深入剖析LinkedList:揭秘底层原理

文章目录
- 一、 概述LinkedList
- 1.1 LinkedList简介
- 1.2 LinkedList的优点和缺点
- 二、 LinkedList数据结构分析
- 2.1 Node节点结构体解析
- 2.2 LinkedList实现了双向链表的原因
- 2.3 LinkedList如何实现了链表的基本操作(增删改查)
- 2.4 LinkedList的遍历方式
- 三、 源码分析
- 3.1 成员变量
- 3.2 构造方法
- 3.3 add()方法
- 3.4 remove()方法
- 3.5 get()方法
- 3.6 set()方法
- 3.7 clear()方法
- 3.8 indexOf()方法
- 四、 总结及实战应用
- 4.1 LinkedList适用场景
- 4.2 LinkedList与ArrayList的比较
- 4.3 LinkedList的使用注意事项
- 4.4 实战应用:设计一个基于LinkedList的LRU缓存算法
一、 概述LinkedList
1.1 LinkedList简介
LinkedList是Java中的一种双向链表数据结构实现类,它实现了List和Deque接口。
LinkedList的特点主要包括以下几点:
- 链表结构:LinkedList内部使用链表来存储元素,每个节点都包含当前元素的值以及指向前一个节点和后一个节点的引用。这种链表结构使得插入和删除元素的操作效率较高。
- 双向访问:每个节点都有指向前一个节点和后一个节点的引用,这使得在LinkedList中可以通过前向或后向遍历访问元素,而不需要像ArrayList那样进行元素的整体移动。
- 动态大小:LinkedList没有固定的容量限制,可以根据需要动态地添加或删除元素,并且不会出现数组扩容的情况。
- 随机访问较慢:由于LinkedList是基于链表的数据结构,因此在访问特定索引位置的元素时,需要从头或尾部开始遍历到目标位置。相比之下,ArrayList可以通过索引直接访问元素,因此在随机访问元素时效率更高。
- 支持队列和栈操作:作为
Deque接口的实现类,LinkedList可以被用作队列(先进先出)和栈(后进先出)的数据结构,可以使用addFirst、removeFirst等方法模拟栈操作,使用addLast、removeFirst等方法模拟队列操作。
总体而言,LinkedList适用于频繁地插入和删除元素的场景,但对于随机访问元素的需求不是很高时,可以考虑使用它。
1.2 LinkedList的优点和缺点
优点:
- 链表的插入和删除操作比较快速,因为只需要改变指针指向即可。
- 可以在任意位置进行插入和删除操作,而不需要像数组那样需要移动其他元素。
- 在迭代时可以快速获取下一个元素,因为每个节点都有指向前后节点的指针。
缺点:
- 链表的访问操作比较慢,因为需要遍历整个链表才能找到对应的元素。
- 由于链表每个节点都需要额外存储前后节点的指针,因此占用的内存空间比数组大。
- 链表没有像数组那样可以直接访问任意位置的元素,因此不能使用索引随机访问元素。
- 当需要频繁进行随机访问时,由于缺乏连续的内存空间,可能会导致缓存命中率降低,从而影响性能。
综上所述,LinkedList 适合在需要频繁进行插入和删除操作,但是不需要频繁随机访问元素的场景下使用。如果需要随机访问或者占用空间比较重要时,可以考虑使用其他数据结构,比如 ArrayList。
二、 LinkedList数据结构分析
2.1 Node节点结构体解析
在Java中,LinkedList的实现是通过一个双向链表来实现的。在LinkedList中,每个节点都有一个指向前一个节点和一个指向后一个节点的引用。
在LinkedList中,Node节点结构体可以被定义如下:
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(E element, Node<E> next, Node<E> prev) {this.item = element;this.next = next;this.prev = prev;}
}
上面的代码定义了一个私有静态内部类Node,该类包含了一个泛型元素item,以及两个Node类型的引用next和prev,分别表示指向下一个节点和上一个节点的引用。此外,Node类还有一个带有三个参数的构造函数,用于初始化节点的prev、item和next属性。
通过这样的设计,LinkedList可以通过Node节点来构建双向链表结构,实现了在任意位置进行节点的插入和删除操作。
2.2 LinkedList实现了双向链表的原因
Java中的LinkedList实现了双向链表是因为双向链表具有以下优点:
- 双向链表可以从前向后或从后向前遍历,而单向链表只能从前往后遍历,这使得双向链表更加灵活和高效。
- 双向链表能够提供
O(1)时间复杂度的前驱和后继节点访问操作,而单向链表则需要O(n)时间复杂度的遍历操作才能找到前驱节点。 - 双向链表相对于单向链表来说,其插入和删除节点的操作更加高效,因为只需要改变前后节点的指针指向即可,而单向链表需要先找到前驱节点再进行操作。
因此,双向链表在实现一些需要频繁插入和删除操作的场景下,比单向链表更加适用。Java中的LinkedList就是基于双向链表实现的,所以它能够高效地支持插入、删除等操作,同时也提供了迭代器和列表迭代器等许多方便的操作。
2.3 LinkedList如何实现了链表的基本操作(增删改查)
在Java中,LinkedList类实现了链表的基本操作,包括增加(添加)、删除、修改和查询等功能。下面是一些常用的方法:
- 添加操作:
- addFirst(E e):在链表的开头添加元素。
- addLast(E e):在链表的末尾添加元素。
- add(int index, E element):在指定位置插入元素。
- 删除操作:
- removeFirst():删除链表的第一个元素。
- removeLast():删除链表的最后一个元素。
- remove(int index):删除指定位置的元素。
- remove(Object o):删除指定元素。
- 修改操作:
- set(int index, E element):将指定位置的元素替换为新的元素。
- 查询操作:
- getFirst():返回链表的第一个元素。
- getLast():返回链表的最后一个元素。
- get(int index):返回指定位置的元素。
- indexOf(Object o):返回指定元素在链表中的索引位置。
- contains(Object o):判断链表是否包含指定元素。
LinkedList类还提供了其他一些方法用于获取链表的大小、清空链表、判断链表是否为空等。
2.4 LinkedList的遍历方式
在Java中,你可以使用以下几种方式对LinkedList进行遍历:
1.使用迭代器(Iterator)进行遍历:
LinkedList<String> linkedList = new LinkedList<>();
// 假设已经向linkedList中添加了元素
Iterator<String> iterator = linkedList.iterator();
while (iterator.hasNext()) {String element = iterator.next();// 对element进行处理
}
2.使用增强型for循环(foreach)进行遍历:
LinkedList<String> linkedList = new LinkedList<>();
// 假设已经向linkedList中添加了元素
for (String element : linkedList) {// 对element进行处理
}
这两种方式都可以用来遍历LinkedList中的元素,你可以根据实际情况选择其中一种来进行遍历操作。
三、 源码分析
3.1 成员变量

3.2 构造方法
/*** 默认构造函数,它不带任何参数,用来创建一个空的 LinkedList 对象*/
public LinkedList() {
}/*** 带有参数的构造函数,它接受一个类型为 Collection 的参数 c*/
public LinkedList(Collection<? extends E> c) {// 调用无参构造函数this();// 将参数 c 中的所有元素添加到新创建的 LinkedList 对象中addAll(c);
}/*** LinkedList 类中的 addAll 方法的定义*/
public boolean addAll(Collection<? extends E> c) {// size表示为当前 LinkedList 中的元素数量// 调用另一个名为 addAll 的方法来将参数 c 中的所有元素添加到 LinkedList 对象中return addAll(size, c);
}/*** 用于将指定集合中的元素插入到指定位置*/
public boolean addAll(int index, Collection<? extends E> c) {// 检查索引的有效性,确保索引在范围内checkPositionIndex(index);// 将集合 c 转换为数组,并将其赋值给对象数组 aObject[] a = c.toArray();// 获取新添加元素的数量int numNew = a.length;// 如果新添加元素的数量为 0,则直接返回 falseif (numNew == 0)return false;// 定义两个节点,pred 表示当前节点的前一个节点,succ 表示当前节点的后一个节点LinkedList.Node<E> pred, succ;// 根据插入位置确定 succ 和 pred 的值// 如果插入位置在末尾,则将 succ 设置为 null,将 pred 设置为最后一个节点if (index == size) {succ = null;pred = last;} else {// 否则,通过 node(index) 方法找到指定位置的节点,并将其设置为 succ,同时将其前一个节点设置为 predsucc = node(index);pred = succ.prev;}// 遍历数组 a 中的元素for (Object o : a) {@SuppressWarnings("unchecked") E e = (E) o;// 将每个元素转换为泛型类型 E,并创建一个新的节点 newNode,该节点的前一个节点为 pred,值为 e,后一个节点为 nullLinkedList.Node<E> newNode = new LinkedList.Node<>(pred, e, null);// 如果 pred 为 null,则将 newNode 设置为链表的第一个节点if (pred == null)first = newNode;else// 否则,将 pred 的下一个节点设置为 newNodepred.next = newNode;// 将 pred 更新为 newNodepred = newNode;}// 根据 succ 是否为 null 来确定插入后的链表结构// 如果 succ 为 null,则表示插入位置在末尾,将 pred 设置为最后一个节点if (succ == null) {last = pred;} else {// 否则,将 pred 的下一个节点设置为 succ,并将 succ 的前一个节点设置为 predpred.next = succ;succ.prev = pred;}// 更新链表的大小和修改计数器size += numNew;modCount++;// 返回 true,表示添加操作成功完成return true;
}
3.3 add()方法
/*** 用于向链表末尾添加一个元素 e*/
public boolean add(E e) {// 将元素 e 添加到链表的末尾linkLast(e);// 添加操作成功return true;
}/*** 向链表末尾添加一个元素的操作*/
void linkLast(E e) {// 创建一个名为 l 的局部变量,用于保存当前链表的最后一个节点的引用,通过访问 last 字段获取最后一个节点的引用final LinkedList.Node<E> l = last;// 创建一个新的节点 newNode,并将其初始化为一个具有前驱节点为 l、元素为 e、后继节点为 null 的节点final LinkedList.Node<E> newNode = new LinkedList.Node<>(l, e, null);// 将链表的 last 指针指向新的节点 newNode,使其成为最后一个节点last = newNode;// 如果 l 为空(即链表为空),则将链表的 first 指针指向新的节点 newNode,否则将 l 节点的后继节点指向新的节点 newNodeif (l == null)first = newNode;elsel.next = newNode;// 增加链表的大小,将链表中元素的数量加1size++;// 增加修改计数器 modCount 的值,用于追踪链表结构的修改次数modCount++;
}
3.4 remove()方法
/*** 用于从 LinkedList 中删除指定的元素*/
public boolean remove(Object o) {// 判断传入的参数 o 是否为 null// 如果 o 为 null,则说明要删除的元素是 null 值if (o == null) {// 因此需要遍历 LinkedList 中的所有节点并查找 item 属性为 null 的节点// 循环体中的变量 x 表示当前正在遍历的节点,初始化为 first(即头节点),在每次迭代后更新为下一个节点,直到遍历完整个 LinkedListfor (LinkedList.Node<E> x = first; x != null; x = x.next) {// 如果当前节点的 item 属性为 null(在 o 为 null 的情况下),则调用辅助方法 unlink 删除该节点并返回 trueif (x.item == null) {unlink(x);return true;}}} else {// 否则需要遍历所有节点并查找 item 属性等于 o 的节点for (LinkedList.Node<E> x = first; x != null; x = x.next) {// 如果当前节点的 item 属性等于 o(在 o 不为 null 的情况下),则调用辅助方法 unlink 删除该节点并返回 trueif (o.equals(x.item)) {unlink(x);return true;}}}return false;
}/*** 这是一个辅助方法,用于删除指定节点 x*/
E unlink(LinkedList.Node<E> x) {// assert x != null;// 保存被删除节点的元素值final E element = x.item;// 存储被删除节点的前驱和后继节点final LinkedList.Node<E> next = x.next;final LinkedList.Node<E> prev = x.prev;// 如果被删除节点是头节点,则将头指针指向其后继节点if (prev == null) {first = next;} else {// 否则更新被删除节点的前驱节点的 next 属性为其后继节点,并将被删除节点的 prev 属性设为 nullprev.next = next;x.prev = null;}// 如果被删除节点是尾节点,则将尾指针指向其前驱节点if (next == null) {last = prev;} else {// 否则更新被删除节点的后继节点的 prev 属性为其前驱节点,并将被删除节点的 next 属性设为 nullnext.prev = prev;x.next = null;}// 将被删除节点的 item 属性设为 nullx.item = null;// 更新 LinkedList 的元素数量和修改次数size--;modCount++;// 返回被删除节点的元素值return element;
}
3.5 get()方法
/*** 用于获取指定索引处的元素*/
public E get(int index) {// 检查索引的有效性,然后调用另一个私有辅助方法 node 来获取对应索引处的节点checkElementIndex(index);// 返回该节点的元素值return node(index).item;
}/*** 检查指定索引是否在有效范围内*/
private void checkElementIndex(int index) {// 调用 isElementIndex 方法来判断索引是否在有效范围内if (!isElementIndex(index))// 如果不在,则抛出 IndexOutOfBoundsException 异常,异常消息由 outOfBoundsMsg 方法返回throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}/*** 判断指定索引是否在有效范围内*/
private boolean isElementIndex(int index) {// 如果索引大于等于 0 并且小于 size,则返回 true;否则返回 falsereturn index >= 0 && index < size;
}
3.6 set()方法
/*** 用于将指定索引(index)位置的元素替换为新的元素,并返回被替换掉的旧元素*/
public E set(int index, E element) {// 用于将指定索引(index)位置的元素替换为新的元素,并返回被替换掉的旧元素checkElementIndex(index);// 获取指定索引位置上的节点LinkedList.Node<E> x = node(index);// 将指定索引位置上的节点的元素值赋给变量 oldVal,即记录旧元素的值E oldVal = x.item;// 将指定索引位置上的节点的元素值替换为新的元素值 elementx.item = element;// 返回被替换掉的旧元素值return oldVal;
}/*** 检查指定索引是否在有效范围内*/
private void checkElementIndex(int index) {// 调用 isElementIndex 方法来判断索引是否在有效范围内if (!isElementIndex(index))// 如果不在,则抛出 IndexOutOfBoundsException 异常,异常消息由 outOfBoundsMsg 方法返回throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}/*** 判断指定索引是否在有效范围内*/
private boolean isElementIndex(int index) {// 如果索引大于等于 0 并且小于 size,则返回 true;否则返回 falsereturn index >= 0 && index < size;
}
3.7 clear()方法
/*** 用于清空整个链表的内容,并释放相关的内存空间*/
public void clear() {// Clearing all of the links between nodes is "unnecessary", but:// 解释了清除所有节点之间链接的操作虽然“不必要”,但有两个原因:// - helps a generational GC if the discarded nodes inhabit// 帮助分代垃圾回收(generational GC)// more than one generation// - is sure to free memory even if there is a reachable Iterator// 和确保释放内存即使存在可达的迭代器// 循环体中的变量 x 初始化为头节点 first,然后在每次迭代中更新为下一个节点,直到遍历完整个链表for (LinkedList.Node<E> x = first; x != null; ) {// 用于保存当前节点 x 的后继节点的引用,以防止在清空当前节点之后丢失对后继节点的引用LinkedList.Node<E> next = x.next;// 将当前节点 x 的元素值、前驱节点和后继节点都设置为 null,从而切断当前节点与前后节点的关联x.item = null;x.next = null;x.prev = null;// 将 x 更新为下一个节点,以便进行下一次循环迭代x = next;}// 清空头节点和尾节点的引用,使整个链表为空first = last = null;// 将链表的大小设置为 0,表示链表中不再包含任何元素size = 0;// 更新修改次数计数器,用于在迭代过程中检测并发修改modCount++;
}3.8 indexOf()方法
/*** 用于查找指定元素在链表中第一次出现的位置(索引)*/
public int indexOf(Object o) {// 初始化索引变量为 0,表示从头节点开始查找int index = 0;// 如果要查找的元素 o 是 null,则执行下面的 for 循环,按顺序遍历链表,查找第一个元素值为 null 的节点if (o == null) {// 变量 x 初始化为头节点 first,然后在每次迭代中更新为下一个节点,直到遍历完整个链表for (LinkedList.Node<E> x = first; x != null; x = x.next) {// 判断当前节点 x 的元素值是否为 null,如果是,则说明找到了要查找的元素,返回当前索引 index 表示该元素在链表中的位置if (x.item == null)return index;// 如果当前节点不是要查找的元素,则将索引变量 index 加 1,继续向下查找index++;}} else {// 如果要查找的元素 o 不是 null,则执行下面的 for 循环,按顺序遍历链表,查找第一个元素值与 o 相等的节点for (LinkedList.Node<E> x = first; x != null; x = x.next) {// 判断当前节点 x 的元素值是否与要查找的元素 o 相等,如果是,则说明找到了要查找的元素,返回当前索引 index 表示该元素在链表中的位置if (o.equals(x.item))return index;// 如果当前节点不是要查找的元素,则将索引变量 index 加 1,继续向下查找index++;}}// 如果整个链表都遍历完了还没有找到要查找的元素,则返回 -1,表示该元素不存在于链表中return -1;
}四、 总结及实战应用
4.1 LinkedList适用场景
LinkedList在Java中适用于以下场景:
- 需要频繁进行插入和删除操作:由于LinkedList是基于链表结构实现的,插入和删除操作的时间复杂度为
O(1),因此适合在需要频繁执行这些操作的场景下使用。 - 需要实现队列(Queue)或双端队列(Deque)功能:LinkedList实现了
Queue和Deque接口,可以作为队列或双端队列来使用。 - 不需要频繁进行随机访问:由于LinkedList对于随机访问的效率较低,如果不需要频繁通过索引来访问元素,而是更多地进行顺序访问或者在头尾进行操作,那么LinkedList比较适合。
- 对内存占用没有过高要求:相比于ArrayList,在一些情况下,由于它的存储结构,LinkedList可能会占用更多的内存空间。
需要注意的是,在某些特定的场景下,可能需要根据具体的需求进行性能测试和选择,以确定使用LinkedList是否能够带来性能上的提升。
4.2 LinkedList与ArrayList的比较
LinkedList和ArrayList是Java中两种常见的集合实现类,它们具有一些不同的特点和适用场景。
LinkedList的特点:
- 基于双向链表实现,每个节点都包含指向前一个节点和后一个节点的引用。
- 高效地支持插入和删除操作,因为只需要改变前后节点的指针指向即可。
- 在使用迭代器进行遍历时,效率较高。
- 对于频繁的插入和删除操作,LinkedList通常比ArrayList更加高效。
ArrayList的特点:
- 基于动态数组实现,内部使用数组来存储元素。
- 支持随机访问,通过索引可以快速访问元素。
- 在获取元素和遍历操作方面,ArrayList相对更高效。
- 对于需要频繁随机访问元素的操作,ArrayList通常比LinkedList更加高效。
综上所述,选择LinkedList还是ArrayList取决于具体的使用场景和需求:
- 如果需要频繁进行插入和删除操作,而对于随机访问的需求较少,则选择LinkedList更合适。
- 如果需要频繁进行随机访问,插入和删除操作相对较少,则选择ArrayList更合适。
需要注意的是,在多线程环境下,LinkedList和ArrayList都不是线程安全的,如果需要在多线程环境下使用,需要进行适当的同步处理或使用线程安全的集合类。
4.3 LinkedList的使用注意事项
在使用 Java 中的 LinkedList 时,有一些需要注意的事项,包括但不限于以下几点:
- 插入和删除效率高:LinkedList 在插入和删除操作上有较高的效率,因为它基于双向链表实现。因此,在需要频繁进行插入和删除操作的场景下,可以考虑使用 LinkedList。
- 随机访问效率低:相比于 ArrayList,LinkedList 对于随机访问的效率较低,因为要通过指针一个个地找到目标位置。因此,在需要频繁进行随机访问的场景下,最好选择 ArrayList。
- 迭代器遍历高效:LinkedList 的迭代器遍历效率较高,可以高效地进行前向和后向遍历操作。
- 注意空间开销:由于 LinkedList 中每个节点都需要存储额外的指针信息,因此相比于 ArrayList,它在存储同样数量的元素时会占用更多的内存空间。
- 不是线程安全的:LinkedList 不是线程安全的,如果需要在多线程环境中使用,需要进行适当的同步处理或考虑使用线程安全的集合类。
- 谨慎使用大数据量:在处理大数据量的情况下,由于 LinkedList 涉及频繁的节点创建和指针操作,可能会导致性能下降,需要谨慎使用。
综上所述,使用 LinkedList 时需要根据具体的场景和需求进行权衡,特别是在涉及到插入、删除、遍历和空间占用等方面需要特别留意。
4.4 实战应用:设计一个基于LinkedList的LRU缓存算法
LRU(Least Recently Used)算法是一种缓存置换策略,它根据数据最近被访问的时间来决定哪些数据会被保留,哪些数据会被淘汰。在 Java 中,可以通过 LinkedList 和 HashMap 来实现 LRU 缓存算法。
具体实现步骤如下:
1.定义一个双向链表和一个哈希表,用于存储缓存数据和快速定位数据。
private class CacheNode {private String key;private Object value;private CacheNode prev;private CacheNode next;public CacheNode(String key, Object value) {this.key = key;this.value = value;}
}private Map<String, CacheNode> cacheMap;
private CacheNode head;
private CacheNode tail;
private int capacity;2.在构造函数中初始化双向链表和哈希表,并设置缓存容量。
public LRUCache(int capacity) {this.capacity = capacity;cacheMap = new HashMap<>(capacity);head = new CacheNode(null, null);tail = new CacheNode(null, null);head.next = tail;tail.prev = head;
}3.实现 get 方法,每次获取数据时,将数据移到链表头部,并更新哈希表中的位置信息。
public Object get(String key) {CacheNode node = cacheMap.get(key);if (node == null) {return null;}// 将节点移动到链表头部moveToHead(node);return node.value;
}private void moveToHead(CacheNode node) {// 先将节点从原有位置删除removeNode(node);// 将节点插入到链表头部insertNodeAtHead(node);
}private void removeNode(CacheNode node) {node.prev.next = node.next;node.next.prev = node.prev;
}private void insertNodeAtHead(CacheNode node) {node.next = head.next;node.next.prev = node;head.next = node;node.prev = head;
}4.实现 put 方法,每次存储数据时,如果缓存已满,则淘汰链表尾部的数据,并在哈希表中删除相应的位置信息。
public void put(String key, Object value) {CacheNode node = cacheMap.get(key);if (node != null) {// 如果键已经存在,则更新值,并移到链表头部node.value = value;moveToHead(node);} else {// 如果键不存在,则插入新节点到链表头部,并添加位置信息到哈希表node = new CacheNode(key, value);cacheMap.put(key, node);insertNodeAtHead(node);if (cacheMap.size() > capacity) {// 如果缓存已满,则淘汰链表尾部的节点,并删除相应位置信息CacheNode removedNode = removeNodeAtTail();cacheMap.remove(removedNode.key);}}
}private CacheNode removeNodeAtTail() {CacheNode removedNode = tail.prev;removeNode(removedNode);return removedNode;
}这样,一个基于 LinkedList 的 LRU 缓存算法就实现了。
可以通过如下代码进行简单的测试:
LRUCache cache = new LRUCache(2);
cache.put("A", 1);
cache.put("B", 2);
System.out.println(cache.get("A")); // 输出 1
cache.put("C", 3);
System.out.println(cache.get("B")); // 输出 null盈若安好,便是晴天
相关文章:
深入剖析LinkedList:揭秘底层原理
文章目录 一、 概述LinkedList1.1 LinkedList简介1.2 LinkedList的优点和缺点 二、 LinkedList数据结构分析2.1 Node节点结构体解析2.2 LinkedList实现了双向链表的原因2.3 LinkedList如何实现了链表的基本操作(增删改查)2.4 LinkedList的遍历方式 三、 …...

计算机网络复习-OSI TCP/IP 物理层
我膨胀了,挂我啊~ 作者简介: 每年都吐槽吉师网安奇怪的课程安排、全校正经学网络安全不超20人情景以及割韭菜企业合作的FW,今年是第一年。。 TCP/IP模型 先做两道题: TCP/IP协议模型由高层到低层分为哪几层: 这题…...

虚拟机服务器中了lockbit2.0/3.0勒索病毒怎么处理,数据恢复应对步骤
网络技术的不断发展也为网络威胁带来了安全隐患,近期,对于许多大型企业来说,许多企业的虚拟机服务器系统遭到了lockbit2.0/3.0勒索病毒攻击,导致企业所有计算机系统瘫痪,无法正常工作,严重影响了企业的正常…...

【MATLAB】 RGB和YCbCr互转
前言 在视频、图像处理领域经常会遇到不同色域图像的转换,比如RGB、YUV、YCbCr色域间的转换,这里提供一组转换公式,供大家参考。 色彩模型 RGB RGB色彩模型是一种用于表示数字图像的颜色空间,其中"RGB"代表红色&…...

【线性代数】决定张成空间的最少向量线性无关吗?
答1: 是的,张成空间的最少向量是线性无关的。 在数学中,张成空间(span space)是一个向量空间,它由一组向量通过线性组合(即每个向量乘以一个标量)生成。如果这组向量是线性无关的&…...
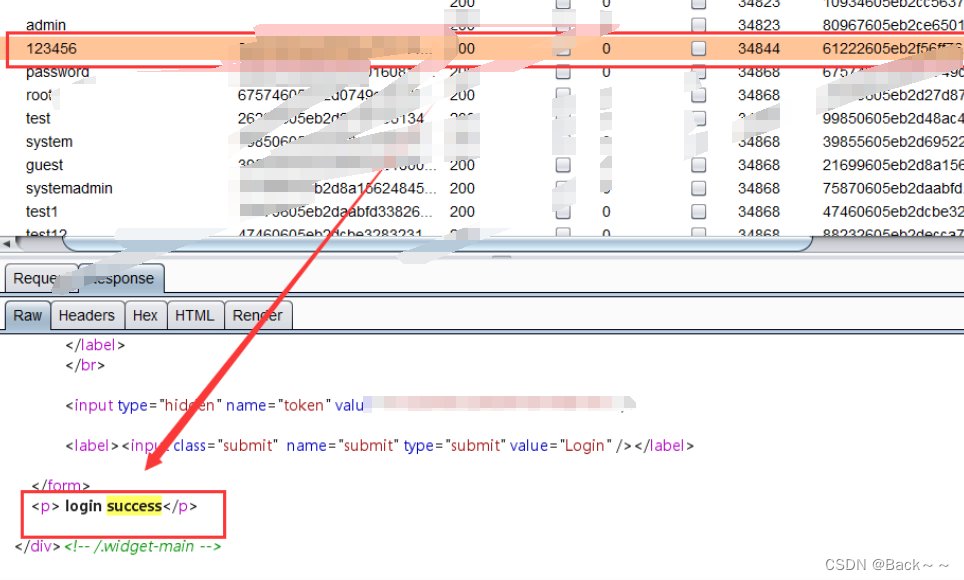
暴力破解(Pikachu)
基于表单的暴力破解 先随便输入一下,然后抓包,进行字典爆破 验证码绕过(on server) server服务端要输入正确的验证码后进行爆破 之后的操作没什么不一样 验证码绕过(on client) 这个也需要输入验证码,但是后面进行字典爆破的时候…...

如何使用CMake查看opencv封装好的函数
当我们有时想查看opencv自带的函数的源代码,比如函数cvCreateImage, 此时我们选中cvCreateImage, 点击鼠标右键->转到定义,我们会很惊讶的发现为什么只看到了cvCreateImage的一个简单声明,而没有源代码呢?这是因为openCV将很多…...

微盛·企微管家:用户运营API集成,电商无代码解决方案
连接电商平台的新纪元:微盛企微管家 随着电子商务的蓬勃发展,电商平台的高效运营已经成为企业成功的关键。在这个新纪元里,微盛企微管家以其创新的无代码开发连接方案,成为企业之间连接电商平台的强大工具。它允许企业轻松集成电…...
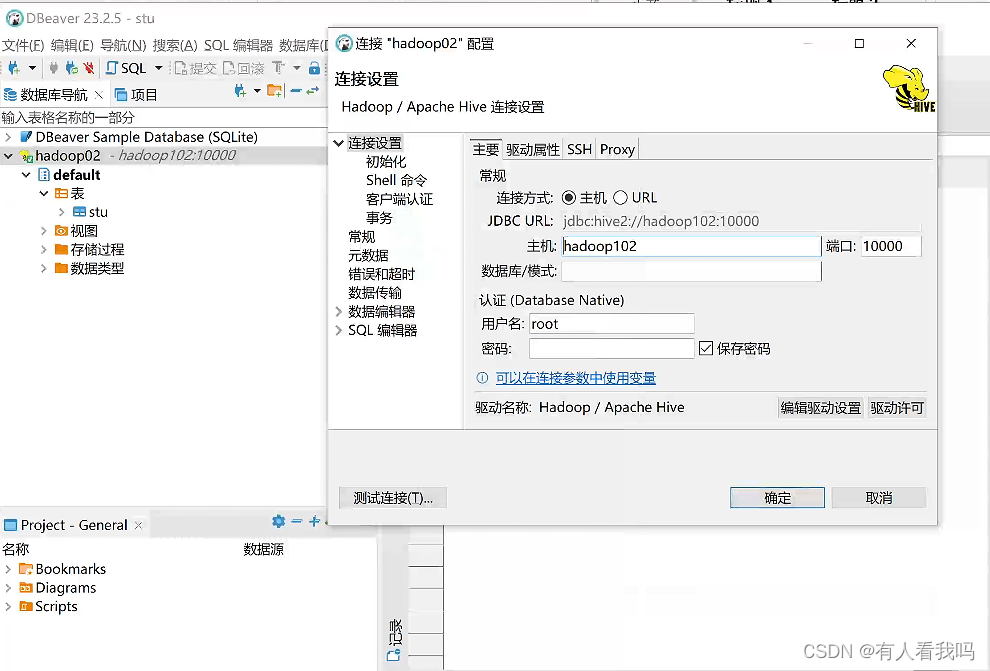
Hive 部署
一、介绍 Apache Hive是一个分布式、容错的数据仓库系统,支持大规模的分析。Hive Metastore(HMS)提供了一个中央元数据存储库,可以轻松地进行分析,以做出明智的数据驱动决策,因此它是许多数据湖架构的关键组…...

CopyOnWriteArrayList源码阅读
1、构造方法 无参构造函数 //创建一个空数组,赋值给array引用 public CopyOnWriteArrayList() {setArray(new Object[0]); }//仅通过getArray / setArray访问的数组。 private transient volatile Object[] array;//设置数组 final void setArray(Object[] a) {arra…...

Windows操作系统:共享文件夹,防火墙的设置
1.共享文件夹 1.1 共享文件夹的优点 1.2 共享文件夹的优缺点 1.3 实例操作 编辑 2.防火墙设置 2.1 8080端口设置 3.思维导图 1.共享文件夹 1.1 共享文件夹的优点 优点 协作和团队合作:共享文件夹使多个用户能够在同一文件夹中协作和编辑文件。这促进了团…...
STM32独立看门狗
时钟频率 40KHZ 看门狗简介 STM32F10xxx 内置两个看门狗,提供了更高的安全性、时间的精确性和使用的灵活性。两个看 门狗设备 ( 独立看门狗和窗口看门狗 ) 可用来检测和解决由软件错误引起的故障;当计数器达到给 定的超时值时,触发一个中…...

财务数据智能化:用AI工具高效制作财务分析PPT报告
Step1: 文章内容提取 WPS AI 直接打开文件,在AI对话框里输入下面指令: 假设你是财务总监,公司考虑与茅台进行业务合作、投资或收购,请整合下面茅台2021年和2022年的财务报告信息。整理有关茅台财务状况和潜在投资回报的信息&…...

vue3中使用three.js记录
记录一下three.js配合vitevue3的使用。 安装three.js 使用npm安装: npm install --save three开始使用 1.定义一个div <template><div ref"threeContainer" class"w-full h-full"></div> </template>可以给这个di…...
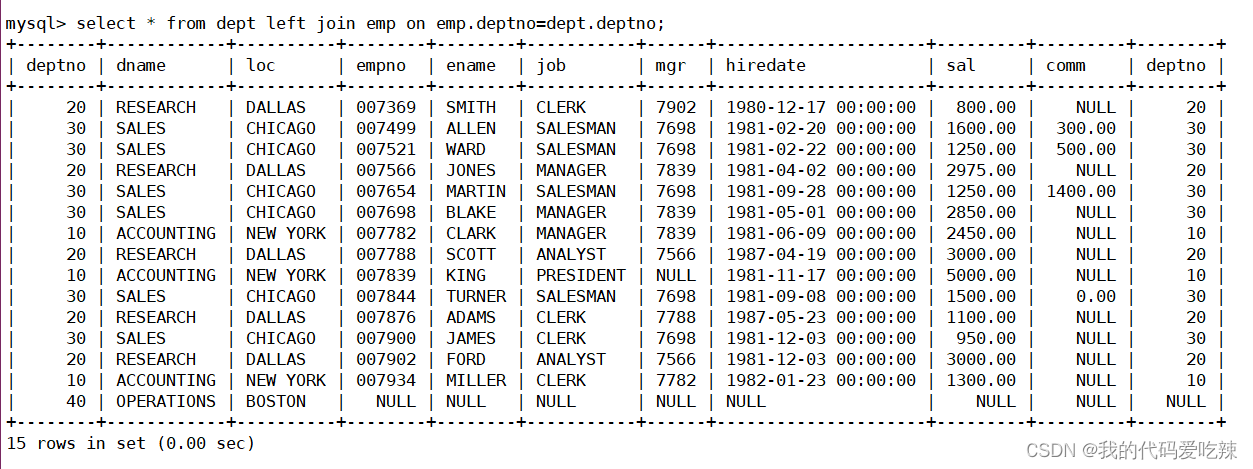
MySQL——表的内外连接
目录 一.内连接 二.外连接 1.左外连接 2.右外连接 一.内连接 表的连接分为内连和外连 内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,我们前面学习的查询都是内连接,也是在开发过程中使用的最多的连接查询。 语法: s…...

基于IPP-FFT的线性调频Z(Chirp-Z,CZT)的C++类库封装并导出为dll(固定接口支持更新)
上一篇分析了三种不同导出C++类方法的优缺点,同时也讲了如何基于IPP库将FFT函数封装为C++类库,并导出为支持更新的dll库供他人调用。 在此基础上,结合前面的CZT的原理及代码实现,可以很容易将CZT变换也封装为C++类库并导出为dll,关于CZT的原理和实现,如有问题请参考: …...

【C语言】指针
基本概念 在C语言中,指针是一种非常重要的数据类型,它用于存储变量的内存地址。指针提供了对内存中数据的直接访问,使得在C语言中可以进行灵活的内存操作和数据传递。以下是关于C语言指针的一些基本概念: 1. 指针的声明ÿ…...

PostgreSql 索引使用技巧
索引种类详情可参考《PostgreSql 索引》 一、适合创建索引的场景 经常与其他表进行连接的表,在连接字段上应该建索引。经常出现在 WHERE 子句中的字段,特别是大表的字段,应该建索引。经常出现在 ORDER BY 子句中的字段,应该建索…...

【华为数据之道学习笔记】6-7打造业务自助分析的关键能力
华为公司将自助分析作为一种公共能力,在企业层面进行了统一构建。一方面,面向不同的消费用户提供了差异性的能力和工具支撑;另一方面,引入了“租户”概念,不同类型的用户可以在一定范围内分析数据、共享数据结果。 1. …...

K8S从harbor中拉取镜像的规则imagePullPolicy
1、参数 配制参数为:imagePullPolicy: 可以选择的值有:Always,IfNotPresent,Never 2、参数结果 如果pod的镜像拉取策略为imagePullPolicy: Always:当harbor不能运行后,pod会一直从harbor上拉…...

解决VMware安装macOS后分辨率锁死的烦恼:手把手教你安装VMware Tools并自定义显示设置
突破VMware中macOS显示限制:从工具安装到完美适配的全流程指南 当你在VMware中成功安装macOS系统后,可能会立刻遇到一个令人沮丧的问题——屏幕分辨率被锁定在低分辨率状态,窗口无法自由缩放,操作体验大打折扣。这种显示限制不仅…...

如何永久免费激活Windows和Office?KMS_VL_ALL_AIO智能激活脚本完整指南
如何永久免费激活Windows和Office?KMS_VL_ALL_AIO智能激活脚本完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows激活弹窗烦恼吗?是否遇到过Office突…...

避坑指南:STM32F407的DAC输出Buffer为啥会导致0V?ADC连续转换模式与DMA配置的细节解析
STM32F407模拟信号处理实战:DAC输出与ADC采样的深度避坑指南 1. 从异常现象到原理剖析:DAC输出Buffer的隐藏陷阱 调试STM32F407的DAC外设时,不少开发者都遇到过这样的困惑:明明配置了正确的数值,输出电压却始终为0V。…...

Borderless Gaming终极指南:三步搞定无缝游戏窗口切换的魔法
Borderless Gaming终极指南:三步搞定无缝游戏窗口切换的魔法 【免费下载链接】Borderless-Gaming Play your favorite games in a borderless window; no more time consuming alt-tabs. 项目地址: https://gitcode.com/gh_mirrors/bo/Borderless-Gaming 你…...

Vibe Vibe 测试自动化:如何用AI帮你写测试代码,保证项目质量
Vibe Vibe 测试自动化:如何用AI帮你写测试代码,保证项目质量 【免费下载链接】vibe-vibe The First Systematic Vibe Coding Open-Source Tutorial | From Zero to Full-Stack, Empowering Everyone to Build Products with AI | Live at: www.vibevibe.…...

Wedding-website开发者指南:理解项目架构与代码实现原理
Wedding-website开发者指南:理解项目架构与代码实现原理 【免费下载链接】wedding-website Our Wedding Website 👫 项目地址: https://gitcode.com/gh_mirrors/we/wedding-website Wedding-website是一个专为婚礼设计的开源网站项目,…...

华硕笔记本性能优化神器:G-Helper轻量控制工具完全指南
华硕笔记本性能优化神器:G-Helper轻量控制工具完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, E…...

战略视角:如何用AI自动化重构团队工作流
战略视角:如何用AI自动化重构团队工作流 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在数字化加速的时代,企业面临的核心挑战不再是技…...

实时洞察,视觉赋能:国内情绪识别API公司推荐及计算机视觉流派深度解析
引言在人工智能与各行业深度融合的今天,通过非接触方式理解用户情绪、生理状态与心理倾向,已成为人机交互、安全防控、健康管理等领域的关键能力。本文围绕提供情绪识别类API的公司类型,梳理国内情绪识别的主流技术路径,并重点解析…...

用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定
用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定 在嵌入式开发领域,PWM(脉冲宽度调制)技术堪称"瑞士军刀"般的存在。无论是调节电机转速、控制舵机角度,还是实现LED呼吸灯效果…...