使用 Elasticsearch 检测抄袭 (二)

我在在之前的文章 “使用 Elasticsearch 检测抄袭 (一)” 介绍了如何检文章抄袭。这个在许多的实际使用中非常有意义。我在 CSDN 上的文章也经常被人引用或者抄袭。有的人甚至也不用指明出处。这对文章的作者来说是很不公平的。文章介绍的内容针对很多的博客网站也非常有意义。在那篇文章中,我觉得针对一些开发者来说,不一定能运行的很好。在今天的这篇文章中,我特意使用本地部署,并使用 jupyter notebook 来进行一个展示。这样开发者能一步一步地完整地运行起来。
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

为了能够上传向量模型,我们必须订阅白金版或试用。

上传模型
注意:如果我们在这里通过命令行来进行上传模型的话,那么你就不需要在下面的代码中来实现上传。可以省去那些个步骤。
我们可以参考之前的文章 “Elasticsearch:使用 NLP 问答模型与你喜欢的圣诞歌曲交谈”。我们使用如下的命令来上传 OpenAI detection 模型:
eland_import_hub_model --url https://elastic:o6G_pvRL=8P*7on+o6XH@localhost:9200 \--hub-model-id roberta-base-openai-detector \--task-type text_classification \--ca-cert /Users/liuxg/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt \--start在上面,我们需要根据自己的配置修改上面的证书路径,Elasticsearch 的访问地址。

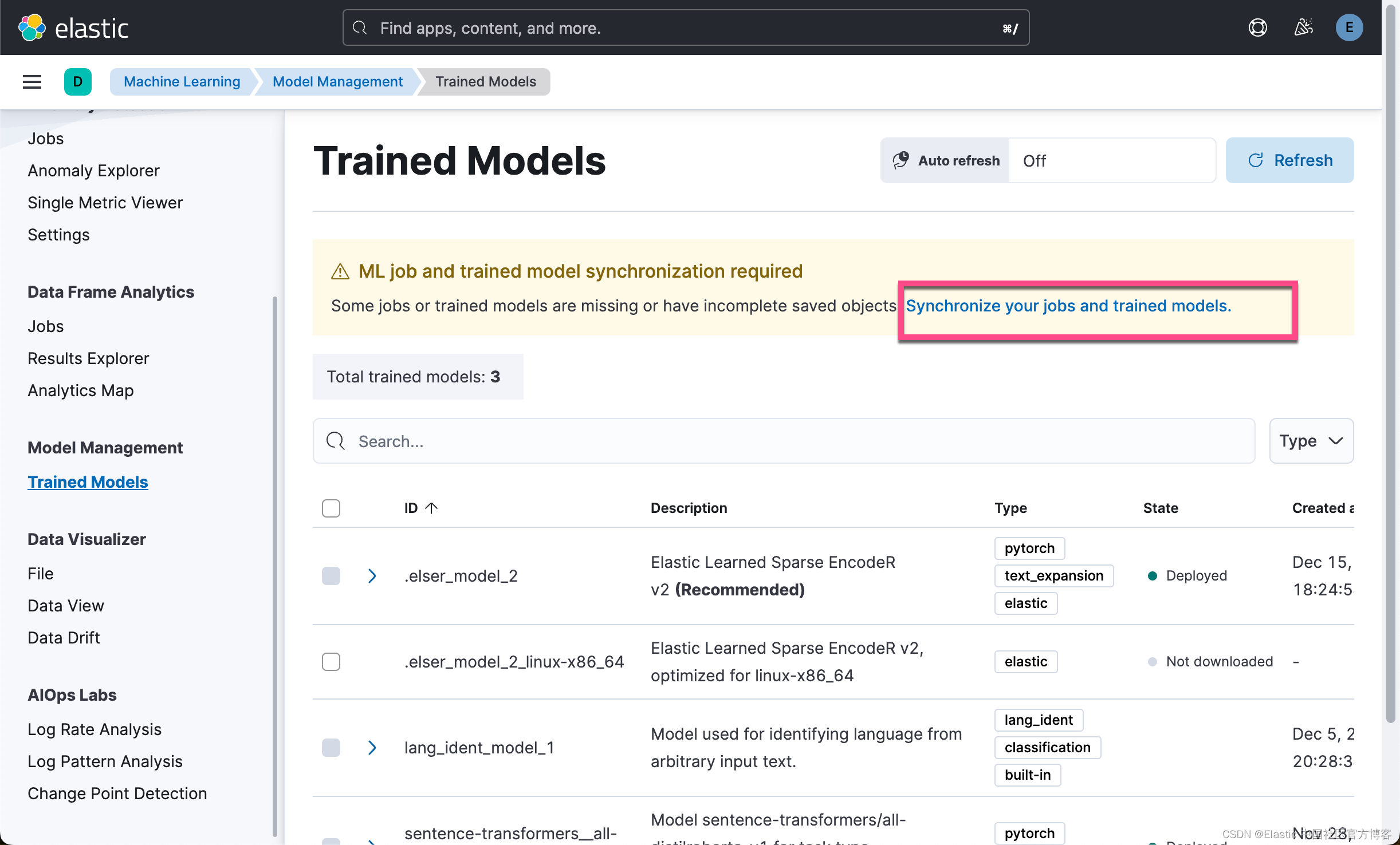
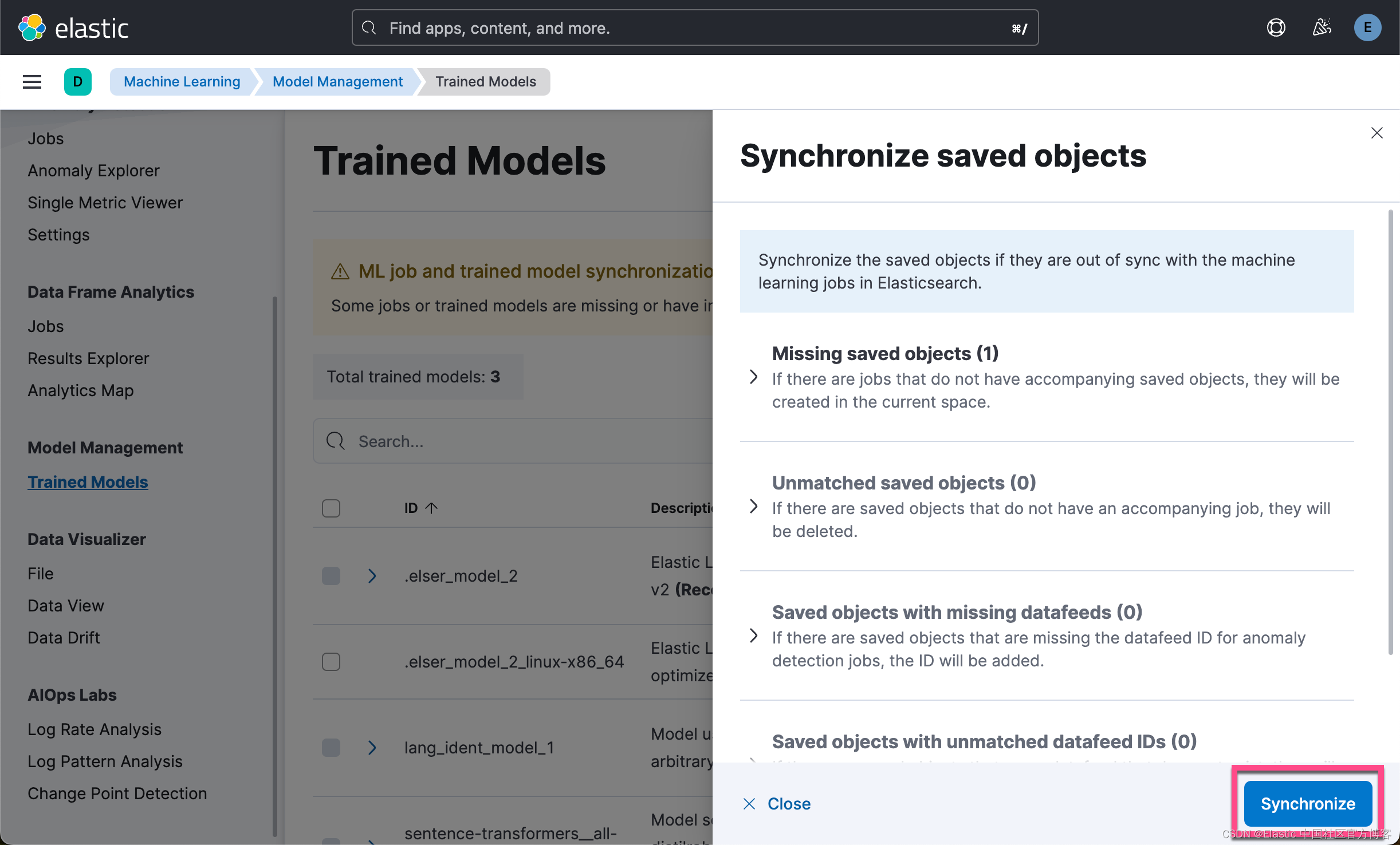
我们可以在 Kibana 中查看最新上传的模型:

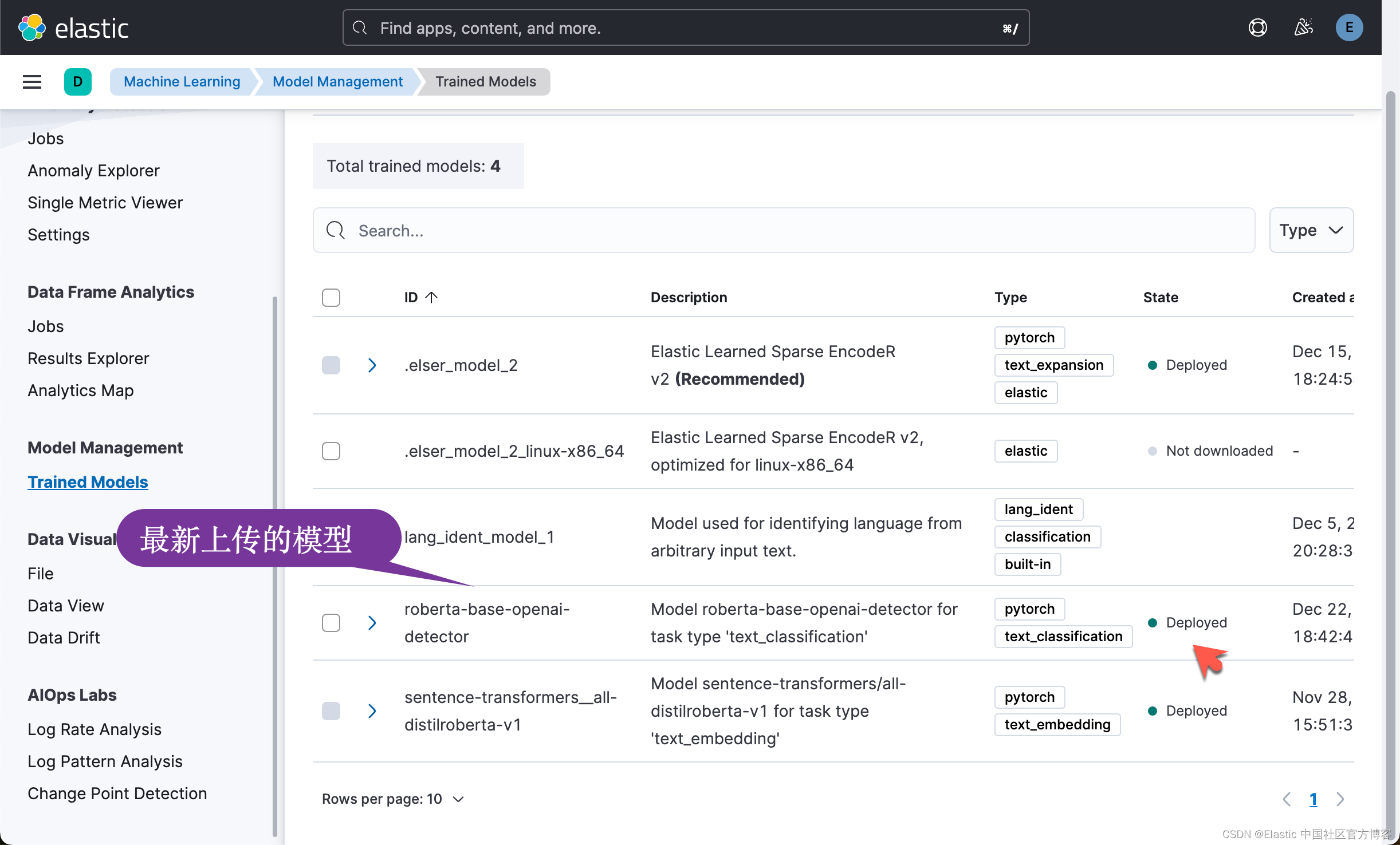
接下来,按照同样的方法,我们安装文本嵌入模型。
eland_import_hub_model --url https://elastic:o6G_pvRL=8P*7on+o6XH@localhost:9200 \--hub-model-id sentence-transformers/all-mpnet-base-v2 \--task-type text_embedding \--ca-cert /Users/liuxg/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt \--start 
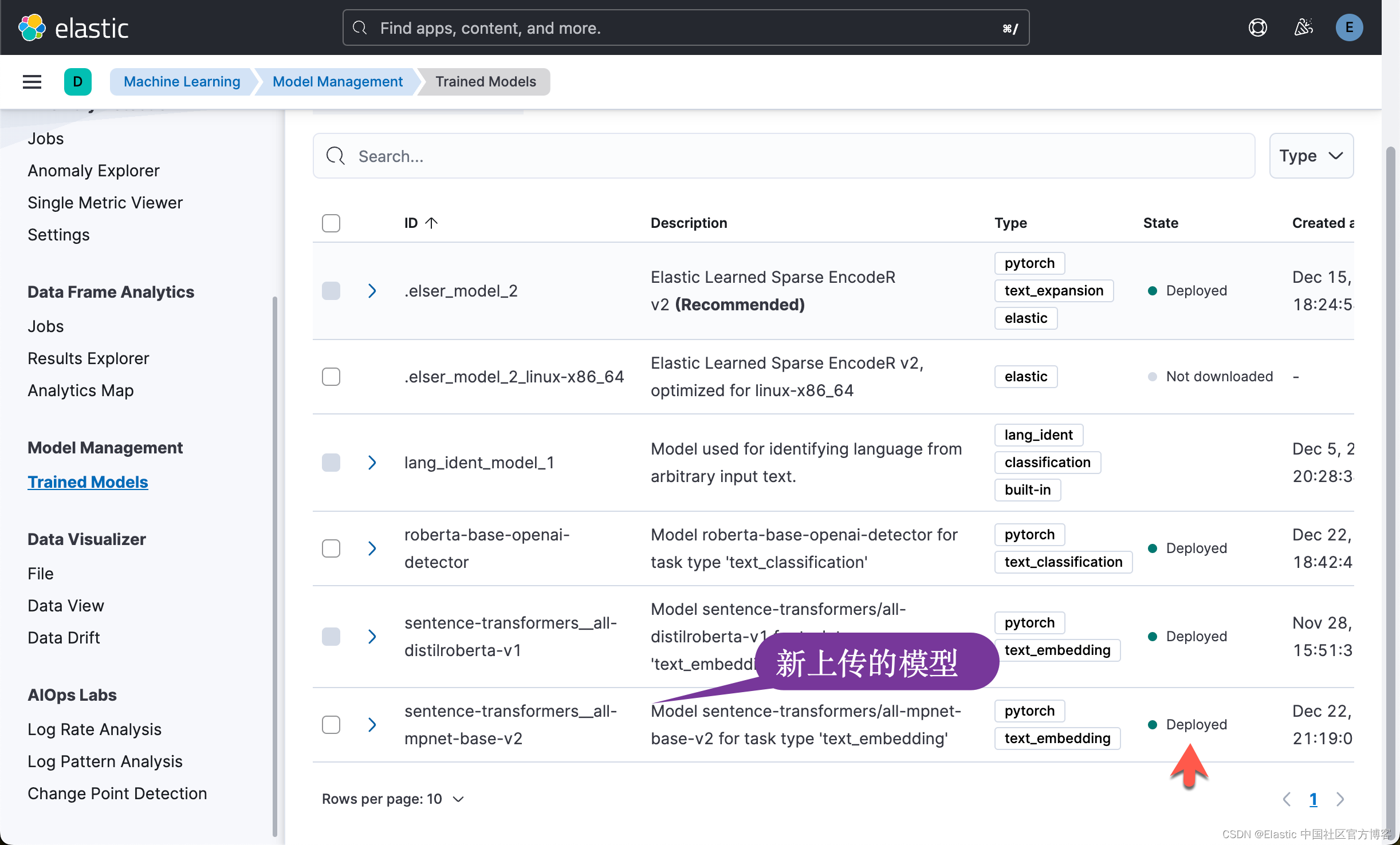
为了方便大家学习,我们可以在如下的地址下载代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs我们可以在如下的位置找到 jupyter notebook:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/plagiarism-detection-with-elasticsearch
$ ls
plagiarism_detection_es_self_managed.ipynb运行代码
接下来,我们开始运行 notebook。我们首先安装相应的 python 包:
pip3 install elasticsearch==8.11
pip3 -q install eland elasticsearch sentence_transformers transformers torch==2.1.0在运行代码之前,我们先设置如下的变量:
export ES_USER="elastic"
export ES_PASSWORD="o6G_pvRL=8P*7on+o6XH"
export ES_ENDPOINT="localhost"我们还需要把 Elasticsearch 的证书拷贝到当前的目录中:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/plagiarism-detection-with-elasticsearch
$ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .
$ ls
http_ca.crt plagiarism_detection_es_self_managed.ipynb
plagiarism_detection_es.ipynb导入包:
from elasticsearch import Elasticsearch, helpers
from elasticsearch.client import MlClient
from eland.ml.pytorch import PyTorchModel
from eland.ml.pytorch.transformers import TransformerModel
from urllib.request import urlopen
import json
from pathlib import Path
import os连接到 Elasticsearch
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)print(client.info())
上传 detector 模型
hf_model_id ='roberta-base-openai-detector'
tm = TransformerModel(model_id=hf_model_id, task_type="text_classification")#set the modelID as it is named in Elasticsearch
es_model_id = tm.elasticsearch_model_id()# Download the model from Hugging Face
tmp_path = "models"
Path(tmp_path).mkdir(parents=True, exist_ok=True)
model_path, config, vocab_path = tm.save(tmp_path)# Load the model into Elasticsearch
ptm = PyTorchModel(client, es_model_id)
ptm.import_model(model_path=model_path, config_path=None, vocab_path=vocab_path, config=config)#Start the model
s = MlClient.start_trained_model_deployment(client, model_id=es_model_id)
s.body
我们可以在 Kibana 中进行查看:

上传 text embedding 模型
hf_model_id='sentence-transformers/all-mpnet-base-v2'
tm = TransformerModel(model_id=hf_model_id, task_type="text_embedding")#set the modelID as it is named in Elasticsearch
es_model_id = tm.elasticsearch_model_id()# Download the model from Hugging Face
tmp_path = "models"
Path(tmp_path).mkdir(parents=True, exist_ok=True)
model_path, config, vocab_path = tm.save(tmp_path)# Load the model into Elasticsearch
ptm = PyTorchModel(client, es_model_id)
ptm.import_model(model_path=model_path, config_path=None, vocab_path=vocab_path, config=config)# Start the model
s = MlClient.start_trained_model_deployment(client, model_id=es_model_id)
s.body
我们可以在 Kibana 中查看:

创建源索引
client.indices.create(
index="plagiarism-docs",
mappings= {"properties": {"title": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"abstract": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"url": {"type": "keyword"},"venue": {"type": "keyword"},"year": {"type": "keyword"}}
})我们可以在 Kibana 中进行查看:
创建 checker ingest pipeline
client.ingest.put_pipeline(id="plagiarism-checker-pipeline",processors = [{"inference": { #for ml models - to infer against the data that is being ingested in the pipeline"model_id": "roberta-base-openai-detector", #text classification model id"target_field": "openai-detector", # Target field for the inference results"field_map": { #Maps the document field names to the known field names of the model."abstract": "text_field" # Field matching our configured trained model input. Typically for NLP models, the field name is text_field.}}},{"inference": {"model_id": "sentence-transformers__all-mpnet-base-v2", #text embedding model model id"target_field": "abstract_vector", # Target field for the inference results"field_map": { #Maps the document field names to the known field names of the model."abstract": "text_field" # Field matching our configured trained model input. Typically for NLP models, the field name is text_field.}}}]
)我们可以在 Kibana 中进行查看:
创建 plagiarism checker 索引
client.indices.create(
index="plagiarism-checker",
mappings={
"properties": {"title": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"abstract": {"type": "text","fields": {"keyword": {"type": "keyword"}}},"url": {"type": "keyword"},"venue": {"type": "keyword"},"year": {"type": "keyword"},"abstract_vector.predicted_value": { # Inference results field, target_field.predicted_value"type": "dense_vector","dims": 768, # embedding_size"index": "true","similarity": "dot_product" # When indexing vectors for approximate kNN search, you need to specify the similarity function for comparing the vectors.}}
}
)我们可以在 Kibana 中进行查看:
写入源文档
我们首先把地址 https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/datasets/emnlp2016-2018.json 里的文档下载到当前目录下:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/plagiarism-detection-with-elasticsearch
$ ls
emnlp2016-2018.json plagiarism_detection_es.ipynb
http_ca.crt plagiarism_detection_es_self_managed.ipynb
models如上所示,emnlp2016-2018.json 就是我们下载的文档。
# Load data into a JSON object
with open('emnlp2016-2018.json') as f:data_json = json.load(f)print(f"Successfully loaded {len(data_json)} documents")def create_index_body(doc):""" Generate the body for an Elasticsearch document. """return {"_index": "plagiarism-docs","_source": doc,}# Prepare the documents to be indexed
documents = [create_index_body(doc) for doc in data_json]# Use helpers.bulk to index
helpers.bulk(client, documents)print("Done indexing documents into `plagiarism-docs` source index")
我们可以在 Kibana 中进行查看:
使用 ingest pipeline 进行 reindex
client.reindex(wait_for_completion=False,source={"index": "plagiarism-docs"},dest= {"index": "plagiarism-checker","pipeline": "plagiarism-checker-pipeline"}
)
在上面,我们设置 wait_for_completion=False。这是一个异步的操作。我们需要等一段时间让上面的 reindex 完成。我们可以通过检查如下的文档数:
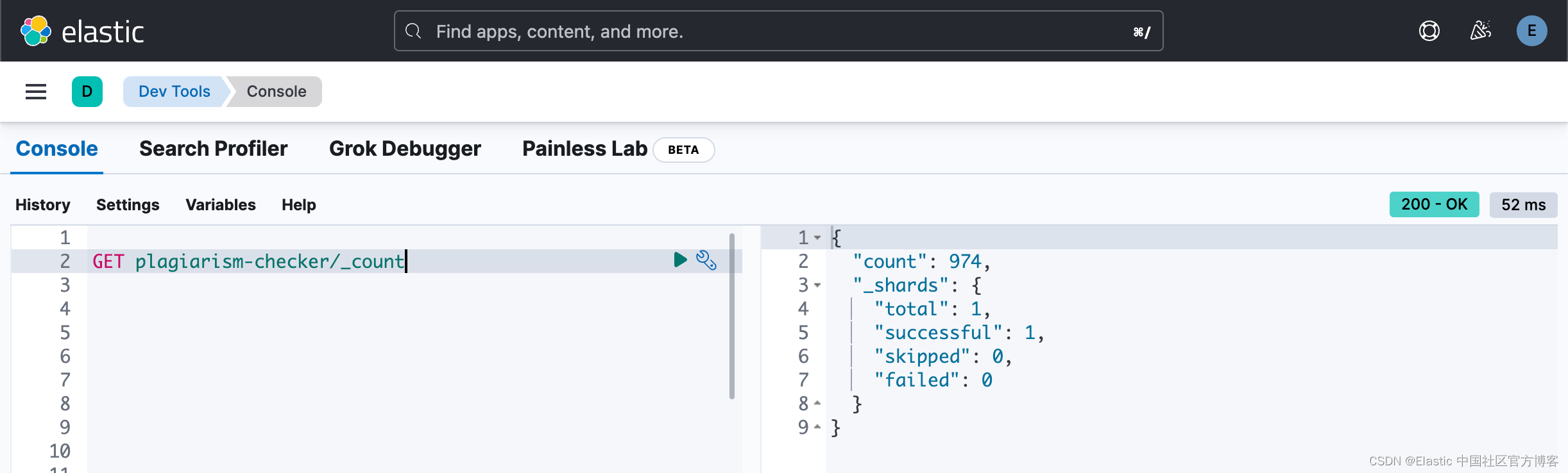
上面表明我们的文档已经完成。我们再接着查看一下 plagiarism-checker 索引中的文档:
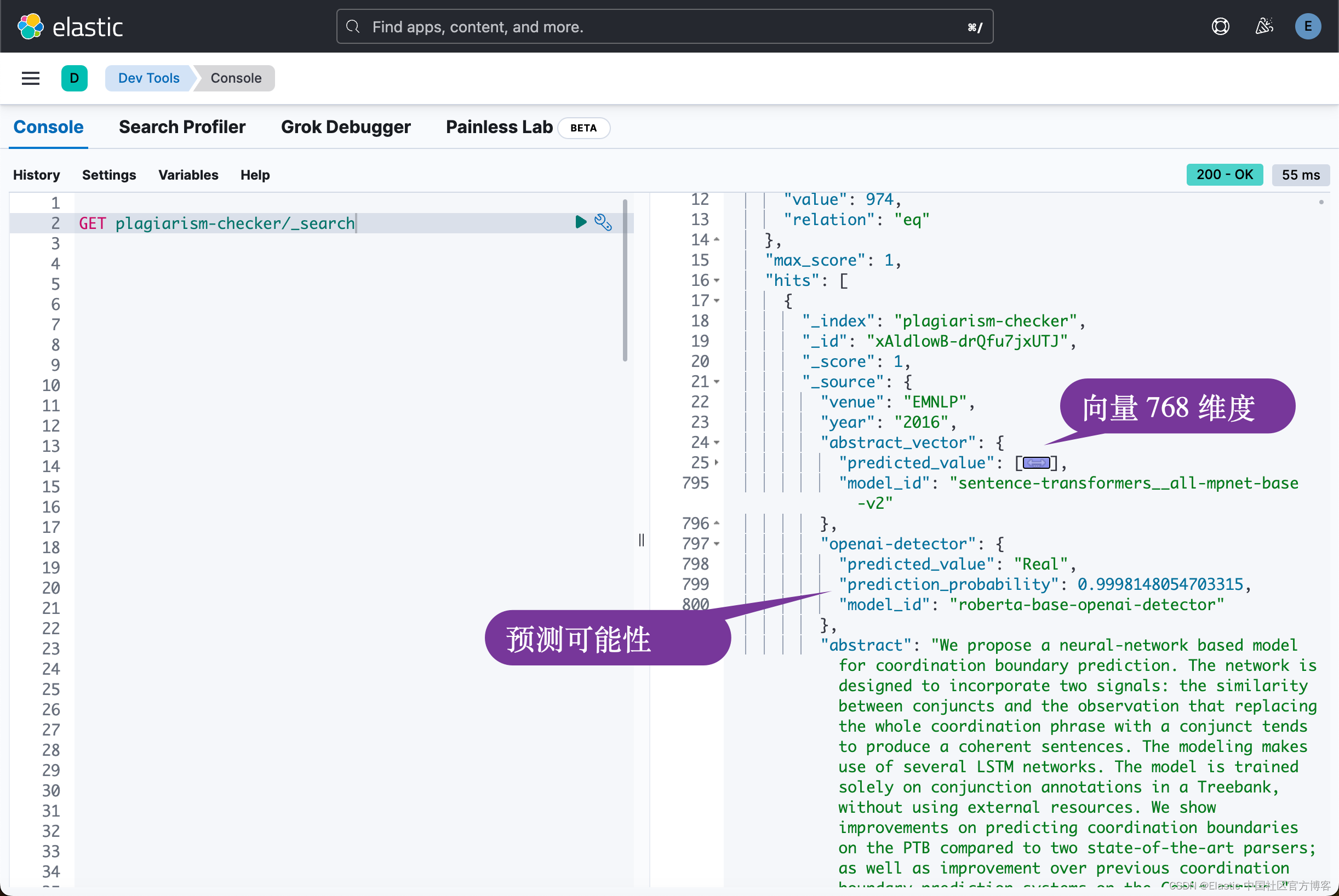
检查重复文字
direct plagarism
model_text = 'Understanding and reasoning about cooking recipes is a fruitful research direction towards enabling machines to interpret procedural text. In this work, we introduce RecipeQA, a dataset for multimodal comprehension of cooking recipes. It comprises of approximately 20K instructional recipes with multiple modalities such as titles, descriptions and aligned set of images. With over 36K automatically generated question-answer pairs, we design a set of comprehension and reasoning tasks that require joint understanding of images and text, capturing the temporal flow of events and making sense of procedural knowledge. Our preliminary results indicate that RecipeQA will serve as a challenging test bed and an ideal benchmark for evaluating machine comprehension systems. The data and leaderboard are available at http://hucvl.github.io/recipeqa.'response = client.search(index='plagiarism-checker', size=1,knn={"field": "abstract_vector.predicted_value","k": 9,"num_candidates": 974,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-mpnet-base-v2","model_text": model_text}}}
)for hit in response['hits']['hits']:score = hit['_score']title = hit['_source']['title']abstract = hit['_source']['abstract']openai = hit['_source']['openai-detector']['predicted_value']url = hit['_source']['url']if score > 0.9:print(f"\nHigh similarity detected! This might be plagiarism.")print(f"\nMost similar document: '{title}'\n\nAbstract: {abstract}\n\nurl: {url}\n\nScore:{score}\n")if openai == 'Fake':print("This document may have been created by AI.\n")elif score < 0.7:print(f"\nLow similarity detected. This might not be plagiarism.")if openai == 'Fake':print("This document may have been created by AI.\n")else:print(f"\nModerate similarity detected.")print(f"\nMost similar document: '{title}'\n\nAbstract: {abstract}\n\nurl: {url}\n\nScore:{score}\n")if openai == 'Fake':print("This document may have been created by AI.\n")ml_client = MlClient(client)model_id = 'roberta-base-openai-detector' #open ai text classification modeldocument = [{"text_field": model_text}
]ml_response = ml_client.infer_trained_model(model_id=model_id, docs=document)predicted_value = ml_response['inference_results'][0]['predicted_value']if predicted_value == 'Fake':print("Note: The text query you entered may have been generated by AI.\n")
similar text - paraphrase plagiarism
model_text = 'Comprehending and deducing information from culinary instructions represents a promising avenue for research aimed at empowering artificial intelligence to decipher step-by-step text. In this study, we present CuisineInquiry, a database for the multifaceted understanding of cooking guidelines. It encompasses a substantial number of informative recipes featuring various elements such as headings, explanations, and a matched assortment of visuals. Utilizing an extensive set of automatically crafted question-answer pairings, we formulate a series of tasks focusing on understanding and logic that necessitate a combined interpretation of visuals and written content. This involves capturing the sequential progression of events and extracting meaning from procedural expertise. Our initial findings suggest that CuisineInquiry is poised to function as a demanding experimental platform.'response = client.search(index='plagiarism-checker', size=1,knn={"field": "abstract_vector.predicted_value","k": 9,"num_candidates": 974,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-mpnet-base-v2","model_text": model_text}}}
)for hit in response['hits']['hits']:score = hit['_score']title = hit['_source']['title']abstract = hit['_source']['abstract']openai = hit['_source']['openai-detector']['predicted_value']url = hit['_source']['url']if score > 0.9:print(f"\nHigh similarity detected! This might be plagiarism.")print(f"\nMost similar document: '{title}'\n\nAbstract: {abstract}\n\nurl: {url}\n\nScore:{score}\n")if openai == 'Fake':print("This document may have been created by AI.\n")elif score < 0.7:print(f"\nLow similarity detected. This might not be plagiarism.")if openai == 'Fake':print("This document may have been created by AI.\n")else:print(f"\nModerate similarity detected.")print(f"\nMost similar document: '{title}'\n\nAbstract: {abstract}\n\nurl: {url}\n\nScore:{score}\n")if openai == 'Fake':print("This document may have been created by AI.\n")ml_client = MlClient(client)model_id = 'roberta-base-openai-detector' #open ai text classification modeldocument = [{"text_field": model_text}
]ml_response = ml_client.infer_trained_model(model_id=model_id, docs=document)predicted_value = ml_response['inference_results'][0]['predicted_value']if predicted_value == 'Fake':print("Note: The text query you entered may have been generated by AI.\n")
完整的代码可以在地址下载:https://github.com/liu-xiao-guo/elasticsearch-labs/blob/main/supporting-blog-content/plagiarism-detection-with-elasticsearch/plagiarism_detection_es_self_managed.ipynb
相关文章:
使用 Elasticsearch 检测抄袭 (二)
我在在之前的文章 “使用 Elasticsearch 检测抄袭 (一)” 介绍了如何检文章抄袭。这个在许多的实际使用中非常有意义。我在 CSDN 上的文章也经常被人引用或者抄袭。有的人甚至也不用指明出处。这对文章的作者来说是很不公平的。文章介绍的内容针对很多的…...

WPF DataGrid
文章目录 SelectionModeHeaderVisibilityBorderBrush SelectionMode DataGrid 控件的 SelectionMode 属性定义了用户可以如何选择 DataGrid 中的行。它是一个枚举类型的属性,有以下几个选项: Single(默认值):只能选择…...
【cesium-5】鼠标交互与数据查询
scene.pick返回的是包含给定窗口位置基元的对象 scene.drillpack返回的是给定窗口位置所有对象的列表 Globe.pick返回的是给光线和地形的交点 Cesium.ScreenSpaceEventType.MIDDLE_CLICK 鼠标中间点击事件 Cesium.ScreenSpaceEventType.MOUSE_MOVE 鼠标移入事件 Cesium.ScreenS…...

Xcode 编译速度慢是什么原因?如何提高编译速度?
作为一个开发者,我们都希望能够高效地开发应用程序,而编译速度是影响开发效率的重要因素之一。然而,有时候我们会发现在使用 Xcode 进行开发时,译速度非常慢,这给我们带来了不少困扰。那么,为什么 Xcode 的…...

Best Arm Identification in Batched Multi-armed Bandit Problems
Q: 这篇论文试图解决什么问题? A: 这篇论文试图解决在批量多臂老虎机问题中进行最佳臂识别(BAI)的挑战,其中必须成批地对臂进行抽样,因为代理等待反馈的时间有限。这种场景出现在许多现实世界的应用中,例如…...

Unity编辑器紫色
紫色原因是因为编辑器内跑了其他平台的shader兼容性导致的,需要动态的去修改shader,主要用到Unity的api : Shader.Find(shaderName); 具体的工具代码如下: using System.Collections; using System.Collections.Generic; using UnityEngine…...
冒泡排序(C语言)
void BubbleSort(int arr[], int len) {int i, j, temp;for (i 0; i < len; i){for (j len - 1; j > i; j--){if (arr[j] > arr[j 1]){temp arr[j];arr[j] arr[j 1];arr[j 1] temp;}}} } 优化: 设置标志位flag,如果发生了交换flag设置…...
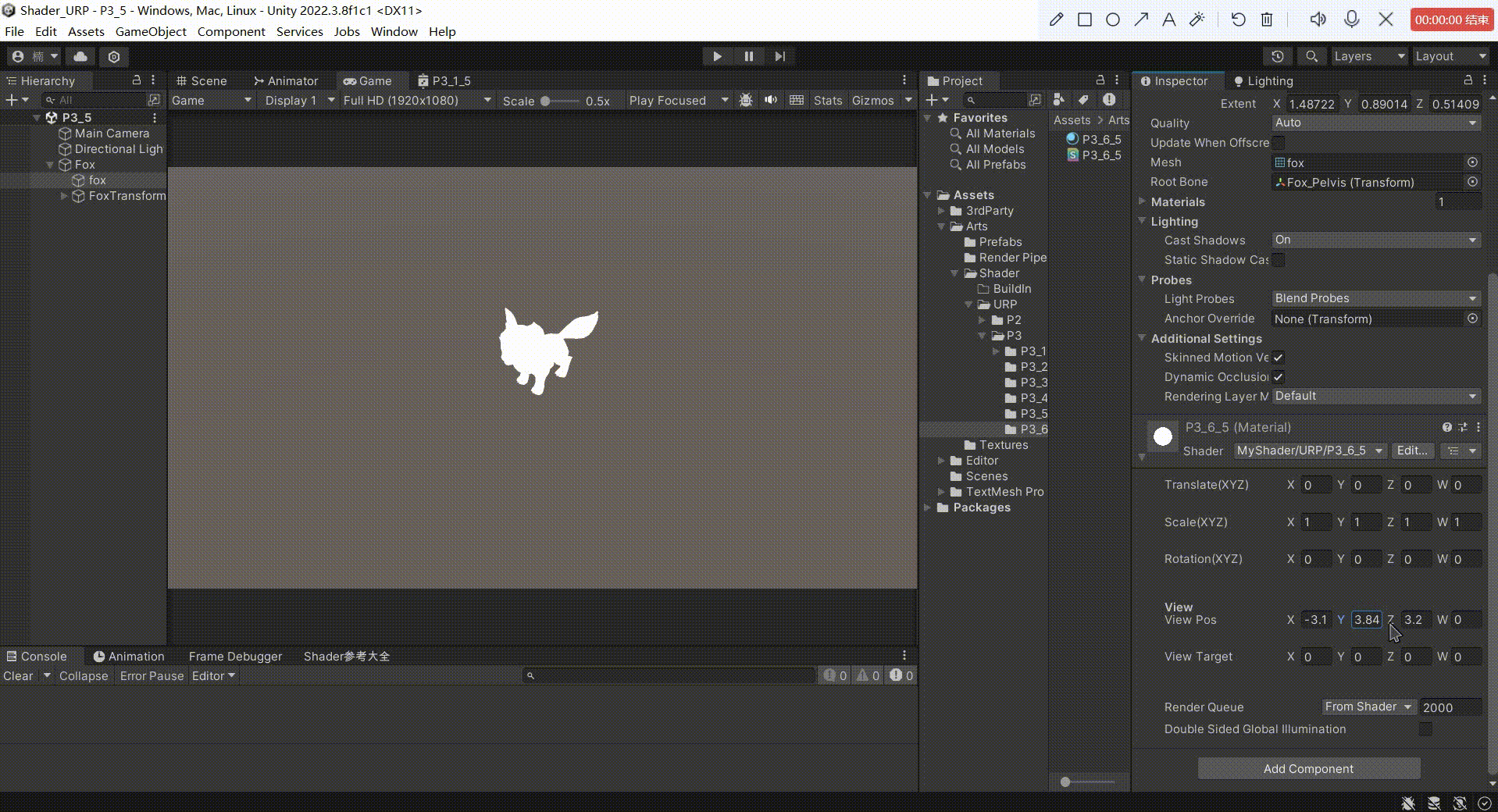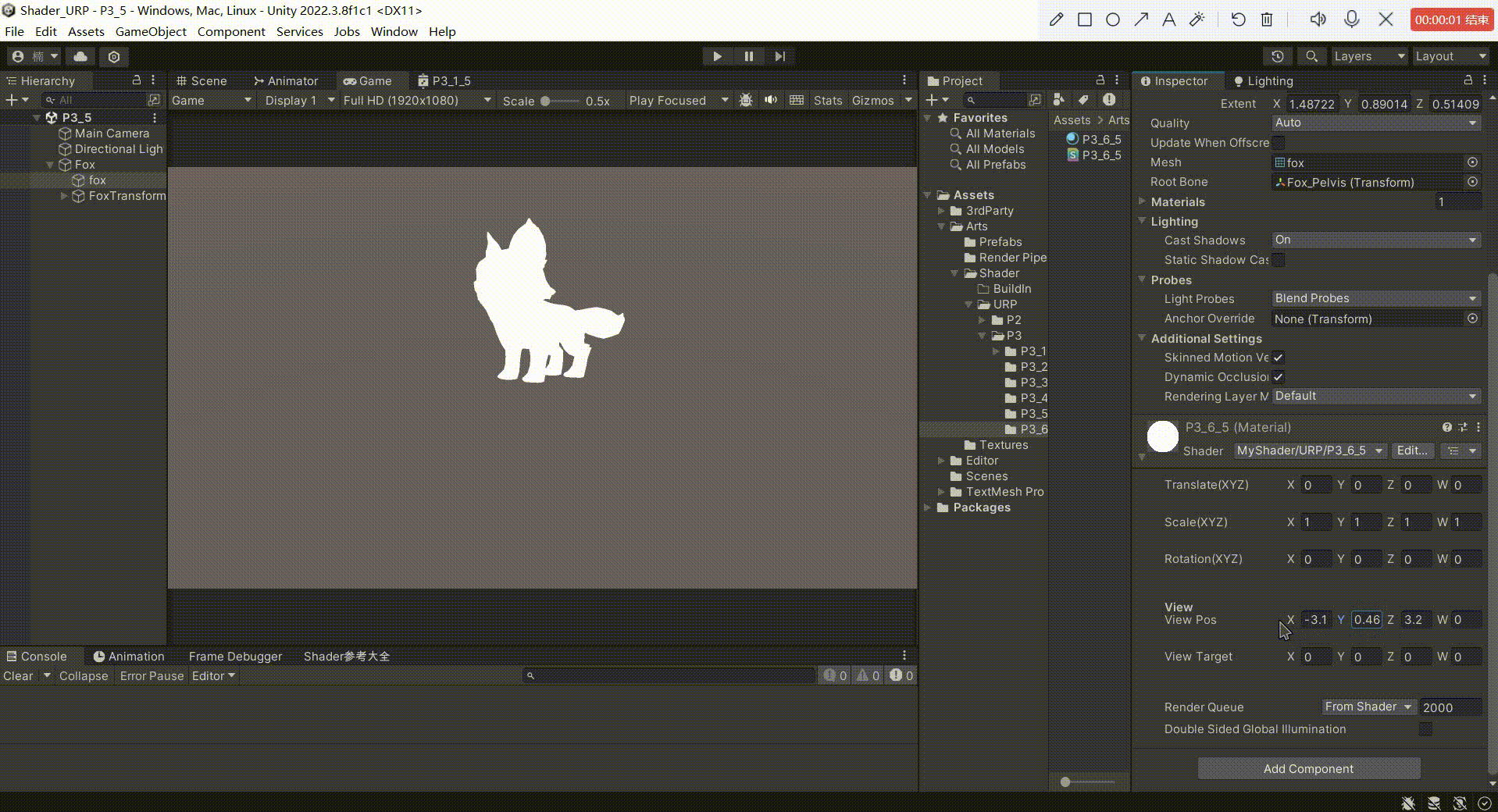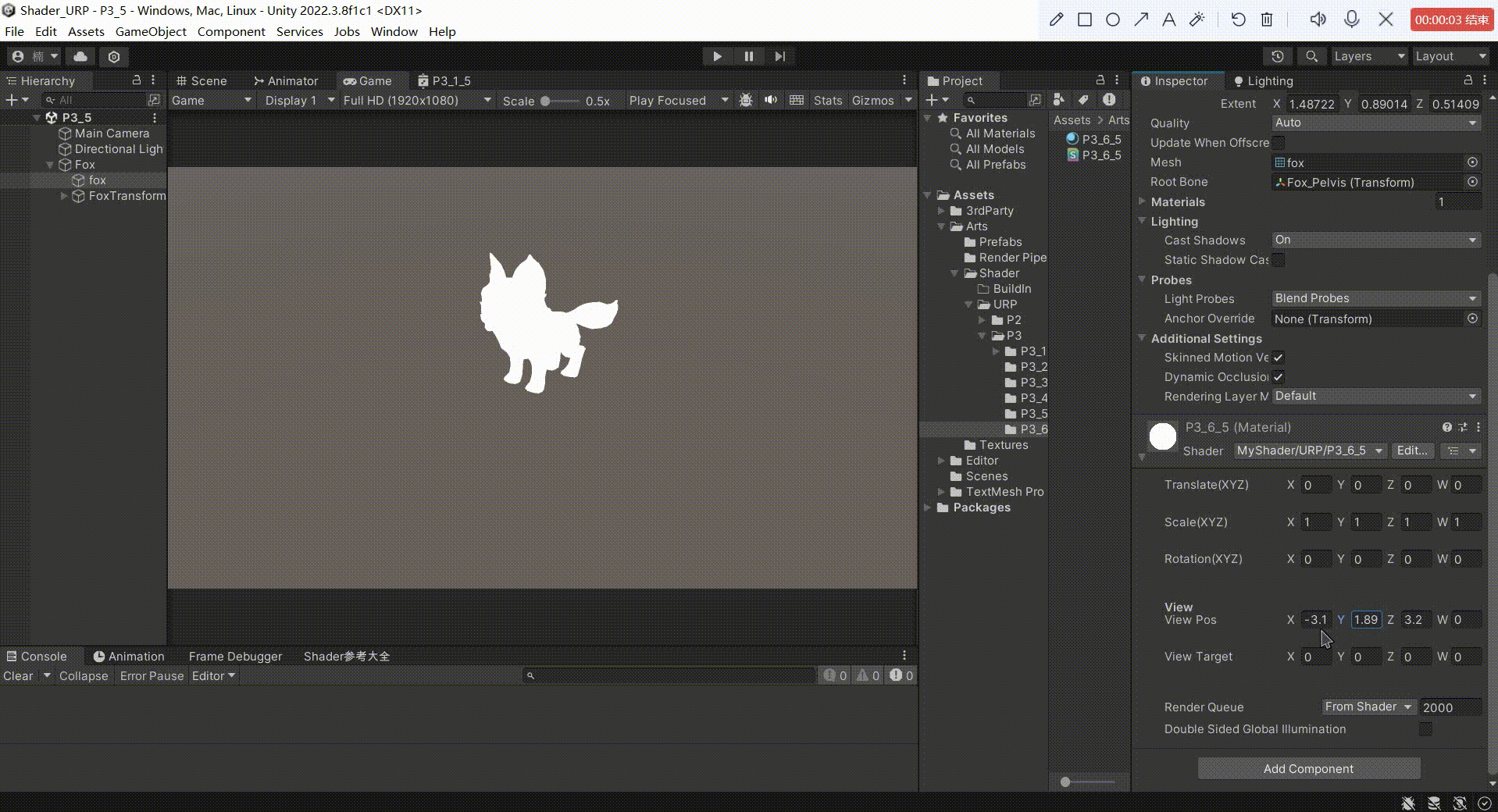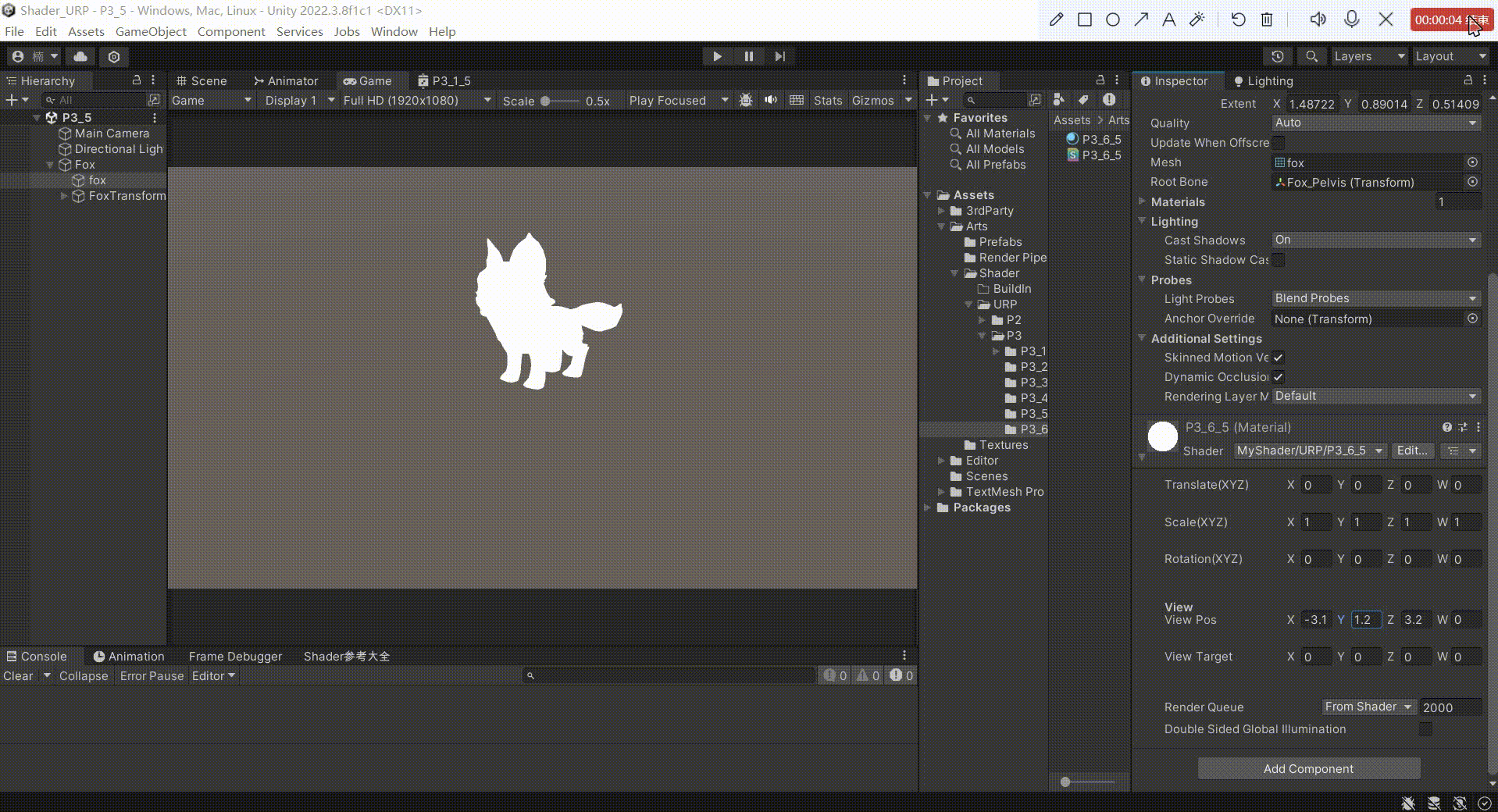
Unity中Shader观察空间推导(在Shader中实现)
文章目录 前言一、观察空间矩阵推导1、求观察空间基向量2、求观察空间的基向量在世界空间中的矩阵 的 逆矩阵2、求平移变换矩阵3、相乘得出 观察空间转化矩阵4、得到顶点的世界空间坐标,然后转化到观察空间5、把观察空间坐标转化为齐次裁剪坐标输出到屏幕 二、最终效…...

Hive04_DDL操作
Hive DDL操作 1 DDL 数据定义 1.1 创建数据库 CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_nameproperty_value, ...)];[IF NOT EXISTS] :判断是否存在 [COMMENT database_c…...

odoo17核心概念view4——view.js
这是view系列的第四篇文章,专门介绍View组件。 作为一个Component,它总共包含js、css、xml三个标准文件,当然最重要的是view.js 首先在setup函数中对传入的参数props做了各种校验,然后扩展了subenv useSubEnv({keepLast: new Kee…...

Centos7 openSSL
阅读时长:10分钟 本文内容: 在阿里云Centos7上部署python3.10.6项目时遇到openSSL协议不支持,导致无法下载第三方包 本文目的: 通过手动编译,升级openssl版本centos7 重编译 python3.10.6github下载缓慢解决镜像源记录…...

Web 安全之文件下载漏洞详解
目录 引言 文件下载漏洞原理 文件下载漏洞的危害 文件下载漏洞类型 文件下载漏洞的利用方法 文件下载漏洞示例 文件下载漏洞的防护措施 漏洞检测与测试 小结 引言 在数字化时代,文件下载是网络应用程序的重要的功能之一,用户可以通过这一功能获…...
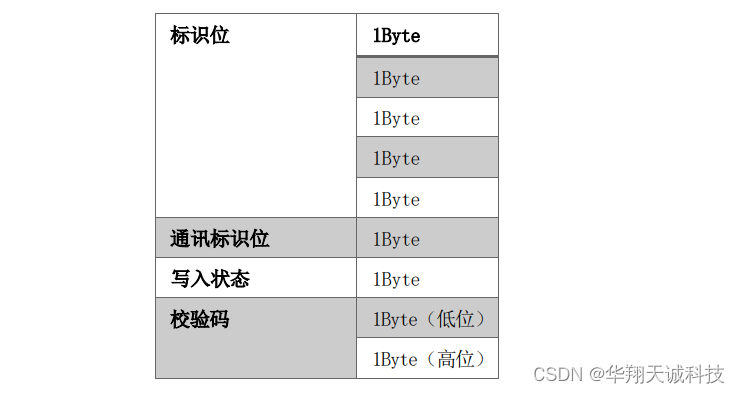
搬运机器人RFID传感器CNS-RFID-01|1S的RS485(MODBUS|HS协议)通讯连接方法
搬运机器人RFID传感器CNS-RFID-01|1S支持RS485通信,可支持RS485(MODBUS RTU)协议、RS485-HS协议,广泛应用于物流仓储,立库 AGV|无人叉车|搬送机器人等领域,常用定位、驻车等,本篇重点介绍CNS-RF…...

使用ZMQ.proxy实现ZMQ PUB消息转发
MQ.proxy 是 ZeroMQ 库中的一个功能,用于创建一个简单的代理服务器。它可以将消息从一个套接字传递到另一个套接字,实现消息的转发和路由。 要使用 ZMQ.proxy,需要按照以下步骤进行操作: 创建两个 ZMQ.Socket 对象:一个…...
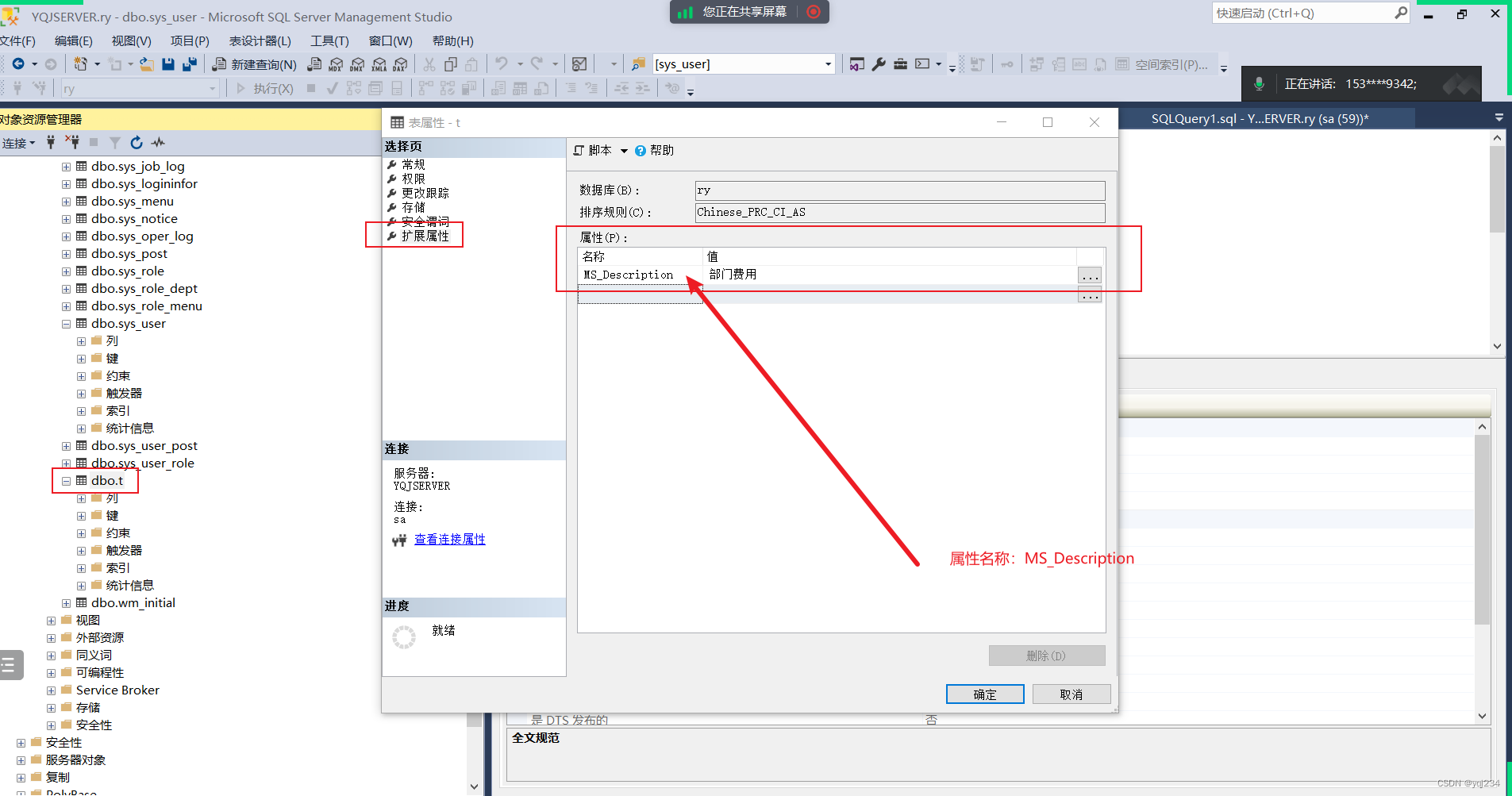
若依SQL Server开发使用教程
1. sys_menu表中的将菜单ID修改为自动ID,解决不能增加菜单的问题,操作流程如下: 解决方案如下 菜单栏->工具->选项 点击设计器,去掉阻止保存要求更新创建表的更改选项,点确认既可以保存了 2 自动生成代码找不表的解决方案…...

Mysql5.7服务器选项、系统变量和状态变量参考
官网地址:MySQL :: MySQL 5.7 Reference Manual :: 5.1.3 Server Option, System Variable, and Status Variable Reference 欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯. MySQL 5.7 参考手册 / ..…...

【Qt-Qss-Style】
Qt编程指南 ■ Qss■ Style■ setStyleSheet ■ style.qss■ border■ 去除弹框背景圆角■ QProgressBar样式表 ■ Qss Qt 支持很多种常见 符号 “>”代表直属子部件,说明两个控件之间是父子关系。 “#”代表后面的字段是前面控件类型的名称,当然也可…...

基于yolov8,制作停车位计数器(附源码)
大家好,YOLO(You Only Look Once) 是由Joseph Redmon和Ali开发的一种对象检测和图像分割模型。 YOLO的第一个版本于2015年发布,由于其高速度和准确性,瞬间得到了广大AI爱好者的喜爱。 Ultralytics YOLOv8则是一款前沿、最先进(SOTA)的模型&a…...
)
C++设计模式:单例模式(饿汉式、懒汉式)
单例模式是什么? 单例模式是一种创建型的软件设计模式。通过单例模式的设计,使得创建的类在当前进程中只有唯一一个实例,并提供一个全局性的访问点,这样可以规避因频繁创建对象而导致的内存飙升情况。 单例模式有三个要点 私有化…...
Django 访问前端页面一直在转异常:ReferenceError:axios is not defined
访问:http://127.0.0.1:8080/ my.html 一、异常: 二、原因 提示:axios找不到!! 查看代码<script src"https://unpkg.com/axios/dist/axios.min.js"></script>无法访问到官网 三、解决 Using j…...

DdddOcr:5分钟掌握Python验证码识别,彻底告别手动输入![特殊字符]
DdddOcr:5分钟掌握Python验证码识别,彻底告别手动输入!🚀 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 还在为繁琐的验证码输入而烦恼吗?…...

DownKyi终极教程:3步掌握B站视频下载,免费打造个人媒体库
DownKyi终极教程:3步掌握B站视频下载,免费打造个人媒体库 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、…...

kagent架构深度解析:4大核心组件如何协同构建云原生AI智能体平台
kagent架构深度解析:4大核心组件如何协同构建云原生AI智能体平台 【免费下载链接】kagent Cloud Native Agentic AI | Discord: https://bit.ly/kagentdiscord 项目地址: https://gitcode.com/gh_mirrors/ka/kagent kagent是一个专为Kubernetes设计的云原生A…...

Sunshine游戏串流服务器:从零部署到专家级调优的完整解决方案
Sunshine游戏串流服务器:从零部署到专家级调优的完整解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要打造完美的游戏串流体验,却总是被复杂的配…...
)
手把手教你用Google Cloud语音API为Android App加个“耳朵”和“嘴巴”(附免费额度避坑指南)
实战指南:在Android应用中集成Google Cloud语音技术 想象一下,你的Android应用能够听懂用户说话,还能用自然流畅的语音回应——这不再是科幻电影里的场景。借助Google Cloud的语音API,即使是独立开发者也能快速为应用添加专业的语…...

AI Agent将如何重构制造业的安全生产隐患识别模式?深度理解与实在Agent闭环实战
一、从“被动监控”到“主动进化”:2026年制造业安全隐患识别的范式迁移 站在2026年的时间节点回看,制造业的安全生产模式正经历着自工业4.0以来最深刻的变革。 传统的安全识别逻辑长期停留在“信号触发-人工干预”的被动阶段, 无论是基于阈值…...

高通平台Sensor驱动移植避坑指南:以QCM6490平台BMI160为例,从编译到上电调试全流程
高通平台Sensor驱动移植实战:QCM6490平台BMI160全流程避坑指南 1. 环境准备与基础架构解析 在QCM6490平台上进行BMI160传感器驱动移植前,必须充分理解高通SEE架构的设计理念。与传统的SSC架构相比,SEE架构通过模块化封装大幅降低了移植复杂度…...

别再傻傻用IO翻转了!用STM32的SPI+DMA驱动WS2812灯带,实测1920颗灯珠依然稳如老狗
STM32 SPIDMA驱动WS2812灯带:从时序优化到千级灯珠稳定控制实战 1. 为什么GPIO翻转方案在大型项目中频频翻车? 很多嵌入式开发者初次接触WS2812灯带时,都会尝试用GPIO翻转来实现控制——毕竟看起来只需要一根信号线,似乎用普通IO口…...

多 Harness Control Plane 如何重塑企业云 Agent 架构
Agent 规模化部署的真正瓶颈不是模型,而是 Harness 选择与治理 在生产环境中,工程领导者决定今年要把云 Agent 推到全团队规模:代码迁移、大型特性构建、生产部署、日常运维全线自动化。可一旦真正落地,第一个卡住的永远不是模型能…...
深入RT-DETR混合编码器:我是如何把Transformer计算瓶颈‘砍掉’一半的
深入RT-DETR混合编码器:我是如何把Transformer计算瓶颈‘砍掉’一半的 在目标检测领域,实时性能一直是工业界和学术界共同追求的圣杯。当传统YOLO系列通过精心设计的卷积网络不断刷新速度记录时,Transformer架构的DETR家族却因沉重的计算负担…...