Android 13 - Media框架(26)- OMXNodeInstance(三)
上一节我们了解了OMXNodeInstance中的端口定义,这一节我们一起来学习ACodec、OMXNode、OMX 组件使用的 buffer 到底是怎么分配出来的,以及如何关联起来的。(我们只会去了解 graphic buffer的创建、input bytebuffer的创建、secure buffer的创建)
1、ACodec::allocateOutputMetadataBuffers
我们先一起来回忆一下,ACodec在使用surface的情况下给ouput port分配buffer使用的是allocateOutputMetadataBuffers方法,这时候真正的graphic buffer还未分配出来,BufferInfo的状态还是OWNED_BY_NATIVE_WINDOW(意为 buffer 还在 native 中)。
for (OMX_U32 i = 0; i < bufferCount; i++) {BufferInfo info;info.mStatus = BufferInfo::OWNED_BY_NATIVE_WINDOW;info.mFenceFd = -1;info.mRenderInfo = NULL;info.mGraphicBuffer = NULL;info.mNewGraphicBuffer = false;info.mDequeuedAt = mDequeueCounter;// 创建 meta datainfo.mData = new MediaCodecBuffer(mOutputFormat, new ABuffer(bufferSize));// Initialize fence fd to -1 to avoid warning in freeBuffer().((VideoNativeMetadata *)info.mData->base())->nFenceFd = -1;info.mCodecData = info.mData;err = mOMXNode->useBuffer(kPortIndexOutput, OMXBuffer::sPreset, &info.mBufferID);mBuffers[kPortIndexOutput].push(info);ALOGV("[%s] allocated meta buffer with ID %u",mComponentName.c_str(), info.mBufferID);}
这里BufferInfo是作为分配出来的buffer的索引,分配的 mCodecData (Meta data) 没有任何作用,仅仅是起着占位的作用。
ACodec 需要给这个 BufferInfo 打上索引,调用useBuffer时,传入的OMXBuffer类型是kBufferTypePreset,这个内容可以到 OMXBuffer.cpp 中查询。
1.1、useBuffer
进入到 OMXNodeInstance 中,首先就会检查 port mode,我们可以看到,如果port mode不是dynamic的类型,会直接报错。
status_t OMXNodeInstance::useBuffer(OMX_U32 portIndex, const OMXBuffer &omxBuffer, IOMX::buffer_id *buffer) {switch (omxBuffer.mBufferType) {case OMXBuffer::kBufferTypePreset: {if (mPortMode[portIndex] != IOMX::kPortModeDynamicANWBuffer&& mPortMode[portIndex] != IOMX::kPortModeDynamicNativeHandle) {break;}return useBuffer_l(portIndex, NULL, NULL, buffer);}}
kBufferTypePreset 在这里应该表示的是占位的意思。
我们不要被 useBuffer 的参数 buffer 迷惑了,它其实是一个 int 类型。判断完成后就会进入到 useBuffer_l 中。
1.2、useBuffer_l
进入下面的内容之前我们首先要了解的是,之所以方法名为 use buffer,指的是 OMX 组件端口使用的 buffer 是在其他地方分配的,OMX 组件仅仅只是使用。
useBuffer_l 的设计思路其实和之前的一篇文章中的 enableNativeBuffers_l 类似,它是把几个不同的设定写到一个函数体当中,用入参来判断当前走的是什么设定。useBuffer_l 有两个参数,但是它其实有三种可能的设定,一种是IMemory,另一种是 IHidlMemory,最后一个是两个参数都为 NULL,表示是一个占位。
status_t OMXNodeInstance::useBuffer_l(OMX_U32 portIndex, const sp<IMemory> ¶ms,const sp<IHidlMemory> &hParams, IOMX::buffer_id *buffer) {BufferMeta *buffer_meta;OMX_BUFFERHEADERTYPE *header;OMX_ERRORTYPE err = OMX_ErrorNone;// 判断是否使用 meta databool isMetadata = mMetadataType[portIndex] != kMetadataBufferTypeInvalid;// 如果使用graphic buffer但是不用meta data则直接报错if (!isMetadata && mGraphicBufferEnabled[portIndex]) {ALOGE("b/62948670");android_errorWriteLog(0x534e4554, "62948670");return INVALID_OPERATION;}// 检查参数,不能同时设定两个参数size_t paramsSize;void* paramsPointer;if (params != NULL && hParams != NULL) {return BAD_VALUE;}// 解析传递的buffer的指针以及buffer的大小,如果什么都没有传,那么指针为NULLif (params != NULL) {// TODO: Using unsecurePointer() has some associated security pitfalls// (see declaration for details).// Either document why it is safe in this case or address the// issue (e.g. by copying).paramsPointer = params->unsecurePointer();paramsSize = params->size();} else if (hParams != NULL) {paramsPointer = hParams->getPointer();paramsSize = hParams->getSize();} else {paramsPointer = nullptr;}// 使用的buffer的大小OMX_U32 allottedSize;// metadata mode下,设定的是占位符,OMXNode 与 OMX 组件之间通过 metadata交流,metadata buffer由 OMXNode分配// 这里需要根据不同的类型分配不同类型的meta data,确定metadata sizeif (isMetadata) {if (mMetadataType[portIndex] == kMetadataBufferTypeGrallocSource) {allottedSize = sizeof(VideoGrallocMetadata);} else if (mMetadataType[portIndex] == kMetadataBufferTypeANWBuffer) {// allottedSize = sizeof(VideoNativeMetadata);} else if (mMetadataType[portIndex] == kMetadataBufferTypeNativeHandleSource) {allottedSize = sizeof(VideoNativeHandleMetadata);} else {return BAD_VALUE;}} else {// NULL 只允许出现在 meta mode 当中// 如果不使用meta data 并且 没有传 buffer下来,那么直接报错// NULL params is allowed only in metadata mode.if (paramsPointer == nullptr) {ALOGE("b/25884056");return BAD_VALUE;}allottedSize = paramsSize;}// 是否是与graphic搭配使用的metadatabool isOutputGraphicMetadata = (portIndex == kPortIndexOutput) &&(mMetadataType[portIndex] == kMetadataBufferTypeGrallocSource ||mMetadataType[portIndex] == kMetadataBufferTypeANWBuffer);// 是否需要分配bufferuint32_t requiresAllocateBufferBit =(portIndex == kPortIndexInput)? kRequiresAllocateBufferOnInputPorts: kRequiresAllocateBufferOnOutputPorts;// quirks 模式下,如果不是使用的 meta data mode,则需要让 OMX 组件分配buffer// we use useBuffer for output metadata regardless of quirksif (!isOutputGraphicMetadata && (mQuirks & requiresAllocateBufferBit)) {// metadata buffers are not connected cross process; only copy if not meta.// quirks 模式下,将 OMX 组件分配的buffer 和 上层 buffer相关绑定,进行数据拷贝// 这应该是很没有效率的一种行为buffer_meta = new BufferMeta(params, hParams, portIndex, !isMetadata /* copy */, NULL /* data */);err = OMX_AllocateBuffer(mHandle, &header, portIndex, buffer_meta, allottedSize);if (err != OMX_ErrorNone) {CLOG_ERROR(allocateBuffer, err,SIMPLE_BUFFER(portIndex, (size_t)allottedSize,paramsPointer));}} else {OMX_U8 *data = NULL;// metadata buffers are not connected cross process// use a backup buffer instead of the actual bufferif (isMetadata) {// 为 meta data buffer 分配空间data = new (std::nothrow) OMX_U8[allottedSize];if (data == NULL) {return NO_MEMORY;}memset(data, 0, allottedSize);// 将 meta data buffer 封装到 BufferMeta 当中buffer_meta = new BufferMeta(params, hParams, portIndex, false /* copy */, data);} else {// 如果不是 meta data mode,直接使用buffer指针data = static_cast<OMX_U8 *>(paramsPointer);// 将 buffer 封装到 BufferMeta 当中buffer_meta = new BufferMeta(params, hParams, portIndex, false /* copy */, NULL);}// 直接把创建的 BufferMeta 传递给 OMX 组件使用,不需要进行buffer拷贝err = OMX_UseBuffer(mHandle, &header, portIndex, buffer_meta,allottedSize, data);if (err != OMX_ErrorNone) {CLOG_ERROR(useBuffer, err, SIMPLE_BUFFER(portIndex, (size_t)allottedSize, data));}}if (err != OMX_ErrorNone) {delete buffer_meta;buffer_meta = NULL;*buffer = 0;return StatusFromOMXError(err);}// 检查创建的buffer header中的上层数据是否和 创建的 buffer meta 相同CHECK_EQ(header->pAppPrivate, buffer_meta);// 为 buffer header 创建 index*buffer = makeBufferID(header);addActiveBuffer(portIndex, *buffer);sp<IOMXBufferSource> bufferSource(getBufferSource());if (bufferSource != NULL && portIndex == kPortIndexInput) {bufferSource->onInputBufferAdded(*buffer);}CLOG_BUFFER(useBuffer, NEW_BUFFER_FMT(*buffer, portIndex, "%u(%zu)@%p", allottedSize, paramsSize, paramsPointer));return OK;
}useBuffer 的内容很长,里面有很多判断,很多同学可能读不太明白里面到底想干什么,这里我们就来解析一下:
-
首先,它会判断configure阶段配置的一些内容, 比如说metadata mode需要和graphic buffer共同使用;IMemory 参数和 IHidlMemory 参数不能同时设定;
-
接下来会分为两种情况,
- metadata mode,也就是我们上面讨论的传下来的buffer类型是kBufferTypePreset的情况(占位),这种情况上层没有真正传buffer下来,OMX组件和上层通过metadata进行数据传递,所以usebuffer中会根据configure的配置获取需要传递的metadata类型,计算metadata所需的size;
- preset byte buffer,这种就是普通的non secure buffer,可以通过指针读写buffer中的数据,use buffer需要获取buffer的地址以及大小;
-
判断是否用quirks,这个东西我们在创建OMXNodeInstance时有看见过,它是在xml中配置的,一旦有了这个配置,那么只要端口不是metadata mode,则需要让OMX组件分配buffer,上层传下来的buffer会与OMX分配的buffer做绑定,创建一个
BufferMeta,上层传的数据会在这里做拷贝,写入到OMX组件分配的buffer当中。(这里是调用OMX_AllocateBuffer的地方之一)
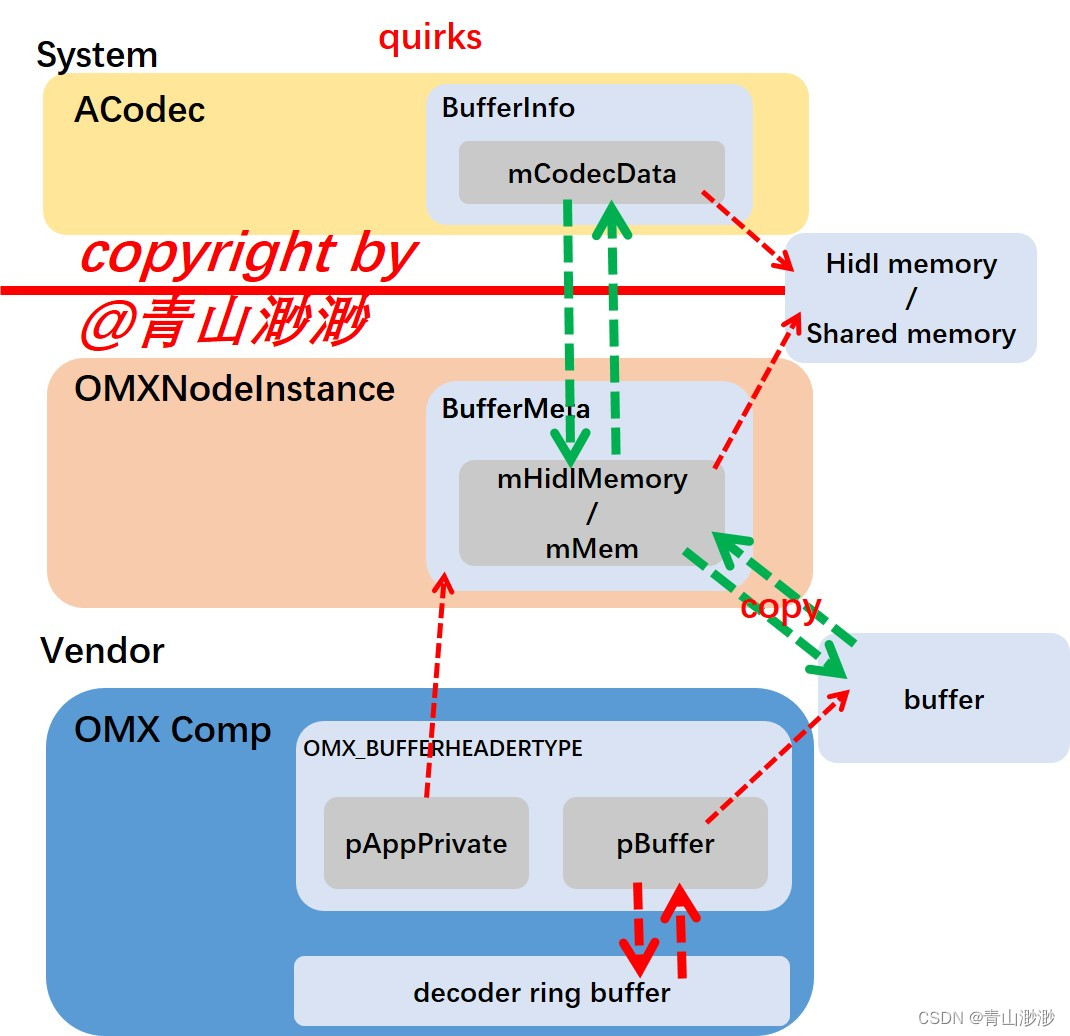
-
如果不使用quirks,那么数据就不需要在OMXNodeInstance层做中转了。
- metadata mode,分配meta data大小的buffer,创建出BufferMeta;
- preset byte buffer,直接用上层传的buffer创建BufferMeta;
- 调用OMX_UseBuffer,将 BufferMeta 和 metadata/buffer 注册到 OMX 组件当中,并且创建出
OMX_BUFFERHEADERTYPE;
-
为创建出的 OMX_BUFFERHEADERTYPE 分配 id;
到这里,useBuffer_l 的分析就完成了,之所以要在 OMXNodeInstance 这一层创建 BufferMeta,可能就是为了记录上层传下来的所有buffer,或者是做数据中转用的。
quirks模式会在 OMXNodeInstance 层多做一次数据拷贝,现在已经被弃用了。
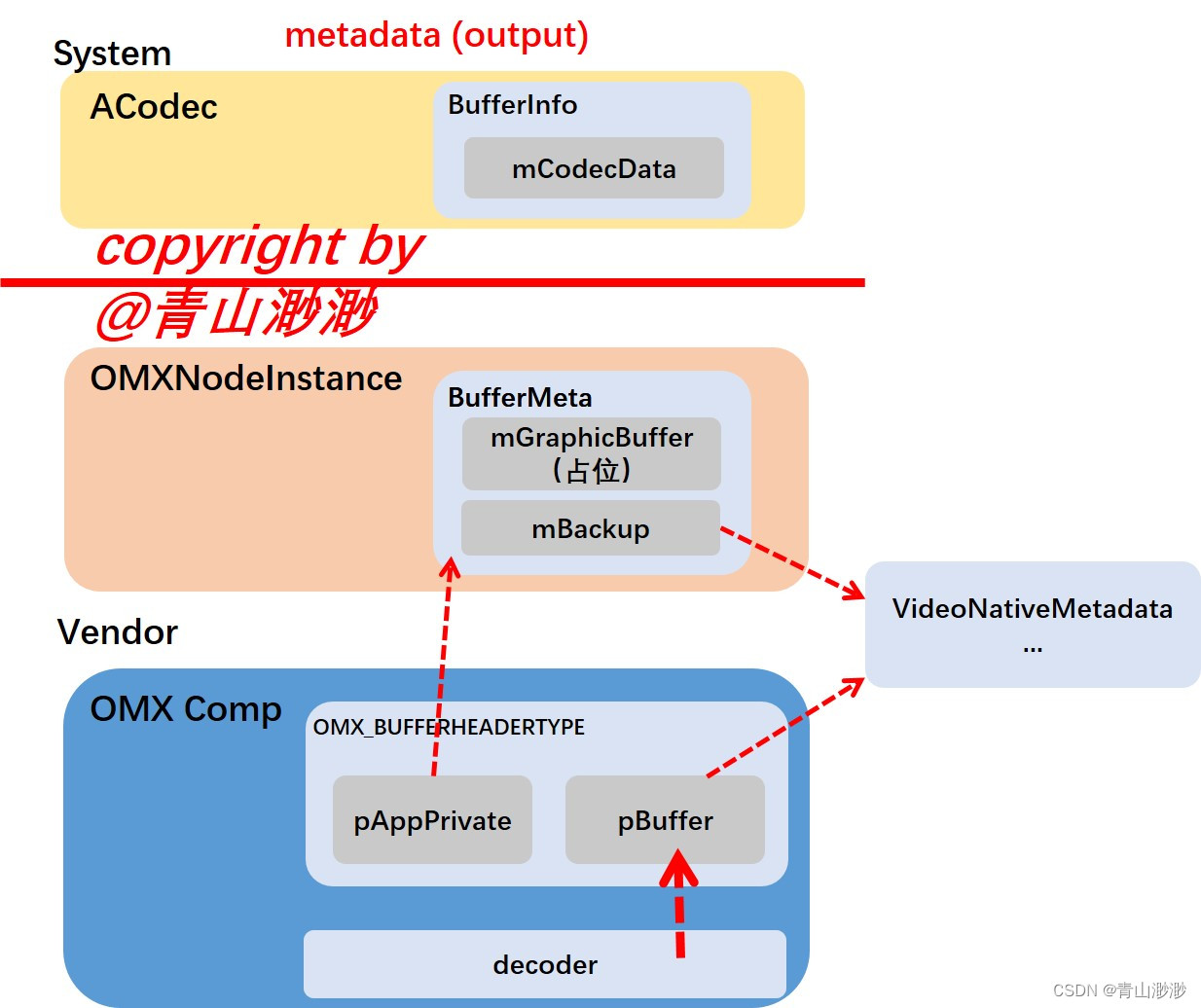
再放上两张示意图:
一张是 preset byte buffer:
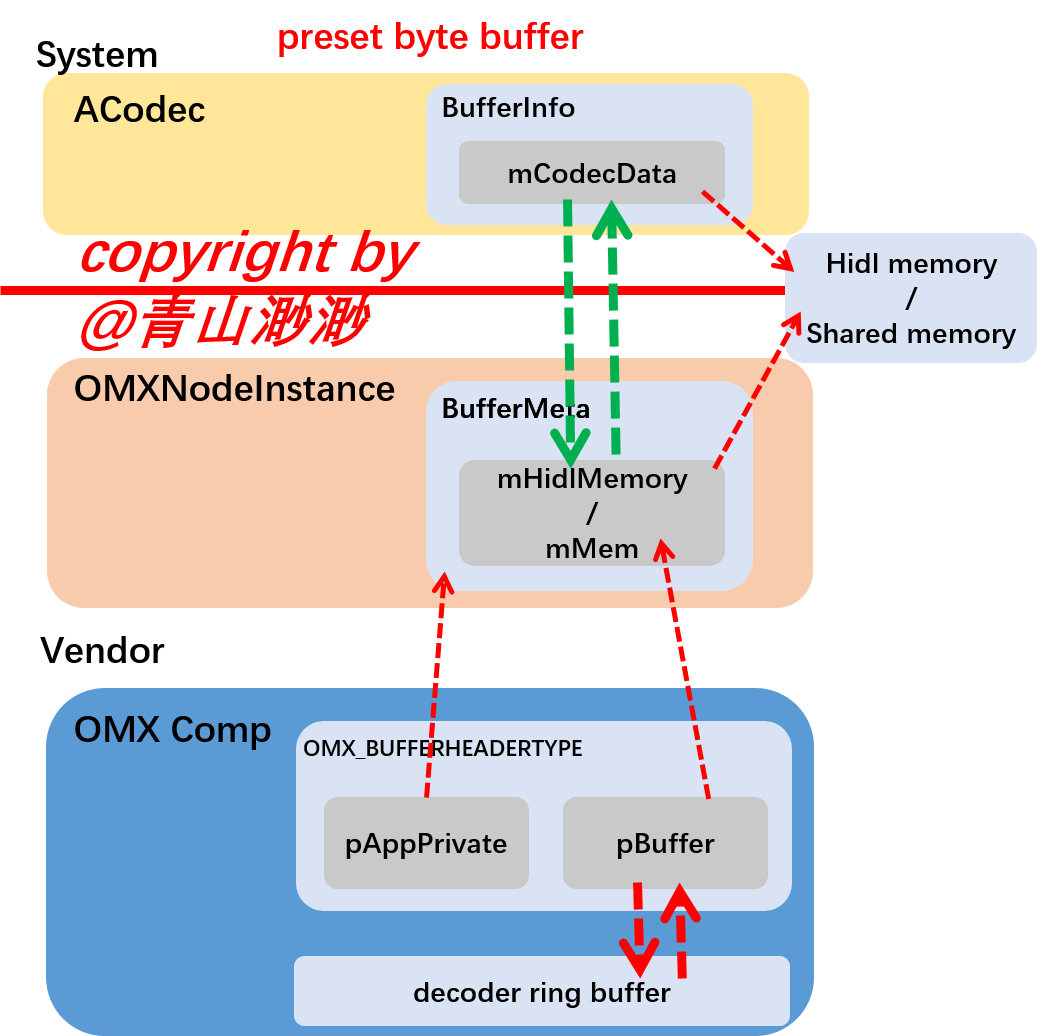
另一张是meta data,可以看到 meta data 模式下,output buffer 不会有任何东西回传给上层。
OMXNodeInstance 收到返回的 OMX_BUFFERHEADERTYPE 后会为其分配 id:
IOMX::buffer_id OMXNodeInstance::makeBufferID(OMX_BUFFERHEADERTYPE *bufferHeader) {if (bufferHeader == NULL) {return 0;}Mutex::Autolock autoLock(mBufferIDLock);IOMX::buffer_id buffer;do { // handle the very unlikely case of ID overflowif (++mBufferIDCount == 0) {++mBufferIDCount;}buffer = (IOMX::buffer_id)mBufferIDCount;} while (mBufferIDToBufferHeader.indexOfKey(buffer) >= 0);mBufferIDToBufferHeader.add(buffer, bufferHeader);mBufferHeaderToBufferID.add(bufferHeader, buffer);return buffer;
}
可以看到一个 OMXNodeInstance 的buffer id用一个mBufferIDCount 成员来管理,所以input buffer和ouput buffer id 是连续的。
makeBufferID 还为 id 和 bufferheader 建立起一个映射,便于快速完成查找。
1.2、allocateSecureBuffer
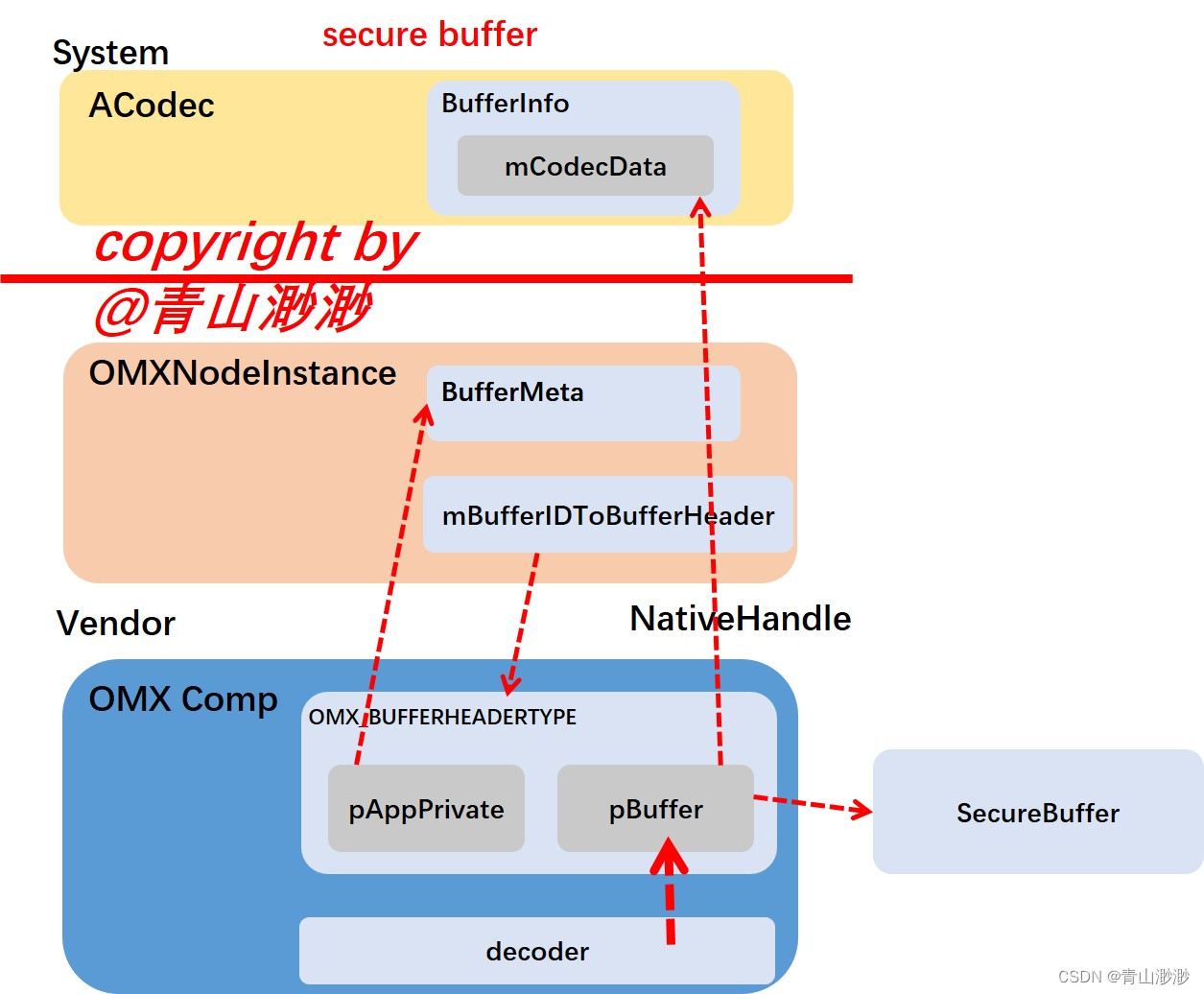
allocate buffer 是让 OMX 组件分配需要使用的 buffer,在ACodec中,只有在使用 secure buffer时,会让omx组件分配buffer handle。secure buffer是一块受保护的buffer,我们无法读取到内部的资料,内存拷贝需要通过操作 handle 来完成,这里我们要看 handle 是如何创建的:
BufferInfo info;info.mStatus = BufferInfo::OWNED_BY_US;info.mFenceFd = -1;info.mRenderInfo = NULL;info.mGraphicBuffer = NULL;info.mNewGraphicBuffer = false;if (mode == IOMX::kPortModePresetSecureBuffer) {void *ptr = NULL;sp<NativeHandle> native_handle;err = mOMXNode->allocateSecureBuffer(portIndex, bufSize, &info.mBufferID,&ptr, &native_handle);info.mData = (native_handle == NULL)? new SecureBuffer(format, ptr, bufSize): new SecureBuffer(format, native_handle, bufSize);info.mCodecData = info.mData;}
可以看到,直接就调用 OMXNode 的 allocateSecureBuffer 方法了,这块buffer将由native层创建,所以 allocateSecureBuffer 将会调用组件的OMX_AllocateBuffer方法:
status_t OMXNodeInstance::allocateSecureBuffer(OMX_U32 portIndex, size_t size, IOMX::buffer_id *buffer,void **buffer_data, sp<NativeHandle> *native_handle) {if (buffer == NULL || buffer_data == NULL || native_handle == NULL) {ALOGE("b/25884056");return BAD_VALUE;}if (portIndex >= NELEM(mSecureBufferType)) {ALOGE("b/31385713, portIndex(%u)", portIndex);android_errorWriteLog(0x534e4554, "31385713");return BAD_VALUE;}Mutex::Autolock autoLock(mLock);if (mHandle == NULL) {return DEAD_OBJECT;}if (!mSailed) {ALOGE("b/35467458");android_errorWriteLog(0x534e4554, "35467458");return BAD_VALUE;}// 检查 port modeif (mPortMode[portIndex] != IOMX::kPortModePresetSecureBuffer) {ALOGE("b/77486542");android_errorWriteLog(0x534e4554, "77486542");return INVALID_OPERATION;}// 创建 BufferMeta,这里的 bufferMeta没有起实质性作用BufferMeta *buffer_meta = new BufferMeta(portIndex);OMX_BUFFERHEADERTYPE *header;// 调用 OMX 组件分配 secure bufferOMX_ERRORTYPE err = OMX_AllocateBuffer(mHandle, &header, portIndex, buffer_meta, size);if (err != OMX_ErrorNone) {CLOG_ERROR(allocateBuffer, err, BUFFER_FMT(portIndex, "%zu@", size));delete buffer_meta;buffer_meta = NULL;*buffer = 0;return StatusFromOMXError(err);}CHECK_EQ(header->pAppPrivate, buffer_meta);// 为 bufferheader 分配id*buffer = makeBufferID(header);// OMX 组件创建的 secure buffer handle 将存储在 buffer header 的 pBuffer 中if (mSecureBufferType[portIndex] == kSecureBufferTypeNativeHandle) {*buffer_data = NULL;// 将handle封装为 native handle*native_handle = NativeHandle::create((native_handle_t *)header->pBuffer, false /* ownsHandle */);} else {*buffer_data = header->pBuffer;*native_handle = NULL;}addActiveBuffer(portIndex, *buffer);sp<IOMXBufferSource> bufferSource(getBufferSource());if (bufferSource != NULL && portIndex == kPortIndexInput) {bufferSource->onInputBufferAdded(*buffer);}CLOG_BUFFER(allocateSecureBuffer, NEW_BUFFER_FMT(*buffer, portIndex, "%zu@%p:%p", size, *buffer_data,*native_handle == NULL ? NULL : (*native_handle)->handle()));return OK;
}
allocateSecureBuffer 和 useBuffer 的内容大同小异,只是调用 OMX_AllocateBuffer 回传的 buffer header 中存储有 OMX 组件分配的 secure buffer header,这个buffer handle将会被封装成为 NativeHandle 回传给上层。OMXNodeInstance 中的 BufferMeta 将不会存储任何相关的资讯。
相关文章:
Android 13 - Media框架(26)- OMXNodeInstance(三)
上一节我们了解了OMXNodeInstance中的端口定义,这一节我们一起来学习ACodec、OMXNode、OMX 组件使用的 buffer 到底是怎么分配出来的,以及如何关联起来的。(我们只会去了解 graphic buffer的创建、input bytebuffer的创建、secure buffer的创…...
力扣题目学习笔记(OC + Swift)21. 合并两个有序链表
21. 合并两个有序链表 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 链表解题经典三把斧: 哑巴节点栈快慢指针 此题比较容易想到的解法是迭代法,生成哑巴节点,然后迭代生成后续节点。…...
C# WPF上位机开发(windows pad上的应用)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 大部分同学可能都认为c# wpf只能用在pc端。其实这是一种误解。c# wpf固然暂时只能运行在windows平台上面,但是windows平台不仅仅是电脑…...

Word使用技巧【开题报告】
1、修改目录:选中目录,点击更新域。 2、更改或删除单个页面上的页眉或页脚 3、借助其他软件在Word导入参考文献 利用zetero导入文献:安装zetero 解决参考文献插入问题 在Word中插入文献操作步骤 英文文献出现“等”,如何解决 Zote…...

电子学会C/C++编程等级考试2022年06月(七级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:有多少种二叉树 输入n(1<n<13),求n个结点的二叉树有多少种形态 时间限制:1000 内存限制:65536输入 整数n输出 答案 样例输入 3样例输出 5 答案: //参考答案 #include<bits/stdc++.h> using namespace std; …...
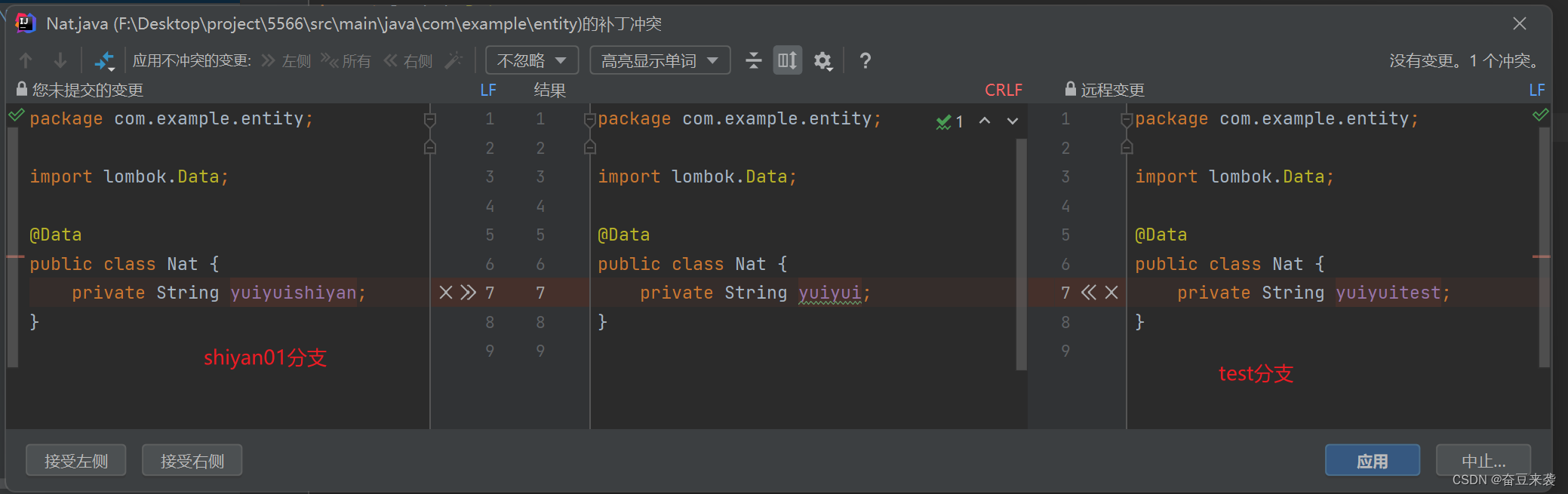
git中的smart checkout和force checkout
切换分支时出现了这个问题: 这是因为shiyan01分支修改了代码,但是没有commit, 所以在切换到test分支的时候弹出这个窗口 一、smart checkout(智能签出) 会把shiyan01分支的改动内容带到test分支。合并处理后的内容就变成了test分支的内容,而shiyan01分支的改动会被…...

vue3整合Element-Plus,极速上手。
条件分页查询: 需求分析: form表单 Button按钮 Table表格 Pagination分页 页面布局: 搜索表单: 如果表单封装的数据较多,建议绑定到一个对象中。 …...

学习Vue2.x
文章目录 一、使用Vue脚手架1.ref和props属性2.mixin混入3.组件化编码流程4.webStorage5.组件自定义事件6.全局事件总线7.消息订阅与发布 二、使用步骤1.引入库 一、使用Vue脚手架 1.ref和props属性 ref属性: (1)被用来给元素或子组件注册应…...
)
新手如何快速熟悉代码,写出东西(持续更新)
目录 第一章、最小编程任务的设想1.1)程序员入门会遇到的问题1.2)最小编程任务的设想1.3)编程逻辑1.4)具体需求 第二章、最小编程单元的练习2.1)代码/需求方面2.1.1)初级练习2.1.2)中级练习2.1.…...
)
11-网络安全框架及模型-软件安全能力成熟度模型(SSCMM)
目录 软件安全能力成熟度模型 1 背景概述 2 主要内容 3 成熟度等级定义 4 关键过程和实践 5 评估方法 6 改进建议 7 持续改进 8 主要价值 9 应用场景 10 优势和局限性 备注 软件安全能力成熟度模型 1 背景概述 SSCMM模型是软件安全能力成熟度模型,它描…...

Linux操作系统基础知识点
Linux是一种计算机操作系统,其内核由林纳斯本纳第克特托瓦兹(Linus Benedict Torvalds)于1991年首次发布。Linux操作系统通常与GNU套件一起使用,因此也被称为GNU/Linux。它是一种类UNIX的操作系统,设计为多用户、多任务…...
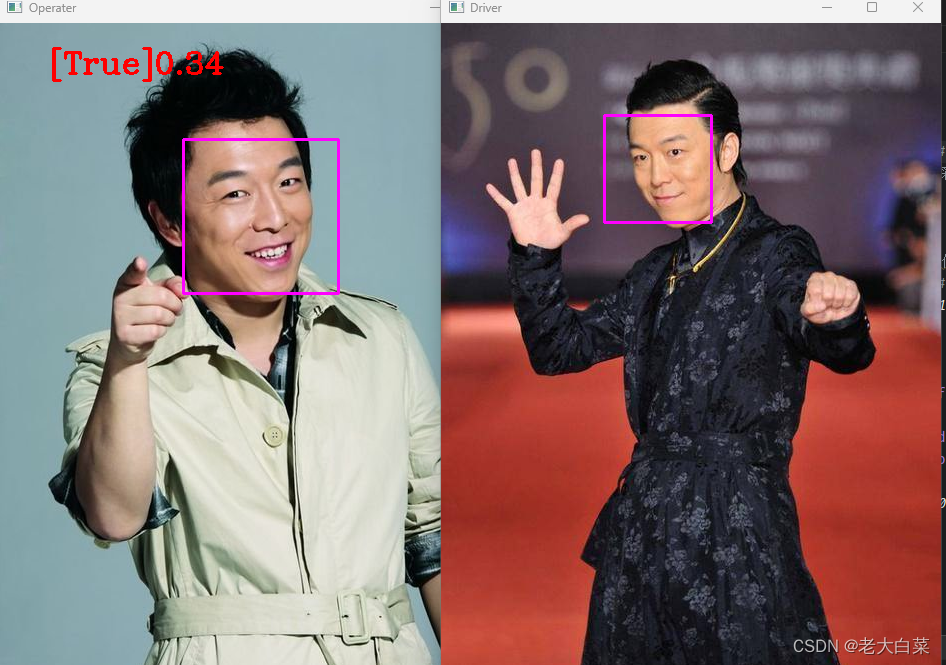
python 通过opencv及face_recognition识别人脸
效果: 使用Python的cv2库和face_recognition库来进行人脸检测和比对的 0是代表一样 认为是同一人。 代码: pip install opencv-python pip install face_recognition# 导入cv2库,用于图像处理 import cv2 # 导入face_recognition库&#…...

Android开发中常见的Hook技术有哪些?
Hook技术介绍 Hook技术是一种在软件开发中常见的技术,它允许开发者在特定的事件发生时插入自定义的代码逻辑。常见的应用场景包括在函数调用前后执行特定的操作,或者在特定的事件发生时触发自定义的处理逻辑。 在Android开发中,Hook通常是通…...

【linux c多线程】线程的创建,线程信息的获取,获取线程返回值
线程创建 专栏内容: 参天引擎内核架构 本专栏一起来聊聊参天引擎内核架构,以及如何实现多机的数据库节点的多读多写,与传统主备,MPP的区别,技术难点的分析,数据元数据同步,多主节点的情况下对…...

MFC或QT中,自绘控件的目的和实现步骤
MFC自绘控件的步骤 自绘控件的目的是为了能够自定义控件的外观、行为和交互方式,以满足特定的需求,同时增强应用程序的用户体验。 实现步骤如下: 1、创建一个继承自MFC控件基类(如CButton、CStatic等)的自定义控件类…...
)
ceph集群搭建详细教程(ceph-deploy)
ceph-deploy比较适合生产环境,不是用cephadm搭建。相对麻烦一些,但是并不难,细节把握好就行,只是命令多一些而已。 实验环境 服务器主机public网段IP(对外服务)cluster网段IP(集群通信&#x…...
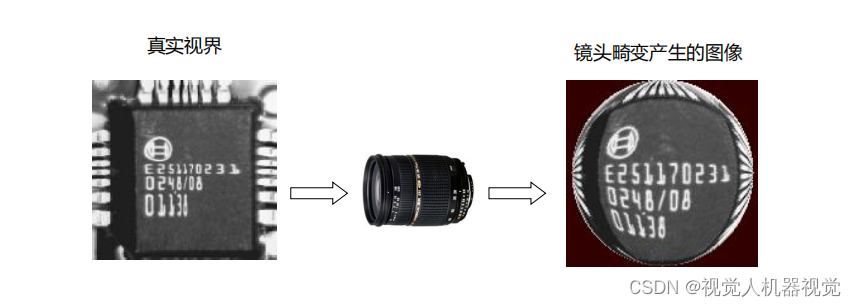
机器视觉系统选型-避免畸变
在定位及高精度测量的系统中,镜头畸变的影响尤其重要 • 使用远心镜头 • 进行系统标定...
的原理和应用)
机器学习笔记 - 线性判别分析(LDA)的原理和应用
一、LDA简述 线性判别分析(LDA)是监督机器学习中用于解决多类分类问题的一种方法。LDA通过数据降维来分离具有多个特征的多个类。这项技术在数据科学中很重要,因为它有助于优化机器学习模型。 线性判别分析,也称为正态判别分析 (NDA) 或判别函数分析 (DFA),遵循生成模型框…...
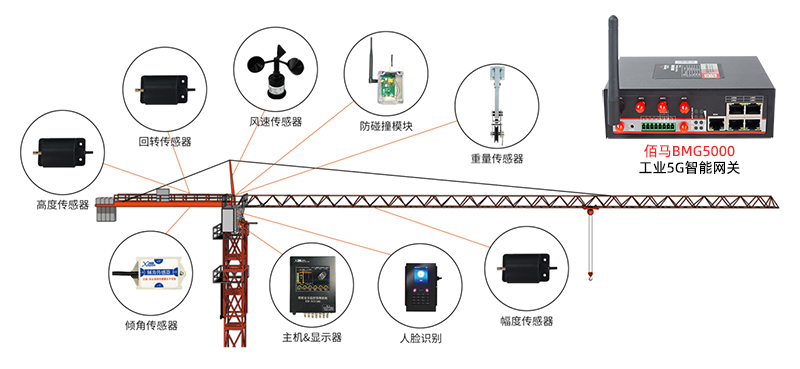
基于5G智能网关的智慧塔吊监测方案
塔吊是建筑施工中必不可少的设施,由于塔吊工作重心高、起重载荷大、人工视距/视角受限等因素,也使得塔吊在工作过程中着较多的危险因素。对此,可以部署基于工业5G智能网关搭建智慧塔吊安全监测系统,实现对塔吊运行的全局精细监测感…...

CountDownLatch详解以及用法示例
一、什么是CountDownLatch CountDownLatch中count down是倒数的意思,latch则是门闩的含义。整体含义可以理解为倒数的门栓。 CountDownLatch的作用也是如此,在构造CountDownLatch(int count):的时候需要传入一个整数count,在这个…...

Ketcher:三步掌握开源化学绘图工具的完整使用指南
Ketcher:三步掌握开源化学绘图工具的完整使用指南 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher 你是否曾因绘制复杂分子结构而烦恼?传统化学绘图软件要么操作复杂,要么…...

Taotoken CLI工具安装与一键配置全模型环境指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken CLI工具安装与一键配置全模型环境指南 对于需要接入多个大模型服务的开发团队而言,统一管理API密钥、模型配置…...

ROS小车转弯卡顿?手把手教你用Python搞定cmd_vel到阿克曼模型的平滑转换
ROS小车转弯卡顿?Python实现cmd_vel到阿克曼模型的平滑转换实战 当你在Gazebo仿真或实际运行ROS控制的阿克曼转向小车时,是否遇到过车体转弯时"一耸一耸"、运动不连贯的尴尬情况?这种卡顿现象往往源于cmd_vel指令到阿克曼运动模型转…...

告别手动PPT制作:用JavaScript实现自动化演示文稿生成
告别手动PPT制作:用JavaScript实现自动化演示文稿生成 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 还在为每周重…...

基于语义检索的LLM工具发现框架:从原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想把手头的几个大语言模型(LLM)能力整合到自己的工具链里,发现一个挺头疼的问题:模型本身很强大,但让它去精准调用外部工具(比如查数据库、发…...

无显式ID推荐系统:从冷启动到跨域泛化的核心技术解析
1. 项目概述:当推荐系统“看不见”用户与物品在推荐系统这个领域里干了十几年,我见过太多模型把“用户ID”和“物品ID”当作理所当然的输入。这就像我们认识一个人,首先记住的是他的名字和长相。传统的协同过滤(Collaborative Fil…...

通过 Python 快速将现有应用接入 Taotoken 的多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 Python 快速将现有应用接入 Taotoken 的多模型服务 如果你正在使用 OpenAI 官方的 Python SDK 开发应用,并且希望…...

告别裸机轮询:在STM32F103上为AHT20温湿度采集加入FreeRTOS实时任务管理
从裸机轮询到RTOS任务管理:STM32F103与AHT20温湿度传感器的架构升级实战 在嵌入式开发领域,如何从简单的功能实现进阶到健壮的软件架构设计,是每个开发者必须面对的挑战。本文将带你完成一次典型的架构升级——将基于STM32F103的AHT20温湿度传…...

open62541批量读写踩坑实录:从‘UA_ReadRequest’配置到结果解析的完整避坑指南
open62541批量读写深度实战:从核心配置到异常处理的完整解决方案 在工业自动化与物联网系统开发中,OPC UA协议已成为设备互联的事实标准。作为开源实现的佼佼者,open62541为开发者提供了强大而灵活的工具集。但当面对需要高效处理大量节点数据…...

别再只盯着动态功耗了!聊聊CMOS数字电路里那个容易被忽略的‘小透明’——静态功耗
别再只盯着动态功耗了!聊聊CMOS数字电路里那个容易被忽略的‘小透明’——静态功耗 在数字电路设计的课堂上,我们总是反复强调动态功耗的计算与优化——开关电容充放电、时钟门控、频率缩放,这些概念几乎成了低功耗设计的代名词。但当你真正打…...