k8s集群部分使用gpu资源的pod出现UnexpectedAdmissionError问题
记录一次排查UnexpectedAdmissionError问题的过程
1. 问题
环境
3master节点+N个GPU节点
kubelet版本:v1.19.4
kubernetes版本:v1.19.4
生产环境K8S集群,莫名其妙的出现大量UnexpectedAdmissionError状态的Pod,导致部分任务执行异常,出现这种情况时,节点的资源是足以支持运行一个GPU Pod的。
报的错误:
Allocate failed due to requested number of devices unavailable for nvidia.com/gpu. Requested: 1, Available: 0, which is unexpected
因为Pod的调度都是指定了spec.nodeName属性的,所以跳过了Pending状态强制进行调度,在资源不足的情况下,就出现了UnexpectedAdmissionError异常。
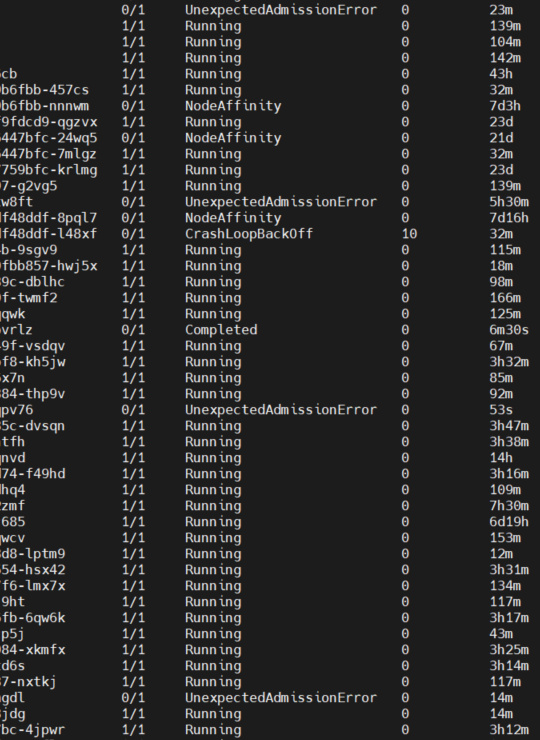
2.排查过程
确定节点资源是否正常
kubectl describe node <node-name>
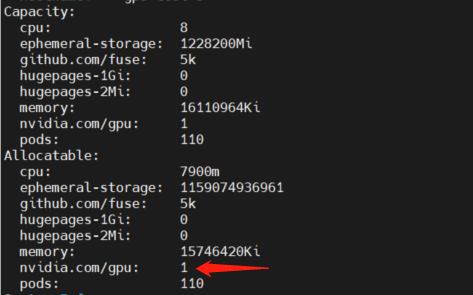
通过describe命令可以看到节点的GPU卡是正常的,然后可以去节点上通过nvidia-dcgm,确定GPU设备是否健康
nvidia-dcgm:nvidia官网
在确定节点和GPU设备都是没问题的情况下,那么开始排查出现问题的原因
通过查看日志和源码,可以定位到日志是在manager.go#devicesToAllocate方法的698行出现
// resource=nvidia.com/gpu// Gets Devices in use.devicesInUse := m.allocatedDevices[resource]// Gets Available devices.available := m.healthyDevices[resource].Difference(devicesInUse)if available.Len() < needed {return nil, fmt.Errorf("requested number of devices unavailable for %s. Requested: %d, Available: %d", resource, needed, available.Len())}
也就是,从健康的GPU集合中去除了已使用的GPU后,可用GPU数量少于所需要的数量,但是通过上面的排查,在创建的Pod.cm.resource.limit:nvidia.com/gpu=1的情况下,理论上应该是成功的,这里出现了报错,那么肯定是GPU卡被占用了。
查看kubelet日志,定位具体问题,日志位于/var/log/messages文件,由于kubelet默认日志级别为--v=2,这里需要将其更改为--v=4
查看是否有/etc/kubernetes/kubelet.env文件,如果有,直接更改KUBE_LOG_LEVEL配置
KUBE_LOGTOSTDERR="--logtostderr=true"
KUBE_LOG_LEVEL="--v=4"
如果没有,则修改/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf文件
添加Environment
Environment="KUBE_LOGTOSTDERR=--logtostderr=true"
Environment="KUBE_LOG_LEVEL=--v=4"
修改ExecStart命令,在参数位追加$KUBE_LOGTOSTDERR $KUBE_LOG_LEVEL
ExecStart=/usr/bin/kubelet $KUBE_LOGTOSTDERR $KUBE_LOG_LEVEL $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
修改后需要重启kubelet
systemctl daemon-reload && systemctl restart kubelet
通过grep命令查看关键日志
grep "package-instance-42895-test-4461" messages
从日志中发现,kubelet监听到了两次创建同一个Pod的事件,也就是为一个Job创建了两个Pod
但是Job的配置都是为1
spec:completions: 1backoffLimit: 0parallelism: 1
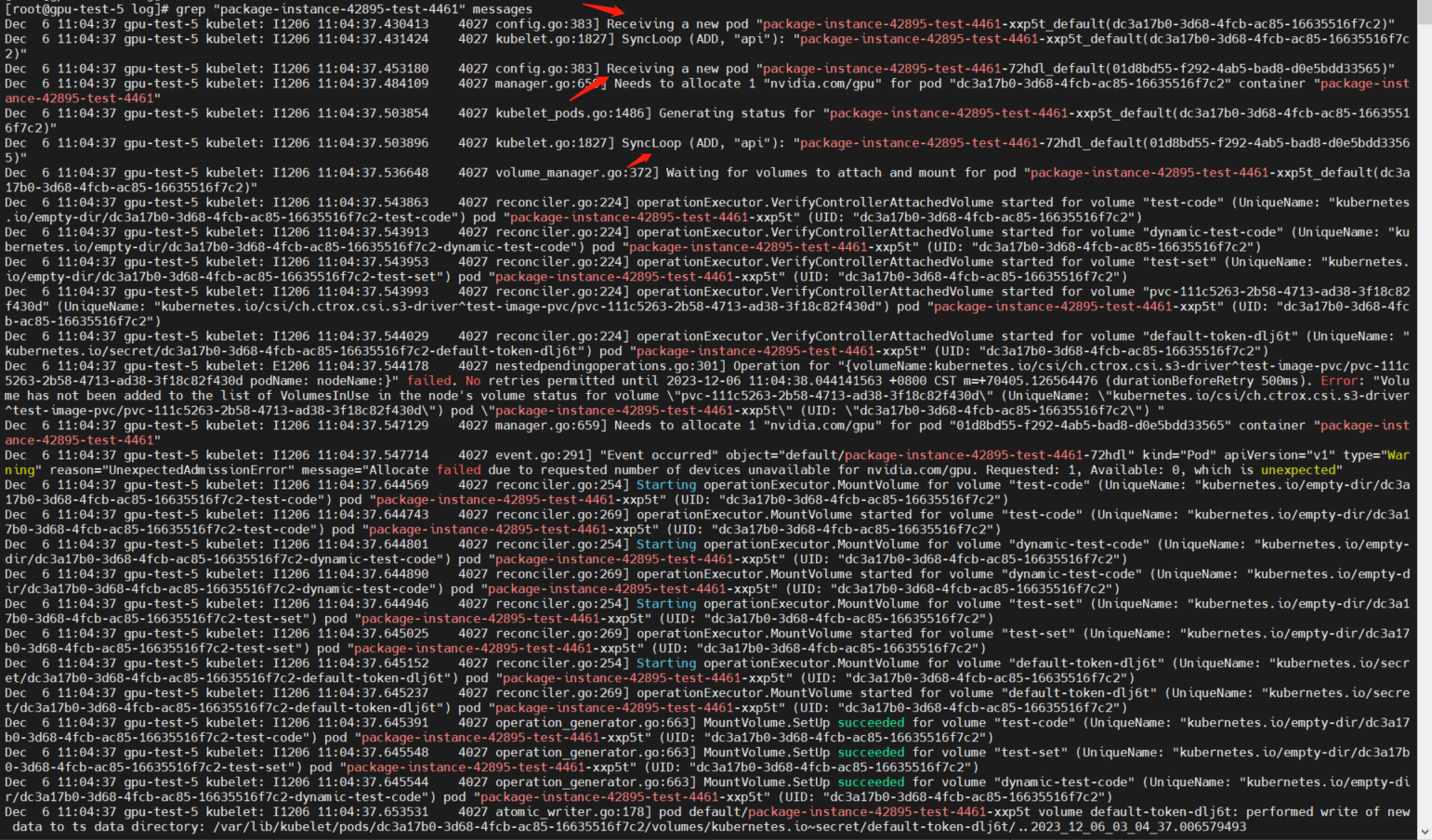
在这样的配置下,应该只有一次创建Pod的事件才对。
再分别查看两次Pod的资源分配日志
通过less messages命令查看详细的日志过程

从日志中可以看出,第一个Pod分配GPU资源是成功的
而在第二个Pod分配GPU资源时,就提示分配失败

至此问题就定位到了,是因为kubelet本应只创建一个Pod,但是确监听到了多次创建Pod的事件。
从这个情况来看,应当所有的任务都失败才对,但只有小部分任务失败了,继续查看日志

在下面的日志可以看到,kubelet随后就监听到了DELETE事件,删除了一个Pod,虽然在这个日志中删除的是创建失败的Pod
但是多观察几个Pod就会发现,删除完全的随机的,并不是根据状态来的,所以就会出现部分任务失败,但是大部分任务都成功的情况。
从上面的排查过程来看,kubelete、node、gpu device都是没有问题的,那么,继续往上排查scheduler
同样的,scheduler的日志级别默认也是--v=2,这里也需要改成--v=4,修改kube-scheduler.yaml文件
vim /etc/kubernetes/manifests/kube-scheduler.yaml
在command中追加一行--v=4
spec:containers:- command:- kube-scheduler- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf- --bind-address=0.0.0.0- --kubeconfig=/etc/kubernetes/scheduler.conf- --leader-elect=false- --leader-elect-lease-duration=15s- --leader-elect-renew-deadline=10s- --port=0- --v=4
更改文件后保存,等待scheduler自动重建。注意重建后日志会清空,所以需要等待下次调度再次重新进行问题排查
然后通过kubectl logs命令,查看三个scheduler的调度日志
kubectl logs -n kube-system kube-scheduler-master-1| grep package-instance-42895-test-4461
kubectl logs -n kube-system kube-scheduler-master-2| grep package-instance-42895-test-4461
kubectl logs -n kube-system kube-scheduler-master-3| grep package-instance-42895-test-4461
[root@master-1 ~]# kubectl logs -n kube-system kube-scheduler-master-1| grep package-instance-42895-test-4461
I1206 03:23:08.641125 1 eventhandlers.go:225] add event for scheduled pod default/package-instance-42895-test-4461-xxp5t
I1206 03:23:08.641463 1 eventhandlers.go:225] add event for scheduled pod default/package-instance-42895-test-4461-72hdl
I1206 03:23:08.866294 1 eventhandlers.go:283] delete event for scheduled pod default/package-instance-42895-test-4461-72hdl[root@master-1 ~]# kubectl logs -n kube-system kube-scheduler-master-2| grep package-instance-42895-test-4461
I1206 03:23:08.641125 1 eventhandlers.go:225] add event for scheduled pod default/package-instance-42895-test-4461-xxp5t
I1206 03:23:08.641463 1 eventhandlers.go:225] add event for scheduled pod default/package-instance-42895-test-4461-72hdl
I1206 03:23:08.866294 1 eventhandlers.go:283] delete event for scheduled pod default/package-instance-42895-test-4461-72hdl[root@master-1 ~]# kubectl logs -n kube-system kube-scheduler-master-3| grep package-instance-42895-test-4461
从上面的日志可以看到,Pod确实被调度了两次,但是,schduler只是负责调度Pod,并不会控制Pod创建的数量。
而且,理论上,应该只有一个leader级别的schduler处于工作状态,其他两个schduler,应当是处于睡眠状态,不进行工作才对,也就说,其他的schduler不应该监听到调度事件。
虽然问题不在此,但是从这里可以发现schduler的部署是有问题的,查看schduler配置
spec:containers:- command:- kube-scheduler- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf- --bind-address=0.0.0.0- --kubeconfig=/etc/kubernetes/scheduler.conf- --leader-elect=false- --leader-elect-lease-duration=15s- --leader-elect-renew-deadline=10s- --port=0- --v=4
在检查了三个节点的schduler配置后,发现有一个节点的schduler配置中,--leader-elect被设置成了fasle
Kubernetes的调度器可以使用leader选举来确保只有一个实例处于活跃状态,负责决策和分配Pod。一旦调度器的活跃实例失效,其他备用实例可以进行leader选举,确保集群的Pod能够被适当地调度到可用的节点上。
同样,如果多个调度器实例都设置为--leader-elect=false,它们将尝试同时管理Pod的调度决策,可能会导致混乱、资源冲突以及不一致的状态。
在这可以确定是--leader-elect=false导致的出现了多个leader级的schduler,将此配置更改为--leader-elect=true。
等待schudler重建,修复了schudler多leader的问题,但是,Pod重复调度的问题依旧没有解决,查看Pod调度调度流程
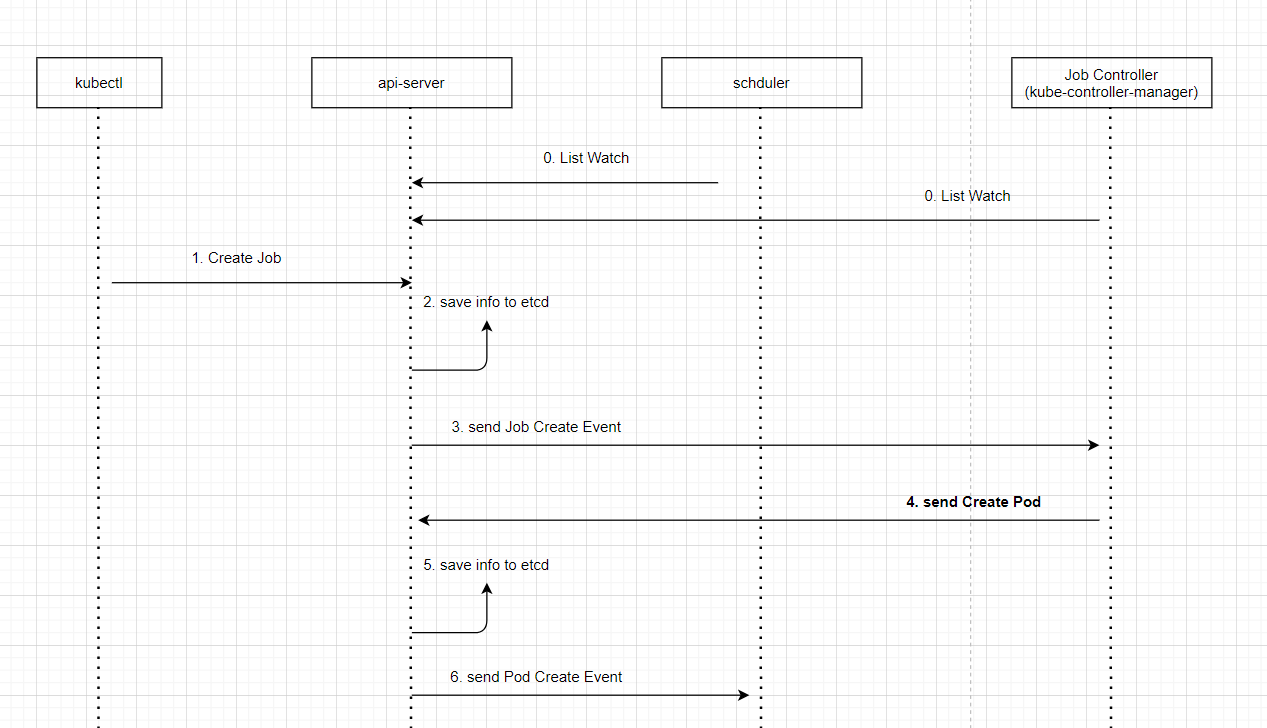
从流程图上可以看出,创建Pod的请求,是由Job Controller发出的,在kubernetes中有很多的控制器,例如
Job Controller、Deployment Controller,这些控制器由控制平面进行管理kube-controller-manger。
结合上面schduler的可以得出结论。是在Job Controller中,发出了两次创建Pod的请求,而kube-controller-manger集群跟schduler集群一样,理论上应该只有一个leader级别的处于工作中的状态,其他两个都应该处于休眠状态。但是这里发起了两次创建请求,显然是有一个以上的leader级的kube-controller-manger,通过查看配置文件,问题跟schduler是一样的
YAML文件路径/etc/kubernetes/manifests/kube-controller-manager.yaml
有一个节点的YAML文件中--leader-elect=false,这个配置也被设置为了false,导致的出现了多个ledaer级的控制平面,从而导致Pod被多次创建。
验证方式也是同样的,通过kubectl logs命令,查看三个kube-controller-manager的监听日志,发现有两个控制平面监听到了Create Job事件,从而导致的这次问题。
kubectl logs -n kube-system kube-controller-manager-master-1 |grep package-instance-42895-test-4461
3. 解决方案
通过修改/etc/kubernetes/manifests/kube-scheduler.yaml和/etc/kubernetes/manifests/kube-controller-manager.yaml两个YAML文件中的--leader-elect配置,将其修改为true,即可解决问题。
--leader-elect=false
相关文章:
k8s集群部分使用gpu资源的pod出现UnexpectedAdmissionError问题
记录一次排查UnexpectedAdmissionError问题的过程 1. 问题 环境 3master节点N个GPU节点 kubelet版本:v1.19.4 kubernetes版本:v1.19.4 生产环境K8S集群,莫名其妙的出现大量UnexpectedAdmissionError状态的Pod,导致部分任务执…...
自定义 el-select 和 el-input 样式
文章目录 需求分析el-select 样式el-input 样式el-table 样式 需求 自定义 选择框的下拉框的样式和输入框 分析 el-select 样式 .select_box{// 默认placeholder:deep .el-input__inner::placeholder {font-size: 14px;font-weight: 500;color: #3E534F;}// 默认框状态样式更…...

解决本地centos虚拟机重启,自动变换 ip 地址的问题
修改网卡配置文件 vi /etc/sysconfig/network-scripts/ifcfg-ens33 原配置: TYPE"Ethernet" PROXY_METHOD"none" BROWSER_ONLY"no" BOOTPROTO"dhcp" DEFROUTE"yes" IPV4_FAILURE_FATAL"no" IPV6INI…...

pt36项目短信OAth2.0
5、短信验证码 1、注册容联云账号,登录并查看开发文档(以下分析来自接口文档) 2、开发文档【准备1】:请求URL地址1.示例:https://app.cloopen.com:8883/2013-12-26/Accounts/{}/SMS/TemplateSMS?sig{}ACCOUNT SID# s…...

教师们如何一对一私发成绩?
在传统的教育中,老师通常会通过班级群或家长会等方式发布学生的成绩信息。然而,这种公开的方式可能会让一些学生感到尴尬和不安,因为他们可能不愿意让其他人知道他们的成绩情况。为了解决这个问题,今天我就给老师们推荐一款免费的…...

12.11
1.q,w,e亮led1,2,3; a,s,d灭led1,2,3; main.c #include "uar1.h"#include "led.h"void delay(int ms){int i,j;for(i0;i<ms;i){for…...

Spring JdbcTemplate
一、简介 Spring 框架对 JDBC 进行封装,使用 JdbcTemplate 方便实现对数据库操作。它是 spring 框架中提供的一个对象,是对原始 Jdbc API 对象的简单封装。spring 框架为我们提供了很多的操作模板类。 针对操作关系型数据: jdbcTemplateHibe…...

力扣编程题算法初阶之双指针算法+代码分析
目录 第一题:复写零 第二题:快乐数: 第三题:盛水最多的容器 第四题:有效三角形的个数 第一题:复写零 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 思路: 上期…...
实现安装“自由化”!在Windows 11中如何绕过“您尝试安装的应用程序未通过微软验证”
这篇文章描述了如果你不能安装应用程序,而是当你在Windows 11中看到消息“您尝试安装的应用程序未通过微软验证”时该怎么办。完成这些步骤将取消你安装的应用程序必须经过Microsoft验证的要求。 使用设置应用程序 “设置”应用程序提供了绕过此警告消息的最简单方法,以便你…...
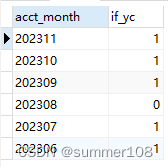
【mysql】下一行减去上一行数据、自增序列场景应用
背景 想获取if_yc为1连续账期数据 思路 获取所有if_yc为1的账期数据下一行减去上一行账期,如果为1则为连续,不等于1就为断档获取不等于1的最小账期,就是离当前账期最近连续账期 代码 以下为mysql语法: select acct_month f…...
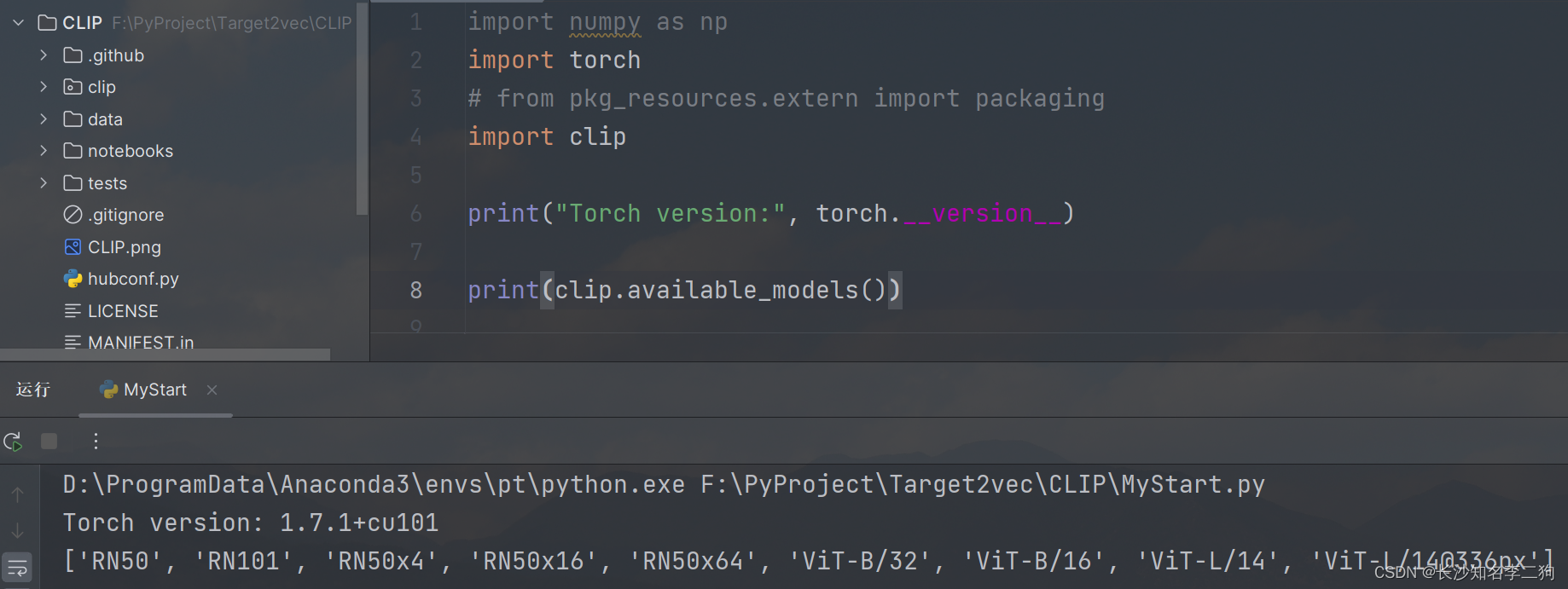
CLIP在Github上的使用教程
CLIP的github链接:https://github.com/openai/CLIP CLIP Blog,Paper,Model Card,Colab CLIP(对比语言-图像预训练)是一个在各种(图像、文本)对上进行训练的神经网络。可以用自然语…...
入职字节外包一个月,我离职了。。。
有一种打工人的羡慕,叫做“大厂”。 真是年少不知大厂香,错把青春插稻秧。 但是,在深圳有一群比大厂员工更庞大的群体,他们顶着大厂的“名”,做着大厂的工作,还可以享受大厂的伙食,却没有大厂…...

SpringBoot的web开发
与其明天开始,不如现在行动! 文章目录 web开发1 web场景1.1 自动配置1.2 默认效果 💎总结 web开发 SpringBoot的web开发能力是由SpringMVC提供的 1 web场景 1.1 自动配置 整合web场景 <dependency><groupId>org.springframewo…...

传染病传播速度
题干 R0值是基本传染数的简称,指的是在没有采取任何干预措施的情况下,平均每位感染者在传染期内使易感者个体致病的数量。数字越大说明传播能力越强,控制难度越大。一个人传染的人的数量可以用幂运算来计算。假设奥密克戎的R0为10࿰…...
前端打包环境配置步骤
获取node安装包并解压 获取node安装包 wget https://npmmirror.com/mirrors/node/v16.14.0/node-v16.14.0-linux-x64.tar.xz 解压 tar -xvf node-v16.14.0-linux-x64.tar.xz 创建软链接 sudo ln -s 此文件夹的绝对路径/bin/node /usr/local/bin/node,具体执行如下…...
、内部样式表(<style>)、外部样式表(<link>、@import))
css的4种引入方式--内联样式(标签内style)、内部样式表(<style>)、外部样式表(<link>、@import)
1.内联样式(Inline Styles):可以直接在HTML元素的style属性中定义CSS样式。 例如: <p style"color: red; font-size: 16px;">这是一段红色的文本</p>内联样式适用于对单个元素应用特定的样式,…...

GPT-4 变懒了?官方回复
你是否注意到,最近使用 ChatGPT 的时候,当你向它提出一些问题,却得到的回应似乎变得简短而敷衍了?对于这一现象,ChatGPT 官方给出了回应。 译文:我们听到了你们所有关于 GPT4 变得更懒的反馈!我…...

编译器和 IR:LLVM IR、SPIR-V 和 MLIR
编译器通常是各种开发工具链中的关键组件,可提高开发人员的工作效率。编译器通常用作独立的黑匣子,它使用高级源程序并生成语义上等效的低级源程序。不过,它仍然是内部结构倾向的;内部之间流动的内容就称为中间表示 (IR࿰…...

蓝牙物联网对接技术难点有哪些?
#物联网# 蓝牙物联网对接技术难点主要包括以下几个方面: 1、设备兼容性:蓝牙技术有多种版本和规格,如蓝牙4.0、蓝牙5.0等,不同版本之间的兼容性可能存在问题。同时,不同厂商生产的蓝牙设备也可能存在兼容性问题。 2、…...

漫谈Uniapp App热更新包-Jenkins CI/CD打包工具链的搭建
零、写在前面 HBuilderX是DCloud旗下的IDE产品,目前只提供了Windows和Mac版本使用。本项目组在开发阶段经常需要向测试环境提交热更新包,使用Jenkins进行CD是非常有必要的一步。尽管HBuilderX提供了CLI,但Jenkins服务通常都是搭建在Linux环境…...

Claude Code 官方回应代码泄漏:这次,他们没有“甩锅人”
这两天,Claude Code 的“代码泄漏”事件在技术圈引发了不少讨论。各种版本的故事层出不穷,甚至还有营销号声称“新员工背锅被开除”。但从官方回应来看,事情的走向,其实完全不一样。👉 Claude Code 团队,正…...

八大网盘直链提取终极指南:突破客户端限制的JavaScript神器
八大网盘直链提取终极指南:突破客户端限制的JavaScript神器 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 /…...

LocalVocal:本地化语音识别的隐私保护方案 - 从部署到优化的全流程指南
LocalVocal:本地化语音识别的隐私保护方案 - 从部署到优化的全流程指南 【免费下载链接】obs-localvocal OBS plugin for local speech recognition and captioning using AI 项目地址: https://gitcode.com/gh_mirrors/ob/obs-localvocal 在数字化沟通日益频…...

NVIDIA Profile Inspector配置问题全方位解决方案
NVIDIA Profile Inspector配置问题全方位解决方案 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 问题定位:识别配置故障的关键信号 在使用NVIDIA Profile Inspector(一款NVIDI…...

深入解析CyberpunkSaveEditor:赛博朋克2077存档编辑的终极指南
深入解析CyberpunkSaveEditor:赛博朋克2077存档编辑的终极指南 【免费下载链接】CyberpunkSaveEditor A tool to edit Cyberpunk 2077 sav.dat files 项目地址: https://gitcode.com/gh_mirrors/cy/CyberpunkSaveEditor 想要彻底掌控《赛博朋克2077》的游戏体…...

GLM-4.1V-9B-Base与Dify联动:零代码构建企业级AI应用平台
GLM-4.1V-9B-Base与Dify联动:零代码构建企业级AI应用平台 1. 企业AI应用的新选择 最近接触了不少企业客户,发现一个普遍现象:大家都想用AI,但真正能用起来的却不多。技术门槛高、开发周期长、维护成本大,这些问题让很…...

史上最快破 10 万 Star!Claude Code Python 重写版震撼上线!
文章目录 📖 介绍 📖 🏡 演示环境 🏡 📒 史上最快10万Star项目 📒 📝 事件始末 🔧 项目架构 🗂️ 目录结构 ⭐ Rust工作区模块 🚀 快速开始 📦 Python版 🦀 Rust版 💡 核心特色 🎯 清洁室重写 🔄 AI辅助开发 📊 Rust性能优化 🌟 项目影响力 …...

3种方法彻底移除Windows Defender:释放系统性能,恢复完全控制权
3种方法彻底移除Windows Defender:释放系统性能,恢复完全控制权 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcod…...

到底要不要用AI写代码?别争了
其实我一直觉得,现在大家讨论 AI 写代码这件事,有点熟悉。因为以前我们也是这么过来的。刚开始写代码那会儿, 不会就打开 百度, 一行一行找答案,复制、试错、再改。一个分号错了能找半天, 中英文标点混了直…...

docker-compose部署nginx转发前端dist8080一直在服务器访问不了
在做不出来就要被老板扔出去了,nginx一直访问不了 转行写代码,使用docker部署所有组件,nginx一直出问题,有前辈帮我看看不 1、配置的nginx2、对应的nginx.conf的配置文件3、前端的dist放在/opt/sbcw/html/dist下就是访问不了&…...