爬虫学习-基础库的使用(requests)
目录
一、安装以及实例引入
(1)requests库下载
(2)实例测试
二、GET请求
(1)基本实例
(2)抓取网页
(3)抓取二进制数据
(4)添加请求头
三、POST请求
四、响应
五、高级用法
(1)文件上传
(3)Session维持
(4)SSL证书验证
(5)超时设置
(6)身份验证
(7)代理设置
(8)Prepared Request
一、安装以及实例引入
(1)requests库下载
win+R打开输入cmd打开window的命令行界面,输入命令:pip install requests
如果想要更新为国内源,可输入命令:pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
(2)实例测试
urllib库中的urlopen方法实际上是以GET方式请求网页,requests库中相应的方法就是get方法,下面通过实例展示一下:
import requests
if __name__ == '__main__':response = requests.get('https://baidu.com')print(type(response))print(response.status_code) # 返回状态码print(type(response.text))print(response.text[:100]) # 返回响应内容print(response.cookies) # 返回cookies响应结果如下:
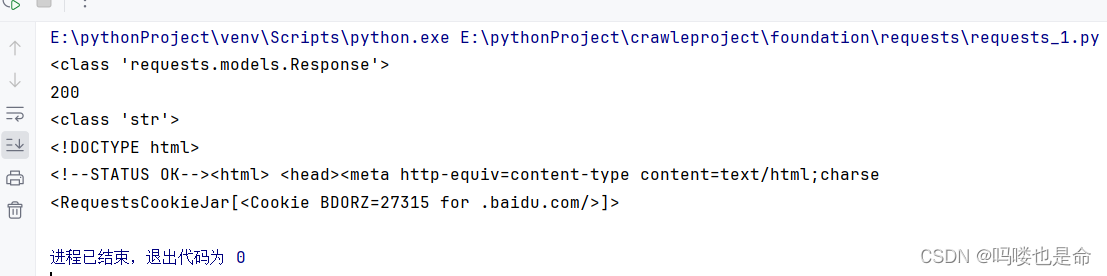
这里我们调用get 方法实现了与urlopen方法相同的操作,返回一个Response对象,并将其赋值在变量response中,然后分别输出了响应的类型、状态码,响应体的类型、内容,以及 Cookie。观察运行结果可以发现,返回的响应类型是 requests.models.Response,响应体的类型是字符str,Cookie 的类型是 RequestsCookieJar。
二、GET请求
HTTP 中最常见的请求之一就是 GET 请求,首先来详细了解一下利用 requests 库构建GET道的方法。
(1)基本实例
下面构建一个最简单的 GET 请求,请求的链接为 https://www.httpsbin.org/get,该网站会判断客端发起的是否为GET 请求,如果是,那么它将返回相应的请求信息:
import requests
if __name__ == '__main__':response = requests.get('https://www.httpbin.org/get')print(response.text)运行结果如下:
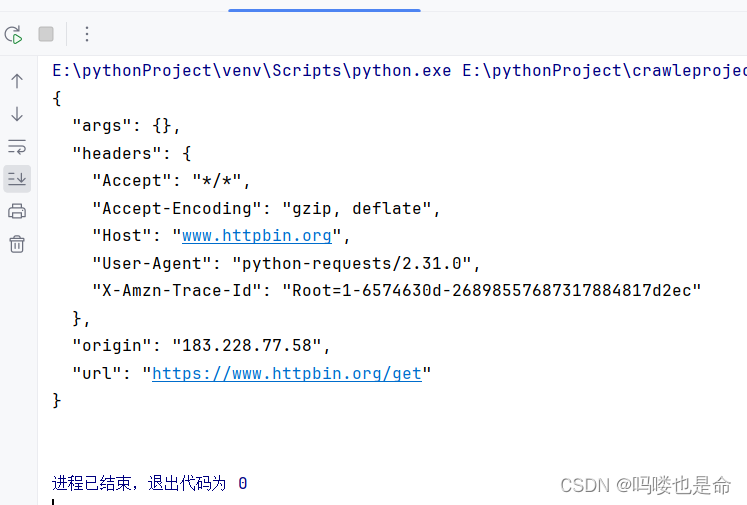
可以发现,我们成功发起了 GET请求,返回结果中包含请求头、URL、IP等信息。
那么,对于GET请求,如果要附加额外的信息,一般怎样添加呢? 例如现在想添加两个参数name和age,其中 name 是 germey、age是 25,于是 URL 就可以写成如下内容:
https://www.https://www.httpbin.org/get?name=germey&age=25
要构造这个请求链接,是不是要直接写成这样呢?
response = requests.get(' https://www.httpbin.org/get?name=germey&age=25')这样也可以,但是看起来有点不人性化哎?这些参数还需要我们手动去拼接,实现起来着实不优雅。
一般情况下,我们利用params 参数就可以直接传递这种信息了, 实例如下:
import requests
if __name__ == '__main__':data = {'name': 'germey','age': 25}response = requests.get('https://www.httpbin.org/get', params=data)print(response.text)运行结果如下:
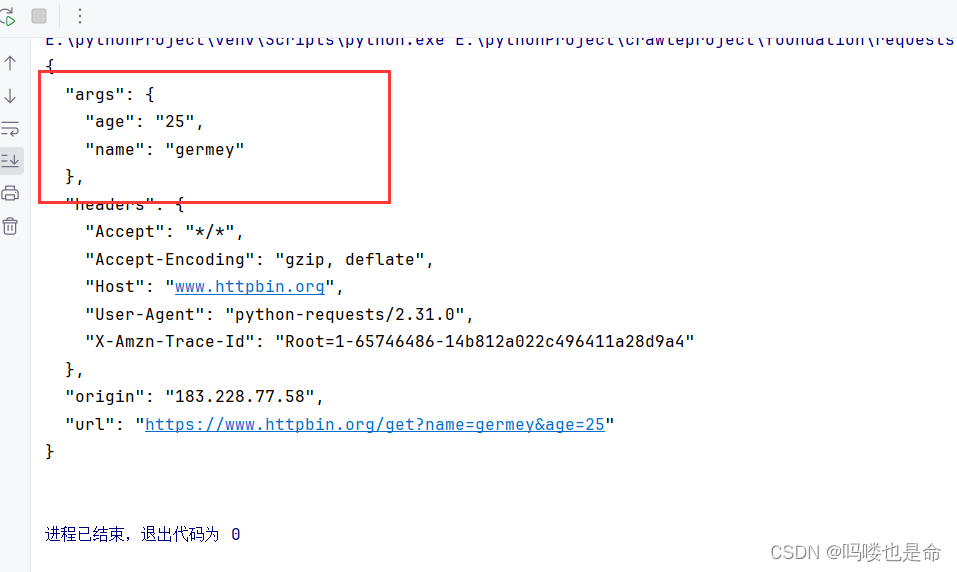
上面我们把URL 参数以字典的形式传给 get方法的params 参数,通过返回信息我们可以判断,请求的链接自动被构造成了 https://www.httpbin.org/get?age=22&name=germey,这样我们就不用自己构造 URL了,非常方便。
另外,网页的返回类型虽然是 str类型,但是它很特殊,是 JSON格式的。所以,如果想直接解析返回结果,得到一个JSON格式的数据,可以直接调用json方法。实例如下:
import requests
if __name__ == '__main__':response = requests.get('https://www.httpbin.org/get')print(type(response.text))print(response.json())print(type(response.json()))运行结果如下:
 可以发现,调用json方法可以将返回结果(JSON格式的字符串)转化为字典。但需要注意的是,如果返回结果不是 JSON 格式, 就会出现解析错误, 抛出 json. decoder.JSONDecodeError 异常。
可以发现,调用json方法可以将返回结果(JSON格式的字符串)转化为字典。但需要注意的是,如果返回结果不是 JSON 格式, 就会出现解析错误, 抛出 json. decoder.JSONDecodeError 异常。
(2)抓取网页
上面的请求链接返回的是JSON格式的字符串,那么如果请求普通的网页, 就肯定能获得相应的内容了。我们以一个实例页面 https://ssr1.scrape.center/ 作为演示,往里面加入一点提取信息的逻辑,将代码完善成如下的样子:
import requests
import re
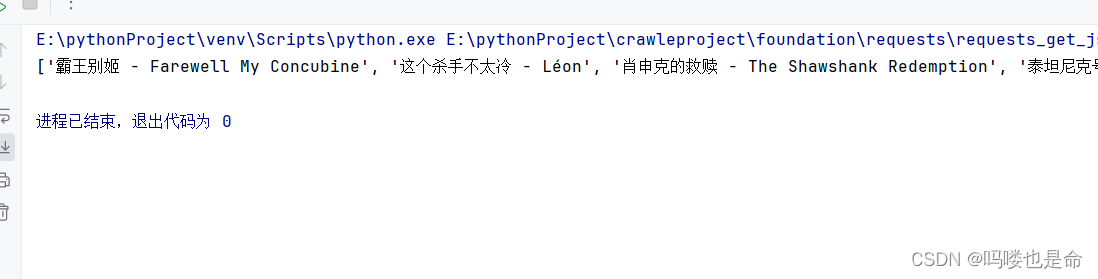
if __name__ == '__main__':response = requests.get('https://ssr1.scrape.center')patten = re.compile('<h2.*?>(.*?)</h2>', re.S)titles = re.findall(patten, response.text)print(titles)这个例子中,我们用最基础的正则表达式来匹配所有的标题内容。关于正则表达式,会在2.3节详细介绍,这里其只作为实例来配合讲解。
运行结果如下:
(3)抓取二进制数据
在上面的例子中,我们抓取的是网站的一个页面,实际上它返回的是一个HTML文档。要是想抓取图片、音频、视频等文件,应该怎么办呢?
图片、音频、视频这些文件本质上都是由二进制码组成的,由于有特定的保存格式和对应的解析方式,我们才可以看到这些形形色色的多媒体。所以,要想抓取它们,就必须拿到它们的二进制数据。下面以示例网站的站点图标为例来看一下:
import requests
if __name__ == '__main__':response = requests.get('https://scrape.center/favicon.ico')print(response.text)print(response.content)这里抓取的内容是站点图标,也就是浏览器中每一个标签上显示的小图标,如图2-3所示。
上述实例将会打印Response对象的两个属性,一个是 text,另一个是content。
运行结果如下:
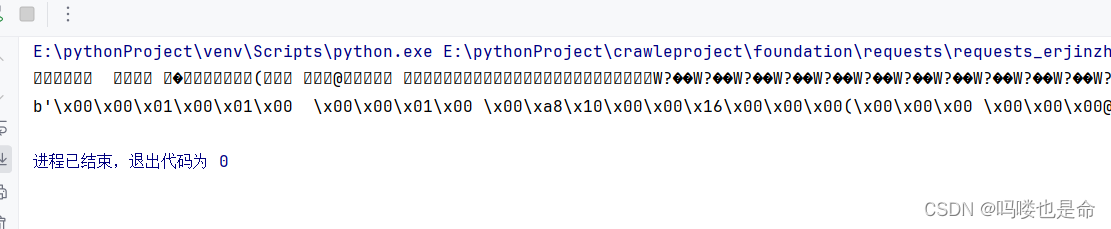
可以注意到,r. text中出现了乱码,r.content的前面带有一个b,代表这是bytes类型的数据。由于图片是二进制数据,所以前者在打印时会转化为 str类型,也就是图片直接转化为字符串,理所当然会出现乱码。上面的运行结果我们并不能看懂,它实际上是图片的二进制数据。不过没关系,我们将刚才提取到的信息保存下来就好了,代码如下:
import requests
if __name__ == '__main__':response = requests.get('https://scrape.center/favicon.ico')with open('favicon.ico', 'wb') as f:f.write(response.content)这里用了 open方法,其第一个参数是文件名称,第二个参数代表以二进制写的形式打开文件,可以向文件里写入二进制数据。上述代码运行结束之后,可以发现在文件夹中出现了名为favicon. ico 的图标,如图所示。这样,我们就把二进制数据成功保存成了一张图片,这个小图标被我们成功爬取下来了。同样地,我们也可以用这种方法获取音频和视频文件。

(4)添加请求头
我们知道,在发起HTTP请求的时候,会有一个请求头Request Headers,那么怎么设置这个请求头呢?很简单,使用headers参数就可以完成了。在刚才的实例中,实际上是没有设置请求头信息的,这样的话,某些网站会发现这并不是一个由正常浏览器发起的请求,于是可能会返回异常结果,导致网页抓取失败。要添加请求头信息,例如这里我们想添加一个User-Agent字段,就可以这么写:
import requests
if __name__ == '__main__':headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36(KHTML, like Gecko)Chrome/52.0.2743.116 Safari/ 537.36'}response = reques当然,可以在这个headers参数中添加任意其他字段信息。
三、POST请求
前面我们了解了最基本的GET请求,另外一种比较常见的请求方式是 POST。使用requests库实现 POST请求同样非常简单,实例如下:
import requests
if __name__ == '__main__':data = {'name': 'germey','age': '25'}response = requests.post('https://www.httpbin.org/post', data=data)print(response.text)这里还是请求 https://www.httpbin.org/post,该网站可以判断请求是否为POST方式,如果是,就返回相关的请求信息。运行结果如下:
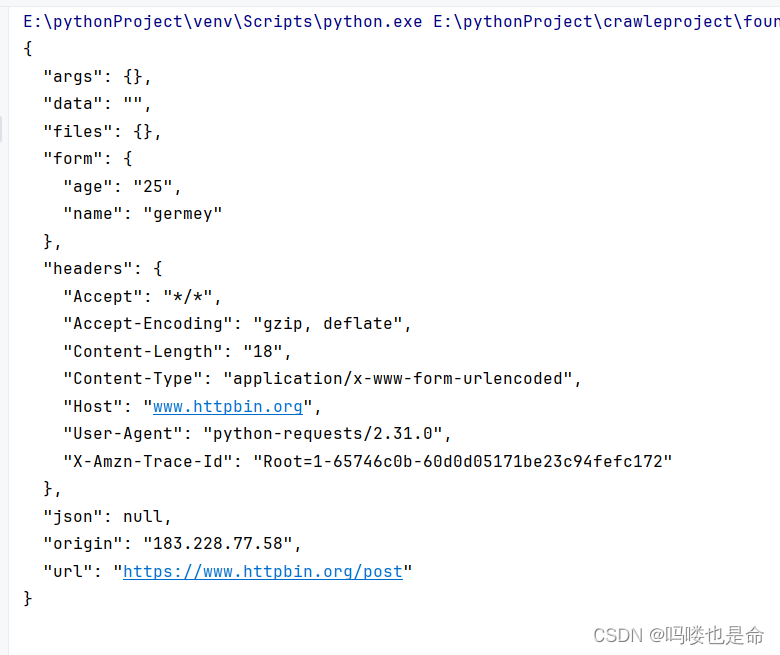
可以发现,我们成功获得了返回结果,其中form部分就是提交的数据,这证明POST请求成功发送了。
四、响应
请求发送后,自然会得到响应。在上面的实例中,我们使用text和content 获取了响应的内容。此外,还有很多属性和方法可以用来获取其他信息,例如状态码、响应头、Cookie等。实例如下:
import requests
if __name__ == '__main__':response = requests.get('https://ssr1.scrape.center/')print(type(response.status_code), response.status_code)print(type(response.headers), response.headers)print(type(response.cookies), response.cookies)print(type(response.url), response.url)print(type(response.history), response.history)
这里通过status_code属性得到状态码、通过headers属性得到响应头、通过 cookies属性得到Cookie、通过 url属性得到 URL、通过 history 属性得到请求历史。并将得到的这些信息分别打印出来。
运行结果如下:
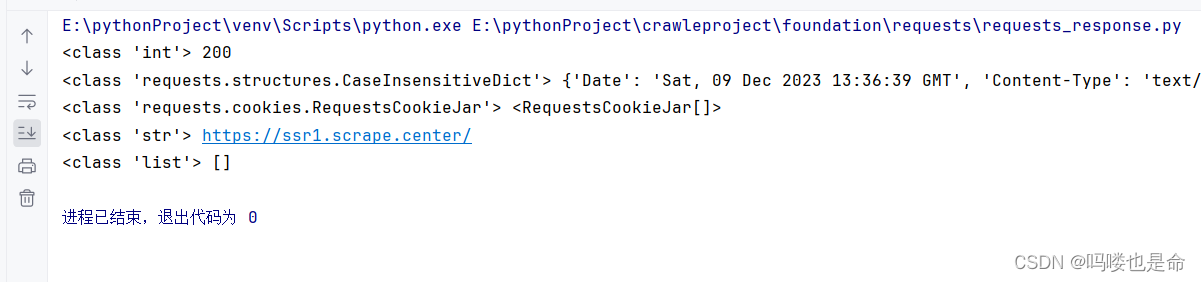
可以看到,headers 和 cookies这两个属性得到的结果分别是 CaseInsensitiveDict和 Requests-CookieJar对象。我们知道,状态码是用来表示响应状态的, 例如200代表我们得到的响应是没问题的,上面例子输出的状态码正好也是200,所以我们可以通过判断这个数字知道爬虫爬取成功了。
requests库还提供了一个内置的状态码查询对象 requests.codes,用法实例如下:
import requests
if __name__ == '__main__':response = requests.get('https://ssr1.scrape.center/')exit() if not response.status_code == requests.codes.ok else print('Requests Successfully')
这里通过比较返回码和内置的表示成功的状态码,来保证请求是否得到了正常响应,如果是,就输出请求成功的消息,否则程序终止运行,这里我们用requests.codes.ok得到的成功状态码是 200。这样我们就不需要再在程序里写状态码对应的数字了,用字符串表示状态码会显得更加直观。当然,肯定不能只有 ok这一个条件码。
下面列出了返回码和相应的查询条件:
# 信息性状态码
100: ('continue',),
101:('switching_protocols',),
102: ('processing',),
103: ('checkpoint',),
122: ('uri_too_long','request_uri_too_long'),
# 成功状态码
200:('ok', 'okay', 'all_ok', 'all_okay','all_good','\\o/','✔'),
201: ('created',),
202: ('accepted',),
203:('non_authoritative_info','non_authoritative_information'),
204: ('no_content',),
205: ('reset_content', 'reset'),
206: ('partial_content', 'partial'),
207:('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'),
208: ('already _ reported',),
226:('im_used',),
# 重定向状态码
300:('multiple_choices',),
301: ('moved_permanently', 'moved', '\\o-'),
302: ('found',),
303:('see_other', 'other'),
304:('not_modified',),
305:('use_proxy',),
306:('switch_proxy',),
307:('temporary_redirect', 'temporary_moved', 'temporary'),
308: ('permanent_redirect',
'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# 客户端错误状态码
400:('bad_request', 'bad'),
401: ('unauthorized',),
402: ('payment_required', 'payment'),
403:('forbidden',),
404:('not_found','-o-'),
405:('method_not_allowed', 'not_allowed'),
406:('not_acceptable',),
407:('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'),
408: ('request_timeout', 'timeout'),
409:('conflict',),
410: ('gone',),
411: ('length_required',),
412:('precondition_failed', 'precondition'),
413: ('request_entity_too_large',),
414: ('request_uri_too_large',),
415:('unsupported_media_type', 'unsupported_media', 'media_type'),
416:('requested_range_not_satisfiable', 'requested_range','range_not_satisfiable'),
417:('expectation_failed',),
418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'),
421: ('misdirected_request',),
422:('unprocessable_entity', 'unprocessable'),
423:('locked',),
424: ('failed_dependency', 'dependency'),
425: ('unordered_collection', 'unordered'),
426: ('upgrade_required', 'upgrade'),
428:('precondition_required', 'precondition'),
429:('too_many_requests', 'too_many'),
431: ('header_fields_too_large', 'fields_too_large'),
444:('no_response', 'none'),
449:('retry_with','retry'),
450:('blocked_by_windows_parental_controls','parental_controls'),
451: ('unavailable_for_legal_reasons','legal_reasons'),
499:('client_closed_request',),
# 服务端错误状态码
500:('internal_server_error','server_error','/o\\', 'x'),
501:('not_implemented',),
502:('bad_gateway',),
503: ('service_unavailable', 'unavailable'),
504:('gateway_timeout',),
505:('http_version_not_supported', 'http_version'),
506:('variant_also_negotiates',),
507:('insufficient_storage',),
509: ('bandwidth_limit_exceeded', 'bandwidth'),
510:('not_extended',),
511: ('network_authentication_required','network_auth','network_authentication')例如想判断结果是不是404状态,就可以用requests.codes.not_found作为内置的状态码做比较。
五、高级用法
(1)文件上传
我们知道使用requests 库可以模拟提交一些数据。除此之外,要是有网站需要上传文件,也可以用它来实现,非常简单,实例如下:
import requests
if __name__ == '__main__':files = {'file': open('favicon.ico', 'rb')}response = requests.post('https://www.httpbin.org/post', files=files)print(response.text)在前面,我们保存了一个文件 favicon.ico,这次就用它来模拟文件上传的过程。需要注意,favicon.ico 需要和当前脚本保存在同一目录下。如果手头有其他文件,当然也可以上传这些文件,更改下代码即可。
运行结果如下:
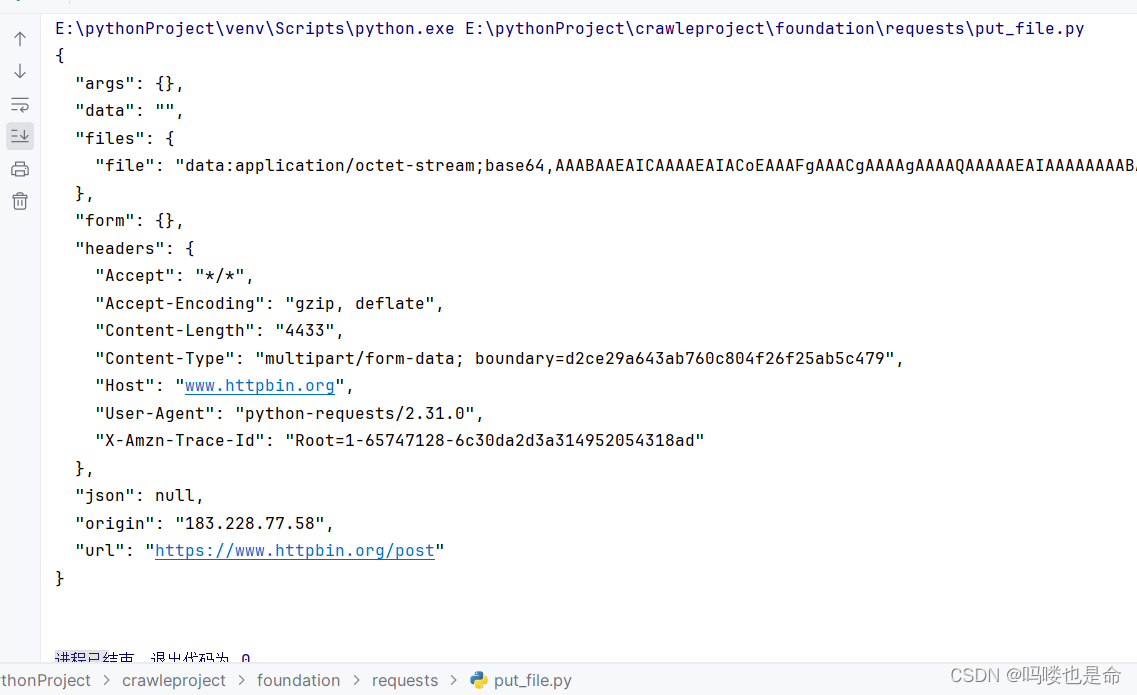
以上结果省略部分内容,上传文件后,网站会返回响应,响应中包含files字段和form字段,而form字段是空的,这证明文件上传部分会单独用一个 files字段来标识。
(2)cookie设置
前面我们使用urllib库处理过Cookie,写法比较复杂,有了requests库以后,获取和设置Cookie 只需一步即可完成。我们先用一个实例看一下获取Cookie 的过程:
import requests
if __name__ == '__main__':response = requests.get('https://www.baidu.com')print(response.cookies)for key, value in response.cookies.items():print(key + '=' + value)运行结果如下:

这里我们首先调用cookies属性,成功得到Cookie,可以发现它属于 RequestCookieJar类型。然后调用items 方法将Cookie 转化为由元组组成的列表,遍历输出每一个 Cookie 条目的名称和值,实现对 Cookie 的避历解析。
当然,我们也可以直接用Cookie来维持登录状态。下面以GitHub为例说明一下,首先我们登录GitHub,然后将请求头中的Cookie 内容复制下来,如图所示。
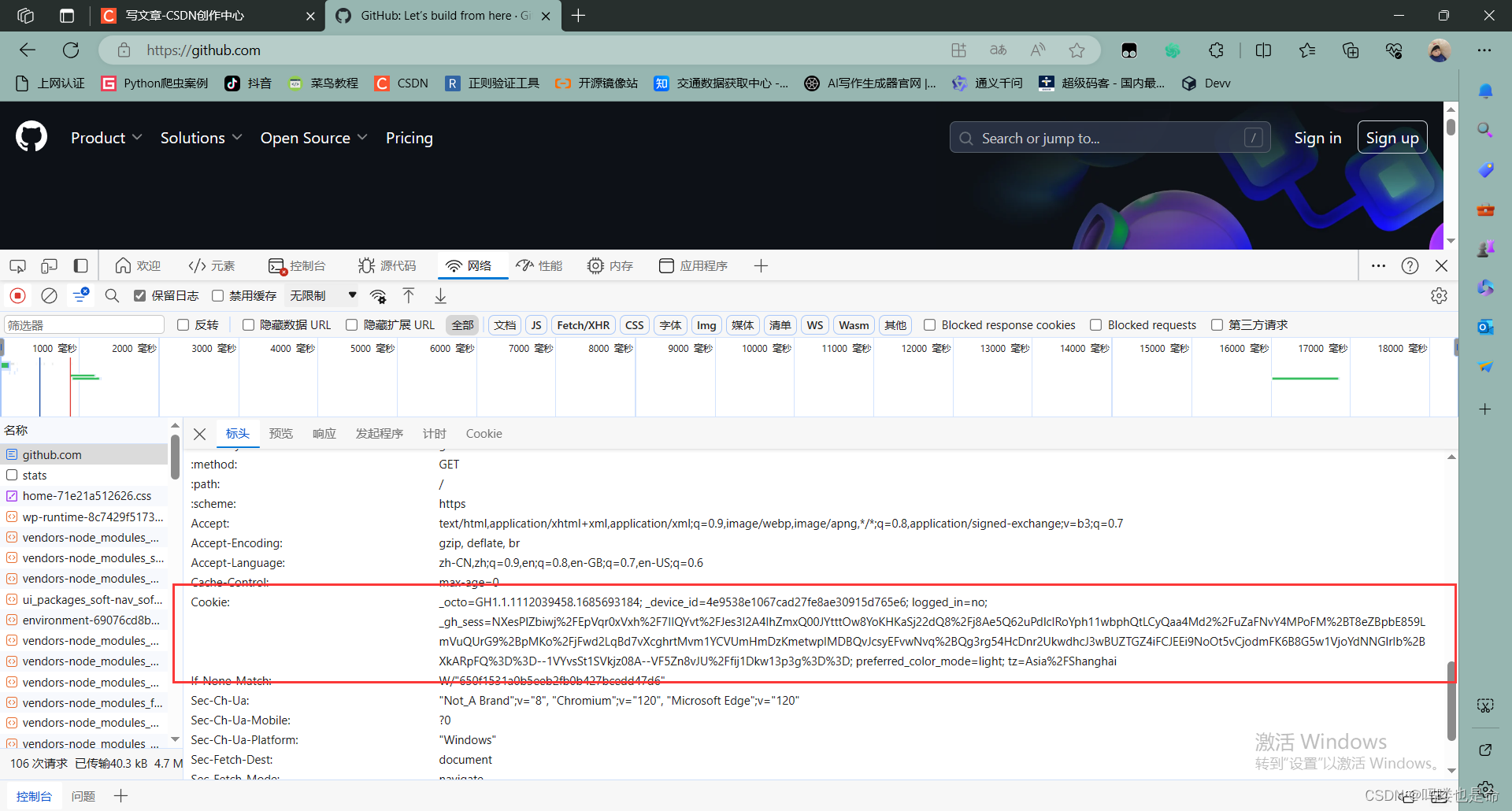
可以将图中框起来的这部分内容替换成你自己的Cookie,将其设置到请求头里面,然后发送请求,实例如下:
import requests
if __name__ == '__main__':headers = {'Cookie': '_octo=GH1.1.1112039458.1685693184; _device_id=4e9538e1067cad27fe8ae30915d765e6; logged_in=no; _gh_sess=NXesPlZbiwj%2FEpVqr0xVxh%2F7IIQYvt%2FJes3I2A4IhZmxQ00JYtttOw8YoKHKaSj22dQ8%2Fj8Ae5Q62uPdlcIRoYph11wbphQtLCyQaa4Md2%2FuZaFNvY4MPoFM%2BT8eZBpbE859LmVuQUrG9%2BpMKo%2FjFwd2LqBd7vXcghrtMvm1YCVUmHmDzKmetwpIMDBQvJcsyEFvwNvq%2BQg3rg54HcDnr2UkwdhcJ3wBUZTGZ4iFCJEEi9NoOt5vCjodmFK6B8G5w1VjoYdNNGlrIb%2BXkARpFQ%3D%3D--1VYvsSt1SVkjz08A--VF5Zn8vJU%2Ffij1Dkw13p3g%3D%3D; preferred_color_mode=light; tz=Asia%2FShanghai'}response = requests.get('https://github.com/', headers=headers)print(response.text)运行结果如下:
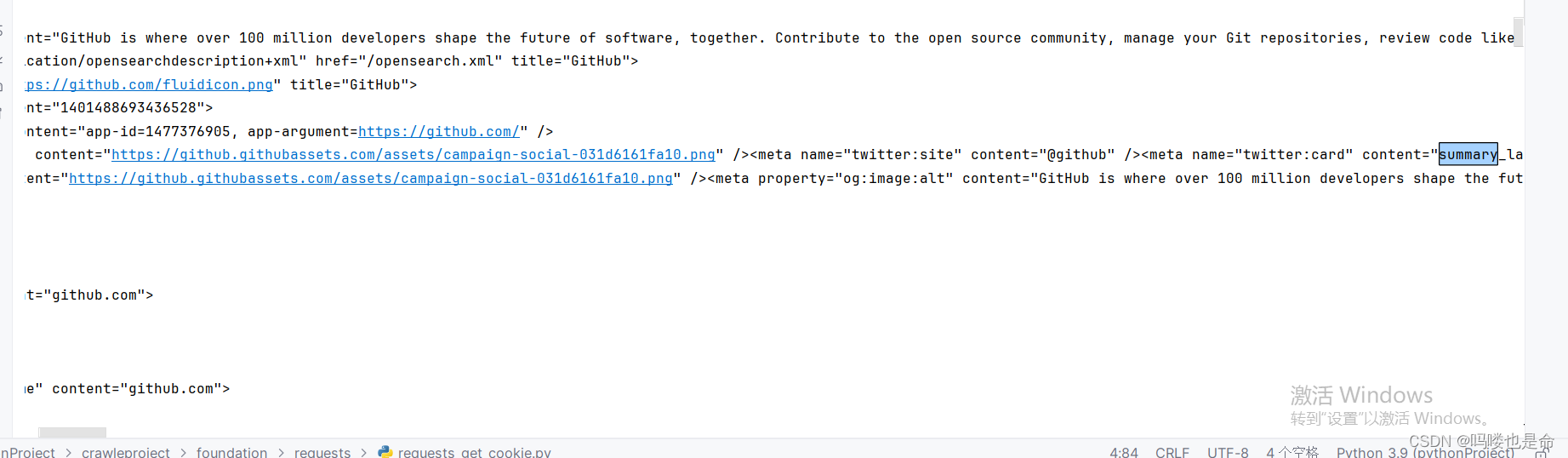
可以发现,结果中包含了登录后才能包含的结果,其中有GitHub用户名信息,你如果尝试一下,同样可以得到你的用户信息。得到这样类似的结果,说明用Cookie 成功模拟了登录状态,这样就能爬取登录之后才能看到的页面了。
(3)Session维持
直接利用requests库中get或post 方法的确可以做到模拟网页的请求,但这两种方法实际上相当于不同的Session,或者说是用两个浏览器打开了不同的页面。设想这样一个场景,第一个请求利用requests 库的 post方法登录了某个网站,第二次想获取成功登录后的自己的个人信息,于是又用了一次 requests 库的 get方法去请求个人信息页面。这实际相当于打开了两个浏览器,是两个完全独立的操作,对应两个完全不相关的Session,那么能够成功获取个人信息吗? 当然不能。有人可能说,在两次请求时设置一样的 Cookie 不就行了?可以,但这样做显得很烦琐,我们有更简单的解决方法。
究其原因,解决这个问题的主要方法是维持同一个Session,也就是第二次请求的时候是打开一个新的浏览器选项卡而不是打开一个新的浏览器。但是又不想每次都设置Cookie,该怎么办呢?这时候出现了新的利器——Session对象。利用Session对象,我们可以方便地维护一个Session,而且不用担心Cookie的问题,它会自动帮我们处理好。
我们先做一个小实验吧,如果沿用之前的写法,实例如下:
import requests
if __name__ == '__main__':requests.get('https://www.httpbin.org/cookies/set/number/123456789')response = requests.get('https://www.httpbin.org/cookies')print(response.text)这里我们请求了一个测试网址 https://www.httpsbin.org/cookies/set/number/123456789 。请求这个网址时,设置了一个Cookie条目,名称是number,内容是123456789。随后又请求了 https://www.httpbin.org/cookies,以获取当前的 Cookie 信息。这样能成功获取设置的 Cookie 吗? 试试看。
运行结果如下:

我们再使用刚才所说的Session试试看:
import requests
if __name__ == '__main__':s = requests.Session()s.get('https://www.httpbin.org/cookies/set/number/123456789')response = s.get('https://www.httpbin.org/cookies')print(response.text)运行结果如下:
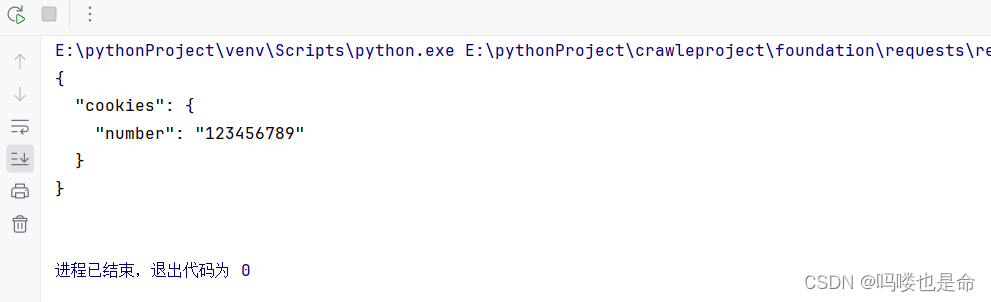
可以看到Cookie 被成功获取了!这下能体会到同一个Session和不同 Session的区别了吧!所以,利用Session可以做到模拟同一个会话而不用担心 Cookie 的问题,它通常在模拟登录成功之后,进行下一步操作时用到。Session 在平常用得非常广泛,可以用于模拟在一个浏览器中打开同一站点的不同页面。
(4)SSL证书验证
现在很多网站要求使用HTTPS协议,但是有些网站可能并没有设置好HTTPS证书,或者网站的HTTPS证书可能并不被CA机构认可,这时这些网站就可能出现SSL证书错误的提示。例如这个实例网站: https://ssr2.scrape.center/,如果用Chrome浏览器打开它,则会提示“您的连接不是私密连接”这样的错误,如图所示。

我们可以在浏览器中通过一些设置来忽略证书的验证。但是如果想用requests 库来请求这类网站,又会遇到什么问题呢? 我们用代码试一下:
import requests
if __name__ == '__main__':response = requests.get('https://ssr2.scrape.center/')print(response.status_code)运行结果如下:
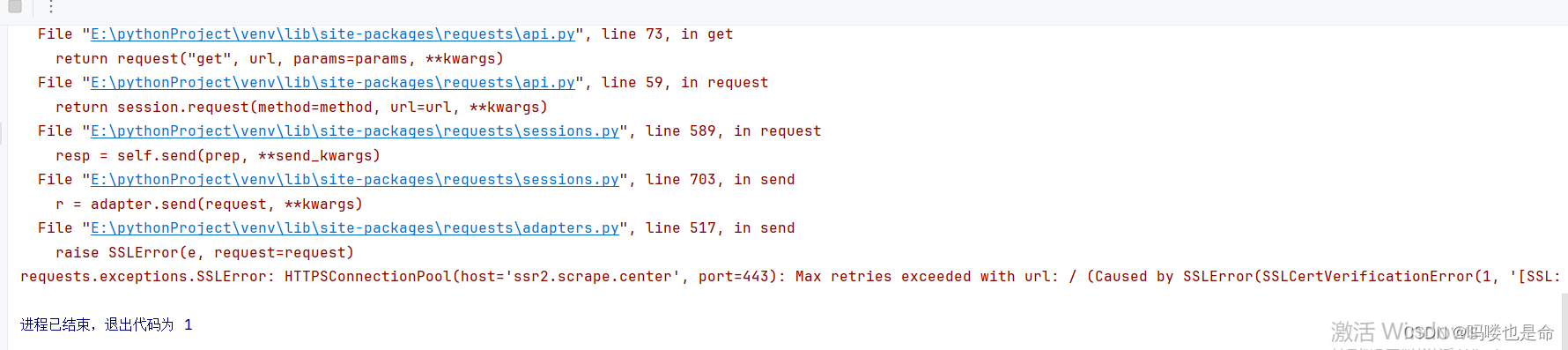
可以看到,直接抛出了 SSLError错误,原因是我们请求的 URL的证书是无效的。
那如果我们一定要爬取这个网站,应该怎么做呢?可以使用 verify 参数控制是否验证证书,如果将此参数设置为 False,那么在请求时就不会再验证证书是否有效。如果不设置 verify参数, 其默认值是 True,会自动验证。于是我们改写代码如下:
import requests
if __name__ == '__main__':response = requests.get('https://ssr2.scrape.center/', verify=False)print(response.status_code)运行结果如下:
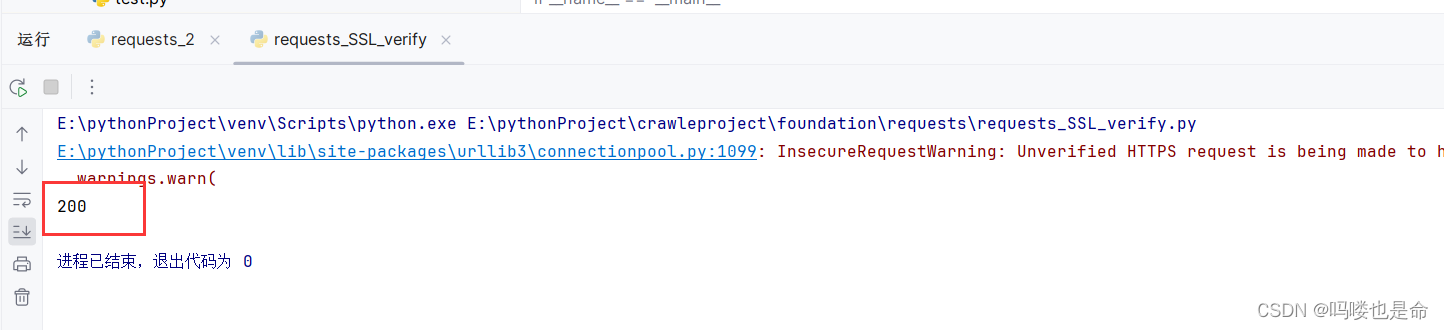
不过我们发现其中报了一个警告,它建议我们给它指定证书。我们可以通过设置忽略警告的方式来屏蔽这个警告:
import requests
import urllib3
if __name__ == '__main__':urllib3.disable_warnings()response = requests.get('https://ssr2.scrape.center/', verify=False)print(response.status_code)或者通过捕获警告到日志的方式忽悠警告:
import logging
import requests
if __name__ == '__main__':logging.captureWarnings(True)response = requests.get('https://ssr2.scrape.center/', verify=False)print(response.status_code)运行结果如下:

当然,我们也可以指定一个本地证书用作客户端证书,这可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组:
import requestsresponse = requests.get(' https://ssr2.scrape.center/',cert=('/path/server.crt','/path/server.key'))print(response. status_code)当然,上面的代码是演示实例,我们需要有crt和key文件,并且指定它们的路径。另外注意,本地私有证书的key必须是解密状态,加密状态的 key是不支持的。
(5)超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才能接收到响应,甚至到最后因为接收不到响应而报错。为了防止服务器不能及时响应,应该设置一个超时时间,如果超过这个时间还没有得到响应,就报错。这需要用到 timeout参数, 其值是从发出请求到服务器返回响应的时间。实例如下:
import requests
if __name__ == '__main__':response = requests.get('https://www.httpbin.org/get', timeout=1)print(response.status_code)通过这样的方式,我们可以将超时时间设置为1秒,意味着如果1秒内没有响应, 就抛出异常。实际上,请求分为两个阶段: 连接(connect)和读取(read)。上面设置的 timeout 是用作连接和读取的 timeout 的总和。如果要分别指定用作连接和读取的 timeout, 则可以传入一个元组:
response = requests.get(' https://www.httpbin.org/get',timeout=(5,30))如果想永久等待,可以直接将timeout设置为None,或者不设置直接留空,因为默认取值是 None。这样的话,如果服务器还在运行,只是响应特别慢, 那就慢慢等吧,它永远不会返回超时错误的。其用法如下:
response = requests.get(' https://www.httpbin.org/get',timeout=None)或直接不加参数:
response = requests.get(' https://www.httpbin.org/get')(6)身份验证
在访问启用了基本身份认证的网站时(例如 https://ssr3.scrape.center/),首先会弹出一个认证窗口,如图所示。
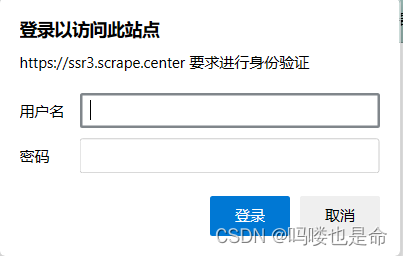
这个网站就是启用了基本身份认证,2.1节我们可以利用urllib库来实现身份的校验,但实现起来相对烦琐。那在requests库中怎么做呢?当然也有办法。我们可以使用requests 库自带的身份认证功能,通过 auth参数即可设置,实例如下:
import requests
from requests.auth import HTTPBasicAuth
if __name__ == '__main__':response = requests.get('https://ssr3.scrape.center/', auth=HTTPBasicAuth('admin', 'admin'))print(response.status_code)这个实例网站的用户名和密码都是 admin,在这里我们可以直接设置。
如果用户名和密码正确,那么请求时就会自动认证成功,返回200状态码;如果认证失败,则返回401状态码。当然,如果参数都传一个 HTTPBasicAuth类,就显得有点烦琐了,所以 requests 库提供了一个更简单的写法,可以直接传一个元组,它会默认使用HTTPBasicAuth这个类来认证。所以上面的代码可以直接简写如下:
import requests
if __name__ == '__main__':response = requests.get('https://ssr3.scrape.center/', auth=('admin', 'admin'))print(response.status_code)(7)代理设置
某些网站在测试的时候请求几次,都能正常获取内容。但是一旦开始大规模爬取,面对大规模且频繁的请求时,这些网站就可能弹出验证码,或者跳转到登录认证页面,更甚者可能会直接封禁客户端的 IP,导致在一定时间段内无法访问。那么,为了防止这种情况发生,我们需要设置代理来解决这个问题,这时就需要用到 proxies参数。可以用这样的方式设置:
import requests
if __name__ == '__main__':proxies = {'http': 'http://10.10.10.10:1080','https': 'https://10.10.10.10:1080'}requests.get('https://www.httpbin.org/get', proxies=proxies)当然,直接运行这个实例可能不行,因为这个代理可能是无效的,可以直接搜索寻找有效的代理并替换试验一下。若代理需要使用上文所述的身份认证,可以使用类似 http://user:password@host:port 这样的语法来设置代理,实例如下:
import requests
if __name__ == '__main__':proxies = {'https': 'http://user:password@10.10.10.10:1080/',}requests.get('https://www.httpbin.org/get',proxies=proxies)除了基本的 HTTP代理外,requests库还支持SOCKS协议的代理。首先,需要安装socks这个库:pip3 install "requests[socks]" 然后就可以使用SOCKS协议代理了,实例如下:
import requests
if __name__ == '__main__':proxies = {'http': 'socks5://user:password@host:port','https':'socks5://user:password@host:port'}requests.get('https://www.httpbin.org/get',proxies=proxies)(8)Prepared Request
我们当然可以直接使用requests 库的 get 和 post 方法发送请求,但有没有想过,这个请求在requests内部是怎么实现的呢?实际上, requests 在发送请求的时候,是在内部构造了一个 Request 对象,并给这个对象赋予了各种参数,包括url、headers、data等,然后直接把这个Request 对象发送出去,请求成功后会再得到一个Response对象,解析这个对象即可。那么Request 对象是什么类型呢?实际上它就是 Prepared Request。我们深入一下,不用get 方法,直接构造一个Prepared Request 对象来试试,代码如下:
from requests import Request, Session
if __name__ == '__main__':url = 'https://www.httpbin.org/post'data = {'name': 'germey'}headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36(KHTML, like Gecko)Chrome/52.0.2743.116 Safari/ 537.36'}s = Session()req = Request('Post', url ,data=data, headers=headers)prepped = s.prepare_request(req)response = s.send(prepped)print(response.text) 我们这里引入了Request 类,然后用 url、data和 headers参数构造了一个Request对象,这时需要再调用Session类的 prepare_request 方法将其转换为一个 Prepared Request对象,再调用 send方法发送,运行结果如下: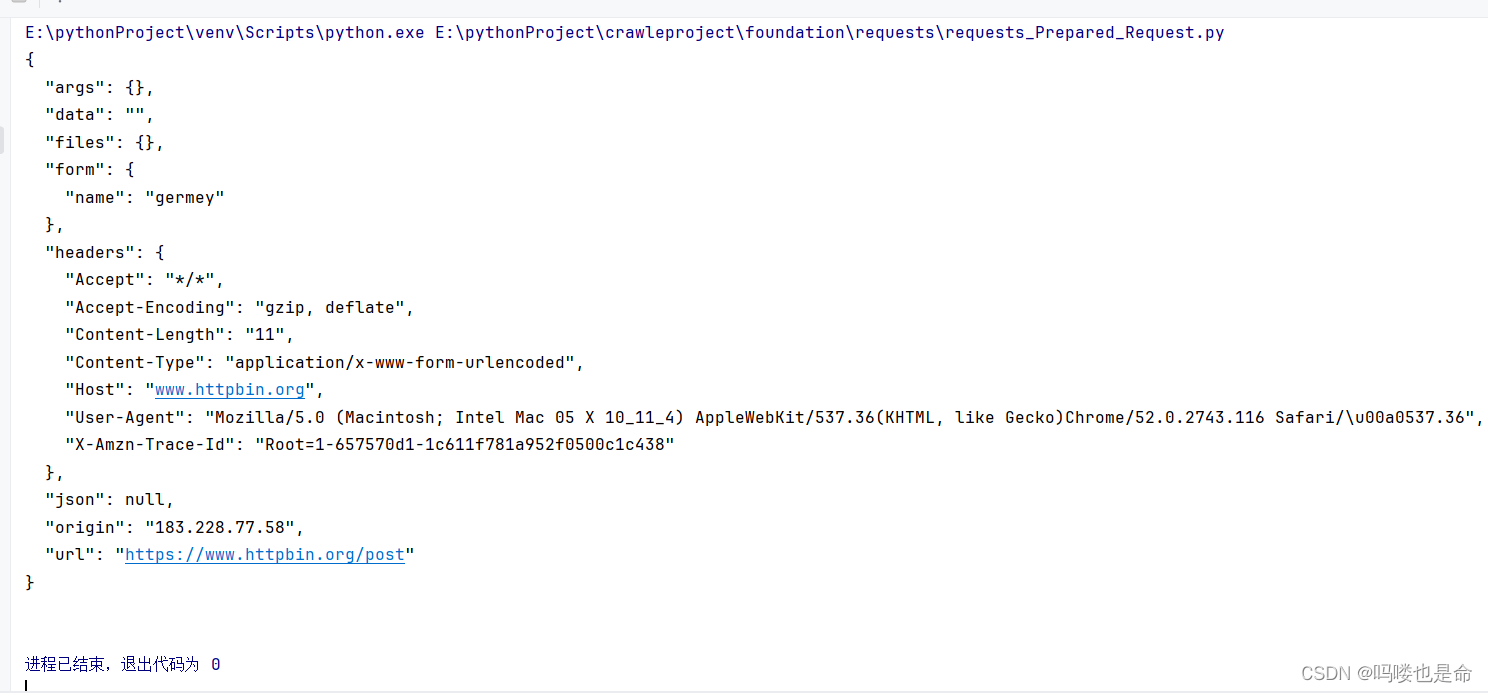
可以看到,我们达到了与POST请求同样的效果。有了 Request 这个对象, 就可以将请求当作独立的对象来看待,这样在一些场景中我们可以直接操作这个Request对象,更灵活地实现请求的调度和各种操作。
相关文章:
爬虫学习-基础库的使用(requests)
目录 一、安装以及实例引入 (1)requests库下载 (2)实例测试 二、GET请求 (1)基本实例 (2)抓取网页 (3)抓取二进制数据 (4)添…...
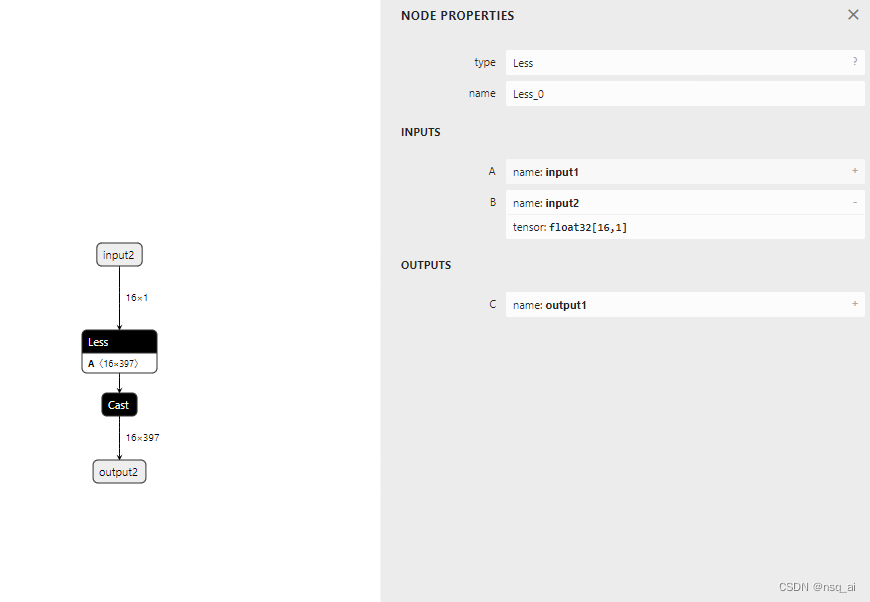
4.8 构建onnx结构模型-Less
前言 构建onnx方式通常有两种: 1、通过代码转换成onnx结构,比如pytorch —> onnx 2、通过onnx 自定义结点,图,生成onnx结构 本文主要是简单学习和使用两种不同onnx结构, 下面以 Less 结点进行分析 方式 方法一&a…...

Java调试技巧之垃圾回收机制解析
Java作为一种高级编程语言,以其跨平台、面向对象、自动内存管理等特性而广受开发者的喜爱。其中,自动内存管理是Java的一大亮点,通过垃圾回收机制实现对内存的自动分配和释放,极大地简化了开发者的工作。本文将深入探讨Java的垃圾…...
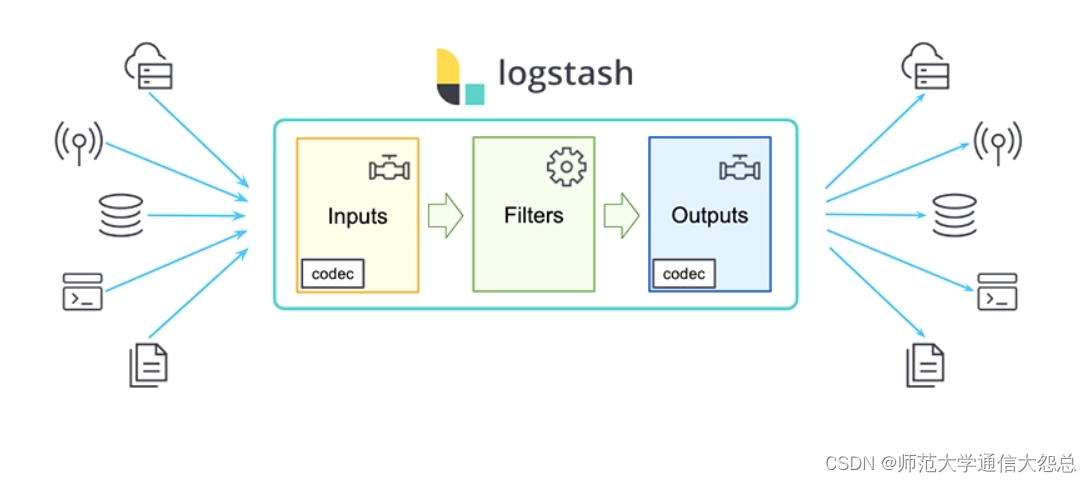
logstash插件简单介绍
logstash插件 输入插件(input) Input:输入插件。 Input plugins | Logstash Reference [8.11] | Elastic 所有输入插件都支持的配置选项 SettingInput typeRequiredDefaultDescriptionadd_fieldhashNo{}添加一个字段到一个事件codeccodecNoplain用于输入数据的…...
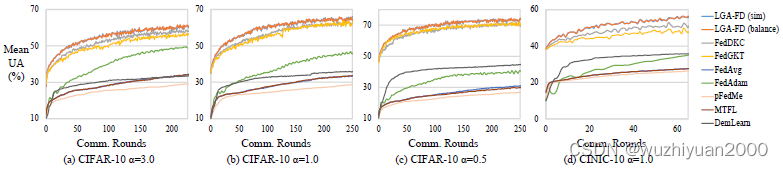
联邦多任务蒸馏助力多接入边缘计算下的个性化服务 | TPDS 2023
联邦多任务蒸馏助力多接入边缘计算下的个性化服务 | TPDS 2023 随着移动智能设备的普及和人工智能技术的发展,越来越多的分布式数据在终端被产生与收集,并以多接入边缘计算(MEC)的形式进行处理和分析。但是由于用户的行为模式与服务需求的多样,不同设备上的数据分布…...

【python爬虫】设计自己的爬虫 3. 文件数据保存封装
考虑到爬取的多媒体文件要保存到本地,因此封装了一个类来专门处理这样的问题,下面看代码: class FileStore:def __init__(self, file_path, read_file_moder,write_file_modewb):"""初始化 FileStore 实例Parameters:- file_…...
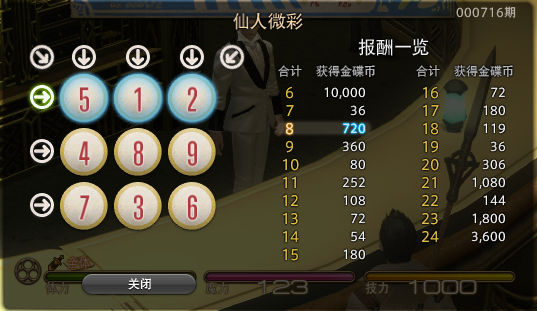
pta模拟题——7-34 刮刮彩票
“刮刮彩票”是一款网络游戏里面的一个小游戏。如图所示: 每次游戏玩家会拿到一张彩票,上面会有 9 个数字,分别为数字 1 到数字 9,数字各不重复,并以 33 的“九宫格”形式排布在彩票上。 在游戏开始时能看见一个位置上…...

【补题】 1
蓝桥杯小白赛 3.小蓝的金牌梦【算法赛】 - 蓝桥云课 (lanqiao.cn) 数组长度为质数,最大的子数组和 素数 前缀和 #include "bits/stdc.h" using namespace std; #define int long long #define N 100010 int ans[N];int s[N];vector&l…...

IP地址定位技术为网络安全建设提供全新方案
随着互联网的普及和数字化进程的加速,网络安全问题日益引人关注。网络攻击、数据泄露、欺诈行为等安全威胁层出不穷,对个人隐私、企业机密和社会稳定构成严重威胁。在这样的背景下,IP地址定位技术应运而生,为网络安全建设提供了一…...
Redis中HyperLogLog的使用
目录 前言 HyperLogLog 前言 在学习HyperLogLog之前,我们需要先学习两个概念 UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。PV&am…...

新版Spring Security6.2架构 (一)
Spring Security 新版springboot 3.2已经集成Spring Security 6.2,和以前会有一些变化,本文主要针对官网的文档进行一些个人翻译和个人理解,不对地方请指正。 整体架构 Spring Security的Servlet 支持是基于Servelet过滤器,如下…...

名字的漂亮度
给出一个字符串,该字符串仅由小写字母组成,定义这个字符串的“漂亮度”是其所有字母“漂亮度”的总和。 每个字母都有一个“漂亮度”,范围在1到26之间。没有任何两个不同字母拥有相同的“漂亮度”。字母忽略大小写。给出多个字符串࿰…...

机器学习基本概念2
资料来源: https://www.youtube.com/watch?vYe018rCVvOo&listPLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J&index1 https://www.youtube.com/watch?vbHcJCp2Fyxs&listPLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J&index2 分三步 1、 定义function b和w是需要透…...
—— Spring Cloud Alibaba 之 Nacos 2.3.0 史上最大更新版本发布)
Spring Cloud 与微服务学习总结(19)—— Spring Cloud Alibaba 之 Nacos 2.3.0 史上最大更新版本发布
Nacos 一个用于构建云原生应用的动态服务发现、配置管理和服务管理平台,由阿里巴巴开源,致力于发现、配置和管理微服务。说白了,Nacos 就是充当微服务中的的注册中心和配置中心。 Nacos 2.3.0 新特性 1. 反脆弱插件 Nacos 2.2.0 版本开始加入反脆弱插件,从 2.3.0 版本开…...

八、C#笔记
/// <summary> /// 第十三章:创建接口和定义抽象类 /// </summary> namespace Chapter13 { class Program { static void Main(string[] args) { //13.1理解接口 ///13.1.1定义接口 ///…...
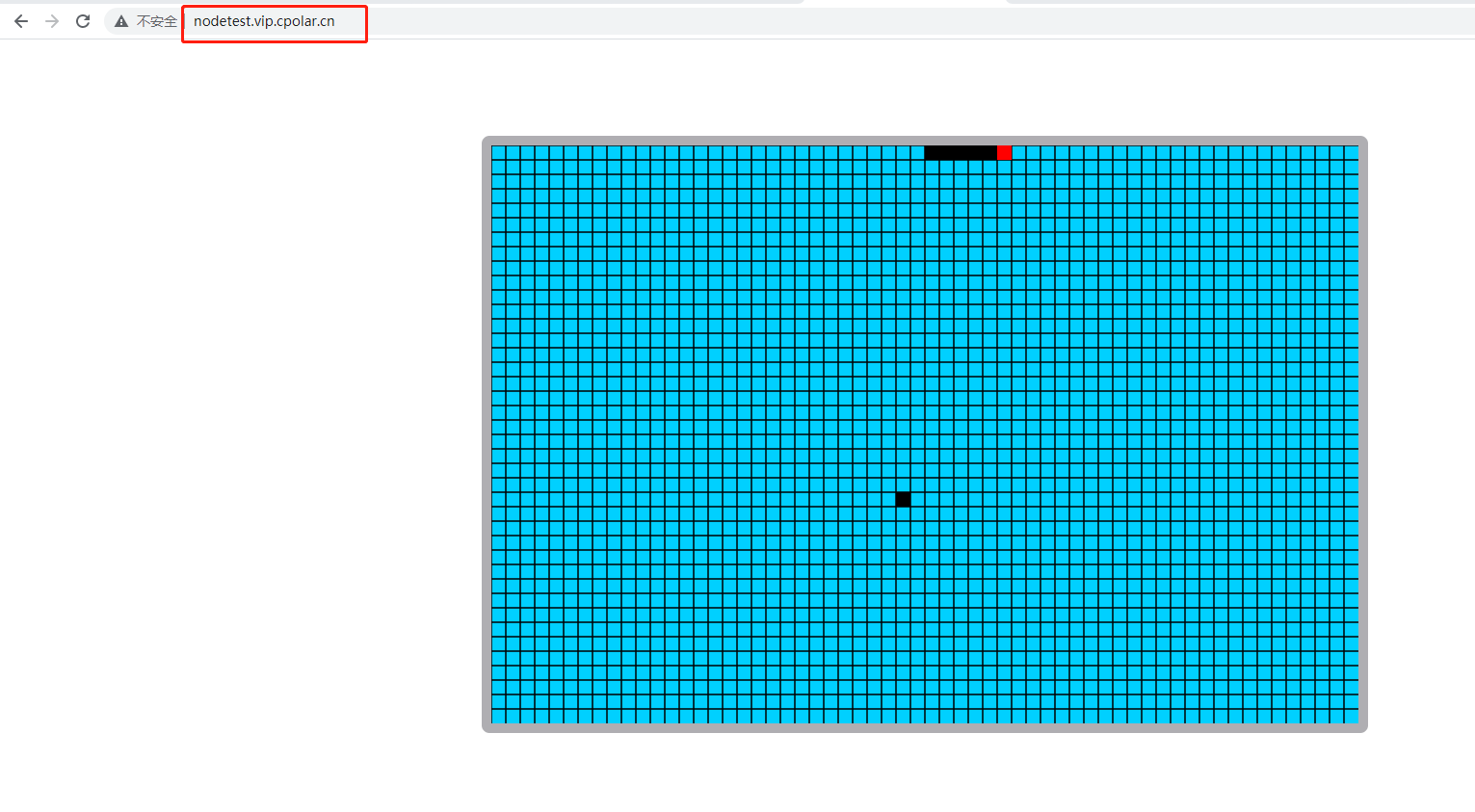
利用Node.js和cpolar实现远程访问,无需公网IP和路由器设置的完美解决方案
文章目录 前言1.安装Node.js环境2.创建node.js服务3. 访问node.js 服务4.内网穿透4.1 安装配置cpolar内网穿透4.2 创建隧道映射本地端口 5.固定公网地址 前言 Node.js 是能够在服务器端运行 JavaScript 的开放源代码、跨平台运行环境。Node.js 由 OpenJS Foundation࿰…...

C++如何通过调用ffmpeg接口对H264文件进行编码和解码
C可以通过调用FFmpeg的API来对H264文件进行编码和解码。下面是一个简单的例子。 首先需要在代码中包含FFmpeg的头文件: extern "C" { #include <libavcodec/avcodec.h> #include <libavformat/avformat.h> #include <libswscale/swscale…...
使用MetaMask + Ganache搭建本地私有网络并实现合约部署与互动
我使用Remix编写合约,MetaMask钱包工具和Ganache搭建了一个私有网络,并且实现了合约的部署和互动。 在前面的博客中提到了 Remix在线环境及钱包申请 以及 Solidity的基本语法 ,没看过的小伙伴可以点击链接查看一下,都是在本专栏下…...
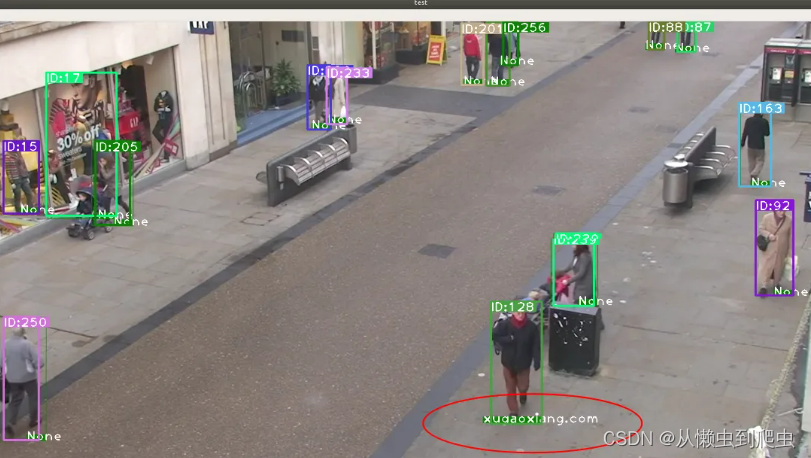
目标检测、目标跟踪、重识别
文章目录 环境前言项目复现特征提取工程下载参考资料 环境 ubuntu 18.04 64位yolov5deepsortfastreid 前言 基于YOLOv5和DeepSort的目标跟踪 介绍过针对行人的检测与跟踪。本文介绍另一个项目,结合 FastReid 来实现行人的检测、跟踪和重识别。作者给出的2个主…...

高防IP防御效果怎么样,和VPN有区别吗
高防IP主要是用于防御网络攻击,可以抵御各种类型的DDoS攻击,隐藏源IP地址,提高网络安全性和用户体验。主要目的是解决外部网络攻击问题,保护网络安全,避免因攻击而导致的业务中断和数据泄露等问题。 而VPN则是一种可以…...
)
STM32F4网口实战:用CubeMX+LwIP+LAN8720A实现DHCP自动获取IP(附完整代码)
STM32F4以太网开发实战:基于CubeMX与LwIP的DHCP自动组网方案 当我们需要为嵌入式设备添加网络连接功能时,以太网接口往往是最可靠的选择之一。STM32F4系列微控制器内置了以太网MAC控制器,配合外部的PHY芯片如LAN8720A,可以快速构建…...

taotoken的按token计费模式如何帮助个人开发者控制实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的按Token计费模式如何帮助个人开发者控制实验成本 对于个人开发者、学生或独立研究者而言,在探索AI应用或进行…...

企业AI编程效率提升:2026最新权威AI编程工具必看
企业AI编程效率提升:2026最新权威AI编程工具必看开篇“企业研发团队效率低下,核心项目交付周期长,如何通过AI编程工具缩短开发周期、提升ROI?”“企业部署AI编程工具,如何兼顾安全合规、代码质量与开发效率,…...

MDK中间件与RTOS依赖关系及嵌入式开发实践
1. MDK中间件与RTOS的依赖关系解析在嵌入式开发领域,Keil MDK(Microcontroller Development Kit)是ARM架构微控制器开发的经典工具链。其Middleware(中间件)库为开发者提供了网络协议栈、USB协议栈、文件系统等常用功能…...

为小型创业团队搭建经济可控的大模型应用开发平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为小型创业团队搭建经济可控的大模型应用开发平台 对于资源有限的创业团队而言,在拥抱大模型技术的同时,必…...
TsubakiTranslator:如何用免费工具打破Galgame语言壁垒的终极指南
TsubakiTranslator:如何用免费工具打破Galgame语言壁垒的终极指南 【免费下载链接】TsubakiTranslator 一款Galgame文本翻译工具,支持Textractor/剪切板/OCR翻译 项目地址: https://gitcode.com/gh_mirrors/ts/TsubakiTranslator 还在为看不懂日语…...

VideoDownloadHelper:打破视频下载壁垒的智能浏览器插件
VideoDownloadHelper:打破视频下载壁垒的智能浏览器插件 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 在信息爆炸的时代&#x…...

嵌入式气体传感器模组选型、集成与工程实践全解析
1. 项目概述:从“感知”到“决策”的桥梁在工业自动化、环境监测乃至我们日常的智能家居设备里,气体传感器模组正扮演着越来越关键的角色。它不像一个独立的传感器探头那么简单,而是一个集成了传感元件、信号调理、数据处理甚至通讯接口的完整…...

终极Ghidra逆向工程指南:30分钟从零掌握二进制分析
终极Ghidra逆向工程指南:30分钟从零掌握二进制分析 【免费下载链接】ghidra Ghidra is a software reverse engineering (SRE) framework 项目地址: https://gitcode.com/GitHub_Trending/gh/ghidra Ghidra作为一款由美国国家安全局(NSAÿ…...

Tigshop 开源商城系统 JAVA v5.8.28 版本发布|『角色权限管理+店铺后台跳转逻辑』优化
全新迭代!Tigshop 开源商城系统 JAVA v5.8.28 版本强势上线!直击后台权限配置繁琐、跳转场景不精准两大痛点,『角色权限管理店铺后台跳转逻辑』同步优化,实现管理员权限与角色联动、店铺/门店后台精准跳转店铺/门店首页࿰…...