语境化语言表示模型
一.语境化语言表示模型介绍
语境化语言表示模型(Contextualized Language Representation Models)是一类在自然语言处理领域中取得显著成功的模型,其主要特点是能够根据上下文动态地学习词汇和短语的表示。这些模型利用了上下文信息,使得同一词汇在不同语境中可以有不同的表示。以下是一些著名的语境化语言表示模型:
-
ELMo(Embeddings from Language Models): ELMo是一种基于LSTM(长短时记忆网络)的双向语言模型,通过在训练时考虑双向上下文信息,为每个词生成一个上下文相关的词向量。ELMo的词向量是通过将前向LSTM和后向LSTM的隐藏状态进行线性组合而得到的。
-
BERT(Bidirectional Encoder Representations from Transformers): BERT是一种基于Transformer架构的预训练模型,通过使用大规模的语言模型预训练来学习上下文相关的词表示。BERT考虑了一个词在句子中的左右上下文,并通过遮蔽掉一些词汇,训练模型来预测这些被遮蔽的词汇。
-
GPT(Generative Pre-trained Transformer): GPT是一系列基于Transformer的预训练模型,与BERT不同,GPT使用了单向的语言模型,即只考虑前面的上下文。GPT系列的模型通过自回归生成方式,逐个预测下一个词。
这些语境化语言表示模型在自然语言处理的多个任务中取得了显著的性能提升,包括文本分类、命名实体识别、情感分析、问答系统等。由于它们能够充分考虑上下文信息,更好地捕捉语义和语法结构,因此在处理复杂的自然语言任务时表现优异。
这些模型通常是在大规模语料库上进行预训练,然后在特定任务上进行微调。这使得它们能够在各种不同领域和任务中取得良好的泛化性能。
二.语境化语言表示模型-ELMO
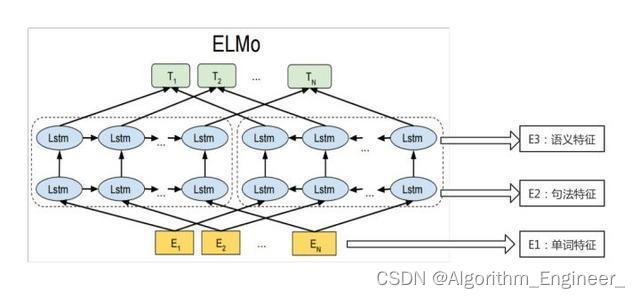
ELMo(Embeddings from Language Models)是一种语境化语言表示模型,由斯坦福大学的研究团队于2018年提出。ELMo旨在通过使用深度双向LSTM(长短时记忆网络)来生成上下文相关的词向量,从而改进传统的静态词向量表示。
ELMo的主要特点包括:
双向上下文建模: ELMo通过使用双向LSTM模型,考虑了一个词在句子中的左右上下文信息。这使得生成的词向量能够更好地捕捉词汇在不同上下文中的含义。层次化表示: ELMo的表示不是简单地从模型的最后一层获取,而是将多个LSTM层的隐藏状态进行线性组合,从而形成多层的语言表示。每一层都对应于不同抽象级别的语言表示,这种层次化的表示可以更好地适应不同任务。预训练和微调: ELMo首先在大规模的语言模型预训练阶段进行学习,然后在特定任务上进行微调。预训练过程使得模型能够学习通用的语言表示,而微调过程则使得模型能够适应特定领域或任务的上下文。
ELMo的词向量表示是通过以下方式计算的:
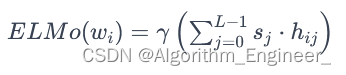
其中,wi是第 i 个词汇,L是LSTM层数,hij 是第 j 层LSTM在第i个词汇上的隐藏状态,sj是模型学到的权重系数,γ是缩放系数。
ELMo的提出带来了对传统静态词向量的一些重要改进,主要体现在以下几个方面:
-
上下文相关性: ELMo生成的词向量是上下文相关的,能够捕捉每个词在不同上下文中的含义。这使得模型更加灵活,能够适应不同语境和任务的要求。
-
多层表示: ELMo采用了多层的双向LSTM,生成了多个层次的语言表示。每个层次对应不同抽象级别的语义信息,使得模型能够在更细粒度和更高层次上理解文本。
-
预训练和微调: ELMo首先在大规模语料上进行预训练,学习通用的语言表示,然后在特定任务上进行微调,适应特定领域或任务的上下文。这种两阶段的训练使得模型更具泛化性。
-
多任务学习: 由于ELMo的语言表示是通过多层双向LSTM的线性组合得到的,每一层都可以用于不同任务。这种多任务学习的特性使得模型能够在一个模型中同时适应多个任务。
ELMo在这些任务中的应用表现:
-
情感分析: 在情感分析任务中,理解文本中的情感极性对于判断文本的情感态度非常重要。ELMo能够捕捉词汇在句子中的不同语境,从而更好地理解和表示情感相关的信息,提高了情感分析模型的性能。
-
问答系统: 在问答系统中,理解问题和文本的语境是关键。ELMo生成的上下文相关的词向量可以更好地捕捉问题和答案之间的关系,使得问答系统更具智能性和准确性。
-
文本分类: 在文本分类任务中,ELMo的上下文相关性使得模型能够更好地理解文本中的语义信息。这对于区分不同类别的文本非常有帮助,提高了文本分类模型的准确性。
-
命名实体识别: 在命名实体识别任务中,ELMo的上下文相关的词向量有助于更好地理解文本中实体的边界和语境,提高了命名实体识别模型的精度。
总的来说,ELMo的应用范围广泛,其上下文相关的词向量表示在多个任务中都展现了显著的优势,使得模型能够更好地理解语言的复杂性和多义性。然而,也需要注意到后续出现的一些更先进的语境化表示模型(如BERT和GPT等)在某些任务上取得了更好的性能。
三.语境化语言表示模型-BERT向量
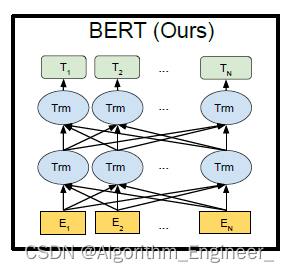
BERT(Bidirectional Encoder Representations from Transformers)模型是一种语境化语言表示模型,通过预训练来生成上下文相关的词向量。在BERT中,词向量通常被称为BERT向量。BERT向量的生成过程包括两个阶段:预训练和微调。
预训练阶段: 在预训练阶段,BERT模型通过大规模的无标签语料库进行训练。在这个阶段,BERT使用了两个任务来学习上下文相关的词向量:掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)任务。
通过在输入文本中随机掩盖一些词汇,BERT模型被训练来预测被掩盖的词汇。同时,BERT模型还通过判断两个句子是否是原文中的连续句子来学习句子级别的关系。这个阶段的输出是每个位置上的上下文相关的词向量。
微调阶段: 在微调阶段,BERT模型根据具体的下游任务(如文本分类、命名实体识别等)的标签信息,使用带标签的数据对模型进行微调。在微调阶段,模型的参数会根据任务的特定目标进行调整,以适应特定任务的要求。微调可以在相对较小的标注数据集上进行,因为BERT已经在大规模的无标签数据上进行了预训练。
BERT向量的特点包括:
上下文相关性: 由于BERT是基于双向Transformer结构进行训练的,生成的词向量能够捕捉每个词在其上下文中的语义信息。
多层次表示: BERT模型包含多个Transformer层,每个层次都提供了一个不同抽象级别的表示。因此,BERT向量是一个多层次的表示,可以在不同任务中灵活应用。
预训练和微调: BERT向量在预训练阶段学习通用的语言表示,而在微调阶段可以根据具体任务的需求进行进一步优化。
BERT向量在自然语言处理的各个任务中都表现出色,取得了许多领域的最新性能。由于BERT的成功,许多后续的语境化语言表示模型(如GPT、RoBERTa等)也在此基础上进行了发展和改进。

四.语境化语言表示模型-GPT
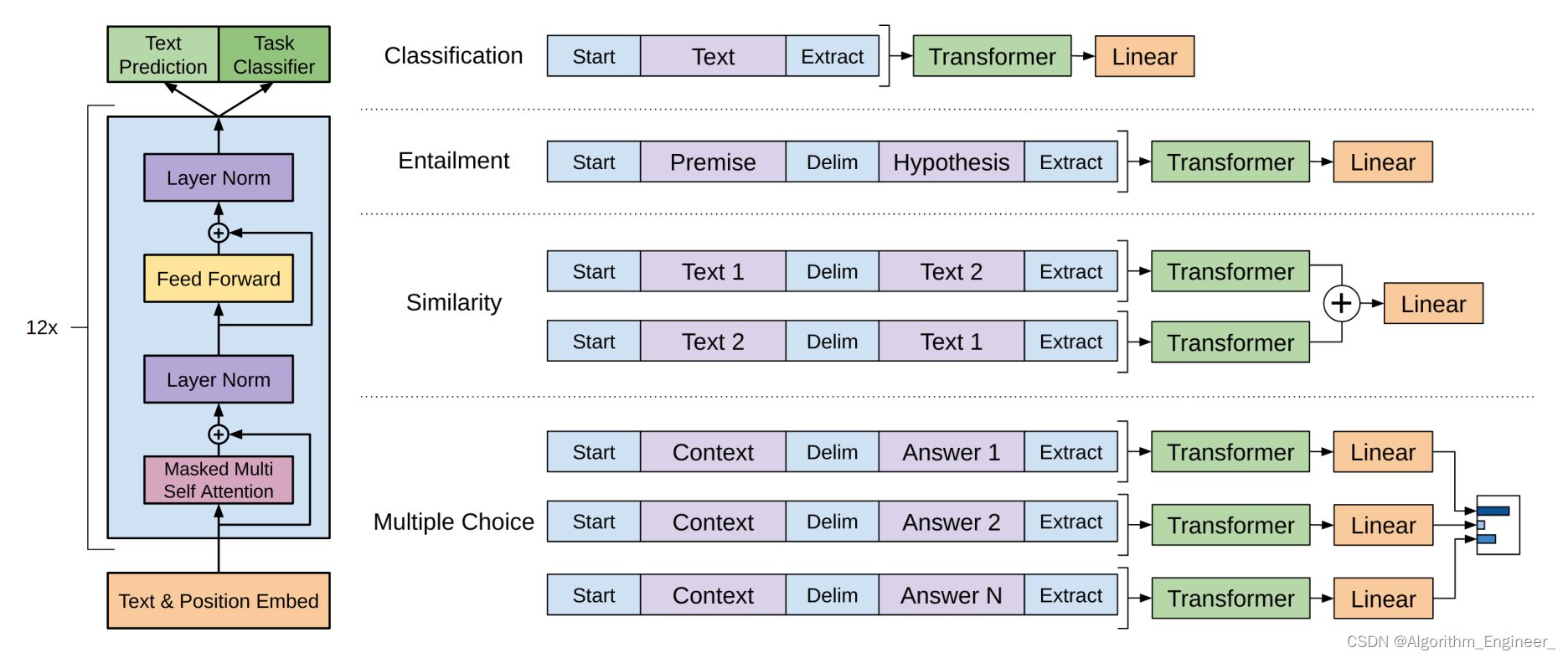
GPT(Generative Pre-trained Transformer)是一种语境化语言表示模型,属于Transformer架构的一部分。与BERT不同,GPT是通过自回归方式进行训练的,即模型在生成文本时依次预测下一个词汇。以下是GPT的一些关键特点:
Transformer架构: GPT采用了Transformer架构,这种架构在处理序列数据时非常强大。Transformer使用注意力机制来捕捉输入序列中不同位置的关系,使得模型能够在长距离上捕捉依赖关系。自回归训练: GPT采用自回归的方式进行训练。在训练过程中,模型通过最大化下一个词的条件概率来预测整个序列。这种方法使得GPT生成的语言表示更加连贯,适用于生成任务。层次化表示: GPT模型通常包含多个Transformer层,每一层都提供了一个不同层次的语言表示。这种层次化的表示使得GPT能够理解文本的不同抽象级别的语义信息。无监督预训练: 在预训练阶段,GPT通过大规模的无标签语料库进行自监督学习,学习通用的语言表示。预训练完成后,模型可以在各种下游任务上进行微调,以适应具体的应用。生成任务应用: GPT最初设计用于生成任务,如文本生成、对话生成等。由于采用了自回归训练方式,GPT在生成连贯且富有语义的文本方面表现出色。OpenAI的GPT系列: GPT的发展成为了一系列模型,包括GPT-2和GPT-3。这些模型在参数规模、性能和能力方面逐渐提升,GPT-3更是达到了数万亿个参数的规模。
GPT在多个自然语言处理任务中都取得了显著的成功,包括文本生成、对话系统、文本摘要等。然而,与BERT等其他模型相比,GPT的无监督训练方式也带来了一些挑战,例如对大规模数据和计算资源的需求。
五.语境化语言表示模型-XLNet
XLNet(eXtreme Learning Machine Network)是一种语境化语言表示模型,由谷歌AI团队于2019年提出。它结合了Transformer的架构和自回归(autoregressive)以及自编码(autoencoding)等训练目标,以提高对上下文的建模能力。以下是一些关键特点:
Transformer架构: XLNet采用Transformer的结构,包括自注意力机制。这使得模型能够有效捕捉文本中的长距离依赖关系。自回归和自编码: XLNet结合了自回归和自编码两种训练目标。自回归部分通过最大化给定上下文条件下下一个词的概率,类似于GPT。自编码部分则通过最大化一个被随机掩码的词预测所有其他词的概率,类似于BERT。Permutation Language Modeling(PLM): XLNet引入了Permutation Language Modeling任务,即对输入序列中的一些词的排列进行预测。这使得模型能够更好地理解词汇之间的全局关系。两个流的架构: XLNet通过两个流的架构实现了自回归和自编码目标的融合。一个流负责从左到右的自回归目标,另一个流负责从右到左的自编码目标。这种设计使得模型更加全面地捕捉上下文信息。超长序列: 由于采用了自回归的方式,XLNet相对于BERT等模型更容易处理长文本,因为它不需要将整个上下文序列压缩到一个固定长度。
XLNet在多个自然语言处理任务上表现出色,包括文本分类、问答系统、命名实体识别等。它的训练过程和细节相对复杂,需要大规模的数据和计算资源。以下是一个简化的伪代码示例,用于理解XLNet的基本训练流程:
import torch
from torch.optim import Adam
from transformers import XLNetTokenizer, XLNetForSequenceClassification# 使用预训练的XLNet模型和tokenizer
model = XLNetForSequenceClassification.from_pretrained('xlnet-base-cased')
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')# 数据准备
text_data = ["Your text data here...", "Another sentence...", ...]
labels = [0, 1, ...] # 根据任务的不同,labels会有所变化tokenized_data = tokenizer(text_data, return_tensors='pt', padding=True, truncation=True)
labels = torch.tensor(labels)# 模型和优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = Adam(model.parameters(), lr=2e-5)# 训练过程
num_epochs = 3for epoch in range(num_epochs):model.train()optimizer.zero_grad()# 前向传播outputs = model(**tokenized_data, labels=labels)loss = outputs.loss# 反向传播和优化loss.backward()optimizer.step()print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item()}")# 保存训练好的模型
model.save_pretrained('path/to/save/model')
tokenizer.save_pretrained('path/to/save/tokenizer')这里的代码是基于Hugging Face的transformers库,该库提供了方便的接口用于使用和微调预训练的XLNet模型。在实际应用中,你可能需要根据任务的不同对模型进行微调,调整模型的超参数,并根据实际情况对数据进行更详细的处理。
相关文章:
语境化语言表示模型
一.语境化语言表示模型介绍 语境化语言表示模型(Contextualized Language Representation Models)是一类在自然语言处理领域中取得显著成功的模型,其主要特点是能够根据上下文动态地学习词汇和短语的表示。这些模型利用了上下文信息…...

PDO【配置】
PDOr: 6040 控制字 6060 模式 6083 加速度 6084 减速度 =====================【定位1】:// 补间7 607A 定位位置 6081 定位速度 =====================【速度3】: 60FF 目标速度 =====================【力矩4…...

CMake入门教程【高级篇】管理MSVC编译器警告
😈「CSDN主页」:传送门 😈「Bilibil首页」:传送门 😈「动动你的小手」:点赞👍收藏⭐️评论📝 文章目录 1.什么是MSVC?2.常用的屏蔽警告3.MSVC所有警告4.target_compile_options用法5.如何在CMake中消除MSVC的警告?6.屏蔽警告编写技巧...
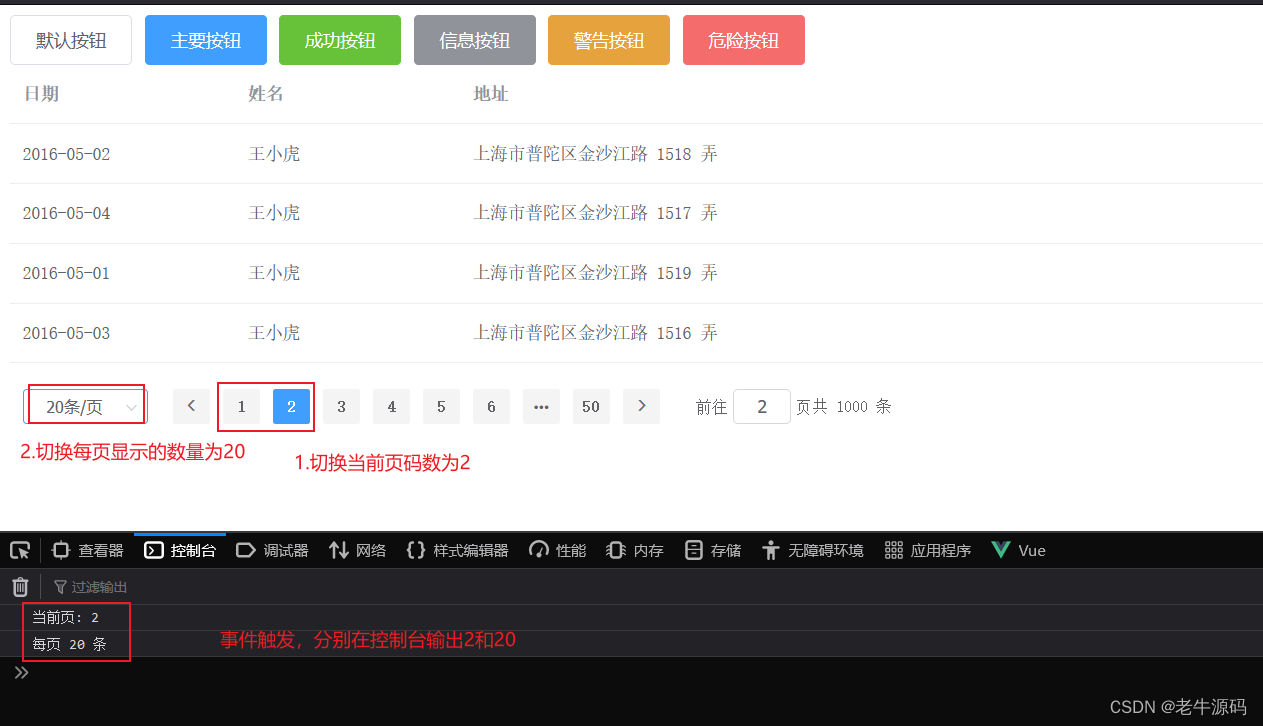
【JaveWeb教程】(8)Web前端基础:Vue组件库Element之Table表格组件和Pagination分页组件 详细示例介绍
目录 1 Table表格组件1.1 组件演示1.2 组件属性详解 2 Pagination分页2.1 组件演示2.2 组件属性详解2.3 组件事件详解 接下来我们来学习一下ElementUI的常用组件,对于组件的学习比较简单,我们只需要参考官方提供的代码,然后复制粘贴即可。本节…...

llama_index 创始人为我们展示召回提升策略(提升15%)
用句子向量替换为句子向量 句子检索,将句子转化为向量。在检索的过程中,假如句子命中,则将句子周围的内容也当做检索内容。 对比句子检索和之前的按块去做切分的检索。可以看到,内容的相关性提升了8%, 构建数据的时候…...
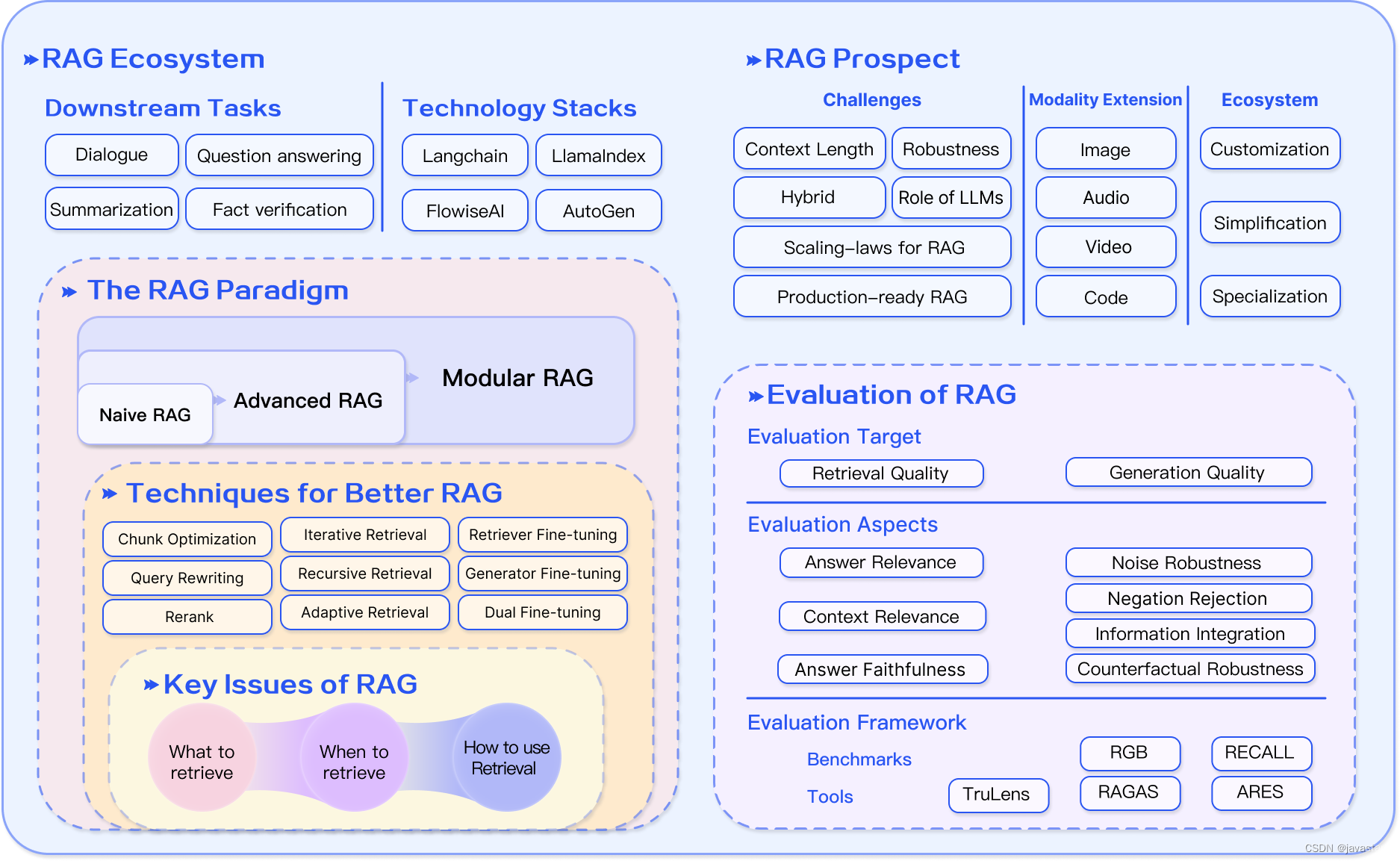
RAG 详解
原文:GitHub - Tongji-KGLLM/RAG-Survey 目录 RAG调查 什么是RAG?RAG的范式 幼稚的 RAG高级 RAG模块化 RAG如何进行增强?RAG 还是微调?如何评估 RAG?前景 严峻的挑战多式联运扩展RAG的生态系统RAG论文清单 增强阶段 …...

【llm 部署运行videochat--完整教程】
# 申请llama权重 https://ai.meta.com/resources/models-and-libraries/llama-downloads/ -> 勾选三个模型 -> 等待接收右键信息 # 下载llama代码库 git clone https://github.com/facebookresearch/llama.git cd llama bash download.py -> email -> url …...

Talking about likes
Tutorial Hi! Tim here with another 925English lesson! In today’s lesson, we’re learning how to talk about likes and preferences. Why It’s Important: Talking about things we like is common in various situations, from meetings to casual chats over lunch…...

DeepSeek 发布全新开源大模型,数学推理能力超越 LLaMA-2
自从 LLaMA 被提出以来,开源大型语言模型(LLM)的快速发展就引起了广泛研究关注,随后的一些研究就主要集中于训练固定大小和高质量的模型,但这往往忽略了对 LLM 缩放规律的深入探索。 开源 LLM 的缩放研究可以促使 LLM…...
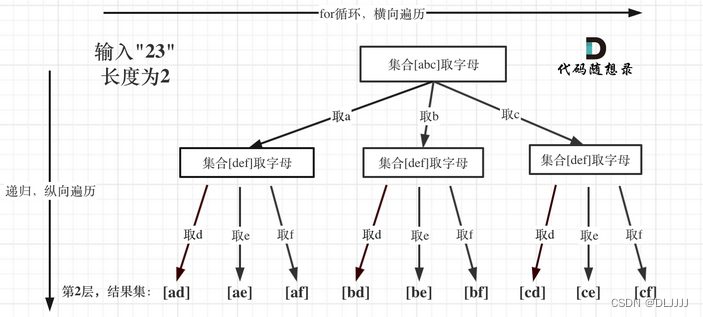
代码随想录算法训练营第二十一天| 回溯 216. 组合总和 III 17. 电话号码的字母组合
216. 组合总和 III 可以参考77.组合中关于选取数组的相关操作。 递归函数的返回值以及参数:一般为void类型 递归函数终止条件:path这个数组的大小如果达到k,说明我们找到了一个子集大小为k的组合了,然后当n为0的时候࿰…...
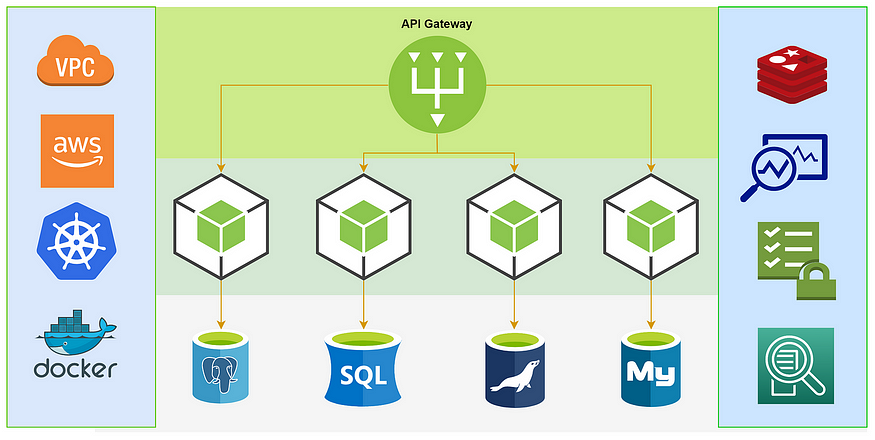
微服务架构最佳实践
我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情 构建和管理微服务是一项艰巨的任务。这是因为微服务就像多个并行的整体应用程序,它们都必须处于同步通信和并发运行时间。因此,在设计和构建…...

国内首款支持苹果Find My芯片-伦茨科技ST17H6x
深圳市伦茨科技有限公司(以下简称“伦茨科技”)发布ST17H6x Soc平台。成为继Nordic之后全球第二家取得Apple Find My「查找」认证的芯片厂家,该平台提供可通过Apple Find My认证的Apple查找(Find My)功能集成解决方案。…...
linux 01 centos镜像下载,服务器,vmware模拟服务器
https://www.bilibili.com/video/BV1pz4y1D73n?p3&vd_source4ba64cb9b5f8c56f1545096dfddf8822 01.使用的版本 国内主要使用的版本是centos 02.centos镜像下载 这里的是centos7 一.阿里云官网地址:https://www.aliyun.com/ 二. -----【文档与社区】 —【…...
)
Linux安装RabbitMq明白纸(无图)
Linux安装RabbitMq步骤 安装环境Erlang和RabbitMQ版本对照安装包下载地址登录Linux服务器创建安装目录将之前下载的两个rpm文件上传到这个目录下,并解压安装Erlang安装完成后,查看Erlang版本安装socat(RabbitMq安装需要这个)解压并…...
Android - CrashHandler 全局异常捕获器
官网介绍如下:Thread.UncaughtExceptionHandler (Java Platform SE 8 ) 用于线程因未捕获异常而突然终止时调用的处理程序接口。当线程由于未捕获异常而即将终止时,Java虚拟机将使用thread . getuncaughtexceptionhandler()查询该线程的UncaughtExceptio…...

商品源数据如何采集,您知道吗?
如今,电子商务已经渗透到了人们生活的方方面面。2020年新冠肺炎突如其来,打乱了人们正常的生产生活秩序,给经济发展带来了极大的影响。抗击疫情过程中,为避免人员接触和聚集,以“无接触配送”为营销卖点的电子商务迅速…...
输入输出流、字符字节流、NIO
1、对输入输出流、字符字节流的学习,以之前做的批量下载功能为例 批量下载指的是,将多个文件打包到zip文件中,然后下载该zip文件。 1.1下载网络上的文件 代码参考如下: import java.io.*; import java.net.URL; import java.n…...
格式化处理)
js中对数字,超大金额(千位符,小数点)格式化处理
前言 这个问题的灵感来自线上一个小bug,前两天刚看完同事写的代码,对数字类型处理的很好,之前一直都是用正则和toFixed(2)处理数字相关,后面发现使用numeral.js处理更完美。 对于下面这种数据的处理,你能想到几种方法…...

Android 打开热点2.4G系统重启解决
Android 打开热点2.4G系统重启解决 文章目录 Android 打开热点2.4G系统重启解决一、前言二、过程分析1、Android 设备开机后第一次打开热点2.4G系统重启2、日志分析3、设备重启原因 三、解决方法四、其他1、wifi/有线网 代理信息也可能导致系统重启2、Android13 热点默认5G频道…...

全链路压力测试有哪些主要作用
全链路压力测试是在软件开发和维护过程中不可或缺的一环,尤其在复杂系统和高并发场景下显得尤为重要。下面将详细介绍全链路压力测试的主要作用。 一、全链路压力测试概述 全链路压力测试是指对软件系统的全部组件(包括前端、后端、数据库、网络、中间件等)在高负载…...

Redis分布式锁进阶第六十八篇
一、本篇前置衔接 第六十八篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争…...

AI命令行工具箱:将大模型无缝集成到终端工作流
1. 项目概述:一个为AI交互而生的命令行工具箱如果你和我一样,每天有大量时间泡在命令行里,同时又频繁地与各种AI模型打交道,那么你肯定也经历过这种“割裂感”:一边是高效、精准、可脚本化的终端环境,另一边…...
提示音音量大小不一样【篇】)
杰理之叠加正弦波(SIN)提示音音量大小不一样【篇】
SDK音量调节默认自带淡入淡出。...

图记忆架构:用知识图谱增强AI智能体的长期记忆与推理能力
1. 项目概述:当记忆成为可编程的图最近在探索如何让AI应用真正“记住”复杂的上下文时,我遇到了一个非常有意思的项目:openclaw-memory-graphiti。这个名字听起来有点拗口,但拆解一下就能明白它的野心——“OpenClaw”可能是一个开…...

启扬RK3568核心板如何赋能智能炒菜机:从嵌入式主控到AI烹饪
1. 项目概述:当嵌入式核心板遇上智能炒菜机在餐饮后厨这个看似传统,实则对效率、成本和一致性要求极高的领域,痛点一直非常明确。人工炒菜,老师傅的手艺固然可贵,但出餐速度受限于体力,菜品口味因厨师状态、…...

终极指南:如何用ROFL-Player永久解决英雄联盟回放版本兼容性问题
终极指南:如何用ROFL-Player永久解决英雄联盟回放版本兼容性问题 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄…...

Faster R-CNN PyTorch终极指南:10分钟搭建你的第一个目标检测模型
Faster R-CNN PyTorch终极指南:10分钟搭建你的第一个目标检测模型 【免费下载链接】faster-rcnn-pytorch 这是一个faster-rcnn的pytorch实现的库,可以利用voc数据集格式的数据进行训练。 项目地址: https://gitcode.com/gh_mirrors/fa/faster-rcnn-pyt…...

NodeJS-Learning包管理艺术:npm高级用法与私有仓库搭建
NodeJS-Learning包管理艺术:npm高级用法与私有仓库搭建 【免费下载链接】NodeJS-Learning This page contains collection of curated links to blog posts, articles, videos, tutorials, books, frameworks, modules, IDEs, testing tools, hosting providers, et…...

Unity 5.6移动VR开发与单通道渲染优化指南
1. Unity 5.6移动VR开发环境配置1.1 Daydream原生支持解析Unity 5.6首次实现了对Daydream平台的原生支持,这标志着移动VR开发进入新阶段。与传统的插件式集成不同,原生支持直接内置于引擎核心,带来三个显著优势:性能提升ÿ…...

Tungsten自适应采样算法:如何智能分配计算资源提升渲染质量
Tungsten自适应采样算法:如何智能分配计算资源提升渲染质量 【免费下载链接】tungsten High performance physically based renderer in C11 项目地址: https://gitcode.com/gh_mirrors/tu/tungsten Tungsten渲染器的自适应采样算法是一种革命性的渲染优化技…...