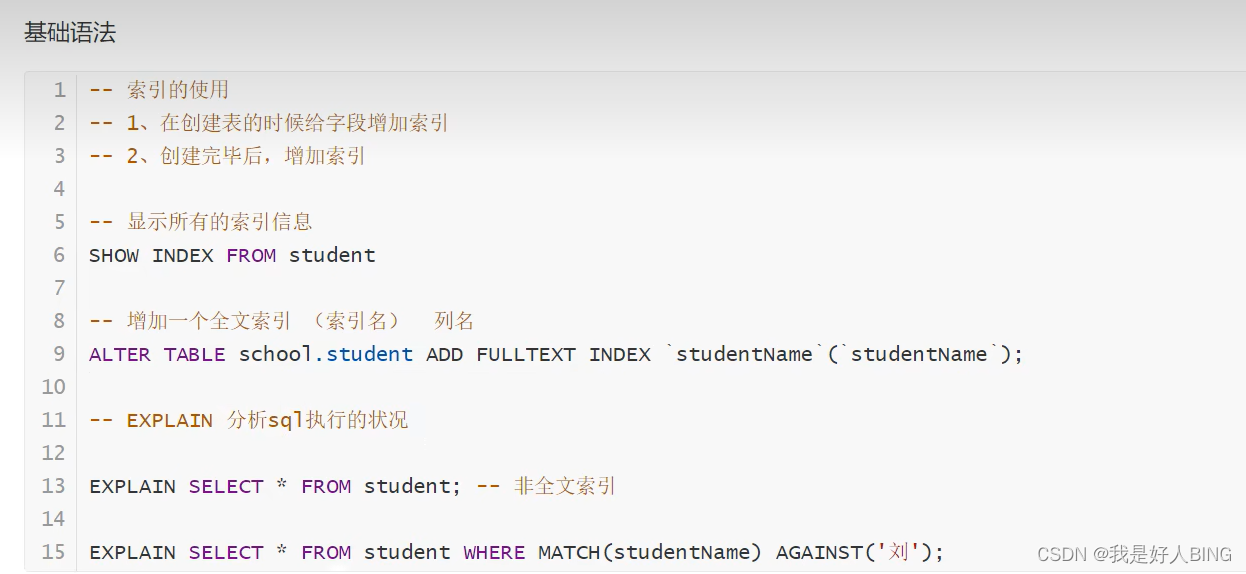
MySQL:索引
MySQL官方对索引的定义为: 索引 (Index) 是帮助MySQL高效获取数据的数据结构。
提取句子主干,就可以得到索引的本质:索引是数据结构。
1. 什么是索引,索引的作用
索引是一种用于快速查询和检索数据的数据结构,帮助mysql提高查询效率的数据结构,而且是排好序的数据结构,存储在磁盘文件里。
索引的作用是在不读取整个表的情况下,使得数据库应用程序可以更快地查找数据,用户无法看到索引,只能被用来加速检索或查询。
优点:
- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
缺点:
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
但是,使用索引一定能提高查询性能吗?
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
索引建立的原则:
- 在最频繁使用的、用以缩小查询范围的字段上建立索引。
- 在最频繁使用的、需要排序的字段上建立索引。
- 对于查询中很少涉及的列或者重复值比较多的列,不宜建立索引。
2. 索引的类型
1. 主键索引(Primary Key)
数据表的主键列使用的就是主键索引。(唯一标识,主键不可重复,只能有一个列作为主键)
一张数据表有只能有一个主键,并且主键不能为 null,不能重复。(可以理解为一种特殊的唯一索引)
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在null值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
2. 二级索引(辅助索引)
二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。
唯一索引,普通索引,前缀索引等索引属于二级索引。
- 唯一索引(Unique Key) :唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。
- 普通索引(Normal Index) :也叫单列索引,给表中的某一个列创建索引,即一个索引只包含单个列;一个表可以有多个单列索引。普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。
- 全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
3. 索引的底层数据结构
1. B 树& B+树
B 树也称 B-树,全称为 多路平衡查找树 ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 Balanced (平衡)的意思。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
- B树是一种平衡多路查找树,满足平衡二叉树的规律,同时可以拥有多个子树,子树的数量取决于关键字的数量,(关键字数量+1),因此从这个特征来看在存储同样数据量,B树会更低一些。
- B+树是在B树的基础上做了增强。主要有两点:
- B树的数据存储在每个节点上,而B+树中的数据存储在叶子节点上,并且通过双向链表的方式对叶子节点的数据进行了连接。
- B树的子树数量等于关键词数量加1,B+树的子树数量等于关键字的数量。
2. 为什么选择B/B+树,为什么要用 B+树,为什么不用二叉树?
B/B+Tree更适合文件系统的索引/更适合硬盘上查询的数据结构。
- 1.高度低-->io次数少
- 2.顺序io只需一次扫描数据 > 随机io-->性能高
- 3.多路子树,数据量大不能一次性全部加载到内存时,会每次加载树的一个节点,由于多路子树的节点数量多于普通树的节点,所以每次加载的数量更多-->速度更快
为什么不是一般二叉树?
二者存储数据的结构可以看出,二叉树随着数据的增加,树的高度会越来越高,而B+树是越来越胖。
树的高度越来越高,增加了I/O次数,导致查询效率减低。而B+树随着数据量的增加,树的宽度越来越大,这样空间利用率更高,可减少I/O次数,查询效率较快。
我们知道,在内存比在磁盘的数据,查询效率快得多。如果树这种数据结构作为索引,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是B树,可以存储更多的节点数据,每个节点包含多个数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快啦。
为什么不是B树而是B+树呢?
- B+树的层级更少。相较于B树,B+树每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快。
- B+树查询效率更高。B+树使用双向链表串连所有叶子节点,而且数据是按照顺序排列的,区间查询效率更高(因为所有数据都在B+树的叶子节点,扫描数据库只需扫一遍叶子结点就行了),但是B树则需要通过中序遍历才能完成查询范围的查找。
- B+树查询效率更稳定。B+树只有叶子结点存放数据的data值,非叶子节点上只存储key值信息,B+树每次都必须查询到叶子节点才能找到数据,而B树查询的数据可能不在叶子节点,也可能在,这样就会造成查询的效率的不稳定。
- B+树的磁盘读写代价更小。B+树的内部节点只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度,因此通常B+树矮更胖,查询产生的I/O更少。B树节点中不仅存了数据的key值,还有data值,而每一个页的存储空间是有限的(16KB),如果data数据较大时将会导致一个页能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。
3. 不同引擎对于B+树的实现
B+Tree在两种存储引擎的实现方式是不同的。
- MylSAM:B+Tree叶节点的「data域存放的是数据记录的地址」
在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的key存在,则取出其data域的值,然后以data域的值为地址读取相应的数据记录。这被称为“非聚簇索引”
- InnoDB:其数据文件「本身就是索引文件」。
相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,「树的叶节点data域保存了完整的数据记录」。
这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。
4. B+ Tree索引和Hash索引区别?
- B+树可以进行范围搜索,hash索引只支持=的操作符,等值查询。
- B+树支持order by进行排序,hash索引没办法利用索引完成排序。
- B+树支持多列联合索引的最左匹配规则。hash索引不支持
- 如果有大量重复健值得情况下,hash索引的效率会很低,因为哈希冲突问题。
- B+树使用like进行模糊查询的时候,like后面%开头可以起到优化作用,Hash索引不行。
Hash索引的缺点
- 查询性能受hash冲突率影响,性能不稳定
- 只能通过等值匹配的方式查询,不能范围查询
- 结构存储上没有顺序,查询时排序无法支持
InnoDB引擎有一个特殊额功能叫做“自适应哈希索引”,当 InnoDB注意到某些索引值被使用得非常频繁时,它会在内存中基于B-Tree索引之上再创建一个哈希索引,这样就让B-Tree索引页具有哈希索引的一些优点,比如快速的哈希查找。
4. 聚集索引和非聚集索引
聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。
聚集索引是依据主键创建的索引,除了主键以外的其他索引,都是非聚集索引。
不是单独的索引类型,是一种数据存储方式。
1. 介绍聚集索引和非聚集索引
在InnoDB引擎里,一张表的数据对应的物理文件本身是按照B+树来组织的,而聚集索引就是按照每张表的一个主键来构建这样一个B+树,叶子节点里面存储了表里面的每一行数据记录,基于这样一个特征,聚集索引不仅仅是一种索引类型,还是一种数据存储方式。
同时意味着每张表里必须有主键,没有主键的话innodb会默认添加一个隐藏列作为主键索引来存储这个表的数据行。一般情况建议使用自增id作为主键,因为id本身具有连续性,对应数据也会按照顺序去存储到磁盘上,写入和检索性能都很高。
innodb里只能存在一个聚集索引,如果有多个,那意味着这个表会有多个副本,这不仅会造成空间浪费,还会导致数据的维护困难。
innodb主键索引存储了一个表的完整数据,主键和行记录放在同一个叶节点,找到了主键也就找到了行记录。所以如果是基于非聚集索引去查找一条数据,最终还是需要访问主键索引来进行检索。
跟MyISAM引擎的非聚集索引不同的是,MyISAM叶节点保存的是地址,而InnoDB是主键,InnoDB非聚集索引的索引文件和数据文件分开存储,索引文件的叶节点只保存主键,在查找时,要先找到叶节点中的主键,再根据主键去主索引文件查找详细行记录;
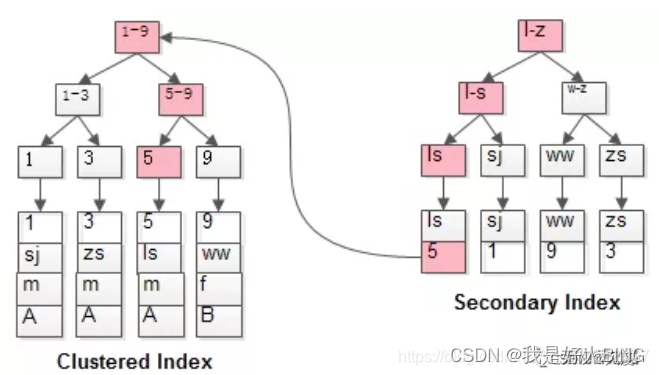
2. 回表查询
上述InnoDB引擎中,非主键索引查找数据时需要先找到主键,再根据主键查找具体行数据,这种现象叫回表查询。
如何解决:覆盖索引,即将查询sql中的字段添加到联合索引里面,只要保证查询语句里面的字段都在索引文件中,就无需进行回表查询;让索引范围覆盖住我们select 的范围,就不会发生回表查询。
比方说有个用户表,有id、name、age、addr四个字段,其中id为主键,主键自带主键索引,无需创建
值1:1、小张、18、成都;
值2:2、小黄、20、北京;
这种查询就必须先在索引文件中找到name为小张的索引节点,很明显这个节点里面只有id,因为这张表只有主键索引,再根据id去数据文件查找具体数据。
如果把name、age、addr建立到联合索引,在找到name为小张的索引节点时,发现里面已经有了我们所需要的age、addr,就无需再到数据文件查找;
当然实际开发中,不可能把所有字段建立到联合索引,应根据实际业务场景,把经常需要查询的字段建立到联合索引即可。
3. 索引下推
索引下推是 MySQL 5.6 版本中提供的一项索引优化功能,可以在非聚簇索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。
不使用索引条件下推优化时的查询过程
获取下一行,首先读取索引信息,然后根据索引将整行数据读取出来。
然后通过where条件判断当前数据是否符合条件,符合返回数据。
使用索引条件下推优化时的查询过程
获取下一行的索引信息。
检查索引中存储的列信息是否符合索引条件,如果符合将整行数据读取出来,如果不符合跳过读取下一行。
用剩余的判断条件,判断此行数据是否符合要求,符合要求返回数据。
5. 联合索引和覆盖索引
1. 覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。
2. 联合索引
使用表中的多个字段创建索引,就是 联合索引,也叫 组合索引 或 复合索引。
覆盖索引是通过联合索引来实现的。
3. 最左前缀匹配原则
最左前缀匹配原则指的是,在使用联合索引时,MySQL 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询,如 >、<、between 和 以%开头的like查询 等条件,才会停止匹配。
如有索引 (a,b,c,d),查询条件 a=1 and b=2 and c>3 and d=4,则会在每个节点依次命中a、b、c,无法命中d。(c已经是范围查询了,d肯定是排不了序了)
因此,列的排列顺序决定了可命中索引的列数。
6. 创建索引及索引的优化
1.选择合适的字段创建索引:
- 不为 NULL 的字段
- 被频繁查询的字段
- 被作为条件查询的字段
- 频繁需要排序的字段
- 被经常频繁用于连接的字段
2.被频繁更新的字段应该慎重建立索引。
3.尽可能的考虑建立联合索引而不是单列索引。
4.注意避免冗余索引 。
5.考虑在字符串类型的字段上使用前缀索引代替普通索引。
7. MySQL 为表字段添加索引
// 主键索引
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )//唯一索引
ALTER TABLE `table_name` ADD UNIQUE ( `column` )//普通索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )//全文索引
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)//联合索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )8、索引原则
- 索引不是越多越好。
- 不要对进程变动数据加索引。
- 小数据量的表不需要加索引。
- 索引一般加在常用来查询的字段上!
索引的数据结构
Hash 类型的索引
Btree : InnoDB 的默认数据结构~
相关文章:
MySQL:索引
MySQL官方对索引的定义为: 索引 (Index) 是帮助MySQL高效获取数据的数据结构。 提取句子主干,就可以得到索引的本质:索引是数据结构。 1. 什么是索引,索引的作用 索引是一种用于快速查询和检索数据的数据结构,帮助mysql提高查询效率的数据…...
CUMT--Java复习--核心类
目录 一、装箱与拆箱 二、“”与equals 三、字符串类 1、String、StringBuffer、StringBuilder的区别 2、String类 3、StringBuffer类 4、StringBuilder类 四、类与类之间关系 一、装箱与拆箱 基本类型与对应封装类之间能够自动进行转换,本质就是Java的自…...
Redis:原理速成+项目实战——Redis实战4(解决Redis缓存穿透、雪崩、击穿)
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习 🌌上期文章:Redis:原理项目实战——Redis实战3(Redis缓存最佳实践(问题解析高级实现)&#x…...
)
后端开发——jdbc的学习(一)
上篇结束了Mysql数据库的基本使用,本篇开始对JDBC进行学习总结,开始先简单介绍jdbc的基本使用,以及简单的练习;后续会继续更新!以下代码可以直接复制到idea中运行,便于理解和练习。 JDBC的概念 JDBC&#…...

阿里云免费SSL证书时长只有3个月,应对方法来了
阿里云免费SSL证书签发有效期从12个月缩短至3个月:尊敬的用户,根据供应商变更要求,免费证书(默认证书)的签发有效期将由12个月缩短至3个月。 免费证书(升级证书)的有效期不会改变。 没错&#…...
Flutter 中使用 ICON
Flutter Icon URL : https://fonts.google.com/icons: 在Flutter中使用 Icon 步骤如下: 导入图标库 在Dart 文件中导入 material.dart 包,该包包含了 Flutter 的图标库。 import package:flutter/material.dart;使用图标组件 …...

百度编辑器常用设置
1、创建编辑器 UE.getEditor(editor, { initialFrameWidth:"100%" //初始化选项 }) 精简版 UE.getEditor(editor) 2、删除编辑器 UE.getEditor(editor).destroy(); 3、使编辑器获得焦点 UE.getEditor(editor).focus(); 4、获取编辑器内容 UE.getEditor(editor).getCo…...
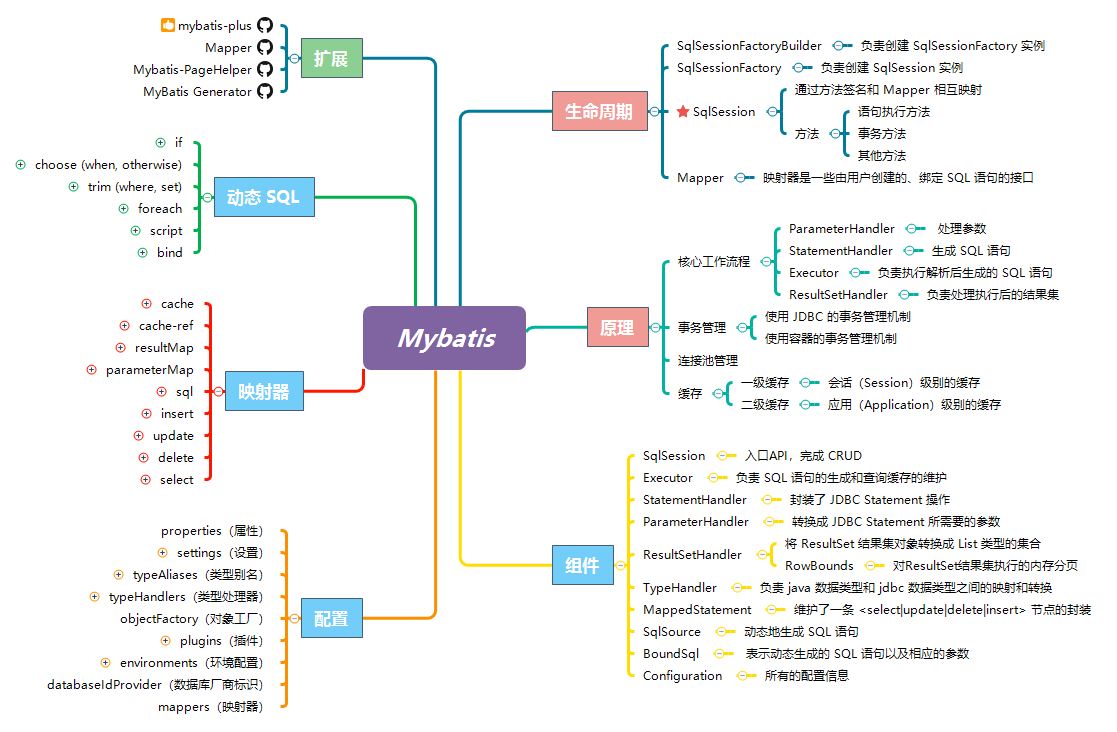
Java ORM 框架 Mybatis详解
📖 内容 Mybatis 的前身就是 iBatis ,是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。本文以一个 Mybatis 完整示例为切入点,结合 Mybatis 底层源码分析,图文并茂的讲解 Mybatis 的核心工作机制。 …...

前端:html+css+js实现CSDN首页
提前说一下,只实现了部分片段哈!如下: 前端:htmlcssjs实现CSDN首页 1. 实现效果2. 需要了解的前端知识3. 固定定位的使用4. js 监听的使用4. 参考代码和运行结果 1. 实现效果 我的实现效果为: 原界面如下,网址为&…...

三种 SqlSession
三种 SqlSession SqlSession 是一个接口,并且里面包含了许多 CRUD 操作数据库等方法。 SqlSession 它有三个实现类,分别是 SqlSessionManager 、DefaultSqlSession 和 SqlSessionTemplate,其中 DefaultSqlSession…...

Mybatis SQL构建器类 - 问题答案
问题 Java开发人员可能会碰到的最棘手的事情之一就是在Java代码中嵌入SQL语句。通常情况下,这是因为需要动态生成SQL语句 - 否则可以将其外部化到文件或存储过程中。正如你已经了解到的,MyBatis在其XML映射功能中有一个强大的解决方案来生成动态SQL。然…...

React 是什么?有什么特性?有哪些优势?
一、是什么 React,用于构建用户界面的 JavaScript 库,只提供了 UI 层面的解决方案 这句话的意思是,React 是一个专注于构建用户界面的 JavaScript 库,它主要关注于解决 UI 层面的问题。它并不是一个全功能的框架,而是…...
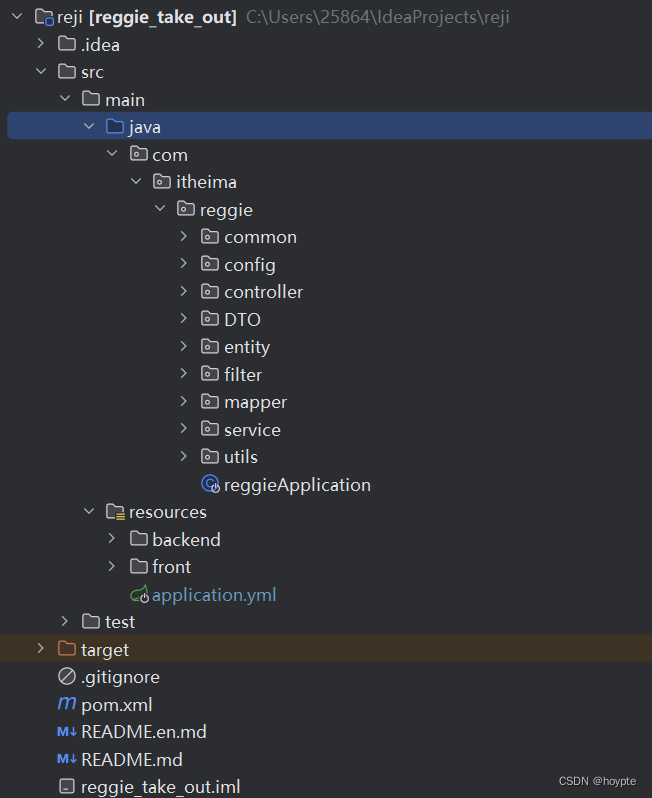
瑞吉外卖项目详细总结
文章目录 瑞吉外卖1.技术栈2.项目文件架构3.业务功能模块(例子)3.1管理员登录接口层(Controller)3.2管理员登录实现层(ServiceImpl)3.3管理员登录服务层(Service)3.4管理员登录Mapper层 4.公共模块4.1 BaseContext(保存…...

Cytoscape 3.10安装包下载及安装教程
Cytoscape3.10下载链接:https://docs.qq.com/doc/DUkpuR0RVU0JVWkFP 1、选中下载好的安装包,右键选择解压到“Cytoscape 3.10”文件夹 2、双击打开“Cytoscape_3_10_0_windows_64bit.exe” 3.点击“Download”,请耐心等待“Java”完成 4、点击…...

data.TensorDataset解析
data.TensorDataset 是 PyTorch 中的一个类,用于创建一个包含多个张量的数据集。这个类的主要作用是将输入的张量组合成一个数据集,使得在训练过程中可以方便地进行数据加载和迭代。 具体来说,TensorDataset 接受一系列的张量作为输入参数&a…...
贝锐花生壳全新功能:浏览器一键远程访问SSHRDP远程桌面
为了满足特定场景的远程访问需求,如:远程群晖NAS设备、远程SQL Server数据库/MySQL数据库、3389远程桌面(RDP远程桌面)、远程SSH、我的世界游戏联机…… 贝锐花生壳推出了场景映射服务,不仅提供满足相应场景的网络带宽…...

2024 年度 AAAI Fellows 揭晓!清华大学朱军教授入选!
今日,国际人工智能领域最权威的学术组织 AAAI 揭晓 2024 年度 Fellows 评选结果,新增 12 位 Fellow。 其中,清华大学计算机系教授朱军因「在机器学习理论与实践方面做出的重大贡献」而成功入选,成为本年度入选的唯一华人学者&…...
:用CA证书签名具有SAN的CSR)
Linux(openssl):用CA证书签名具有SAN的CSR
Linux(openssl):创建CA证书,并用其对CSR进行签名_生成ca证书签名请求文件csr-CSDN博客 提供了方法为CSR进行签名。 对于有SAN的CSR如何签名呢? 1.创建CA证书,与下面的帖子一样...

从零开始了解大数据(七):总结
系列文章目录 从零开始了解大数据(一):数据分析入门篇-CSDN博客 从零开始了解大数据(二):Hadoop篇-CSDN博客 从零开始了解大数据(三):HDFS分布式文件系统篇-CSDN博客 从零开始了解大数据(四):MapReduce篇-CSDN博客 从零开始了解大…...
)
增量预训练经验积累(3)
站在巨人的肩膀上才能走的更远~本文主要是针对《千亿参数开源大模型 BLOOM 背后的技术》进行学习和提取关键经验。 1、BLOOM与Megatron-DeepSpeed 1.1 BLOOM训练细节 BLOOM 的模型架构与 GPT3 非常相似,只是增加了一些改进,176B BLOOM 模型的训练于 2022 年 3 月至 7 月期…...


3步搞定微信聊天记录导出:Mac用户必备的数据备份指南
3步搞定微信聊天记录导出:Mac用户必备的数据备份指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心珍贵的微信聊天记录因为手机丢失或系统升级而…...
)
【AI 越强越离不开工具】:2026 年大模型开发者必备的工具链全景实战(附代码 + 架构图)
前言 目录 前言 一、核心悖论:为什么 AI 越强大,反而越依赖工具? 二、核心拆解:从 Tool 到 Skill 到 Agent,工具链的三层进化逻辑 三、2026 年 AI 工具链全景架构图 四、四大核心工具模块实战(附可直…...

智能重复文件清理:DupeGuru终极配置与实战指南
智能重复文件清理:DupeGuru终极配置与实战指南 【免费下载链接】dupeguru Find duplicate files 项目地址: https://gitcode.com/gh_mirrors/du/dupeguru 在数字时代,重复文件如同无形的存储黑洞,悄无声息地吞噬着宝贵的磁盘空间。无论…...
Zotero PDF Translate终极配置指南:如何一键激活20+翻译服务
Zotero PDF Translate终极配置指南:如何一键激活20翻译服务 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode.com/gh_mir…...

PCL2启动器游戏启动失败的终极解决方案:3步快速修复指南
PCL2启动器游戏启动失败的终极解决方案:3步快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL Plain Craft Launcher 2(PCL2)…...

低代码平台表单设计器 unione form editor 组件介绍--文件上传
低代码平台表单设计器 unione form editor 组件介绍--文件上传 在企业级低代码表单开发中,文件上传组件是实现“附件提交、资料归档、证据留存”的核心组件,广泛应用于合同上传、简历提交、凭证上传、图片上传等场景。不同于其他输入类组件,文…...

C# Winform高效分页实践:SunnyUI uiPagination控件详解与数据绑定
1. 初识SunnyUI uiPagination控件 第一次接触SunnyUI的uiPagination控件是在开发一个订单管理系统时。当时客户抱怨系统加载5000多条记录时会卡顿近10秒,我试过各种传统分页方案都不够理想,直到发现了这个宝藏控件。它就像Winform界的"瑞士军刀&quo…...

开源的精神内核:是自由协作,还是商业公司的免费劳动力?
一、溯源:开源精神的三重底色——自由、共享与协作要理解开源的本质,我们必须先回到其精神原点。开源运动自诞生之日起,就携带着自由、共享与协作的基因,这三者共同构成了其精神内核的底色,缺一不可。自由,…...

Windows平台iOS模拟器开发革命:ipasim如何让iOS应用在Windows上“原生“运行
Windows平台iOS模拟器开发革命:ipasim如何让iOS应用在Windows上"原生"运行 【免费下载链接】ipasim iOS emulator for Windows 项目地址: https://gitcode.com/gh_mirrors/ip/ipasim 嘿,开发者朋友们!你是否曾经梦想过在Win…...