PostgreSQL之SEMI-JOIN半连接
什么是Semi-Join半连接
Semi-Join半连接,当外表在内表中找到匹配的记录之后,Semi-Join会返回外表中的记录。但即使在内表中找到多条匹配的记录,外表也只会返回已经存在于外表中的记录。而对于子查询,外表的每个符合条件的元组都要执行一轮子查询,效率比较低下。此时使用半连接操作优化子查询,会减少查询次数,提高查询性能。其主要思路是将子查询上拉到父查询中,这样内表和外表是并列关系,外表的每个符合条件的元组,只需要在内表中找符合条件的元组即可,所以效率会大大提高。
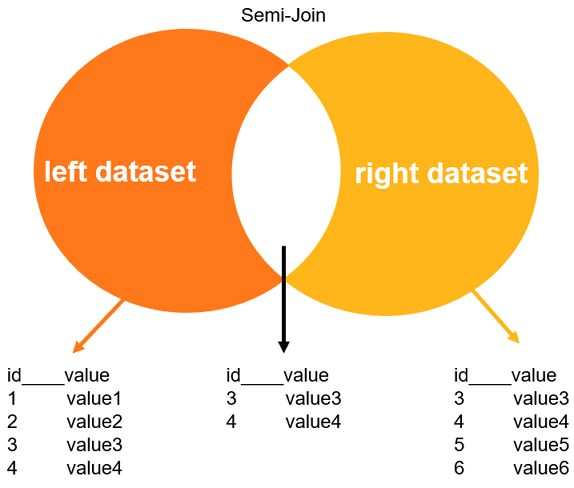
当参与等值JOIN的表达式存在有重复值时, 如果不需要找出该表其他字段的值(也就是仅使用JOIN字段/表达式), 那么JOIN时只需要查每个值的第一条, 然后就可以跳到下一个值. 在数据库中常常被用来优化 in, exists, not exists, = any(), except 等操作(或者逻辑上成立的其他JOIN场景).
还有什么特别的join?PostgreSQL 与关系代数 (Equi-Join , Semi-Join , Anti-Join , Division)
并不是所有数据库都实现了所有场景的semi join, 例如 Oracle中的半连接,MySQL也有半连接
如果未实现, 有什么方法可以模拟semi-join?递归/group by/distinct on/distinct
Semi-Join 例子
准备测试数据
postgres=# create table a (id int, info text, ts timestamp);
CREATE TABLE
postgres=# create table b (like a);
CREATE TABLE
postgres=# insert into a select id, md5(random()::text), now() from generate_series(0,1000000) as t(id);
INSERT 0 1000001 -- b表的100万行记录中b.id只有11个唯一值
postgres=# insert into b select random()*10, md5(random()::text), now() from generate_series(0,1000000) as t(id);
INSERT 0 1000001 postgres=# create index on a (id);
CREATE INDEX
postgres=# create index on b (id);
CREATE INDEX
未优化SQL
select a.* from a where exists (select 1 from b where a.id=b.id); postgres=# explain analyze select a.* from a where exists (select 1 from b where a.id=b.id); QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------- Merge Join (cost=18436.17..18436.66 rows=11 width=45) (actual time=226.590..226.598 rows=11 loops=1) Merge Cond: (a.id = b.id) -> Index Scan using a_id_idx on a (cost=0.42..27366.04 rows=1000001 width=45) (actual time=0.010..0.013 rows=12 loops=1) -> Sort (cost=18435.74..18435.77 rows=11 width=4) (actual time=226.576..226.577 rows=11 loops=1) Sort Key: b.id Sort Method: quicksort Memory: 25kB -> HashAggregate (cost=18435.44..18435.55 rows=11 width=4) (actual time=226.568..226.570 rows=11 loops=1) Group Key: b.id Batches: 1 Memory Usage: 24kB -> Index Only Scan using b_id_idx on b (cost=0.42..15935.44 rows=1000001 width=4) (actual time=0.010..77.936 rows=1000001 loops=1) Heap Fetches: 0 Planning Time: 0.189 ms Execution Time: 226.630 ms
(13 rows)
以上查询没有使用semi-join, 性能很一般.
由于b表的100万行记录中b.id只有11个唯一值, 可以使用semi-join进行加速.
用法参考: 《用PostgreSQL找回618秒逝去的青春 - 递归收敛优化》
使用递归模拟SEMI-JOIN, 只需要 0.171 ms 既可得出b表 11个值的结果.
with recursive tmp as ( select min(id) as id from b union all select (select min(b.id) from b where b.id > tmp.id) from tmp where tmp.id is not null
)
select * from tmp where tmp.id is not null; id
---- 0 1 2 3 4 5 6 7 8 9 10
(11 rows)
执行计划如下
postgres=# explain analyze with recursive tmp as ( select min(id) as id from b union all select (select min(b.id) from b where b.id > tmp.id) from tmp where tmp.id is not null
)
select * from tmp where tmp.id is not null; QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------- CTE Scan on tmp (cost=50.07..52.09 rows=100 width=4) (actual time=0.028..0.134 rows=11 loops=1) Filter: (id IS NOT NULL) Rows Removed by Filter: 1 CTE tmp -> Recursive Union (cost=0.44..50.07 rows=101 width=4) (actual time=0.025..0.126 rows=12 loops=1) -> Result (cost=0.44..0.45 rows=1 width=4) (actual time=0.024..0.025 rows=1 loops=1) InitPlan 3 (returns $1) -> Limit (cost=0.42..0.44 rows=1 width=4) (actual time=0.021..0.022 rows=1 loops=1) -> Index Only Scan using b_id_idx on b b_1 (cost=0.42..18435.44 rows=1000001 width=4) (actual time=0.020..0.020 rows=1 loops=1) Index Cond: (id IS NOT NULL) Heap Fetches: 0 -> WorkTable Scan on tmp tmp_1 (cost=0.00..4.76 rows=10 width=4) (actual time=0.007..0.007 rows=1 loops=12) Filter: (id IS NOT NULL) Rows Removed by Filter: 0 SubPlan 2 -> Result (cost=0.45..0.46 rows=1 width=4) (actual time=0.007..0.007 rows=1 loops=11) InitPlan 1 (returns $3) -> Limit (cost=0.42..0.45 rows=1 width=4) (actual time=0.006..0.006 rows=1 loops=11) -> Index Only Scan using b_id_idx on b (cost=0.42..6979.51 rows=333334 width=4) (actual time=0.006..0.006 rows=1 loops=11) Index Cond: ((id IS NOT NULL) AND (id > tmp_1.id)) Heap Fetches: 0 Planning Time: 0.177 ms Execution Time: 0.171 ms
(23 rows)
使用递归模拟semi-join, SQL改写如下:
select a.* from a where exists (select 1 from b where a.id=b.id); 改写成 select a.* from a where exists (select 1 from
(
with recursive tmp as ( select min(id) as id from b union all select (select min(b.id) from b where b.id > tmp.id) from tmp where tmp.id is not null
)
select * from tmp where tmp.id is not null
) b where a.id=b.id);
改写后速度从226.630 ms 提升到 0.246 ms
postgres=# explain analyze select a.* from a where exists (select 1 from
(
with recursive tmp as ( select min(id) as id from b union all select (select min(b.id) from b where b.id > tmp.id) from tmp where tmp.id is not null
)
select * from tmp where tmp.id is not null
) b where a.id=b.id); QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=53.76..318.49 rows=100 width=45) (actual time=0.154..0.189 rows=11 loops=1) -> HashAggregate (cost=53.34..54.34 rows=100 width=4) (actual time=0.144..0.149 rows=11 loops=1) Group Key: tmp.id Batches: 1 Memory Usage: 24kB -> CTE Scan on tmp (cost=50.07..52.09 rows=100 width=4) (actual time=0.027..0.139 rows=11 loops=1) Filter: (id IS NOT NULL) Rows Removed by Filter: 1 CTE tmp -> Recursive Union (cost=0.44..50.07 rows=101 width=4) (actual time=0.024..0.130 rows=12 loops=1) -> Result (cost=0.44..0.45 rows=1 width=4) (actual time=0.023..0.024 rows=1 loops=1) InitPlan 3 (returns $1) -> Limit (cost=0.42..0.44 rows=1 width=4) (actual time=0.020..0.021 rows=1 loops=1) -> Index Only Scan using b_id_idx on b b_1 (cost=0.42..18435.44 rows=1000001 width=4) (actual time=0.019..0.019 rows=1 loops=1) Index Cond: (id IS NOT NULL) Heap Fetches: 0 -> WorkTable Scan on tmp tmp_1 (cost=0.00..4.76 rows=10 width=4) (actual time=0.008..0.008 rows=1 loops=12) Filter: (id IS NOT NULL) Rows Removed by Filter: 0 SubPlan 2 -> Result (cost=0.45..0.46 rows=1 width=4) (actual time=0.007..0.007 rows=1 loops=11) InitPlan 1 (returns $3) -> Limit (cost=0.42..0.45 rows=1 width=4) (actual time=0.006..0.006 rows=1 loops=11) -> Index Only Scan using b_id_idx on b (cost=0.42..6979.51 rows=333334 width=4) (actual time=0.006..0.006 rows=1 loops=11) Index Cond: ((id IS NOT NULL) AND (id > tmp_1.id)) Heap Fetches: 0 -> Index Scan using a_id_idx on a (cost=0.42..2.63 rows=1 width=45) (actual time=0.003..0.003 rows=1 loops=11) Index Cond: (id = tmp.id) Planning Time: 0.295 ms Execution Time: 0.246 ms
(29 rows)
相关文章:
PostgreSQL之SEMI-JOIN半连接
什么是Semi-Join半连接 Semi-Join半连接,当外表在内表中找到匹配的记录之后,Semi-Join会返回外表中的记录。但即使在内表中找到多条匹配的记录,外表也只会返回已经存在于外表中的记录。而对于子查询,外表的每个符合条件的元组都要…...

开发规范及常用工具
一、定义对象规范 entity : 是与数据库一一对应的字段 vo : 返回给前端的视图对象 dto : 前端传过来的参数封装成dto,用于返回给前端的对象,一般用于查询操作。 POJO是DO/DTO/BO/VO的统称,禁止命名成xxxPOJO。 1、entity实体类与数据库中的字段一一对应…...
】火星文计算(模拟-JavaPythonC++JS实现))
238.【2023年华为OD机试真题(C卷)】火星文计算(模拟-JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-火星文计算二.解题思路三.题解代码Python题解代…...

如何通过openresty 限制国外Ip访问
参考代码 https://gitee.com/xiaoyun461/blocking-external-networks首先 需要的依赖: libmaxminddb https://github.com/maxmind/libmaxminddbmaxmind-geoip https://github.com/Dreamacro/maxmind-geoiplibmaxminddb 需要gcc编译,可用 Dockerfile …...

【Vue2】一个数组按时间分割为【今年】和【往年】俩个数组
一. 需求 后端返回一个数组,前端按时间维度将该数组的分割为【今年】和【往年】俩个数组后端返回的数组格式如下 timeList:[{id:1,billTime:"2024-01-10",createTime:"2024-01-10 00:00:00",status:0},{id:2,billTime:"2022-05-25"…...
解决鸿蒙APP的内存泄漏
解决鸿蒙(HarmonyOS)应用的内存泄漏问题需要采用一系列的策略和技术。与解决Android内存泄漏类似,以下是一些建议,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1…...

云原生专栏大纲
1. 私有云实战之基础环境搭建 2. 云原生实战之kubesphere搭建 3.云原生之kubesphere运维 4. 云原生之kubesphere基础服务搭建 5.云原生安全之kubesphere应用网关配置域名TLS证书 6.云原生之DevOps和CICD 7.云原生之jenkins集成SonarQube 8.云原生存储之Ceph集群 9.云原生存储之…...

robot_framework的robot语法与python脚本之间的语法转换
Robot Framework是一个开源的自动化测试框架,支持关键字驱动和数据驱动的测试方法。它具有简单易学的语法和丰富的库,可以与多种语言进行集成,包括Python。 1. robot 的关键字 Robot Framework 是一个用于自动化测试和自动化任务的开源框架…...

D1675滤波器和缓冲器用于单通道6阶高清视频滤波驱动电路,可提高视频信号性能
D1675单电源工作电压为2.5V到5V,是一款高清视频信号译码、编码的滤波器和缓冲器。与使用分立元件的传统设计相比,D1675更能节省PCB板面积,并降低成本以及提高视频信号性能。D1675集成了一个直流耦合输入缓冲器、一个消除带外噪声的视频编码器…...
Java18:网络编程
一.对象序列化: 1.对象流: ObjectInputStream 和 ObjectOutputStream 2.作用: ObjectOutputSteam:内存中的对象-->存储中的文件,通过网络传输出去 ObjectInputStream:存储中的文件,通过网络传输出去…...

【Python百宝箱】模拟未见之境:精准工具畅游分子动力学风景
分子演绎:模拟工具的综合探索 前言 在当今科学研究中,分子动力学模拟成为解析原子和分子行为的关键工具之一。本文将深入探讨几种领先的分子动力学模拟工具,包括MDTraj、ASE(原子模拟环境)、OpenMM和CHARMM。这些工具…...

Vue 3面试题
Vue 3面试题 以下是一些常见的Vue 3面试题: Vue 3中的Composition API是什么?它与Options API有什么区别? 答案: Composition API是Vue 3中引入的一种新的组件设计模式,它允许开发者通过函数的形式组织和重用组件的逻…...

M-A352AD10高精度三轴加速度计
一般描述 M-A352是一种三轴数字输出加速度计,具有超低噪声、高稳定性、低功耗等特点,采用了夸特的精细处理技术。. 多功能M-A352具有高精度和耐久性,非常适合广泛的具有挑战性的应用,如SHM、地震观测、工业设备的状态监测和工业…...
(1.13) SiK无线电高级配置(七))
(1)(1.13) SiK无线电高级配置(七)
文章目录 前言 17 技术细节 18 名词解释 前言 本文提供 SiK 遥测无线电(SiK Telemetry Radio)的高级配置信息。它面向"高级用户"和希望更好地了解无线电如何运行的用户。 17 技术细节 在评估该无线电是否符合当地法规时,了解其使用的技术可能会有所帮…...
如何注释 PDF?注释PDF文件方法详情介绍
大多数使用 PDF 文档的用户都熟悉处理这种格式的文件时出现的困难。有些人仍然认为注释 PDF 的唯一方法是打印文档,使用笔或荧光笔然后扫描回来。 您可能需要向 PDF 添加注释、添加注释、覆盖一些文本或几何对象。经理、部门负责人在编辑公司内的合同、订单、发票或…...

GEE APP——基于PFI纯净森林指数的CCDC-SMA算法的长时序森林监测APP
简介 森林生态系统的碳排放受到破碎化加速和边缘效应的极大影响。要了解这些影响,就必须准确监测破碎化森林景观的变化。然而,这些变化通常强度低、尺度小,因此很难使用中等空间分辨率的卫星图像(如 Landsat)来检测。为了应对这一挑战,本研究开发了纯林指数(PFI),该指…...

CF1446B Catching Cheaters 题解 DP
Catching Cheaters 传送门 题面翻译 给我们两个字符串,让我们从中选出两个字串,算出它们的最大公共子序列长度。然后将它乘 4 4 4在减去两个字串的长度。问你这个数最大是多少。 题目描述 You are given two strings A A A and B B B representin…...

用python实现文本/图片生成视频
使用Python来生成视频通常涉及到使用一些专门的库,比如 OpenCV 或者 moviepy。下面是一个简单的例子,使用OpenCV和PIL(Python Imaging Library)来创建一个视频。 python复制代码 import cv2 import numpy as np from PIL import …...

Android Gradle Plugin、Gradle、Android Studio版本关系
参考链接 Android Gradle Plugin 与 gradle 对应关系 插件版本所需的最低 Gradle 版本8.38.48.28.28.18.08.08.07.47.57.37.47.27.3.37.17.27.07.04.2.06.7.14.1.06.54.0.06.1.13.6.0 - 3.6.45.6.43.5.0 - 3.5.45.4.13.4.0 - 3.4.35.1.13.3.0 - 3.3.34.10.13.2.0 - 3.2.14.63…...

PyTorch深度学习实战(30)——Deepfakes
PyTorch深度学习实战(30)——Deepfakes 0. 前言1. Deepfakes 原理2. 数据集分析3. 使用 PyTorch 实现 Deepfakes3.1 random_warp.py3.2 Deepfakes.py 小结系列链接 0. 前言 Deepfakes 是一种利用深度学习技术生成伪造视频和图像的技术。它通过将一个人的…...

如何高效采集直播数据:微信视频号监控工具的完整实战指南
如何高效采集直播数据:微信视频号监控工具的完整实战指南 【免费下载链接】wxlivespy 微信视频号直播间弹幕信息抓取工具 项目地址: https://gitcode.com/gh_mirrors/wx/wxlivespy 在直播电商时代,掌握实时互动数据已成为提升直播效果的关键。你是…...

收藏!2026大厂AI招聘火爆:日薪5000抢博士,普通岗简历石沉大海?小白程序员必看生存指南
2026年大厂招聘季AI岗位需求暴涨215%,字节日薪5000抢清北博士,阿里AI岗占offer六成。AI核心岗位年薪可达百万,供需比仅0.15。非AI岗位受冲击,但AIGC产品经理、AI运营等潜力岗位升温。求职者需注重顶会论文、开源贡献等加分项&…...

终极指南:如何在Windows上使用BiliBili-UWP第三方客户端告别卡顿,享受流畅观影体验
终极指南:如何在Windows上使用BiliBili-UWP第三方客户端告别卡顿,享受流畅观影体验 【免费下载链接】BiliBili-UWP BiliBili的UWP客户端,当然,是第三方的了 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBili-UWP 还在…...

半导体行业数据解析:销售额与资本支出双高增长背后的逻辑
1. 行业数据深度解析:半导体销售额与资本支出的双高增长最近和几个在晶圆厂和设计公司工作的朋友聊天,大家不约而同地提到了一个词:“忙疯了”。订单排到明年,产线24小时连轴转,连带着上游的设备商和材料供应商都跟着“…...
)
AI大模型赋能数据治理:小白也能掌握的5个高频场景与避坑指南(收藏备用)
数据治理是企业数字化转型难题,AI大模型带来破局点。本文阐述大模型如何解决效率低、门槛高、适配弱等痛点,提供3个高价值落地场景(非结构化数据治理、数据质量治理、数据资产化治理)及5个高频踩坑陷阱,并给出最佳实践…...

终极AI图像分层工具LayerDivider:3分钟完成复杂插画自动分层
终极AI图像分层工具LayerDivider:3分钟完成复杂插画自动分层 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 在数字设计创作中,您…...

别再让图片拖慢你的Unity项目!手把手教你用AssetPostprocessor搞定尺寸与压缩
Unity项目性能优化:智能图片处理全攻略 1. 为什么图片处理对Unity项目至关重要 在Unity开发过程中,图片资源往往是项目体积膨胀的罪魁祸首。一个中型项目可能包含数千张纹理,如果不加控制,这些资源会迅速吞噬内存和存储空间。更糟…...

AntiDupl.NET:告别数字杂乱,让图片管理回归优雅
AntiDupl.NET:告别数字杂乱,让图片管理回归优雅 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾经在整理照片时,发现手机里…...
)
Hydrin 1 ([Arg8, Gly10, Lys11, Arg12]-Vasotocin)
一、基础信息多肽名称:Hydrin 1,加压催产素变体 [Arg8, Gly10, Lys11, Arg12]-Vasotocin 三字母序列:Cys-Tyr-Ile-Gln-Asn-Cys-Pro-Arg-Gly-Gly-Lys-Arg 单字母序列:CYIQNCPRG GKR 氨基酸数目:12 aa 结构特征ÿ…...

第十章:C++ 迷你单元测试框架
第十章:C++ 迷你单元测试框架 本章从"写业务"切换到"写工具"。前 9 个案例都是给最终用户看的应用;本案例要做的是给其他程序员用的库——一个百行代码、头文件 only 的单元测试框架(类似 Catch2 的最小骨架)。你将集中练习三件被前 9 个案例覆盖不到位…...