六.聚合函数
聚合函数
- 1.什么是聚合函数
- 1.1AVG和SUM函数
- 1.2MIN和MAX函数
- 1.3COUNT函数
- 2.GROUP BY
- 2.1基本使用
- 2.2使用多个列分组
- 2.3GROUP BY中使用WITH ROLLUP
- 3.HAVING
- 3.1基本使用
- 3.2WHERE和HAVING的区别
- 4.SELECT的执行过程
- 4.1查询的结构
- 4.2SELECT执行顺序
- 4.3SQL执行原理
1.什么是聚合函数
- 聚合函数作用于一组数据,并对一组数据返回一个值。

- 聚合函数类型
- AVG()
- SUM()
- MAX()
- MIN()
- COUNT()
- 聚合函数语法

聚合函数不能嵌套调用。比如不能出现类似AVG(SUM(字段名称))形式的调用。
1.1AVG和SUM函数
可以对数值型数据使用AVG和SUM函数
SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';

1.2MIN和MAX函数
可以对任意数据类型的数据使用MIN和MAX函数
SELECT MIN(hire_date), MAX(hire_date)
FROM employees;

1.3COUNT函数
- COUNT(*)返回表中记录总数,适用于任意数据类型
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;
- COUNT(expr)返回expr不为空的记录总数
SELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 50;
问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。问题:能不能使用count(列名)替换count(*)?
不要使用 count(列名)来替代 count() , count() 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2.GROUP BY
2.1基本使用

可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
WHERE一定放在FROM的后面
在SELECT列表中所有未包含在组函数中的列都应该包含在GROUP BY子句中
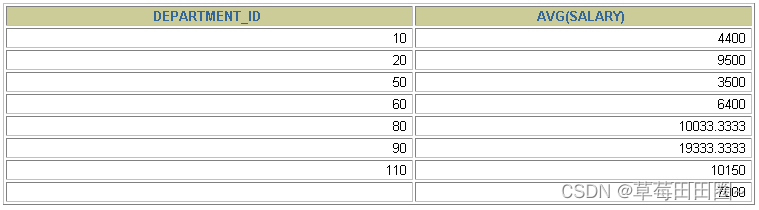
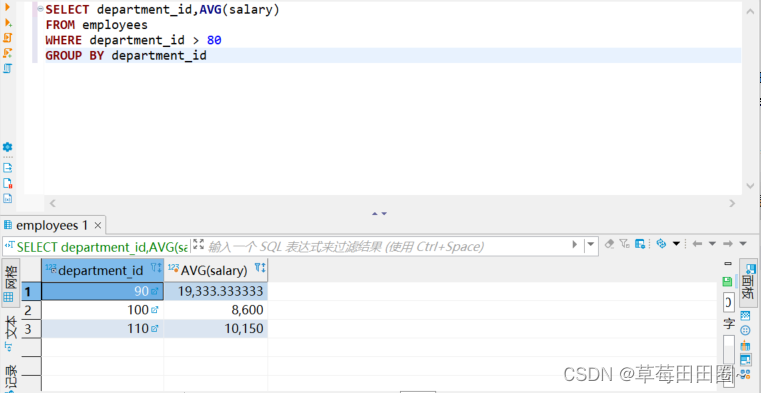
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id ;
包含在GROUP BY子句中的列不必包含在SELECT列表中
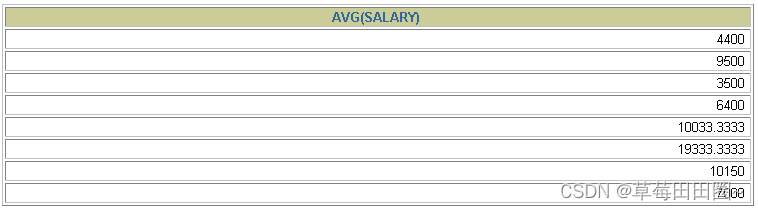
SELECT AVG(salary)
FROM employees
GROUP BY department_id ;
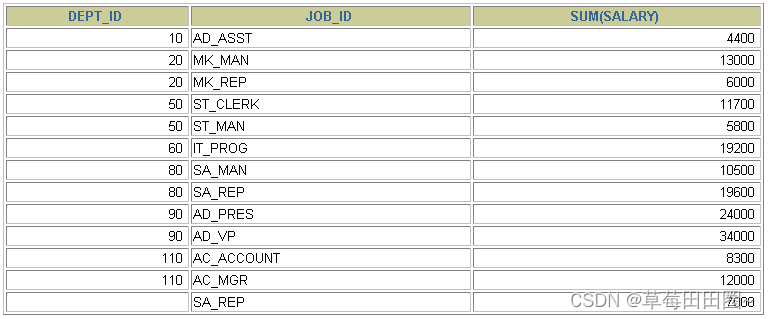
2.2使用多个列分组
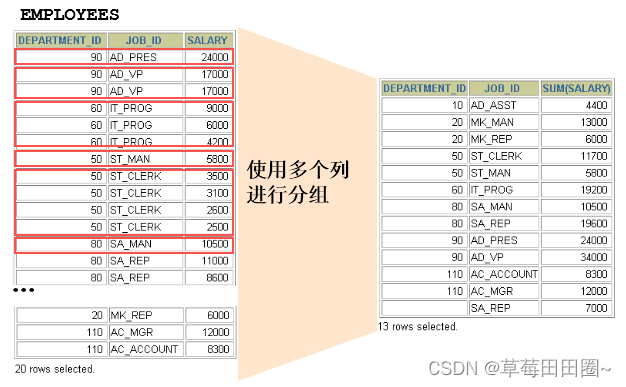
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id ;
2.3GROUP BY中使用WITH ROLLUP
使用WITH GROUP关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的综合,即统计记录数量。
SELECT department_id,AVG(salary)
FROM employees
WHERE department_id > 80
GROUP BY department_id WITH ROLLUP;
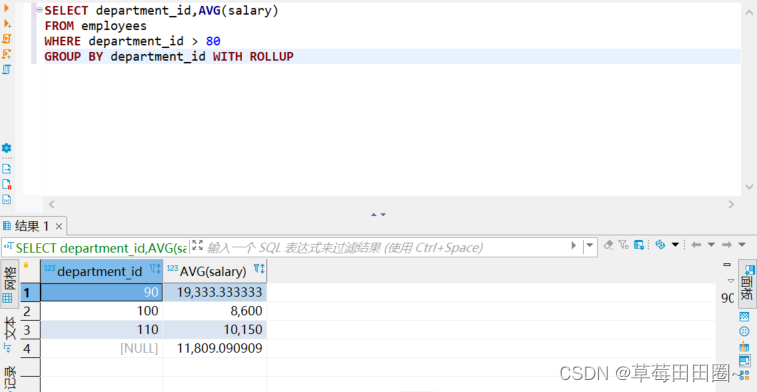
注意:当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是相互排斥的。
3.HAVING
3.1基本使用
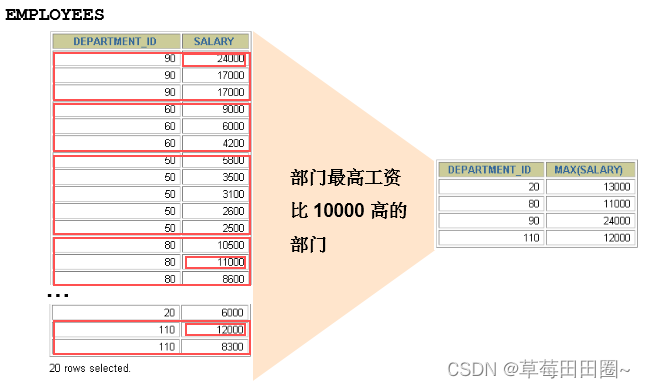
过滤分组:HAVING子句
- 行已经被分组
- 使用了聚合函数
- 满足HAVING子句中条件的分组将被显示
- HAVING不能单独使用,必须要跟GROUP BY一起使用。

SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;

非法使用聚合函数:不能在WHERE子句中使用聚合函数
SELECT department_id, AVG(salary)
FROM employees
WHERE AVG(salary) > 8000
GROUP BY department_id;

3.2WHERE和HAVING的区别
区别1:WHERE可以直接使用表中的字段作为筛选,但不能使用分组中的计算函数作为筛选条件;HAVING必须要与GROUP BY配合使用,可以把分组计算的函数和分组字段作为筛选条件。
这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE是先筛选后连接的,而HAVING是线连接后筛选的。这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
小结如下
| 优点 | 缺点 | |
|---|---|---|
| WHERE | 先筛选数据在关联,执行效率高 | 不能使用分组中的计算函数进行筛选 |
| HAVING | 可以使用分组中的计算函数 | 在最后的结果中进行筛选,执行效率低 |
4.SELECT的执行过程
4.1查询的结构
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页
4.2SELECT执行顺序
你需要记住 SELECT 查询时的两个顺序:
1.关键字的舒徐是不能颠倒的
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
2.SELECT语句执行顺序(MySQL和Oracle中,SELECT执行顺序基本相同):
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT

比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个 虚拟表 ,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
4.3SQL执行原理
SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
- 首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
- 通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
- 添加外部行。如果我们使用的是左连接、右链接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
当我们拿到了查询数据表的原始数据,也就是最终的虚拟表 vt1,就可以在此基础上再进行 WHERE 阶段。在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表 vt2。
然后进入第三步和第四步,也就是 GROUP 和 HAVING阶段。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表 vt3 和 vt4。
当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到 SELECT 和 DISTINCT阶段。
首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表 vt5-1 和 vt5-2。
当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是 ORDER BY 阶段,得到虚拟表 vt6。
最后在 vt6 的基础上,取出指定行的记录,也就是 LIMIT 阶段,得到最终的结果,对应的是虚拟表 vt7。
当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。
练习
- where子句可否使用组函数进行过滤?
- 查询公司员工工资的最大值,最小值,平均值,总和
- 查询各job_id的员工工资的最大值,最小值,平均值,总和
- 选择具有各个job_id的员工人数
- 查询员工最高工资和最低工资的差距(DIFFERENCE)
- 查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
- 查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
- 查询每个工种、每个部门的部门名、工种名和最低工资
1.where子句可否使用组函数进行过滤?
NO
2.查询公司员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary), MIN(salary), AVG(salary), SUM(salary)
FROM employees;
3.查询各job_id的员工工资的最大值,最小值,平均值,总和
SELECT job_id, MAX(salary), MIN(salary), AVG(salary), SUM(salary)
FROM employees
GROUP BY job_id;
4.选择具有各个job_id的员工人数
SELECT job_id, COUNT(*)
FROM employees
GROUP BY job_id;
5.查询员工最高工资和最低工资的差距(DIFFERENCE)
SELECT MAX(salary), MIN(salary), MAX(salary) - MIN(salary) DIFFERENCE
FROM employees;
6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
SELECT manager_id, MIN(salary)
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
HAVING MIN(salary) > 6000;
7.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
SELECT department_name, location_id, COUNT(employee_id), AVG(salary) avg_sal
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
GROUP BY department_name, location_id
ORDER BY avg_sal DESC;
8.查询每个工种、每个部门的部门名、工种名和最低工资
SELECT department_name,job_id,MIN(salary)
FROM departments d LEFT JOIN employees e
ON e.`department_id` = d.`department_id`
GROUP BY department_name,job_id
相关文章:
六.聚合函数
聚合函数 1.什么是聚合函数1.1AVG和SUM函数1.2MIN和MAX函数1.3COUNT函数 2.GROUP BY2.1基本使用2.2使用多个列分组2.3GROUP BY中使用WITH ROLLUP 3.HAVING3.1基本使用3.2WHERE和HAVING的区别 4.SELECT的执行过程4.1查询的结构4.2SELECT执行顺序4.3SQL执行原理 1.什么是聚合函数…...

Eclipse_03_如何加快index速度
1. ini配置文件 -Xms:是最小堆内存大小,也是初始堆内存大小,因为堆内存大小可以根据使用情况进行扩容,所以初始值最小,随着扩容慢慢变大。 -Xmx:是最大堆内存大小,随着堆内存的使用率越来越高&a…...

scrapy的入门和使用
scrapy的入门使用 学习目标: 掌握 scrapy的安装应用 创建scrapy的项目应用 创建scrapy爬虫应用 运行scrapy爬虫应用 scrapy定位以及提取数据或属性值的方法掌握 response响应对象的常用属性 1 安装scrapy 命令: sudo apt-get install scrapy 或者&#x…...

yolov5单目测距+速度测量+目标跟踪(算法介绍和代码)
要在YOLOv5中添加测距和测速功能,您需要了解以下两个部分的原理: 单目测距算法 单目测距是使用单个摄像头来估计场景中物体的距离。常见的单目测距算法包括基于视差的方法(如立体匹配)和基于深度学习的方法(如神经网…...

flink 读取 apache paimon表,查看source的延迟时间 消费堆积情况
paimon source查看消费的数据延迟了多久 如果没有延迟 则显示0 官方文档 Metrics | Apache Paimon...
无人机在融合通信系统中的应用
无人驾驶飞机简称“无人机”,是利用无线电遥控设备和自备的程序控制装置操纵的不载人飞行器,现今无人机在航拍、农业、快递运输、测绘、新闻报道多个领域中都有深度的应用。 在通信行业中,无人机广泛应用于交通,救援,消…...
MySQL库的操作
目录 创建数据库创建数据库案例字符集和校验规则查看系统默认字符集以及校验规则查看数据库支持的字符集查看数据库支持的字符集校验规则校验规则对数据库的影响 操纵数据库查看数据库修改数据库删除数据库数据库备份和恢复表的备份和恢复查看连接情况 创建数据库 创建数据库的…...

服务器解析漏洞有哪些?IIS\APACHE\NGINX解析漏洞利用
解析漏洞是指在Web服务器处理用户请求时,对输入数据(如文件名、参数等)进行解析时产生的漏洞。这种漏洞可能导致服务器对用户提供的数据进行错误解析,使攻击者能够执行未经授权的操作。解析漏洞通常涉及到对用户输入的信任不足&am…...

Https图片链接下载问题
1. 获取方法 入参是一个Url, 和一个随机的名称. 返回值是MultipartFile, 这里因为我这里需要调接口传到服务器, 这里也可以直接通过inputStream进行操作. 按需修改 /*** 通过Url获取文件** param url* param fileName 随机产生一个文件名, 可以是uuid等* return* throws Excep…...

Wireshark在移动网络中的应用
第一章:Wireshark基础及捕获技巧 1.1 Wireshark基础知识回顾 1.2 高级捕获技巧:过滤器和捕获选项 1.3 Wireshark与其他抓包工具的比较 第二章:网络协议分析 2.1 网络协议分析:TCP、UDP、ICMP等 2.2 高级协议分析:HTTP…...
)
Leetcode 1901. 寻找峰值 II(Java + 列最大值 + 二分)
题目 1901. 寻找峰值 II 一个 2D 网格中的 峰值 是指那些 严格大于 其相邻格子(上、下、左、右)的元给你一个 从 0 开始编号 的 m x n 矩阵 mat ,其中任意两个相邻格子的值都 不相同 。找出 任意一个 峰值 mat[i][j] 并 返回其位置 [i,j] 。你可以假设整个矩阵周边…...

RabbitMQ 消息持久化
默认情况下,exchange、queue、message 等数据都是存储在内存中的,这意味着如果 RabbitMQ 重启、关闭、宕机时所有的信息都将丢失。 RabbitMQ 提供了持久化来解决这个问题,持久化后,如果 RabbitMQ 发送 重启、关闭、宕机ÿ…...

Opencv实验合集——实验四:图片融合
1.概念 图像融合是将两个或多个图像结合在一起,创建一个新的图像的过程。这个过程的目标通常是通过合并图像的信息来获得比单个图像更全面、更有信息量的结果。图像融合可以在许多领域中应用,包括计算机视觉、遥感、医学图像处理等。 融合的方法有很多…...

Java复习
CH1 Java Fundamentals 1.1 Java Features(java特色) 1.1 Simplicity: simple grammar, rich library 简单好用: 语法简单,库文件丰富 1.2 Pure OO: everything is object! 所有程序都是对象 1.3 Security: memory access,…...
腾讯云微服务11月产品月报 | TSE 云原生 API 网关支持 WAF 对象接入
2023年 11月动态 TSE 云原生 API 网关 1、支持使用私有 DNS 解析 服务来源支持私有 DNS 解析器,用户可以添加自己的 DNS 解析器地址进行私有域名解析,适用于服务配置了私有域名的用户。 2、支持 WAF 对象接入 云原生 API 网关对接 Web 安全防火墙&…...

性能优化-待处理
1 性能优化-循环展开...

Linux: sysctl: network: ip_no_pmtu_disc,容易搞混的参数名称
这个参数的迷惑性在于双重否定,字面意思是关闭PMTU发现的功能。如果设置为1,代表关闭;如果是0,代表不关闭pmtu发现的功能。所以说明里,有disable/enable,就容易搞混。所以要甄别网上的某些博客的说明,不要被误导。 ip_no_pmtu_disc - INTEGER Disable Path MTU Discover…...

关于“Python”的核心知识点整理大全26
目录 10.3.9 决定报告哪些错误 10.4 存储数据 10.4.1 使用 json.dump()和 json.load() number_writer.py number_reader.py 10.4.2 保存和读取用户生成的数据 对于用户生成的数据,使用json保存它们大有裨益,因为如果不以某种方式进行存储…...

Axure中继器完成表格的增删改查的自定义元件(三列表格与十列表格)
目录 一、中继器 1.1 定义 1.2 特点 1.3 适用场景 二、三列表格增删改查 2.1 实现思路 2.2 效果演示 三、十列表格增删改查 3.1 实现思路 3.2 效果演示 一、中继器 1.1 定义 在Axure中,"中继器"通常指的是界面设计中的一个元素,用…...

刚clone下来的项目如何上传到新的仓库
查看当前项目的git信息 git remote -v 查看git目录上传到哪个路径下 拉下的项目如何上传到新的仓库 git clone xxxcd xxxrm -r .git 删除原有的git信息,有问题一直回车git init 初始化gitgit add . git commit -m ‘xxx’git remote add origin 远程库地址&#…...

意法半导体权力交接:从博佐蒂到谢里的战略延续与挑战
1. 从Bozotti到Chery:一场静水深流的权力交接在半导体这个以技术迭代和资本狂热著称的行业里,权力更迭往往伴随着戏剧性的股价波动、战略急转弯或是人事地震。然而,2018年5月31日,当意法半导体(STMicroelectronics NV&…...

污水处理通气帽标准尺寸参数与国标通气帽定制要点
在好些个工程现场当中,人们往往会忽略掉一个看起来平常但是特别要害的小部件——通气帽。特别是在污水处理的体系当中,它承担平衡内部和外部的气压,阻止异味向外溢出,阻拦异物进入等好几个方面的功能。要是选择类型不适合…...

如何准备打动评审的物联网与硬件创业技术演讲
1. 从听众到讲者:在EE Live分享你的硬件与物联网洞见如果你是一名电子设计工程师、嵌入式开发者,或者正在硬件创业的浪潮中摸索,那么EE Live这个名字对你来说应该不陌生。这个由EE Times主办的年度盛会,前身是DESIGN West…...
函数绘制三维曲面图)
用surf( )函数绘制三维曲面图
在“用plot3( )函数绘制三维曲线图”中,实现了三维曲线的绘制,得到了一个类似面包圈形状的旋转曲面,很喜欢这个造型,就想到是不是可以直接绘制出曲面,而不只是用曲线方式绘制出看起来像曲面的图形。一看参考书…...

第八部分-企业级实践——36. CI/CD 集成
36. CI/CD 集成 1. CI/CD 概述 CI/CD(持续集成/持续部署)与 Docker 结合,可以实现代码提交后自动构建镜像、测试、部署的完整流程,大幅提升开发效率和发布质量。 ┌──────────────────────────────…...

免费Windows桌面分区工具NoFences:3分钟打造高效工作空间
免费Windows桌面分区工具NoFences:3分钟打造高效工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱无章的Windows桌面而烦恼吗?NoFen…...

5分钟快速上手JD-GUI:免费Java反编译工具的完整实战指南
5分钟快速上手JD-GUI:免费Java反编译工具的完整实战指南 【免费下载链接】jd-gui A standalone Java Decompiler GUI 项目地址: https://gitcode.com/gh_mirrors/jd/jd-gui 你是否曾面对一个只有.class文件的Java项目,却急于想了解它的内部实现&a…...

Primr:开源AI研究代理,35分钟自动生成公司深度战略分析报告
1. 项目概述:Primr,一个将公司网站转化为深度战略分析的AI研究代理 如果你做过公司研究、市场分析或者投资尽调,你肯定知道那有多痛苦。打开浏览器,输入公司网址,在“关于我们”、“产品”、“新闻”和“博客”之间来…...

STM32F103C6/RC + HC-SR04超声波测距:Proteus 8.9仿真避坑与LCD1602显示实战
STM32F103C6/RC HC-SR04超声波测距:Proteus 8.9仿真避坑与LCD1602显示实战 在嵌入式开发的学习过程中,仿真工具为我们提供了极大的便利,尤其是对于资源有限或硬件条件不足的开发者来说,Proteus仿真软件无疑是一把利器。然而&…...

auto-rednote:自动化信息整理工具的设计原理与实战应用
1. 项目概述与核心价值 最近在整理个人笔记和知识库时,我遇到了一个几乎所有内容创作者和开发者都会头疼的问题:如何高效地将散落在各处的、格式不一的“红色笔记”(比如微信收藏、网页剪藏、临时备忘录)自动整理成结构化的、可检…...