【强化学习-读书笔记】表格型问题的 Model-Free 方法
参考
Reinforcement Learning, Second Edition
An Introduction
By Richard S. Sutton and Andrew G. Barto
无模型方法
在前面的文章中,我们介绍的是有模型方法(Model-Based)。在强化学习中,"Model"可以理解为算法对环境的一种建模与抽象。这个模型用于捕捉智能体与环境之间的交互关系。建模的目的是为了帮助智能体更好地理解环境的动态特性,从而能够更有效地制定策略。在 Model-Based 方法中,智能体使用这个模型来规划未来的行动,而在 无模型方法(Model-Free) 方法中,智能体直接通过与环境的交互来学习策略,而不依赖于显式的环境模型。
无模型方法仅仅需要从环境中收集到 S , A , R , . . . S,A,R,... S,A,R,... 序列,作为算法的经验,持续更新。
根据每一次采样序列的长短,无模型方法分为 MC 和 TD 两大类。
MC 蒙特卡洛方法
从一个状态 s s s出发,重复采样多条轨迹,每一条状态都采样直到终止状态,把轨迹的平均折扣回报作为状态价值的估计
V π ( s ) = E [ G t ∣ s ] ≈ 1 N ∑ i = 1 N G t i V_\pi (s)=\mathbb{E}[G_t|s]\approx \frac{1}{N}\sum_{i=1}^N G_{t}^i Vπ(s)=E[Gt∣s]≈N1i=1∑NGti

MC 的增量更新
V π ( s ) ← V π ( s ) + 1 N ( G t − V π ( s ) ) V_\pi(s) \leftarrow V_\pi(s)+\frac{1}{N}(G_t-V_\pi(s)) Vπ(s)←Vπ(s)+N1(Gt−Vπ(s))
对于非平稳问题,增量更新为(红色:TD target):
V π ( s ) ← V π ( s ) + α ( G t − V π ( s ) ) V_\pi(s) \leftarrow V_\pi(s)+\alpha(\red{G_t}-V_\pi(s)) Vπ(s)←Vπ(s)+α(Gt−Vπ(s))
缺点:
- 只适用于有限幕问题
- 更新慢,需要采样整条序列,然后才进行更新。
TD 时序差分方法
TD 在 MC 上做了修改,不需要采样整条序列,而是只采样一步(贝尔曼方程),用 V V V 对后面所有的奖励进行估计(自举法) ,然后立刻进行更新(红色:TD target):
V π ( s ) ← V π ( s ) + α ( R t + 1 + γ V π ( S t + 1 ) − V π ( s ) ) V_\pi(s) \leftarrow V_\pi(s)+\alpha(\red{R_{t+1}+\gamma V_\pi(S_{t+1})} -V_\pi(s)) Vπ(s)←Vπ(s)+α(Rt+1+γVπ(St+1)−Vπ(s))
一般来说,TD方法比MC方法收敛更快。
MC vs TD
- TD 可以在线学习,效率高一些,采样和学习可以同时进行,而MC不行,要一直模拟到游戏结束
- TD 方差大,因为没训练好的时候 V V V本身就估计不准,所以 V t + 1 V_{t+1} Vt+1引入了额外的误差
强化学习中的重要性加权
例子引入:现在给定的轨迹是另一个策略 μ \mu μ (顶级选手的下法 μ ( a ∣ s ) \mu(a|s) μ(a∣s))采样出来的,如果用 μ \mu μ 的轨迹计算得到的 G t G_t Gt (经验)直接用来进行另一个策略 π \pi π (入门选手 π ( a ∣ s ) \pi(a|s) π(a∣s))的学习,那么就可能不合适。
从算法的角度说,在于 TD target G t G_{t} Gt 对于 μ \mu μ 的评价是不准确的,我们需要对 G t G_t Gt进行修正。
改进的方法是使用重要性加权。
- MC 的重要性加权
朴素的想法:对于那些 π \pi π 也能做出类似的 ( a ∣ s ) (a|s) (a∣s) 动作,给予这些动作对应的轨迹的回报 G t G_t Gt 更大的权重,反之给予小的权重。
于是 MC 的重要性加权如下:
G t π / μ = π ( a t ∣ s t ) μ ( a t ∣ s t ) π ( a t + 1 ∣ s t + 1 ) μ ( a t + 1 ∣ s t + 1 ) . . . π ( a T ∣ s T ) μ ( a T ∣ s T ) G t G_{t}^{\pi/\mu}=\frac{\pi(a_t|s_t)}{\mu(a_t|s_t)}\frac{\pi(a_{t+1}|s_{t+1})}{\mu(a_{t+1}|s_{t+1})}...\frac{\pi(a_{T}|s_{T})}{\mu(a_{T}|s_{T})}G_t Gtπ/μ=μ(at∣st)π(at∣st)μ(at+1∣st+1)π(at+1∣st+1)...μ(aT∣sT)π(aT∣sT)Gt
用加权之后的总折扣 G t π / μ G_{t}^{\pi/\mu} Gtπ/μ更新值函数
V π ( s ) ← V π ( s ) + α ( G t π / μ − V π ( s ) ) V_\pi(s) \leftarrow V_\pi(s)+\alpha(G_{t}^{\pi/\mu}-V_\pi(s)) Vπ(s)←Vπ(s)+α(Gtπ/μ−Vπ(s))
问题在于:
- 无法在 μ \mu μ 为0时使用
- 由于连续多个商相乘,显著增大方差。
改进:- TD 的重要性加权
TD 由于只用一步进行更新,所以相应的重要性采样只有一个商,可以降低方差。
V π ( s ) ← V π ( s ) + α ( π ( a t ∣ s t ) μ ( a t ∣ s t ) ( r t + 1 + γ V ( S t + 1 ) ) − V π ( s ) ) V_\pi(s) \leftarrow V_\pi(s)+\alpha \left(\blue{\frac{\pi(a_t|s_t)}{\mu(a_t|s_t)}}\red{(r_{t+1}+\gamma V(S_{t+1}))}-V_\pi(s) \right) Vπ(s)←Vπ(s)+α(μ(at∣st)π(at∣st)(rt+1+γV(St+1))−Vπ(s))

TD 方法: SARSA
两个步骤:
- ϵ \epsilon ϵ-贪心(或者 Decaying ϵ − \epsilon- ϵ−贪心,更加有效)地选择 A A A,从而得到 S , A , R ′ , S ′ , A ′ S ,A ,R' ,S', A' S,A,R′,S′,A′五元组,
- 利用五元组更新价值函数,TD target = R + γ Q ( S ′ , A ′ ) =R+\gamma Q(S',A') =R+γQ(S′,A′)
Q ( S , A ) ← Q ( S , A ) + α [ R + γ Q ( S ′ , A ′ ) − Q ( S , A ) ] Q(S,A)\leftarrow Q(S,A) + \alpha [\red{R+ \gamma Q(S',A')} - Q(S,A)] Q(S,A)←Q(S,A)+α[R+γQ(S′,A′)−Q(S,A)]
SARSA 是一种 On-policy (同轨策略)方法,因为用于计算 TD target 的值函数和用于动作选择的值函数是同一个。
特点:
- 同轨策略
- 运算量小,轻量化,在线
- 偏保守,考虑了 ϵ \epsilon ϵ 的影响(悬崖例子)
TD 方法:Q-learning
和 SARSA 的唯一区别:
将给 TD target 加了一个 max,是用最大估计价值来更新值函数。
Q ( S , A ) ← Q ( S , A ) + α [ R + γ max a Q ( S ′ , a ) − Q ( S , A ) ] Q(S,A)\leftarrow Q(S,A) + \alpha [\red{R+ \gamma \max_a Q(S',a)} - Q(S,A)] Q(S,A)←Q(S,A)+α[R+γamaxQ(S′,a)−Q(S,A)]
- 异轨策略(Off-policy)
- 运算量大,因为要比较每一个 a a a 的价值
- 偏激进,没有考虑 ϵ \epsilon ϵ 的影响(悬崖例子)
- 有过估计的问题,由于 max \max max 操作,会让估计值偏大,导致算法过于自信。
SARSA 改进: 期望 SARSA
由于 SARSA 每一次只用 S ′ , A ′ S',A' S′,A′作为下一个状态的估计,会导致方差较大, 期望 SARSA 引入后继所有状态价值的期望,降低了方差。
Q ( S , A ) ← Q ( S , A ) + α [ R + γ ∑ a π ( a ∣ S ′ ) Q ( S ′ , a ) − Q ( S , A ) ] Q(S,A)\leftarrow Q(S,A) + \alpha [\red{R+ \gamma \sum_{a} \pi(a|S')Q(S',a)} - Q(S,A)] Q(S,A)←Q(S,A)+α[R+γa∑π(a∣S′)Q(S′,a)−Q(S,A)]
期望 SARSA 既可以看作 SARSA 的期望版本,也可以看作将 Q-learning 的 max 改为 mean 的版本。
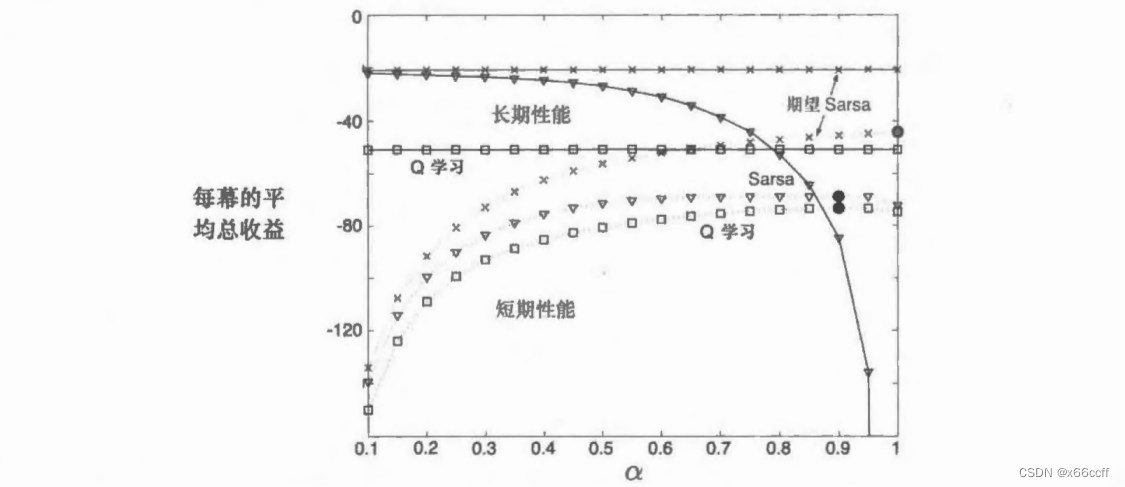
期望 Sarsa 在计算上比 Sarsa 更加复杂。但作为回报,它消除了因为随机选择产生的方差。 在相同数量的经验下,我们可能会预想它的表现能略好于 Sarsa, 期望 Sarsa也确实表现更好。
除了增加少许的计算量之。期望 Sarsa 应该完全优于这两种更知名的时序差分控制算法
最大化偏差与双学习
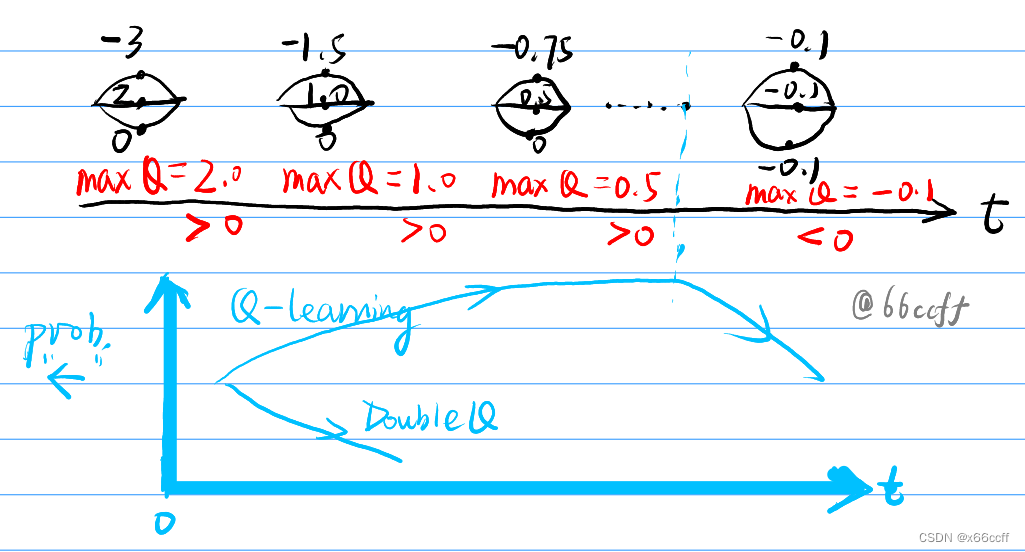
Q-learning 存在最大化偏差的问题,max 的操作会让算法过高估计值函数。
书中的例子:
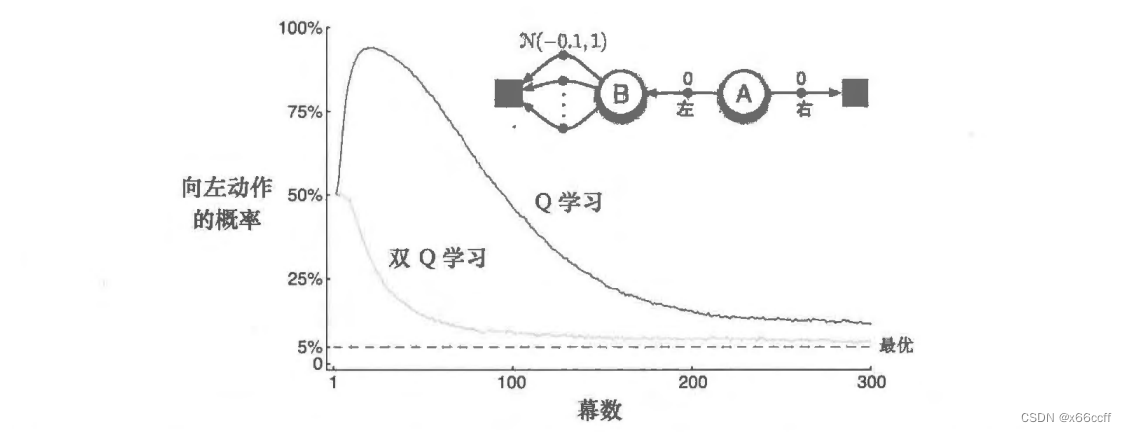
走左边在期望意义上是更差的,但是由于左边的奖励是由 N ( − 0.1 , 1 ) \mathcal{N}(-0.1,1) N(−0.1,1) 产生的,在刚开始的时候算法的 Q ( s , a ) Q(s,a) Q(s,a) 大概率有正数,因此 max 之后会得到一个正数,这会驱使算法在刚开始的时候往左边走。当估计次数增多之后,左边各个状态都收敛到 -0.1 的均值奖励,从而 max Q 必然小于0,算法开始回头,往期望恒为 0 的右边走。
双 Q 学习
这里实际上是非深度版本的Double Q-learning,因为没有buffer,所以是 Q 1 , Q 2 Q_1,Q_2 Q1,Q2完全对等的地位,用交替更新的方法打破对称性。在实际选择动作的时候用 Q 1 + Q 2 Q_1+Q_2 Q1+Q2

在交替更新的时候,都用需要更新的那个 Q Q Q 进行动作选择,然后另一个 Q ′ Q' Q′ 进行动作估计
(类似于 Deep Double Q-learning ,快 Q θ Q_{\theta} Qθ 用来选动作,慢 Q θ − Q_{\theta -} Qθ− 用来进行价值估计)
相关文章:
【强化学习-读书笔记】表格型问题的 Model-Free 方法
参考 Reinforcement Learning, Second Edition An Introduction By Richard S. Sutton and Andrew G. Barto无模型方法 在前面的文章中,我们介绍的是有模型方法(Model-Based)。在强化学习中,"Model"可以理解为算法…...

【手撕算法系列】k-means
k-means k-means算法介绍 k-means算法介绍 K-means算法是一种用于聚类的迭代算法,它将数据集划分为K个簇,其中每个数据点属于与其最近的簇的中心。这个算法的目标是最小化簇内的平方和误差(簇内数据点与簇中心的距离的平方和)。 …...

D33|动态规划!启程!
1.动态规划五部曲: 1)确定dp数组(dp table)以及下标的含义 2)确定递推公式 3)dp数组如何初始化 4)确定遍历顺序 5)举例推导dp数组 2.动态规划应该如何debug 找问题的最好方式就是把…...
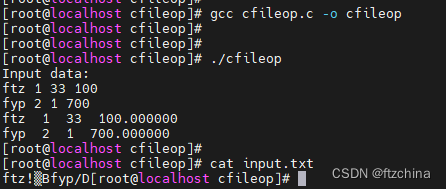
C语言----文件操作(二)
在上一篇文章中我们简单介绍了在C语言中文件是什么以及文件的打开和关闭操作,在实际工作中,我们不仅仅是要打开和关闭文件,二是需要对文件进行增删改写。本文将详细介绍如果对文件进行安全读写。 一,以字符形式读写文件ÿ…...

oracle 10046事件跟踪
10046事件是一个很好的排查sql语句执行缓慢的内部事件,具体设置方式如下: 根据10046事件跟踪SQL语句 1、 alter session set events 10046 trace name context forever,level 12; 2、执行SQL语句 3、关闭10046事件 alter session set events 10046 trace…...
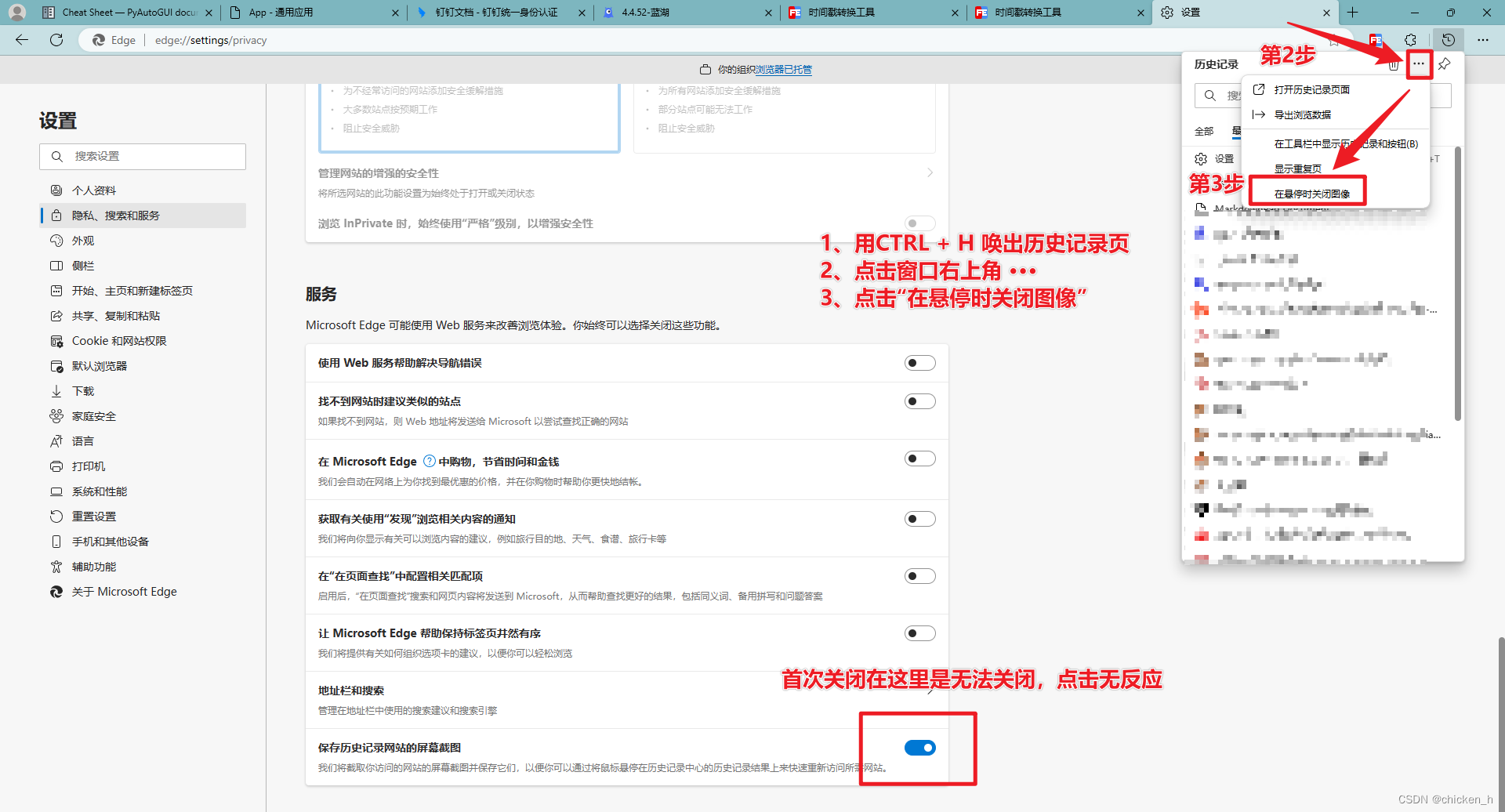
微软自带浏览器Edge,无法关闭“保存历史记录网站的屏幕截图”解决方案
微软自带浏览器Edge,无法关闭“保存历史记录网站的屏幕截图”解决方案 吐槽1:Windows自带的Chrome内核版本的浏览器Microsofg Edge刚发布时可谓一股清流,启动速度快,占用内存较小,相信很多人也开始抛弃正代Chrome&…...

讲座 | 颠覆传统摄像方式乃至计算机视觉的“脉冲视觉”
传统相机拍摄视频时其实是以一定帧率进行采样,视频其实还是一串图片的集合,因此低帧率时会觉得视频卡,拍摄高速运动物体时会有运动模糊等等问题。然而你能想象这一切都可以被“脉冲视觉”这一前沿技术改变吗? 今天下午听了北京大学…...
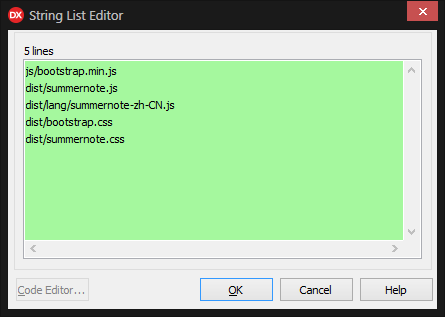
uniGUI学习之UniHTMLMemo1富文本编辑器
1]系统自带的富文本编辑器 2]jQueryBootstarp富文本编辑器插件summernote.js 1]系统自带的富文本编辑器 1、末尾增加<p> 2、增加字体 3、解决滚屏问题 4、输入长度限制问题 5、显示 并 编辑 HTML源代码(主要是图片处理) 1、末尾增加<p> UniHTMLMemo1.Lines…...
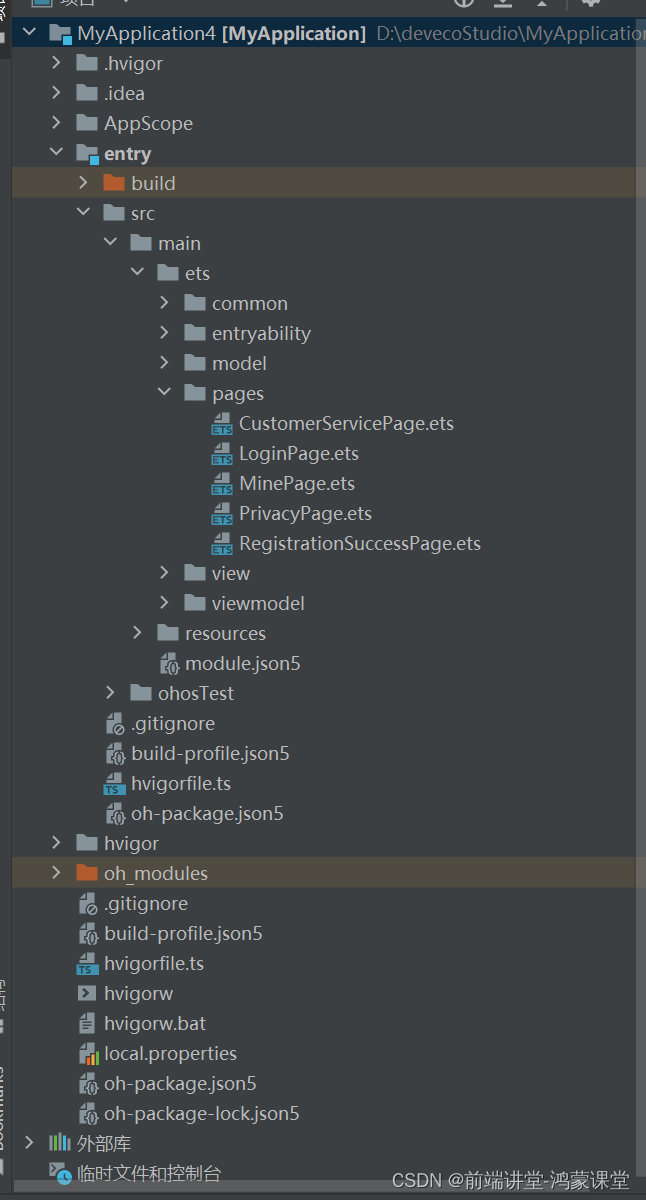
详细教程 - 从零开发 鸿蒙harmonyOS应用 第四节 (鸿蒙Stage模型 登录页面 ArkTS版 推荐使用)
在鸿蒙OS中,Ability是应用程序提供的抽象功能,可以理解为一种功能。在应用程序中,一个页面即一种能力,如登录页面,即具有登录功能的能力。以下是对鸿蒙新建项目的登录代码功能的详细解读和工作流程的描述: …...

uniapp怎么实现授权登录
在Uniapp中实现授权登录通常涉及以下几个步骤: 创建登录按钮:在页面中创建一个按钮,用于触发登录操作。 获取用户授权:当用户点击登录按钮时,调用uni.login或uni.getUserInfo等API获取用户授权。 处理授权回调&#…...

从零开始:前端架构师的基础建设和架构设计之路
文章目录 一、引言二、前端架构师的职责三、基础建设四、架构设计思想五、总结《前端架构师:基础建设与架构设计思想》编辑推荐内容简介作者简介目录获取方式 一、引言 在现代软件开发中,前端开发已经成为了一个不可或缺的部分。随着互联网的普及和移动…...
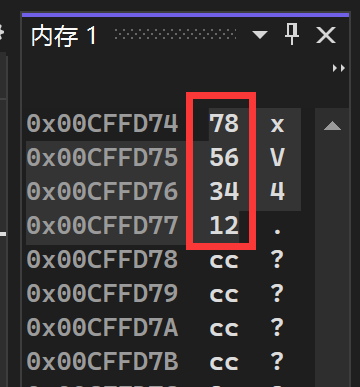
椋鸟C语言笔记#26:数据在内存中的存储(大小端字节序)、浮点数的存储(IEEE754)
萌新的学习笔记,写错了恳请斧正。 目录 大小端字节序 什么是大小端 写一个判断大小端的程序 浮点数在内存中的存储(IEEE 754规则) 引入 存储规则解释 读取规则解释 1.阶码不全为0或全为1(规格化数) 2.阶码全为…...
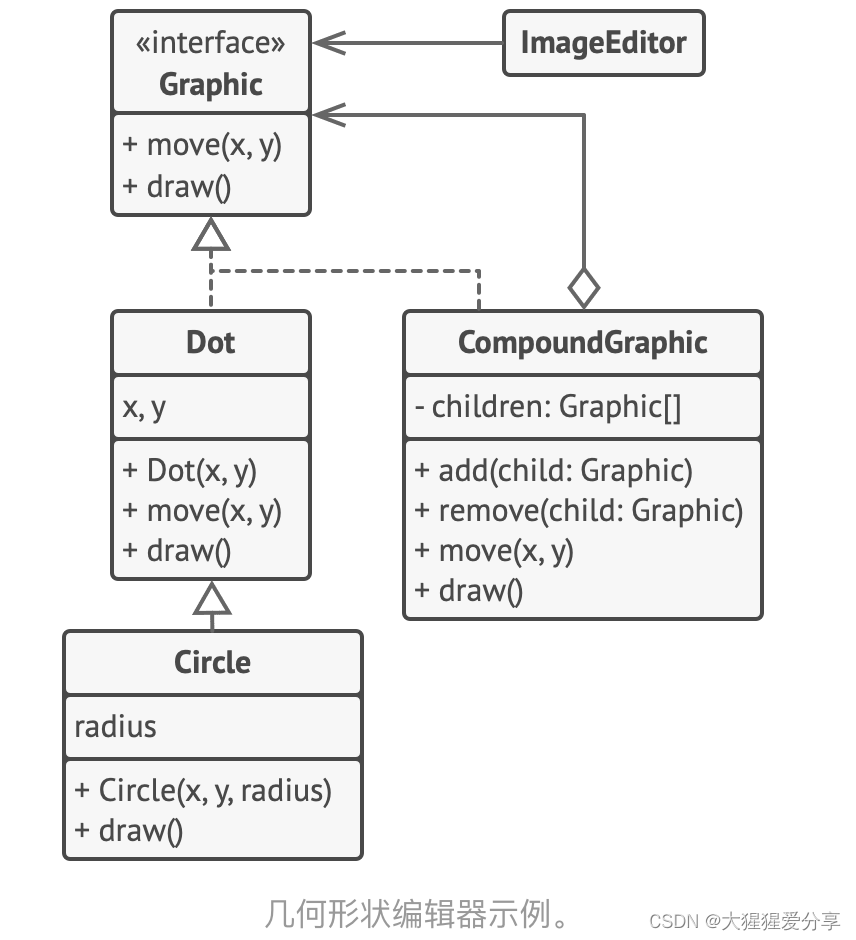
设计模式——组合模式(结构型)
引言 组合模式是一种结构型设计模式, 你可以使用它将对象组合成树状结构, 并且能像使用独立对象一样使用它们。 问题 如果应用的核心模型能用树状结构表示, 在应用中使用组合模式才有价值。 例如, 你有两类对象: …...

鸿蒙小车之多任务调度实验
说到鸿蒙我们都会想到华为mate60:遥遥领先!我们一直领先! 我们这个小车也是采用的是鸿蒙操作系统,学习鸿蒙小车,让你遥遥领先于你的同学。 文章目录 前言一、什么是任务?为什么要有任务二、任务的状态三、任…...
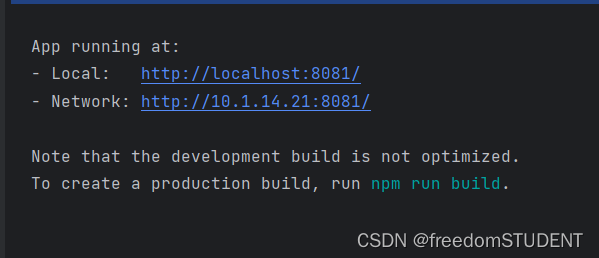
【报错栏】(vue)Module not found: Error: Can‘t resolve ‘element-ui‘ in xxx
Module not found: Error: Cant resolve element-ui in xxx 报错原因是: 未安装 element-ui 依赖 解决: npm install element-ui 运行...
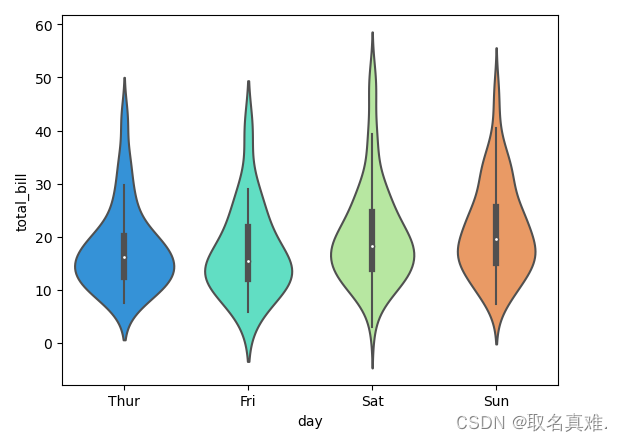
seaborn库图形进行数据分析(基于tips数据集)
Seaborn 是一个基于 matplotlib 的数据可视化库,可以用来绘制各种统计图表,包括散点图、条形图、折线图、箱线图等。Seaborn 提供了一些用于美化图表的默认样式和颜色主题,使得生成的图表更具有吸引力。下面是一些 Seaborn 库的常用功能和用法…...
AC843. n皇后问题--60
我们只需要把蓝色的往上移动就行了 if(!col[i][j]&&!dg[ui]&&!udg[])//1y(i)向下,x(u)向右为正。yxb的by-x一定>0,y-xb的bxy可能>0,这个不考虑,只看-bxy....

Js WebSocket类,收发Json,带心跳,断线重连
如题 心跳:4秒发一次 断线:2秒后自动重连 收发:发送和返回json,处理粘包断包等情况,json字符串最大长度9999 缓存:未连接时,自动缓存100个包,当连接时会自动发出 JS代码 var MyWeb…...

VBA技术资料MF96:单字段多条件高级筛选
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到…...
电子取证中Chrome各版本解密Cookies、LoginData账号密码、历史记录
文章目录 1.前置知识点2.对于80.X以前版本的解密拿masterkey的几种方法方法一 直接在目标机器运行Mimikatz提取方法二 转储lsass.exe 进程从内存提取masterkey方法三 导出SAM注册表 提取user hash 解密masterkey文件(有点麻烦不太推荐)方法四 已知用户密…...

Janus-Pro-7B效果展示:手写体/表格/多语言混合OCR识别准确率实测
Janus-Pro-7B效果展示:手写体/表格/多语言混合OCR识别准确率实测 1. 引言 你有没有遇到过这样的场景?翻出一张老照片,背面是长辈用钢笔写下的寄语,字迹有些潦草,想把它转成电子版保存,却一个字也认不出来…...

别再手动刷新了!SAP ALV中利用change事件与modify_cell实现智能数据同步
SAP ALV开发进阶:巧用change事件与modify_cell构建智能数据联动体系 在SAP前端开发领域,ALV(ABAP List Viewer)作为最常用的数据展示控件,其交互体验直接影响用户操作效率。传统开发模式中,当用户修改某个单…...

ComfyUI-FramePackWrapper功能选择指南:如何根据资源控制与使用便捷性选择最优方案
ComfyUI-FramePackWrapper功能选择指南:如何根据资源控制与使用便捷性选择最优方案 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper ComfyUI-FramePackWrapper作为一款高效的AI视频生成插…...

终极Windows系统清理指南:免费工具让电脑重获新生
终极Windows系统清理指南:免费工具让电脑重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 您的Windows电脑是否变得越来越慢?C盘空…...

Zotero重复条目智能处理指南:从混乱到有序的文献管理解决方案
Zotero重复条目智能处理指南:从混乱到有序的文献管理解决方案 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 学术研究中ÿ…...

霜儿-汉服-造相Z-Turbo模型推理优化:理解与避免神经网络中的耦合过度
霜儿-汉服-造相Z-Turbo模型推理优化:理解与避免神经网络中的耦合过度 不知道你有没有遇到过这种情况:想让AI画一个穿汉服的女孩,结果出来的图,发型和衣服总是一起“跑偏”。比如,你想生成一个“唐代齐胸襦裙”的造型&…...

Kandinsky-5.0-I2V-Lite-5s效果展示:建筑图纸→镜头平移漫游视频生成案例
Kandinsky-5.0-I2V-Lite-5s效果展示:建筑图纸→镜头平移漫游视频生成案例 1. 惊艳效果预览 Kandinsky-5.0-I2V-Lite-5s带来的建筑漫游视频生成效果令人印象深刻。想象一下,你有一张静态的建筑设计图纸,通过这个模型,只需简单描述…...

融合多尺度特征与注意力机制的YOLOv5红外小目标检测优化方案
1. 红外小目标检测的技术挑战 红外遥感图像中的小目标检测一直是计算机视觉领域的难点问题。与可见光图像相比,红外图像具有低对比度、高噪声、目标尺寸小等特点,这使得传统检测算法难以取得理想效果。在实际应用中,军事侦察中的无人机识别、…...

别再让单片机‘死机’!手把手教你用TPV6823设计一个靠谱的硬件看门狗电路
嵌入式系统守护者:TPV6823硬件看门狗电路实战指南 当电机控制板在工厂车间突然停止响应,或是工业传感器在雷雨天气后持续报错,许多工程师的第一反应往往是"程序又跑飞了"。这种嵌入式系统运行失控的现象,就像一台无人看…...

Go Channel 缓冲区机制与性能影响
Go Channel 缓冲区机制与性能影响 在Go语言中,Channel是协程间通信的核心机制,而缓冲区的设置直接影响程序的并发性能和稳定性。理解缓冲区的运作原理及其对性能的影响,对于编写高效、可靠的并发程序至关重要。本文将从缓冲区的底层机制出发…...