Spark: 检查数据倾斜的方法以及解决方法总结
1. 使用Spark UI
Spark UI提供了一个可视化的方式来监控和调试Spark作业。你可以通过检查各个Stage的任务执行时间和数据大小来判断是否存在数据倾斜。
- 任务执行时间: 如果某个Stage中的大部分任务很快完成,但有少数任务执行时间非常长,这可能是数据倾斜的迹象。
- 数据大小: 在Spark UI的Stage页可以查看每个任务处理的数据量。如果有任务处理的数据量远大于其他任务,这可能表明数据倾斜。
2. 查看数据分布
使用DataFrame的describe()或summary()方法可以查看数据的统计信息,从而了解数据分布情况。
df.describe().show() # 或者 df.summary().show()
3. 计算每个分区的记录数
通过计算每个分区的记录数,可以直接观察到数据是否均匀分布。
from pyspark.sql.functions import spark_partition_id df.withColumn("partition_id", spark_partition_id()).groupBy("partition_id").count().show()
4. 检查键的分布
如果你的数据是基于键进行操作的(如groupBy或join),检查键的分布情况可以帮助识别数据倾斜。
df.groupBy("your_key_column").count().orderBy("count", ascending=False).show()
5. 使用累加器
累加器可以用来在执行过程中收集信息,例如,你可以为每个分区添加一个累加器,以跟踪处理的记录数量。
from pyspark import AccumulatorParamclass LongAccumulatorParam(AccumulatorParam):def zero(self, initialValue):return 0def addInPlace(self, v1, v2):return v1 + v2task_counts = sc.accumulator(0, LongAccumulatorParam())def count_records(iterator):global task_countscount = 0for record in iterator:count += 1task_counts += countreturn iteratordf.rdd.mapPartitions(count_records).count() print(task_counts.value)
6. 使用第三方监控工具
第三方监控工具如Ganglia, Prometheus, Grafana等可以集成到Spark环境中,提供更详细的监控数据帮助识别数据倾斜。
通过上述方法,你可以检查数据是否倾斜,并据此采取相应的优化措施。
一些其他方法
1. 检查Stage的任务执行时间
- 在Spark UI中检查各个Stage的任务执行时间,如果发现有个别任务的执行时间远远高于其他任务,这可能是数据倾斜的迹象。
2. 检查Stage的任务输入数据大小
- 同样在Spark UI中,查看各个任务的输入数据大小。如果某个任务处理的数据量异常大,这可能表明该部分数据发生了倾斜。
3. 检查数据分布
- 可以使用
df.groupBy("keyColumn").count().orderBy(desc("count"))这样的命令来查看数据分布,如果某些key的数量远大于其他key,说明数据倾斜。
4. 使用累加器(Accumulators)
- 在Spark任务中使用累加器来记录处理每个key的记录数,这样可以在任务执行完毕后分析各个key的记录数,从而发现数据倾斜。
5. 执行样本调查
- 对数据集进行采样,然后对采样结果进行分析,以估计整个数据集的数据分布情况。这种方法适用于数据集过大时的初步检查。
6. 查看日志文件
- 分析Executor的日志文件,可以查看到处理数据时的详细信息,包括每个任务处理的记录数、处理时间等,有助于发现数据倾斜。
7. 使用自定义分区器
- 如果预先知道数据分布不均,可以使用自定义分区器来优化数据分布,从而避免数据倾斜。
以上方法可以帮助检测和分析Spark作业中可能存在的数据倾斜问题。在发现数据倾斜后,可以采取相应的优化措施,比如调整并行度、使用广播变量、重新设计数据分区策略等,来减轻或解决数据倾斜的问题。
解决数据倾斜的策略
数据倾斜是大数据处理中常见的问题,特别是在使用Spark等分布式计算框架时。数据倾斜发生时,任务的处理时间会因为某些节点上的数据量过大而显著增加。以下是一些常见的解决数据倾斜的方法:
1. 增加并行度
- 方法: 通过调整
spark.default.parallelism(对于RDD操作)和spark.sql.shuffle.partitions(对于Spark SQL操作)的值来增加任务的并行度。 - 效果: 可以使得数据更加均匀地分布在更多的分区中,减少单个节点的负载。
2. 重新分区
- 方法: 使用
repartition()或coalesce()方法对数据进行重新分区。repartition()可以增加分区数,打乱数据并均匀分布。coalesce()用于减少分区数,效率比repartition()更高,因为它避免了全局shuffle。
- 效果: 可以减少数据倾斜,但是
repartition()可能会导致大量的数据传输。
3. 提供自定义分区器
- 方法: 对于键值对RDD,可以使用自定义分区器来控制数据如何分布到不同的分区。
- 效果: 通过自定义逻辑来避免热点键造成的倾斜。
4. 过滤大键
- 方法: 如果数据倾斜是由某些键值对中的热点键引起的,可以尝试过滤掉这些键,单独处理。
- 效果: 将热点数据单独处理可以减轻数据倾斜的问题。
5. 使用随机前缀和扩展键
- 方法: 给热点键添加随机前缀或扩展键的方式来分散这些键的数据。
- 效果: 可以将原本集中在单个分区的数据分散到多个分区中。
6. 广播小表
- 方法: 在进行join操作时,如果一个表非常小,可以使用广播变量将其广播到所有节点。
- 效果: 避免了对小表进行shuffle,可以显著减少数据倾斜问题。
7. 使用样本数据调整键
- 方法: 使用样本数据来分析数据分布,并根据分布情况调整键的分布。
- 效果: 通过调整键的分布来减轻或消除数据倾斜。
8. 优化业务逻辑
- 方法: 重新考虑和优化业务逻辑,可能存在更合理的数据处理方式来避免数据倾斜。
- 效果: 有时候通过业务逻辑的优化可以根本上解决数据倾斜的问题。
9. 使用外部存储进行shuffle
- 方法: 使用外部存储系统(如HDFS)来进行数据的shuffle操作。
- 效果: 当内存不足以处理大量的数据倾斜时,使用外部存储可以避免内存溢出。
10. 调整数据源
- 方法: 在数据进入Spark之前预处理数据源,以减少倾斜。
- 效果: 通过预处理可以在数据进入Spark前就减少倾斜,有助于提高整体处理效率。
在实际工作中,通常需要根据具体的场景和数据特征来选择合适的策略。有时候,组合使用多种策略会更有效。
相关文章:

Spark: 检查数据倾斜的方法以及解决方法总结
1. 使用Spark UI Spark UI提供了一个可视化的方式来监控和调试Spark作业。你可以通过检查各个Stage的任务执行时间和数据大小来判断是否存在数据倾斜。 任务执行时间: 如果某个Stage中的大部分任务很快完成,但有少数任务执行时间非常长,这可能是数据倾…...
基于JavaWeb+BS架构+SpringBoot+Vue“共享书角”图书借还管理系统系统的设计和实现
基于JavaWebBS架构SpringBootVue“共享书角”图书借还管理系统系统的设计和实现 文末获取源码Lun文目录前言主要技术系统设计功能截图订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 文末获取源码 Lun文目录 第1章 概 述 5 1.1 开发背景及研究意义 5 1.2 国内外研究…...

论文阅读:TinyGPT-V 论文阅读及源码梳理对应
!!!目前只是初稿,静待周末更新 引言 TinyGPT-V来自论文:TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones,是一篇基于较小LLM作为backbone的多模态工作。相关工作已经开源&…...

XCTF:MISCall[WriteUP]
使用file命令,查看该文件类型 file d02f31b893164d56b7a8e5edb47d9be5 文件类型:bzip2 使用bzip2命令可对该文件进行解压 bzip2 -d d02f31b893164d56b7a8e5edb47d9be5 生成了一个后缀为.out的文件 再次使用file命令,查看该文件类型 file…...

【MIdjourney】图像角度关键词
本篇仅是我个人在使用过程中的一些经验之谈,不代表一定是对的,如有任何问题欢迎在评论区指正,如有补充也欢迎在评论区留言。 1.侧面视角(from side) 侧面视角观察或拍摄的主体通常以其侧面的特征为主要焦点,以便更好地展示其轮廓…...

使用 Jamf Pro 和 Okta 工作流程实现自动化苹果设备管理
Jamf的销售工程师Vincent Bonnin与Okta的产品经理Emily Wendell一起介绍了JNUC 2021的操作方法会议。它们涵盖了Okta工作流程(Okta Workflow),并在其中集成了Jamf Pro,构建了一些工作流程,并提供了几个用例。 Okta 工作…...
C++)
根能抵达的节点(二分法、DFS)C++
给定一棵由 N个节点构成的带边权树。节点编号从 0到 N−1,其中 0 号点为根节点。最初,从根节点可以抵达所有节点(包括自己)。如果我们将所有边权小于 X 的边全部删掉,那么从根节点可以抵达的节点数目就可能发生改变。 …...
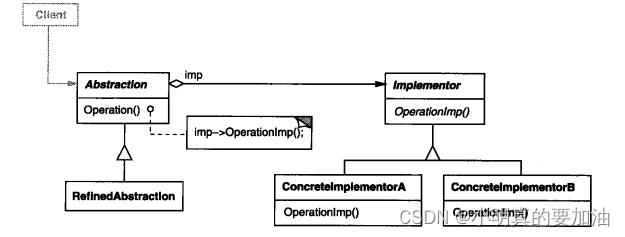
一天一个设计模式---桥接模式
概念 桥接器模式是一种结构型设计模式,旨在将抽象部分与实现部分分离,使它们可以独立变化而不相互影响。桥接器模式通过创建一个桥接接口,连接抽象和实现,从而使两者可以独立演化。 具体内容 桥接器模式通常包括以下几个要素&a…...
OpenHarmony4.0Release系统应用常见问题FAQ
前言 自OpenHarmony4.0Release发布之后,许多小伙伴使用了配套的系统应用源码以及IDE作为基线开发,也遇到了各种各样的问题,这篇文档主要收录了比较常见的一些问题解答。 FAQ 系统应用源码在哪 目前OpenHarmony系统应用分为3种模式&#x…...
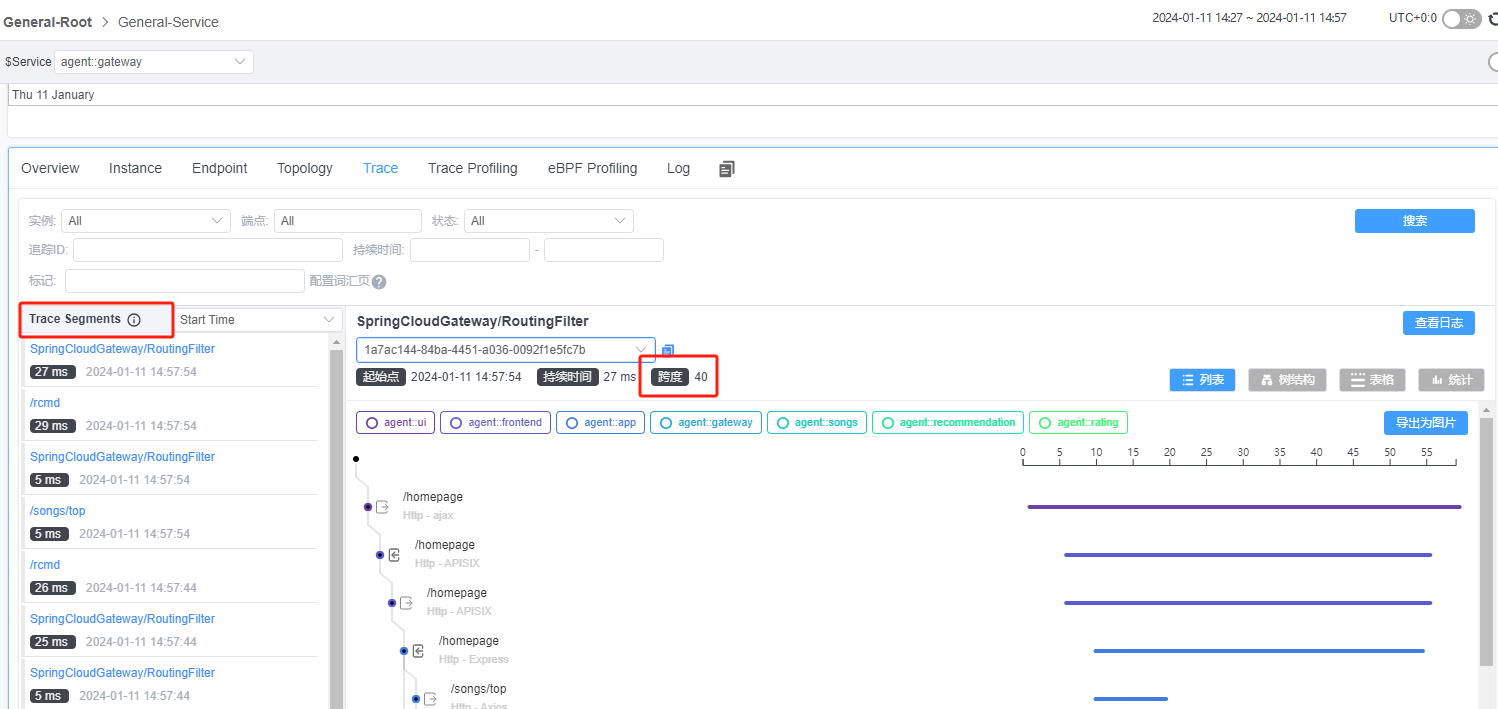
Skywalking UI页面中操作的各种实用功能汇总
刚刚接触skywalking不久,在这里总结一下在UI页面中操作的各种实用功能,随着使用的不断深入,我也会对文章进行持续补充。 本文skywalking 的ui入口是官方demo ,版本是10.0.0-SNAPSHOT-593bd05 http://demo.skywalking.apache.org…...
springboot摄影跟拍预定管理系统源码和论文
首先,论文一开始便是清楚的论述了系统的研究内容。其次,剖析系统需求分析,弄明白“做什么”,分析包括业务分析和业务流程的分析以及用例分析,更进一步明确系统的需求。然后在明白了系统的需求基础上需要进一步地设计系统,主要包罗软件架构模式、整体功能模块、数据库设计。本项…...

【python】python新年烟花代码【附源码】
欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 新年的钟声即将敲响,为了庆祝这个喜庆的时刻,我们可以用 Python 编写一个炫彩夺目的烟花盛典。本文将详细介绍如何使用 Pygame 库创建一个令人惊叹的烟花效果。 一、效果图: 二…...
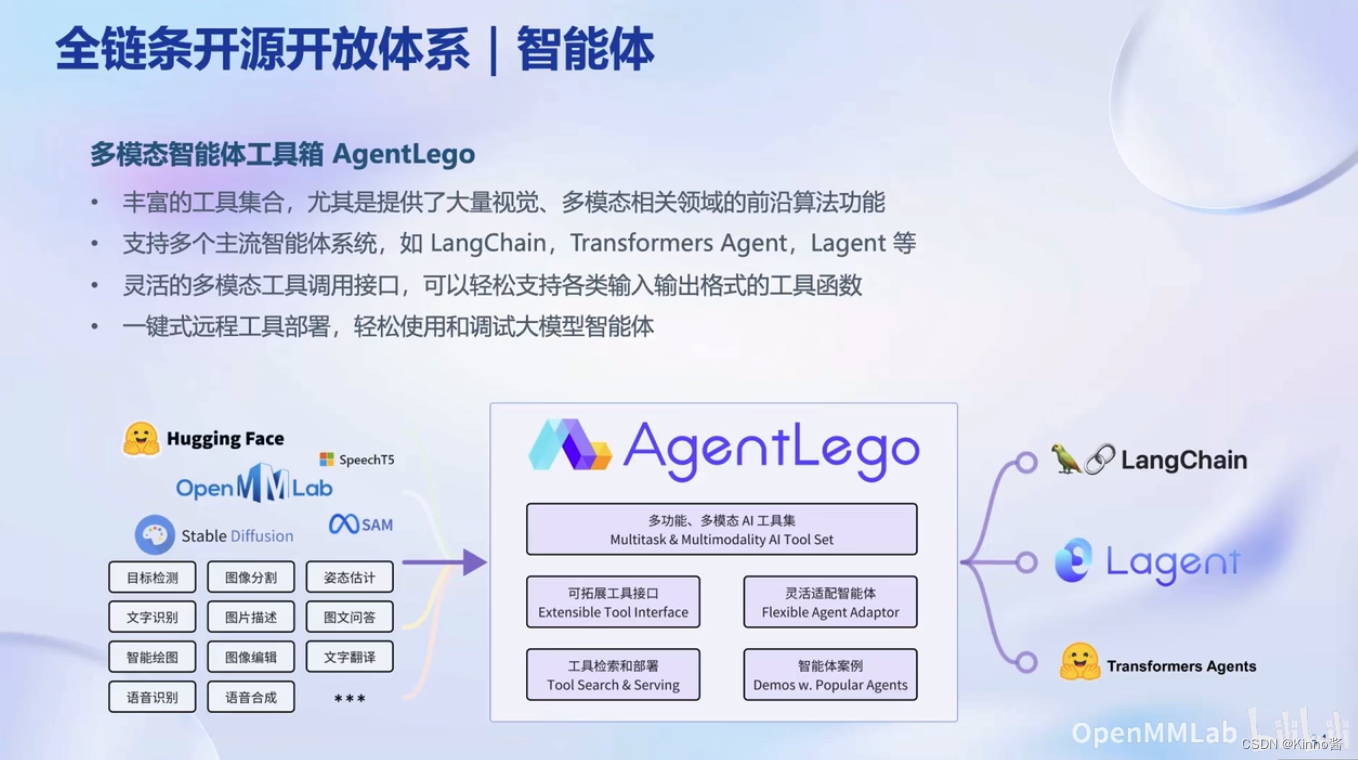
书生·浦语大模型实战营-学习笔记1
目录 书生浦语大模型全链路开源体系数据集预训练微调评测部署多智能体 视频地址: (1)书生浦语大模型全链路开源体系 开源工具github: https://github.com/InternLM/InternLM 书生浦语大模型全链路开源体系 这次视频中介绍了由上海人工智能实验室OpenMMLa…...
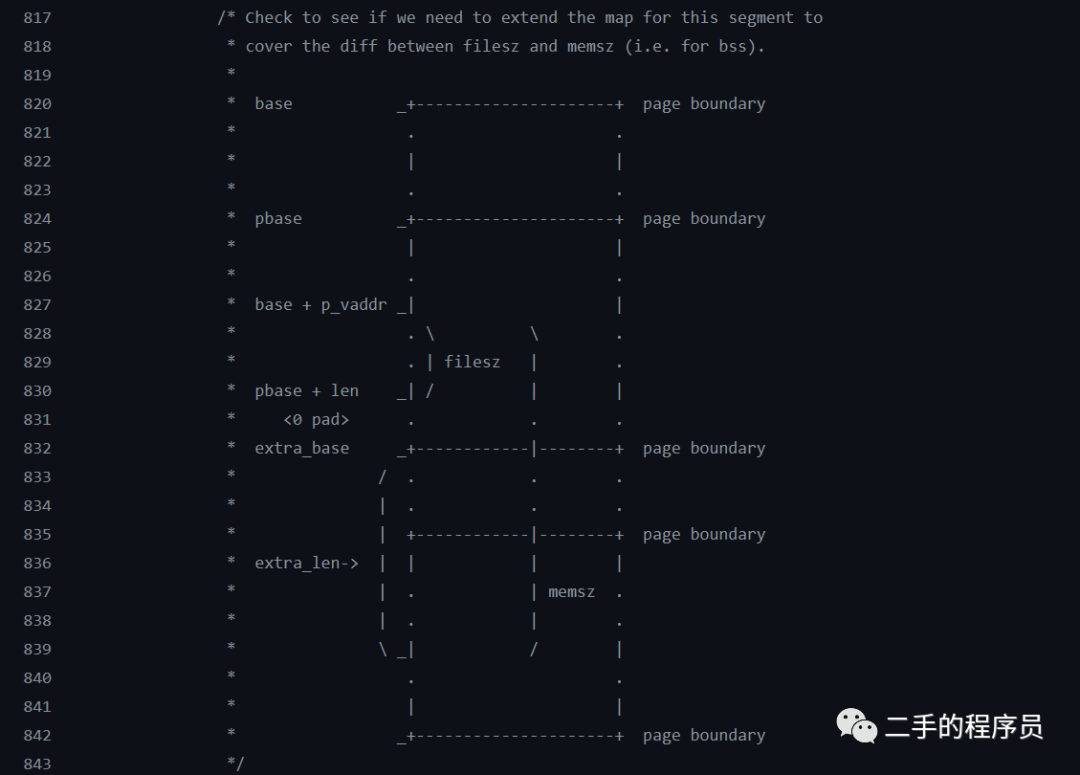
ELF解析03 - 加载段
本文主要讨论 mmap 函数以及如何使用 mmap 函数来加载一个 ELF 的可加载段。 01纠错 Android 8 及以后是会读取 section header 的,但不是所有的 section 都会读取。 https://cs.android.com/android/platform/superproject/main//main:bionic/linker/linker_phdr…...
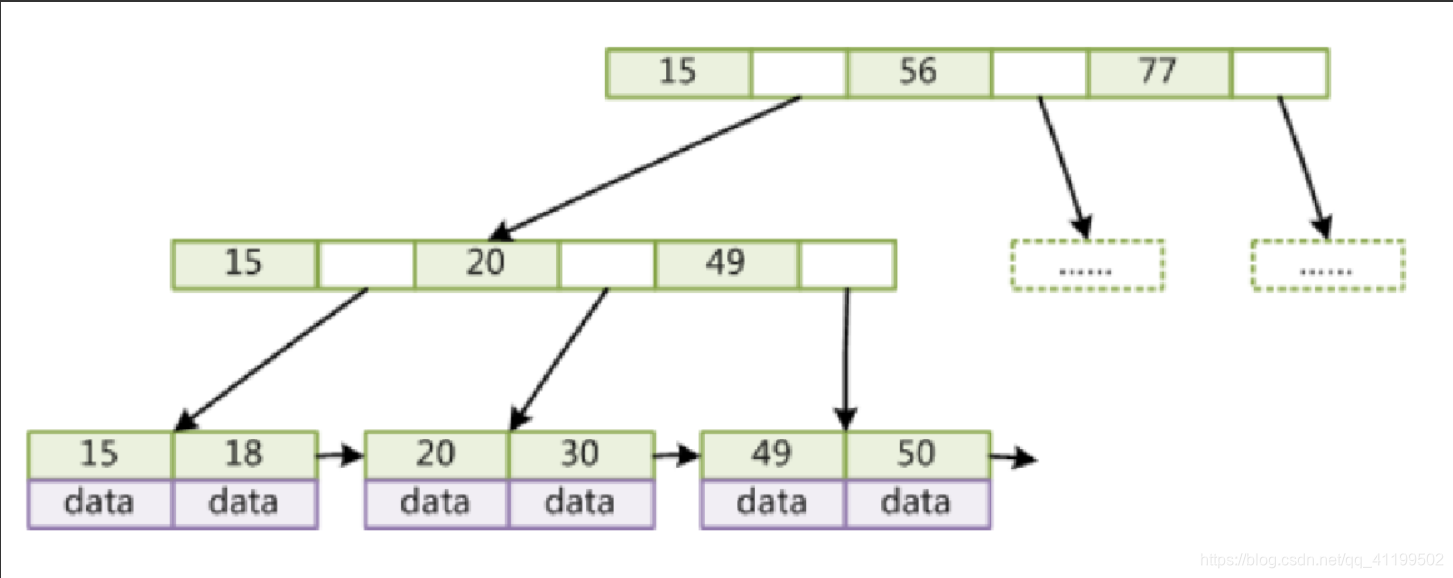
Mysql——索引相关的数据结构
索引 引入 我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为…...

无代码DIY图像检索
软件环境准备 可参见《HuggingFists-低代码玩转LLM RAG-准备篇》中的HuggingFists安装及Milvus安装。 流程环境准备 图片准备 进入HuggingFists内置的文件系统,数据源->文件系统->sengee_fs_settings_201创建Image文件夹将事先准备的多张相同或不同种类的图…...
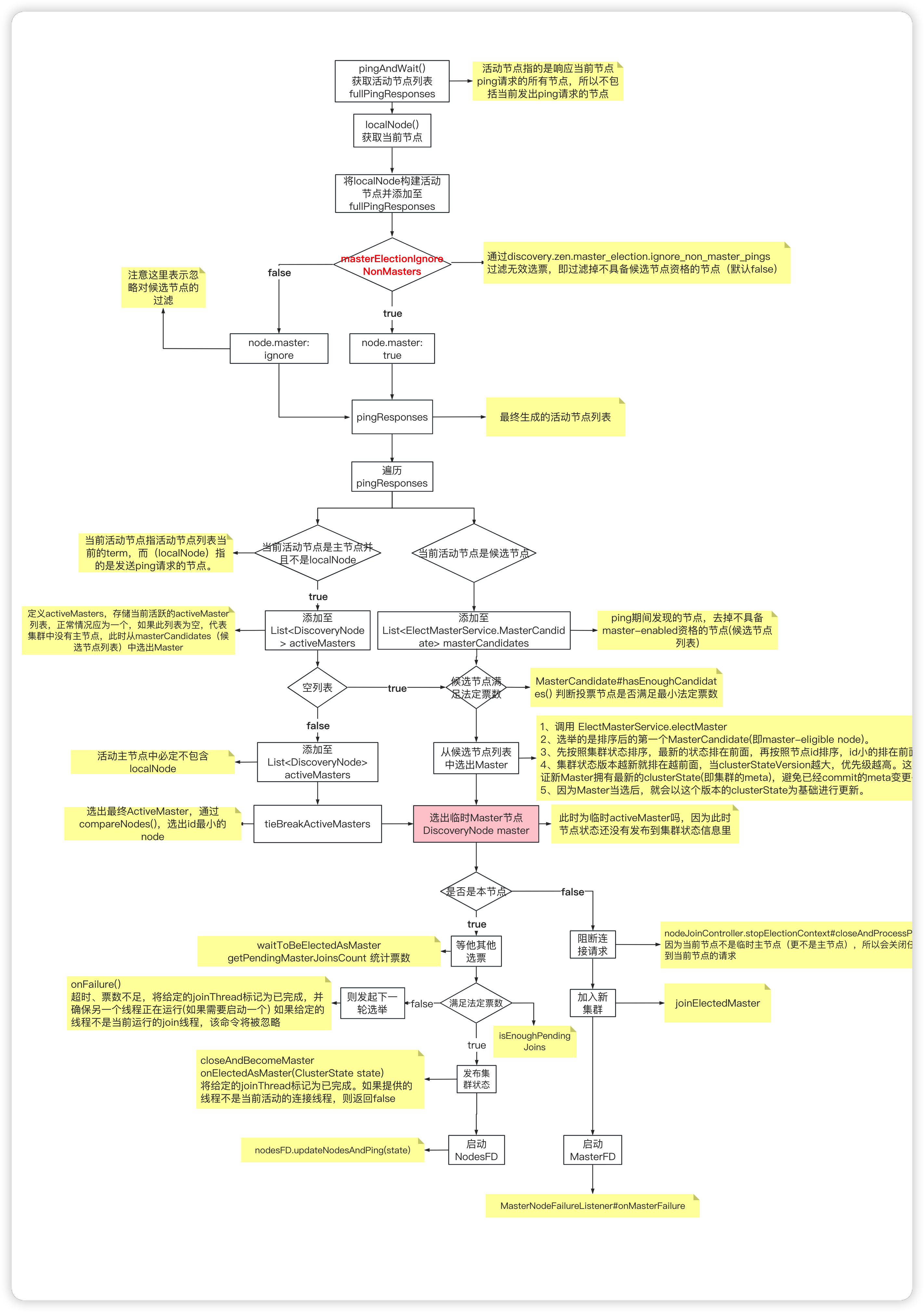
Elasticsearch--Master选举
角色 主节点(active master):一般指的是活跃的主节点,避免负载任务,主节点主要用来管理集群,专用master节点仍将充当协调节点 候选节点(master-eligible nodes):默认具备…...

微服务实战系列之Filter
前言 Filter,又名过滤器,当然不是我们日常中见到的,诸如此类构件: 而应该是微服务中常使用的,诸如此类(图片来自官网,点击可查看原图): 一般用于字符编码转换…...

使用GPT大模型调用工具链
本文特指openai使用sdk的方式调用工具链。 安装openai pip install openai export OPENAI_API_KEY"YOUR OPENAI KEY" 定义工具函数 from openai import OpenAI import jsonclient OpenAI() #工具函数 def get_current_weather(location, unit"fahrenheit&q…...

C语言实现bmp图像底层数据写入与创建
要用C语言实现bmp图像底层数据写入进而创建一张bmp图像,需要对bmp图像文件格式非常了解,如果不太熟悉bmp图像文件格式请先移步bmp图像文件格式超详解 创建bmp图像文件的方式有很多,比如用halcon,用qt,这些都是把已经画…...

AI应用开发利器:ai-devkit工具包核心功能与工程实践指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现一个挺有意思的项目,叫codeaholicguy/ai-devkit。乍一看名字,你可能会觉得这又是一个“AI开发工具包”,市面上类似的工具已经多如牛毛了。但深入用下来,我发现它不太一…...

解锁GitHub极速体验:智能加速插件深度解析
解锁GitHub极速体验:智能加速插件深度解析 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub GitHub加速插件(…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...
)
告别混乱信号!用CANdb++ Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程)
告别混乱信号!用CANdb Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程) 在汽车电子开发领域,CAN总线如同神经脉络般贯穿整车系统。我曾参与过一个新能源整车项目,由于早期缺乏规范的DBC文件,不同ECU厂商…...

Boss直聘职位数据自动化采集:Python爬虫架构设计与工程实践
1. 项目概述与核心价值最近在技术社区里,看到不少朋友在讨论一个叫longsizhuo/BossZhiPin_Job_Search的项目。光看名字,你大概就能猜到,这是一个跟“Boss直聘”和“职位搜索”相关的自动化工具。作为一个在招聘数据分析和自动化领域摸爬滚打了…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

基于大语言模型的本地语义搜索工具LLocalSearch部署与应用指南
1. 项目概述:一个能“读懂”你电脑的本地搜索工具 如果你和我一样,电脑里塞满了各种文档、邮件、聊天记录和代码片段,那么“找东西”这件事,绝对能排进日常最耗时的任务前三。传统的文件搜索,比如Windows自带的搜索或者…...

猫抓插件:5分钟掌握浏览器资源嗅探的终极武器
猫抓插件:5分钟掌握浏览器资源嗅探的终极武器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天,你…...

自主智能体框架构建指南:从LLM工具调用到多任务规划系统
1. 项目概述:一个能“开疆拓土”的智能体框架最近在开源社区里,一个名为njbrake/agent-of-empires的项目引起了我的注意。光看这个名字,就充满了野心和想象力——“帝国的代理人”。这可不是一个简单的脚本工具,而是一个旨在构建能…...
)
别再让用户等上传!用@ffmpeg/ffmpeg在浏览器里直接压缩视频(附ThinkPHP项目实战)
浏览器端视频压缩实战:基于FFmpeg.wasm与ThinkPHP的高效集成方案 引言 在当今内容为王的互联网时代,视频已成为用户生成内容(UGC)的核心载体。然而,高清视频带来的大文件体积往往成为用户体验的瓶颈——上传等待时间长…...