Sqoop与其他数据采集工具的比较分析

比较Sqoop与其他数据采集工具是一个重要的话题,因为不同的工具在不同的情况下可能更适合。在本博客文章中,将深入比较Sqoop与其他数据采集工具,提供详细的示例代码和全面的内容,以帮助大家更好地了解它们之间的差异和优劣势。
Sqoop
Sqoop是一个Apache项目,专门设计用于在Hadoop生态系统和关系型数据库之间传输数据。它提供了方便的命令行界面,支持从关系型数据库导入数据到Hadoop集群,以及从Hadoop导出数据到关系型数据库。Sqoop是Hadoop生态系统的一部分,因此与Hadoop集成非常紧密。
以下是一些Sqoop的关键特点:
-
支持多种数据库: Sqoop支持与各种关系型数据库的集成,包括MySQL、Oracle、SQL Server等。
-
增量加载: Sqoop支持增量加载策略,可仅导入发生变化的数据,而不必每次导入整个数据集。
-
数据格式转换: Sqoop可以将数据从数据库中提取并将其转换为Hadoop支持的数据格式,如Avro、Parquet等。
-
命令行界面: Sqoop提供了易于使用的命令行界面,方便用户进行操作和配置。
Sqoop vs. Flume
-
Sqoop: 适用于批量数据传输,特别是从关系型数据库到Hadoop。增量加载功能非常强大,适用于数据仓库等场景。
-
Flume: 适用于流式数据采集,具有实时数据传输的能力。它更适合处理日志文件和事件流等实时数据。
示例代码:Sqoop的批量导入
sqoop import \--connect jdbc:mysql://localhost:3306/mydb \--username myuser \--password mypassword \--table mytable \--target-dir /user/hadoop/mytable_data
Sqoop vs. Kafka Connect
-
Sqoop: 主要用于传输批量数据,适用于大规模的数据导入和导出任务。对于数据仓库和数据湖等批处理场景非常有用。
-
Kafka Connect: 适用于流式数据集成,特别是与Apache Kafka集成。它可以在实时流中捕获数据,并将其推送到Kafka主题。
示例代码:使用Kafka Connect从MySQL导入数据到Kafka
curl -X POST -H "Content-Type: application/json" --data '{"name": "mysql-source","config": {"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector","tasks.max": "1","connection.url": "jdbc:mysql://localhost:3306/mydb","connection.user": "myuser","connection.password": "mypassword","mode": "timestamp+incrementing","timestamp.column.name": "last_modified","incrementing.column.name": "id","topic.prefix": "mysql-","poll.interval.ms": "1000","batch.max.rows": "500"}
}' http://localhost:8083/connectors
Sqoop vs. Spark
-
Sqoop: 主要用于传输大规模批处理数据,特别适用于与关系型数据库的集成。Sqoop的增量加载功能强大,适用于数据仓库和数据湖等场景。
-
Spark: 是一个通用的大数据处理框架,具有批处理和流处理的能力。Spark可以在内存中高效处理数据,并支持实时数据流处理。
示例代码:使用Spark从MySQL导入数据
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("SqoopVsSpark").getOrCreate()# 从MySQL加载数据
df = spark.read \.format("jdbc") \.option("url", "jdbc:mysql://localhost:3306/mydb") \.option("dbtable", "mytable") \.option("user", "myuser") \.option("password", "mypassword") \.load()# 执行数据处理操作
# ...# 保存结果或输出
# df.write.parquet("/user/hadoop/mytable_data")
Sqoop vs. Flink
-
Sqoop: 主要用于批处理数据传输,适用于大规模数据导入和导出。Sqoop的增量加载功能可用于数据仓库等批处理任务。
-
Flink: 是一个流式数据处理引擎,具有实时数据流处理和批处理的能力。Flink适用于需要低延迟和复杂事件处理的实时数据处理任务。
示例代码:使用Flink进行实时数据流处理
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class FlinkExample {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> sourceStream = env.socketTextStream("localhost", 9999);DataStream<Tuple2<String, Integer>> wordCounts = sourceStream.flatMap(new Tokenizer()).keyBy(0).sum(1);wordCounts.print();env.execute("Flink Example");}public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {// 实现数据处理逻辑// ...}}
}
总结
在本文中,对Sqoop与其他数据采集工具进行了全面的比较分析,包括Flume、Kafka Connect、Spark和Flink等。每个工具都有其自身的特点和适用场景,根据项目需求和数据采集要求选择合适的工具非常重要。
希望本文提供的示例代码和详细内容有助于大家更好地理解Sqoop与其他工具之间的差异和优劣势,以便在数据采集和数据处理过程中做出明智的决策。
相关文章:
Sqoop与其他数据采集工具的比较分析
比较Sqoop与其他数据采集工具是一个重要的话题,因为不同的工具在不同的情况下可能更适合。在本博客文章中,将深入比较Sqoop与其他数据采集工具,提供详细的示例代码和全面的内容,以帮助大家更好地了解它们之间的差异和优劣势。 Sq…...

Pandas实战100例 | 案例 31: 转换为分类数据
案例 31: 转换为分类数据 知识点讲解 在处理包含文本数据的 DataFrame 时,将文本列转换为分类数据类型通常是一个好主意。这可以提高性能并节省内存。Pandas 允许将列转换为 category 类型。 分类数据类型: category 类型适用于那些只包含有限数量不同值的列&…...

椋鸟C语言笔记#33:文件的顺序读写
萌新的学习笔记,写错了恳请斧正。 目录 光标(文件位置指示器) 文件的顺序读写 fgetc 使用实例 fputc 使用实例 fgets fputs 使用实例 fscanf fprintf fread fwrite 使用实例 光标(文件位置指示器) 我们…...

Transformer - Attention is all you need 论文阅读
虽然是跑路来NLP,但是还是立flag说要做个project,结果kaggle上的入门project给的例子用的是BERT,还提到这一方法属于transformer,所以大概率读完这一篇之后,会再看BERT的论文这个样子。 在李宏毅的NLP课程中多次提到了…...

安装配置Flink
安装配置Flink 1.上传安装包到Linux 2.解压到指定路径 tar -zxf ./flink-1.14.0-bin-scala_2.12.tgz /usr/local/src/3.修改环境变量 vi ~/.bashrc#往最后加入 export FLINK_HOME /usr/local/src/flink-1.14.0/ export PATH$PATH:$FLINK_HOME/bin#激活环境变量 source ~/.…...
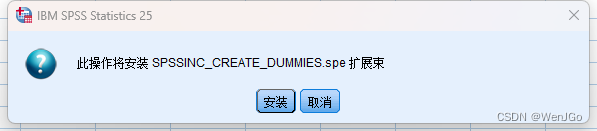
解决Spss没有创建虚拟变量的选项的问题
这个是今天用spss想创建虚拟变量然后发现我的spss没有。 然后能怎么办我就百度呗, 说是在扩展里连接扩展中心 天哪,谁能连上,我连不上 于是就找到了从github上下载到本地,然后安装到spss中 目录 解决方法 点击code 再点击D…...

wxWidgets实战:使用mpWindow绘制阻抗曲线
选择模型时,需要查看model的谐振频率,因此需要根据s2p文件绘制一张阻抗曲线。 如下图所示: mpWindow 左侧使用mpWindow,右侧使用什么? wxFreeChart https://forums.wxwidgets.org/viewtopic.php?t44928 https://…...
冻结和解冻神经网络模型的参数)
深度学习15—(迁移学习)冻结和解冻神经网络模型的参数
冻结与解冻代码: def freeze_net(net):if not net:returnfor p in net.parameters():p.requires_grad Falsedef unfreeze_net(net):if not net:returnfor p in net.parameters():p.requires_grad True 这段代码定义了两个函数:freeze_net 和 unfree…...

强化学习应用(八):基于Q-learning的无人机物流路径规划研究(提供Python代码)
一、Q-learning简介 Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个价值函数来指导智能体在环境中做出决策,以最大化累积奖励。 Q-learning算法的核心思想是通过不断更新一个称为Q值的…...

常见面试题之HTML
行内元素有哪些?块级元素有哪些? 空(void)元素有那些? HTML 中的行内元素(inline elements)通常用于在一行内显示,不会独占一行的空间。常见的行内元素有: <span>:用于对文本…...

数据结构与算法教程,数据结构C语言版教程!(第三部分、栈(Stack)和队列(Queue)详解)六
第三部分、栈(Stack)和队列(Queue)详解 栈和队列,严格意义上来说,也属于线性表,因为它们也都用于存储逻辑关系为 "一对一" 的数据,但由于它们比较特殊,因此将其单独作为一章,做重点讲解。 使用栈…...

使用Docker部署PDF多功能工具Stirling-PDF
1.服务器上安装docker 安装比较简单,这种安装的Docker不是最新版本,不过对于学习够用了,依次执行下面命令进行安装。 sudo apt install docker.io sudo systemctl start docker sudo systemctl enable docker 查看是否安装成功 $ docker …...

linux安装系统遇到的问题
这两天打算攻克下来网络编程,发现这也确实是很重要的一个东西,但我就奇了怪了,老师就压根没提,反正留在我印象的就一个tcp/ip七层网络。也说正好,把linux命令也熟悉熟悉,拿着我大一课本快速过过 连接cento…...

groovy XmlParser 递归遍历 xml 文件,修改并保存
使用 groovy.util.XmlParser 解析 xml 文件,对文件进行修改(新增标签),然后保存。 是不是 XmlParser 没有提供方法遍历每个节点,难道要自己写? 什么是递归? 不用说,想必都懂得~ …...
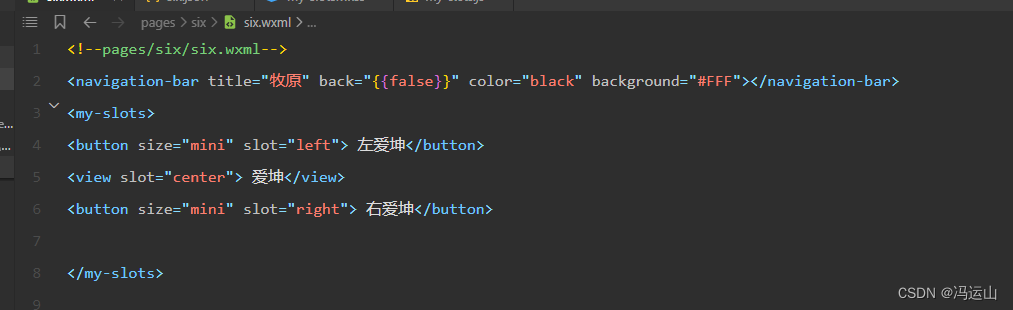
小程序基础学习(多插槽)
先创建插槽 定义多插槽的每一个插槽的属性 在js文件中启用多插槽 在页面使用多插槽 组件代码 <!--components/my-slots/my-slots.wxml--><view class"container"><view class"left"> <slot name"left" ></slot>&…...
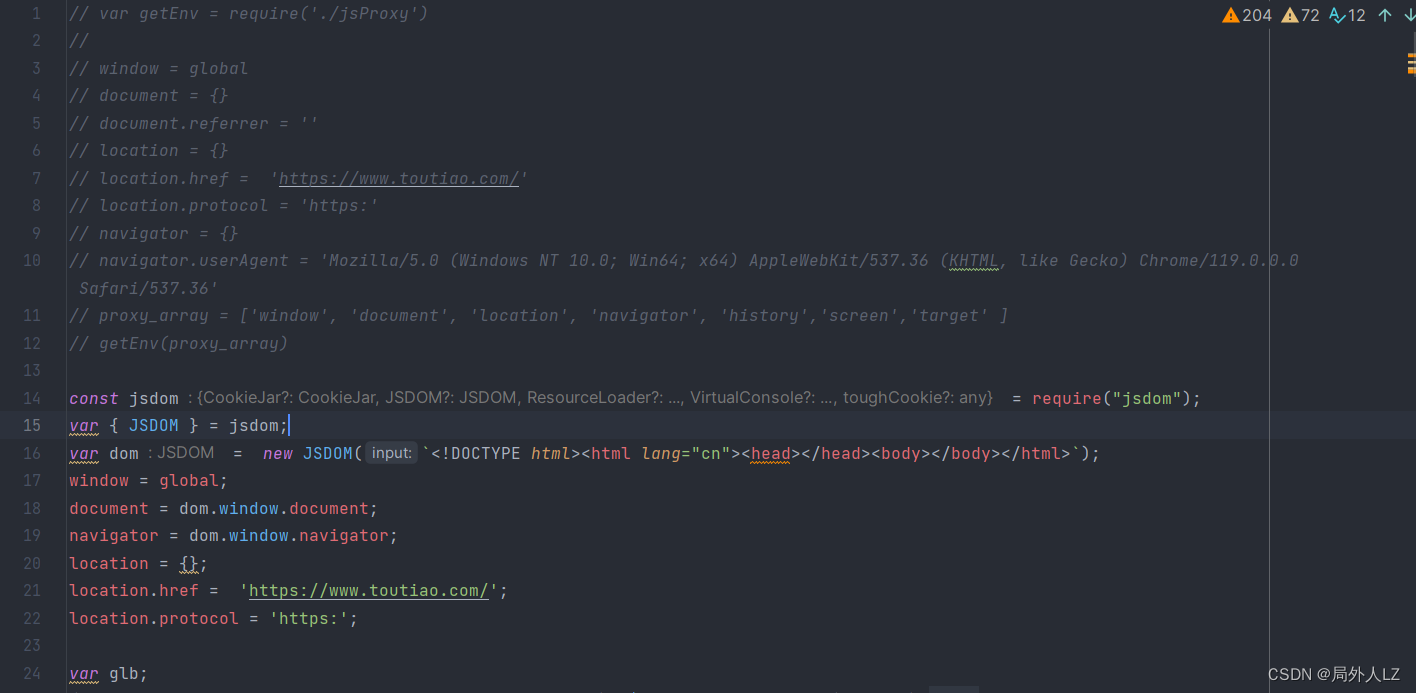
爬虫补环境jsdom、proxy、Selenium案例:某条
声明: 该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关 一、简介 爬虫逆向补环境的目的是为了模拟正常用户的行为,使爬虫看起来更像是一个真实的用户在浏览网站。这样可以…...

电子学会C/C++编程等级考试2021年09月(四级)真题解析
C/C++编程(1~8级)全部真题・点这里 第1题:最佳路径 如下所示的由正整数数字构成的三角形: 7 3 8 8 1 0 2 7 4 4 4 5 2 6 5 从三角形的顶部到底部有很多条不同的路径。对于每条路径,把路径上面的数加起来可以得到一个和,和最大的路径称为最佳路径。你的任务就是求出最佳路径…...

DevExpress历史安装文件包集合
Components - DevExpress.NET组件安装包此安装程序包括所有 .NET Framework、.NET Core 3 和 .NET 5、ASP.NET Core 和 HTML/JavaScript 组件和库(Web和桌面应用程序开发只需要安装此文件即可)。 注意:自DevExpress21.1版本之后,该…...

科技云报道:“存算一体”是大模型AI芯片的破局关键?
科技云报道原创。 在AI发展历史上,曾有两次“圣杯时刻”。 第一次发生在2012年10月,卷积神经网络(CNN)算法凭借比人眼识别更低的错误率,打开了计算机视觉的应用盛世。 第二次是2016年3月,DeepMind研发的…...

watch监听一个对象中的属性 - Vue篇
vue中提供了watch方法,可以监听data内的某些数据的变动,触发相应的方法。 1.监听一个对象 <script>export default {data() {return {obj: {name: ,code: ,timePicker:[]}}},watch: {obj: {handler(newVal, oldVal) {//todo},immediate: true,deep…...
)
为什么你的Midjourney账单暴涨200%?3个被官方文档隐瞒的计费临界点曝光(含--tile模式下的隐性显存倍增机制)
更多请点击: https://intelliparadigm.com 第一章:Midjourney GPU时间计算的本质与计费范式重构 Midjourney 的 GPU 时间并非基于物理设备的实时秒级占用,而是通过抽象化的“任务单元”(Task Unit, TU)进行计量。每个…...

CF-ISAC技术:无蜂窝网络中的感知通信一体化
1. CF-ISAC技术概述无线通信系统正经历从单纯的信息传输向"感知-通信一体化"的范式转变。集成感知与通信(ISAC)技术通过共享硬件资源和频谱,实现了环境感知与数据传输的深度协同。这种技术突破源于多天线系统(MIMO&…...

2025最权威的五大AI科研神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 降低AI工具的存在有着极其关键的意义,这类工具可以有效地料理AI生成的内容&…...

告别手机热点!实测特斯拉Model 3用USB无线网卡搭建‘永久’车载WiFi,看视频、OTA升级全搞定
特斯拉Model 3车载WiFi终极方案:告别流量焦虑与手机依赖 每次开车带家人出行时,后排的孩子总抱怨"视频又卡住了",而手机热点不仅耗电还经常断连——这可能是许多特斯拉车主的共同困扰。更尴尬的是,当车辆停在信号死角时…...

实测Taotoken API调用延迟与稳定性在SpringBoot服务中的表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken API调用延迟与稳定性在SpringBoot服务中的表现 在将大模型能力集成到后端微服务时,开发者不仅关注功能的…...
实战:基于ETAS工具链的接口与数据映射》)
《AUTOSAR软件组件(SWC)实战:基于ETAS工具链的接口与数据映射》
1. AUTOSAR软件组件(SWC)基础概念 在汽车电子开发领域,AUTOSAR(汽车开放系统架构)已经成为行业标准。软件组件(SWC)作为AUTOSAR架构中的核心元素,承担着实现具体功能的重任。简单来说,SWC就像乐高积木,每个…...

如何在浏览器中高效使用微信网页版:浏览器扩展的终极解决方案
如何在浏览器中高效使用微信网页版:浏览器扩展的终极解决方案 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为无法在浏览器中直接使…...

从校园到职场:技术新人必须完成的3个思维转变
从象牙塔迈入软件测试的真实战场,许多技术新人会感到一种强烈的“水土不服”。在学校里,你的目标是交出一份正确的作业或通过一场考试,评价体系清晰且单一。但在职场,测试工程师面对的是不完整的文档、随时变更的需求和“为什么上…...

Blender 3MF插件:从设计到打印的无缝桥梁 [特殊字符]
Blender 3MF插件:从设计到打印的无缝桥梁 🚀 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 还在为3D模型在不同软件间转换而烦恼吗?B…...

AI系统行为治理:构建确定性护栏与运行时安全控制
1. 项目概述:为AI系统构建确定性的行为护栏如果你正在构建一个会“动手”的AI应用——无论是能帮你写代码的智能助手,还是能操作数据库的自动化流程,甚至是部署在物理设备上的机器人——那么你迟早会面临一个核心问题:如何确保它只…...