【分布式链路追踪技术】sleuth+zipkin


目录
1.概述
2.搭建演示工程
3.sleuth
4.zipkin
5.插拔式存储
5.1.存储到MySQL中
5.2.用MQ来流量削峰
6.联系作者
1.概述
当采用分布式架构后,一次请求会在多个服务之间流转,组成单次调用链的服务往往都分散在不同的服务器上。这就会带来一个问题:
故障难以溯源。
发起请求,然后请求报错,到底是调用链中哪一环出了问题?很难以定位。这时候就需要用到链路追踪技术了。所谓的链路追踪技术,也就是想办法让分布式系统中的单次请求的链路调用成为可被追踪的,便于在出现故障的时候进行快速的定位溯源。
目前有两套实现思路:
-
基于日志来实现,常用到的有Sleuth、zipkin
-
基于agent来实现,常用到的有skywaiking
本文讲解的是其中基于日志实现的sleuth以及其配套的可视化套件zipkin。
关于分布式链路追踪作者上文讲过详细的概论:
https://bugman.blog.csdn.net/article/details/135175596?spm=1001.2014.3001.5502
2.搭建演示工程
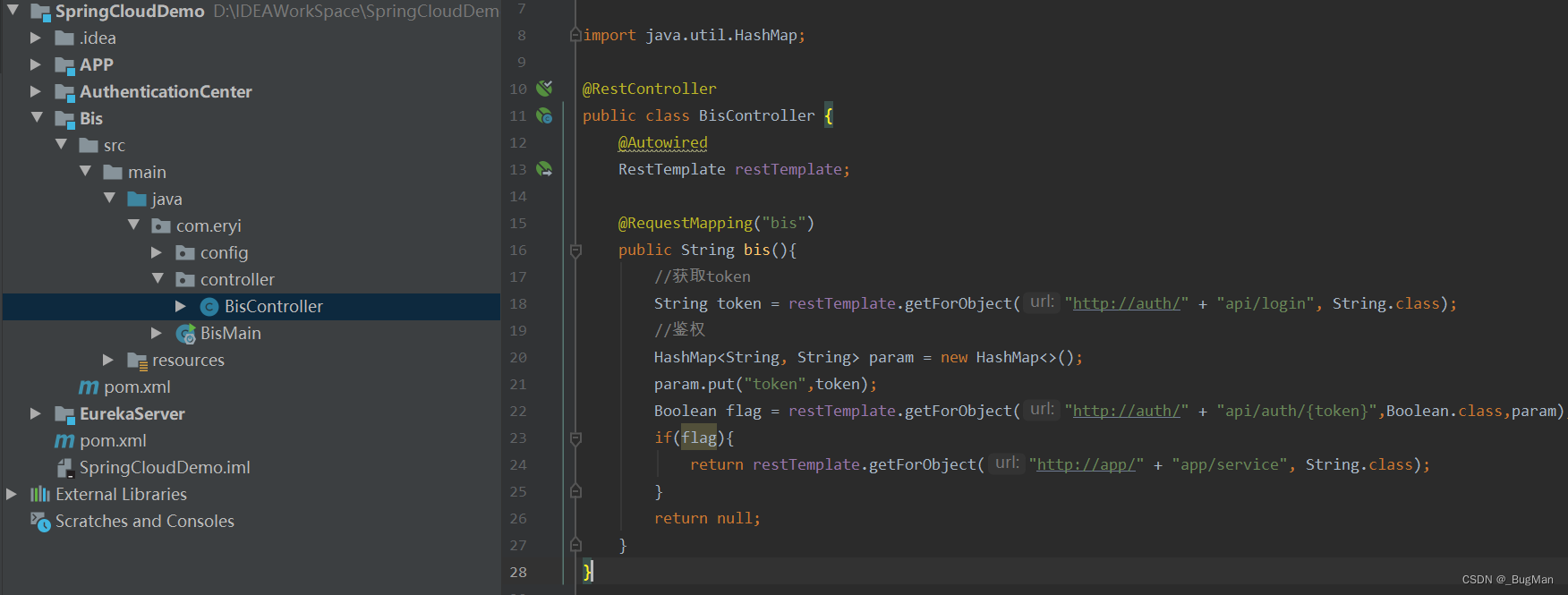
本次用于演示的工程很简单,用spring cloud来搭建三个服务,一个app服务用来提供服务,一个鉴权中心用来登录以及鉴权,一个bis服务用来聚合:

在bis中调用鉴权中心来登录获取token,然后校验token,校验通过后调用app提供的服务:
spring cloud的成体系的文章,在博主的另一个专栏,从0开始一步步深入浅出(该系列登上过2023年的新星计划):
http://t.csdnimg.cn/PDgr3
3.sleuth
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>3.1.8</version>
</dependency>
去访问bis,会看到:
bis的日志:

AuthenticationCenter的日志:

APP的日志:

我想到这里很多读者会有个疑问。
问:
sleuth这么保证一个链路上的traceID是相同的?
答:
当一个请求进入 Spring Cloud 的微服务系统时,Sleuth 会生成一个唯一的 Trace ID。如果请求是从另一个使用 Sleuth 的服务传入的,Sleuth 会提取并使用该服务传入的 Trace ID。Sleuth 集成了这些通信协议,如HTTP协议,并在服务间调用时自动将 Trace ID 添加到 HTTP 请求的头部、消息的元数据等中。
4.zipkin
光有了日志,进行问题排查还是要一条条的翻,还是很繁琐。所以配套出现了可视化套件,由推特开发的——zipkin。其能对标准opentracing格式的日志进行收集和展示。zipkin采用的标准的CS架构,client向server发数据。
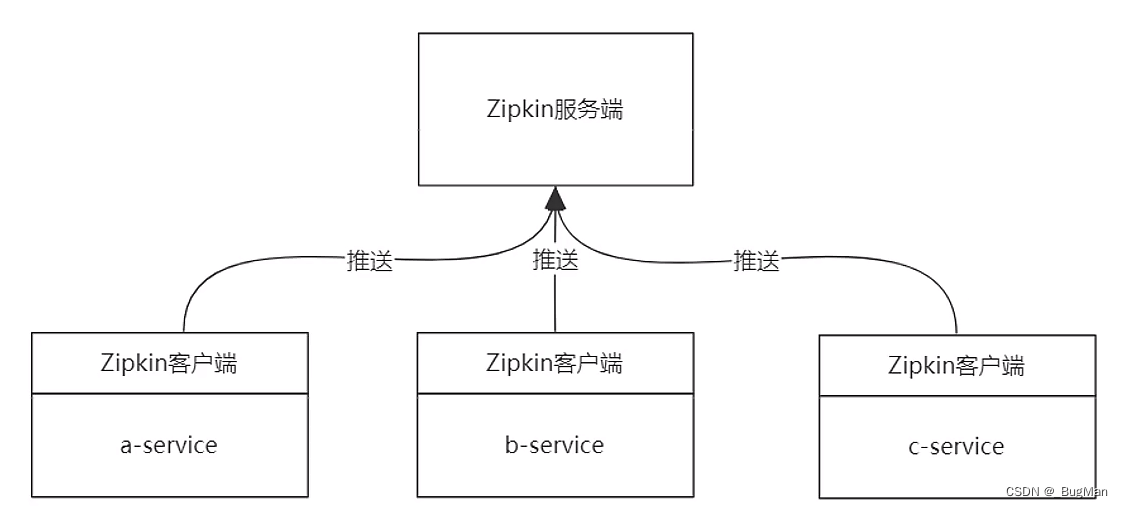
服务端:
服务端是一个jar包,直接跑起来就可以,下载地址:
Central Repository: io/zipkin/zipkin-server
客户端:
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
配置:
#zipkin server地址
spring.zipkin.base-url=http://localhost:9411/
#client向server发送数据的方式,web,http报文
spring.zipkin.sender.type=web
效果:
zipkin的启动日志里已经清晰的告诉了Web界面的访问地址是多少:

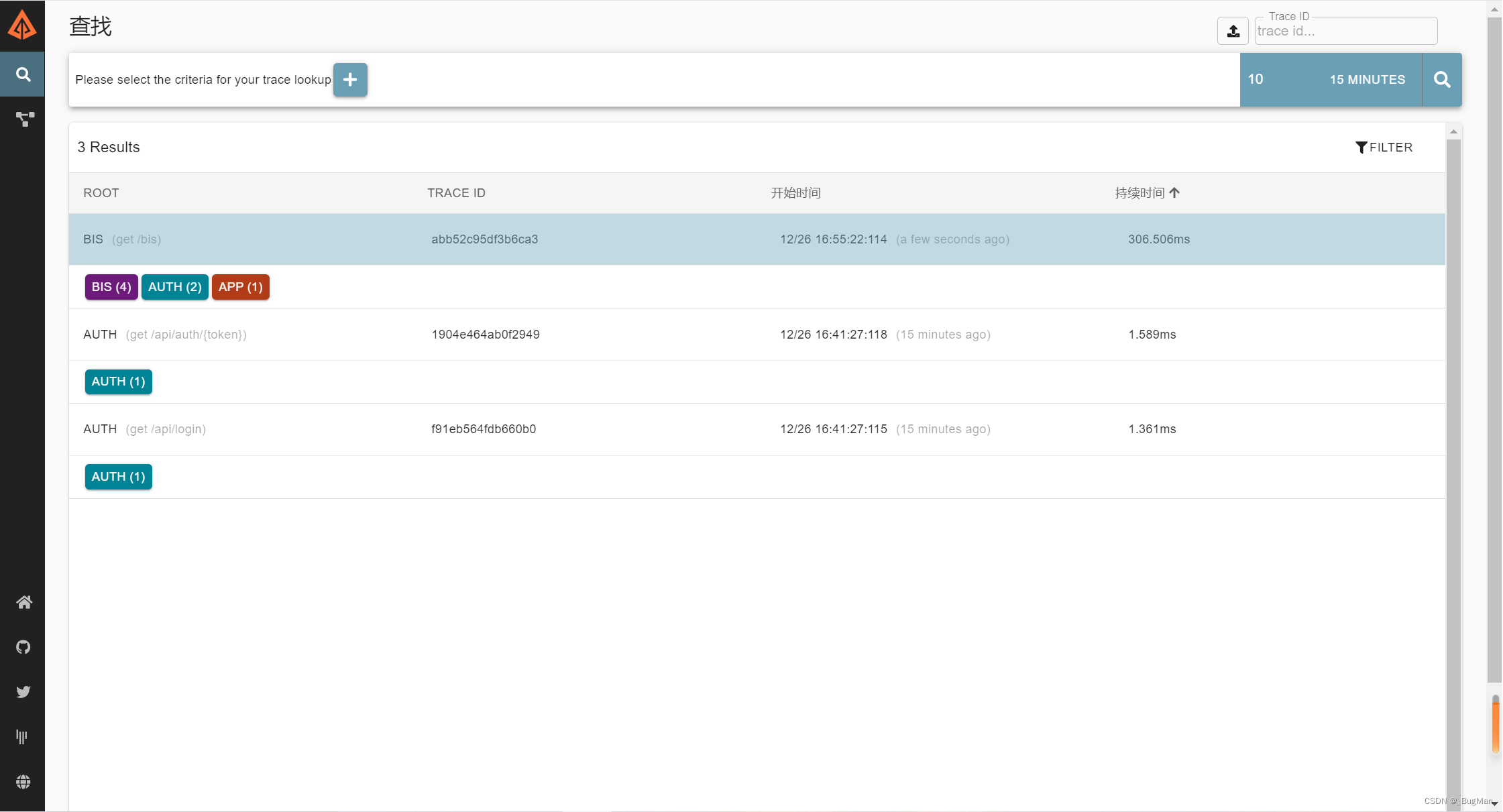
访问127.0.0.1:9411/可以看到:
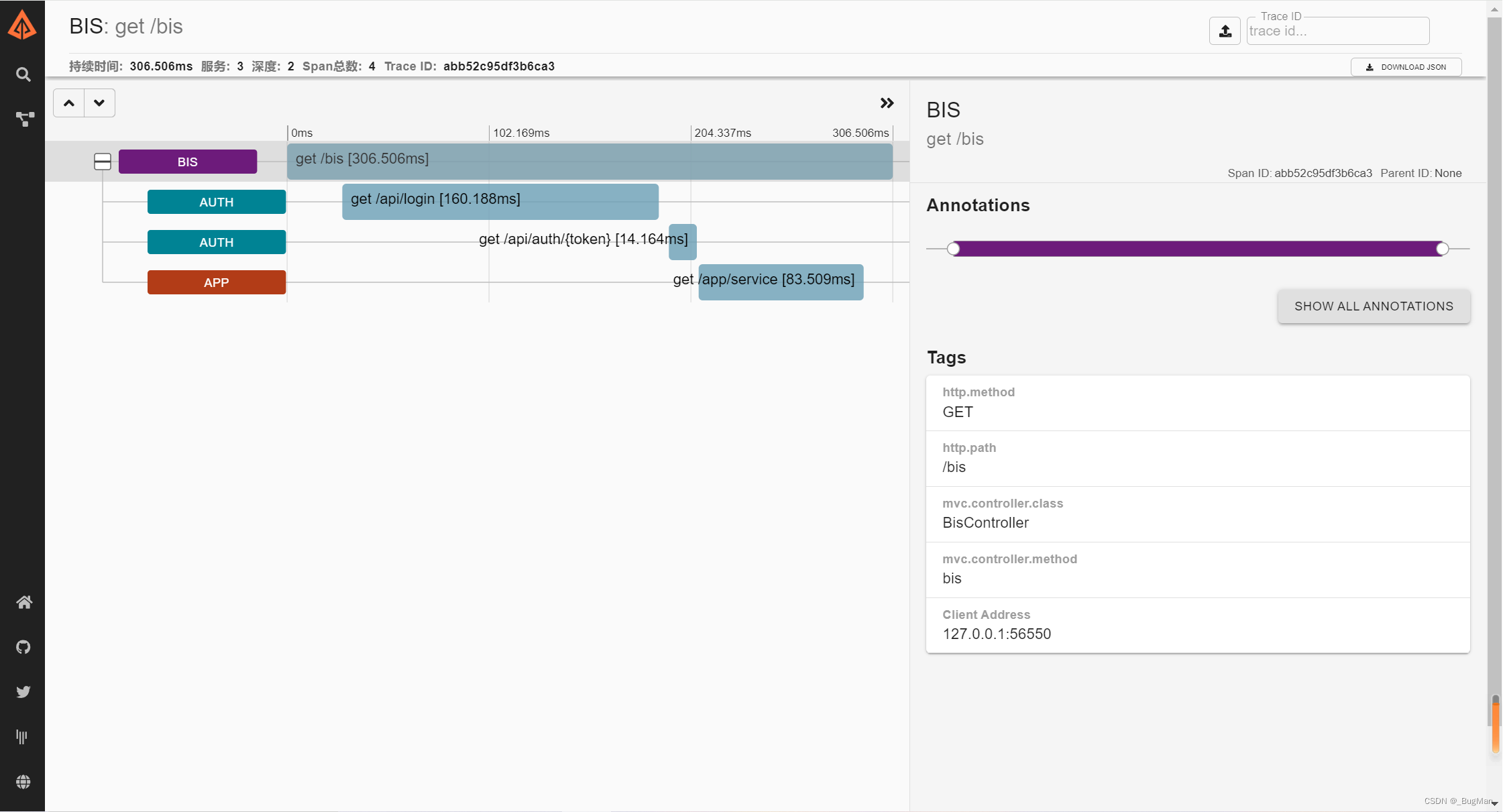
点进链路可以看到单次请求的详细内容:
5.插拔式存储
zipkin从各个client中收集到的server上的数据存到哪儿去?默认是将数据存储在内存中,除此之外zipkin还支持多种数据的存储方式,如mysql、ES等,根据场景需要可自行切换。
5.1.存储到MySQL中
要存储到MySQL中首先当然是要先建表,zipkin在项目文件中自带了mysql的建表脚本:
https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
server的源码工程的配置文件中可以看到,存储默认是内存,参数有默认值,但是支持传参来设置:
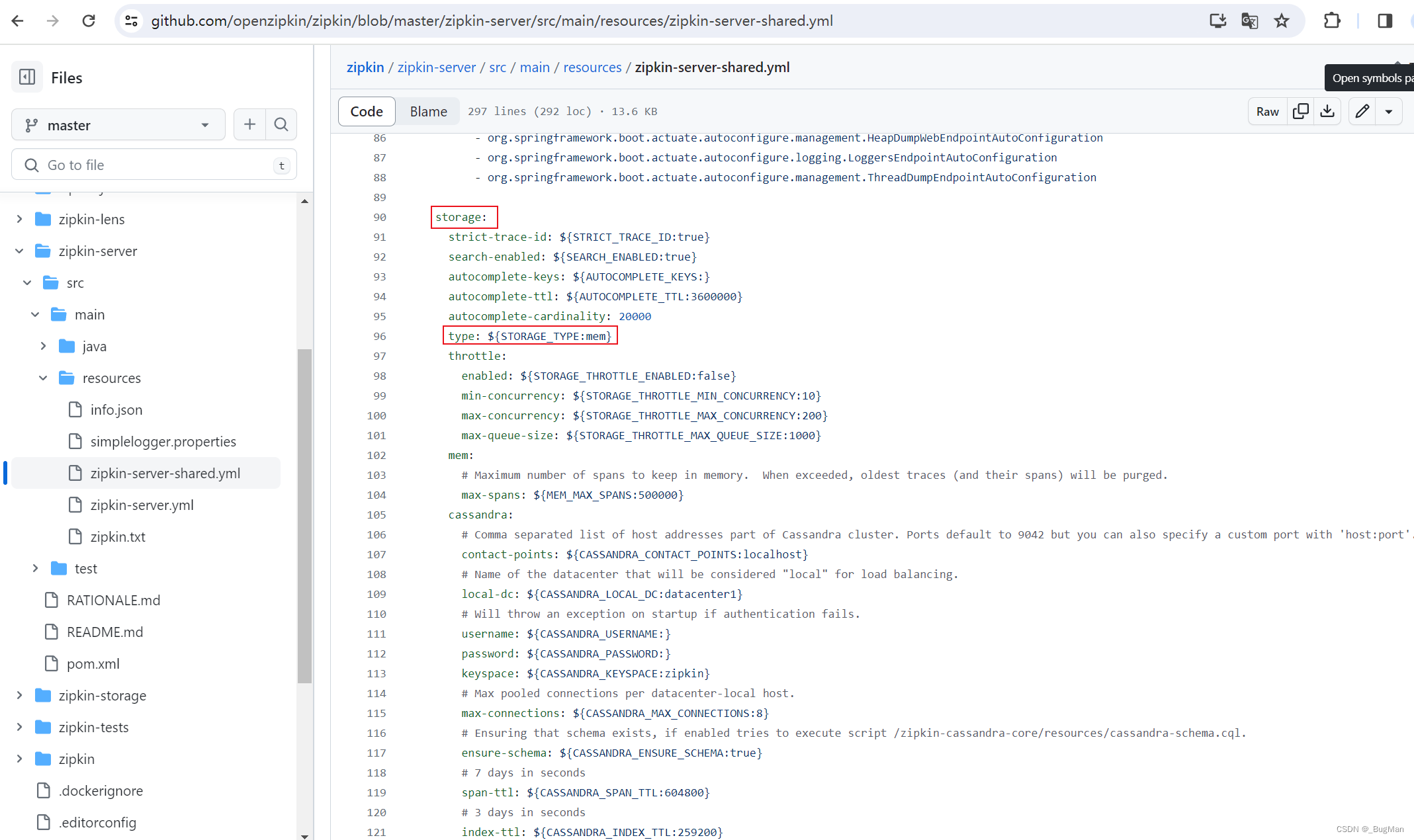
所以在用java -jar启动的时候可以通过跟参数的方式来切换存储类型:
java -jar zipkin-server-2.20.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSOL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=admin --MYSQL_DB=zipkin
这样数据就会存进MySQL中来进行持久化了。
5.2.用MQ来流量削峰
zipkin支持多种数据的存储方式,如mysql、ES等,默认是将数据存储在内存中。
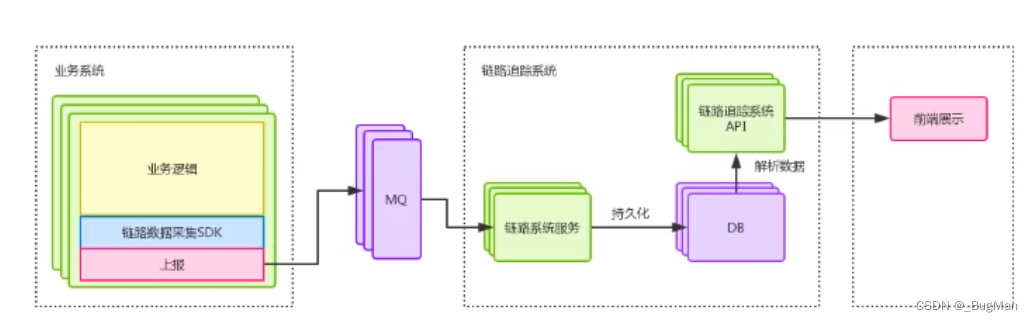
server端:
从配置文件中可以看到,zipkin server支持Kafka、rabbitMQ等多种MQ,具体配置是用启动传参的方式来配置的:

想用哪种MQ,直接去配置即可,这里以rabbitMQ为例:
java -jar zipkin-server-2.20.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSOL-TCP-PORT=3306 --MYSOL_USER=root --MYSQL_PASS=admin --MYSQL_DB=zipkin --RABBIT_ADDRESSES=10.1.2.10:5672 --RABBIT_USER=quest --RABBIT_PASSWORD=guest --RABBIT_VIRTUAL_HOST=/ --RABBIT_QUEUE=zipkin
client端:
client端增加以下关于mq的配置:
#zipkin server地址
spring.zipkin.base-url=http://localhost:9411/
#client向server发送数据的方式,rabbitmq
spring.zipkin.sender.type=rabbit
#队列名称
spring.zipkin.rabbitmq.queue=zipkin
#服务器IP、端口号、账户名、密码
spring.rabbitmq.host=10.1.2.10
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
#虚拟主机地址
spring.rabbitmq.virtual-host=/
#是否开启发布重试
spring.rabbitmq.listener.direct.retry.enabled=true
#最大重试次数
spring.rabbitmq.listener.direct.retry.max-attempts=5
#重试间隔时间
spring.rabbitmq.listener.direct.retry.initial-interval=5000
#是否开启消费者重试
spring.rabbitmq.listener.simple.retry.enabled=true
#最大重试次数
spring.rabbitmq.listener.simple.retry.max-attempts=5
#最大间隔时间
spring.rabbitmq.listener.simple.retry.initial-interval=5000
6.联系作者
公众号:
博主会在上面成体系的输出后端干货。

商务合作、各种交流:
相关文章:
【分布式链路追踪技术】sleuth+zipkin
目录 1.概述 2.搭建演示工程 3.sleuth 4.zipkin 5.插拔式存储 5.1.存储到MySQL中 5.2.用MQ来流量削峰 6.联系作者 1.概述 当采用分布式架构后,一次请求会在多个服务之间流转,组成单次调用链的服务往往都分散在不同的服务器上。这就会带来一个问…...

Windows 源码编译 MariaDB
环境 Win11, vs2022, git, cmake, Bison from GnuWin32, perl, Gnu Diff. 默认都安装好。 perl 看之前博客教程。perl Bison from GnuWin32 默认安装到 C:\GnuWin32 Add C:\GnuWin32\bin to your system PATH after installation. 下载mariadb源码 地址:MariaD…...

【动画视频生成】
转自:机器之心 动画视频生成这几天火了,这次 NUS、字节的新框架不仅效果自然流畅,还在视频保真度方面比其他方法强了一大截。 最近,阿里研究团队构建了一种名为 Animate Anyone 的方法,只需要一张人物照片࿰…...
《Spring Cloud学习笔记:微服务保护Sentinel》
Review 解决了服务拆分之后的服务治理问题:Nacos解决了服务治理问题OpenFeign解决了服务之间的远程调用问题网关与前端进行交互,基于网关的过滤器解决了登录校验的问题 流量控制:避免因为突发流量而导致的服务宕机。 隔离和降级:…...

解密负载均衡:如何平衡系统负载(下)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
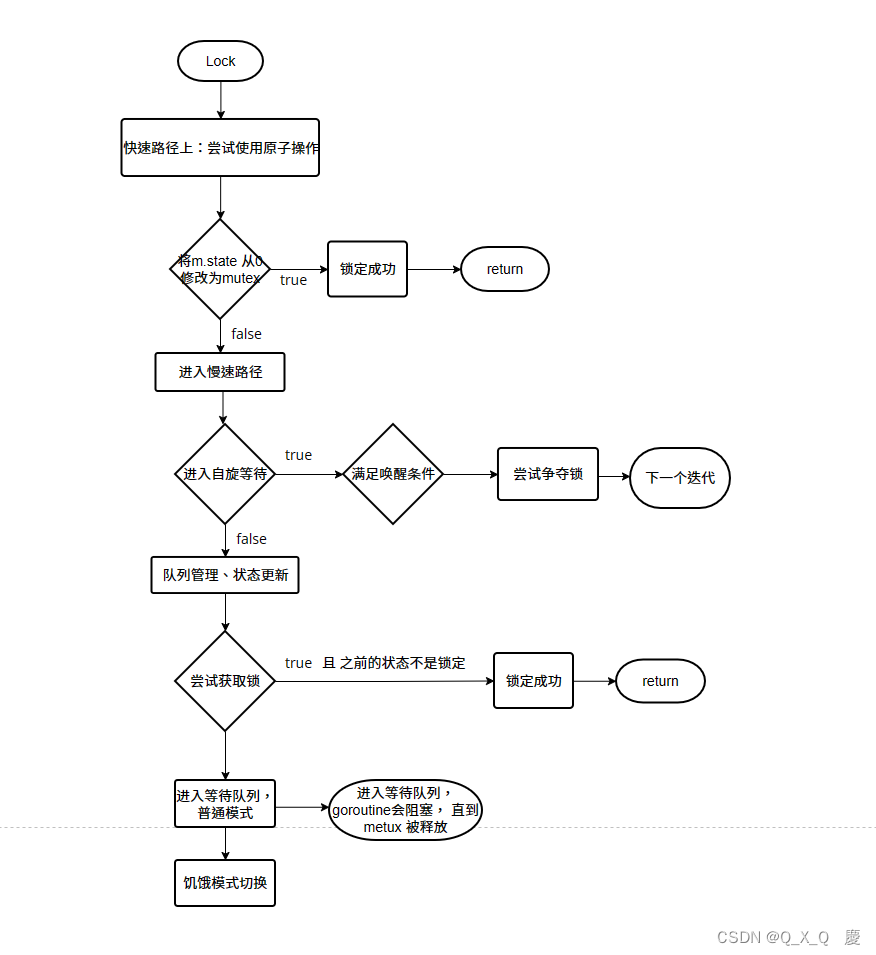
go 源码解读 - sync.Mutex
sync.Mutex mutex简介mutex 方法源码标志位获取锁LocklockSlowUnlock怎么 调度 goroutineruntime 方法 mutex简介 mutex 是 一种实现互斥的同步原语。(go-version 1.21) (还涉及到Go运行时的内部机制)mutex 方法 Lock() 方法用于…...
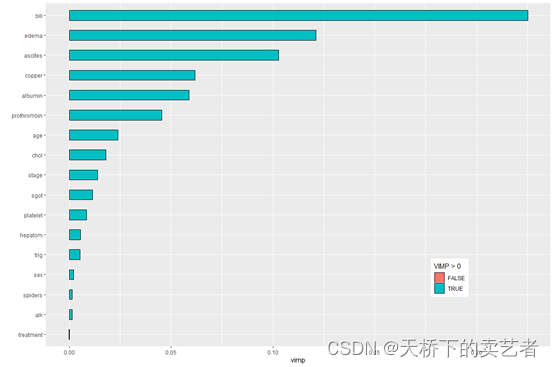
机器学习系列--R语言随机森林进行生存分析(1)
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。随机生存森林(RSF࿰…...
<JavaEE> TCP 的通信机制(四) -- 流量控制 和 拥塞控制
目录 TCP的通信机制的核心特性 五、流量控制 1)什么是“流量控制”? 2)如何做到“流量控制”? 3)“流量控制”的作用 六、拥塞控制 1)什么是“拥塞控制”? 2)如何做到“拥塞…...
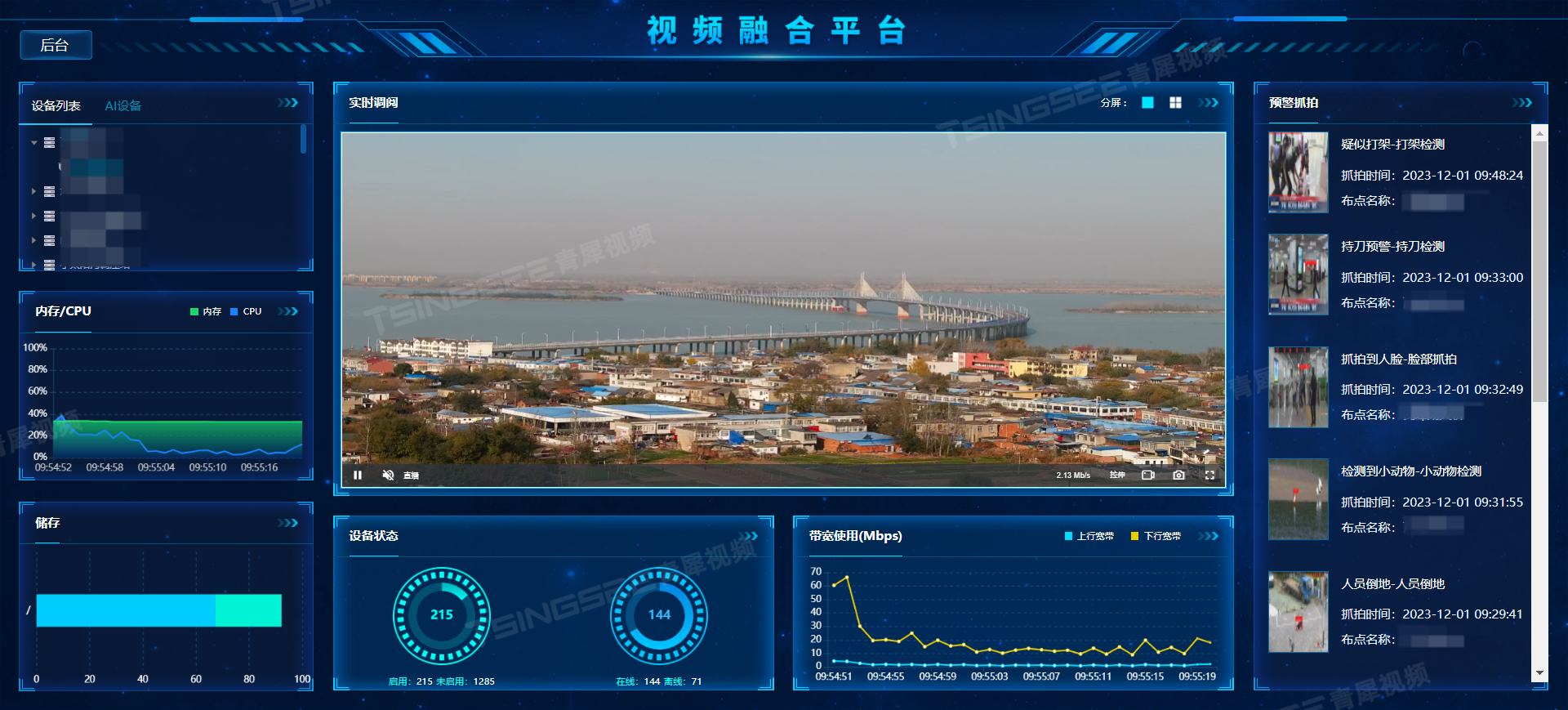
智慧监控平台/AI智能视频EasyCVR接口调用编辑通道详细步骤
视频监控TSINGSEE青犀视频平台EasyCVR能在复杂的网络环境中,将分散的各类视频资源进行统一汇聚、整合、集中管理,在视频监控播放上,GB28181视频安防监控汇聚平台可支持1、4、9、16个画面窗口播放,可同时播放多路视频流,…...

Go语言实现KV存储系统:前言
文章目录 前言前提条件持久索引并发总结 前言 你好,我是醉墨居士,最近想做一些存储方面的东西玩玩,我第一时间就想到了能不能自己开发一个保存键值对的存储系统 我找了些资料,准备使用Go语言实现一下,想着有想法咱就…...

代码随想录刷题笔记(DAY1)
前言:因为学校的算法考试让我认识了卡哥,为了下学期冲击大厂实习的理想,我加入了卡哥的算法训练营,从今天开始我每天会更新自己的刷题笔记,与大家一起打卡,一起共勉! Day 1 01. 二分查找 &…...

Linux域名IP映射
本地域名IP映射 在Linux系统中,域名映射可以通过编辑/etc/hosts文件来实现。/etc/hosts文件用于将主机名映射到IP地址,从而实现本地域名解析。它通常被用于在没有DNS服务器的情况下,手动指定特定域名和IP地址的映射关系。 格式:…...

postman使用-03发送请求
文章目录 请求1.新建请求2.选择请求方式3.填写请求URL4.填写请求参数get请求参数在params中填写(填完后在url中会自动显示)post请求参数在body中填写,根据接口文档请求头里面的content-type选择body中的数据类型post请求参数为json-选择raw-选…...

【Spring实战】09 MyBatis Generator
文章目录 1. 依赖2. 配置文件3. 生成代码4. 详细介绍 generatorConfig.xml5. 代码详细总结 Spring MyBatis Generator 是 MyBatis 官方提供的一个强大的工具,它能够基于数据库表结构自动生成 MyBatis 持久层的代码,包括实体类、Mapper 接口和 XML 映射文…...

【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框架
一个理解人类偏好学习的统一理论框架 《A General Theoretical Paradiam to Understand Learning from Human Preferences》 论文地址:https://arxiv.org/pdf/2310.12036.pdf 相关博客 【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框…...
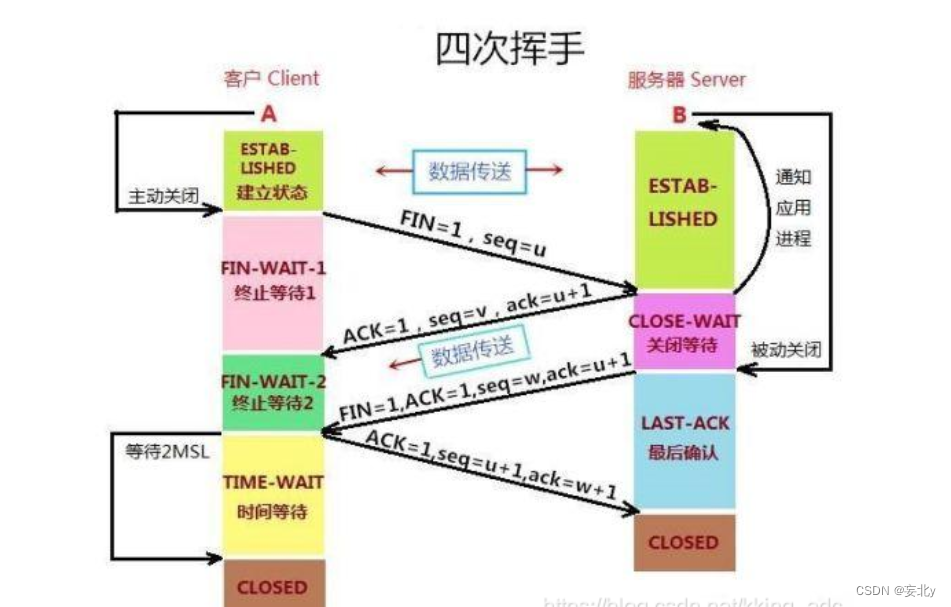
计算机网络——传输层(五)
前言: 最重要的网络层我们已经学习完了,下面让我们再往上一层,对网络层的上一层传输层进行一个学习与了解,学习网络层的基本概念和网络层中的TCP协议和UDP协议 目录 编辑一、传输层的概述: 1.传输层: …...
python3处理docx并flask显示
前言: 最近有需求处理docx文件,并讲内容显示到页面,对world进行在线的阅读,这样我这里就使用flaskDocument对docx文件进行处理并显示,下面直接上代码: Document处理: 首先下载Document的库文…...
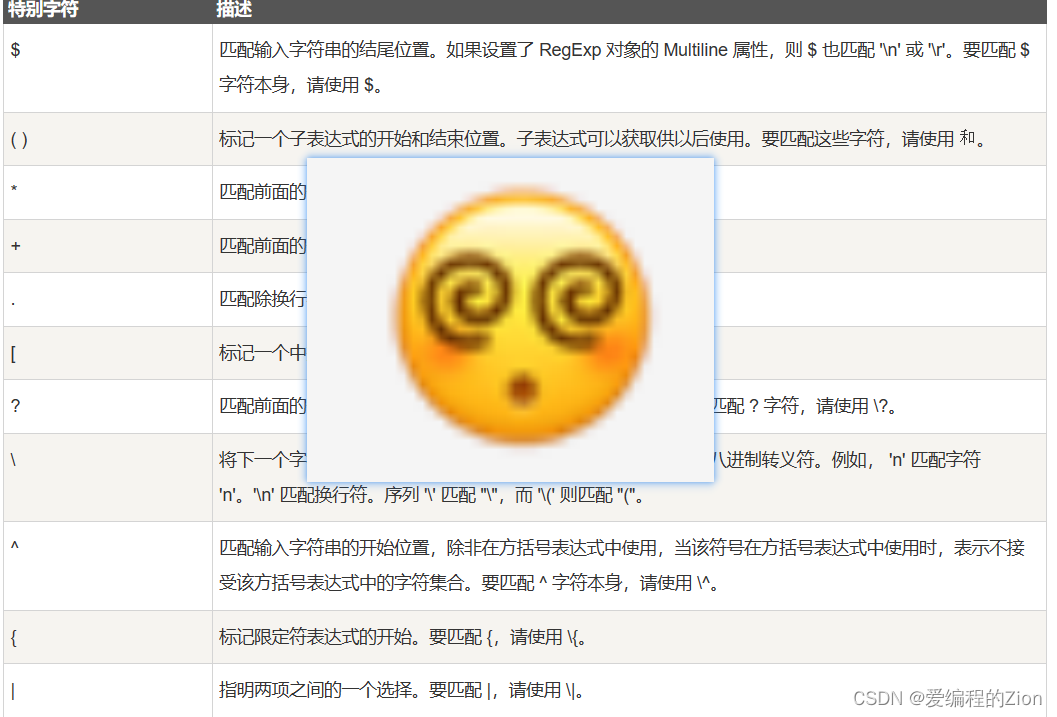
Python:正则表达式速通,码上上手!
1前言 正则表达式(Regular Expression)是一种用来描述字符串模式的表达式。它是一种强大的文本匹配工具,可以用来搜索、替换和提取符合特定模式的文本。 正则表达式由普通字符(例如字母、数字、符号等)和元字符&#…...
centos7安装nginx并安装部署前端
目录: 一、安装nginx第一种方式(外网)第二种方式(内网) 二、配置前端项目三、Nginx相关命令 好久不用再次使用生疏,这次记录一下 一、安装nginx 第一种方式(外网) 1、下载nginx ng…...
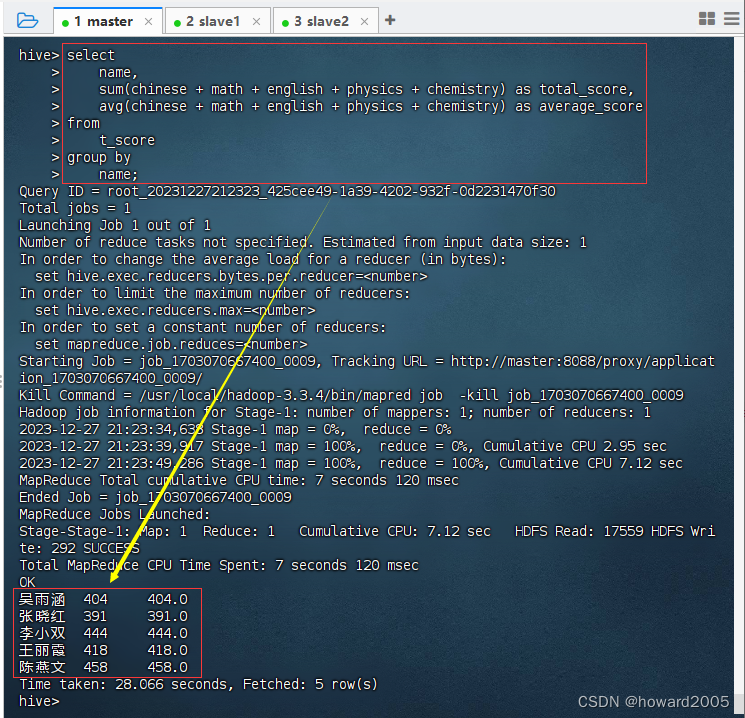
Hive实战:统计总分与平均分
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、将文本文件上传到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、创建Hive表,加载HDFS数据文件…...

告别AWCC臃肿:500KB轻量级Alienware灯光风扇控制终极方案
告别AWCC臃肿:500KB轻量级Alienware灯光风扇控制终极方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 厌倦了Alienware Command Center&…...

AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程
AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

2026年AI搜索优化服务商TOP10榜单发布:技术原生派领跑,垂直专精派各显神通
随着生成式AI全面重构用户信息获取与消费决策路径,AI搜索优化(GEO)已从概念验证迈入规模化落地阶段。企业面临的痛点高度集中:技术门槛高、效果难量化、服务商良莠不齐。为帮助企业精准选型,我们基于技术自研能力、实战…...
)
STM32F4实战:手把手教你用DCMI接口驱动OV2640摄像头(附完整代码)
STM32F4实战:从零构建OV2640摄像头驱动系统 1. 硬件连接与信号解析 OV2640摄像头模块与STM32F4的硬件连接需要同时处理电源、控制信号和数据传输三个子系统。我们先拆解这个200万像素摄像头的物理接口特性: 电源部分需要特别注意电压匹配: 核…...

AirUI全流程可视化开发平台:从设计稿到代码的范式革命
1. 项目概述:从“手写”到“拖拽”的范式转变“告别手写UI代码”,这大概是每个前端开发者在面对复杂页面和频繁需求变更时,内心最真实的呐喊。我入行十几年,从手写HTML、CSS,到使用jQuery,再到拥抱React、V…...

忆阻器混沌电路设计与储层计算应用
1. 忆阻器混沌电路的设计原理与实现1.1 忆阻器的非线性特性基础忆阻器(Memristor)作为第四种基本电路元件,其核心特性在于电阻值会随通过它的电荷量历史而变化。这种"记忆"特性来源于器件内部导电细丝的形成与断裂过程。在Pt/HfO2/…...

ETime:高效推动你的时间
我做了一个开源时间工作台:ETime 如果你也试过很多时间管理工具,可能会遇到同一种疲惫:记录本身变成了另一件需要坚持的事。 ETime 想解决的不是“怎样把每一分钟都管起来”,而是更朴素的一件事:让开始更轻ÿ…...

桌面音乐可视化革命:Lano Visualizer如何让你的音乐“看得见“
桌面音乐可视化革命:Lano Visualizer如何让你的音乐"看得见" 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 在数字时代&#…...

从堆叠到双线性:手把手图解注意力机制的‘进化史’与PyTorch实现对比
从堆叠到双线性:手把手图解注意力机制的‘进化史’与PyTorch实现对比 在计算机视觉与自然语言处理的交叉领域,注意力机制早已从最初的简单加权求和发展为具有复杂交互能力的计算范式。本文将带您穿越注意力机制的进化长廊,通过PyTorch实战演示…...

STM32F4/F7上跑AI手写识别:从CUBEMX配置到串口通信的完整避坑指南
STM32F4/F7实战AI手写识别:从模型部署到数据处理的工程化解决方案 在嵌入式设备上部署神经网络进行手写识别,正逐渐从实验室走向工业现场。STM32F4/F7系列凭借其平衡的性能与功耗,成为边缘AI应用的理想选择。本文将深入探讨从模型准备到实际部…...