【消息中间件】Rabbitmq消息可靠性、持久化机制、各种消费
原文作者:我辈李想
版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。
文章目录
- 前言
- 一、常见用法
- 1.消息可靠性
- 2.持久化机制
- 3.消息积压
- 批量消费:增加 prefetch 的数量,提高单次连接的消息数
- 并发消费:多部署几台消费者实例
- 4.重复消费
- 二、其他
- 1.队列存在大量unacked数据
- 2.重试连接:建立连接
- 3.rabbitmq心跳连接
- 4.重试连接:消费ack确认前连接异常断开时
前言
一、常见用法
1.消息可靠性
RabbitMQ 提供了多种机制来确保消息的可靠性,以防止消息丢失或被意外删除。以下是几种提高消息可靠性的方法:
-
持久化消息(Durable Message):在发布消息时,将消息的
deliveryMode设置为2,即可将消息设置为持久化消息。持久化消息会将消息写入磁盘,即使 RabbitMQ 服务器重启,消息也不会丢失。 -
持久化队列(Durable Queue):创建队列时,将队列的
durable参数设置为true,即可创建一个持久化队列。持久化队列会将队列的元数据和消息都存储在磁盘上,即使消息队列服务器重启,队列的元数据和消息仍然可以恢复。 -
确认模式(Publisher Confirms):使用确认模式可以确保消息被成功发送到 RabbitMQ 服务器,并得到确认。通过在信道上使用
channel.confirmSelect()启用确认模式,然后通过channel.waitForConfirms()方法来等待服务器的确认。 -
事务模式(Transactions):使用事务模式可以保证消息的原子性,要么全部发送成功,要么全部失败。通过在信道上使用
channel.txSelect()开启事务模式,在发送消息后使用channel.txCommit()提交事务,或使用channel.txRollback()进行回滚。 -
消费者应答(Consumer Acknowledgement):在消费者接收和处理消息后,必须发送确认应答给 RabbitMQ 服务器。通过使用
channel.basicAck()方法发送确认应答,以告知服务器消息已经成功处理。
通过使用上述机制,可以在 RabbitMQ 中实现消息的可靠性传输和处理,以防止消息的丢失和重复传递。
这里有篇博客,大家可以看看。
2.持久化机制
在RabbitMQ中,消息持久化是一种机制,可以确保消息在服务器宕机或重启之后不丢失。默认情况下,RabbitMQ的消息是存储在内存中的,如果服务器宕机,则会导致消息的丢失。要实现消息的持久化,可以采取以下步骤:
-
创建一个持久化的交换机(Exchange):
在定义交换机时,将其durable参数设置为true,例如:channel.exchangeDeclare("exchange_name", "direct", true); -
创建一个持久化的队列(Queue):
在定义队列时,将其durable参数设置为true,例如:channel.queueDeclare("queue_name", true, false, false, null); -
将持久化的队列与交换机进行绑定:
使用队列和交换机的bind方法进行绑定,例如:channel.queueBind("queue_name", "exchange_name", "routing_key"); -
发布持久化的消息:
在发布消息时,将消息的deliveryMode属性设置为2,表示消息是持久化的,例如:String message = "Hello RabbitMQ!"; channel.basicPublish("exchange_name", "routing_key", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());
通过以上步骤,就可以实现消息的持久化。当RabbitMQ服务器宕机或重启后,消息会被保存在磁盘中,并在服务器恢复后重新投递给消费者。需要注意的是,虽然消息被持久化了,但是在发送到队列之前,仍然有可能发生丢失,所以在实际的应用中,还需要考虑一些因素,比如网络故障、消费者的可靠性等。
3.消息积压
批量消费:增加 prefetch 的数量,提高单次连接的消息数
为了提高消费性能,可以将多个消息批量进行消费,减少消费者和消息队列的交互次数。通过设置合适的批量消费大小,可以在一次网络往返中消费多个消息,从而提高消费性能。
要实现RabbitMQ的批量消费,可以使用RabbitMQ的channel.basicQos方法来设置每次消费的消息数量。以下是一个示例代码,演示如何实现批量消费:
import pikadef callback(ch, method, properties, body):print("Received message: %s" % body)# 处理消息的逻辑# 发送确认给RabbitMQch.basic_ack(delivery_tag=method.delivery_tag)def consume_messages():connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))channel = connection.channel()# 设置每个消费者一次性获取的消息数量channel.basic_qos(prefetch_count=10)# 注册消费者并开始消费消息channel.basic_consume(queue='my_queue', on_message_callback=callback)# 进入一个循环,一直等待消息的到来channel.start_consuming()consume_messages()
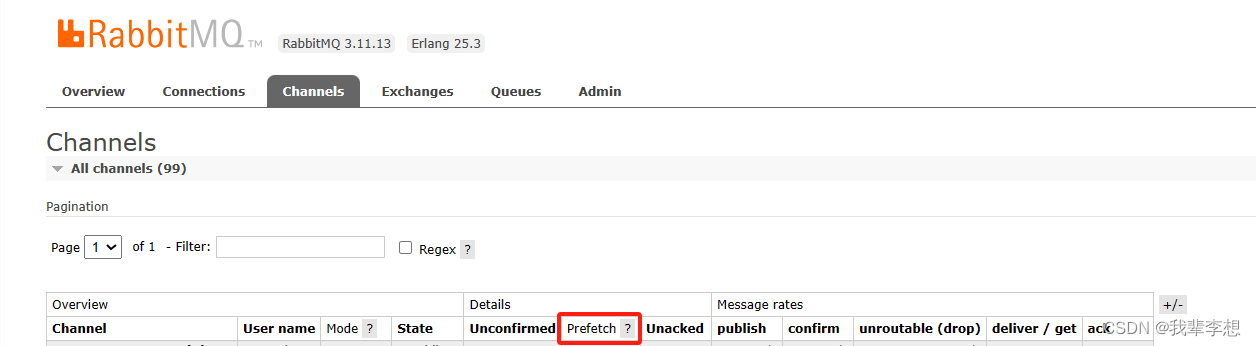
在上面的代码中,我们通过channel.basic_qos(prefetch_count=10)设置每次处理的消息数量为10。这样,在消费者处理完10条消息之前,RabbitMQ将不会再向其发送更多消息。
这样,就实现了RabbitMQ的批量消费。你可以根据需求,在basic_qos方法中设置适合你的消息数量。
并发消费:多部署几台消费者实例
可以采用多线程或多进程的方式进行消息的并发消费,将多个消费者并行处理消息。通过增加并发消费者的数量,可以提高消息的处理速度,提高消费的性能。
使用进程池来消费RabbitMQ的消息可以更好地管理并发性能。通过使用进程池,可以在一个固定的池子中创建多个进程,并且复用它们来消费消息,从而减少进程创建和销毁的开销。
以下是一个使用进程池消费RabbitMQ消息的示例:
import multiprocessing
import os
import time
import pikadef consumer(queue_name):connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.queue_declare(queue=queue_name)def callback(ch, method, properties, body):print(f'Process {os.getpid()} received message: {body}')time.sleep(1)channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)channel.start_consuming()def main():# 创建进程池pool = multiprocessing.Pool(processes=5)# 在进程池中提交任务for _ in range(5):pool.apply_async(consumer, ('my_queue',))pool.close()pool.join()if __name__ == '__main__':main()
在上述示例中,我们使用multiprocessing.Pool来创建一个包含5个进程的进程池。然后,我们使用apply_async方法向进程池中提交任务,每个任务都是调用consumer函数来消费"my_queue"队列中的消息。进程池会自动分配任务给闲置的进程来处理。通过close和join方法,我们可以确保所有任务都被完成。
4.重复消费
-
消息确认:在消费者处理完一条消息后,通过调用
basic_ack方法手动确认消息已经成功消费。这样,RabbitMQ就会将该消息标记为已经处理,不会再次发送给其他消费者。同时,还可以设置auto_ack参数为False,禁用自动消息确认机制,以确保消息被正确确认。 -
消息持久化:可以通过设置消息的
delivery_mode属性为2来将消息标记为持久化消息。这样,即使消费者在处理消息时发生故障,消息也会被保存在磁盘上,待消费者恢复正常后会重新投递。 -
唯一消费者:可以通过设置队列的
exclusive参数为True,创建一个排他队列。这样,只有一个消费者可以连接到该队列,并独占地消费其中的消息,避免重复消费。 -
消息去重:在消费者端可以维护一个已消费消息的记录,例如在数据库或缓存中记录已消费的消息的ID或唯一标识。每次消费消息时,先检查记录中是否已经存在该消息,如果存在则跳过,避免重复处理。
-
幂等操作:在消费者的处理逻辑中,要确保操作是幂等的,即多次执行同一个操作的效果和执行一次的效果是一样的。这样,即使消息被重复消费,也不会产生副作用。
二、其他
1.队列存在大量unacked数据
通过rabbitmq的后台管理,进入相应的队列,滑到最下边,找到purge。purge将清空这个队列的消息。

2.重试连接:建立连接
import pika
from retry import retry@retry(pika.exceptions.AMQPConnectionError, delay=5, jitter=(1, 3))def consume(self, callback):"""Start consuming AMQP messages in the current process"""try:self.start_consuming_message()except ConnectionClosed as e:self.clear()self.reconnect(queue_oname, exchange, route_key, is_use_rabbitpy=1)except ChannelClosed as e:self.clear()self.reconnect(queue_oname, exchange, route_key, is_use_rabbitpy=1)finally:self.start_consuming_message()
3.rabbitmq心跳连接
RabbitMQ 心跳是一种保持连接活跃的机制。当 RabbitMQ 与客户端建立连接后,它会定期发送心跳包来确认连接仍然有效。如果在一段时间内没有收到心跳回复,RabbitMQ 将会关闭连接。心跳属于ConnectionParameters参数heartbeat,我理解是应该用于生产者,确保能够成功发送消息,如果消费者中设置了heartbeat,一定要大于消费程序的处理时间,保证消费期间结束后,可以响应心跳。
parameters = pika.ConnectionParameters(host, int(port), '/', credentials=userx, heartbeat=int(heartbeat))
如果消费者使用心跳,还可以参考这个博客
4.重试连接:消费ack确认前连接异常断开时
这个需要开启链接断开的重试,属于ConnectionParameters的retry_delay和connection_attempts参数。rabbitmq重启,消费者中使用heartbeat时间不足以覆盖消费时间。
connectionParameters = pika.ConnectionParameters(host='localhost',virtual_host=5672,credentials=credentials,socket_timeout=10,heartbeat=0,retry_delay=10, # 连接尝试重连间隔connection_attempts=10, # 连接尝试次数
)
相关文章:
【消息中间件】Rabbitmq消息可靠性、持久化机制、各种消费
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、常见用法1.消息可靠性2.持久化机制3.消息积压批量消费:增加 prefetch 的数量,提高单次连接的消息数并发消费:…...

aws-sdk-cpp通过bazel构建的S3_client轮子
感觉时间过得很快,又是很久没有更新了 哎,主要原因还是很久都没有学什么东西了,进入社会后不知不觉间倦怠了许多 没什么办法,上班了之后做的很多东西都是调用api,越来越像一个工具人了,虽然说本身也大差不…...

关于WPF MVVM 的详细使用过程以及注意的问题
WPF MVVM 是一种常用的设计模式,在 WPF 应用程序中使用它可以更好地分离界面逻辑和业务逻辑,并且更容易进行单元测试和重构。下面是深入理解 WPF MVVM 的详细使用过程以及注意的问题。 一、MVVM 的基本概念 MVVM 是 Model-View-ViewModel 的缩写&#…...

计算机视觉 全教程目录
1、OpenCV 图像处理框架 实战系列 总目录 OpenCV 图像处理框架 实战系列 总目录 2、现代卷积网络实战系列 总目录 现代卷积网络实战系列 总目录 3、YOLO 物体检测 系列教程 总目录 YOLO 物体检测 系列教程 总目录 4、图像分割实战-系列教程 总目录 图像分割实战-系列教程 总目录…...

油猴脚本开发,之如何添加html和css
简介 油猴是一个脚本管理器,让我们能够方便的使用js脚本,以实现对页面内容的修改、功能增强或其他定制化操作。 常见脚本管理器 Tampermonkey 应该是各位见得最多的也是最知名的,好用又稳定,多浏览器支持Greasemonkey 用户脚本始祖&#x…...
【MATLAB】BiGRU神经网络时序预测算法
有意向获取代码,请转文末观看代码获取方式~也可转原文链接获取~ 1 基本定义 BiGRU神经网络时序预测算法是一种基于双向门控循环单元(GRU)的多变量时间序列预测方法。该方法结合了双向模型和门控机制,旨在有效地捕捉时间序列数据中…...
)
57.0/初识 PhotoShopCS4(详细版)
目录 57.1 PhotoShop 概要 57.2.1 像素和分辨率 57.2.2 色彩模式 57.2.3 位图和矢量图 57.3 PhotoShop 基本操作 57.3.1 PhotoShop 界面的认识 57.3.2 PhotoShop 基本界面工具 57.3.3 移动选择工具(V) 57.3.4 选框工具(M)编辑 编辑57.3.5 套索工具(L) 57.3…...
[C#]opencvsharp进行图像拼接普通拼接stitch算法拼接
介绍: opencvsharp进行图像拼一般有2种方式:一种是传统方法将2个图片上下或者左右拼接,还有一个方法就是融合拼接,stitch拼接就是一种非常好的算法。opencv里面已经有stitch拼接算法因此我们很容易进行拼接。 效果: …...
-第10章算法设计与数据结构面试题精粹)
《妙趣横生的算法》(C语言实现)-第10章算法设计与数据结构面试题精粹
【10-1】输入一个字符串并将它输出,以ctrlz组合键表示输入完毕,要求将输入的字符串中多于1个的连续空格符合并为1个。 //10-1 2023年12月30日17点11分-17点18分 # include <stdio.h> int main() {char c;c getchar();//scanf("%c", &a…...

(JAVA)-(网络编程)-初始网络编程
网络编程就是在通信协议下,不同的计算机上运行的程序,进行的数据传输。 讲的通俗一点,就是以前我们写的代码是单机版的,网络编程就是联机版的。 应用场景:即时通信,网游对战,金融证券…...

Observer观察者模式(组件协作)
观察者模式(组件协作) 链接:观察者模式实例代码 解析 目的 在软件构建过程中,我们需要为某些对象建立一种“通知依赖关系” ——一个对象(目标对象)的状态发生改变,所有的依赖对象࿰…...

数据挖掘 聚类度量
格式化之前的代码: import numpy as np#计算 import pandas as pd#处理结构化表格 import matplotlib.pyplot as plt#绘制图表和可视化数据的函数,通常与numpy和pandas一起使用。 from sklearn import metrics#聚类算法的评估指标。 from sklearn.clust…...
[Angular] 笔记 24:ngContainer vs. ngTemplate vs. ngContent
请说明 Angular 中 ngContainer, ngTemplate 和 ngContent 这三者之间的区别。 chatgpt 回答: 这三个在 Angular 中的概念是关于处理和组织视图的。 1. ngContainer: ngContainer 是一个虚拟的 HTML 容器,它本身不会在最终渲染…...

❀My排序算法学习之插入排序❀
目录 插入排序(Insertion Sort):) 一、定义 二、基本思想 三、示例 时间复杂度 空间复杂度 bash C++ 四、稳定性分析...

【算法题】30. 串联所有单词的子串
题目 给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。 s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。 例如,如果 words ["ab","cd","ef"], 那么 "…...

SAP-FI模块 处理自动生成会计凭证增强
ENHANCEMENT 2 ZEHENC_SAPMF05A. "active version * FI 20221215:固定资产业务过渡科目摘要增强功能 WAIT UP TO 1 SECONDS.READ TABLE xbseg WITH KEY hkont 1601990001. IF sy-subrc 0.DATA: lt_bkdf TYPE TABLE OF bkdf,lt_bkpf TYPE TABLE OF bkpf,…...
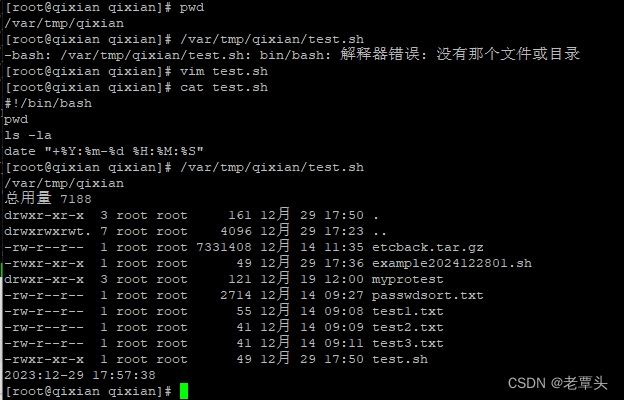
Shell脚本-bin/bash: 解释器错误: 没有那个文件或目录-完整路径执行-“/”引发的脑裂
引起该不适的一种可能以及解决方案,网上较多,比如: 但按以上方式操作,并经过查看,发现仍然未能解决问题。 因为两种方式执行,有一种能成功,有一种不能,刚开始未怀疑是文件问题&…...
详细使用)
React MUI(版本v5.15.2)详细使用
使用React MUI(版本v5.15.2)的详细示例。请注意,由于版本可能会有所不同,因此建议您查阅官方文档以获取最新的信息和示例。但是,我将根据我的知识库为您提供一些基本示例。 首先,确保您已经按照之前的说明…...
用CSS中的动画效果做一个转动的表
<!DOCTYPE html> <html lang"en"><head><meta charset"utf-8"><title></title><style>*{margin:0;padding:0;} /*制作表的样式*/.clock{width: 500px;height: 500px;margin:0 auto;margin-top:100px;border-rad…...
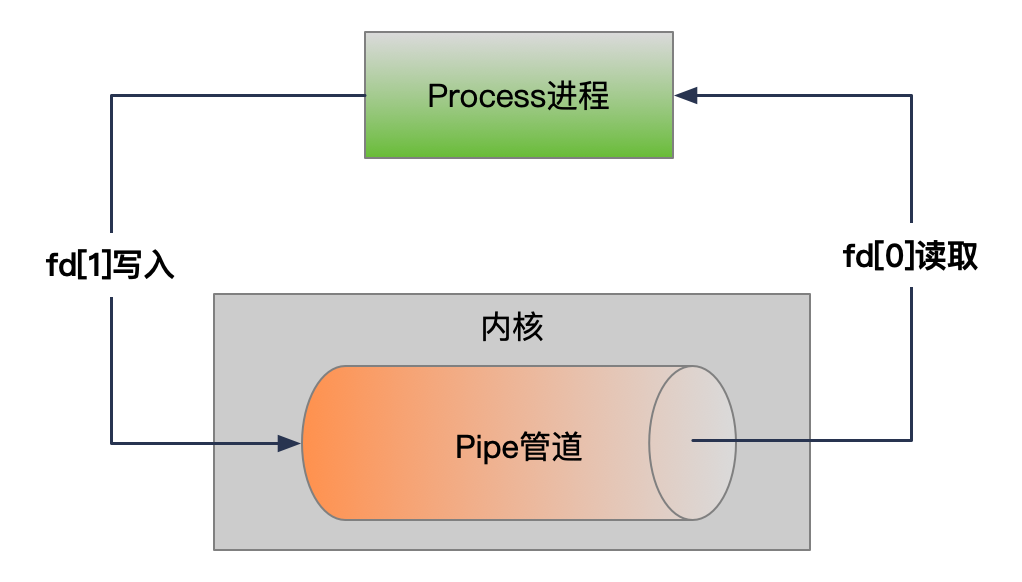
【linux】Linux管道的原理与使用场景
Linux管道是Linux命令行界面中一种强大的工具,它允许用户将多个命令链接起来,使得一个命令的输出可以作为另一个命令的输入。这种机制使得我们可以创建复杂的命令链,并在处理数据时提供了极大的灵活性。在本文中,我们将详细介绍Li…...
)
LLVM指令调度实战:如何用llvm-mca优化AArch64代码性能(附TSV110配置示例)
LLVM指令调度实战:如何用llvm-mca优化AArch64代码性能(附TSV110配置示例) 在ARM架构的性能优化领域,指令调度质量直接影响着关键计算任务的吞吐量。本文将带您深入llvm-mca工具链的实际应用,通过TSV110处理器的具体案例…...

别再被NFS的‘非法端口’拦住了!手把手教你用insecure选项解决mount.nfs: access denied
突破NFS端口限制:深入解析insecure选项的实战应用 上周在调试一个嵌入式开发环境时,遇到了一个典型的NFS挂载问题。当我在VirtualBox虚拟机中尝试挂载物理机上的NFS共享目录时,终端突然弹出mount.nfs: access denied by server while mountin…...

如何构建大型可维护的Vugu项目:Go WebAssembly UI库最佳实践指南
如何构建大型可维护的Vugu项目:Go WebAssembly UI库最佳实践指南 【免费下载链接】vugu Vugu: A modern UI library for GoWebAssembly (experimental) 项目地址: https://gitcode.com/gh_mirrors/vu/vugu Vugu是一个现代化的Go语言WebAssembly UI库…...
LibreTranslate模型部署优化指南:从技术痛点到落地实践
LibreTranslate模型部署优化指南:从技术痛点到落地实践 【免费下载链接】LibreTranslate Free and Open Source Machine Translation API. Self-hosted, offline capable and easy to setup. 项目地址: https://gitcode.com/GitHub_Trending/li/LibreTranslate …...

OpenClaw多通道控制:Qwen3-32B-Chat同时响应飞书与网页端指令
OpenClaw多通道控制:Qwen3-32B-Chat同时响应飞书与网页端指令 1. 为什么需要多通道控制? 上周三晚上11点,我正在用OpenClaw的网页控制台整理项目文档,突然飞书弹出同事的紧急需求:"能不能立刻帮我生成上季度销售…...

TNTSearch 实战案例:构建电商产品搜索系统的完整流程
TNTSearch 实战案例:构建电商产品搜索系统的完整流程 【免费下载链接】tntsearch A fully featured full text search engine written in PHP 项目地址: https://gitcode.com/gh_mirrors/tn/tntsearch TNTSearch 是一个功能强大的 PHP 全文搜索引擎ÿ…...

PyTorch模型的TensorRT优化:原理与实践
PyTorch模型的TensorRT优化:原理与实践 1. 背景与意义 在深度学习模型部署过程中,推理速度是一个关键指标。TensorRT是NVIDIA开发的高性能深度学习推理优化库,它可以显著提高模型的推理速度,降低延迟。本文将深入探讨TensorRT的工…...

AI人脸生成新范式:IP-Adapter-FaceID PlusV2双重嵌入技术解析
AI人脸生成新范式:IP-Adapter-FaceID PlusV2双重嵌入技术解析 【免费下载链接】IP-Adapter-FaceID 项目地址: https://ai.gitcode.com/hf_mirrors/h94/IP-Adapter-FaceID 在AI人脸生成领域,如何在保持身份一致性的同时实现风格的灵活控制&#x…...

运维面试别再背八股文了!这15道高频笔试题,我用真实排错案例给你讲透
运维面试突围指南:用真实故障案例拆解15道高频技术题 去年冬天的一个凌晨,我接到了一通紧急电话——某电商平台的支付系统突然瘫痪,每分钟损失超过六位数。当我顶着寒风赶到机房时,发现这只是因为一个简单的NTP时间不同步问题。这…...

LFM2.5-1.2B-Thinking-GGUF案例分享:为国产操作系统社区生成的发行版更新日志摘要
LFM2.5-1.2B-Thinking-GGUF案例分享:为国产操作系统社区生成的发行版更新日志摘要 1. 模型简介 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低资源环境优化设计。该模型采用GGUF格式存储,配合llama.cpp运行时&…...