【自然语言处理】用Python从文本中删除个人信息-第二部分
自我介绍
- 做一个简单介绍,酒架年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师酒馆】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。微信小号【ca_cea】

Python中隐私过滤器的实现,该过滤器通过命名实体识别(NER)删除个人身份信息(PII)
这是我上一篇关于从文本中删除个人信息的文章的后续内容。
GDPR是欧盟制定的《通用数据保护条例》。其目的是保护所有欧洲居民的数据。保护数据也是开发人员的内在价值。通过控制对列和行的访问,保护行/列数据结构中的数据相对容易。但是免费文本呢?
在我上一篇文章中,我描述了一个基于正则表达式用法和禁止词列表的解决方案。在本文中,我们添加了一个基于命名实体识别(NER)的实现。完整的实现可以在github PrivacyFilter项目中找到。
什么是命名实体识别?
根据维基百科,NER是:
命名实体识别(NER)(也称为(命名)实体识别、实体分块和实体提取)是信息提取的一个子任务,旨在定位非结构化文本中提到的命名实体,并将其分类为预定义的类别,如人名、组织、位置、医疗代码、时间表达式、数量、货币值、百分比等。
因此,这一切都是关于寻找和识别文本中的实体。一个实体可以是一个单词或一系列连续的单词。实体被分类到预定义的类别中。例如,在下面的句子中,发现了三个实体:实体人“Sebastian Thrun”、实体组织“Google”和实体日期“2007”。
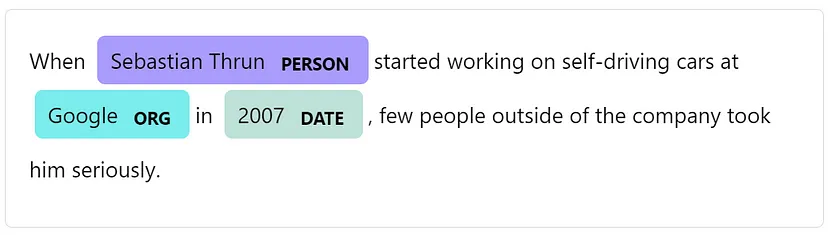
Example entity recognition (source: Spacy.io)
NER是自然语言处理(NLP)人工智能领域的一个子集。该领域包含处理和分析自然语言的算法。当NER能够用自然语言识别实体时,如果是个人、组织、日期或地点等与隐私相关的实体,则可以从文本中删除这些实体。
使用NER过滤PII
首先,我们需要一个NLP处理包。NLP包是按语言训练的,因为所有语言都有自己的语法。我们正在与达奇合作,所以我们需要一个了解这一点的人。我们将使用Spacy作为我们的隐私过滤器。
在Spacy网站上可以找到一个帮助安装Spacy的工具。在选择Python环境和语言后,它会给出相应的命令来安装Spacy:
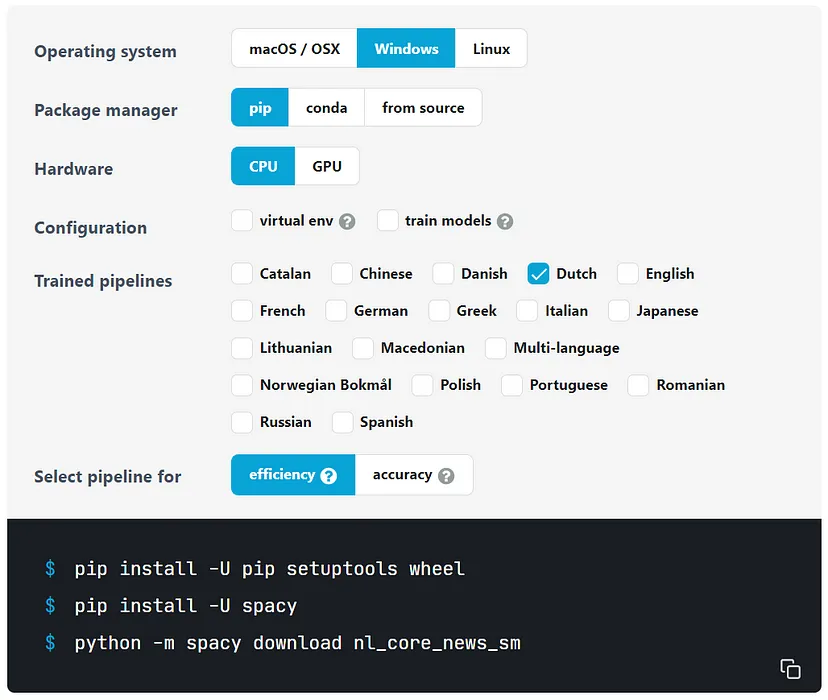
Spacy install tool (source: Spacy.io)
所选管道(效率或精度)决定了NER模型相对于尺寸和速度的精度。选择“效率”会产生更小、更快的模型,但与“精度”相比精度更低。这取决于您的用例哪个模型更合适。为了发展,我们选择使用效率模型。进行第一次净入学率分析:
import spacy
nlp = spacy.load("nl_core_news_sm")
doc = nlp("Geert werkt sinds 2010 voor HAL.")
for token in doc:print(token.text, token.pos_, token.ent_type_)'''
Output:
Geert PROPN PERSON
werkt VERB
sinds ADP
2010 NUM DATE
voor ADP
HAL PROPN ORG
. PUNCT
'''
在第2行导入Spacy包之后,将使用Spacy.load()方法加载模型。在这种情况下,加载了Dutch的有效模型。模型由其名称指定,该名称与上一步中用于下载模型的名称相同。要切换到准确的荷兰语模型,请将“nl_core_news_sm”替换为“nl_core _news_lg”。对于上面的示例,这将产生相同的输出。
快速、简单的性能测试表明,加载小型模型大约需要2.0秒,加载大型模型大约需要4.5秒。分析一个句子需要5.5毫秒,而不是6.0毫秒。大型号似乎需要大约500 MB的额外内存。
词性(POS)标签的含义可以在这个网站上找到。例如,它们是:
Geert PROPN PERSON Proper noun, person werkt VERB Verb sinds ADP Adposition, case marking 2010 NUM DATE Numeral, date voor ADB Adposition HAL PROPN ORG Proper noun, organisation . PUNCT Punctuation
对于过滤PII,我们对POS类型NUM和PROPN感兴趣。我们将用描述其实体类型的标签来替换POS文本元素。
import spacystring = "Geert werkt sinds 2010 voor HAL."
print(string)
nlp = spacy.load("nl_core_news_sm")
doc = nlp(string)filtered_string = ""
for token in doc:if token.pos_ in ['PROPN', 'NOUN', 'NUM']:new_token = " <{}>".format(token.ent_type_)elif token.pos_ == "PUNCT":new_token = token.textelse:new_token = " {}".format(token.text)filtered_string += new_token
filtered_string = filtered_string[1:]
print(filtered_string)'''
Output:
Geert werkt sinds 2010 voor HAL.
<PERSON> werkt sinds <NUMBER> voor <ORG>.
'''
代码的第一部分加载语言模型,并将输入字符串解析为令牌列表(doc)。第8-16行中的循环通过迭代文档中的所有标记来构建过滤后的文本。如果令牌的类型为PROPN、NOUN或NUMBER,则会用标记<…>替换,其中标记等于Spacy识别的实体类型。所有令牌都通过前缀空间连接到新字符串。前缀是必需的,因为标记化字符串已经删除了这些前缀。如果是标点符号,则不添加前缀空格(第12-13行)。
在循环之后,由于第11行或第13行的原因,新字符串的第一个字符是一个空格,因此我们需要删除这个空格(第17行)。这导致字符串中没有隐私信息。
它有多好?
在上一篇文章中,我们已经建立了一个基于禁止词列表的隐私过滤器。与NER相比,该学徒需要更多的代码和精力。但它们的比较如何?
- NER要求语法正确的句子。在这种情况下,即使姓名拼写错误,也可以很好地替换隐私信息。NER优于禁言表。
- 无论上下文如何,禁词过滤器都会替换禁词。尤其是街道名称和城市名称的列表会导致大量不必要的删除词。例如,植物名称、动物或城堡等项目等单词作为街道名称很常见,将从文本中删除。这可能会删除许多不必要的单词,从而降低生成文本的可用性。NER的表现会更好。
- 如果文本在语法上不正确(例如,“你叫什么名字?”问题的答案“Peter”将不会被NER过滤为正确。这些句子在聊天信息和对话记录中很常见。在这些情况下,NER方法将失败,因为NER算法无法用一个或几个词来确定这些答案的性质。
因此,这完全取决于您的用例和所需的过滤级别。该组合确定最佳方法是使用禁止列表版本、NER版本还是甚至两者的组合。后者将结合这两种方法的优点(但也有部分缺点)。要找到最佳方法,请使用数据的子集来筛选和测试不同的算法和/或组合,以找到最适合的算法。
将NER与禁止词列表(FWL)进行比较的一些示例:
INPUT: Geert werkt sinds 2010 voor HAL. NER : <FILTERED> werkt sinds <FILTERED> voor <FILTERED>. FWL : <FILTERED> werkt sinds <FILTERED> voor HAL. INPUT: Heert werkt sinds 2010 voor HAL. NER : <FILTERED> werkt sinds <FILTERED> voor <FILTERED>. FWL : Heert werkt sinds <FILTERED> voor HAL. INPUT: Wat is je naam? Geert. NER : Wat is je naam? Geert. FWL : Wat is je naam? FILTERED. INPUT: Geert kijkt naar de duiven op het dak. NER : <FILTERED> kijkt naar de duiven op het dak. FWL : <FILTERED> kijkt naar de <FILTERED> op het dak.
(为了便于比较,所有标签(如<PERSON>)都替换为通用标签<FILTERED>)
- 第一个示例显示tat FWL无法删除公司名称,因为它没有公司名称列表。NER算法在句子上确定了“HAL”是一个名词,更具体地说是一个组织。
- 第二个例子表明,NER可以处理名称中的类型错误,因为它查看句子的结构,而FWL不将“Heert”识别为名称。名称列表只包含拼写正确的版本。
- 第三个例子表明,NER需要语法正确的句子来识别“Geert”这个名字。这可能是一次谈话的记录,也可能是聊天中的互动。它展示了NER如何在书面语言方面表现良好,但在理解口语方面存在困难。
- 在最后一个例子中,FWL删除了“duiven”一词,因为它不仅描述了动物(duiven在荷兰语中是鸽子的意思),而且还是一个城市的名字。
privacy filter code on Github 包含这两种方法,在初始化过程中可以选择NER方法或FWL方法。我们在本文中没有涉及正则表达式,但选择NER方法也会执行正则表达式(NER无法识别和替换URL等)。它还包含了一些使用和过滤的示例文本,以了解两种方法在现实生活中的美国案例中的差异。
最后一句话
本文和前一篇文章描述了删除文本中个人信息的两种方法。这两种方法都有其优点和缺点,不可能为所有用例选择一种方法。删除更多的隐私信息也会导致删除更多的非隐私信息,从而降低过滤文本的价值。NER在删除已识别的隐私信息方面更准确,但需要格式良好的句子才能操作。为了最大限度地提高安全性,甚至可以将这两种方法结合起来。请随意在Github上尝试实现。
我希望你喜欢这篇文章。想要获得更多灵感,请查看我的其他文章
本文:【自然语言处理】用Python从文本中删除个人信息-第二部分 | 开发者开聊
欢迎收藏 【全球IT瞭望】,【架构师酒馆】和【开发者开聊】.
相关文章:
【自然语言处理】用Python从文本中删除个人信息-第二部分
自我介绍 做一个简单介绍,酒架年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【…...

设计模式之-中介者模式,快速掌握中介者模式,通俗易懂的讲解中介者模式以及它的使用场景
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...
12.25
led.c #include "led.h" void all_led_init() {RCC_GPIO | (0X3<<4);//时钟使能GPIOE_MODER &(~(0X3<<20));//设置PE10输出GPIOE_MODER | (0X1<<20);//设置PE10为推挽输出GPIOE_OTYPER &(~(0x1<<10));//PE10为低速输出GPIOE_OSPEED…...
)
MySQL5.7的几种安装方式总结(排错踩坑呕心沥血的经历)
包安装 添加国内源:mysql | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 注意:5.7安装之后有一个临时密码,进行登录并修改新密码后才可以对mysql进行操作。 可以yun list看看各个系统光盘自带的都是什么版本&…...

zookeeper基本使用
目录 环境搭建 单机版搭建 集群版搭建 基本语法使用 可视化客户端 数据结构 节点分类 1. 持久节点 2. 临时节点 3. 有序节点 4. 容器节点 5. TTL节点 节点状态 监听机制 watch监听 永久性watch 应用场景 1. 实现分布式锁 2. 乐观锁更新数据 应用场景总结 选…...

【华为机试】2023年真题B卷(python)-分月饼
一、题目 题目描述: 中秋节公司分月饼,m个员工,买了n个月饼,m<n,每个员工至少分1个月饼,但可以分多个,单人份到最多月饼的个数为Max1,单人分到第二多月饼的个数是Max2,…...

EtherCAT主站SOEM -- 11 -- EtherCAT从站 XML 文件解析
EtherCAT主站SOEM -- 11 -- EtherCAT从站 XML 文件解析 1 EtherCAT 从站信息规范1.1 XML 文件说明1.1.1 XML 数据类型1.1.2 EtherCATInfo1.1.3 Groups1.1.4 Devices1.1.5 Modules1.1.6 Types1.1.6.1 AccessType 的组成1.1.6.2 ArraylnfoType 的组成1.1.6.3 DeviceType 的组成1.…...

YOLOv5算法改进(23)— 更换主干网络GhostNet + 添加CA注意力机制 + 引入GhostConv
前言:Hello大家好,我是小哥谈。本节课就让我们结合论文来对YOLOv5进行组合改进(更换主干网络GhostNet + 添加CA注意力机制 + 引入GhostConv),希望同学们学完本节课可以有所启迪,并且后期可以自行进行YOLOv5算法的改进!🌈 前期回顾: YOLOv5算法改进(1)— 如何去…...

centos系统部署rancher1.6版本并部署服务
1. centos上部署docker. 请参考 博客 2. 用docker安装rancher1.6 sudo docker run -d -v /mnt/rancher/db:/var/lib/mysql --restartunless-stopped -p 8080:8080 rancher/server3.浏览器登录做设置 3.1 浏览器打开 1.117.92.32:8080 #直接就登录了 3.2 第一次进入&am…...

Matlab实时读取串口数据并实时画图方法
** Matlab实时读取串口数据并实时画图方法 ** 按照数据串口协议如:$KT2,1.80,88.18,39.54,42.86,LO[0.72,-1.04,0.35],举例。 s serialport("COM12",115200,"Timeout",5); poszeros(100000,3); j1; data1 read(s,1,"uint8&…...
智能优化算法应用:基于向量加权平均算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于向量加权平均算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于向量加权平均算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.向量加权平均算法4.实验参数设定…...
SpringBoot - Maven 打包合并一个胖 JAR 以及主项目 JAR 依赖 JAR 分离打包解决方案
问题描述 <plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.1.18.RELEASE</version><configuration><!--<classifier>exec</classifier>--…...

react 18 Hooks扩展函数式组件的状态管理
React函数式组件 特点 React函数式组件具有以下特点: 简洁:使用函数的方式定义组件,语法简单直观。无状态:函数式组件没有内部状态(state),只依赖于传入的props。可复用:函数式组…...
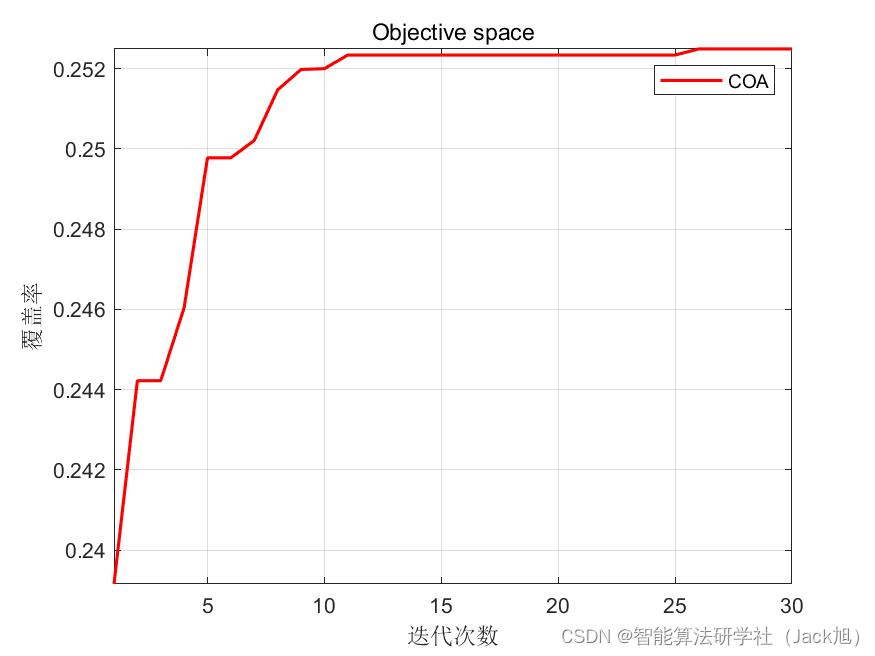
智能优化算法应用:基于浣熊算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于浣熊算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于浣熊算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.浣熊算法4.实验参数设定5.算法结果6.参考文献7.MA…...

c++ qt QtWidgetsApplication 项目 使用外部ui
1 包含生成的UI头文件: 例如,如果你的Qt Designer的.ui文件名为test.ui,那么生成的头文件通常为ui_test.h。 #include "ui_test.h"2 实例化UI类:.h文件中实例化ui 在你的主要类的头文件中,你通常会声明一个U…...
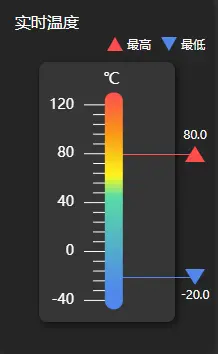
使用React 18、Echarts和MUI实现温度计
关键词 React 18 Echarts和MUI 前言 在本文中,我们将结合使用React 18、Echarts和MUI(Material-UI)库,展示如何实现一个交互性的温度计。我们将使用Echarts绘制温度计的外观,并使用MUI创建一个漂亮的用户界面。 本文…...
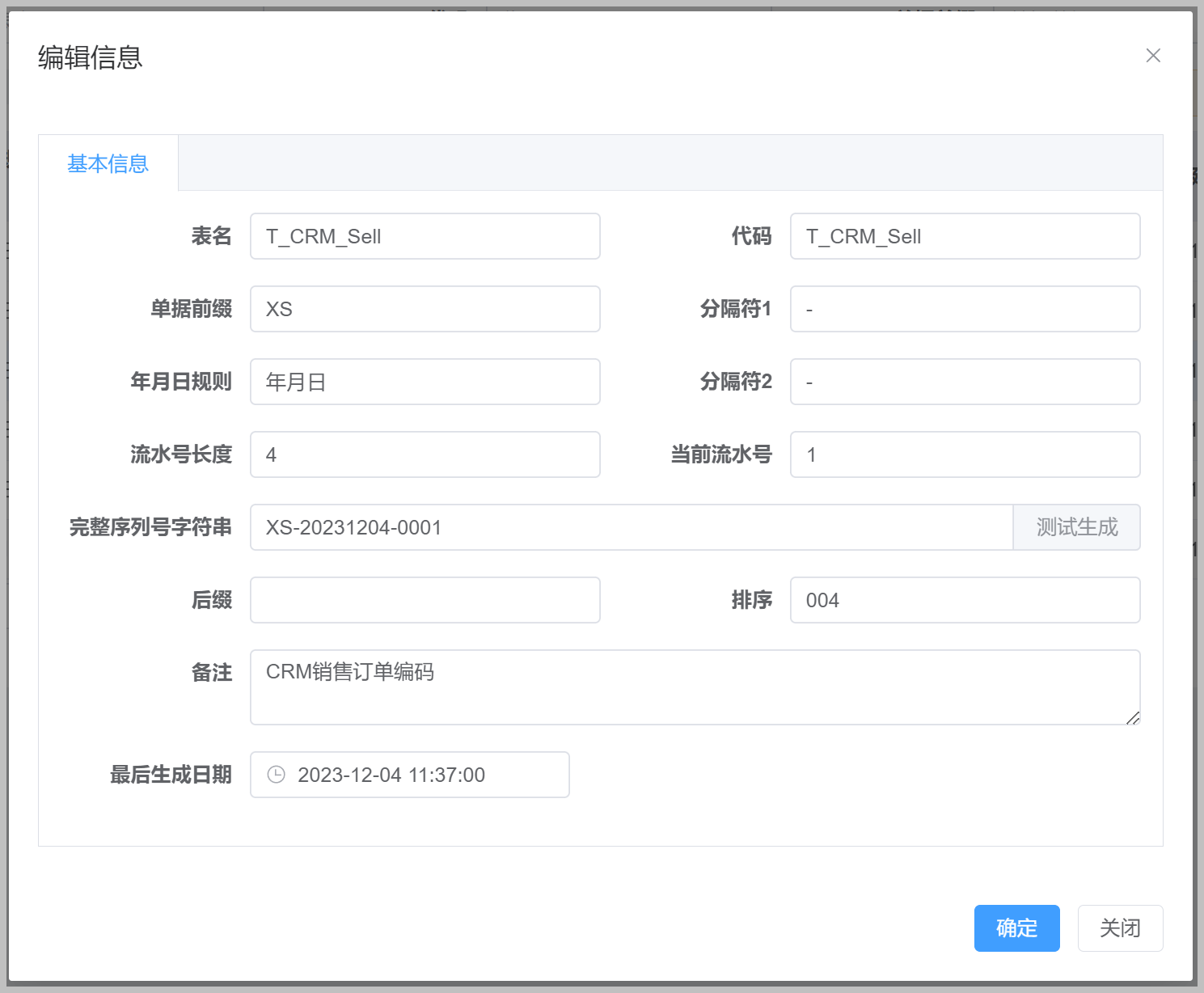
使用代码生成工具快速开发应用-结合后端Web API提供接口和前端页面快速生成,实现通用的业务编码规则管理
1、通用的业务编码规则的管理功能 在前面随笔我们介绍了一个通用的业务编码规则的管理功能,通过代码生成工具Database2Sharp一步步的生成相关的后端和Winform、WPF的界面,进行了整合,通过利用代码生成工具Database2sharp生成节省了常规功能的…...
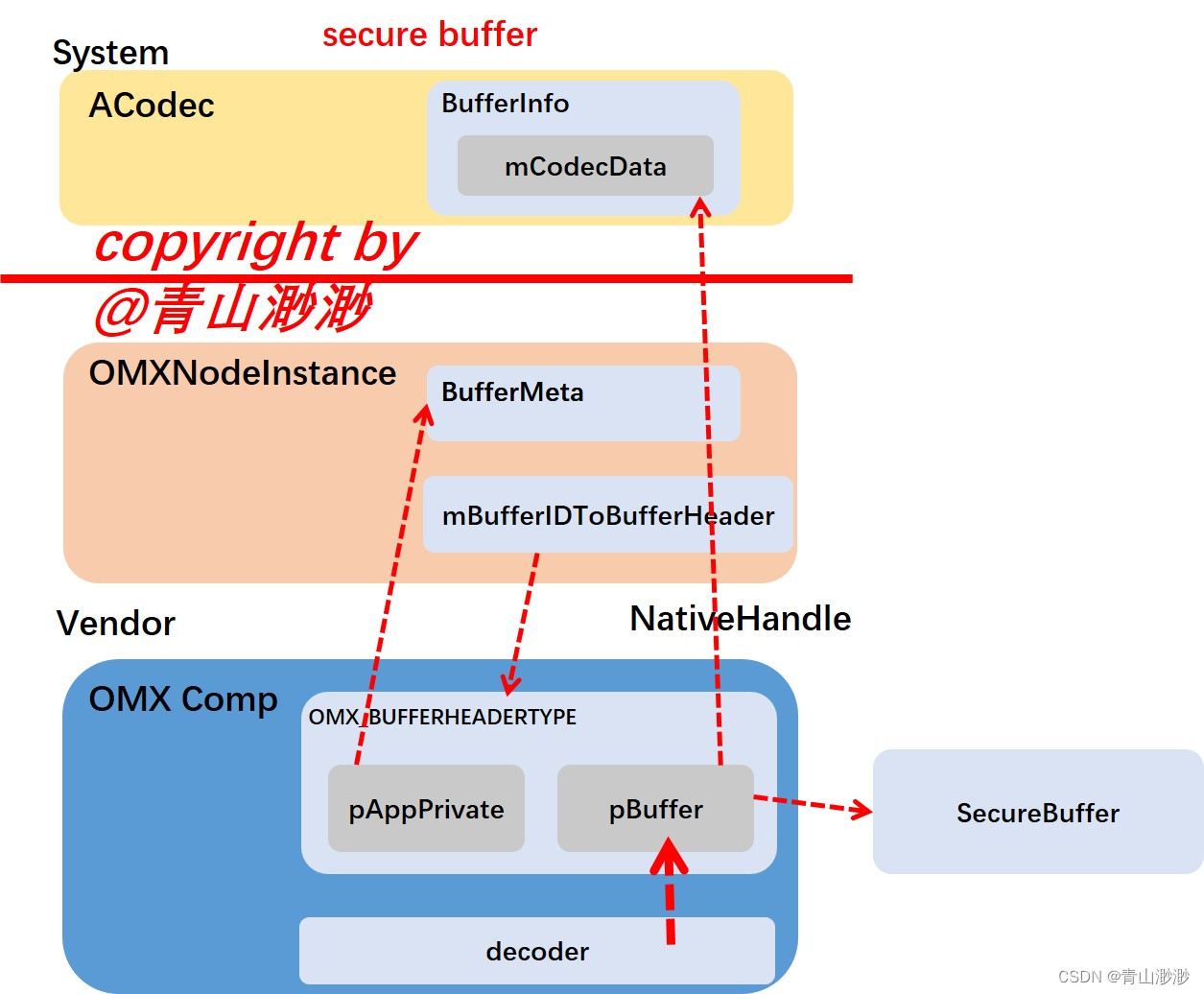
Android 13 - Media框架(26)- OMXNodeInstance(三)
上一节我们了解了OMXNodeInstance中的端口定义,这一节我们一起来学习ACodec、OMXNode、OMX 组件使用的 buffer 到底是怎么分配出来的,以及如何关联起来的。(我们只会去了解 graphic buffer的创建、input bytebuffer的创建、secure buffer的创…...
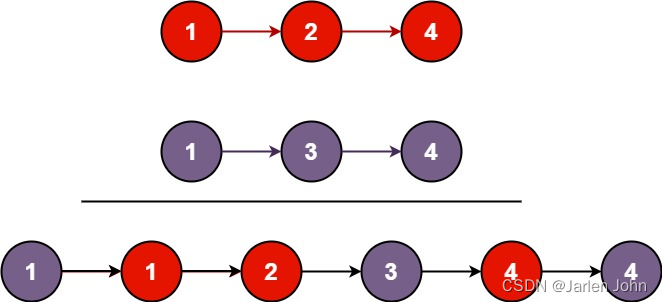
力扣题目学习笔记(OC + Swift)21. 合并两个有序链表
21. 合并两个有序链表 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 链表解题经典三把斧: 哑巴节点栈快慢指针 此题比较容易想到的解法是迭代法,生成哑巴节点,然后迭代生成后续节点。…...
C# WPF上位机开发(windows pad上的应用)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 大部分同学可能都认为c# wpf只能用在pc端。其实这是一种误解。c# wpf固然暂时只能运行在windows平台上面,但是windows平台不仅仅是电脑…...

如何快速掌握音频频谱分析:Spek开源工具完整指南
如何快速掌握音频频谱分析:Spek开源工具完整指南 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek 想要深入了解音频文件的内部结构吗?Spek音频频谱分析器是你的理想选择!这款免费…...

Python自动化签到脚本dailycheckin:Docker部署与模块化设计详解
1. 项目概述与核心价值最近在折腾一些自动化工具,发现一个挺有意思的项目,叫Sitoi/dailycheckin。简单来说,这是一个用 Python 写的签到脚本集合,能帮你自动完成各种网站和应用的日常签到任务。你可能觉得签到不就是点一下吗&…...

书匠策AI到底在干嘛?用“拆快递“的方式,给你科普它的毕业论文功能全流程
各位同学,你们有没有拆过那种"一步一步跟着说明书就能装好"的宜家家具? 今天我要用拆快递的逻辑,帮你把书匠策AI(官网:h 官网直达:www.shujiangce.com,微信公众号搜一搜"书匠策…...

普冉PY32F0系列开发:如何用VSCode+Cortex-Debug插件实现媲美Keil的图形化调试体验?
普冉PY32F0开发实战:VSCodeCortex-Debug打造专业级嵌入式调试环境 在嵌入式开发领域,高效的调试工具往往能决定项目的成败。对于使用普冉PY32F0系列Cortex-M0 MCU的开发者而言,传统商业IDE虽然功能完善,但存在许可成本高、跨平台支…...

Taotoken用量看板如何让我们清晰掌握各模型消耗与团队使用习惯
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何让我们清晰掌握各模型消耗与团队使用习惯 作为团队管理者,在引入大模型能力支持业务开发时&#…...

Niagara Editor界面详解:从零上手视觉特效创作
1. 认识Niagara Editor:视觉特效的创作工坊 第一次打开Niagara Editor时,满屏的面板和按钮可能会让你感到不知所措。别担心,这就像走进一个设备齐全的厨房——虽然工具很多,但每样都有其特定用途。作为Unreal Engine的粒子特效系…...

BNO085传感器RVC模式实战:Python驱动与姿态解算应用指南
1. 项目概述与核心价值在机器人、无人机或者任何需要感知自身在三维空间中“朝向”的项目里,姿态解算都是一个绕不开的核心技术。简单来说,它就是要回答“我的设备现在头朝哪、身子歪了多少度”这类问题。过去,我们可能用一个简单的三轴加速度…...

【信息科学与工程学】【通信工程】第一百二十二篇 数字通信函数01
数字通信算法/函数库 函数编号: F001 函数名称: qpsk_modulator 类型: 调制 (Modulation) 通信分析: 该函数实现经典的正交相移键控调制,将输入的二进制比特流映射为复数符号(IQ数据)。它是数字通信发射机的基础模块,将数字信息加载到载波相位上,具有恒包络特…...

Godot 4动态网格切割:实现实时物理破坏效果
1. 项目概述与核心价值 最近在Godot社区里,一个名为 cloudofoz/godot-smashthemesh 的开源项目引起了我的注意。乍一看这个标题,可能会觉得有些抽象——“粉碎网格”?但当你深入了解后,会发现它精准地解决了一个在3D游戏开发&am…...

软考资料全集
距离2026年上半年软考(5月开考)已不算遥远,现在正是着手准备的好时机。回顾这几年的备考历程,我也曾为找资料花费不少时间。趁着这次整理,我把手头积累的各科目复习资料——全部来自互联网公开渠道——系统地归拢了一下…...