Python综合数据分析_RFM用户分层模型
文章目录
- 1.数据加载
- 2.查看数据情况
- 3.数据合并及填充
- 4.查看特征字段之间相关性
- 5.聚合操作
- 6.时间维度上看销售额
- 7.计算用户RFM
- 8.数据保存存储
- (1).to_csv
- (1).to_pickle
1.数据加载
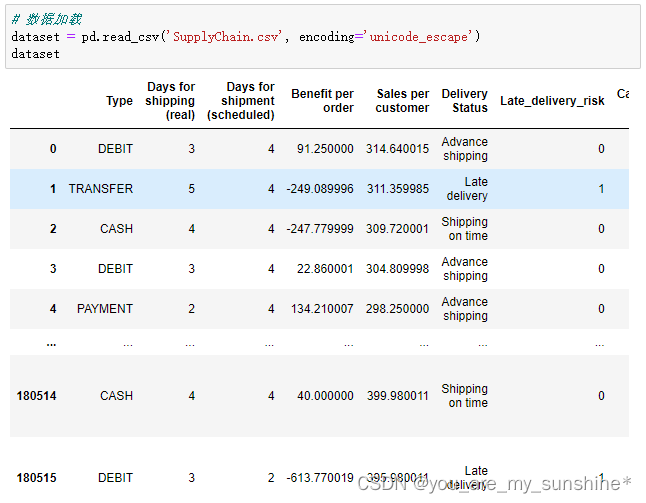
import pandas as pd
dataset = pd.read_csv('SupplyChain.csv', encoding='unicode_escape')
dataset
2.查看数据情况
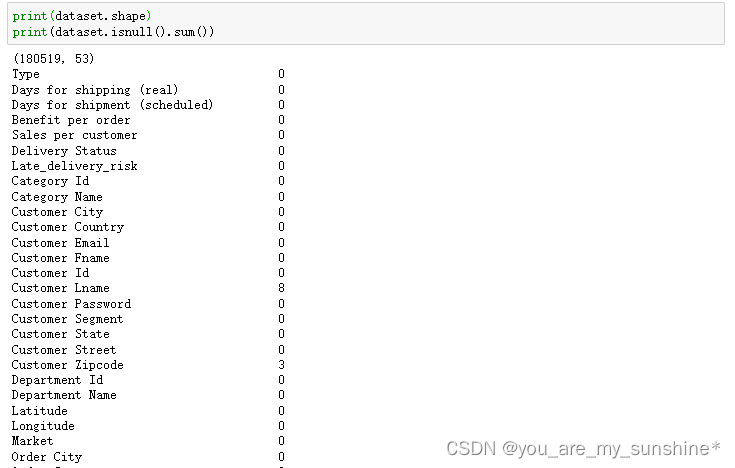
print(dataset.shape)
print(dataset.isnull().sum())

3.数据合并及填充
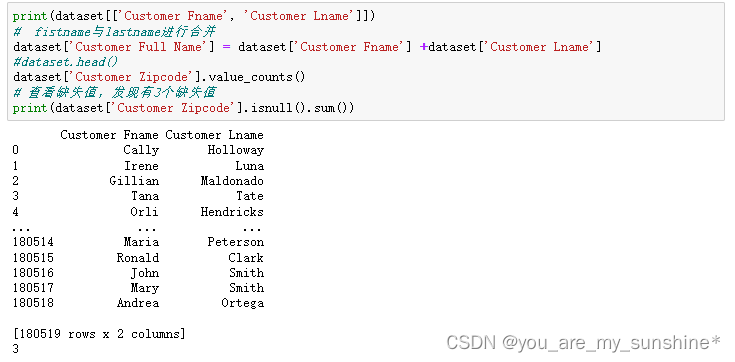
print(dataset[['Customer Fname', 'Customer Lname']])
# fistname与lastname进行合并
dataset['Customer Full Name'] = dataset['Customer Fname'] +dataset['Customer Lname']
#dataset.head()
dataset['Customer Zipcode'].value_counts()
# 查看缺失值,发现有3个缺失值
print(dataset['Customer Zipcode'].isnull().sum())
dataset['Customer Zipcode'] = dataset['Customer Zipcode'].fillna(0)
dataset.head()

4.查看特征字段之间相关性
import matplotlib.pyplot as plt
import seaborn as sns
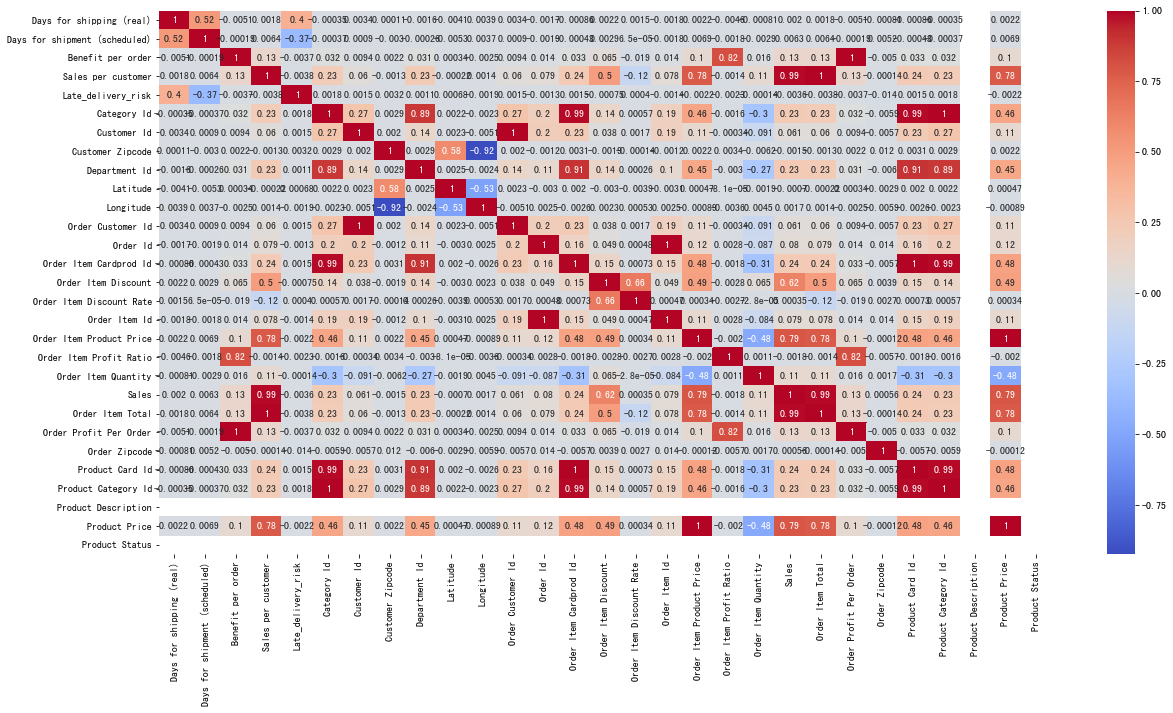
# 特征字段之间相关性 热力图
data = dataset
plt.figure(figsize=(20,10))
# annot=True 显示具体数字
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
# 结论:可以观察到Product Price和Sales,Order Item Total有很高的相关性
5.聚合操作
# 基于Market进行聚合
market = data.groupby('Market')
# 基于Region进行聚合
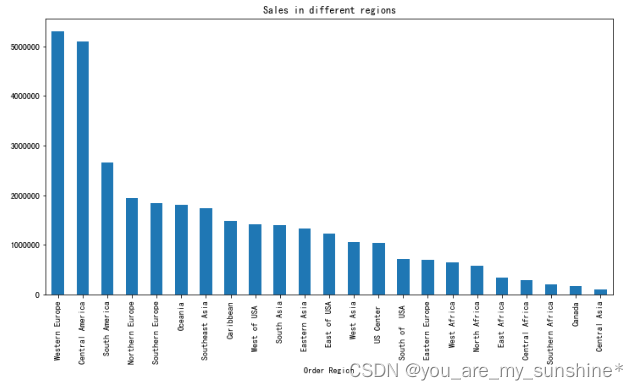
region = data.groupby('Order Region')
plt.figure(1)
market['Sales per customer'].sum().sort_values(ascending=False).plot.bar(figsize=(12,6), title='Sales in different markets')
plt.figure(2)
region['Sales per customer'].sum().sort_values(ascending=False).plot.bar(figsize=(12,6), title='Sales in different regions')
plt.show()

# 基于Category Name进行聚类
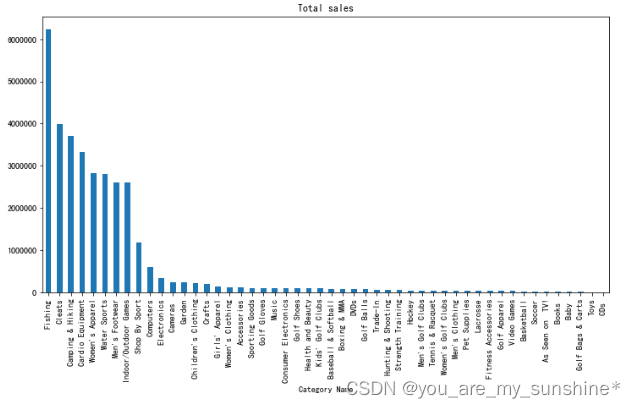
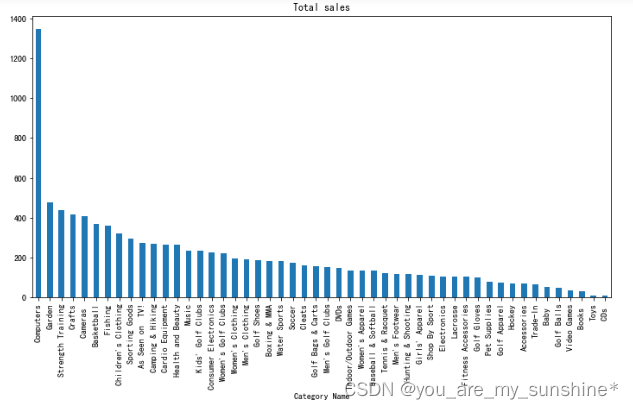
cat = data.groupby('Category Name')
plt.figure(1)
# 不同类别的 总销售额
cat['Sales per customer'].sum().sort_values(ascending=False).plot.bar(figsize=(12,6), title='Total sales')
plt.figure(2)
# 不同类别的 平均销售额
cat['Sales per customer'].mean().sort_values(ascending=False).plot.bar(figsize=(12,6), title='Total sales')
plt.show()
6.时间维度上看销售额
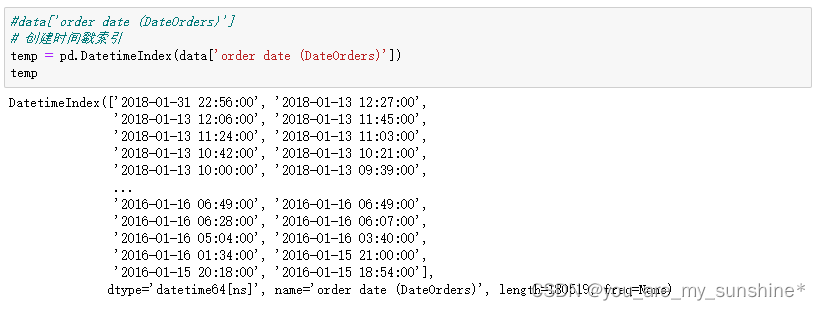
#data['order date (DateOrders)']
# 创建时间戳索引
temp = pd.DatetimeIndex(data['order date (DateOrders)'])
temp
# 取order date (DateOrders)字段中的year, month, weekday, hour, month_year
data['order_year'] = temp.year
data['order_month'] = temp.month
data['order_week_day'] = temp.weekday
data['order_hour'] = temp.hour
data['order_month_year'] = temp.to_period('M')
data.head()

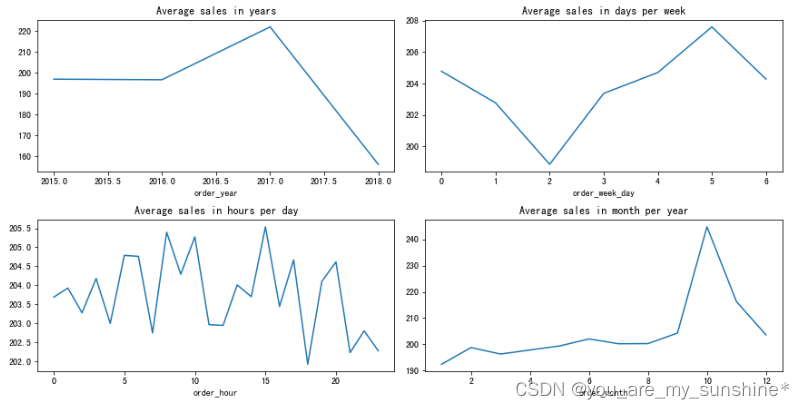
# 对销售额进行探索,按照不同时间维度 年,星期,小时,月
plt.figure(figsize=(10, 12))
plt.subplot(4, 2, 1)
df_year = data.groupby('order_year')
df_year['Sales'].mean().plot(figsize=(12, 12), title='Average sales in years')
plt.subplot(4, 2, 2)
df_day = data.groupby('order_week_day')
df_day['Sales'].mean().plot(figsize=(12, 12), title='Average sales in days per week')
plt.subplot(4, 2, 3)
df_hour = data.groupby('order_hour')
df_hour['Sales'].mean().plot(figsize=(12, 12), title='Average sales in hours per day')
plt.subplot(4, 2, 4)
df_month = data.groupby('order_month')
df_month['Sales'].mean().plot(figsize=(12, 12), title='Average sales in month per year')
plt.tight_layout()
plt.show()
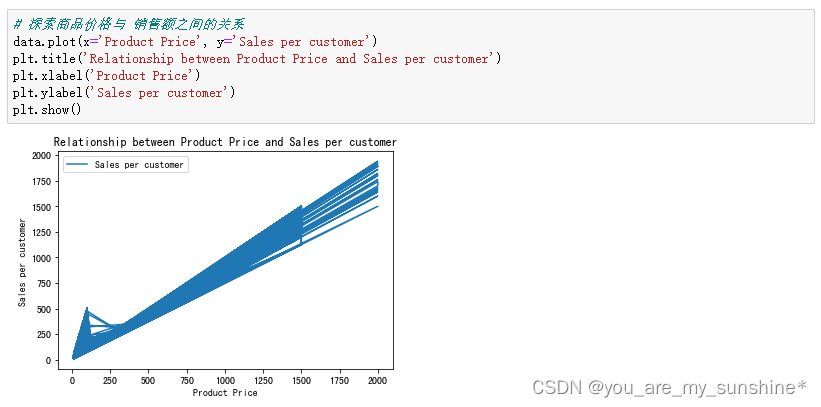
# 探索商品价格与 销售额之间的关系
data.plot(x='Product Price', y='Sales per customer')
plt.title('Relationship between Product Price and Sales per customer')
plt.xlabel('Product Price')
plt.ylabel('Sales per customer')
plt.show()
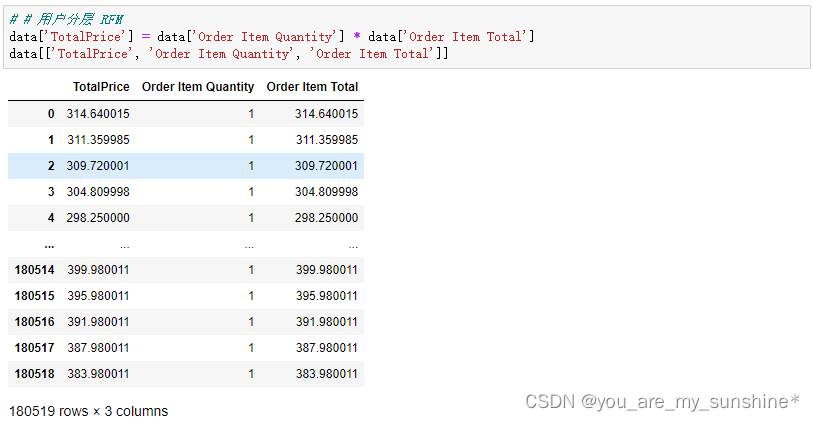
7.计算用户RFM
# # 用户分层 RFM
data['TotalPrice'] = data['Order Item Quantity'] * data['Order Item Total']
data[['TotalPrice', 'Order Item Quantity', 'Order Item Total']]
# 时间类型转换
data['order date (DateOrders)'] = pd.to_datetime(data['order date (DateOrders)'])
# 统计最后一笔订单的时间
data['order date (DateOrders)'].max()

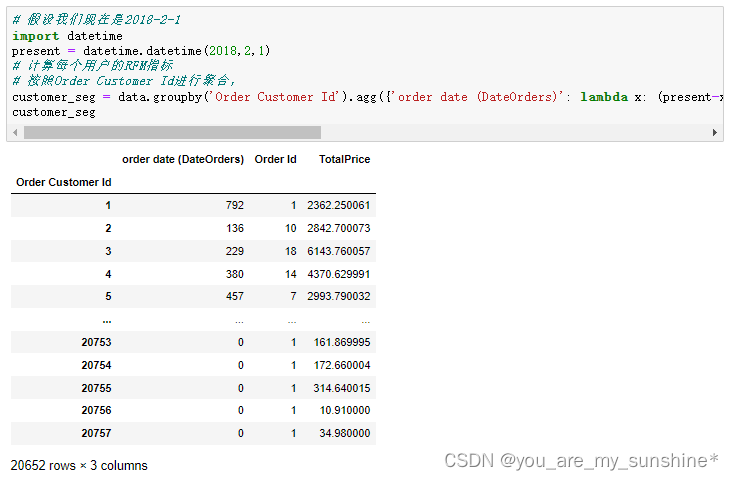
# 假设我们现在是2018-2-1
import datetime
present = datetime.datetime(2018,2,1)
# 计算每个用户的RFM指标
# 按照Order Customer Id进行聚合,
customer_seg = data.groupby('Order Customer Id').agg({'order date (DateOrders)': lambda x: (present-x.max()).days, 'Order Id': lambda x:len(x), 'TotalPrice': lambda x: x.sum()})
customer_seg
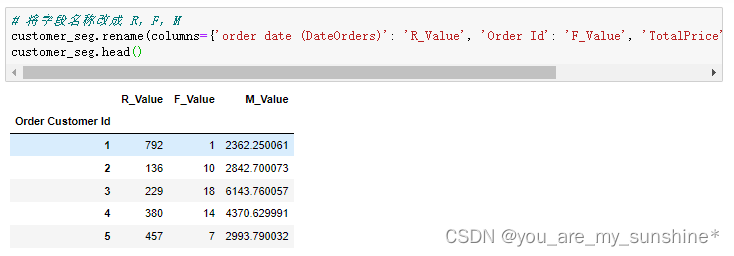
# 将字段名称改成 R,F,M
customer_seg.rename(columns={'order date (DateOrders)': 'R_Value', 'Order Id': 'F_Value', 'TotalPrice': 'M_Value'}, inplace=True)
customer_seg.head()
# 将RFM数据划分为4个尺度
quantiles = customer_seg.quantile(q=[0.25, 0.5, 0.75])
quantiles = quantiles.to_dict()
quantiles

# R_Value越小越好 => R_Score就越大
def R_Score(a, b, c):if a <= c[b][0.25]:return 4elif a <= c[b][0.50]:return 3elif a <= c[b][0.75]:return 2else:return 1# F_Value, M_Value越大越好
def FM_Score(a, b, c):if a <= c[b][0.25]:return 1elif a <= c[b][0.50]:return 2elif a <= c[b][0.75]:return 3else:return 4
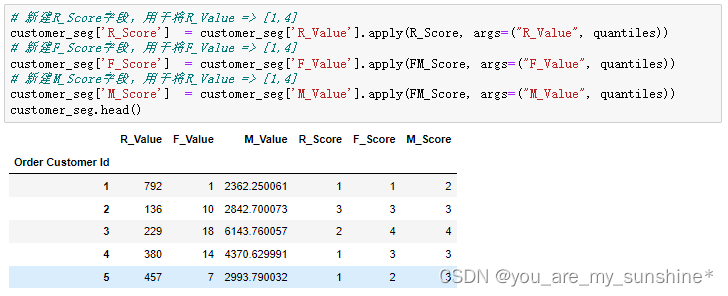
# 新建R_Score字段,用于将R_Value => [1,4]
customer_seg['R_Score'] = customer_seg['R_Value'].apply(R_Score, args=("R_Value", quantiles))
# 新建F_Score字段,用于将F_Value => [1,4]
customer_seg['F_Score'] = customer_seg['F_Value'].apply(FM_Score, args=("F_Value", quantiles))
# 新建M_Score字段,用于将R_Value => [1,4]
customer_seg['M_Score'] = customer_seg['M_Value'].apply(FM_Score, args=("M_Value", quantiles))
customer_seg.head()
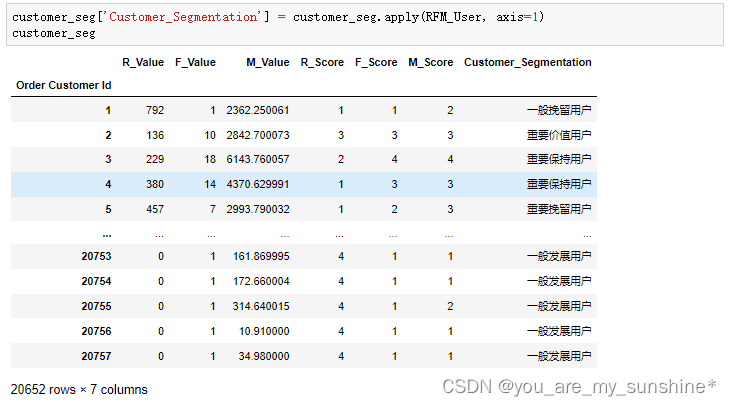
# 计算RFM用户分层
def RFM_User(df):if df['M_Score'] > 2 and df['F_Score'] > 2 and df['R_Score'] > 2:return '重要价值用户'if df['M_Score'] > 2 and df['F_Score'] <= 2 and df['R_Score'] > 2:return '重要发展用户'if df['M_Score'] > 2 and df['F_Score'] > 2 and df['R_Score'] <= 2:return '重要保持用户'if df['M_Score'] > 2 and df['F_Score'] <= 2 and df['R_Score'] <= 2:return '重要挽留用户'if df['M_Score'] <= 2 and df['F_Score'] > 2 and df['R_Score'] > 2:return '一般价值用户'if df['M_Score'] <= 2 and df['F_Score'] <= 2 and df['R_Score'] > 2:return '一般发展用户'if df['M_Score'] <= 2 and df['F_Score'] > 2 and df['R_Score'] <= 2:return '一般保持用户'if df['M_Score'] <= 2 and df['F_Score'] <= 2 and df['R_Score'] <= 2:return '一般挽留用户'customer_seg['Customer_Segmentation'] = customer_seg.apply(RFM_User, axis=1)
customer_seg
8.数据保存存储
(1).to_csv
customer_seg.to_csv('supply_chain_rfm_result.csv', index=False)
(1).to_pickle
# 数据预处理后,将处理后的数据进行保存
data.to_pickle('data.pkl')
参考资料:开课吧
相关文章:
Python综合数据分析_RFM用户分层模型
文章目录 1.数据加载2.查看数据情况3.数据合并及填充4.查看特征字段之间相关性5.聚合操作6.时间维度上看销售额7.计算用户RFM8.数据保存存储(1).to_csv(1).to_pickle 1.数据加载 import pandas as pd dataset pd.read_csv(SupplyChain.csv, encodingunicode_escape) dataset2…...
【C++进阶04】STL中map、set、multimap、multiset的介绍及使用
一、关联式容器 vector/list/deque… 这些容器统称为序列式容器 因为其底层为线性序列的数据结构 里面存储的是元素本身 map/set… 这些容器统称为关联式容器 关联式容器也是用来存储数据的 与序列式容器不同的是 其里面存储的是<key, value>结构的键值对 在数据检索时…...

在 Linux 中开启 Flask 项目持续运行
在 Linux 中开启 Flask 项目持续运行 在部署 Flask 项目时,情况往往并不是那么理想。默认情况下,关闭 SSH 终端后,Flask 服务就停止了。这时,您需要找到一种方法在 Linux 服务器上实现持续运行 Flask 项目,并在服务器…...

考研个人经验总结【心理向】
客官你好 首先,不管你是以何种原因来到这篇博客,以下内容或多或少可能带给你一些启发。如果你还是大二or大三学生,有考研的打算,不妨提前了解一些考研必备的心理战术,有时候并不是你知识学得不好,而是思维…...
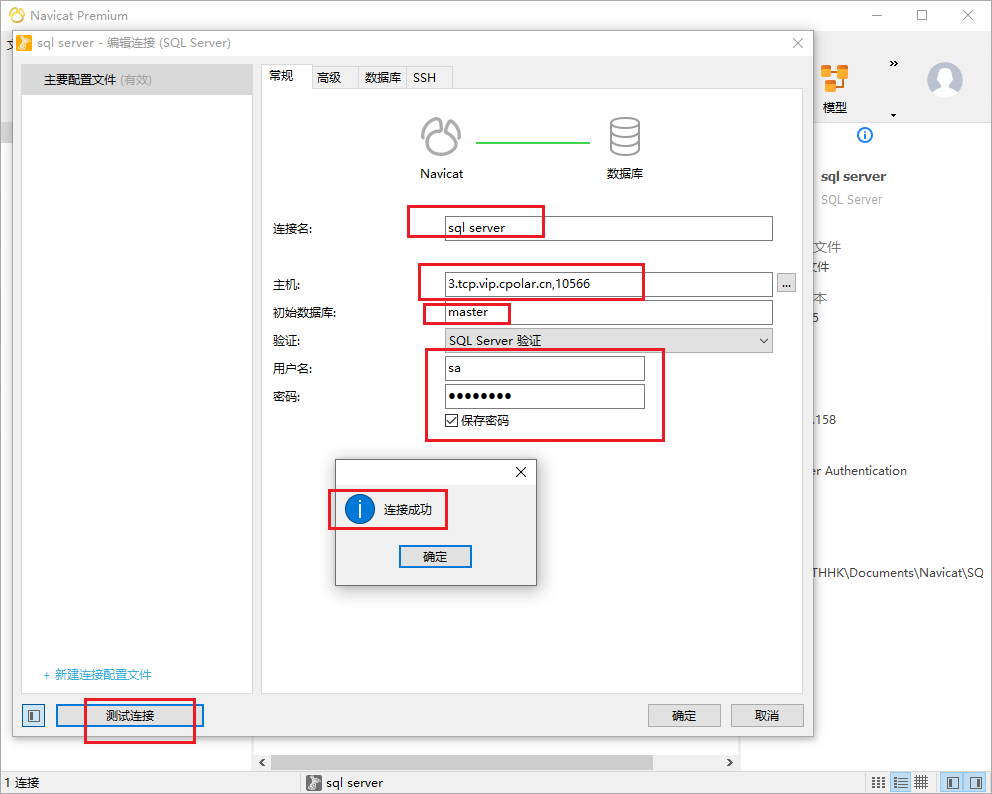
如何在CentOS安装SQL Server数据库并通过内网穿透工具实现公网访问
文章目录 前言1. 安装sql server2. 局域网测试连接3. 安装cpolar内网穿透4. 将sqlserver映射到公网5. 公网远程连接6.固定连接公网地址7.使用固定公网地址连接 前言 简单几步实现在Linux centos环境下安装部署sql server数据库,并结合cpolar内网穿透工具࿰…...

jupyter内核错误
1、在dos窗口输入以下命令激活环境:anaconda activate 【py环境名,比如py37】(目的是新家你一个虚拟环境) 2、在虚拟环境py37下安装jupyter notebook,命令:pip install jupyter notebook 3、安装ipykerne…...
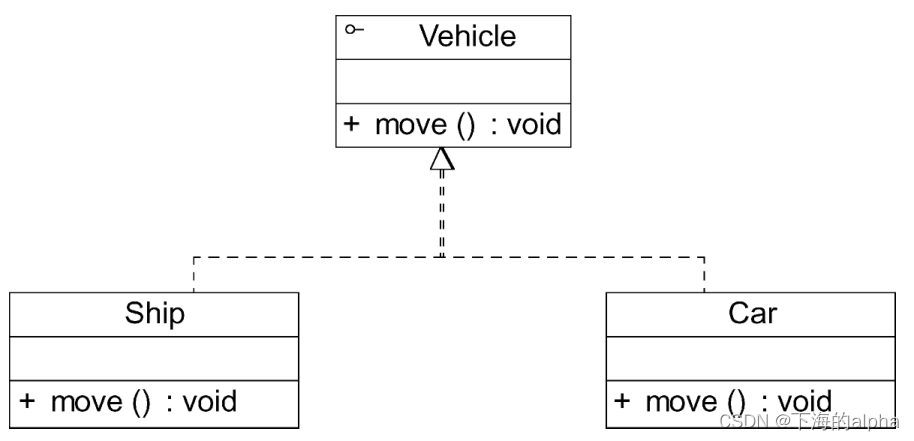
设计模式的艺术P1基础—2.3 类之间的关系
设计模式的艺术P1基础—2.3 类之间的关系 在软件系统中,类并不是孤立存在的,类与类之间存在各种关系。对于不同类型的关系,UML提供了不同的表示方式 1.关联关系 关联(Association)关系是类与类之间最常用…...

工业无人机行业研究:预计2025年将达到108.2亿美元
近年来,在技术进步和各行各业对无人驾驶飞行器 (UAV) 不断增长的需求的推动下,工业无人机市场一直在快速增长。该市场有望在未来几年继续其增长轨迹,许多关键趋势和因素推动其发展。 在全球范围内,工业无人机市场预计到 2025 年将…...

PCA主成分分析算法
在数据分析中,如果特征太多,或者特征之间的相关性太高,通常可以用PCA来进行降维。比如通过对原有10个特征的线性组合, 我们找出3个主成分,就足以解释绝大多数的方差,该算法在高维数据集中被广泛应用。 算法(…...
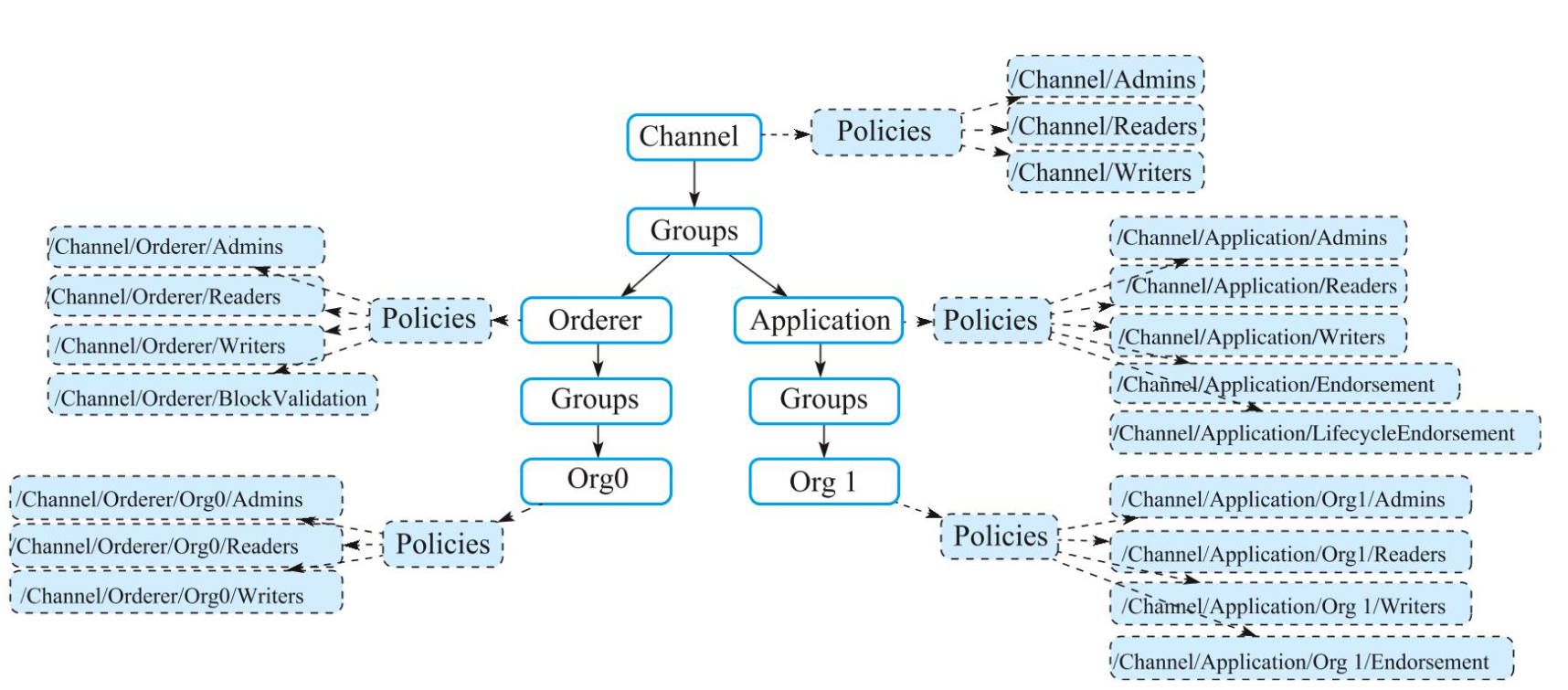
Hyperledger Fabric 权限策略和访问控制
访问控制是区块链网络十分重要的功能,负责控制某个身份在某个场景下是否允许采取某个操作(如读写某个资源)。 常见的访问控制模型包括强制访问控制(Mandatory Access Control)、自主访问控制(Discretionar…...

Day28 回溯算法part04 93. 复原IP地址 78. 子集 90. 子集 II
回溯算法part04 93. 复原IP地址 78. 子集 90. 子集 II 93. 复原 IP 地址 class Solution { private:vector<string> result;bool isValid(string& s,int start,int end){if (start > end) return false;if (s[start] 0 && start ! end) { // 0开头的数…...

Linux系统常用的安全优化
环境:CentOS7.9 1、禁用SELinux SELinux是美国国家安全局对于强制访问控制的实现 1)永久禁用SELinux vim /etc/selinux/config SELINUXdisabled #必须重启系统才能生效2)临时禁用SELInux getenforce #查看SELInux当前状态 setenforce 0 #数字…...
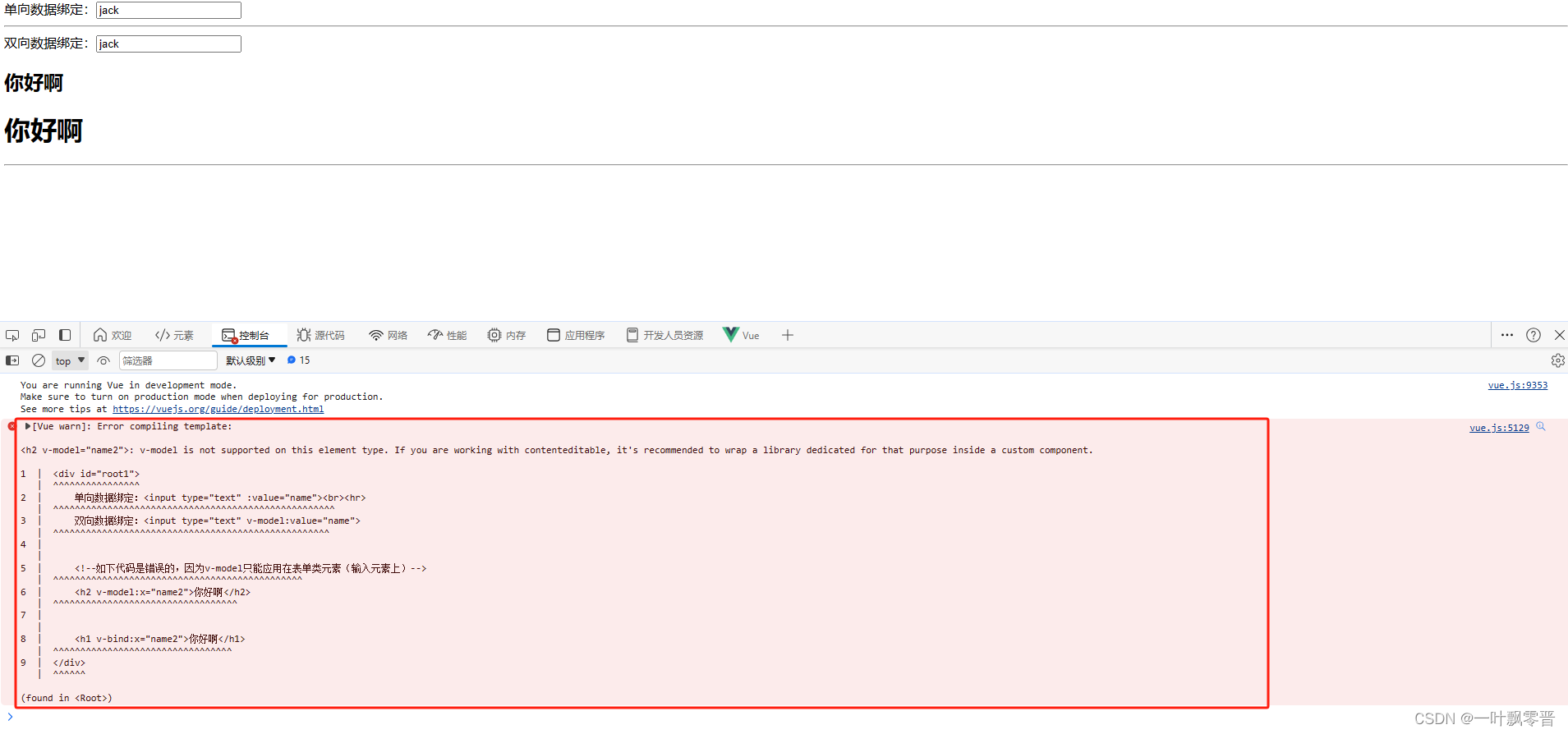
Vue-4、单向数据绑定与双向数据绑定
1、单向数据绑定 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>数据绑定</title><!--引入vue--><script type"text/javascript" src"https://cdn.jsdelivr.net/npm/…...

【Flutter 开发实战】Dart 基础篇:常用运算符
在Dart中,运算符是编写任何程序的基本构建块之一。本文将详细介绍Dart中常用的运算符,以帮助初学者更好地理解和运用这些概念。 1. 算术运算符 算术运算符用于执行基本的数学运算。Dart支持常见的加、减、乘、除、整除以及取余运算。常见的算数运算符如…...

C++:ifstream通过getline读取文件会忽略最后一行空行
getline是读取文件的常用函数,虽然使用简单,但是有一个较容易被忽视的问题,就是文件最后一行空行会被忽略。 #include <iostream> #include <fstream> #include <string> using namespace std;void readWholeFileWithGetline(string fileName) {string t…...

力扣123. 买卖股票的最佳时机 III
动态规划 思路: 最多可以完成两笔交易,因此任意一天结束后,会处于5种状态: 未进行任何操作;只进行了一次买操作;进行了一次买操作和一次卖操作;再完成了一次交易之后,进行了一次买操…...

Vue3:vue-cli项目创建
一、node.js检测或安装: node -v node.js官方 二、vue-cli安装: npm install -g vue/cli # OR yarn global add vue/cli/*如果安装的时候报错,可以尝试一下方法 删除C:\Users**\AppData\Roaming下的npm和npm-cache文件夹 删除项目下的node…...

C# .Net学习笔记—— 异步和多线程(Task)
一、概念 Task是DotNet3.0之后所推出的一种新的使用多线程的方式,它是基于ThreadPool线程进行封装的。 二、使用多线程的时机 任务能够并发运行的时候,提升速度;优化体验 三、基本使用方法 private void button5_Click(object sender, Ev…...
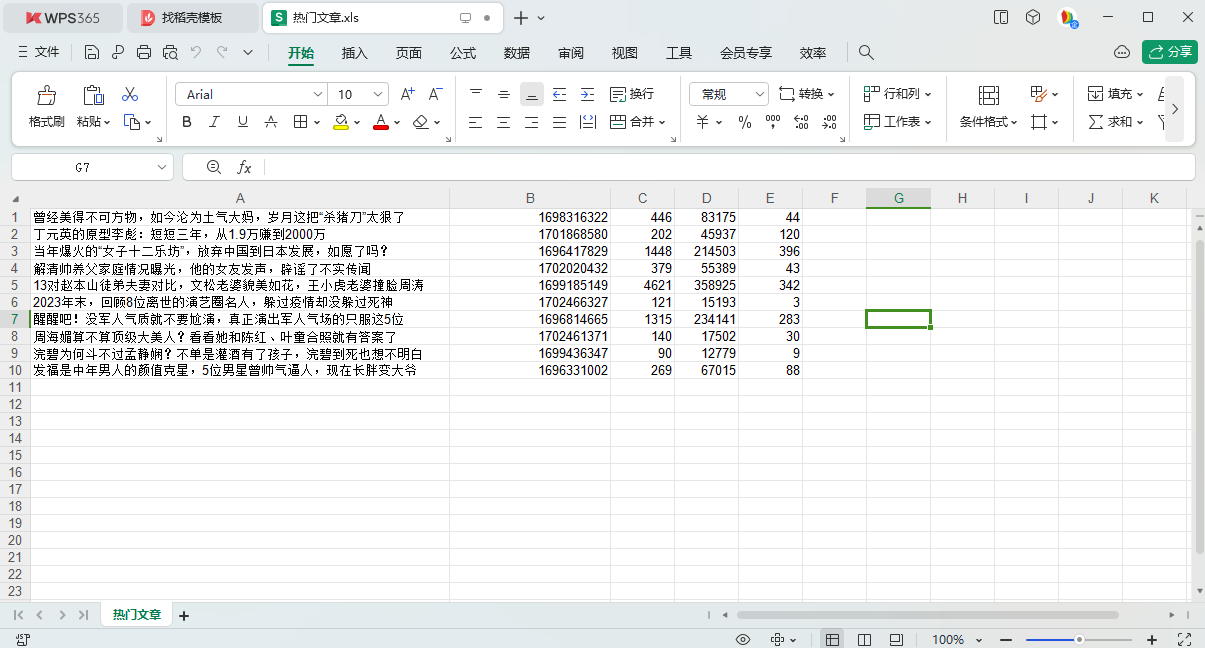
Python从入门到网络爬虫(读写Excel详解)
前言 Python操作Excel的模块有很多,并且各有优劣,不同模块支持的操作和文件类型也有不同。最常用的Excel处理库有xlrd、xlwt、xlutils、xlwings、openpyxl、pandas,下面是各个模块的支持情况: 工具名称.xls.xlsx获取文件内容写入…...
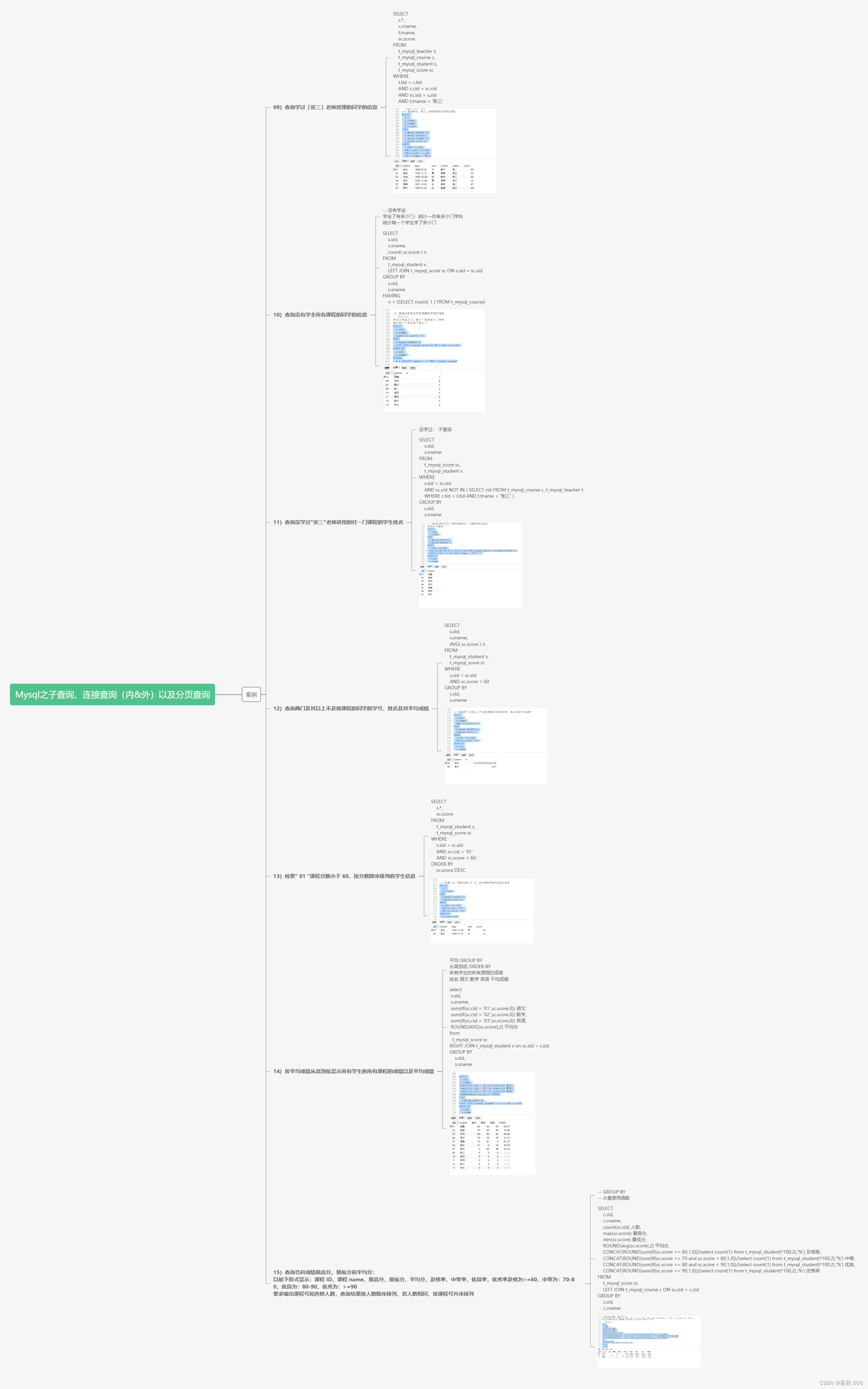
Mysql之子查询、连接查询(内外)以及分页查询
目录 一.案例(接上篇博客) 09)查询学过「张三」老师授课的同学的信息 10)查询没有学全所有课程的同学的信息 11)查询没学过"张三"老师讲授的任一门课程的学生姓名 12)查询两门及其以上不及格课程…...

Flutter for OpenHarmony学习资料搜索与PDF阅读器技术文章
Flutter for OpenHarmony学习资料搜索与PDF阅读器技术文章 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 🚀 Flutter for OpenHarmony 学习资料搜索与 PDF 阅读器开发实战 大家好!今天带大家从零开始打造一款专…...

光伏并网系统谐波抑制控制策略【附程序】
✨ 长期致力于锁相环、谐波电流检测、二阶广义积分器、LMS滤波器研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于双二阶广义积分器-锁频环的自适应…...

别再花钱买板卡了!手把手教你用NI MAX免费创建虚拟PCI6224,搞定LabVIEW数字IO
零成本搭建LabVIEW开发环境:虚拟PCI6224板卡实战指南 当我在大学实验室第一次接触LabVIEW时,面对动辄上万的NI板卡价格标签,几乎浇灭了我的学习热情。直到发现NI MAX的虚拟设备功能——这个隐藏的宝藏工具,让我在没有物理硬件的情…...

3PEAK思瑞浦 TP2262-TSR TSSOP8 运算放大器
特性 供电电压:3V至36V 低供电电流:每通道最大1000A差分输入电压范围至电源轨,可作为比较器工作 输入轨至-Vs,轨到轨输出快速响应:3.5MHz带宽,15V/us斜率,100ns过载恢复时间 低失调电压:-25C时最大2mV-2.5 mV在-40C至85C(最大) -3…...

边缘计算与AI驱动:2019年技术底层逻辑重塑与产业变革
1. 从数据洪流到智能边缘:2019年的技术底层逻辑重塑 每天产生2.5万亿亿字节的数据,这个数字听起来像是天方夜谭,但这就是我们正在面对的现实。更关键的是,其中90%的数据是在过去两年里生成的。作为一名在半导体和系统设计领域摸爬…...

java+uniapp集成unipush2实现消息推送
一、开通uniPush2.0 1.实名认证 登录DCloud开发者中心,通过实名认证 2.进入UniPush控制台 HBuilderX中打开项目的manifest.json文件 导航在“App模块配置” → 项的“Push(消息推送)” → “UniPush”下点击配置 或者申请开通。 3.配置应用信息 在UniPush开通界面…...
/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享)
瑞芯微刷机工具(RKDevTool)/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享
瑞芯微刷机工具(RKDevTool)/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享 适合(处理器是RK字母开头的芯片),比如RK3128、RK3188、RK3229、RK3288、RK3368、RK3328、RK3399、RK3528、RK3568、RK3566、RK3588等等瑞芯微芯…...

技术决策的后悔药:选型错误后的补救策略
在软件测试的全生命周期中,技术选型是影响测试效率、质量与项目成败的关键环节。小到一款测试工具的挑选,大到整个测试框架的搭建,每一次决策都如同在迷雾中航行,稍有不慎便可能驶入“选型错误”的漩涡。当测试环境兼容性问题频发…...

AI时代数据中心架构变革:从计算中心到加速基础设施
1. 从“计算中心”到“加速基础设施”:数据中心架构的范式转移最近和几个在头部云厂商做架构设计的老朋友聊天,话题总绕不开一个词:加速基础设施。这词儿听起来挺高大上,但说白了,就是咱们传统数据中心那套“通用计算存…...

如何在5分钟内将你的普通鼠标变成macOS生产力神器
如何在5分钟内将你的普通鼠标变成macOS生产力神器 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为macOS上鼠标滚轮生硬、侧键闲置而烦恼吗…...