JavaWeb笔记之MySQL数据库

#Author 流云#Version 1.0
一、引言
1.1 现有的数据存储方式有哪些?
1.2 以上存储方式存在哪些缺点?
1.3 没有使用数据库,你将会变成这样

1.4 使用数据库,你会变成这样


二、数据库
2.1 概念
2.2 数据库的分类
三、数据库管理系统
3.1 概念
3.2 常见数据库管理系统
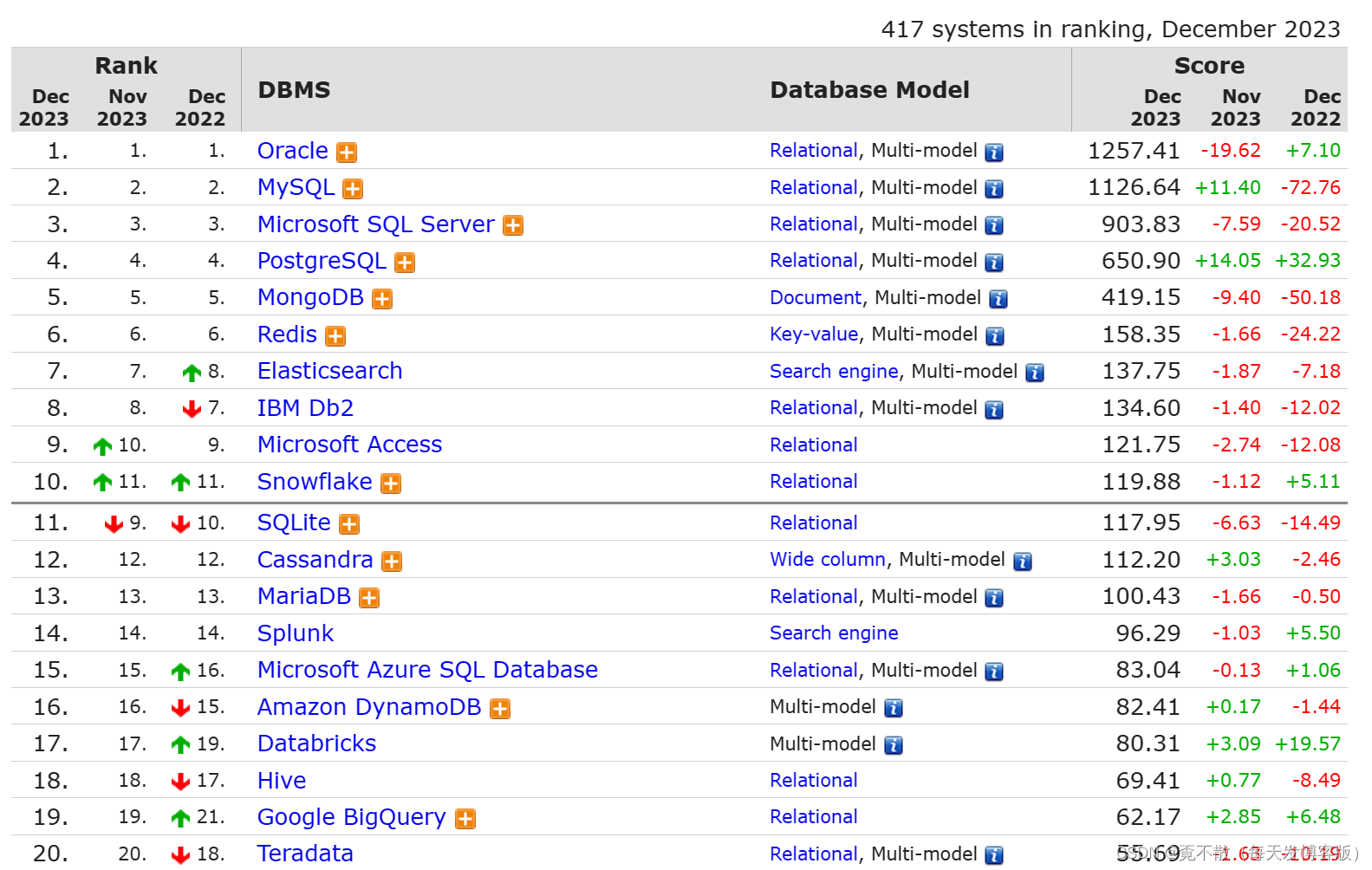
3.3 数据库的排名
四、MySQL
4.1 简介
1. MySQL Community Server 社区版本,开源免费,但不提供官方技术支持。2. MySQL Enterprise Edition 企业版本,需付费,可以试用30天。3. MySQL Cluster 集群版,开源免费。可将几个MySQL Server封装成一个Server。4. MySQL Cluster CGE 高级集群版,需付费。
4.2 访问与下载
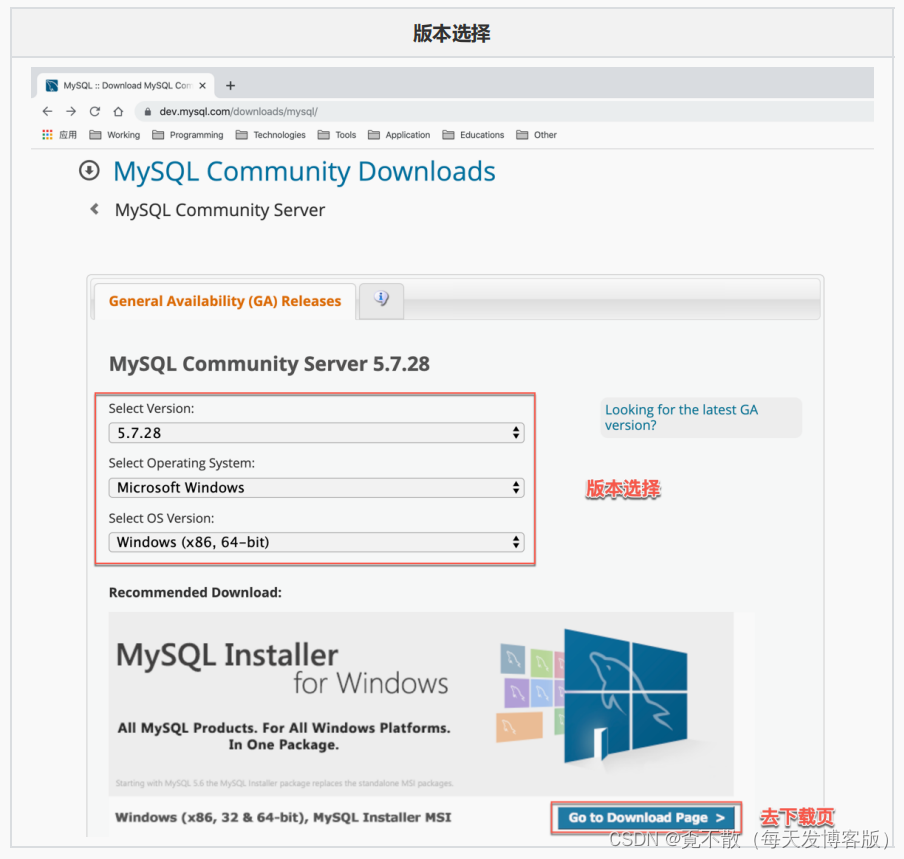
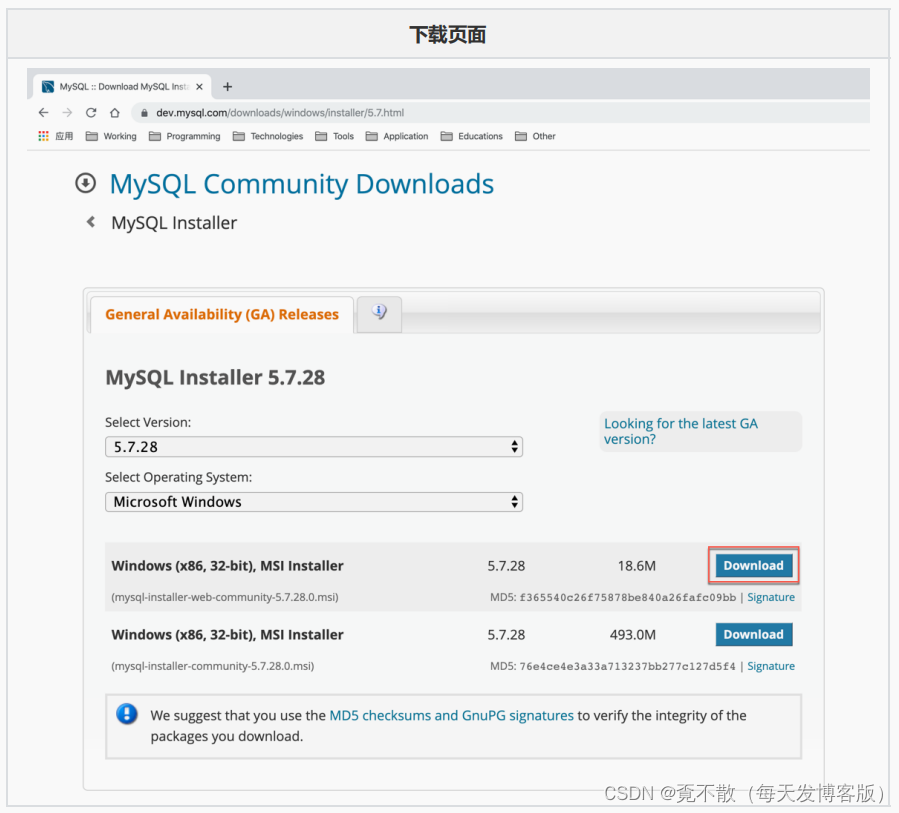
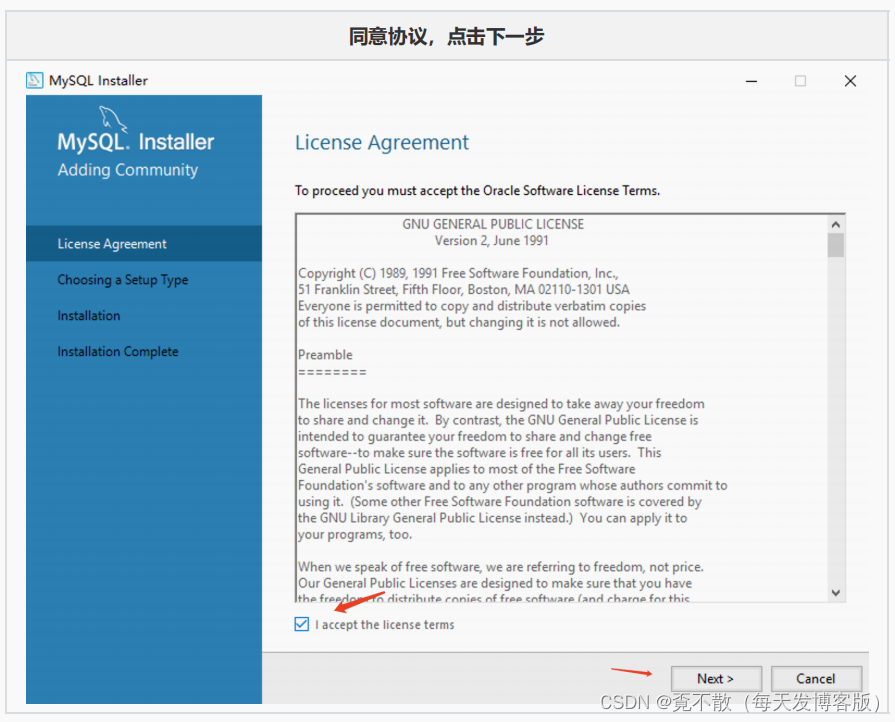
4.3 安装
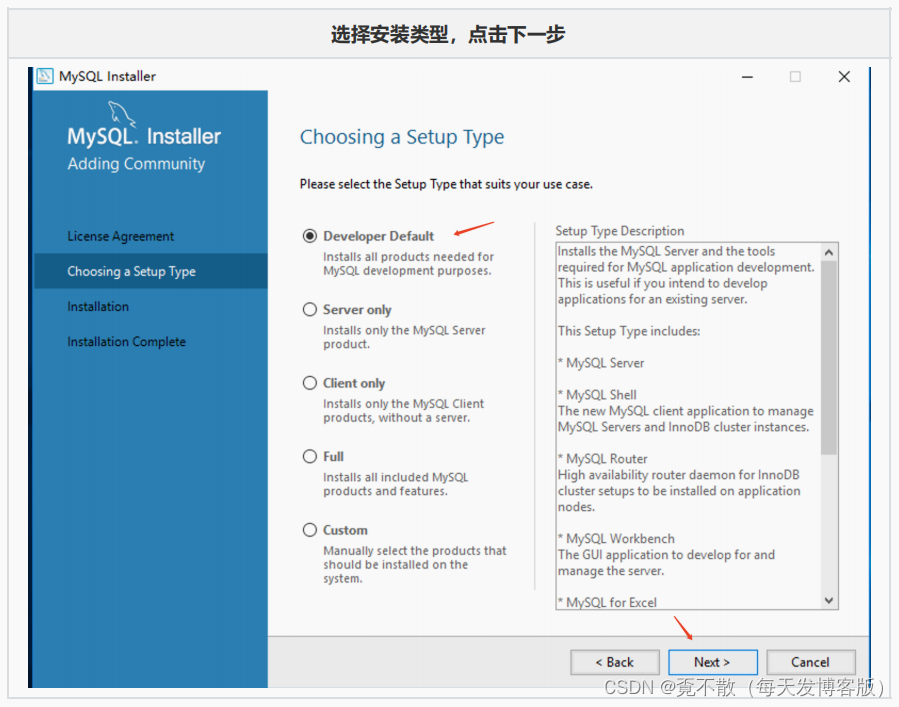
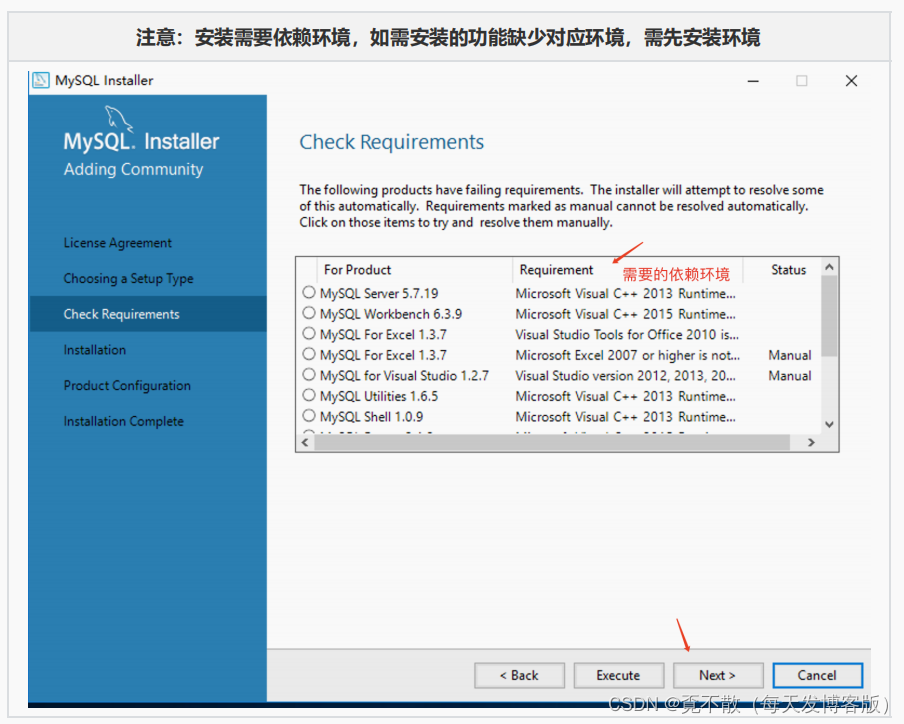
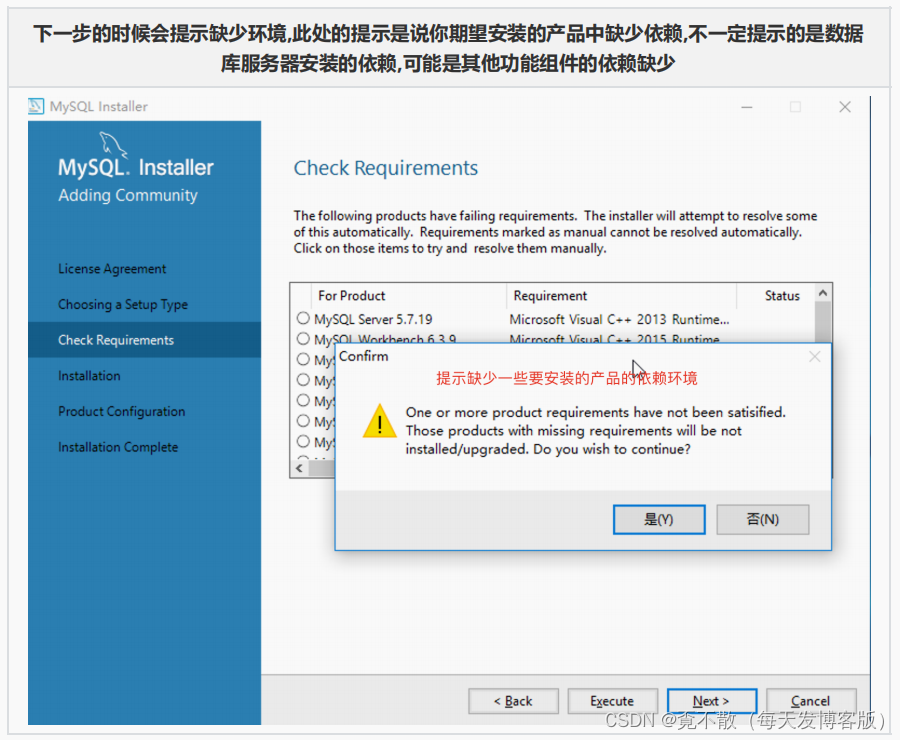
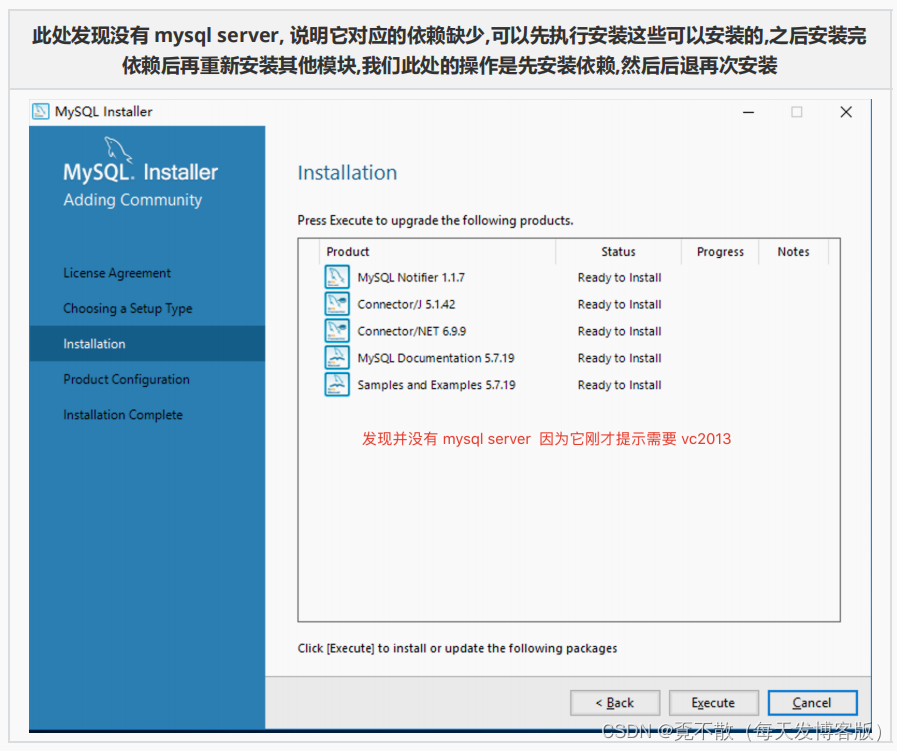
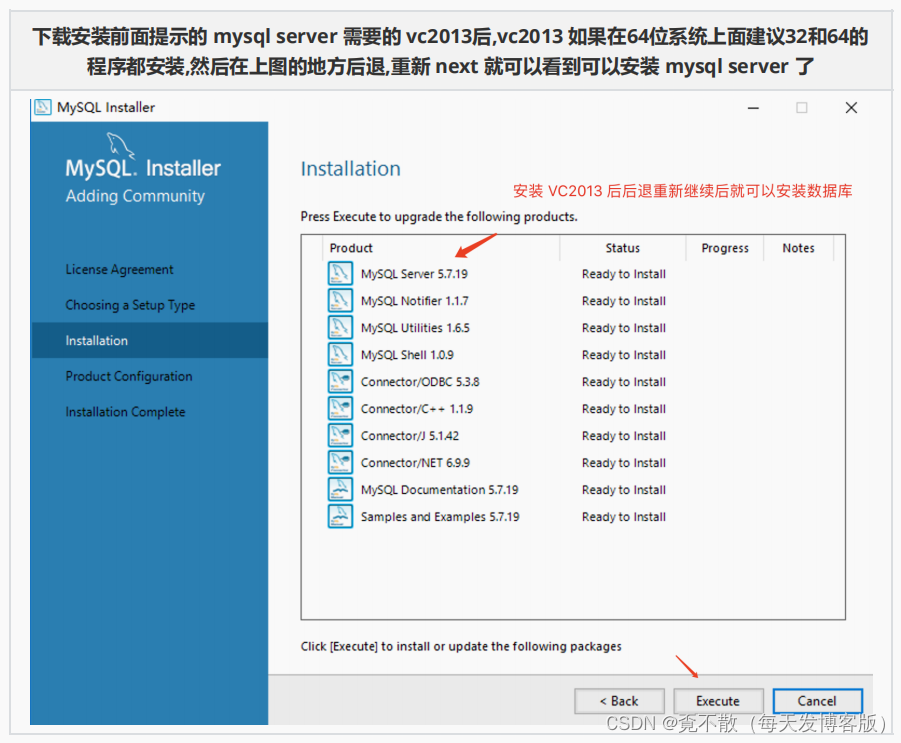
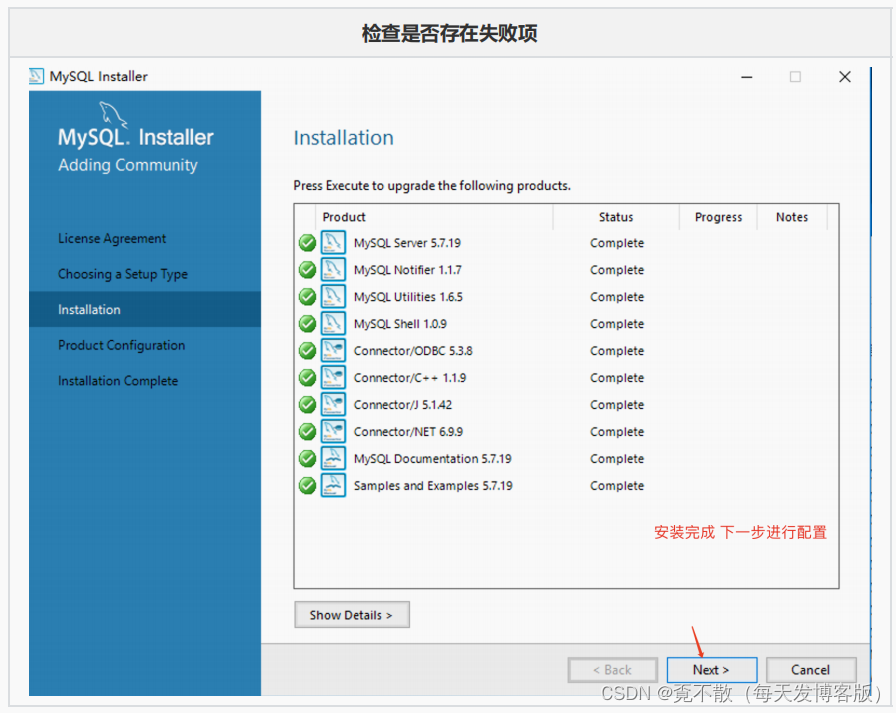
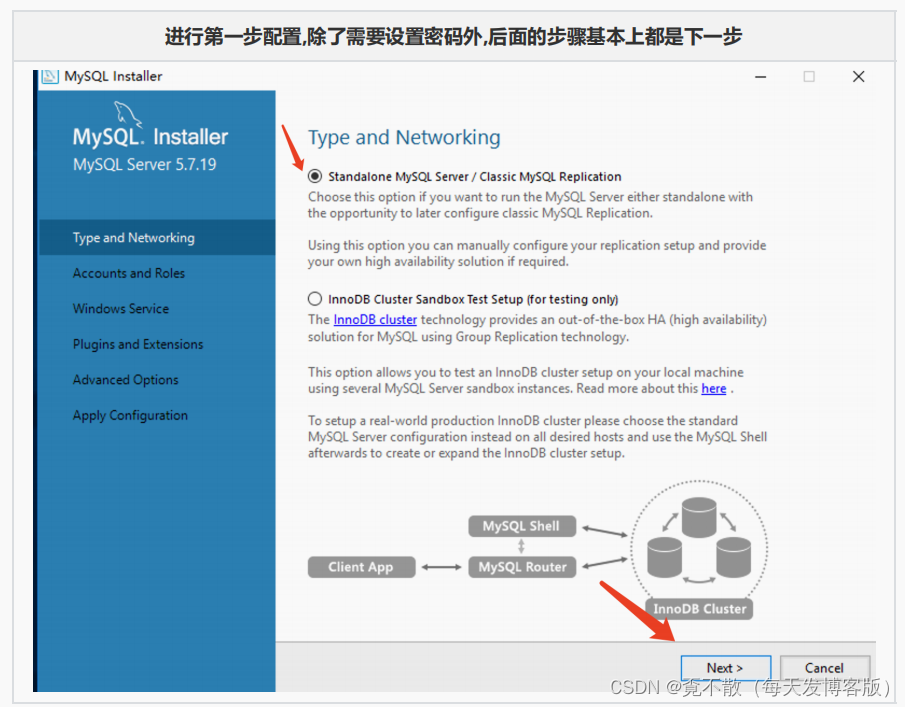
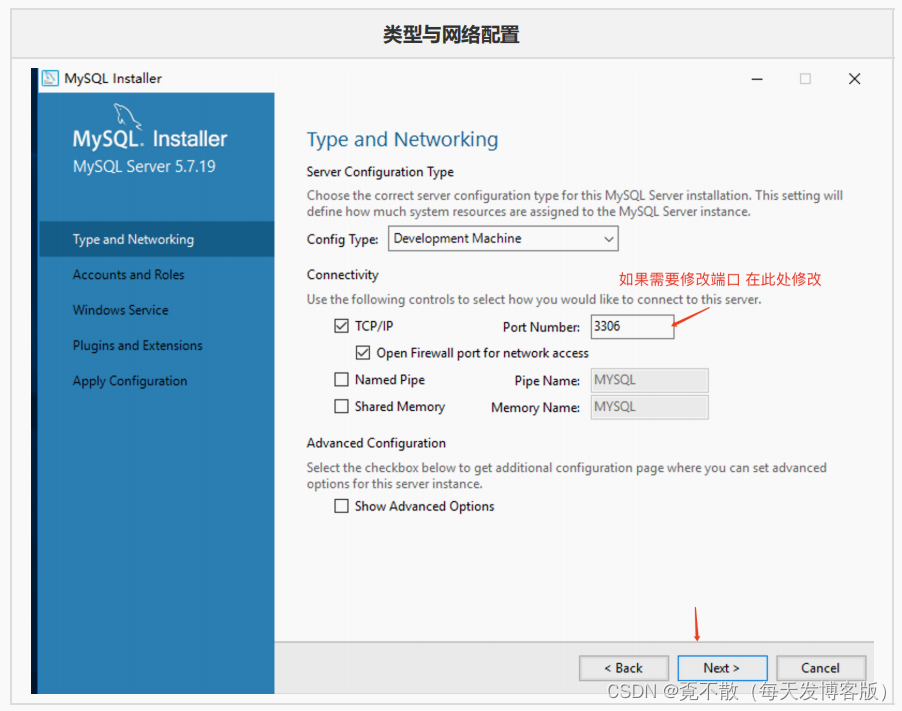
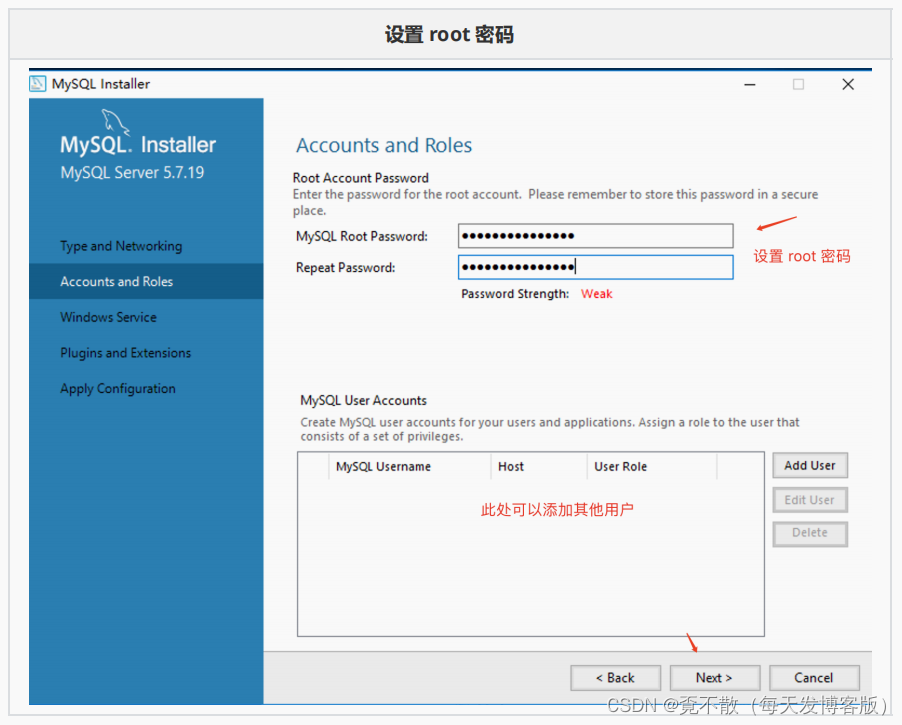
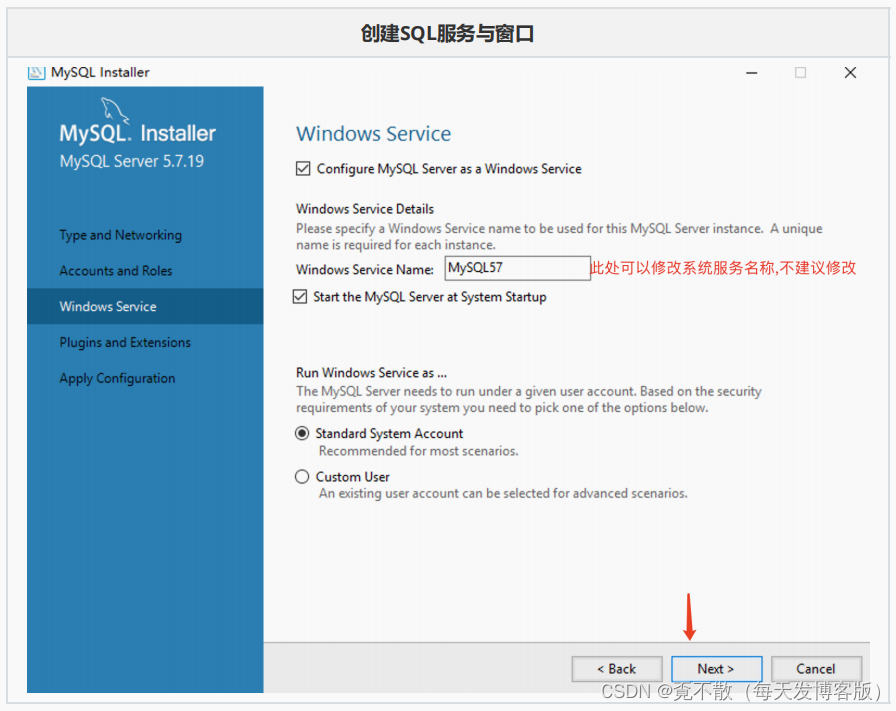
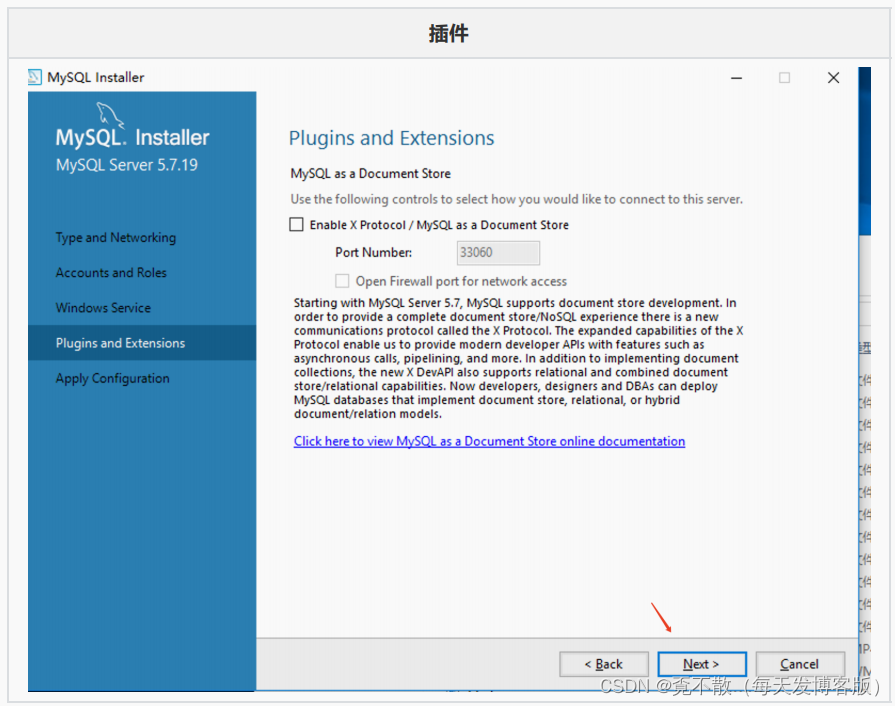
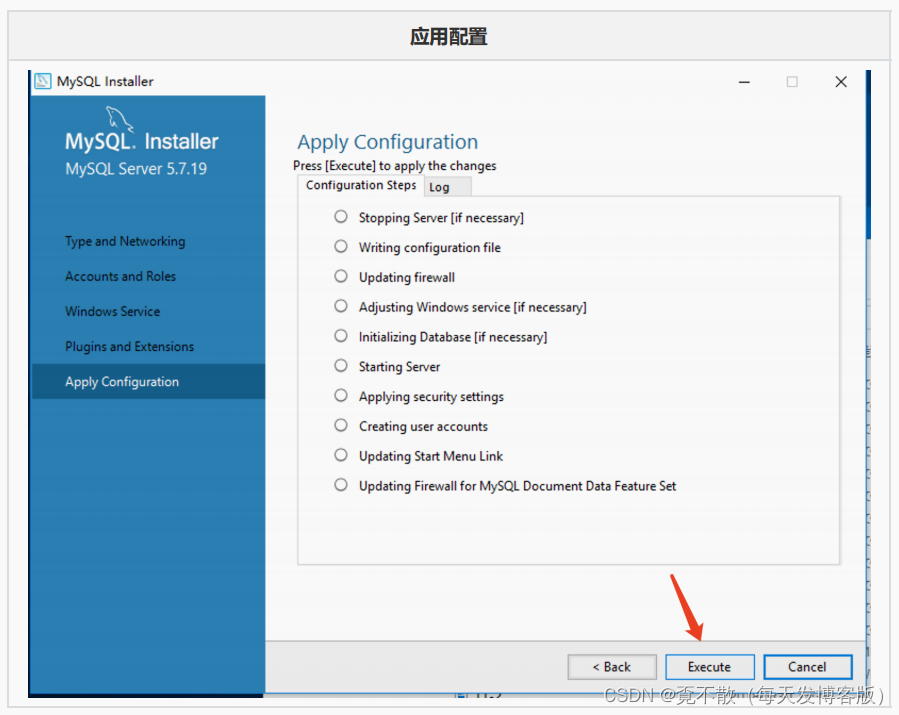
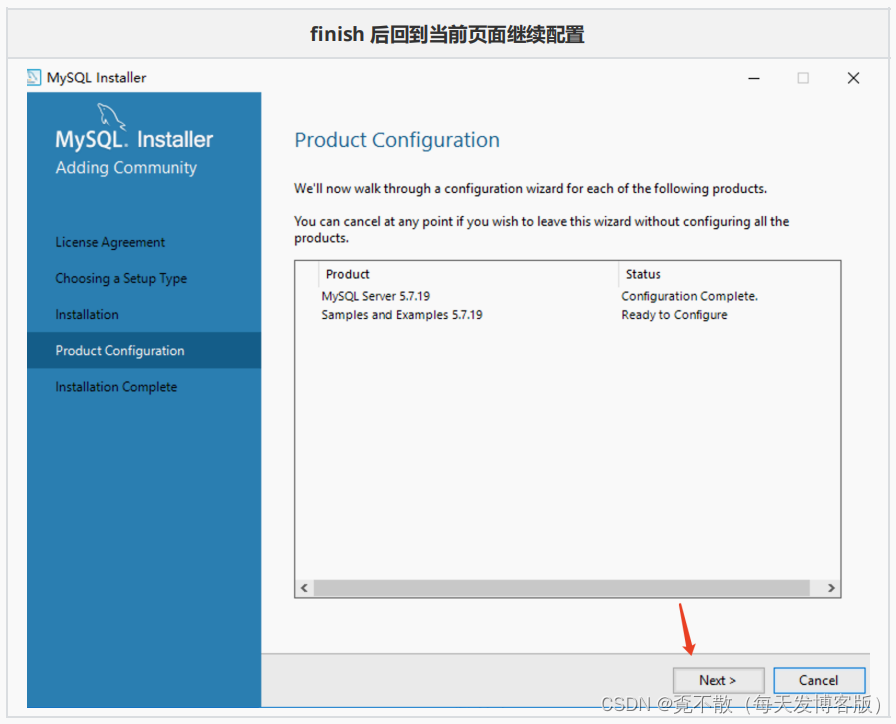
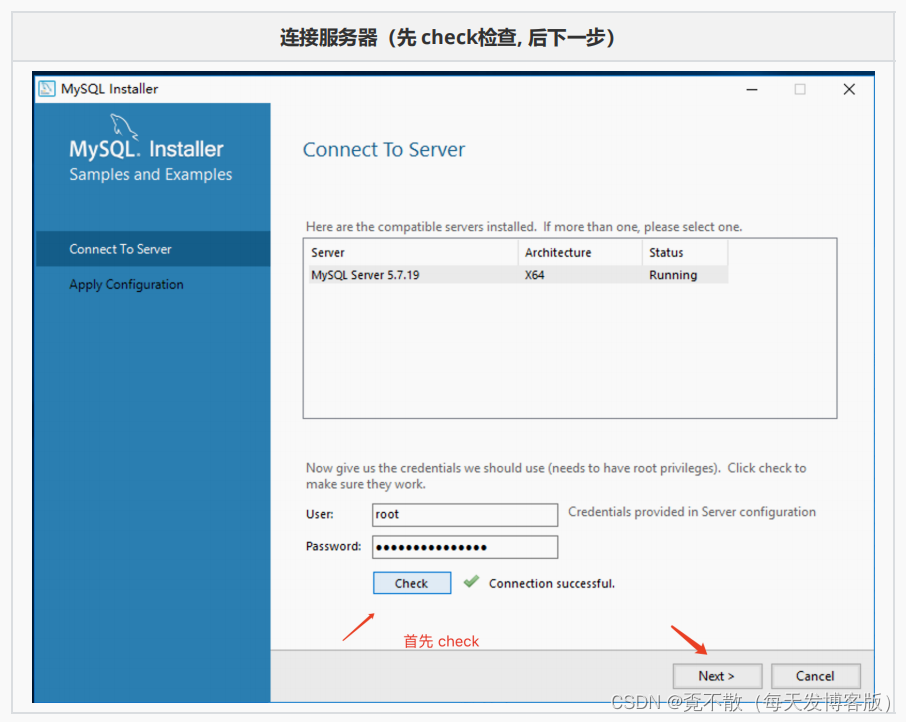
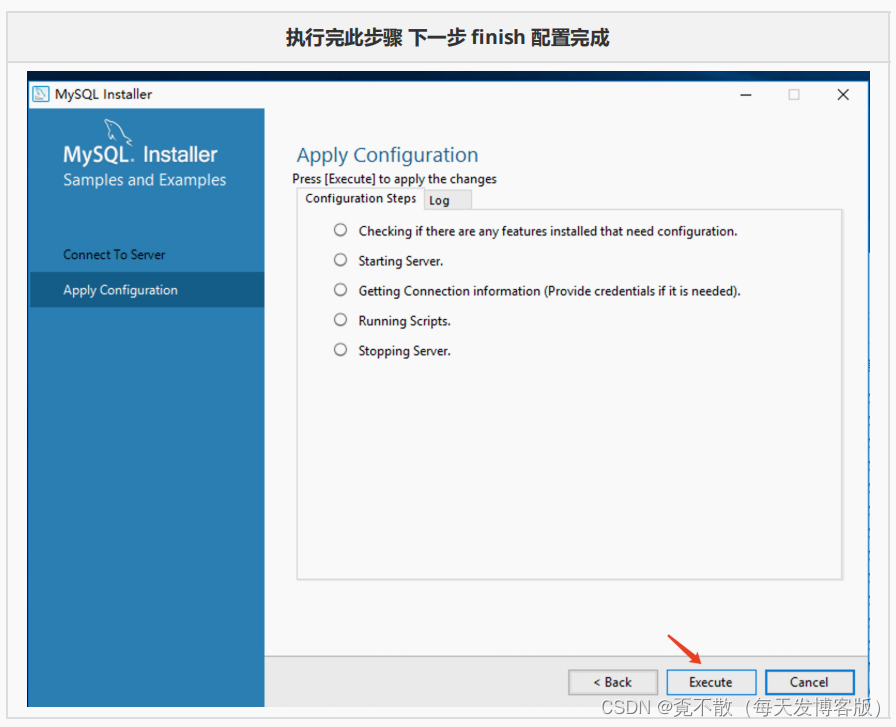
4.4 卸载
4.5 配置环境变量
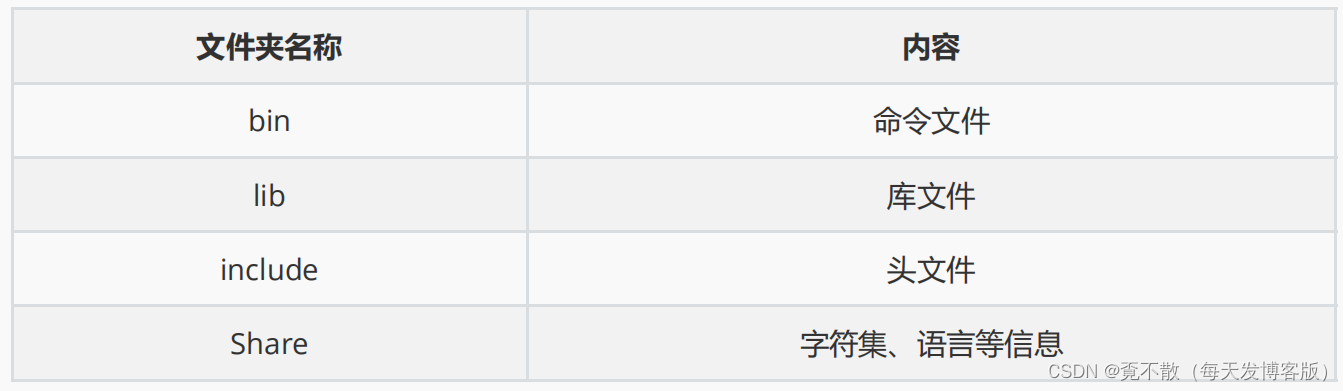
4.6 MySQL目录结构
4.7 MySQL配置文件
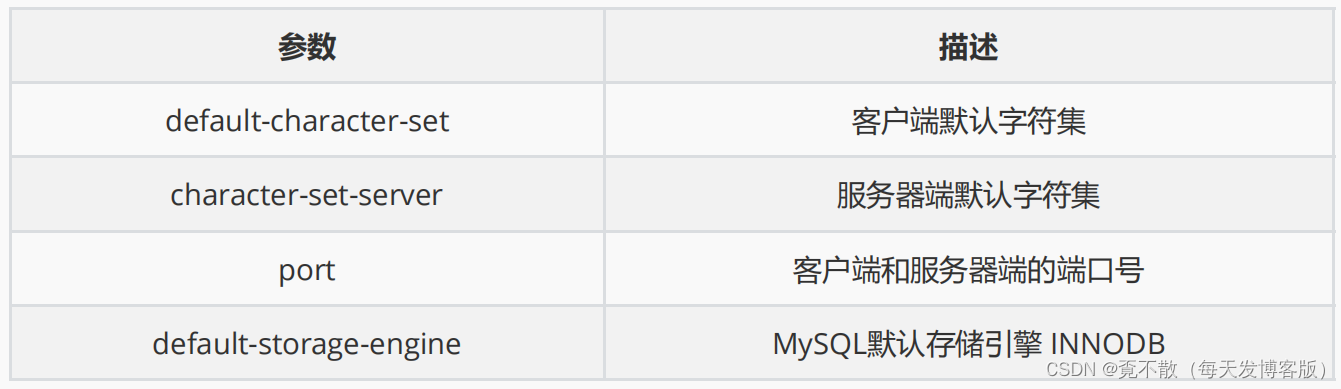
五、SQL语言
5.1 概念
5.2 MySQL应用
5.3 基本命令
mysql> SHOW DATABASES; #显示当前MySQL中包含的所有数据库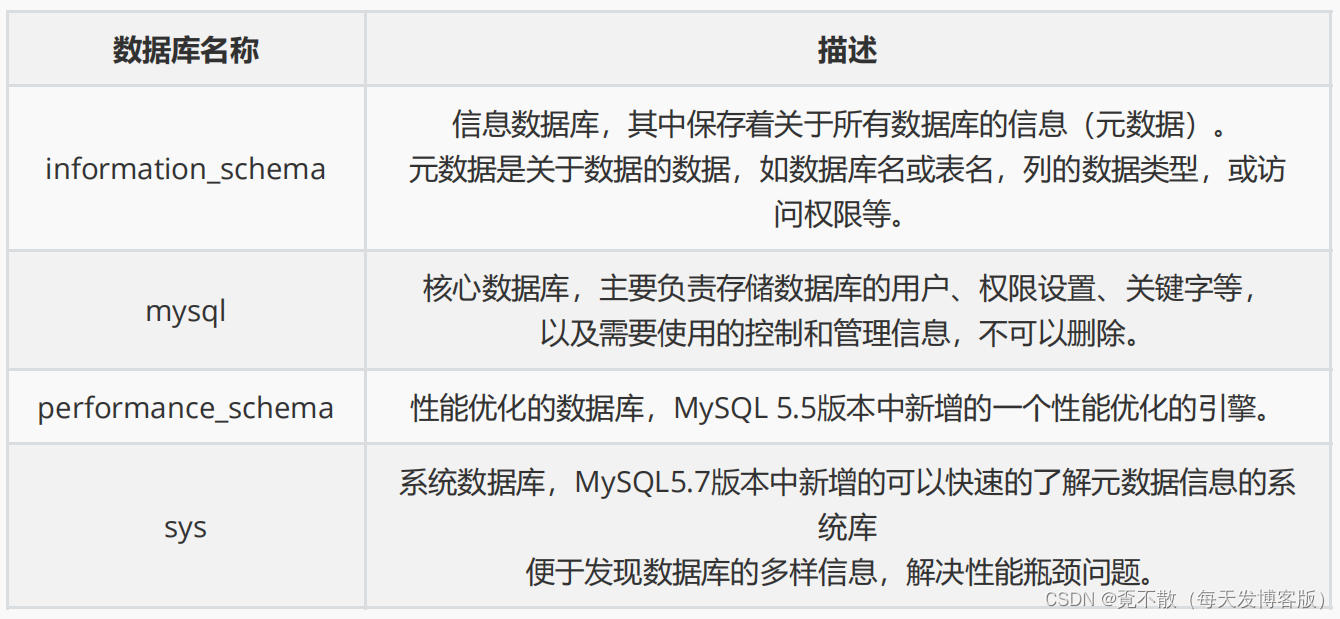
mysql> CREATE DATABASE mydb1; #创建mydb数据库
mysql> CREATE DATABASE mydb2 CHARACTER SET gbk; #创建数据库并设置编码格式为gbk
mysql> CREATE DATABASE IF NOT EXISTS mydb4; #如果mydb4数据库不存在,则创建;如果存在,则不创建。mysql> SHOW CREATE DATABASE mydb2; #查看创建数据库时的基本信息mysql> ALTER DATABASE mydb2 CHARACTER SET gbk; #查看创建数据库时的基本信息mysql> DROP DATABASE mydb1; #删除数据库mydb1mysql> select database(); #查看当前使用的数据库mysql> USE mydb1; #使用mydb1数据库六、客户端工具
6.1 Navicate
6.2 SQLyog
6.3 使用客户端工具
七、 DML 操作【重点 】
7.1 新增(INSERT)
7.1.1 添加一条信息
#添加一条工作岗位信息
INSERT INTO t_jobs(JOB_ID,JOB_TITLE,MIN_SALARY,MAX_SALARY) VALUES('JAVA_Le','JAVA_Lecturer',2500,9000);#添加一条员工信息
INSERT INTO `t_employees`
(EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID)VALUES('194','Samuel','McCain','SMCCAIN', '650.501.3876', '1998-07-01', 'SH_CLERK','3200', NULL, '123', '50');7.2 修改(UPDATE)
7.2.1 修改一条信息
#修改编号为100 的员工的工资为 25000
UPDATE t_employees SET SALARY = 25000 WHERE EMPLOYEE_ID = '100';#修改编号为135 的员工信息岗位编号为 ST_MAN,工资为3500
UPDATE t_employees SET JOB_ID=ST_MAN,SALARY = 3500 WHERE EMPLOYEE_ID = '135';7.3 删除(DELETE)
7.3.1 删除一条信息
#删除编号为135 的员工
DELETE FROM t_employees WHERE EMPLOYEE_ID='135';#删除姓Peter,并且名为 Hall 的员工
DELETE FROM t_employees WHERE FIRST_NAME = 'Peter' AND LAST_NAME='Hall';7.4 清空整表数据(TRUNCATE)
7.4.1 清空整张表
#清空t_countries整张表
TRUNCATE TABLE t_countries;八、数据查询【重点 】
8.1 数据库表的基本结构
-- 员工表 employee
employee_id --编号
first_name --名字
email --邮箱
salary --月薪
commission_pct --提成
manager_id --所属经理编号
department_id --部门id
job_id --工作编号-- 部门表 department
department_id --部门编号
department_name --部门名称-- 工作表 job
job_id --工作id
job_name --工作名称
job_desc --工作内容--经理表 manager
manager_id --经理编号
manager_name --经理名字8.2 基本查询

8.2.1 查询部分列
#查询员工表中所有员工的编号、名字、邮箱
SELECT employee_id,first_name,email FROM t_employees;8.2.2 查询所有列
#查询员工表中所有员工的所有信息(所有列)
SELECT 所有列的列名 FROM t_employees;
SELECT * FROM t_employees;8.2.3 对列中的数据进行运算
#查询员工表中所有员工的编号、名字、年薪
SELECT employee_id , first_name , salary*12 FROM t_employees;
8.2.4 列的别名
#查询员工表中所有员工的编号、名字、年薪(列名均为中文)
SELECT employee_id as "编号" , first_name as "名字" , salary*12 as "年薪" FROM t_employees;8.2.5 查询结果去重
#查询员工表中所有经理的ID。
SELECT DISTINCT manager_id FROM t_employees;8.3排序查询

8.3.1 依据单列排序
#查询员工的编号,名字,薪资。按照工资高低进行降序排序。
SELECT employee_id , first_name , salary
FROM t_employees
ORDER BY salary DESC;8.3.2 依据多列排序
#查询员工的编号,名字,薪资。按照工资高低进行升序排序(薪资相同时,按照编号进行升序排序)。
SELECT employee_id , first_name , salary
FROM t_employees
ORDER BY salary DESC , employee_id ASC;8.4 条件查询

8.4.1 等值判断(=)
#查询薪资是11000的员工信息(编号、名字、薪资)
SELECT employee_id , first_name , salary
FROM t_employees
WHERE salary = 11000;8.4.2 逻辑判断(and、or、not)
#查询薪资是11000并且提成是0.30的员工信息(编号、名字、薪资)
SELECT employee_id , first_name , salary
FROM t_employees
WHERE salary = 11000 AND commission_pct = 0.30;8.4.3 不等值判断(> 、< 、>= 、<= 、!= 、<>)
#查询员工的薪资在6000~10000之间的员工信息(编号,名字,薪资)
SELECT employee_id , first_name , salary
FROM t_employees
WHERE salary >= 6000 AND salary <= 10000;8.4.4 区间判断(between and)
#查询员工的薪资在6000~10000之间的员工信息(编号,名字,薪资)
SELECT employee_id , first_name , salary
FROM t_employees
WHERE salary BETWEEN 6000 AND 10000; #闭区间,包含区间边界的两个值8.4.5 NULL 值判断(IS NULL、IS NOT NULL)
#查询没有提成的员工信息(编号,名字,薪资 , 提成)
SELECT employee_id , first_name , salary , commission_pct
FROM t_employees
WHERE commission_pct IS NULL;8.4.6 枚举查询( IN (值 1,值 2,值 3 ) )
#查询部门编号为70、80、90的员工信息(编号,名字,薪资 , 部门编号)
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE department_id IN(70,80,90);
注:in的查询效率较低,可通过多条件拼接。8.4.7 模糊查询
#查询名字以"L"开头的员工信息(编号,名字,薪资 , 部门编号)
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE first_name LIKE 'L%';#查询名字以"L"开头并且长度为4的员工信息(编号,名字,薪资 , 部门编号)
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE first_name LIKE 'L___';8.4.8 分支结构查询
CASEWHEN 条件1 THEN 结果1WHEN 条件2 THEN 结果2WHEN 条件3 THEN 结果3ELSE 结果
END#查询员工信息(编号,名字,薪资 , 薪资级别<对应条件表达式生成>)
SELECT employee_id , first_name , salary , department_id ,CASEWHEN salary>=10000 THEN 'A'WHEN salary>=8000 AND salary<10000 THEN 'B'WHEN salary>=6000 AND salary<8000 THEN 'C'WHEN salary>=4000 AND salary<6000 THEN 'D'ELSE 'E'END as "LEVEL"
FROM t_employees;8.5 时间查询
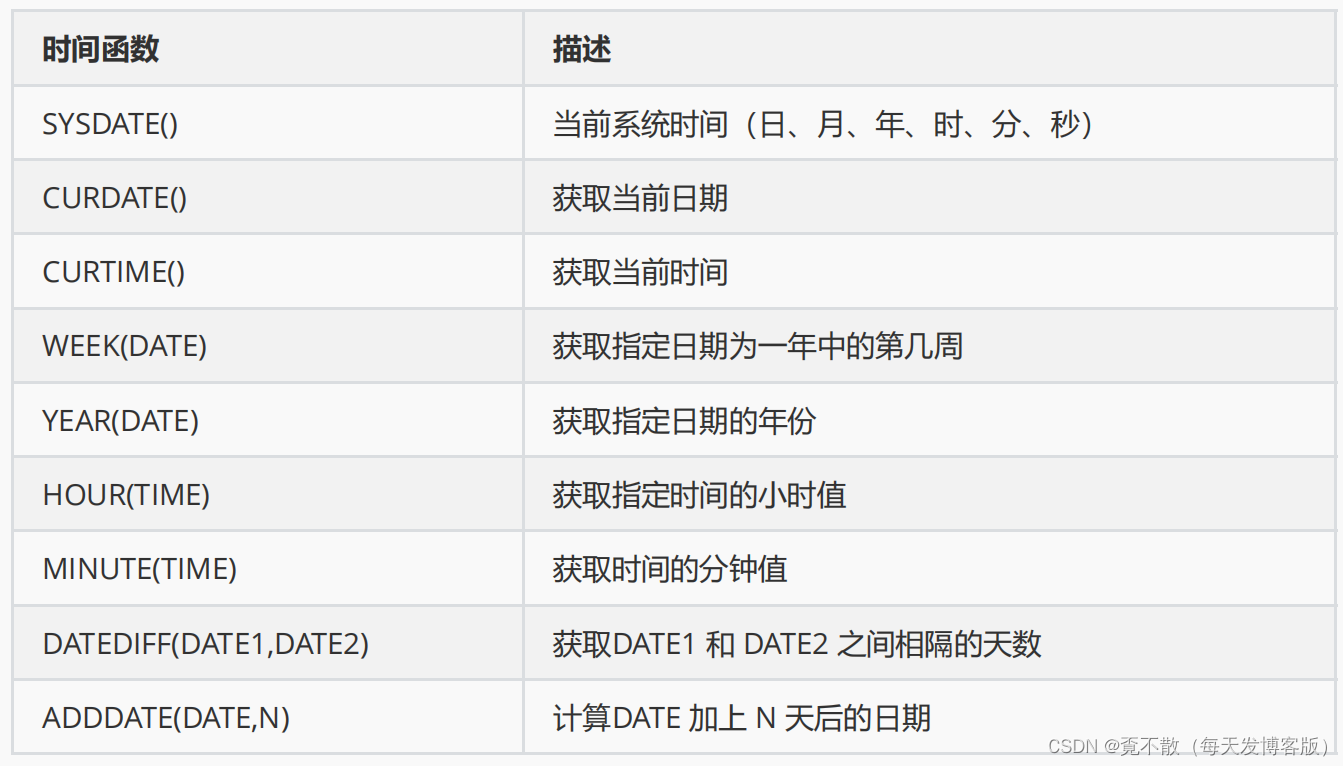
8.5.1 获得当前系统时间
#查询当前时间
SELECT SYSDATE();#查询当前时间
SELECT NOW();#获取当前日期
SELECT CURDATE();#获取当前时间
SELECT CURTIME();8.6 字符串查询
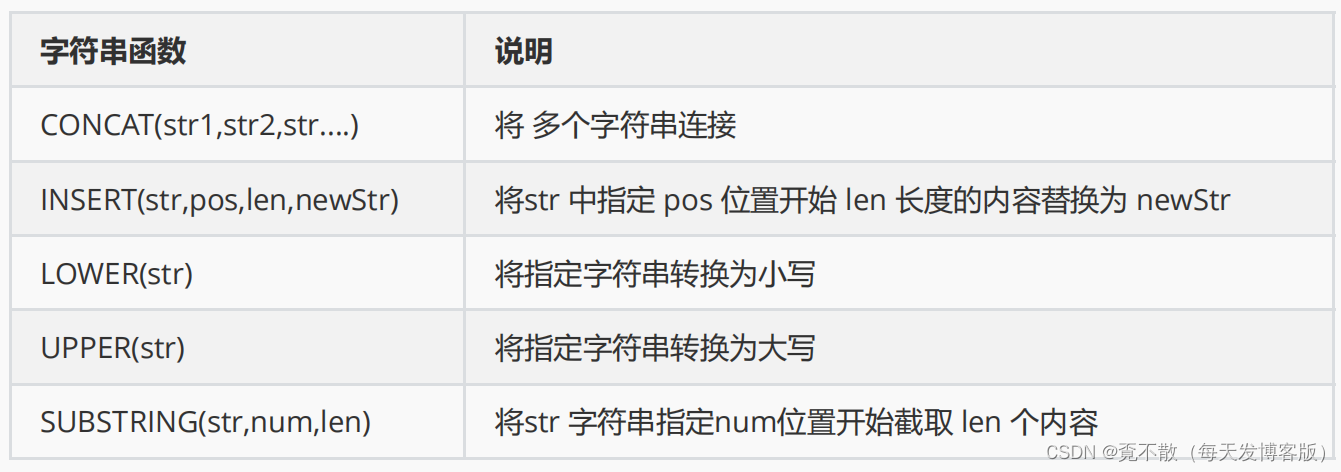
8.6.1 字符串应用
#拼接内容
SELECT CONCAT('My','S','QL');#字符串替换
SELECT INSERT('这是一个数据库',3,2,'MySql');#结果为这是 MySql 数据库#指定内容转换为小写
SELECT LOWER('MYSQL');#mysql#指定内容转换为大写
SELECT UPPER('mysql');#MYSQL#指定内容截取
SELECT SUBSTRING('JavaMySQLOracle',5,5);#MySQL8.7 聚合函数
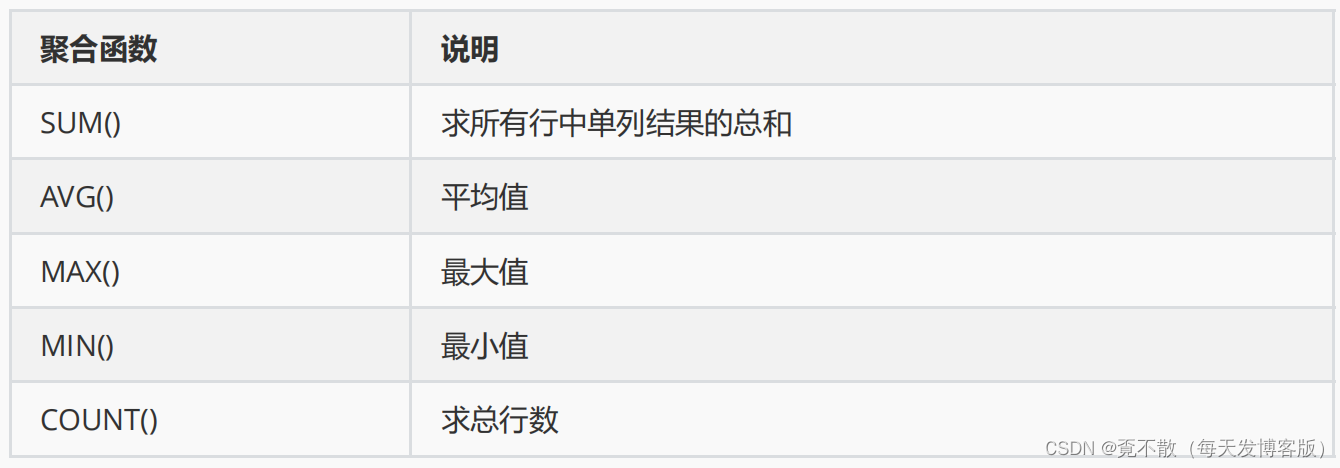
8.7.1 单列总和
#统计所有员工每月的工资总和
SELECT sum(salary)
FROM t_employees;8.7.2 单列平均值
#统计所有员工每月的平均工资
SELECT AVG(salary)
FROM t_employees;8.7.3 单列最大值
#统计所有员工中月薪最高的工资
SELECT MAX(salary)
FROM t_employees;8.7.4 单列最小值
#统计所有员工中月薪最低的工资
SELECT MIN(salary)
FROM t_employees;8.7.5 总行数
#统计员工总数
SELECT COUNT(*)
FROM t_employees;#统计有提成的员工人数
SELECT COUNT(commission_pct)
FROM t_employees;8.8 分组查询

8.8.1 查询各部门的总人数
#思路:
#1.按照部门编号进行分组(分组依据是 department_id)
#2.再针对各部门的人数进行统计(count)
SELECT department_id,COUNT(employee_id)
FROM t_employees
GROUP BY department_id;8.8.2 查询各部门的平均工资
#思路:
#1.按照部门编号进行分组(分组依据department_id)。
#2.针对每个部门进行平均工资统计(avg)。
SELECT department_id , AVG(salary)
FROM t_employees
GROUP BY department_id8.8.3 查询各个部门、各个岗位的人数
#思路:
#1.按照部门编号进行分组(分组依据 department_id)。
#2.按照岗位名称进行分组(分组依据 job_id)。
#3.针对每个部门中的各个岗位进行人数统计(count)。
SELECT department_id , job_id , COUNT(employee_id)
FROM t_employees
GROUP BY department_id , job_id;8.8.4 常见问题
#查询各个部门id、总人数、first_name
SELECT department_id , COUNT(*) , first_name
FROM t_employees
GROUP BY department_id; #error8.9 分组过滤查询

8.9.1 统计部门的最高工资
#统计60、70、90号部门的最高工资
#思路:
#1). 确定分组依据(department_id)
#2). 对分组后的数据,过滤出部门编号是60、70、90信息
#3). max()函数处理
SELECT department_id , MAX(salary)
FROM t_employees
GROUP BY department_id
HAVING department_id in (60,70,90)
# group确定分组依据department_id
#having过滤出60 70 90部门
#select查看部门编号和max函数。8.10 限定查询

8.10.1 查询前 5 行记录
#查询表中前五名员工的所有信息
SELECT * FROM t_employees LIMIT 0,5;8.10.2 查询范围记录
#查询表中从第四条开始,查询 10 行
SELECT * FROM t_employees LIMIT 3,10;8.10.3 LIMIT典型应用
#思路:第一页是从 0开始,显示 10 条
SELECT * FROM LIMIT 0,10;#第二页是从第 10 条开始,显示 10 条
SELECT * FROM LIMIT 10,10;#第三页是从 20 条开始,显示 10 条
SELECT * FROM LIMIT 20,10;8.11 查询总结
8.11.1 SQL 语句编写顺序
8.11.2 SQL 语句执行顺序
1.FROM :指定数据来源表
2.WHERE : 对查询数据做第一次过滤
3.GROUP BY : 分组
4.HAVING : 对分组后的数据第二次过滤
5.SELECT : 查询各字段的值
6.ORDER BY : 排序
7.LIMIT : 限定查询结果8.12 子查询(作为条件判断)
8.12.1 查询工资大于Bruce 的员工信息
#1.先查询到 Bruce 的工资(一行一列)
SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce';#工资是 6000
#2.查询工资大于 Bruce 的员工信息
SELECT * FROM t_employees WHERE SALARY > 6000;
#3.将 1、2 两条语句整合
SELECT * FROM t_employees WHERE SALARY > (SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce' );8.13 子查询(作为枚举查询条件)
8.13.1 查询与名为'King'同一部门的员工信息
#思路:
#1. 先查询 'King' 所在的部门编号(多行单列)
SELECT department_id
FROM t_employees
WHERE last_name = 'King'; //部门编号:80、90#2. 再查询80、90号部门的员工信息
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE department_id in (80,90);#3.SQL:合并
SELECT employee_id , first_name , salary , department_id
FROM t_employees
WHERE department_id in (SELECT department_id cfrom t_employees WHERE last_name = 'King'); #N行一列8.13.2 工资高于60部门所有人的信息
#1.查询 60 部门所有人的工资(多行多列)
SELECT SALARY from t_employees WHERE DEPARTMENT_ID=60;#2.查询高于 60 部门所有人的工资的员工信息(高于所有)
select * from t_employees where SALARY > ALL(select SALARY from t_employees WHERE DEPARTMENT_ID=60);#。查询高于 60 部门的工资的员工信息(高于部分)
select * from t_employees where SALARY > ANY(select SALARY from t_employees WHERE DEPARTMENT_ID=60);8.14 子查询(作为一张表)
8.14.1 查询员工表中工资排名前 5 名的员工信息
#思路:
#1. 先对所有员工的薪资进行排序(排序后的临时表)
select employee_id , first_name , salary
from t_employees
order by salary desc#2. 再查询临时表中前5行员工信息
select employee_id , first_name , salary
from (临时表)
limit 0,5;#SQL:合并
select employee_id , first_name , salary
from (select employee_id , first_name , salary from t_employees order by salary
desc) as temp
limit 0,5;8.15 合并查询(了解)
8.15.1 合并两张表的结果(去除重复记录)
#合并两张表的结果,去除重复记录
SELECT * FROM t1 UNION SELECT * FROM t2;8.15.2 合并两张表的结果(保留重复记录)
#合并两张表的结果,不去除重复记录(显示所有)
SELECT * FROM t1 UNION ALL SELECT * FROM t2;8.16 表连接查询
8.16.1 内连接查询(INNER JOIN ON)
#1.查询所有有部门的员工信息(不包括没有部门的员工) SQL 标准
SELECT * FROM t_employees INNER JOIN t_jobs ON t_employees.JOB_ID = t_jobs.JOB_ID#2.查询所有有部门的员工信息(不包括没有部门的员工) MYSQL
SELECT * FROM t_employees,t_jobs WHERE t_employees.JOB_ID = t_jobs.JOB_ID8.16.2 三表连接查询
#查询所有员工工号、名字、部门名称、部门所在国家ID
SELECT * FROM t_employees e
INNER JOIN t_departments d
on e.department_id = d.department_id
INNER JOIN t_locations l
ON d.location_id = l.location_id8.16.3 左外连接(LEFT JOIN ON)
#查询所有员工信息,以及所对应的部门名称(没有部门的员工,也在查询结果中,部门名称以NULL 填充)
SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM
t_employees e
LEFT JOIN t_departments d
ON e.department_id = d.department_id;8.16.4 右外连接(RIGHT JOIN ON)
#查询所有部门信息,以及此部门中的所有员工信息(没有员工的部门,也在查询结果中,员工信息以NULL填充)
SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM
t_employees e
RIGHT JOIN t_departments d
ON e.department_id = d.department_id;九、数据库高级
9.1 存储过程
9.1.1 创建存储过程
CREATE[DEFINER = { user | CURRENT_USER }]PROCEDURE sp_name ([proc_parameter[,...]])[characteristic ...] routine_bodyproc_parameter:[ IN | OUT | INOUT ] param_name typecharacteristic:COMMENT 'string'| LANGUAGE SQL| [NOT] DETERMINISTIC| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }| SQL SECURITY { DEFINER | INVOKER }routine_body:Valid SQL routine statement[begin_label:] BEGIN[statement_list]……
END [end_label]DELIMITER $$
CREATE PROCEDURE pro_test1()BEGININSERT INTO t2(tname) VALUES('haha');UPDATE t1 SET tname='jack1' WHERE tid=1;SELECT * FROM t1;END $$
call pro_test1()9.1.2 存储过程参数
CREATE PROCEDURE pro_test2(IN t2_name VARCHAR(20) , IN t1_id INT)BEGININSERT INTO t2(tname) VALUES(t2_name);UPDATE t1 SET tname='jack1' WHERE tid=t1_id;SELECT * FROM t1;END $$
CALL pro_test2('hehe',2)DELIMITER $$
CREATE PROCEDURE pro_test3(OUT tname VARCHAR(20))BEGINSET tname = 'xixi';END $$
CALL pro_test3(@tname);
SELECT @tname;DELIMITER $$
CREATE PROCEDURE pro_test4(INOUT tname VARCHAR(20))BEGINSELECT tname;SELECT CONCAT(tname,"hello") INTO tname;END $$
SET @tname='jack';
CALL pro_test4(@tname);
SELECT @tname;9.1.3 存储过程变量
declare num2 int default 100;
select num2;
DELIMITER $$
CREATE PROCEDURE pro_test5()BEGINDECLARE num INT DEFAULT 100;SELECT num;set num = 200;select num;END $$
CALL pro_test5DELIMITER $$
CREATE PROCEDURE pro_test6()BEGINDECLARE num INT DEFAULT 100;SELECT num;SELECT tid INTO num FROM t1 WHERE tname='jack';SELECT num;END $$
CALL pro_test6DELIMITER $$
CREATE PROCEDURE pro_test7()BEGINSET @param_t1 = 300;SELECT @param_t1;SELECT tid INTO @param_t1 FROM t1 WHERE tname='jack';SELECT @param_t1;END $$
CALL pro_test7根据系统变量的作用域分为:全局变量与会话变量(两个@符号)全局变量(@@global.)在MySQL启动的时候由服务器自动将全局变量初始化为默认值;全局变量的默认值可以通过更改MySQL配置文件(my.ini、my.cnf)来更改。会话变量(@@session.)在每次建立一个新的连接的时候,由MySQL来初始化;
MYSQL会将当前所有全局变量的值复制一份来做为会话变量(也就是说,如果在建立会话以后,没有手动更改过会话变量与全局变量的值,那所有这些变量的值都是一样的)。
全局变量与会话变量的区别:对全局变量的修改会影响到整个服务器,但是对会话变量的修改,只会影响到当前的会话。9.1.4 条件语句
IF expression THENstatements;
END IF;
----------------------------------------
IF expression THENstatements;
ELSEelse-statements;
END IF;
----------------------------------------
IF expression THENstatements;
ELSEIF elseif-expression THENelseif-statements;
...
ELSEelse-statements;
END IF;DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)BEGINIF tid = 1 THENINSERT INTO t1(tname) VALUES('tom');END IF;
END $$
CALL pro_test8(1);
-----------------------------------------------------------------
DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)BEGINIF tid = 1 THENINSERT INTO t1(tname) VALUES('tom');ELSESELECT CONCAT(tid,'xixi');END IF;END $$
CALL pro_test8(2);
---------------------------------------------------------------------
DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)BEGINIF tid = 1 THENINSERT INTO t1(tname) VALUES('tom');ELSEIF tid = 2 THENSELECT CONCAT(tid,'xixi');ELSEIF tid = 3 THENSELECT CONCAT(tid,'xxxxxx');END IF;END $$
CALL pro_test8(3);9.1.5 循环语句
DELIMITER $$
CREATE PROCEDURE pro_test9(IN number INT)BEGIN-- 满足什么条件继续循环WHILE number > 0 DOSELECT number;SET number=number-1;END WHILE;END $$
CALL pro_test9(6);DELIMITER $$
CREATE PROCEDURE pro_test10(IN number INT)BEGINREPEATINSERT INTO t1(tname) VALUES(CONCAT('aa',number));SET number=number-1;UNTIL number < 0 -- 这里不需要加分号 这个是满足什么条件退出循环END REPEAT;END $$
CALL pro_test10(6);DELIMITER $$
CREATE PROCEDURE pro_test11()BEGINBEGINDECLARE i INT DEFAULT 0;loop_x : LOOPINSERT INTO t1(tname) VALUES(CONCAT('bb',i));SET i=i+1;IF i > 5 THENLEAVE loop_x;END IF;END LOOP;END;END $$
CALL pro_test119.1.6 分支语句
DELIMITER $$
CREATE PROCEDURE pro_test12(IN var INT)BEGINCASE varWHEN 1 THENSELECT 'a';WHEN 2 THENSELECT 'b';ELSESELECT 'c';END CASE;END $$
CALL pro_test12(2);9.2 函数(了解)
CREATE FUNCTION func_name ([param_name type[,...]])
RETURNS type
[characteristic ...]
BEGINroutine_body
END;(1)func_name :存储函数的名称。
(2)param_name type:可选项,指定存储函数的参数。
(3)RETURNS type:指定返回值的类型。
(4)characteristic:可选项,指定存储函数的特性。
(5)routine_body:SQL代码内容。调用函数
SELECT func_name([parameter[,…]]);DELIMITER //
CREATE FUNCTION fc_test(id INT)
RETURNS VARCHAR(20)
BEGINSELECT tname INTO @name FROM t1 WHERE tid=id;RETURN @name;
END //
SELECT fc_test(2);9.3 触发器Trigger(了解)
9.3.1 主外键级联操作
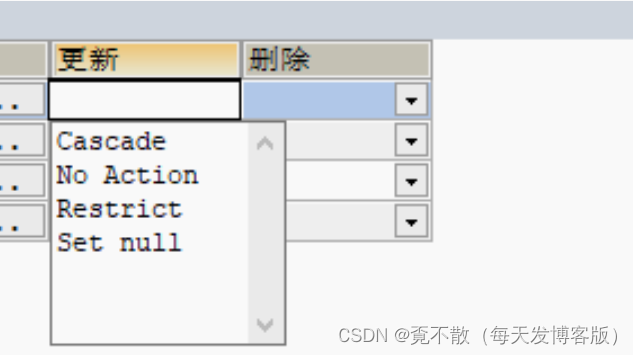
NULL、RESTRICT、NO ACTION
删除:从表记录不存在时,主表才可以删除。删除从表,主表不变
更新:从表记录不存在时,主表才可以更新。更新从表,主表不变CASCADE
删除:删除主表时自动删除从表。删除从表,主表不变
更新:更新主表时自动更新从表。更新从表,主表不变SET NULL
删除:删除主表时自动更新从表值为NULL。删除从表,主表不变
更新:更新主表时自动更新从表值为NULL。更新从表,主表不变9.3.2 Trigger
CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROW
trigger_stmt
trigger_name:触发器的名称
tirgger_time:触发时机,为BEFORE或者AFTER
trigger_event:触发事件,为INSERT、DELETE或者UPDATE
tb_name:表示建立触发器的表明,就是在哪张表上建立触发器
trigger_stmt:触发器的程序体,可以是一条SQL语句或者是用BEGIN和END包含的多条语句
所以可以说MySQL创建以下六种触发器:
BEFORE INSERT,BEFORE DELETE,BEFORE UPDATE
AFTER INSERT,AFTER DELETE,AFTER UPDATEBEFORE和AFTER参数指定了触发执行的时间,在事件之前或是之后
FOR EACH ROW表示任何一条记录上的操作满足触发事件都会触发该触发器CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件
ON 表名 FOR EACH ROW
BEGIN执行语句列表
END
DELIMITER $$
CREATE TRIGGER tri_test1 AFTER DELETE
ON t1 FOR EACH ROWBEGININSERT INTO t2(tname) VALUES('ssss');
END$$SELECT * FROM t1;
SELECT * FROM t2;UPDATE t1 SET tname = 'aaa' WHERE tid = 1;
DELETE FROM t1 WHERE tid=1;9.4 视图(了解)
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]VIEW view_name [(column_list)]AS select_statement[WITH [CASCADED | LOCAL] CHECK OPTION]CREATE VIEW view_test1
AS
SELECT * FROM t1;CREATE VIEW view_test2
AS
SELECT employee_id,first_name,manager_name FROM employee LEFT JOIN manager ON
employee.`manager_id` = manager.`manager_id`;9.5 索引和约束
9.5.1 约束
1、非空约束:not null; 指示某列不能存储 NULL 值。
2、唯一约束:unique(); unique约束的字段,要求必须是唯一的,但null除外。
3、主键约束:primary key(); 主键约束=not null + unique,确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
4、外键约束:foreign key ;保证一个表中的数据匹配另一个表中的值的参照完整性。
5、自增约束:auto_increment。
6、默认约束:default 给定默认的值。
7、检查性约束:check 保证列中的值符合指定的条件。9.5.2 索引
1、主键索引(primary key);
2、唯一索引(unique);
3、常规索引(index);
4、全文索引(full text);
全文索引是MyISAM的一个特殊索引类型,它查找的是文本中的关键词,主要用于全文检索。
MySQL InnoDB从5.6开始已经支持全文索引,但InnoDB内部并不支持中文、日文等,因为这些语言没有分隔符。可以使用插件辅助实现中文、日文等的全文索引。SHOW INDEX FROM table_name;索引字段尽量使用数字型(简单的数据类型)
尽量不要让字段的默认值为NULL
使用唯一索引
使用组合索引代替多个列索引
注意重复/冗余的索引、不使用的索引1.查询中很少使用到的列 不应该创建索引,如果建立了索引然而还会降低mysql的性能和增大了空间需求。
2.很少数据的列也不应该建立索引,比如 一个性别字段 0或者1,在查询中,结果集的数据占了表中数据行的比例比较大,mysql需要扫描的行数很多,增加索引,并不能提高效率。
3.定义为text和image和bit数据类型的列不应该增加索引。
4.当表的修改(UPDATE,INSERT,DELETE)操作远远大于检索(SELECT)操作时不应该创建索引,这两个操作是互斥的关系。相关文章:
JavaWeb笔记之MySQL数据库
#Author 流云 #Version 1.0 一、引言 1.1 现有的数据存储方式有哪些? Java程序存储数据(变量、对象、数组、集合),数据保存在内存中,属于瞬时状态存储。 文件(File)存储数据,保存…...
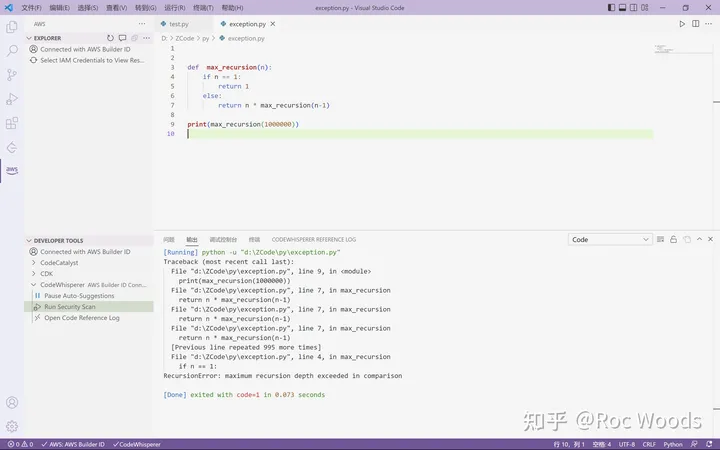
Amazon CodeWhisperer 开箱初体验
文章作者:Coder9527 科技的进步日新月异,正当人工智能发展如火如荼的时候,各大厂商在“解放”码农的道路上不断创造出各种 Coding 利器,今天在下就带大家开箱体验一个 Coding 利器: Amazon CodeWhisperer。 亚马逊云科…...

Java的引用类型有几种?区别是什么?
Java中的引用类型主要分为四种:强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)和虚引用(Phantom Reference)。这些引用类型在Java中主要用于…...

掌握iText:轻松处理PDF文档-基础篇
关于iText iText是一个强大的PDF处理库,可以用于创建、读取和操作PDF文件。它支持PDF表单、加密和签署等操作,同时支持多种字体和编码。maven的中央仓库中的最新版本是5.X,且iText5不是完全免费的,但是基础能力是免费使用的&…...

小红书民宿文案怎么写?建议收藏
随着民宿市场的日益火爆,如何在众多民宿中脱颖而出,吸引更多租客入住,成为摆在每一位民宿业主面前的难题。一篇优质的小红书民宿文案,不仅能吸引潜在租客的关注,还能提高民宿的知名度。本文伯乐网络传媒将从八个方面教…...

C#教程(一):面向对象
1、介绍 C#是一种多范式编程语言,但其中一个主要的编程范式是面向对象编程(OOP)。面向对象编程有一些特点,而C#提供了丰富的功能来支持这些特点。 2、面向对象特点 封装(Encapsulation): 封装…...

Linux系统中部署minio服务、开启反向代理、二级域名SSL加固
链接: B站1小时-配置指导视频: 一、创建minio 文件目录(/project/minio) 二、下载Minio wget https://dl.min.io/server/minio/release/linux-amd64/minio 三、在minio目录中-创建日志文件 四、对minio(可以理解为windows系统中的.exe可执行文件) 进行授权 chmod 777 min…...

PMP备考总结:项目管理PMP考试提高通过率,轻松上岸~
分享一篇左羊学霸的备考总结,希望能帮到正在备考的友友们~ 前言 作为⼀名通过PMP项⽬管理认证并且拿到3A成绩 ( PMP认证最好成绩) 的 学习者, 来跟⼤家分享下我考取PMP证书的动机与过程 。考证不是主要⽬ 的, 在考证的过程深化⾃⼰的项⽬管理…...

shell脚本中获取当前脚本的绝对路径
说明: PWD 是获取当前脚本的执行路径的,下面的方式是获取文件绝对路径的。 话不多说,直接上硬货!!! #!/bin/bashecho "执行路径 $PWD"absolute_path$(readlink -f "$0") # 获取目录路径 directory$(dirname "$absolute_path&q…...
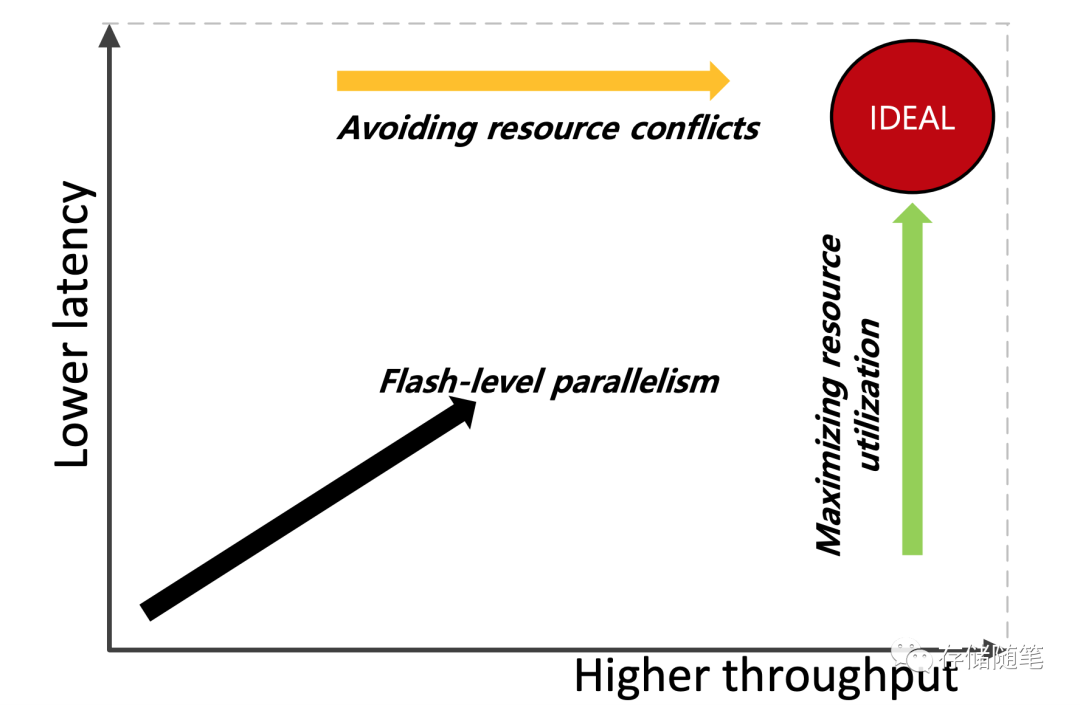
SSD基础架构与NAND IO并发问题探讨
在我们的日常生活中,我们经常会遇到一些“快如闪电”的事物:比如那场突如其来的雨、那个突然出现在你眼前的前任、还有就是今天我们要聊的——固态硬盘(SSD)。 如果你是一个技术宅,或者对速度有着近乎偏执的追求&…...

激光雷达反射率定标板如何提取障碍信息
随着信息科技技术的发展,自动驾驶技术在移动机器人等智能移动设备领域得到广泛应用。智能移动设备不仅减少了人力劳动,方便生活,而且提高了工作效率。激光雷达作为自动驾驶技术的核心避障传感器,得到迅速发展。 激光雷达通过对发射…...

【开源】基于JAVA的桃花峪滑雪场租赁系统
项目编号: S 036 ,文末获取源码。 \color{red}{项目编号:S036,文末获取源码。} 项目编号:S036,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 游客服务2.2 雪场管理 三、数据库设…...

将VOC2012格式的数据集转为YOLOV8格式
文章目录 简介1.数据集格式1.1数据集目录格式对比1.2标签格式对比 2.格式转换脚本3.文件处理脚本 简介 将voc2012中xml格式的标签转为yolov8中txt格式将转换后的图像和标签按照yolov8训练的要求整理为对应的目录结构 1.数据集格式 1.1数据集目录格式对比 (1&…...
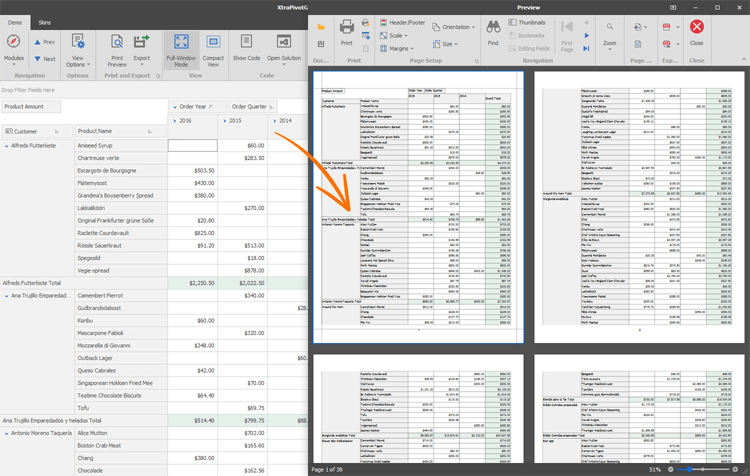
DevExpress WinForms Pivot Grid组件,一个类似Excel的数据透视表控件(二)
界面控件DevExpress WinForms的Pivot Grid组件是一个类似Excel的数据透视表控件,用于多维(OLAP)数据分析和跨选项卡报表。在上文中(点击这里回顾>>)我们介绍了DevExpress WinForms Pivot Grid组件的性能、分析服务、数据塑造能力等&…...

为什么越来越多的人从事软件测试行业?
1.市场需求增加:随着数字化转型和互联网的普及,各行各业都需要高质量、稳定可靠的软件来支持其业务运作。因此,对软件测试人员的需求也随之增加。同时,新兴技术的发展,如物联网、大数据、区块链、人工智能等࿰…...

ERP数据仓库模型
ERP数据仓库模型建设是一个复杂的过程,涉及到多个主题域。以下是一个详细的设计方案: 确定业务需求和目标 在开始设计数据仓库模型之前,需要了解企业的业务需求和目标。这包括了解企业的运营模式、业务流程、关键绩效指标等。通过与业务部门…...

基于单片机的智能小车 (论文+源码)
1. 系统设计 此次可编程智能小车系统的设计系统,结合STM32单片机,蓝牙模块,循迹模块,电机驱动模块来共同完成本次设计,实现小车的循迹避障功能和手机遥控功能,其整体框架如图2.1所示。其中,采用…...
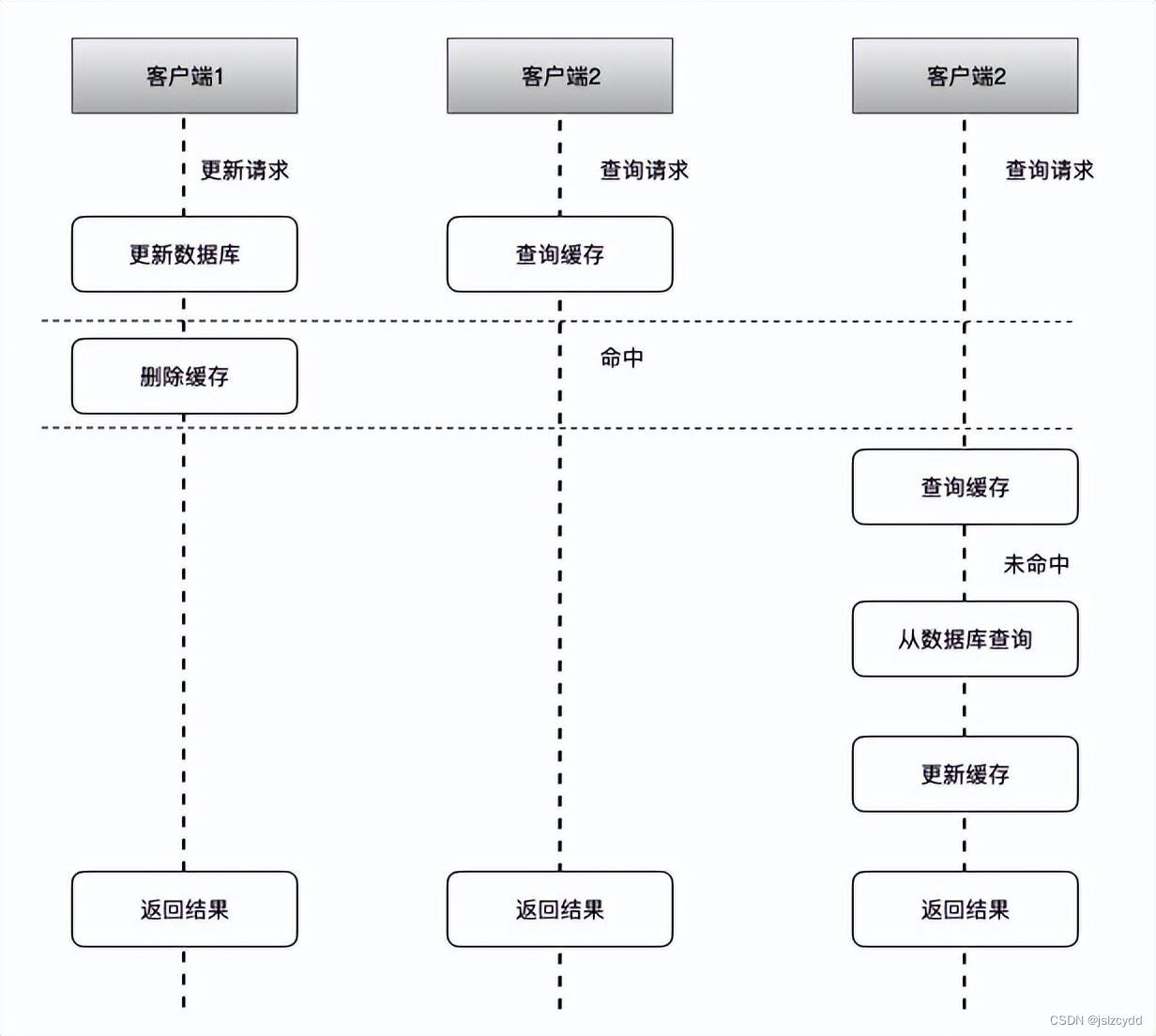
Redis和MySQL双写一致性实用解析
1、背景 先阐明一下Mysql和Redis的关系:Mysql是数据库,用来持久化数据,一定程度上保证数据的可靠性;Redis是用来当缓存,用来提升数据访问的性能。 关于如何保证Mysql和Redis中的数据一致(即缓存一致性问题…...
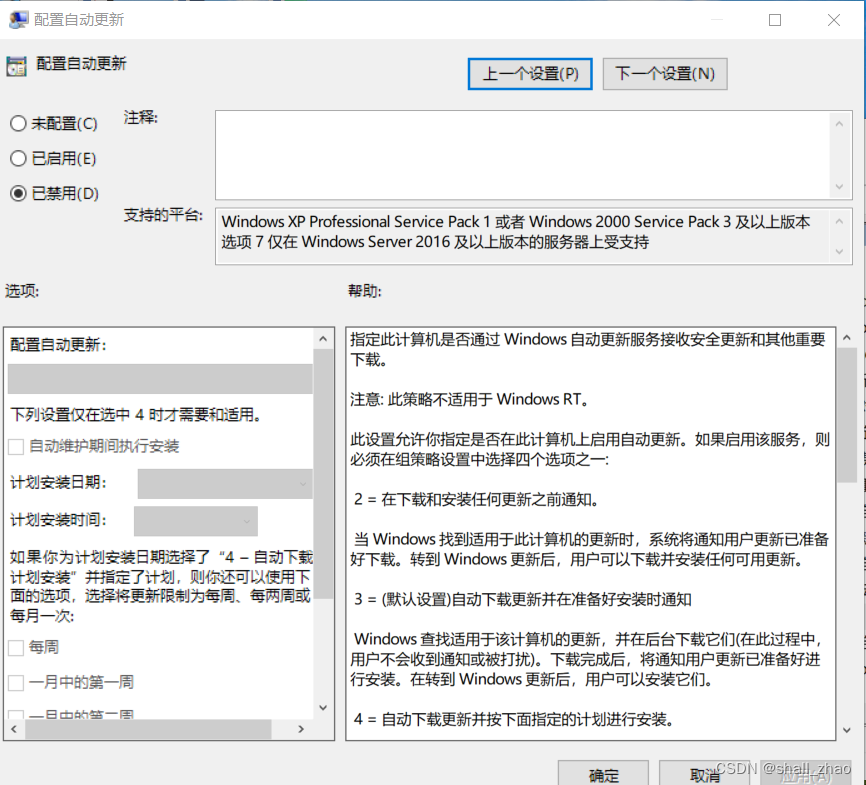
win10彻底永久关闭自动更新的方法
win10彻底永久关闭自动更新的方法 文章目录 win10彻底永久关闭自动更新的方法一、禁用Windows Update服务二、在组策略里关闭Win10自动更新相关服务 可以参考这个视频的做法: 教学视频搬用 一、禁用Windows Update服务 1、同时按下键盘 Win R,打开运行…...
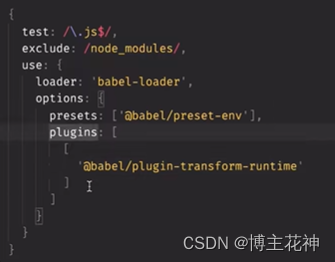
【webpack】初始化
webpack 旧项目的问题下一代构建工具 Vite 主角 :webpack安装webpack1,mode的选项2,使用source map 精准定位错误行数3,使用watch mode(观察模式),自动运行4,使用webpack-dev-server工具,自动刷…...

DaVinci Developer与Configurator Pro联调指南:如何高效设计SWC并集成到ECU工程
DaVinci Developer与Configurator Pro联调实战:从SWC设计到ECU集成的全流程解析 在汽车电子控制单元(ECU)开发领域,工具链的协同效率直接决定了项目进度和质量。作为Vector公司AUTOSAR工具链的核心组件,DaVinci Develo…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

Kubernetes配置管理实战:基于Kustomize的结构化部署与多环境管理
1. 项目概述:一个被低估的Kubernetes配置管理利器如果你和我一样,长期在Kubernetes生态里摸爬滚打,那你一定经历过这样的场景:为了部署一个稍微复杂点的应用,需要维护一堆YAML文件——Deployment、Service、ConfigMap、…...

TPU柔性材料3D打印GoPro车载支架:从减震原理到实战拍摄全指南
1. 项目概述与设计思路我一直对第一人称视角(FPV)拍摄很着迷,尤其是那种能贴着地面、模拟小车视角疾驰的画面,动态感和沉浸感是手持拍摄无法比拟的。市面上的运动相机车载支架要么是硬连接,颠簸起来画面抖动得厉害&…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

基于Docker构建标准化开发环境:原理、实践与VSCode集成指南
1. 项目概述:一个面向开发者的“开箱即用”环境在软件开发这条路上,我踩过最多的坑,往往不是来自复杂的业务逻辑,而是来自那句“在我机器上好好的”。环境配置,这个看似基础却又无比磨人的环节,消耗了无数开…...

树莓派+Kali Linux+PiTFT打造便携式安全测试平台全攻略
1. 项目概述如果你和我一样,对网络安全和嵌入式硬件都抱有浓厚的兴趣,那么将Kali Linux与树莓派结合,再配上一块小巧的触摸屏,绝对是一个能让你兴奋起来的项目。这不仅仅是把两个热门技术拼在一起,更是打造一个真正便携…...
Adafruit Feather RP2040 SCORPIO:专为大规模NeoPixel灯光控制而生的开发板
1. 项目概述:为什么你需要一块专为大规模灯光控制而生的开发板?如果你曾经尝试过用一块普通的微控制器驱动超过几百个NeoPixel(或WS2812)LED,你很可能已经撞上了性能的天花板。CPU被时序生成任务完全占用,动…...

基于CircuitPython的嵌入式游戏开发:从帧缓冲区到对象池的Flappy Bird实现
1. 项目概述:当Flappy Bird遇上CircuitPython如果你玩过经典的Flappy Bird,也捣鼓过像Raspberry Pi Pico这样的微控制器,那你有没有想过把这两者结合起来?我最近就用CircuitPython在RP2040开发板上完整复刻了一个“猫版”Flappy B…...
基于GEMMA与NeoPixel制作智能可穿戴首饰:从硬件选型到代码实现
1. 项目概述:当微型控制器遇见珠宝设计几年前,当我第一次把一块微控制器塞进一个首饰盒里,看着它驱动一圈LED发出柔和的光晕时,我就知道,电子制作和个性化穿戴的结合,远不止于智能手表或健身手环。我们今天…...