装了miniconda,mini…...
:表单验证)
React-hook-form-mui(三):表单验证
前言 在上一篇文章中,我们介绍了react-hook-form-mui的基础用法。本文将着重讲解表单验证功能。 react-hook-form-mui提供了丰富的表单验证功能,可以通过validation属性来设置表单验证规则。本文将详细介绍validation的三种实现方法,以及如何…...

【私域运营秘籍】4大用户调研方法,让你轻松掌握用户心理!
我们常说私域运营的核心是用户运营。根据二八法则,20%的超级用户贡献企业80%的利润。因此,企业应该根据用户的价值贡献来有针对性地进行运营。 然而,在实际的私域运营中,我们不仅需要找出贡献价值不同的用户,还可以从…...

2.8寸 ILI9341 TFTLCD 学习移植到STM32F103C8T6
2.8寸 ILI9341 TFTLCD 学习移植到STM32F103C8T6 文章目录 2.8寸 ILI9341 TFTLCD 学习移植到STM32F103C8T6前言第1章 LCD简介1.1 LCD硬件接口介绍 第2章 LCD指令介绍第3章 LCD 8080驱动方式3.1 8080写时序3.2 8080读时序 第4章 LCD 驱动代码部分4.1 修改代码部分4.2 代码工程下载…...

Java利用TCP实现简单的双人聊天
一、创建新项目 首先创建一个新的项目,并命名为聊天。然后创建包,创建两个类,客户端(SocketClient)和服务器端(SocketServer) 二、实现代码 客户端代码: package 聊天; import ja…...

vLLM-v0.17.1效果展示:多LoRA热切换,支持10+垂类模型动态加载
vLLM-v0.17.1效果展示:多LoRA热切换,支持10垂类模型动态加载 1. vLLM框架核心能力 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,最初由加州大学伯克利分校的天空计算实验室开发,现已发展成为社区驱动的开源项目。…...

Bubblewrap项目部署实战:从开发环境到Google Play发布的完整流程
Bubblewrap项目部署实战:从开发环境到Google Play发布的完整流程 【免费下载链接】bubblewrap Bubblewrap is a Command Line Interface (CLI) that helps developers to create a Project for an Android application that launches an existing Progressive Web A…...

使用PHP Imagick扩展将PDF转换为图片功能的完整方案
引言在开发中,经常需要将 PDF 文档转换为图片格式,以便于在线预览、生成缩略图或进行其他图像处理操作。PHP 的 Imagick 扩展提供了强大的图像处理能力,可以轻松实现这一需求。本文将介绍如何使用 Imagick 扩展创建一个高效的 PDF 转图片工具…...

PHP利用Opcache实现保护源码的示例详解
不用 IonCube(或类似的)。不知道这是啥的话,就是加密 PHP 代码但还能运行的工具。问题是太贵了。性能要好,PHP 原生支持。后来想到,PHP 有个"opcache"功能,能把源码编译成操作码(机器…...

lingbot-depth-pretrain-vitl-14多场景落地:AR实时遮挡、3D重建、工业检测一文详解
lingbot-depth-pretrain-vitl-14多场景落地:AR实时遮挡、3D重建、工业检测一文详解 想象一下,你手里只有一部普通的手机摄像头,却想让它像人眼一样“感知”距离,知道哪个物体离你近,哪个离你远。或者,你有…...

SecGPT-14B+OpenClaw联调指南:解决模型响应超时问题
SecGPT-14BOpenClaw联调指南:解决模型响应超时问题 1. 问题背景与场景定位 上周在尝试用OpenClaw调用SecGPT-14B分析一份12万字的网络安全报告时,遭遇了令人头疼的响应超时问题。这个场景很典型——当我们需要处理长文本安全分析时,模型推理…...

基于SpringBoot + Vue的定制化设计服务平台
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

家庭教育小帮手:OpenClaw+Kimi-VL-A3B-Thinking自动批改孩子手写作业
家庭教育小帮手:OpenClawKimi-VL-A3B-Thinking自动批改孩子手写作业 1. 为什么需要自动化作业批改? 作为一名经常辅导孩子作业的家长,我深刻体会到手工批改作业的痛点。每天晚上检查数学题时,既要核对答案正确性,又要…...

MySQL主从延迟
技术文章大纲:MySQL主从延迟根因诊断法引言主从复制在MySQL高可用架构中的重要性主从延迟的常见影响(数据不一致、查询延迟、故障恢复风险)诊断延迟问题的必要性主从延迟的核心原理主从复制的基本流程(binlog生成、传输、重放&…...

MySQL 主从延迟全链路根因诊断与破局法则
MySQL 主从延迟全链路根因诊断与破局法则 在复杂的微服务架构和高并发场景中,数据库的读写分离是标配。然而,伴随而来的“主从延迟”(Replication Lag)往往是引发线上数据一致性问题的幽灵。很多时候,前端反馈“刚写入…...