【OpenAI Q* 超越人类的自主系统】DQN :Q-Learning + 深度神经网络
深度 Q 网络:用深度神经网络,来近似Q函数
- 强化学习介绍
- 离散场景,使用行为价值方法
- 连续场景,使用概率分布方法
- 实时反馈连续场景:使用概率分布 + 行为价值方法
- DQN(深度 Q 网络)= 深度神经网络 + Q-Learning
- Q-Learning
- 模型结构
- 损失函数
- 经验回放
- 探索策略
- 流程关联
- DQN 优化
- DDQN:双 DQN,实现无偏估计
- Dueling DQN:提高决策的准确性和效率
- Noisy DQN:增强模型的探索能力
- 优先级经验回放
- OpenAI Q* :超越人类的自主系统
强化学习介绍
机器学习是把带标签的数据训练模型,使得预测值尽可能接近真实值。
强化学习是通过和环境交互,奖励来训练模型,使得最后获取的奖励最大期望值。
在强化学习中,机器基于环境做出行为,正确的行为能够获得奖励。
以获得更多奖励为目标,实现机器与环境的最优互动。
如教狗子握手的时候,如果狗子正确握手,就能得到骨头奖励,不握手就没有。
如果咬了主人一口,还会受到惩罚。
长此以往,狗子为了得到更多骨头,就能学会握手这个技能。
强化学习和机器学习最大不同在于,环境未知。
因为环境未知,所以我们不能通过大量数据得到决策。
只能通过和环境的交互中,不断改进策略。
强化学习的发展历史:
- 动态规划:学过数据结构与算法的人,都了解,是传统算法策略中最难的,千变万化。
- 表格方法:时序差分、Q-Learning 、SARSA
- 函数逼近:线性函数逼近、多项式函数逼近、基函数逼近
- 深度强化学习:DQN、DDPG、AlphaStar、A2C、A3C、PPO
强化学习可分为离散、连续场景。
离散场景,使用行为价值方法
离散场景:机器行为的有限的,如动作类游戏。只有向上、向下、向左、向右这 4 个动作,移动也只能一格一格地走。
可以把每个状态下的所有行为列举出来,用评论家为每个行为打分,通过选择最高分的行为实现最优互动。
因为需要评估每个行为的价值,所以这种学习方法被称为基于行为价值的方法。
基于值的方法需要根据每个行为的价值进行打分,选出价值最高的行为。
由于要穷举出所有行为,因此它只适用于离散场景(动作类游戏),无法应对连续场景。
Q-Learning 和 DQN 算法,都属于基于值的强化学习方法。
优势在于,基于行为价值的方法能实时反馈。
可以根据每个行为的价值进行打分,这个分数就相当于每个行为的实时反馈。
连续场景,使用概率分布方法
连续场景:机器的行为是连贯的,如赛车的方向盘转动角度可以在一定区间内任意取值,角度之间可以无限分割。
还有基于行为概率的方法,无需根据每个行为的价值来打分,可以很好地胜任连续场景。
基于行为概率策略的方法并不需要考虑行为的价值,而是反应调整。
机器会在训练过程中随机抽取一些行为,与环境互动。如果行为获得了奖励,就会提高选择它的概率。以后遇到同样的状态时,有更高的概率再次做出这个行为。
相反,如果未获得奖励,或者受到了惩罚,就保持或者降低该行为的概率。
经过大量训练,最终会得出连续行为的概率分布。
基于这样的原理,一个行为能获得越多奖励,被选择的概率就越大,从而实现机器和环境的最优化互动。
PPO、演员-评论家 就是能处理连续场景的算法。
优势在于,基于策略的方法能应用连续场景上。但不能实时反馈。
实时反馈连续场景:使用概率分布 + 行为价值方法
机器在与环境互动时,难以得到实时反馈,往往要在整个回合结束后才能获得奖励。
如赢一盘棋是正向奖励,输一盘棋是负面奖励,但棋局中某一颗棋子的价值很难即时评估。
想要提高学习效率,就必须想办法提供实时反馈。
有没有办法可以在应对连续场景上的优点,和离散场景在实时反馈上的优点结合呢?
比如演员-评论家算法。
这个算法分成两半,一半是演员,另一半是评论家。
-
演员:这一半基于概率分布,策略梯度算法。它有一个神经网络,可以根据行为的概率,选出行为。
-
评论家:这一半基于行为价值,DQN 算法。它有一个神经网络,可以根据行为的价值进行打分。
将概率分布和行为价值的方法相结合:
- 由基于概率分布的策略网络在连续场景中选出行为
- 由基于行为价值的价值网络给行为提供实时反馈
概率分布网络就像写作业的学生,行为价值网络就像批改作业的老师。
二者结合,反复地写作业、改作业,对比方法,找出最好的方法。
DQN(深度 Q 网络)= 深度神经网络 + Q-Learning
DQN 算法全称 深度Q网络,以 Q-Learning 算法为基础,融合了神经网络。
因为传统Q学习,不适合处理大规模数据(连续状态空间)的问题,就可用深度神经网络来近似Q函数。
Q-Learning
Q 值表示做出一个行为后能够获得的累计奖励,越大,越应该选择。
Q 值的组成是:当前状态s下,所有行为 a 的 Q 值。
那优化目标就是,每个状态(s)下都能做出 Q 值最大的行为(a),从而实现机器与环境的最优交互。
我们会使用表格用于存储和更新Q值,是因为这种方法提供了一种直观、清晰的方式来表示和跟踪每个状态和行为组合的预期回报。
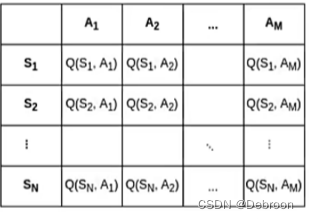
当状态和行为的数量非常庞大时,用表格储存所有数据会占用非常多的资源。
一般就会想到状态压缩,只保存与决策相关的几个最优可能来源。
但是在强化学习中,每个状态-动作对的历史信息都可能对学习最优策略至关重要,所以不能用状态压缩。
问题就是,输入状态s、行为a,怎么计算出 Q 值?
使用神经网络可以直接学习状态、行为、Q值的关系,输入状态,就能得到每个行为的Q值。
神经网络在这的功能:从存储 3 个值的排列组合,到只存储状态。
模型结构

-
现在的状态(St):
- 想象你在一个房间里(这就是现在的状态St),你有几个门可以选择出去(这些门是你可以采取的动作A)。
-
Q网络:
- Q网络就像一个超级计算机,它能告诉你选择每扇门的好处是什么(这就是Q(St, A),每个动作的预期奖励)。
-
选择动作和获得奖励(R):
- 根据Q网络的建议,你选择了一扇门并通过它(这就是你的动作A),然后你可能会找到一些糖果(这是你的奖励R)。
-
下一个状态(St+1):
- 通过门之后,你来到了另一个房间(这就是下一个状态St+1)。
-
target Q网络:
- 这里有另一个类似的超级计算机,它叫做 target Q 网络。它会计算在新房间里,选择下一扇门的好处,帮助你决定下一次应该选择哪扇门。
-
更新Q网络(loss):
- 你告诉第一个超级计算机你找到的糖果和第二个超级计算机的建议。第一个超级计算机会用这些信息来更新自己,变得更聪明,以便下次能给出更好的建议。
在这个过程中,Q网络不断学习和更新,目的是帮助你在这个房间的世界里找到更多的糖果。
每次你选择了一个动作并看到结果,Q网络都会变得更好,帮助你做出更好的选择。
损失函数
损失函数采用时序差分来,比较两个连续时间步的 Q 值来计算误差,并将这个误差用于更新神经网络的权重。
- DQN的损失函数用来衡量我们的预测(比如猜测)和实际发生的事情之间的差距。
在DQN中,损失函数特别关注的是预测的奖励(我们认为采取某个动作能得到多少好处)和实际得到的奖励(实际采取动作后得到的好处)之间的差别。

上图有 2 个 Q 网络,目标 Q 网络 是 S t + 1 S_{t+1} St+1。
损失函数更新Q值规则:
- Q ( s t , a t ) = Q ( s t , a t ) + α [ r t + 1 + γ max Q ( s t + 1 , a t + 1 ) ⏟ Target Value − Q ( s t , a t ) ] Q(s_t,a_t)=Q(s_t,a_t)+\alpha[\underbrace{r_{t+1}+\gamma\max Q(s_{t+1},a_{t+1})}_{\text{Target Value}}-Q(s_t,a_t)] Q(st,at)=Q(st,at)+α[Target Value rt+1+γmaxQ(st+1,at+1)−Q(st,at)]
使用均方差误差做损失函数:
- ω ∗ = arg min ω 1 2 N ∑ i = 1 N [ Q ω ( s t i , a t i ) − ( r t + 1 i + γ max a t + 1 Q ω ( s t + 1 i , a t + 1 ) ) ] 2 \omega^*=\arg\min_\omega\frac{1}{2N}\sum_{i=1}^N\left[Q_\omega\left(s_t^i,a_t^i\right)-\left(r_{t+1}^i+\gamma\max_{a_{t+1}}Q_\omega\left(s_{t+1}^i,a_{t+1}\right)\right)\right]^2 ω∗=argminω2N1∑i=1N[Qω(sti,ati)−(rt+1i+γmaxat+1Qω(st+1i,at+1))]2
Q w Q_{w} Qw 网络每步都更新,后面的 目标 Q 网络 隔几步才更新。
隔几步才更新目标Q网络是为了让训练更加稳定和有效,就像你在学习时每隔一段时间才询问朋友一样。
如果每步都听从朋友的建议,就会过于保守,完全用他的经验(使用已知的最佳动作)了,错过更好的动作选择。
经验回放
经验回放就像是给机器一个记事本,它可以在每次玩游戏后记下自己的经验(特别是已知的最佳动作)。
这个记事本包含了机器在不同游戏情况下的经验,比如在某个特定情况下采取了哪个动作,以及随后获得了多少奖励。
在执行任务的同时,将一部分数据(通常是状态、动作、奖励和下一个状态等信息)存储到经验池中,以供后续的训练使用。
在训练过程中不仅仅使用当前的经验来更新模型,还要积累更多的经验,以便在训练中使用更多的数据。这可以有几个好处:
-
稳定性:通过将多个时间步的经验存储到经验池中,可以减少训练数据的相关性,使训练更加稳定。这有助于防止模型陷入局部最优解或出现训练不稳定的情况。
-
重复利用经验:存储的经验可以多次用于训练,这有助于更有效地学习和提高样本的利用率。有时候,某些经验可能在一开始并不显著,但随着训练的积累,它们可能变得更有价值。
探索策略
但有一个问题:是选择已知的好方法(已知的最佳动作),还是尝试新方法(尝试新动作,可能有更好的方法)?
探索策略就是决定如何平衡这两种选择的方法。
如果一直按同一个按钮,它可能会错过更好的方法,但如果总是尝试新方法,它可能会很难取得进展。
在 ε-greedy 探索策略下,智能体以ε的概率选择随机动作(探索),以1-ε的概率选择当前认为最优的动作(利用)。
在一部分时间步中会尝试新的动作以发现更多信息,而在另一部分时间步中会选择已知的最佳动作以最大化奖励。
初始的时候,多探索ε要大,经验多了后,多利用ε减少
流程关联
-
Q-Learning(时间步0):
- 开始时,我们有一个深度神经网络(DNN),该网络的目标是学习在不同状态下采取不同动作的Q值,以获得最大的累积奖励。
- 我们初始化Q值网络,并且可以随机选择一个探索策略来探索环境。
-
探索策略:
- 在每个时间步骤,智能体使用探索策略来选择一个动作,如ε-greedy策略,这使得智能体有机会尝试新的动作。初始的时候,多探索ε要大,经验多了后,多利用ε减少
-
环境交互:
- 智能体采取选定的动作,并与环境互动,从环境中获得奖励(r_t+1)和新的状态(s_t+1)。
-
经验回放:
- 智能体将这次互动的信息(状态s_t、动作a_t、奖励r_t+1和下一个状态s_t+1)存储到经验池中。
-
损失函数计算:
- 定期或随机地,我们从经验池中抽取一些数据,这些数据用于计算损失函数。
- 损失函数的目标是调整深度神经网络DNN的参数( ω \omega ω),以使 Q 值网络的预测更接近真实的 Q 值。
- 损失函数通常是均方差误差(MSE),用来比较 Q 值网络的预测 Q 值和目标 Q 值(根据Q-Learning更新公式计算得出的值)之间的差异。
-
DNN参数更新:
- 使用损失函数的梯度,我们更新深度神经网络(DNN)的参数( ω \omega ω),以减小预测误差。
-
Q值网络更新:
- 周期性地或者在一定步骤之后,我们将Q值网络的权重更新为DNN的权重,以确保Q值网络也受到最新的训练影响。
-
探索策略更新:
- 随着训练的进行,我们可能会逐渐降低探索策略中的探索比例ε,以便智能体更多地依赖学到的Q值来做出决策,而不是随机探索。
-
重复:
- 重复执行上述步骤,不断与环境互动、收集经验、更新网络参数,直到智能体能够获得满意的策略并在任务中表现出色。
DQN 优化
DDQN:双 DQN,实现无偏估计

因为 DQN 的 Q 值更新是以下一个状态为参考,我们是神经网络近似估算给的都是最大值,层层传递,会导致偏大。
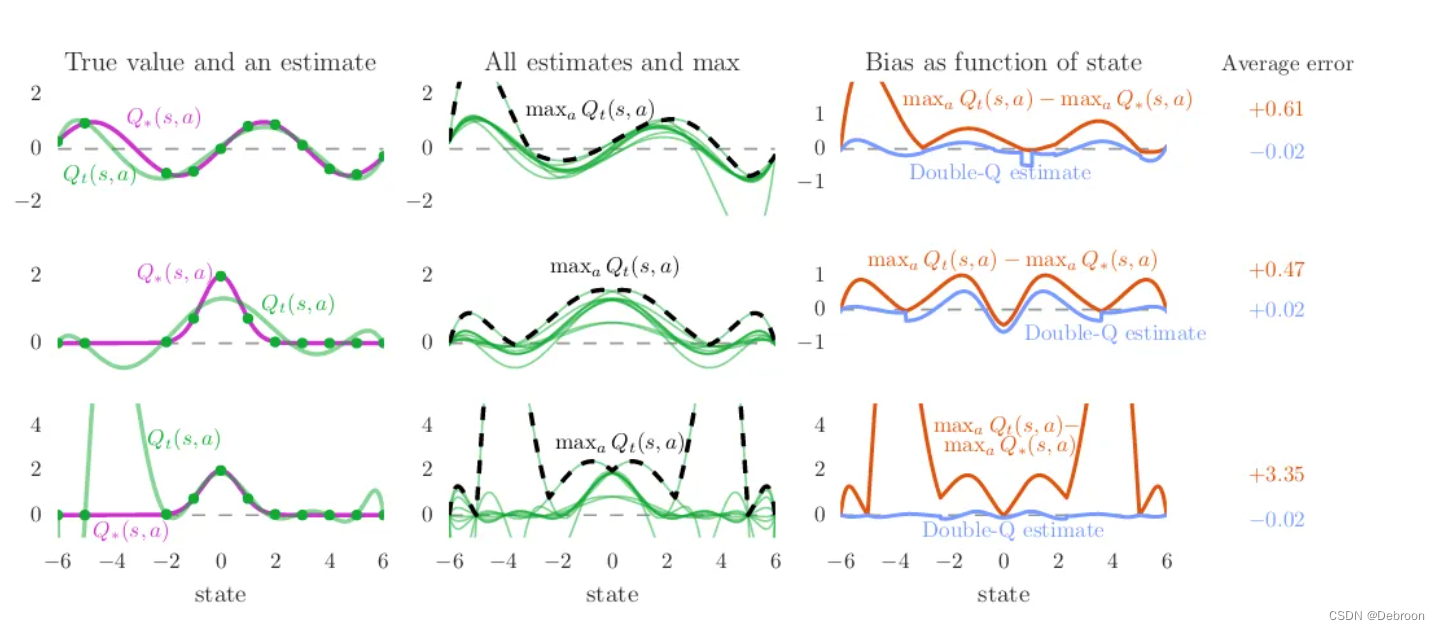
-
真实值和估计值(True value and an estimate):
- 紫色虚线表示真实值,也就是在游戏中某个动作实际的分数。
- 绿色实线表示我们的网络估计的值。在 DDQN 中,我们尝试让这条绿线尽可能接近紫线。
-
所有估计值和最大值(All estimates and max):
- 这里有三条绿色实线,每一条代表一个独立的网络在不同时间的估计。
- 黑色虚线代表这些估计中的最大值,DDQN 通过分开选择动作和评估动作的价值来避免过高估计这个最大值。
-
偏差作为状态函数(Bias as function of state):
- 橙色线代表使用传统方法(一个网络同时选择动作和评估价值)时的偏差。
- 蓝色线代表DDQN(分开网络)的偏差。我们可以看到蓝色线通常更接近零线,这意味着 DDQN 的估计更准确。
-
平均错误(Average error):
- 这个图展示了平均而言,传统方法和DDQN方法的误差大小。
- DDQN(蓝色线)的误差通常比传统方法(橙色线)的小,这表明 DDQN 提供了更准确的Q值估计。
在 DDQN 中,我们用两个网络分别来选择动作和评估动作的价值,这样做可以减少估计中的偏差和误差,而不是过分依赖单一的估计。
DDQN 只改变了目标值的计算方法,其他地方与DQN算法完全一致。
- 让Q网络、Q 目标网络,俩个网络相互监督。
就像是有两个智能助手:
- 一个助手(目标网络)负责告诉你下一步最好的行动方向
- 另一个助手(估算网络)则用来判断这个行动有多好。
这两个助手轮流工作,确保你既知道往哪走,又不会对前方的好处期望过高。
损失函数的变化:
Q ( s t , a t ) ⟷ r t + 1 + γ Q ′ ( s t + 1 , a r g m a x a Q ( s t + 1 , a ) ) Q(s_t,a_t)\longleftrightarrow r_{t+1}+\gamma Q'\left(s_{t+1},\mathop{\mathrm{argmax}}_aQ\left(s_{t+1},a\right)\right) Q(st,at)⟷rt+1+γQ′(st+1,argmaxaQ(st+1,a))
具体来说:
-
估算网络(Evaluation Network):
- 这个网络在每一步学习中都会更新。它基于最新的游戏数据(如玩家的动作和得到的奖励)来预测Q值,即每一个可能动作的期望奖励。
-
目标网络(Target Network):
- 这个网络与估算网络结构相同,但它不会在每一步都更新。目标网络的参数会定期地、较慢地更新,例如,每N步学习之后,目标网络会复制估算网络的参数。这样可以提供一个相对稳定的目标值,以供估算网络学习。
-
相互监督的实现:
- 当智能体从环境中收集数据并需要更新估算网络的参数时,它会计算两部分信息:
- 使用估算网络选出最好的动作(即在当前状态下预测未来奖励最大的动作)。
- 使用目标网络评估这个最好动作的Q值(即这个最好动作的未来奖励)。
- 当智能体从环境中收集数据并需要更新估算网络的参数时,它会计算两部分信息:
-
结合使用两个网络的优势:
- 由于估算网络趋向于过估计Q值,通过使用目标网络的稳定性来评估这个最好动作的Q值,算法可以减少估算网络可能带来的过度乐观的预测。
- 在实际更新估算网络的参数时,会用目标网络的这个评估值作为学习目标,而不是直接用估算网络的输出。
通过这种方式,两个网络相互监督,一个提供动作选择的建议,另一个提供稳定的目标值,共同工作以实现更准确的学习和决策过程。
Dueling DQN:提高决策的准确性和效率
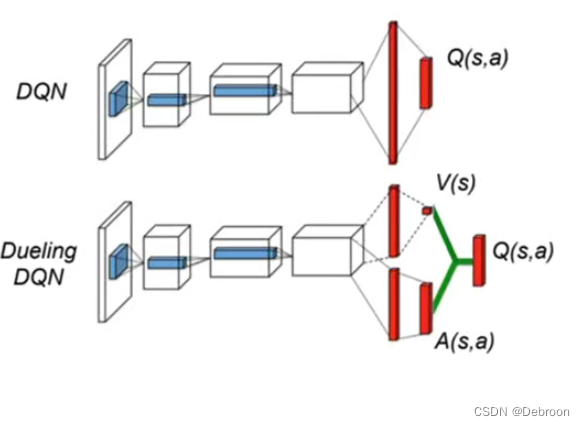
Dueling DQN 的核心思想是将 Q 值的估计分解为两个独立的部分:状态值(Value)和优势值(Advantage)。
-
状态值(V(s)):这是在给定状态下,不考虑任何具体动作的情况下,智能体预计能获得的总回报。简单来说,它反映了仅凭当前状态就能判断的智能体处境的好坏。
-
优势值(A(s, a)):这个值衡量了相对于其他可能动作,选择某个特定动作可能带来的额外回报。如果一个动作比其他动作好得多,它的优势值就会更高。
然后,这两个值合并起来,形成了对每个动作的 Q 值的估计:
- Q ( s , a ) = V ( s ) + A ( s , a ) Q(s,a)=V(s)+A(s,a) Q(s,a)=V(s)+A(s,a)
但这里有一个问题:如果我们简单地加起来,可能会有多个状态和动作对的组合导致相同的 Q 值,这样就不能正确地学习它们的区别了。
为了解决这个问题,Dueling DQN 使用了一个技巧来稳定学习过程:它会从每个动作的优势值中减去所有动作优势值的平均值:
- Q ( s , a ) = V ( s ) + ( A ( s , a ) − mean a A ( s , a ) ) Q(s,a)=V(s)+(A(s,a)-\text{mean}_aA(s,a)) Q(s,a)=V(s)+(A(s,a)−meanaA(s,a))
强制让没有优势的动作(也就是平均动作)的优势值为零。
这样的结构使得网络能够更加明确地区分出在决策中状态价值和动作选择的影响。
一部分帮你看到当前位置的总体价值(比如这是不是一个好地方),另一部分让你看到每个动作(比如跳跃、下蹲或向右移动)的特别价值。
这样你就能更清楚地知道是继续在当前位置探索好,还是采取某个特别动作好。
DDQN改善了训练过程的稳定性并减少了估值偏差,而Dueling-DQN通过独立评估状态的总体价值和每个动作的相对优势,提高决策的准确性和效率。
Noisy DQN:增强模型的探索能力
在传统的DQN中,探索通常是通过 ε-greedy 策略实现的,即智能体有一定概率(ε)随机选择动作(探索),而不是总是选择它认为最好的动作(利用)。
随着训练的进行,这个概率逐渐降低,智能体越来越多地选择它认为的最佳动作。
Noisy DQN 采用了不同的方法来实现探索。它在网络的参数上添加可学习的噪声,使得即使在选择最佳动作时,智能体的行为也会有一定的随机性。
Noisy DQN 的创新之处在于它引入了噪声,直接添加到网络的参数中,而不是依靠外部的随机探索策略(如ε-greedy)。
这样做的好处是:
-
自动调整探索率:在Noisy DQN中,探索是通过网络内部的噪声决定的。随着训练的进行和智能体学习的改进,这个内部噪声可以自动调整,从而调整探索的程度。
-
更有效的探索:由于噪声是直接加在网络参数上的,这种方法可能比传统的随机探索更有效,因为它允许网络学习何时探索以及如何探索,而不是简单地随机选择动作,避免过早陷入固定行为模式(过度依赖经验)。
优先级经验回放
对传统的经验回放机制进行了改进。
在标准的经验回放中,智能体在训练过程中收集的经验(即从环境中得到的状态、动作、奖励和新状态的数据)被存储在一个记忆缓冲区中,然后这些经验被随机抽取来训练智能体。
这个方法的一个局限性是它假设所有经验都同等重要,但实际上并非如此。
优先级经验回放的核心思想是,某些经验比其他经验更有价值,应该更频繁地用于训练。
这种方法通过赋予每个经验一个优先级来实现,让学习率高的状态权重更大。
- Q ( s t , a t ) = Q ( s t , a t ) + α [ r t + 1 + γ max Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ⏟ T D e r r o r ] Q(s_{t},a_{t})=Q(s_{t},a_{t})+\alpha[\underbrace{r_{t+1}+\gamma\operatorname*{max}Q(s_{t+1},a_{t+1})-Q(s_{t},a_{t})}_{\mathrm{TD~error}}] Q(st,at)=Q(st,at)+α[TD error rt+1+γmaxQ(st+1,at+1)−Q(st,at)]
-
当前状态和动作(( s_t, a_t )):
- 在时间 ( t ),智能体在状态 ( s_t ) 中,并选择了动作 ( a_t )。
-
Q值更新(( Q(s_t, a_t) ) 更新):
- ( Q(s_t, a_t) ) 是当前状态和动作对应的预期奖励值。我们想要更新这个值,使其更接近实际的预期奖励。
-
学习率 ( α \alpha α):
- α \alpha α 是学习率,它决定了新信息覆盖旧信息的程度。如果 α \alpha α 很大,新信息就会更快地覆盖旧信息。
-
即时奖励 ( r t + 1 ) ( r_{t+1} ) (rt+1):
- r t + 1 r_{t+1} rt+1 是智能体在时间 ( t+1 ) 获得的即时奖励,即在状态 ( s_t ) 采取动作 ( a_t ) 后得到的奖励。
-
折扣因子 ( γ ) (\gamma ) (γ):
- ( γ ) (\gamma ) (γ) 是折扣因子,用于调整未来奖励的重要性。一个较低的 ( γ ) (\gamma ) (γ) 使智能体更专注于即时奖励,而较高的 ( γ ) (\gamma ) (γ)使智能体更考虑长远奖励。
-
最大未来奖励( max Q ( s t + 1 , a t + 1 ) \max Q(s_{t+1}, a_{t+1}) maxQ(st+1,at+1)):
- max Q ( s t + 1 , a t + 1 ) \max Q(s_{t+1}, a_{t+1}) maxQ(st+1,at+1) 是在下一个状态 s t + 1 s_{t+1} st+1 中所有可能动作的最大Q值,代表了智能体对未来最优动作的最佳预期奖励。
-
时序差分(Temporal Difference Error):
- r t + 1 + γ max Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) r_{t+1} + \gamma \max Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t) rt+1+γmaxQ(st+1,at+1)−Q(st,at)是TD误差,它代表了当前Q值和包括即时奖励及未来最大奖励的新估计之间的差异。
-
更新规则:
- 最后,整个公式 Q ( s t , a t ) = Q ( s t , a t ) + α [ T D e r r o r ] Q(s_t, a_t) = Q(s_t, a_t) + \alpha [TD~error] Q(st,at)=Q(st,at)+α[TD error] 表示用TD误差更新当前的Q值,以更好地估计在状态 ( s_t ) 下采取动作 ( a_t ) 的长期奖励。
OpenAI Q* :超越人类的自主系统
OpenAI在11月22号,给公司人员发了一封内部信,承认了 Q*,并将这个项目描述为 “超越人类的自主系统”。
Q* 是在搞 过程监督,通过奖励推理的每个正确步骤。
而不仅仅是结果监督,奖励正确的最终答案。
Q* 是 Q-learning 和 A* (可能)的组合,能大幅度提升推理能力,用于解决数学中高难度问题。
openai研究 Q-learning 的成果:https://noambrown.github.io。

Q-learning 需要大量的探索(左图二基本遍历完了),A* (左图三只遍历了一部分)。
Q* 结合了双方的优点(左图四):
- 更高效选择策略:高效地学习最优策略,并且可以用于部分可观察的环境
- 自我修剪:评估并去除其模型中不必要的部分,以提高效率和决策的过程,类似于一个人反思自己的思想和行为,实现自我提升。
- 迁移学习:使 Q-learning 模型在一个领域受过训练后能够将其知识应用于不同但相关的领域的技术,比如会开摩托,学习自行车就很容易
- 创造和不可知能力:在Q-learning框架中实现元学习可以使人工智能学会如何学习,这是一种自省创造性解决问题,提出以前没有考虑过的新颖的解决方案,如破解密码系统或发明新的数学方法。
最强的是不可知能力,成功破解了现代加密算法 AES,但是不可知。
相关文章:
【OpenAI Q* 超越人类的自主系统】DQN :Q-Learning + 深度神经网络
深度 Q 网络:用深度神经网络,来近似Q函数 强化学习介绍离散场景,使用行为价值方法连续场景,使用概率分布方法实时反馈连续场景:使用概率分布 行为价值方法 DQN(深度 Q 网络) 深度神经网络 Q-L…...

Vue axios Post请求 403 解决之道
前言: 刚开始请求的时候报 CORS 错误,通过前端项目配置后算是解决了,然后,又开始了新的报错 403 ERR_BAD_REQUEST。但是 GET 请求是正常的。 后端的 Controller 接口代码如下: PostMapping(value "/login2&qu…...
【Leetcode】重排链表、旋转链表、反转链表||
目录 💡重排链表 题目描述 方法一: 方法二: 💡旋转链表 题目描述 方法: 💡反转链表|| 题目描述 方法: 💡总结 💡重排链表 题目描述 给定一个单链表 L 的头节…...
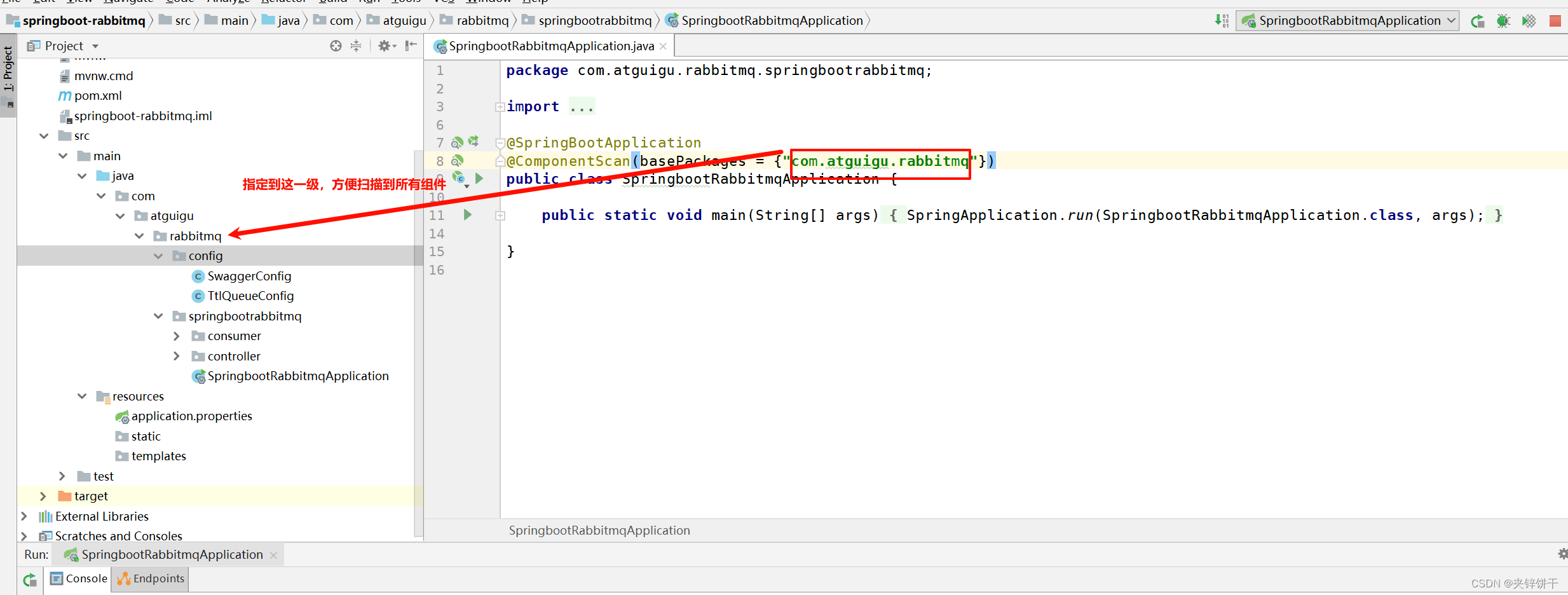
RabbitMQ 报错:Failed to declare queue(s):[QD, QA, QB]
实在没想到会犯这种低级错误。 回顾整理一下吧: 原因:SpringBoot主配置类默认只会扫描自己所在的包及其子包下面的组件。其他位置的配置不会被扫描。 如果非要使用其他位置,就需要在启动类上面指定新的扫描位置。注意新的扫描位置会覆盖默…...
Neo4j 5建库
Neo4j 只有企业版可以运行多个库,社区版无法创建多个库,一个实例只能运行一个库; 如果业务需要使用多个库怎么办呢? 就是在一个机器上部署多个实例,每个实例单独一个库名 这个库的名字我们可以自己定义; …...

鲁棒最小二乘法 拟合圆
圆拟合算法_基于huber加权的拟合圆算法-CSDN博客 首次拟合圆得到采用的上述blog中的 Ksa Fit 方法。 该方法存在干扰点时,拟合得到的结果会被干扰。 首次拟合圆的方法 因此需要针对外点增加权重因子,经过多次迭代后&…...

LeetCode——动态规划
动态规划 一、一维数组:斐波那契数列 爬楼梯70简单 dp定义: dp[i]表示爬到第i阶有多少种不同的方式 状态转移方程: dp[i] dp[i-1] dp[i-1] (每次可以爬1或2个台阶) 边界条件: dp[0] 1; dp[1] 1;&#…...

opencv和gdal的读写图片波段顺序问题
最近处理遥感影像总是不时听到 图片的波段错了,一开始不明就里,都是图片怎么就判断错了。 1、图像RGB波段顺序判断 后面和大家交流,基本上知道了一个判断标准。 一般来说,进入人眼的自然画面在计算机视觉中一般是rgb波段顺序表示…...

PyQt 打包成exe文件
参考链接 Python程序打包成.exe(史上最全面讲解)-CSDN博客 手把手教你将pyqt程序打包成exe(1)_pyqt exe-CSDN博客 PyInstaller 将DLL文件打包进exe_怎么把dll文件加到exe里-CSDN博客 自己的问题 按照教程走的话,会出现找不到“mmdeploy_ort_net.dll”文件的报错…...
)
【Web2D/3D】SVG(第二篇)
1. 前言 SVG(Scalable Vector Graphics,可缩放矢量图形)是一种使用XML描述2D图形的语言,由于SVG是基于XML(HTML也是基于XML的),因为SVG DOM中每个元素都是可以操作的,包含修改元素属…...

leetcode18. 四数之和
题目描述 给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复): …...
(十八)Flask之threaing.local()对象
0、引子: 如下是一段很基础的多线程代码: from threading import Threaddemo 0def task(arg):global demodemo argprint(demo)for i in range(10):t Thread(targettask, args(i, ))t. start()当程序运行时,可能会看到输出的顺序是混乱的…...
ffmpeg 硬件解码零拷贝unity 播放
ffmpeg硬件解码问题 ffmpeg 在硬件解码,一般来说,我们解码使用cuda方式,当然,最好的方式是不要确定一定是cuda,客户的显卡不一定有cuda,windows 下,和linux 下要做一些适配工作,最麻…...
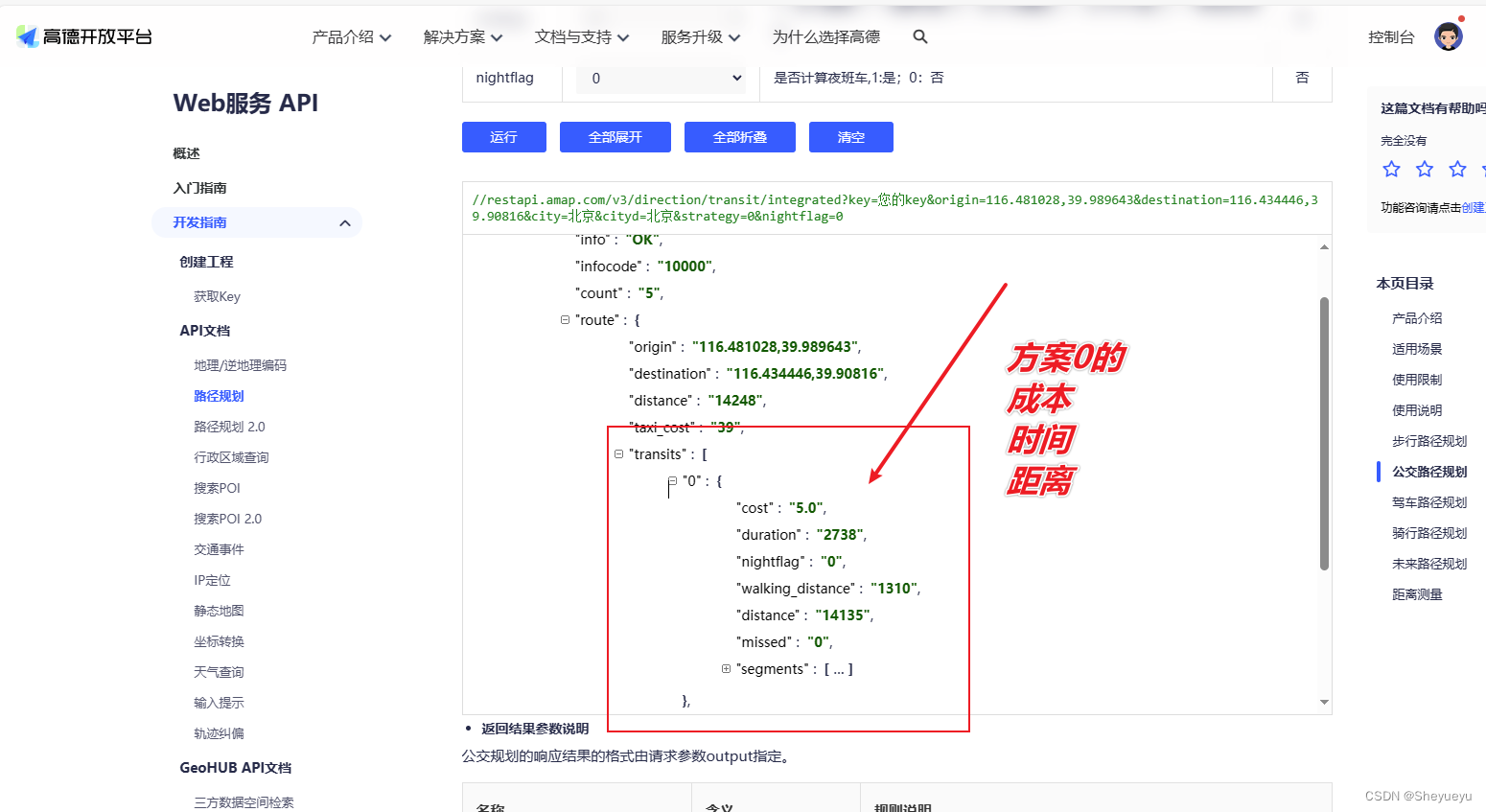
高德地图_公共交通路径规划API,获取两地点之间的驾车里程和时间
import pandas as pd import requests import jsondef get_dis_tm(origin, destination,city,cityd):url https://restapi.amap.com/v3/direction/transit/integrated?key xxx #这里就是需要去高德开放平台去申请key,请在xxxx位置填写,web服务APIlink {}origin{}&desti…...

PyTorch深度学习实战(28)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(28)——对抗攻击 0. 前言1. 对抗攻击2. 对抗攻击模型分析3. 使用 PyTorch 实现对抗攻击小结系列链接 0. 前言 近年来,深度学习在图像分类、目标检测、图像分割等诸多领域取得了突破性进展,深度学习模型已经能…...
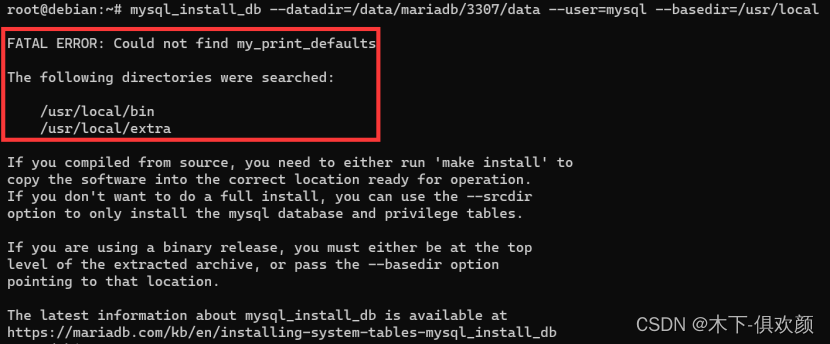
MariaDB单机多实例的配置方法
1、什么是数据库的单机多实例 数据库的单机多实例是指在一台物理服务器上运行多个数据库实例。这种部署方式允许多个数据库实例共享相同的物理资源,如CPU、内存和存储,从而提高硬件利用率并降低成本。每个数据库实例可以独立运行,处理不同的…...
加强->servlet->tomcat
0什么是servlet jsp也是servlet 细细体会 Servlet 是 JavaEE 的规范之一,通俗的来说就是 Java 接口,将来我们可以定义 Java 类来实现这个接口,并由 Web 服务器运行 Servlet ,所以 TomCat 又被称作 Servlet 容器。 Servlet 提供了…...

Python初学者必须吃透的69个内置函数!
所谓内置函数,就是Python提供的, 可以直接拿来直接用的函数,比如大家熟悉的print,range、input等,也有不是很熟,但是很重要的,如enumerate、zip、join等,Python内置的这些函数非常精巧且强大的&…...
Day73力扣打卡
打卡记录 统计移除递增子数组的数目 II(双指针) 链接 class Solution:def incremovableSubarrayCount(self, a: List[int]) -> int:n len(a)i 0while i < n - 1 and a[i] < a[i 1]:i 1if i n - 1: # 每个非空子数组都可以移除return n …...

Android原生实现分段选择
六年前写的一个控件,一直没有时间总结,趁年底不怎么忙,整理一下之前写过的组件。供大家一起参考学习。废话不多说,先上图。 一、效果图 实现思路使用的是radioGroup加radiobutton组合方式。原理就是通过修改RadioButton 的backgr…...

除了高精度定位,CORS基准站网还能为你提供哪些意想不到的数据服务?
解锁CORS基准站网的隐藏价值:从厘米级定位到时空大数据平台 当大多数人提起CORS基准站网时,第一反应往往是"高精度定位"。确实,这套由数百个地面站点组成的网络系统,能够为各类GNSS设备提供实时厘米级甚至毫米级的定位修…...
)
别再死记0.7V了!用Multisim仿真带你玩转二极管三种等效模型(附实战电路分析)
用Multisim仿真破解二极管模型的三大迷思:从理论到实战的深度探索 在电子工程的学习道路上,二极管总是那个让人又爱又恨的元件。它看似简单,却藏着无数让初学者抓狂的细节。你是否也曾困惑:为什么教科书总说硅管压降是0.7V&#x…...

阿里云Ubuntu22..04安装jdk21、MySQL8、nginx
推荐直接: Ubuntu 22.04下面全部基于: root 用户 Ubuntu 22.04展开。一、先更新系统 apt update && apt upgrade -y安装基础工具: apt install -y wget curl vim unzip net-tools二、安装 JDK21(推荐 Temurin)…...

不止于解题:聊聊猪圈密码、圣堂武士密码和标准银河字母背后的历史与趣闻
不止于解题:猪圈密码、圣堂武士密码与标准银河字母的文化考古 当你在CTF竞赛中第一次遇到那些神秘的几何符号时,是否曾好奇过这些图形背后的故事?从共济会的秘密集会到《我的世界》游戏中的彩蛋,图形密码早已超越了单纯的加密工具…...

Fast-GitHub:智能网络优化架构解析与分布式加速方案
Fast-GitHub:智能网络优化架构解析与分布式加速方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 在国内开发者面临G…...

2026年婚礼背景音乐素材下载网站TOP5:从版权、曲库到实用场景全面评测
引言:为什么婚礼背景音乐素材越来越需要“可商用、可溯源、可快速下载” 2026年,婚礼内容已经不再只是一支婚礼纪录片,而是拆分成婚礼预告片、接亲快剪、仪式短片、First Look、婚礼跟拍花絮、短视频平台竖版成片、婚庆公司案例展示等多个内…...

Spike Prime避坑指南:Python控制电机和传感器时,新手最常遇到的5个错误及解决方法
Spike Prime避坑指南:Python控制电机和传感器时新手最常遇到的5个错误 第一次用Python控制Spike Prime的电机和传感器时,那种期待和兴奋很快就会被各种报错消磨殆尽。明明照着官方文档写的代码,电机就是不转;传感器读数永远为零&a…...

【YOLOv5 v6.1】从零到一:手把手实战自定义数据集训练与部署避坑指南
1. 环境准备:从零搭建YOLOv5训练环境 第一次接触YOLOv5时,我最头疼的就是环境配置。这里分享一个经过多次验证的稳定方案,适用于大多数NVIDIA显卡设备。首先需要安装Anaconda,这是管理Python环境的利器。我习惯用Miniconda&#x…...

qpOASES终极指南:5分钟快速安装配置与二次规划求解器应用教程
qpOASES终极指南:5分钟快速安装配置与二次规划求解器应用教程 【免费下载链接】qpOASES Open-source C implementation of the recently proposed online active set strategy 项目地址: https://gitcode.com/gh_mirrors/qp/qpOASES 你是否曾为复杂的二次规划…...

AArch64虚拟内存系统架构与硬件自动更新机制详解
1. AArch64虚拟内存系统架构概述AArch64是ARMv8及ARMv9架构的64位执行状态,其虚拟内存系统架构(Virtual Memory System Architecture)是现代ARM处理器的核心组成部分。这套系统通过多级页表机制实现虚拟地址到物理地址的转换,为操…...