机器学习 -决策树的案例
场景
我们对决策树的基本概念和算法其实已经有过了解,那我们如何利用决策树解决问题呢?
构建决策树
数据准备
我们准备了一些数据如下:
# 定义新的数据集
new_dataSet = [['晴朗', '是', '高', '是'],['雨天', '否', '低', '否'],['阴天', '是', '中', '是'],['晴朗', '否', '高', '是'],['晴朗', '是', '低', '否'],['雨天', '是', '高', '否'],['阴天', '否', '中', '是'],['晴朗', '否', '低', '否']
]
这些数据分别是天气,是否闷热,风速和是否出门郊游。
现在要解决的问题是“基于当前的天气和其他条件,我们是否应该进行户外活动?
构建决策树
我们先检查这个数据集类别是否相同:
classList = [example[-1] for example in dataSet]if classList.count(classList[0]) == len(classList):return classList[0]
很显然,数据集类别不同,那么我们需要检查是否还有特征可分:如果说,只有类别特征的话,我们选择多数:
if len(dataSet[0]) == 1:return majorityCnt(classList)
def majorityCnt(classList):classCount = {} # 创建一个空字典,用于存储每个元素及其出现次数# 遍历传入的列表for vote in classList:# 如果元素不在字典中,将其加入字典并初始化计数为0if vote not in classCount.keys():classCount[vote] = 0# 对于列表中的每个元素,增加其在字典中的计数classCount[vote] += 1# 对字典进行排序。这里使用sorted()函数,以字典的值(即元素的计数)作为排序依据。# key=operator.itemgetter(1)指定按照字典的值(第二个元素)来排序。# reverse=True表示降序排序,即出现次数最多的元素会排在最前面。sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)# 返回出现次数最多的元素。sortedClassCount[0]表示排序后的第一个元素(即出现次数最多的元素),# 而sortedClassCount[0][0]则是该元素本身。return sortedClassCount[0][0]
显然我们除了类别特征还有其他特征,我们选择最佳特征进行分割,所谓最佳特征,就是说有最高的信息增益的特征,信息增益的解释在上一节中有:
传送门:机器学习-决策树
最佳特征的索引是 2,对应于我们数据集中的 ‘风速’ 特征。这意味着在当前数据集中,'风速’在划分数据集时能提供最大的信息增益。OK
def chooseBestFeatureToSplit(dataSet):numFeatures = len(dataSet[0]) - 1 # 计算特征的数量(减去最后一列标签)baseEntropy = calcShannonEnt(dataSet) # 计算数据集当前的熵bestInfoGain = 0.0 # 初始化最佳信息增益bestFeature = -1 # 初始化最佳特征的索引for i in range(numFeatures): # 遍历所有特征featList = [example[i] for example in dataSet] # 提取当前特征列的所有值uniqueVals = set(featList) # 获取当前特征的唯一值集合newEntropy = 0.0 # 初始化新熵for value in uniqueVals: # 遍历当前特征的每个唯一值subDataSet = splitDataSet(dataSet, i, value) # 根据当前特征和值分割数据集prob = len(subDataSet) / float(len(dataSet)) # 计算子数据集的比例newEntropy += prob * calcShannonEnt(subDataSet) # 计算新熵,并累加infoGain = baseEntropy - newEntropy # 计算信息增益if abs(infoGain) > abs(bestInfoGain):bestInfoGain = infoGain # 更新最佳信息增益bestFeature = i # 更新最佳特征索引return bestFeature # 返回最佳特征的索引下一步是使用这个特征来分割数据集,并递归地创建决策树。我们将对这个特征的每个唯一值进行分割,并在每个子集上重复此过程。这将形成决策树的不同分支。让我们开始构建决策树。
bestFeatLabel = labels[bestFeat]myTree = {bestFeatLabel:{}}del(labels[bestFeat])featValues = [example[bestFeat] for example in dataSet]uniqueVals = set(featValues)for value in uniqueVals:subLabels = labels[:] #copy all of labels, so trees don't mess up existing labelsmyTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
如果一个特征有多个唯一值,那么 uniqueVals 将包含这些值,决策树的每个分支将对应这些值之一。
通过这些步骤,决策树逐渐在数据集的特征上进行分割,直到所有的数据都被正确分类或没有更多的特征可以用来进一步分割。
最终的决策树应该长这样:
{'其他条件2': {'低': '否', '中': '是', '高': {'天气': {'晴朗': '是', '雨天': '否'}}}
}
完整可执行代码
完整的代码如下:
# 计算熵
def calcShannonEnt(dataSet):# 统计实例总数numEntries = len(dataSet)# 字典标签,统计标签出现的次数labelCounts = {}for data in dataSet:# 每个实例的最后一个元素是标签元素currentLabel = data[-1]if currentLabel not in labelCounts:labelCounts[currentLabel] = 0# 为当前类别标签的计数加一labelCounts[currentLabel] += 1# 设置初始熵shannonEnt = 0.0 # 初始化熵为0for key in labelCounts:prob = float(labelCounts[key]) / numEntries # 计算每个类别标签的出现概率shannonEnt -= prob * log(prob, 2) # 使用香农熵公式计算并累加熵return shannonEnt # 返回计算得到的熵def majorityCnt(classList):classCount = {} # 创建一个空字典,用于存储每个元素及其出现次数# 遍历传入的列表for vote in classList:# 如果元素不在字典中,将其加入字典并初始化计数为0if vote not in classCount.keys():classCount[vote] = 0# 对于列表中的每个元素,增加其在字典中的计数classCount[vote] += 1# 对字典进行排序。这里使用sorted()函数,以字典的值(即元素的计数)作为排序依据。# key=operator.itemgetter(1)指定按照字典的值(第二个元素)来排序。# reverse=True表示降序排序,即出现次数最多的元素会排在最前面。sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)# 返回出现次数最多的元素。sortedClassCount[0]表示排序后的第一个元素(即出现次数最多的元素),# 而sortedClassCount[0][0]则是该元素本身。return sortedClassCount[0][0]def splitDataSet(dataSet, axis, value):retDataSet = [] # 创建一个新的列表用于存放分割后的数据集for featVec in dataSet: # 遍历数据集中的每个样本if featVec[axis] == value: # 检查当前样本在指定特征轴上的值是否等于给定的值reducedFeatVec = featVec[:axis] # 截取当前样本直到指定特征轴的部分reducedFeatVec.extend(featVec[axis+1:]) # 将指定特征轴之后的部分添加到截取的列表中retDataSet.append(reducedFeatVec) # 将处理后的样本添加到分割后的数据集列表中return retDataSet # 返回分割后的数据集def chooseBestFeatureToSplit(dataSet):numFeatures = len(dataSet[0]) - 1 # 计算特征的数量(减去最后一列标签)baseEntropy = calcShannonEnt(dataSet) # 计算数据集当前的熵bestInfoGain = 0.0 # 初始化最佳信息增益bestFeature = -1 # 初始化最佳特征的索引for i in range(numFeatures): # 遍历所有特征featList = [example[i] for example in dataSet] # 提取当前特征列的所有值uniqueVals = set(featList) # 获取当前特征的唯一值集合newEntropy = 0.0 # 初始化新熵for value in uniqueVals: # 遍历当前特征的每个唯一值subDataSet = splitDataSet(dataSet, i, value) # 根据当前特征和值分割数据集prob = len(subDataSet) / float(len(dataSet)) # 计算子数据集的比例newEntropy += prob * calcShannonEnt(subDataSet) # 计算新熵,并累加infoGain = baseEntropy - newEntropy # 计算信息增益if abs(infoGain) > abs(bestInfoGain):bestInfoGain = infoGain # 更新最佳信息增益bestFeature = i # 更新最佳特征索引return bestFeature # 返回最佳特征的索引def createTree(dataSet,labels):classList = [example[-1] for example in dataSet]if classList.count(classList[0]) == len(classList):return classList[0]#stop splitting when all of the classes are equalif len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSetreturn majorityCnt(classList)bestFeat = chooseBestFeatureToSplit(dataSet)bestFeatLabel = labels[bestFeat]myTree = {bestFeatLabel:{}}del(labels[bestFeat])featValues = [example[bestFeat] for example in dataSet]uniqueVals = set(featValues)for value in uniqueVals:subLabels = labels[:] #copy all of labels, so trees don't mess up existing labelsmyTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)return myTree这是完整的代码,可以试着玩一下,可玩性还是ok的。
结束
决策树的案例到此结束,事实上和IF比较相似。
相关文章:

机器学习 -决策树的案例
场景 我们对决策树的基本概念和算法其实已经有过了解,那我们如何利用决策树解决问题呢? 构建决策树 数据准备 我们准备了一些数据如下: # 定义新的数据集 new_dataSet [[晴朗, 是, 高, 是],[雨天, 否, 低, 否],[阴天, 是, 中, 是],[晴朗…...
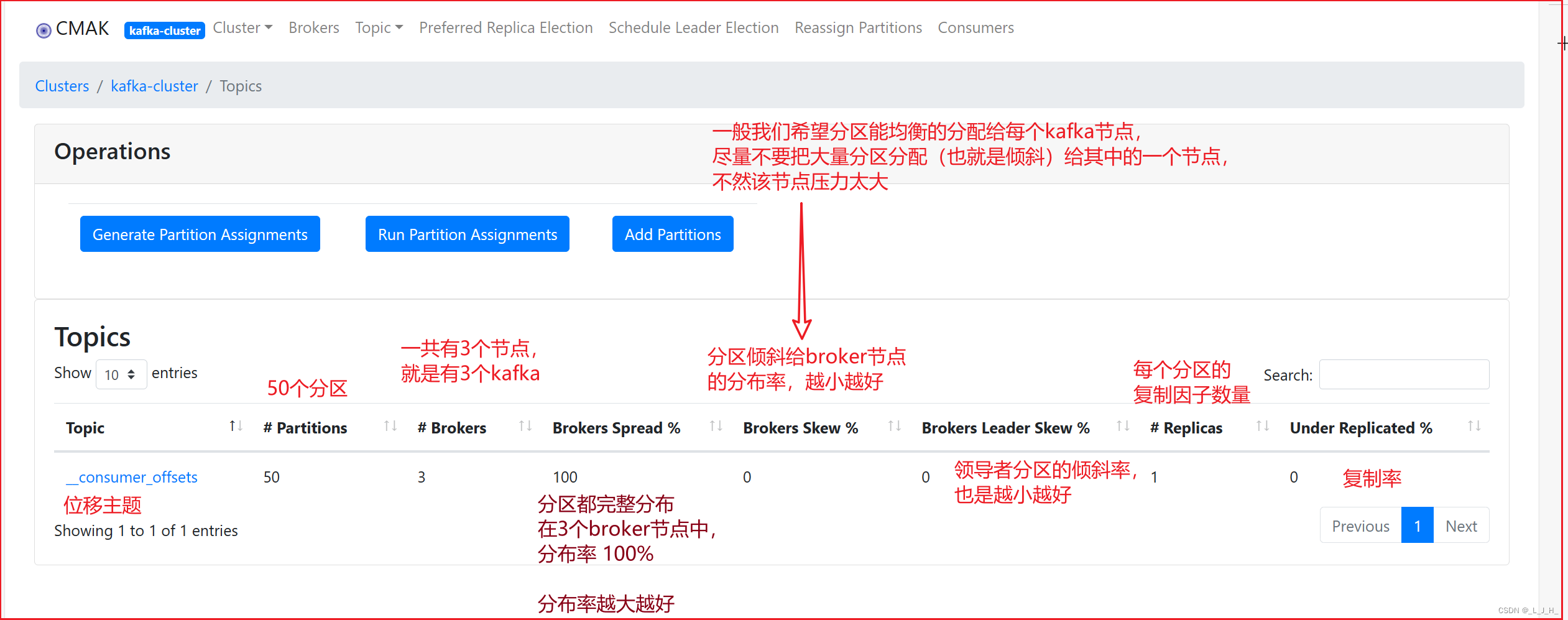
04、Kafka ------ 各个功能的作用解释(Cluster、集群、Broker、位移主题、复制因子、领导者副本、主题)
目录 启动命令:CMAK的用法★ 在CMAK中添加 Cluster★ 在CMAK中查看指定集群★ 在CMAK中查看 Broker★ 位移主题★ 复制因子★ 领导者副本和追随者副本★ 查看主题 启动命令: 1、启动 zookeeper 服务器端 小黑窗输入命令: zkServer 2、启动 …...

1、C语言:数据类型/运算符与表达式
数据类型/运算符/表达式 1.数据类型与长度2.常量3.声明4. 运算符5. 表达式 1.数据类型与长度 基本数据类型 类型说明char字符型,占用一个字节,可以存放本地字符集中的一个字符int整型,通常反映了所有机器中整数的最自然长度float单精度浮点…...
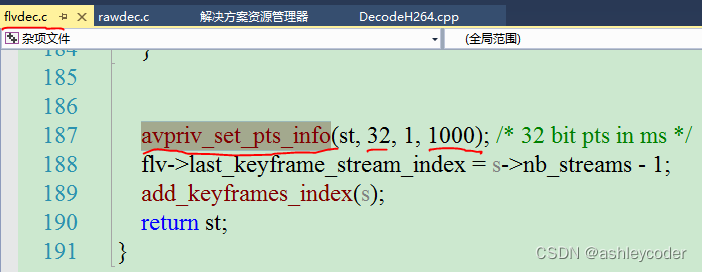
[ffmpeg系列 03] 文件、流地址(视频)解码为YUV
一 代码 ffmpeg版本5.1.2,dll是:ffmpeg-5.1.2-full_build-shared。x64的。 文件、流地址对使用者来说是一样。 流地址(RTMP、HTTP-FLV、RTSP等):信令完成后,才进行音视频传输。信令包括音视频格式、参数等协商。 接流的在实际…...

python算法每日一练:连续子数组的最大和
这是一道关于动态规划的算法题: 题目描述: 给定一个整数数组 nums,请找出该数组中连续子数组的最大和,并返回这个最大和。 示例: 输入:[-2, 1, -3, 4, -1, 2, 1, -5, 4] 输出:6 解释ÿ…...
一个vue3的tree组件
https://download.csdn.net/download/weixin_41012767/88709466...

新手练习项目 4:简易2048游戏的实现(C++)
名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder) 目录 一、效果图二、代码(带注释)三、说明 一、效果图 二、代码(带…...

2023年度总结:技术沉淀、持续学习
2023年度总结:技术沉淀、持续学习 一、引言 今年是我毕业的第二个年头,也是完整的一年,到了做年终总结的时候了 这一年谈了女朋友,学习了不少技术,是充实且美好的一年! 首先先看年初定的小目标…...
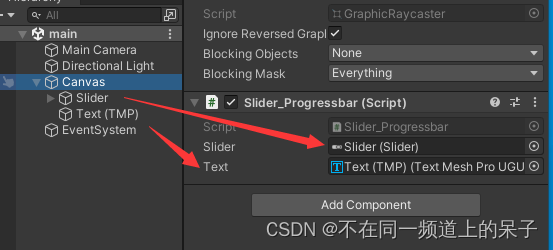
Unity 利用UGUI之Slider制作进度条
在Unity中使用Slider和Text组件可以制作简单的进度条。 首先在场景中右键->UI->Slider,新建一个Slider组件: 同样方法新建一个Text组件,最终如图: 创建一个进度模拟脚本,Slider_Progressbar.cs using System.C…...
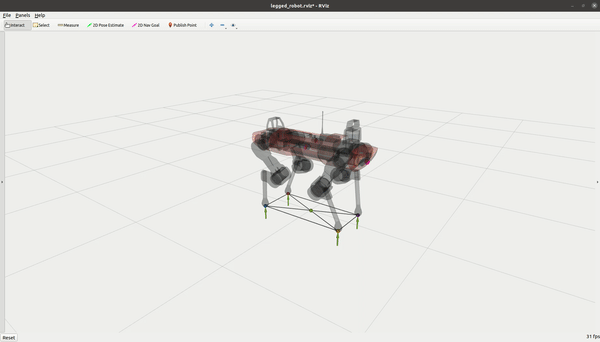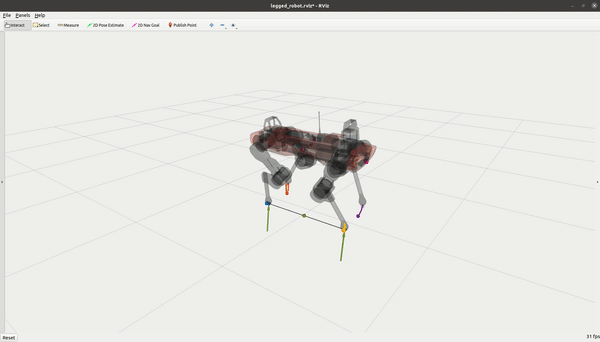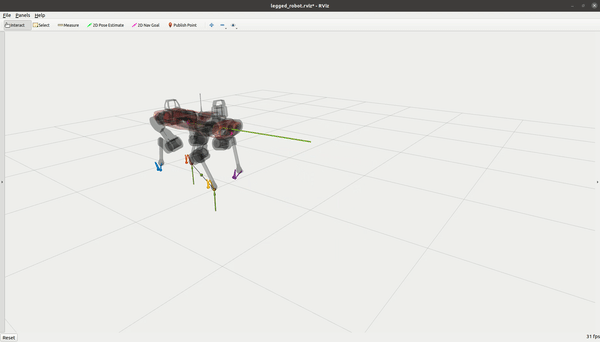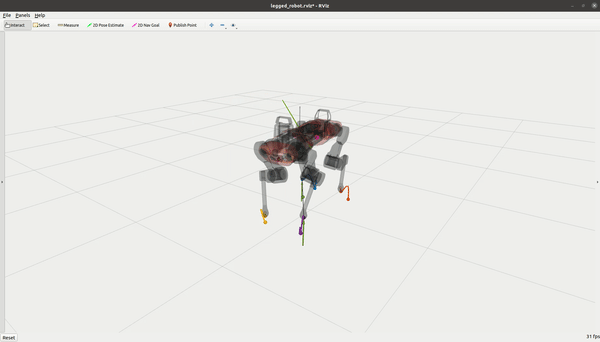
OCS2 入门教程(四)- 机器人示例
系列文章目录 前言 OCS2 包含多个机器人示例。我们在此简要讨论每个示例的主要特点。 System State Dim. Input Dim. Constrained Caching Double Integrator 2 1 No No Cartpole 4 1 Yes No Ballbot 10 3 No No Quadrotor 12 4 No No Mobile Manipul…...

FreeRTOS学习第6篇–任务状态挂起恢复删除等操作
目录 FreeRTOS学习第6篇--任务状态挂起恢复删除等操作任务的状态设计实验IRReceiver_Task任务相关代码片段实验现象本文中使用的测试工程 FreeRTOS学习第6篇–任务状态挂起恢复删除等操作 本文目标:学习与使用FreeRTOS中的几项操作,有挂起恢复删除等操作…...
BLE Mesh蓝牙组网技术详细解析之Access Layer访问层(六)
目录 一、什么是BLE Mesh Access Layer访问层? 二、Access payload 2.1 Opcode 三、Access layer behavior 3.1 Access layer发送消息的流程 3.2 Access layer接收消息的流程 3.3 Unacknowledged and acknowledged messages 3.3.1 Unacknowledged message …...

Netlink 通信机制
文章目录 前言一、Netlink 介绍二、示例代码参考资料 前言 一、Netlink 介绍 Netlink套接字是用以实现用户进程与内核进程通信的一种特殊的进程间通信(IPC) ,也是网络应用程序与内核通信的最常用的接口。 在Linux 内核中,使用netlink 进行应用与内核通信的应用有…...

2024.1.8每日一题
LeetCode 回旋镖的数量 447. 回旋镖的数量 - 力扣(LeetCode) 题目描述 给定平面上 n 对 互不相同 的点 points ,其中 points[i] [xi, yi] 。回旋镖 是由点 (i, j, k) 表示的元组 ,其中 i 和 j 之间的距离和 i 和 k 之间的欧式…...
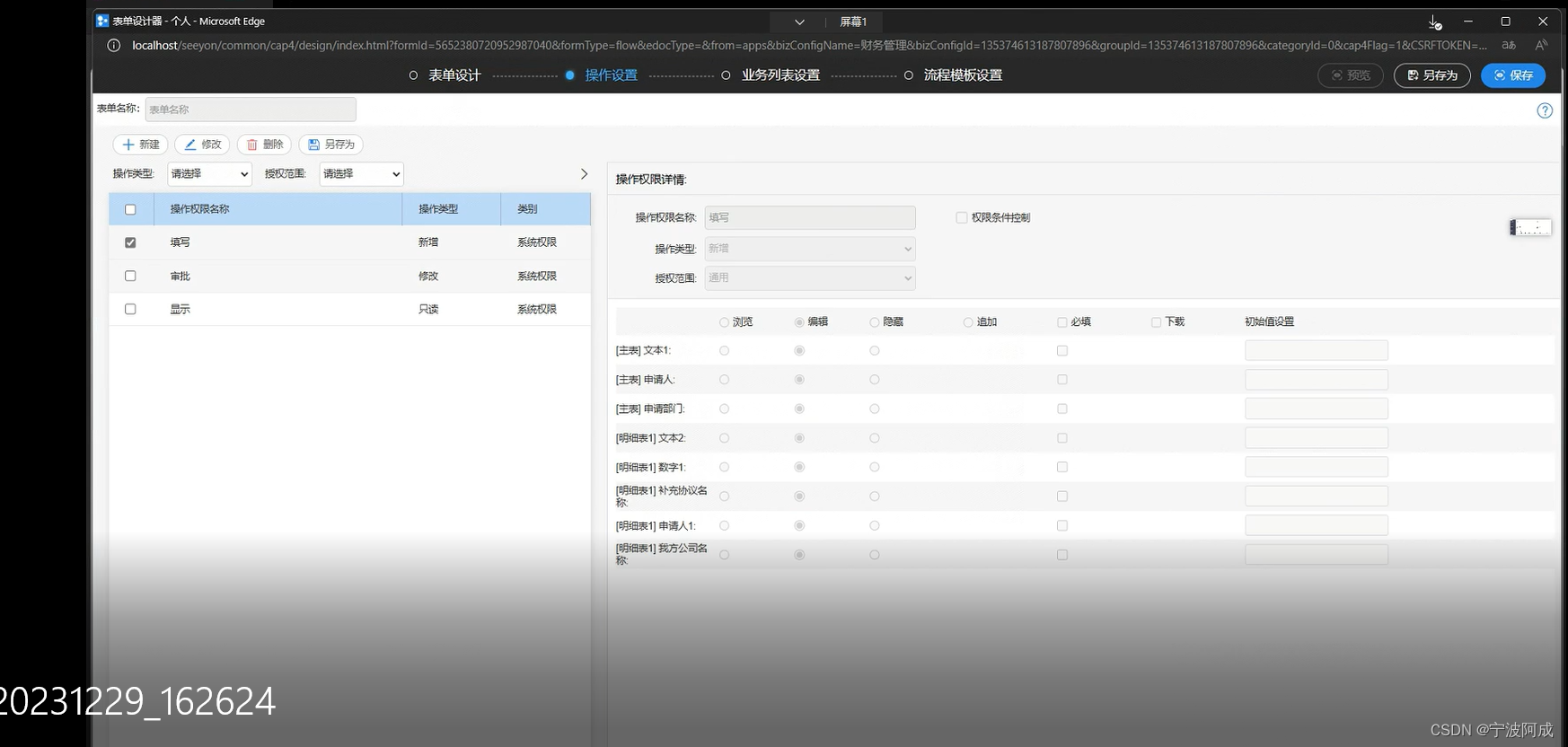
看了致远OA的表单设计后的思考
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 更多nbcio-boot功能请看演示系统 gitee源代码地址 后端代码: https://gitee.com/nbacheng/n…...
mmdetection训练自己的数据集
mmdetection训练自己的数据集 这里写目录标题 mmdetection训练自己的数据集一: 环境搭建二:数据集格式转换(yolo转coco格式)yolo数据集格式coco数据集格式yolo转coco数据集格式yolo转coco数据集格式的代码 三: 训练dataset数据文件配置config…...

MySQL取出N列里最大or最小的一个数据
如题,现在有3列,都是数字类型,要取出这3列里最大或最小的的一个数字 -- N列取最小 SELECT LEAST(temperature_a,temperature_b,temperature_c) min FROM infrared_heat-- N列取最大 SELECT GREATEST(temperature_a,temperature_b,temperat…...
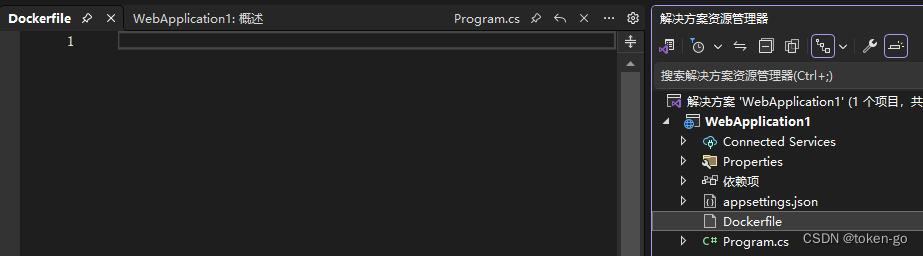
编写.NET的Dockerfile文件构建镜像
创建一个WebApi项目,并且创建一个Dockerfile空文件,添加以下代码,7.0代表的你项目使用的SDK的版本,构建的时候也需要选择好指定的镜像tag FROM mcr.microsoft.com/dotnet/aspnet:7.0 AS base WORKDIR /app EXPOSE 80 EXPOSE 443F…...
 练习7-4 找出不是两个数组共有的元素)
【C语言】浙大版C语言程序设计(第三版) 练习7-4 找出不是两个数组共有的元素
前言 最近在学习浙大版的《C语言程序设计》(第三版)教材,同步在PTA平台上做对应的练习题。这道练习题花了比较长的时间,于是就写篇博文记录一下我的算法和代码。 2024.01.03 题目 练习7-4 找出不是两个数组共有的元素 作者 张彤…...

7.27 SpringBoot项目实战 之 整合Swagger
文章目录 前言一、Maven依赖二、编写Swagger配置类三、编写接口配置3.1 控制器Controller 配置描述3.2 接口API 配置描述3.3 参数配置描述3.4 忽略API四、全局参数配置五、启用增强功能六、调试前言 在我们实现了那么多API以后,进入前后端联调阶段,需要给前端同学提供接口文…...

动感软膜天花技术白皮书:从异形设计到商业照明的实战解析
动感软膜天花技术白皮书:从异形设计到商业照明的实战解析动感软膜天花的科技内核与市场演进当人们走进现代商业空间,头顶那片既能模拟蓝天白云软膜天花效果,又能实现动态光影变幻的顶面系统,正是动感软膜天花技术的具象化呈现。这…...

FreeVA:零训练成本,用图像大模型实现视频理解的新范式
1. 项目概述:一个无需训练的“零成本”视频助手 最近在折腾多模态大模型(MLLM)的时候,我发现了一个挺有意思的现象:大家一提到让模型理解视频,第一反应就是得搞“视频指令微调”。简单说,就是拿…...

Steam成就管理神器:如何在5分钟内解锁所有成就的终极完整指南
Steam成就管理神器:如何在5分钟内解锁所有成就的终极完整指南 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 还在为Steam游戏中那些遥不可及的…...

抖音图片怎么去水印?2026实测免费去水印方法全盘点,这几款工具真好用
抖音图片怎么去水印?2026实测免费去水印方法全盘点,这几款工具真好用 刷抖音的时候,你有没有遇到过这种情况:看到一张超好看的图片,点保存,结果发现角落里多了一行「用户名」或者一个抖音 Logo,…...

基于Helm与Kubernetes的以太坊节点自动化部署与运维实战
1. 项目概述:当以太坊遇见Kubernetes如果你和我一样,在区块链基础设施领域摸爬滚打多年,从早期手动编译客户端、配置systemd服务,到后来用Docker Compose编排节点,每一步都伴随着大量的重复劳动和运维痛点。当节点数量…...

Windows Cleaner终极指南:3步解决C盘爆红和电脑卡顿难题
Windows Cleaner终极指南:3步解决C盘爆红和电脑卡顿难题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设计的…...

基于大语言模型的银行对账单自动化分析与财务预测实战
1. 项目概述:当大语言模型遇上个人财务分析最近在GitHub上看到一个挺有意思的项目,叫“AI银行对账单文档自动化与个人财务分析预测”。光看这个标题,就能感觉到一股浓浓的“技术赋能生活”的味道。简单来说,这个项目想干的事儿&am…...

Clawforce:开源AI智能体团队基础设施,实现持久化与安全协作
1. 项目概述:Clawforce,一个为持久化AI智能体团队构建的基础设施最近在AI智能体领域,一个词被反复提及:“Agentic AI”,即智能体驱动的AI。这不再是让单个AI模型回答一个问题那么简单,而是构建一个能够自主…...

谷歌seo如何发布外链? 推荐3个外贸SOHO全自动工具
身处外贸圈的人都明白,空有一身好产品,网站在谷歌搜不到也是白搭。现在的算法比五年前聪明太多,靠那种五块钱一千条的群发软件纯属给自己的域名“投毒”。我在操作几十个独立站的过程中发现,外链的数量早就不吃香了,现…...

初创公司如何利用Taotoken快速构建AI产品原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何利用Taotoken快速构建AI产品原型 对于资源有限的初创团队而言,验证产品想法、快速推出原型是生存和发展的…...