大数据云计算——Docker环境下部署Hadoop集群及运行集群案列
大数据云计算——Docker环境下部署Hadoop集群及运行集群案列
本文着重介绍了在Docker环境下部署Hadoop集群以及实际案例中的集群运行。首先,文章详细解释了Hadoop的基本概念和其在大数据处理中的重要性,以及为何选择在Docker环境下部署Hadoop集群。接着,阐述了在Docker中配置和启动Hadoop集群所需的步骤和技术要点。
在展示部署过程中,文章包含了针对Docker容器的Hadoop组件设置,并指导读者如何通过Docker Compose或其他相关工具建立一个多节点的Hadoop集群。特别强调了节点间的通信和配置,确保集群可以有效协同工作。
进一步,本文通过案例描述了在已搭建的Hadoop集群上运行的具体应用场景。案例可能涉及到数据存储、MapReduce任务或其他Hadoop支持的数据处理方式。这些案例旨在展示Hadoop集群在实际大数据处理中的应用和价值。
通过本文,读者可以深入了解如何利用Docker环境快速搭建Hadoop集群,并通过案例展示集群的运行过程,为大数据云计算中的Hadoop应用提供了实用的指导和参考。
首先查看版本环境(docker中没有下载docker和docker-compose的可以看我上一篇博客
Linux 安装配置Docker 和Docker compose 并在docker中部署mysql和中文版portainer图形化管理界面
查看docker和docker-compose版本:
docker versiondocker-compose version

OK,环境没问题,我们正式开始Docker中部署hadoop
<Docker中部署Hadoop>
更新系统
sudo apt update
sudo apt upgrade
国内加速镜像下载修改仓库源
创建或修改 /etc/docker/daemon.json 文件
sudo vi /etc/docker/daemon.json{"registry-mirrors": [ "http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn","https://registry.docker-cn.com","https://kfp63jaj.mirror.aliyuncs.com"]
}
重载docker让CDN配置生效
sudo systemctl daemon-reloadsudo systemctl restart docker
抓取ubuntu 20.04的镜像作为基础搭建hadoop环境
sudo docker pull ubuntu:20.04
使用该ubuntu镜像启动,填写具体的path替代
sudo docker run -it -v <host-share-path>:<container-share-path> ubuntu
例如
sudo docker run -it -v ~/hadoop/build:/home/hadoop/build ubuntu 
容器启动后,会自动进入容器的控制台
在容器的控制台安装所需软件
apt-get update
apt-get upgrade
安装所需软件
apt-get install net-tools vim openssh-server 
/etc/init.d/ssh start让ssh服务器自动启动
vi ~/.bashrc在文件的最末尾按O进入编辑模式,加上:
/etc/init.d/ssh start 
按ESC返回命令模式,输入:wq保存并退出。
让修改即刻生效
source ~/.bashrc
配置ssh的无密码访问
ssh-keygen -t rsa连续按回车

cd ~/.sshcat id_rsa.pub >> authorized_keys
进入docker中ubuntu里面的容器
docker start 11f9454b301fdocker exec -it clever_gauss bash
安装JDK 8
hadoop 3.x目前仅支持jdk 7, 8
apt-get install openjdk-8-jdk在环境变量中引用jdk,编辑bash命令行配置文件
vi ~/.bashrc在文件的最末尾加上
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/export PATH=$PATH:$JAVA_HOME/bin
让jdk配置即刻生效
source ~/.bashrc![]()
测试jdk正常运作
java -version
将当前容器保存为镜像
sudo docker commit <CONTAINER ID> <IMAGE NAME> #自己起的镜像名字
sudo docker commit 11f9454b301f ubuntu204 #我的是ubuntu204
可以看到该镜像已经创建成功,下次需要新建容器时可直接使用该镜像

注意!!!此过程的两个相关路径如下(不要搞混了):
<host-share-path>指的是~/hadoop/build
<container-share-path>指的是/home/hadoop/build
下载hadoop,下面以3.2.3为例
https://hadoop.apache.org/releases.html
cd ~/hadoop/buildwget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz(这种方法能下载但是会出现下载的包大小不对,我们可以用第二种方法)
方法二:
在自己电脑浏览器输入下载https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
下载到自己电脑上 通过winscp上传到虚拟机中

然后有安装包的目录打开终端, 输入
sudo mv hadoop-3.2.3.tar.gz ~/hadoop/build移动文件到目录 ~/hadoop/build

在容器控制台上解压hadoop(就是之前创建的容器的控制台,不是自己的控制台!
docker start 11f9454b301fdocker exec -it clever_gauss bashcd /home/hadoop/buildtar -zxvf hadoop-3.2.3.tar.gz -C /usr/local

安装完成了,查看hadoop版本
cd /usr/local/hadoop-3.2.3./bin/hadoop version
为hadoop指定jdk位置
vi etc/hadoop/hadoop-env.sh![]()
查找到被注释掉的JAVA_HOME配置位置,更改为刚才设定的jdk位置
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/hadoop联机配置
配置core-site.xml文件
vi etc/hadoop/core-site.xml加入:
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop-3.2.3/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property>
</configuration>
配置hdfs-site.xml文件
vi etc/hadoop/hdfs-site.xml
加入
<configuration><!--- 配置保存Fsimage位置 --><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop-3.2.3/namenode_dir</value></property><!--- 配置保存数据文件的位置 --><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop-3.2.3/datanode_dir</value></property><property><name>dfs.replication</name><value>3</value></property> </configuration>

MapReduce配置
该配置文件的定义:
https://hadoop.apache.org/docs/r<Hadoop版本号>/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
配置mapred-site.xml文件
vi etc/hadoop/mapred-site.xml
加入:
<configuration><!--- mapreduce框架的名字 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><! -- 设定HADOOP的位置给yarn和mapreduce程序 --><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
配置yarn-site.xml文件
vi etc/hadoop/yarn-site.xml
加入
<configuration>
<!-- Site specific YARN configuration properties --><!-- 辅助服务,数据混洗 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>master</value></property>
</configuration>
服务启动权限配置
配置start-dfs.sh与stop-dfs.sh文件
vi sbin/start-dfs.sh 和 vi sbin/stop-dfs.shvi sbin/start-dfs.shHDFS_DATANODE_USER=rootHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root
继续修改配置文件
vi sbin/stop-dfs.shHDFS_DATANODE_USER=rootHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root
配置start-yarn.sh与stop-yarn.sh文件
vi sbin/start-yarn.sh 和 vi sbin/stop-yarn.shvi sbin/start-yarn.shYARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root
vi sbin/stop-yarn.shYARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root
核心文件一定不能配错,否则后面会出现很多问题!
配置完成,保存镜像
docker ps
docker commit 11f9454b301f ubuntu-myx保存的镜像名为 ubuntu-myx
![]()

启动hadoop,并进行网络配置
打开三个宿主控制台,启动一主两从三个容器
master
打开端口映射:8088 => 8088
sudo docker run -p 8088:8088 -it -h master --name master ubuntu-myx
启动节点worker01
sudo docker run -it -h worker01 --name worker01 ubuntu-myx
节点worker02
sudo docker run -it -h worker02 --name worker02 ubuntu-myx

分别打开三个容器的/etc/hosts,将彼此的ip地址与主机名的映射信息补全(三个容器均需要如此配置)
vi /etc/hosts使用以下命令查询ip
ifconfig
添加信息(每次容器启动该文件都需要调整)
172.17.0.3 master
172.17.0.4 worker01
172.17.0.5 worker02



检查配置是否有效
ssh masterssh worker01ssh worker02master 连接worker01节点successfully:

worker01节点连接master 成功:

worker02连接worker01节点successfully:

在master容器上配置worker容器的主机名
cd /usr/local/hadoop-3.2.3vi etc/hadoop/workers
删除localhost,加入
worker01
worker02

网络配置完成
启动hadoop
在master主机上
cd /usr/local/hadoop-3.2.3./bin/hdfs namenode -format正常启动


启动服务
./sbin/start-all.sh
效果如下表示正常

在hdfs上建立一个目录存放文件
假设该目录为:/home/hadoop/input
./bin/hdfs dfs -mkdir -p /home/hadoop/input./bin/hdfs dfs -put ./etc/hadoop/*.xml /home/hadoop/input
查看分发复制是否正常
./bin/hdfs dfs -ls /home/hadoop/input
运行案例:
在hdfs上建立一个目录存放文件
例如
./bin/hdfs dfs -mkdir -p /home/hadoop/wordcount把文本程序放进去
./bin/hdfs dfs -put hello /home/hadoop/wordcount查看分发情况
./bin/hdfs dfs -ls /home/hadoop/wordcount

运行MapReduce自带wordcount的示例程序(自带的样例程序运行不出来,可能是虚拟机性能的问题,这里就换成了简单的wordcount程序)
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount /home/hadoop/wordcount /home/hadoop/wordcount/output
运行成功:


运行结束后,查看输出结果
./bin/hdfs dfs -ls /home/hadoop/wordcount/output./bin/hdfs dfs -cat /home/hadoop/wordcount/output/*
至此,Docker部署hadoop成功!跟着步骤走一般都没有什么问题。
相关文章:
大数据云计算——Docker环境下部署Hadoop集群及运行集群案列
大数据云计算——Docker环境下部署Hadoop集群及运行集群案列 本文着重介绍了在Docker环境下部署Hadoop集群以及实际案例中的集群运行。首先,文章详细解释了Hadoop的基本概念和其在大数据处理中的重要性,以及为何选择在Docker环境下部署Hadoop集群。接着&…...
)
计算机网络链路层(期末、考研)
计算机网络总复习链接🔗 目录 组帧差错控制检错编码纠错编码 流量控制与可靠传输机制流量控制、可靠传输与滑动窗口机制单帧窗口与停止-等待协议多帧滑动窗口与后退N帧协议(GBN)多帧滑动窗口与选择重传协议 介质访问控制信道划分介质访问控制…...

洛谷 P8794 [蓝桥杯 2022 国 A] 环境治理
文章目录 [蓝桥杯 2022 国 A] 环境治理题目链接题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示 思路解析CODE给点思考 [蓝桥杯 2022 国 A] 环境治理 题目链接 https://www.luogu.com.cn/problem/P8794 题目描述 LQ 国拥有 n n n 个城市,从 0 0 …...

力扣面试150题 | 买卖股票的最佳时期
力扣面试150题 | 买卖股票的最佳时期 题目描述解题思路代码实现 题目描述 121.买卖股票的最佳时期 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一…...
uniapp 之 图片 视频 文件上传
<view class"" style"padding: 24rpx 0"><text>相关资料 <text class"fs-26 color-666">(图片、视频、文档不超过9个)</text> </text><view class"flex align-center" style&…...

MIT线性代数笔记-第28讲-正定矩阵,最小值
目录 28.正定矩阵,最小值打赏 28.正定矩阵,最小值 由第 26 26 26讲的末尾可知在矩阵为实对称矩阵时,正定矩阵有以下四种判定方法(都是充要条件): 所有特征值都为正左上角所有 k k k阶子矩阵行列式都为正&…...
Python:五种算法RFO、GWO、DBO、HHO、SSA求解23个测试函数
一、五种算法介绍 (1)红狐优化算法(Red fox optimization,RFO) (2)灰狼优化算法(Grey Wolf Optimizer,GWO) (3)蜣螂优化算法(Dung beetle opti…...

如何参与开源项目
大家好,受卡哥邀请,和大家分享一下开源活动的相关经验。首先简要自我介绍一下,我目前在一所985研二在读,主要学习大数据方向,从去年开始参与开源活动近一年时间,也对多个Apache框架有所贡献。 由于学校或专…...
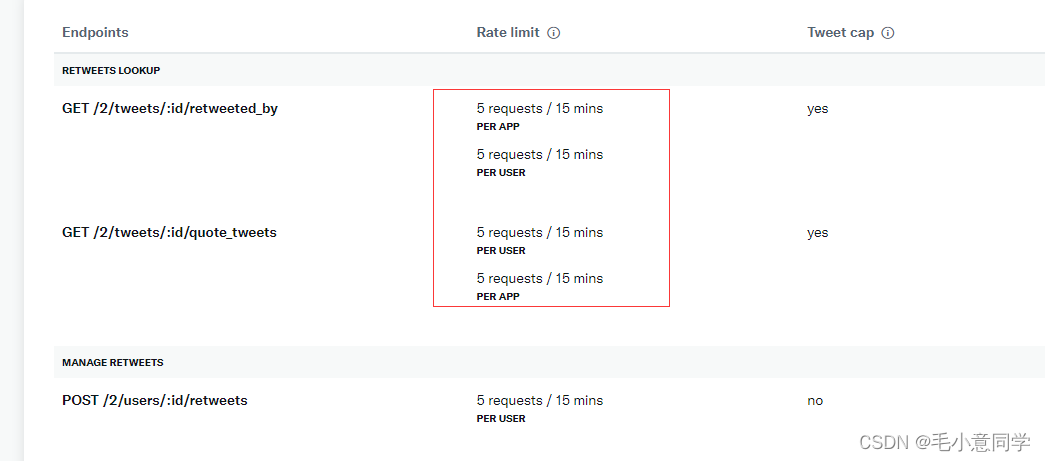
twitter开发如何避坑
此篇介绍在twitter开发过程中遇到的坑(尤其是费用的坑)。 一坑:免费接口少! 刚开始申请免费API使用的时候,twitter官方只会给你三个免费接口使用。 发twitter、删推文、查看用户信息。 这三个接口远远不够开发中使用…...
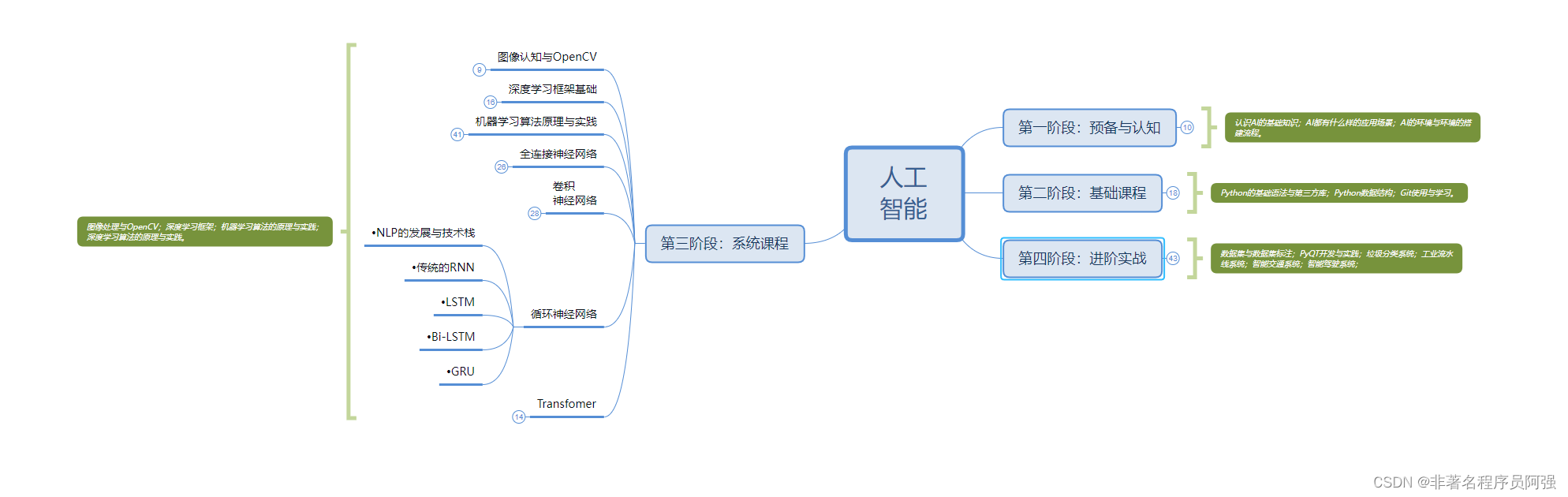
人工智能算法合集
人工智能(Artificial Intelligence,AI)作为当今世界最热门的技术领域之一,正日益改变着我们的生活方式、工作方式甚至整个社会结构。在人工智能领域中,算法是至关重要的一环,它们是实现人工智能技术应用的核…...

PythonStudio:一款国人写的python及窗口开发编辑IDE,可以替代pyqt designer等设计器了
本款软件只有十几兆,功能算是强大的,国人写的,很不错的python界面IDE.顶部有下载链接。下面有网盘下载链接,或者从官网直接下载。 目前产品免费,以后估计会有收费版本。主页链接:PythonStudio-硅量实验室 作…...
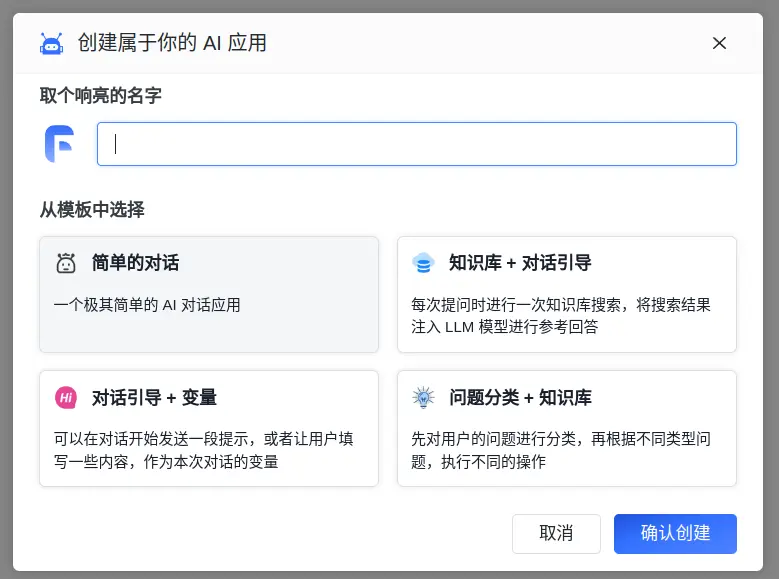
大模型应用_FastGPT
1 功能 整体功能,想解决什么问题 官方说明:FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!个人体会…...

elasticsearch|大数据|elasticsearch的api部分实战操作以及用户和密码的管理
一, 前言 本文主要内容是通过elasticsearch的api来进行一些集群的管理和信息查询工作,以及elasticsearch用户的增删改查和密码的重设以及重置如何操作 接上文:elasticsearch|大数据|elasticsearch低版本集群的部署安装和安全增强---密码设…...

Android多进程和跨进程通讯方式
前言 我们经常开发过程中经常会听到线程和进程,在讲述Android进程多进程前我打算先简单梳理一下这俩者。 了解什么是进程与线程 进程: 系统中正在运行的一个应用程序,某个程序一旦运行就是一个进程,是资源分配的最小单位&#…...

通过Jenkins将应用发布到K8s1.24.3
一、准备基础环境 cat >> /etc/hosts <<EOF 192.168.180.210 k8s-master 192.168.180.200 k8s-node1 192.168.180.190 k8s-node2 192.168.180.180 gitlab 192.168.180.170 jenkins 192.168.180.160 harbor EOF 配置主机名 hostnamectl set-hostname k8s-master &am…...

正则表达式入门与实践
文章目录 一、为什么要有正则二、正则表达式基础概念三、Pattern与Matcher类的使用(一)Pattern类的常用方法(二)Matcher类的常用方法四、常用正则规则及其含义(一)规范表示(二)数量表示(三)逻辑运算符五、String对正则表达式的支持六、实践演练(一)匹配给定文本中的…...
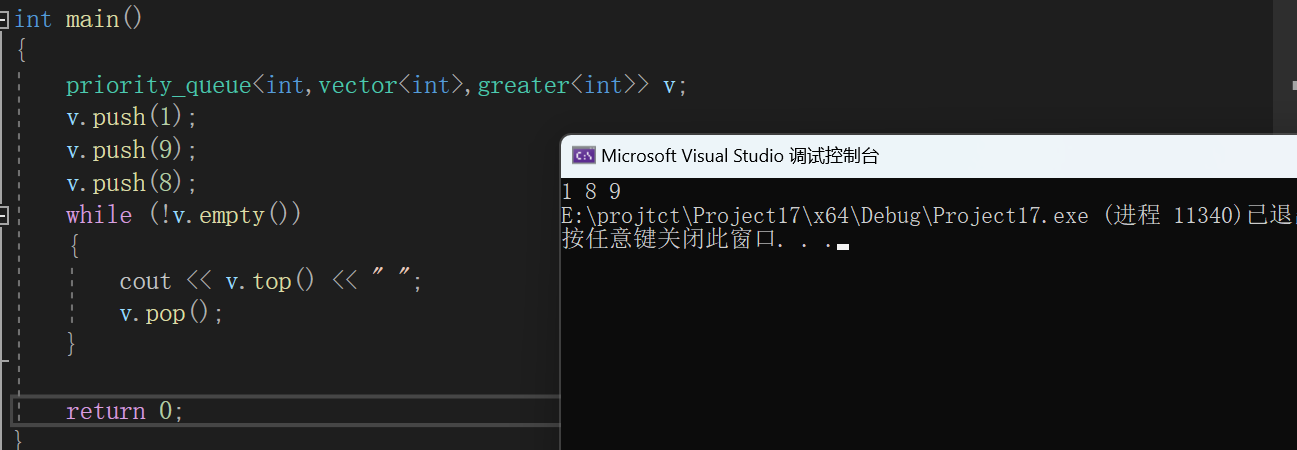
C++初阶(十六)优先级队列
📘北尘_:个人主页 🌎个人专栏:《Linux操作系统》《经典算法试题 》《C》 《数据结构与算法》 ☀️走在路上,不忘来时的初心 文章目录 一、priority_queue的介绍和使用1、priority_queue的介绍2、priority_queue的使用 二、priori…...
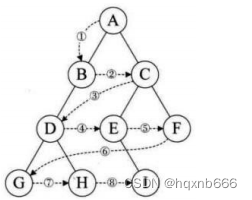
深入探索C语言中的二叉树:数据结构之旅
引言 在计算机科学领域,数据结构是基础中的基础。在众多数据结构中,二叉树因其在各种操作中的高效性而脱颖而出。二叉树是一种特殊的树形结构,每个节点最多有两个子节点:左子节点和右子节点。这种结构使得搜索、插入、删除等操作…...

如何发现服务器被入侵了,服务器被入侵了该如何处理?
作为现代社会的重要基础设施之一,服务器的安全性备受关注。服务器被侵入可能导致严重的数据泄露、系统瘫痪等问题,因此及时排查服务器是否被侵入,成为了保障信息安全的重要环节。小德将给大家介绍服务器是否被侵入的排查方案,并采…...
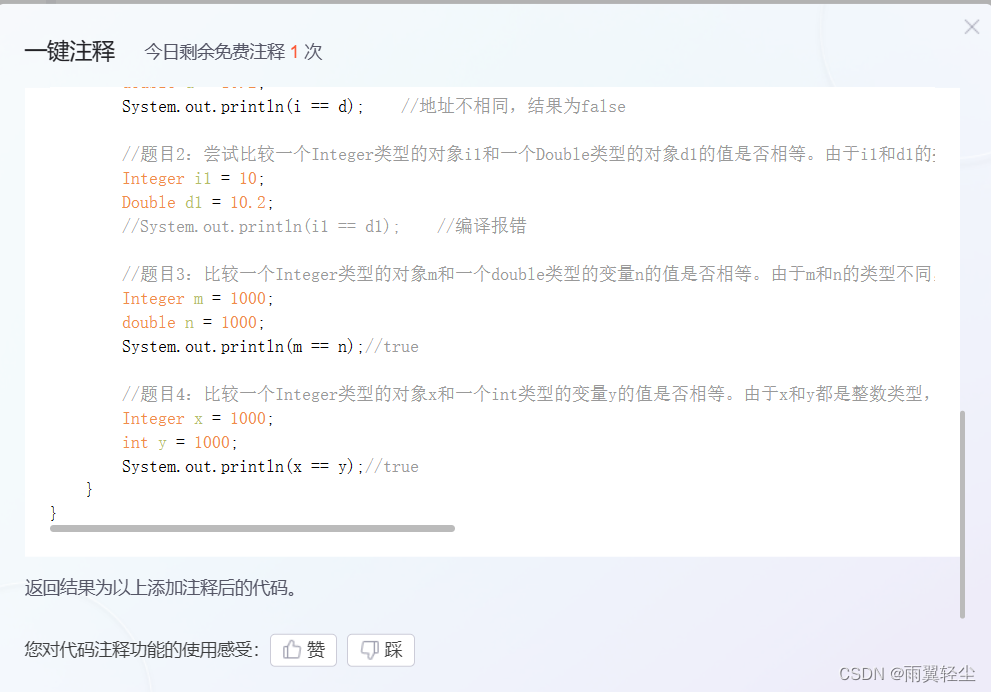
CSDN一键注释功能
这是什么牛逼哄哄的功能 看这里: 然后: 再试一个: 输出结果是?package yuyi03.interview;/*** ClassName: InterviewTest2* Package: yuyi03.interview* Description:** Author 雨翼轻尘* Create 2023/12/14 0014 0:08*/ publ…...

Purpur性能调优实战指南:7大核心优化方案深度解析
Purpur性能调优实战指南:7大核心优化方案深度解析 【免费下载链接】Purpur Purpur is a drop-in replacement for Paper servers designed for configurability, and new fun and exciting gameplay features. 项目地址: https://gitcode.com/gh_mirrors/pu/Purpu…...

5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库
5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 凌晨两点,小林还在为明…...

DriveBench:面向真实驾驶场景的长序列多智能体交互基准测试框架
1. 项目概述:从“世界基准”到“驾驶基准”的演进如果你在自动驾驶或者计算机视觉领域摸爬滚打过几年,一定对“基准测试”(Benchmark)这个词又爱又恨。爱的是,它提供了一个相对公平的擂台,让不同算法、不同…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

基于LLM的游戏AI智能体:从感知到决策的框架构建与实践
1. 项目概述:一个能“玩”游戏的AI智能体最近在GitHub上看到一个挺有意思的项目,叫ChattyPlay-Agent。光看名字,你可能会觉得这又是一个基于大语言模型的聊天机器人。但点进去仔细研究后,我发现它的定位非常独特:这是一…...

基于Stable Diffusion与LoRA技术打造个人AI头像:从原理到实战
1. 项目概述:当AI开始“自拍”——SelfyAI的定位与核心价值最近在AI图像生成领域,一个名为SelfyAI的项目引起了我的注意。它不是一个简单的文生图工具,而是瞄准了一个非常具体且高频的需求:生成高质量、风格一致的个人AI头像。简单…...

基于LLM与视觉模型融合的智能体框架:从原理到工业质检实践
1. 项目概述:当AI学会“看”与“想”最近在探索AI与视觉结合的落地场景时,我深度体验了landing-ai/vision-agent这个项目。它不是一个简单的图像识别工具,而是一个试图让AI具备“视觉推理”能力的智能体框架。简单来说,它让AI不仅…...

终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效
终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经因为ThinkPad风扇的"直升机起…...

大语言模型与多模态生成融合:架构、工具与实践指南
1. 项目概述:当大语言模型遇见多模态生成最近两年,AI领域最激动人心的进展,莫过于大语言模型(LLMs)和多模态生成模型的“双向奔赴”。前者以ChatGPT、GPT-4为代表,展现了惊人的语言理解、推理和生成能力&am…...

VS Code Live Server完全指南:告别手动刷新,拥抱实时开发新时代
VS Code Live Server完全指南:告别手动刷新,拥抱实时开发新时代 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vs…...