YOLOv8改进 | 主干篇 | 利用MobileNetV3替换Backbone(轻量化网络结构)
一、本文介绍
本文给大家带来的改进机制是MobileNetV3,其主要改进思想集中在结合硬件感知的网络架构搜索(NAS)和NetAdapt算法,以优化移动设备CPU上的性能。它采用了新颖的架构设计,包括反转残差结构和线性瓶颈层,以及新的高效分割解码器Lite Reduced Atrous Spatial Pyramid Pooling(LR-ASPP),以提升在移动分类、检测和分割任务上的表现。实验表明,MobileNets在资源和准确性的权衡方面表现出色,并在多种应用(如对象检测、细粒度分类、面部属性识别和大规模地理定位)中展现了其有效性。
适用检测目标:这个模型非常适合轻量化的读者来使用,同时伴随着大幅度的涨点。
推荐指数:⭐⭐⭐⭐⭐
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
效果回顾展示->
目录
一、本文介绍
二、MobileNetV3的框架原理
2.1 NAS和NetAdapt算法
2.2 反转残差结构和线性瓶颈层
三、MobileNetV3的核心代码
四、手把手教你添加MobileNetV3网络结构
修改一
修改二
修改三
修改四
修改五
修改六
修改七
修改八
五、MobileNetV3的yaml文件
六、成功运行记录
七、本文总结
二、MobileNetV3的框架原理
 官方论文地址:官方论文地址点击即可跳转
官方论文地址:官方论文地址点击即可跳转
官方代码地址:官方代码地址
MobileNetV3的主要改进思想集中在结合硬件感知的网络架构搜索(NAS)和NetAdapt算法,以优化移动设备CPU上的性能。它采用了新颖的架构设计,包括反转残差结构和线性瓶颈层,以及新的高效分割解码器Lite Reduced Atrous Spatial Pyramid Pooling(LR-ASPP),以提升在移动分类、检测和分割任务上的表现。这些改进通过精心设计的轻量级架构,实现了更高的准确度、更低的延迟,并在不同的资源使用场景中实现了更好的性能。
MobileNetV3的主要创新点包括:
1. 结合了硬件感知的网络架构搜索(NAS)和NetAdapt算法,针对移动设备CPU进行优化。
2. 引入了新颖的架构设计,包括反转残差结构和线性瓶颈层。
3. 提出了高效的Lite Reduced Atrous Spatial Pyramid Pooling(LR-ASPP)作为新的分割解码器。
2.1 NAS和NetAdapt算法
MobileNetV3采用了硬件感知的网络架构搜索(NAS)和NetAdapt算法,这两种技术相互补充,可以结合起来有效地为特定硬件平台找到优化的模型。特别是,它采用了平台感知NAS进行块级搜索,类似于之前的MnasNet-A1方法,使用相同的基于RNN的控制器和相同的分解层次搜索空间,以便为大型移动模型找到全局网络结构,目标是大约80ms的延迟。然后在此基础上应用NetAdapt算法和其他优化措施。这种方法允许在顺序方式中对单个层进行微调,而不是尝试推断粗略但全局的架构。NetAdapt的第二个技术是用于层级搜索,它更适用于小型移动模型,因为对于小型模型来说,准确性随着延迟的变化更加显著,因此需要一个较小的权重因子w = -0.15来补偿不同延迟下的较大准确性变化。通过这个新的权重因子,我们从头开始一个新的架构搜索,以找到初始种子模型,然后应用NetAdapt和其他优化来获得最终的MobileNetV3-Small模型
2.2 反转残差结构和线性瓶颈层
MobileNetV3在架构上进行了一些修改,以降低某些较慢层的延迟,同时保持准确性。这些修改超出了当前搜索空间的范围。第一项修改重新设计了网络的最后几层是如何相互作用以更有效地生成最终特征的。基于MobileNetV2的反转瓶颈结构的当前模型在最终层使用1x1卷积以扩展到更高维的特征空间。这一层对于预测中拥有丰富的特征至关重要。然而,这也增加了额外的延迟。为了减少延迟并保留高维特征,我们将这一层移到最终的平均池化之后

上图展示了MobileNetV2和MobileNetV3的网络结构层。
上侧 (MobileNetV2层):展示了反转残差和线性瓶颈结构。每个块由狭窄的输入和输出层组成,这些层没有非线性操作,后面跟着扩展到更高维空间并投影到输出的操作。残差连接连接了瓶颈层,而不是扩展层。
下侧 (MobileNetV2 + Squeeze-and-Excite): 展示了与Squeeze-and-Excite层一起使用的MobileNetV3。与先前不同,在残差层中应用了挤压和激励操作。
三、MobileNetV3的核心代码
下面的代码是整个MobileNetV1的核心代码,大家如果想学习可以和上面的框架原理对比着看一看估计会有一定的收获,使用方式看章节四。
"""A from-scratch implementation of MobileNetV3 paper ( for educational purposes ).PaperSearching for MobileNetV3 - https://arxiv.org/abs/1905.02244v5author : shubham.aiengineer@gmail.com
"""import torch
from torch import nn
from torchsummary import summaryclass SqueezeExitationBlock(nn.Module):def __init__(self, in_channels: int):"""Constructor for SqueezeExitationBlock.Args:in_channels (int): Number of input channels."""super().__init__()self.pool1 = nn.AdaptiveAvgPool2d(1)self.linear1 = nn.Linear(in_channels, in_channels // 4) # divide by 4 is mentioned in the paper, 5.3. Large squeeze-and-exciteself.act1 = nn.ReLU()self.linear2 = nn.Linear(in_channels // 4, in_channels)self.act2 = nn.Hardsigmoid()def forward(self, x):"""Forward pass for SqueezeExitationBlock."""identity = xx = self.pool1(x)x = torch.flatten(x, 1)x = self.linear1(x)x = self.act1(x)x = self.linear2(x)x = self.act2(x)x = identity * x[:, :, None, None]return xclass ConvNormActivationBlock(nn.Module):def __init__(self,in_channels: int,out_channels: int,kernel_size: list,stride: int = 1,padding: int = 0,groups: int = 1,bias: bool = False,activation: torch.nn = nn.Hardswish,):"""Constructs a block containing a convolution, batch normalization and activation layerArgs:in_channels (int): number of input channelsout_channels (int): number of output channelskernel_size (list): size of the convolutional kernelstride (int, optional): stride of the convolutional kernel. Defaults to 1.padding (int, optional): padding of the convolutional kernel. Defaults to 0.groups (int, optional): number of groups for depthwise seperable convolution. Defaults to 1.bias (bool, optional): whether to use bias. Defaults to False.activation (torch.nn, optional): activation function. Defaults to nn.Hardswish."""super().__init__()self.conv = nn.Conv2d(in_channels,out_channels,kernel_size,stride=stride,padding=padding,groups=groups,bias=bias,)self.norm = nn.BatchNorm2d(out_channels)self.activation = activation()def forward(self, x):"""Perform forward pass."""x = self.conv(x)x = self.norm(x)x = self.activation(x)return xclass InverseResidualBlock(nn.Module):def __init__(self,in_channels: int,out_channels: int,kernel_size: int,expansion_size: int = 6,stride: int = 1,squeeze_exitation: bool = True,activation: nn.Module = nn.Hardswish,):"""Constructs a inverse residual blockArgs:in_channels (int): number of input channelsout_channels (int): number of output channelskernel_size (int): size of the convolutional kernelexpansion_size (int, optional): size of the expansion factor. Defaults to 6.stride (int, optional): stride of the convolutional kernel. Defaults to 1.squeeze_exitation (bool, optional): whether to add squeeze and exitation block or not. Defaults to True.activation (nn.Module, optional): activation function. Defaults to nn.Hardswish."""super().__init__()self.residual = in_channels == out_channels and stride == 1self.squeeze_exitation = squeeze_exitationself.conv1 = (ConvNormActivationBlock(in_channels, expansion_size, (1, 1), activation=activation)if in_channels != expansion_sizeelse nn.Identity()) # If it's not the first layer, then we need to add a 1x1 convolutional layer to expand the number of channelsself.depthwise_conv = ConvNormActivationBlock(expansion_size,expansion_size,(kernel_size, kernel_size),stride=stride,padding=kernel_size // 2,groups=expansion_size,activation=activation,)if self.squeeze_exitation:self.se = SqueezeExitationBlock(expansion_size)self.conv2 = nn.Conv2d(expansion_size, out_channels, (1, 1), bias=False) # bias is false because we are using batch normalization, which already has biasself.norm = nn.BatchNorm2d(out_channels)def forward(self, x):"""Perform forward pass."""identity = xx = self.conv1(x)x = self.depthwise_conv(x)if self.squeeze_exitation:x = self.se(x)x = self.conv2(x)x = self.norm(x)if self.residual:x = x + identityreturn xclass MobileNetV3(nn.Module):def __init__(self,n_classes: int = 1000,input_channel: int = 3,config: str = "large",dropout: float = 0.8,):"""Constructs MobileNetV3 architectureArgs:`n_classes`: An integer count of output neuron in last layer, default 1000`input_channel`: An integer value input channels in first conv layer, default is 3.`config`: A string value indicating the configuration of MobileNetV3, either `large` or `small`, default is `large`.`dropout` [0, 1] : A float parameter for dropout in last layer, between 0 and 1, default is 0.8."""super().__init__()# The configuration of MobileNetv3.# input channels, kernel size, expension size, output channels, squeeze exitation, activation, strideRE = nn.ReLUHS = nn.Hardswishconfigs_dict = {"small": ((16, 3, 16, 16, True, RE, 2),(16, 3, 72, 24, False, RE, 2),(24, 3, 88, 24, False, RE, 1),(24, 5, 96, 40, True, HS, 2),(40, 5, 240, 40, True, HS, 1),(40, 5, 240, 40, True, HS, 1),(40, 5, 120, 48, True, HS, 1),(48, 5, 144, 48, True, HS, 1),(48, 5, 288, 96, True, HS, 2),(96, 5, 576, 96, True, HS, 1),(96, 5, 576, 96, True, HS, 1),),"large": ((16, 3, 16, 16, False, RE, 1),(16, 3, 64, 24, False, RE, 2),(24, 3, 72, 24, False, RE, 1),(24, 5, 72, 40, True, RE, 2),(40, 5, 120, 40, True, RE, 1),(40, 5, 120, 40, True, RE, 1),(40, 3, 240, 80, False, HS, 2),(80, 3, 200, 80, False, HS, 1),(80, 3, 184, 80, False, HS, 1),(80, 3, 184, 80, False, HS, 1),(80, 3, 480, 112, True, HS, 1),(112, 3, 672, 112, True, HS, 1),(112, 5, 672, 160, True, HS, 2),(160, 5, 960, 160, True, HS, 1),(160, 5, 960, 160, True, HS, 1),),}self.model = nn.Sequential(ConvNormActivationBlock(input_channel, 16, (3, 3), stride=2, padding=1, activation=nn.Hardswish),)for (in_channels,kernel_size,expansion_size,out_channels,squeeze_exitation,activation,stride,) in configs_dict[config]:self.model.append(InverseResidualBlock(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,expansion_size=expansion_size,stride=stride,squeeze_exitation=squeeze_exitation,activation=activation,))hidden_channels = 576 if config == "small" else 960_out_channel = 1024 if config == "small" else 1280self.model.append(ConvNormActivationBlock(out_channels,hidden_channels,(1, 1),bias=False,activation=nn.Hardswish,))self.index = [16, 24, 48, 576]self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward(self, x):"""Perform forward pass."""results = [None, None, None, None]for model in self.model:x = model(x)if x.size(1) in self.index:position = self.index.index(x.size(1)) # Find the position in the index listresults[position] = xreturn resultsif __name__ == "__main__":# Generating Sample imageimage_size = (1, 3, 224, 224)image = torch.rand(*image_size)# Modelmobilenet_v3 = MobileNetV3(config="small")# summary(# mobilenet_v3,# input_data=image,# col_names=["input_size", "output_size", "num_params"],# device="cpu",# depth=2,# )out = mobilenet_v3(image)print("Output shape : ", out.shape)四、手把手教你添加MobileNetV3网络结构
这个主干的网络结构添加起来算是所有的改进机制里最麻烦的了,因为有一些网略结构可以用yaml文件搭建出来,有一些网络结构其中的一些细节根本没有办法用yaml文件去搭建,用yaml文件去搭建会损失一些细节部分(而且一个网络结构设计很多细节的结构修改方式都不一样,一个一个去修改大家难免会出错),所以这里让网络直接返回整个网络,然后修改部分 yolo代码以后就都以这种形式添加了,以后我提出的网络模型基本上都会通过这种方式修改,我也会进行一些模型细节改进。创新出新的网络结构大家直接拿来用就可以的。下面开始添加教程->
(同时每一个后面都有代码,大家拿来复制粘贴替换即可,但是要看好了不要复制粘贴替换多了)
修改一
我们复制网络结构代码到“ultralytics/nn/modules”目录下创建一个py文件复制粘贴进去 ,我这里起的名字是MobileNetV3。

修改二
找到如下的文件"ultralytics/nn/tasks.py" 在开始的部分导入我们的模型如下图。
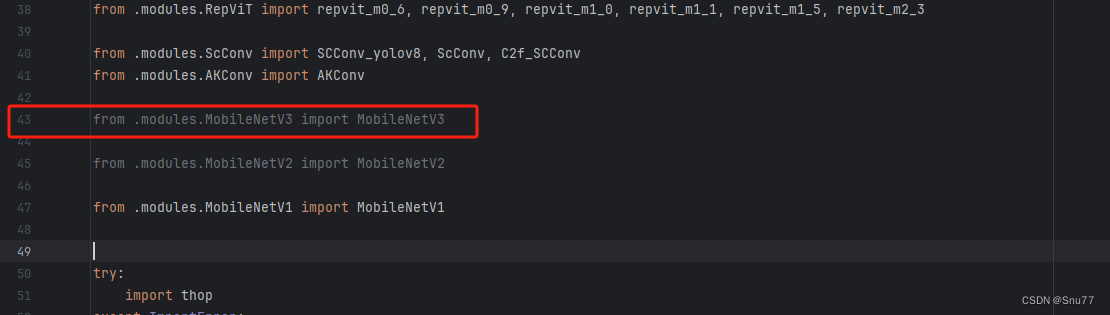
from .modules.MobileNetV1 import MobileNetV3修改三
添加如下两行代码!!!

修改四
找到七百多行大概把具体看图片,按照图片来修改就行,添加红框内的部分,注意没有()只是函数名。

elif m in {自行添加对应的模型即可,下面都是一样的}:m = m()c2 = m.width_list # 返回通道列表backbone = True修改五
下面的两个红框内都是需要改动的。

if isinstance(c2, list):m_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typem.np = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type修改六
如下的也需要修改,全部按照我的来。
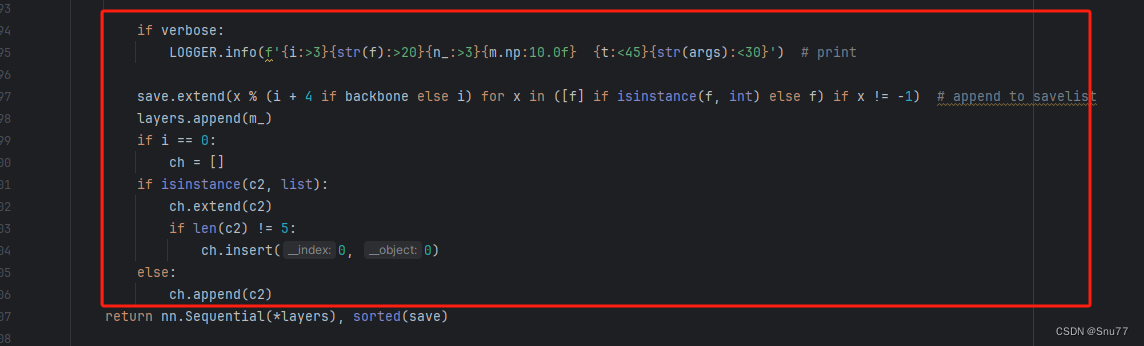
代码如下把原先的代码替换了即可。
if verbose:LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # printsave.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)if len(c2) != 5:ch.insert(0, 0)else:ch.append(c2)修改七
修改七和前面的都不太一样,需要修改前向传播中的一个部分, 已经离开了parse_model方法了。
可以在图片中开代码行数,没有离开task.py文件都是同一个文件。 同时这个部分有好几个前向传播都很相似,大家不要看错了,是70多行左右的!!!,同时我后面提供了代码,大家直接复制粘贴即可,有时间我针对这里会出一个视频。

代码如下->
def _predict_once(self, x, profile=False, visualize=False):"""Perform a forward pass through the network.Args:x (torch.Tensor): The input tensor to the model.profile (bool): Print the computation time of each layer if True, defaults to False.visualize (bool): Save the feature maps of the model if True, defaults to False.Returns:(torch.Tensor): The last output of the model."""y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)if len(x) != 5: # 0 - 5x.insert(0, None)for index, i in enumerate(x):if index in self.save:y.append(i)else:y.append(None)x = x[-1] # 最后一个输出传给下一层else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x到这里就完成了修改部分,但是这里面细节很多,大家千万要注意不要替换多余的代码,导致报错,也不要拉下任何一部,都会导致运行失败,而且报错很难排查!!!很难排查!!!
修改八
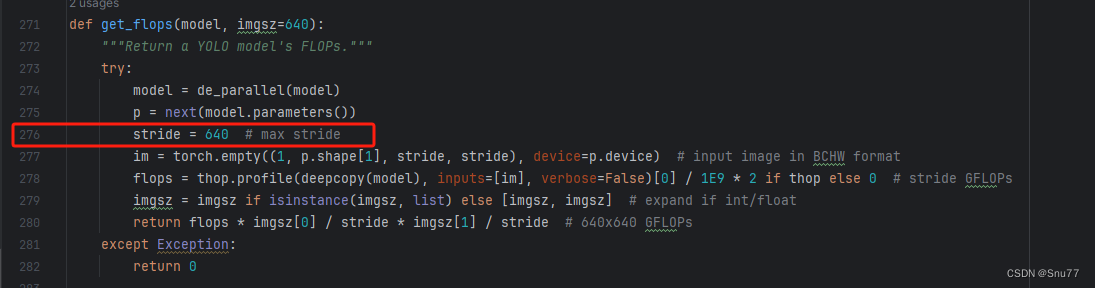
我们找到如下文件'ultralytics/utils/torch_utils.py'按照如下的图片进行修改。
五、MobileNetV3的yaml文件
复制如下yaml文件进行运行!!!
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, MobileNetV3, []] # 4- [-1, 1, SPPF, [1024, 5]] # 5# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4- [-1, 3, C2f, [512]] # 8- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3- [-1, 3, C2f, [256]] # 11 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]] # 12- [[-1, 8], 1, Concat, [1]] # 13 cat head P4- [-1, 3, C2f, [512]] # 14 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]] # 15- [[-1, 5], 1, Concat, [1]] # 16 cat head P5- [-1, 3, C2f, [1024]] # 17 (P5/32-large)- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
六、成功运行记录
下面是成功运行的截图,已经完成了有1个epochs的训练,图片太大截不全第2个epochs了。

七、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备

相关文章:
YOLOv8改进 | 主干篇 | 利用MobileNetV3替换Backbone(轻量化网络结构)
一、本文介绍 本文给大家带来的改进机制是MobileNetV3,其主要改进思想集中在结合硬件感知的网络架构搜索(NAS)和NetAdapt算法,以优化移动设备CPU上的性能。它采用了新颖的架构设计,包括反转残差结构和线性瓶颈层&…...

MATLAB Mobile - 使用预训练网络对手机拍摄的图像进行分类
系列文章目录 前言 此示例说明如何使用深度学习对移动设备摄像头采集的图像进行分类。 在您的移动设备上安装和设置 MATLAB Mobile™。然后,从 MATLAB Mobile 的“设置”登录 MathWorks Cloud。 在您的设备上启动 MATLAB Mobile。 一、在您的设备上安装 MATLAB M…...

LangChain入门指南:定义、功能和工作原理
LangChain入门指南:定义、功能和工作原理 引言LangChain是什么?LangChain的核心功能LangChain的工作原理LangChain实际应用案例如何开始使用LangChain 引言 在人工智能的浪潮中,语言模型已成为推动技术革新的重要力量。从简单的文本生成到复…...
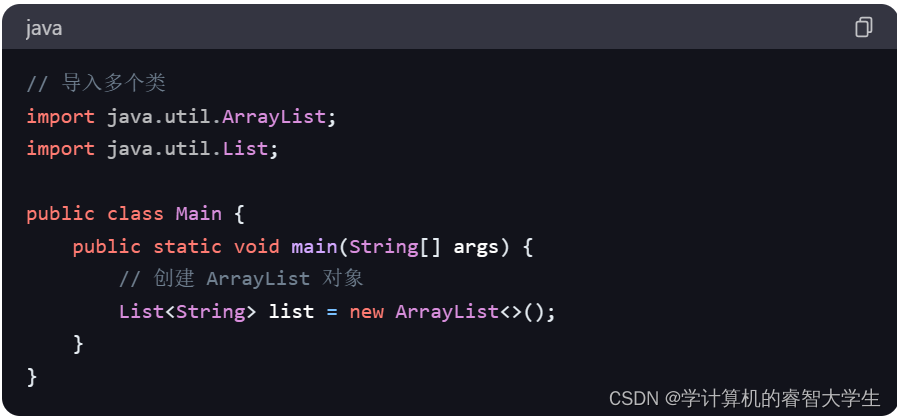
关键字:import关键字
在 Java 中,import关键字用于导入类或接口,使你可以在代码中使用它们而无需完全限定其名称。以下是使用import关键字的示例代码: 在上述示例中,通过使用import关键字导入了java.util.ArrayList类,这样就可以在代码中直…...

【C#】.net core 6.0 通过依赖注入注册和使用上下文服务
给自己一个目标,然后坚持一段时间,总会有收获和感悟! 请求上下文是指在 Web 应用程序中处理请求时,包含有关当前请求的各种信息的对象。这些信息包括请求的头部、身体、查询字符串、路由数据、用户身份验证信息以及其他与请求相关…...
关于redis单线程和IO多路复用的理解
首先,Redis是一个高性能的分布式缓存中间件。其复杂性不言而喻,对于Redis整体而言肯定不是只有一个线程。 我们常说的Redis 是单线程,主要是指 Redis 在网络 IO和键值对读写是采用一个线程来完成的,这也是 Redis 对外提供键值存储…...

第四十一章 XML 映射参数摘要
文章目录 第四十一章 XML 映射参数摘要 第四十一章 XML 映射参数摘要 TopicParameters启用 XML 映射。XMLENABLED 类参数将属性映射到元素或属性。XMLPROJECTION property parameter ("NONE", "ATTRIBUTE", "XMLATTRIBUTE", "CONTENT"…...

redis之五种基本数据类型
一) 字符串(String) 1 使用场景 2 编码 3 编码转换 二) List(列表) 1 使用场景 2 编码 三) Set(无序集合) 1 使用场景 2 编码 3 编码转换 四) ZSet(有序集合) 1 使用场景 2 编码 3 编码转换 五) Hash 1 使用场景 2 编码 3 编码转换 五种基本数据类型 redis…...
RocketMQ系统性学习-RocketMQ高级特性之消息大量堆积处理、部署架构和高可用机制
🌈🌈🌈🌈🌈🌈🌈🌈 【11来了】文章导读地址:点击查看文章导读! 🍁🍁🍁🍁🍁🍁dz…...
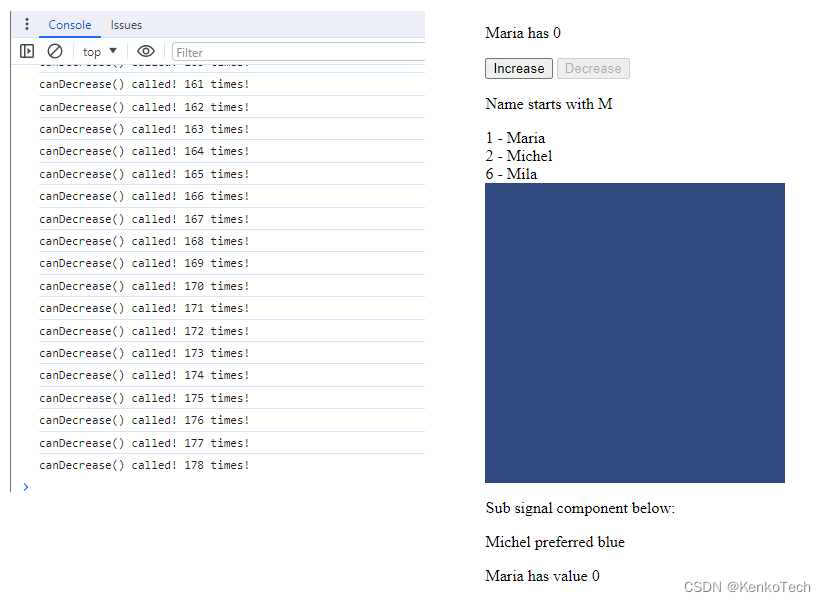
Angular 进阶之五: Signals到底用不用?
Angular 在V16的时候推出了Signals,在17正式作为主打功能之一强烈推荐,看过了各种博主的各种科普文章也没说明白,到底这东西值不值得用?毕竟项目大了,重构代码也不是闹着玩儿的。各种科普文章主要在说两点:…...

构建数字化金融生态系统:云原生的创新方法
内容来自演讲:曾祥龙 | DaoCloud | 解决方案架构师 摘要 本文探讨了金融企业在实施云原生体系时面临的挑战,包括复杂性、安全、数据持久化、服务网格使用和高可用容灾架构等。针对网络管理复杂性,文章提出了Spiderpool开源项目,…...

前端性能优化五:css和js位置
1. 精简HTML代码: ①. css链接文件尽量放在页面头部:a. css的加载不会阻塞DOM Tree的解析.b. 但会阻塞DOM Tree渲染,也会阻塞后面JS的执行.c. 将css放在任何body元素之前:(1). 可以确保在文档中解析了所有css的样式包括内联样式和外联的.(2). 减少了浏览器必须重排文档的次数.…...

苏州耕耘无忧物联网:降本增效,设备维护管理数字化转型的引领者
随着科技的快速发展和工业4.0的推动,设备维护管理已经从传统的被动式、经验式维护,转向了更加积极主动、数据驱动的维护模式。在这个过程中,苏州耕耘无忧物联科技有限公司以其深厚的技术积累和丰富的管理经验,引领着设备维护管理数…...
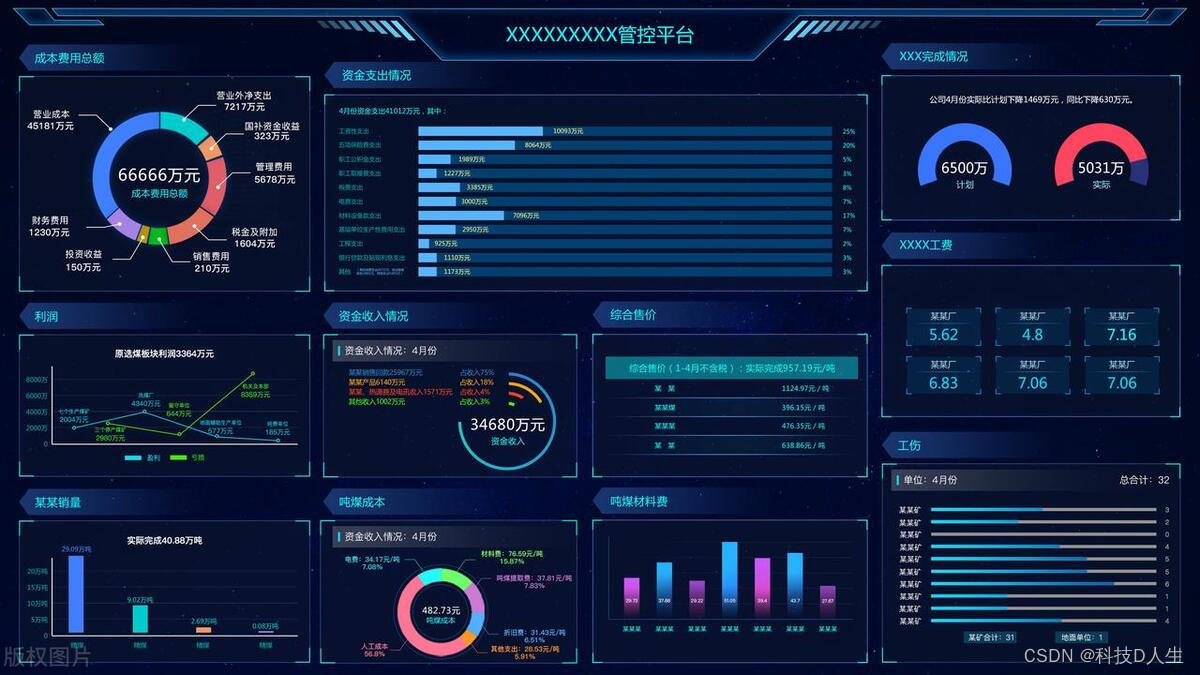
15个热门的开源数据可视化项目
数据可视化(即 BI仪表盘)是图形表示的数据。它涉及产生将表示的数据之间的关系传达给图像查看者的图像。这种通信是通过在可视化过程中使用图形标记和数据值之间的系统映射来实现的。该映射建立了如何在视觉上表示数据值,确定图形标记的属性(例如大小或颜色)如何以及在多大程…...

【第七在线】数据分析与人工智能在商品计划中的应用
随着技术的不断进步,数据分析和人工智能(AI)已经成为了现代商品计划的关键组成部分。在服装行业,这两项技术正在帮助企业更好地理解市场需求、优化库存管理、提高生产效率和提供更好的客户体验。本文将深入探讨数据分析和人工智能…...

【圣诞】极安云科赠书活动第①期:CTF实战:从入门到提升
【圣诞】极安云科赠书活动第①期:CTF实战:从入门到提升 9787111724834 9787121376955 9787302556275 ISBN编号:9787111724834 书名:CTF实战:从入门到提升 定:99.00元 开本:184mm260ÿ…...
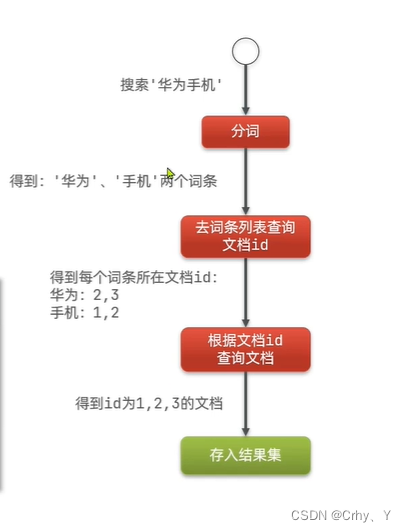
分布式搜索elasticsearch概念
什么是elasticsearch? elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容 目录 elasticsearch的场景 elasticsearch的发展 Lucene篇 Elasticsearch篇 elasticsearch的安装 elasticsearch的场景 elasticsear…...

Linux环境安装Hadoop
(1)下载Hadoop安装包并上传 下载Hadoop安装包到本地,并导入到Linux服务器的/opt/software路径下 (2)解压安装包 解压安装文件并放到/opt/module下面 [roothadoop100 ~]$ cd /opt/software [roothadoop100 software…...
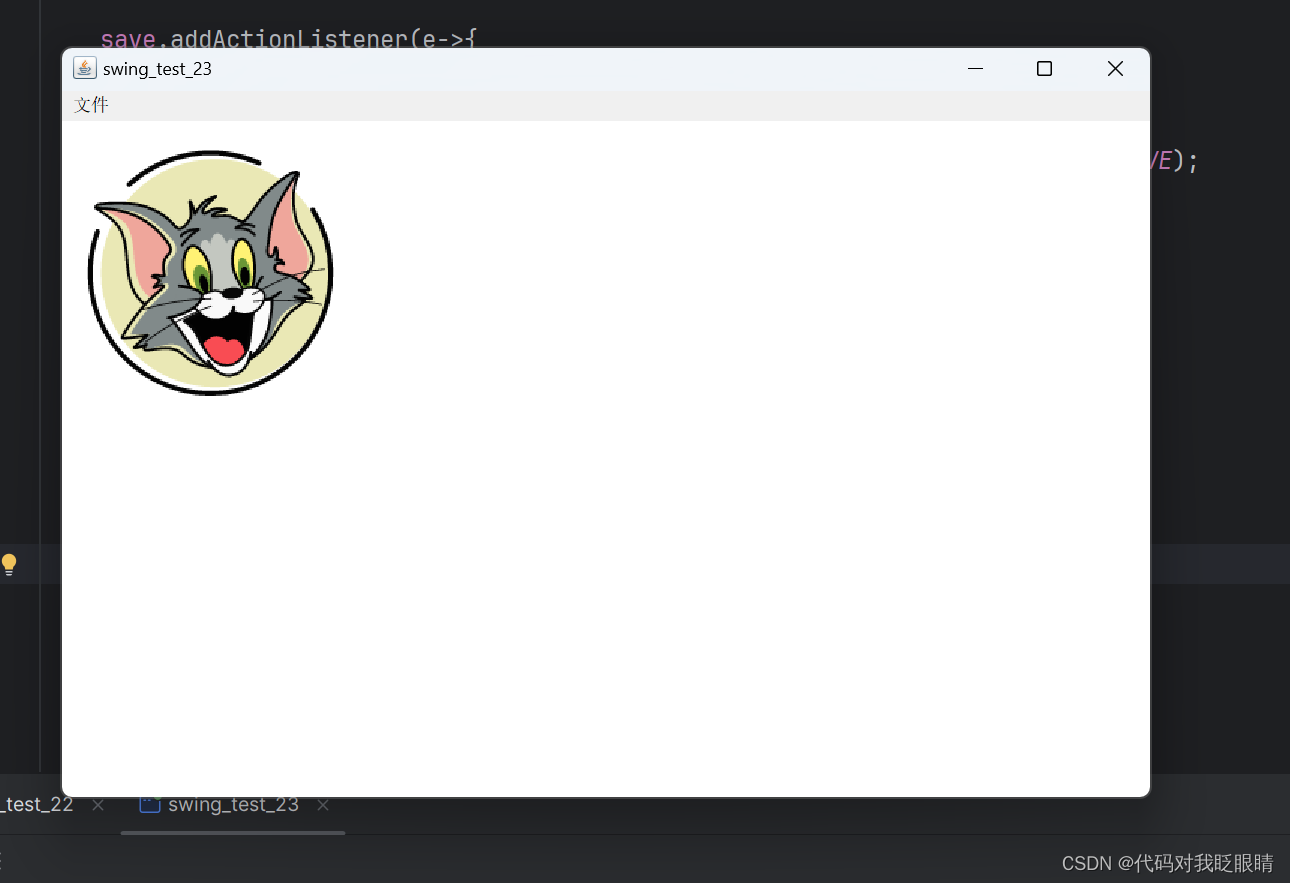
swing快速入门(二十五)
注释很详细,直接上代码 新增内容 1.ImageIO.write读取并显示图片 2.ImageIO.writeImageIO.write读取并保存图片 package swing21_30;import javax.imageio.ImageIO; import java.awt.*; import java.awt.event.WindowAdapter; import java.awt.event.WindowEvent…...

智能优化算法应用:基于卷尾猴算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于卷尾猴算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于卷尾猴算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.卷尾猴算法4.实验参数设定5.算法结果6.参考文…...

Cadence Allegro自定义快捷键全攻略:从env文件到Skill脚本
1. 项目概述:为什么我们需要自定义快捷键?如果你是一名电子工程师,或者经常使用Cadence Allegro进行PCB设计,那么对软件自带的默认快捷键一定又爱又恨。爱的是,它确实提供了一些基础的操作加速;恨的是&…...

5分钟快速上手:LuckyLilliaBot QQ机器人完整部署指南
5分钟快速上手:LuckyLilliaBot QQ机器人完整部署指南 【免费下载链接】LuckyLilliaBot 支持 OneBot 11、Satori 和 Milky 协议 项目地址: https://gitcode.com/gh_mirrors/li/LuckyLilliaBot 你是否正在寻找一款简单易用、功能强大的QQ机器人框架?…...

memtest_vulkan:专业级Vulkan GPU显存稳定性测试工具全解析
memtest_vulkan:专业级Vulkan GPU显存稳定性测试工具全解析 【免费下载链接】memtest_vulkan Vulkan compute tool for testing video memory stability 项目地址: https://gitcode.com/gh_mirrors/me/memtest_vulkan 在GPU计算和图形处理日益重要的今天&…...

3大核心优势:为什么GanttProject能让你秒懂项目管理
3大核心优势:为什么GanttProject能让你秒懂项目管理 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 你是否曾经面对复杂的项目计划感到无从下手?GanttProject这款免…...
)
DeepSeek GAOKAO测试结果深度复盘(附17套真题响应日志与错误归因图谱)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek GAOKAO测试结果深度复盘(附17套真题响应日志与错误归因图谱) 在2024年高考真题压力测试中,DeepSeek-V2模型在覆盖全国卷Ⅰ、Ⅱ、Ⅲ及北京、上海、浙江等17套…...

【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告
更多请点击: https://intelliparadigm.com 第一章:【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告 现象复现与基准测试协议 我们在标准LIGO-PRL语料集(v2.3)上对NotebookLM…...

Vivado功耗分析保姆级教程:从综合后DCP到布局布线后的精确估算
Vivado功耗分析深度实战:从DCP文件到精准优化策略 在FPGA设计流程中,功耗分析往往被工程师视为"最后一公里"的验证环节,但实际上它应该贯穿整个设计周期。Xilinx Vivado提供的功耗分析工具链,能够帮助我们从早期综合阶段…...

GraphGym高级特性:动态图学习与多任务图神经网络
GraphGym高级特性:动态图学习与多任务图神经网络 【免费下载链接】GraphGym Platform for designing and evaluating Graph Neural Networks (GNN) 项目地址: https://gitcode.com/gh_mirrors/gr/GraphGym GraphGym是一个强大的图神经网络(GNN&am…...

bsnes性能优化技巧:CPU、SA1和SuperFX超频配置完全手册
bsnes性能优化技巧:CPU、SA1和SuperFX超频配置完全手册 【免费下载链接】bsnes bsnes is a Super Nintendo (SNES) emulator focused on performance, features, and ease of use. 项目地址: https://gitcode.com/gh_mirrors/bs/bsnes bsnes是一款专注于性能…...

Prisma Relay游标分页库实战:解决GraphQL分页难题
1. 项目概述:一个解决分页痛点的利器如果你在构建一个使用 Prisma 和 GraphQL 的后端应用,并且正在为如何实现高效、标准化的 Relay 风格分页而头疼,那么devoxa/prisma-relay-cursor-connection这个库很可能就是你正在寻找的“瑞士军刀”。它…...