CUDA驱动深度学习发展 - 技术全解与实战
全面介绍CUDA与pytorch cuda实战
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人

一、CUDA:定义与演进
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一个并行计算平台和应用编程接口(API)模型。它允许开发者使用NVIDIA的GPU进行高效的并行计算,从而加速计算密集型任务。在这一节中,我们将详细探讨CUDA的定义和其演进过程,重点关注其关键的技术更新和里程碑。
CUDA的定义
CUDA是一种允许软件开发者和软件工程师直接访问虚拟指令集和并行计算元素的平台和编程模型。它包括CUDA指令集架构(ISA)和并行计算引擎在GPU上的实现。CUDA平台是为了利用GPU的强大计算能力而设计,特别适合处理可以并行化的大规模数据计算任务。
CUDA的演进历程
CUDA的诞生
- 2006年:CUDA的初现
- NVIDIA在2006年发布了CUDA,这标志着GPU计算的一个重大突破。在这之前,GPU主要被用于图形渲染。
CUDA的早期版本
- CUDA 1.0(2007年)
- 这是CUDA的首个公开可用版本,为开发者提供了一套全新的工具和API,用于编写GPU加速程序。
- CUDA 2.0(2008年)
- 引入了对双精度浮点运算的支持,这对科学计算尤为重要。
CUDA的持续发展
- CUDA 3.0(2010年)和CUDA 4.0(2011年)
- 引入了多项改进,包括对更多GPU架构的支持和更高效的内存管理。CUDA 4.0特别强调了对多GPU系统的支持,允许更加灵活的数据共享和任务分配。
CUDA的成熟期
- CUDA 5.0(2012年)到CUDA 8.0(2016年)
- 这一时期CUDA的更新聚焦于提高性能、增强易用性和扩展其编程模型。引入了动态并行性,允许GPU线程自动启动新的核函数,极大地增强了程序的灵活性和并行处理能力。
CUDA的现代版本
- CUDA 9.0(2017年)到CUDA 11.0(2020年)
- 这些版本继续推动CUDA的性能和功能边界。加入了对最新GPU架构的支持,如Volta和Ampere架构,以及改进的编译器和更丰富的库函数。CUDA 11特别重视对大规模数据集和AI模型的支持,以及增强的异构计算能力。
每个CUDA版本的发布都是对NVIDIA在并行计算领域技术革新的体现。从早期的基础设施搭建到后来的性能优化和功能扩展,CUDA的发展历程展示了GPU计算技术的成熟和深入应用。在深度学习和高性能计算领域,CUDA已成为一个不可或缺的工具,它不断推动着计算极限的扩展。
通过对CUDA定义的理解和其演进历程的回顾,我们可以清楚地看到CUDA如何从一个初步的概念发展成为今天广泛应用的高性能计算平台。每一次更新都反映了市场需求的变化和技术的进步,使CUDA成为了处理并行计算任务的首选工具。
二、CUDA与传统CPU计算的对比
在深入理解CUDA的价值之前,将其与传统的CPU计算进行比较是非常有帮助的。这一章节旨在详细探讨GPU(由CUDA驱动)与CPU在架构、性能和应用场景上的主要差异,以及这些差异如何影响它们在不同计算任务中的表现。
架构差异
CPU:多功能性与复杂指令集
- 设计理念:
- CPU设计注重通用性和灵活性,适合处理复杂的、串行的计算任务。
- 核心结构:
- CPU通常包含较少的核心,但每个核心能够处理复杂任务和多任务并发。
GPU:并行性能优化
- 设计理念:
- GPU设计重点在于处理大量的并行任务,适合执行重复且简单的操作。
- 核心结构:
- GPU包含成百上千的小核心,每个核心专注于执行单一任务,但在并行处理大量数据时表现卓越。
性能对比
处理速度
- CPU:
- 在执行逻辑复杂、依赖于单线程性能的任务时,CPU通常表现更优。
- GPU:
- GPU在处理可以并行化的大规模数据时,如图像处理、科学计算,表现出远超CPU的处理速度。
能效比
- CPU:
- 在单线程任务中,CPU提供更高的能效比。
- GPU:
- 当任务可以并行化时,GPU在能效比上通常更有优势,尤其是在大规模计算任务中。
应用场景
CPU的优势场景
- 复杂逻辑处理:
- 适合处理需要复杂决策树和分支预测的任务,如数据库查询、服务器应用等。
- 单线程性能要求高的任务:
- 在需要强大单线程性能的应用中,如某些类型的游戏或应用程序。
GPU的优势场景
- 数据并行处理:
- 在需要同时处理大量数据的场景下,如深度学习、大规模图像或视频处理。
- 高吞吐量计算任务:
- 适用于需要高吞吐量计算的应用,如科学模拟、天气预测等。
了解CPU和GPU的这些关键差异,可以帮助开发者更好地决定何时使用CPU,何时又应转向GPU加速。在现代计算领域,结合CPU和GPU的优势,实现异构计算,已成为提高应用性能的重要策略。CUDA的出现使得原本只能由CPU处理的复杂任务现在可以借助GPU的强大并行处理能力得到加速。
总体来说,CPU与GPU(CUDA)在架构和性能上的差异决定了它们在不同计算任务中的适用性。CPU更适合处理复杂的、依赖于单线程性能的任务,而GPU则在处理大量并行数据时表现出色。
三、CUDA在深度学习中的应用
深度学习的迅速发展与CUDA技术的应用密不可分。这一章节将探讨为什么CUDA特别适合于深度学习应用,以及它在此领域中的主要应用场景。
CUDA与深度学习:为何完美契合
并行处理能力
- 数据并行性:
- 深度学习模型,特别是神经网络,需要处理大量数据。CUDA提供的并行处理能力使得这些计算可以同时进行,大幅提高效率。
- 矩阵运算加速:
- 神经网络的训练涉及大量的矩阵运算(如矩阵乘法)。GPU的并行架构非常适合这种类型的计算。
高吞吐量
- 快速处理大型数据集:
- 在深度学习中处理大型数据集时,GPU能够提供远高于CPU的吞吐量,加快模型训练和推理过程。
动态资源分配
- 灵活的资源管理:
- CUDA允许动态分配和管理GPU资源,使得深度学习模型训练更为高效。
深度学习中的CUDA应用场景
模型训练
- 加速训练过程:
- 在训练阶段,CUDA可以显著减少模型对数据的训练时间,尤其是在大规模神经网络和复杂数据集的情况下。
- 支持大型模型:
- CUDA使得训练大型模型成为可能,因为它能够有效处理和存储巨大的网络权重和数据集。
模型推理
- 实时数据处理:
- 在推理阶段,CUDA加速了数据的处理速度,使得模型能够快速响应,适用于需要实时反馈的应用,如自动驾驶车辆的视觉系统。
- 高效资源利用:
- 在边缘计算设备上,CUDA可以提供高效的计算,使得在资源受限的环境下进行复杂的深度学习推理成为可能。
数据预处理
- 加速数据加载和转换:
- 在准备训练数据时,CUDA可以用于快速加载和转换大量的输入数据,如图像或视频内容的预处理。
研究与开发
- 实验和原型快速迭代:
- CUDA的高效计算能力使研究人员和开发者能够快速测试新的模型架构和训练策略,加速研究和产品开发的进程。
CUDA在深度学习中的应用不仅加速了模型的训练和推理过程,而且推动了整个领域的发展。它使得更复杂、更精确的模型成为可能,同时降低了处理大规模数据集所需的时间和资源。此外,CUDA的普及也促进了深度学习技术的民主化,使得更多的研究者和开发者能够访问到高效的计算资源。
总的来说,CUDA在深度学习中的应用极大地加速了模型的训练和推理过程,使得处理复杂和大规模数据集成为可能。
四、CUDA编程实例
在本章中,我们将通过一个具体的CUDA编程实例来展示如何在PyTorch环境中利用CUDA进行高效的并行计算。这个实例将聚焦于深度学习中的一个常见任务:矩阵乘法。我们将展示如何使用PyTorch和CUDA来加速这一计算密集型操作,并提供深入的技术洞见和细节。
选择矩阵乘法作为示例
矩阵乘法是深度学习和科学计算中常见的计算任务,它非常适合并行化处理。在GPU上执行矩阵乘法可以显著加速计算过程,是理解CUDA加速的理想案例。
环境准备
在开始之前,确保你的环境中安装了PyTorch,并且支持CUDA。你可以通过以下命令进行检查:
import torch
print(torch.__version__)
print('CUDA available:', torch.cuda.is_available())
这段代码会输出PyTorch的版本并检查CUDA是否可用。
示例:加速矩阵乘法
以下是一个使用PyTorch进行矩阵乘法的示例,我们将比较CPU和GPU(CUDA)上的执行时间。
准备数据
首先,我们创建两个大型随机矩阵:
import torch
import time# 确保CUDA可用
assert torch.cuda.is_available()# 创建两个大型矩阵
size = 1000
a = torch.rand(size, size)
b = torch.rand(size, size)
在CPU上进行矩阵乘法
接下来,我们在CPU上执行矩阵乘法,并测量时间:
start_time = time.time()
c = torch.matmul(a, b)
end_time = time.time()print("CPU time: {:.5f} seconds".format(end_time - start_time))
在GPU上进行矩阵乘法
现在,我们将相同的操作转移到GPU上,并比较时间:
# 将数据移动到GPU
a_cuda = a.cuda()
b_cuda = b.cuda()# 在GPU上执行矩阵乘法
start_time = time.time()
c_cuda = torch.matmul(a_cuda, b_cuda)
end_time = time.time()# 将结果移回CPU
c_cpu = c_cuda.cpu()print("GPU time: {:.5f} seconds".format(end_time - start_time))
在这个示例中,你会注意到使用GPU进行矩阵乘法通常比CPU快得多。这是因为GPU可以同时处理大量的运算任务,而CPU在执行这些任务时则是顺序的。
深入理解
数据传输的重要性
在使用CUDA进行计算时,数据传输是一个重要的考虑因素。在我们的例子中,我们首先将数据从CPU内存传输到GPU内存。这一过程虽然有一定的时间开销,但对于大规模的计算任务来说,这种开销是值得的。
并行处理的潜力
GPU的并行处理能力使得它在处理类似矩阵乘法这样的操作时极为高效。在深度学习中,这种能力可以被用来加速网络的训练和推理过程。
优化策略
为了最大化GPU的使用效率,合理的优化策略包括精细控制线程布局、合理使用共享内存等。在更复杂的应用中,这些优化可以带来显著的性能提升。
五、PyTorch CUDA深度学习案例实战
在本章节中,我们将通过一个实际的深度学习项目来展示如何在PyTorch中结合使用CUDA。我们选择了一个经典的深度学习任务——图像分类,使用CIFAR-10数据集。此案例将详细介绍从数据加载、模型构建、训练到评估的整个流程,并展示如何利用CUDA加速这个过程。
环境设置
首先,确保你的环境已经安装了PyTorch,并支持CUDA。可以通过以下代码来检查:
import torchprint("PyTorch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
如果输出显示CUDA可用,则可以继续。
CIFAR-10数据加载
CIFAR-10是一个常用的图像分类数据集,包含10个类别的60000张32x32彩色图像。
加载数据集
使用PyTorch提供的工具来加载和归一化CIFAR-10:
import torch
import torchvision
import torchvision.transforms as transforms# 数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加载训练集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)# 加载测试集
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
构建神经网络
接下来,我们定义一个简单的卷积神经网络(CNN):
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = Net()
CUDA加速
将网络转移到CUDA上:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
训练网络
使用CUDA加速训练过程:
import torch.optim as optimcriterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)for epoch in range(2): # 多次循环遍历数据集running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 2000 == 1999: # 每2000个小批次打印一次print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))running_loss = 0.0print('Finished Training')
测试网络
最后,我们在测试集上评估网络性能:
correct = 0
total = 0
with torch.no_grad():for data in testloader:images, labels = data[0].to(device), data[1].to(device)outputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
相关文章:
CUDA驱动深度学习发展 - 技术全解与实战
全面介绍CUDA与pytorch cuda实战 关注TechLead,分享AI全维度知识。作者拥有10年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士&…...

如何做用户分层和标签体系
“活动作了一场接一场,简直要累死了,拉进来的客户也没有多少,投入产出完全不成比例,怎么办?“ “有那么多注册用户,但是GMV怎么才这么点,他们怎么不买啊,难道都是羊毛党?…...

Vue+Element Ui实现el-table自定义表头下拉选择表头筛选
用vueelement ui开发管理系统时,使用el-table做表格,当表格列过多的时候,想要做成可选表头的,实现表格列的筛选显示,效果如下: 代码文件结构: 废话不多说,直接上代码: 第…...

使用Java连接MongoDB (6.0.12) 报错
报错: Exception in thread "main" com.mongodb.MongoCommandException: Command failed with error 352: Unsupported OP_QUERY command: create. 上图中“The client driver may require an upgrade”说明了“客户端驱动需要进行升级”,解…...
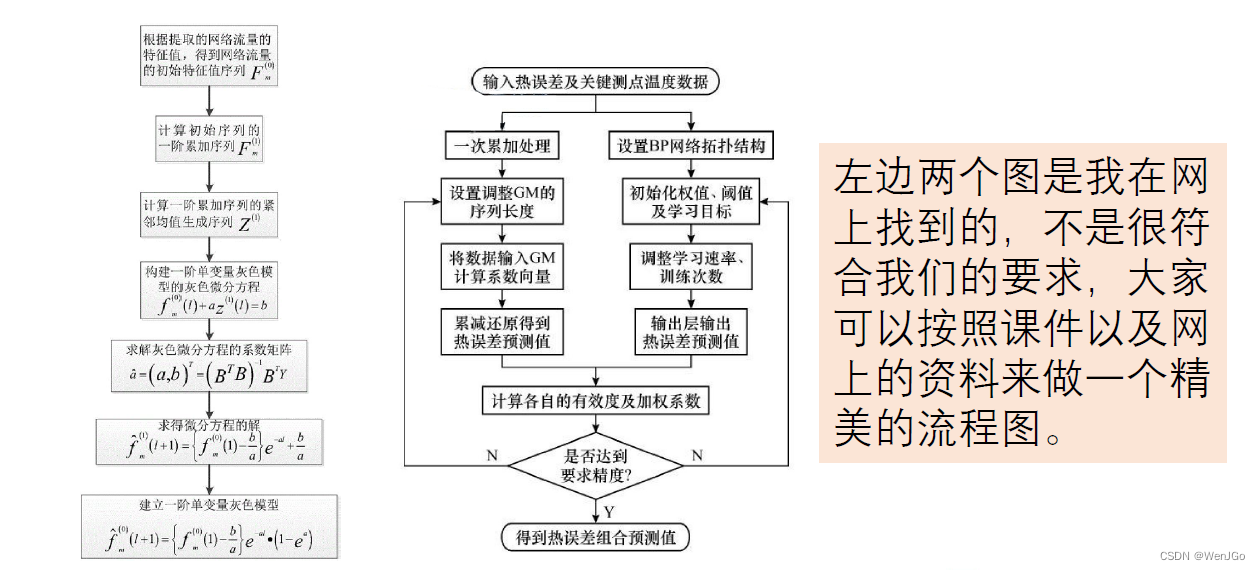
数学建模day16-预测模型
本讲首先将介绍灰色预测模型,然后将简要介绍神经网络在数据预测中的应用,在本讲的最 后,我将谈谈清风大佬对于数据预测的一些看法。 注:本文源于数学建模学习交流相关公众号观看学习视频后所作 目录 灰色系统 GM(1,1)…...
Vue3响应式系统(一)
一、副作用函数。 副作用函数指的是会产生副作用的函数。例如:effect函数会直接或间接影响其他函数的执行,这时我们便说effect函数产生了副作用。 function effect(){document.body.innerText hello vue3 } 再例如: //全局变量let val 2f…...

MStart | MStart开发与学习
MStart | MStart开发与学习 1.学习 1.MStart |开机LOG显示异常排查及调整...
Etcd:context deadline exceeded原因探究及解决)
GoZero微服务个人探索之路(一)Etcd:context deadline exceeded原因探究及解决
产生错误原因就是与etcd交互时候需要指定: 证书文件的路径 客户端证书文件的路径 客户端密钥文件的路径 (同时这貌似是强制默认就需要指定了) 但我们怎么知道这三个文件路径呢,如下方法 1. 找到etcd的配置文件,里…...
C语言从入门到实战——结构体与位段
结构体与位段 前言一、结构体类型的声明1.1 结构体1.1.1 结构的声明1.1.2 结构体变量的创建和初始化 1.2 结构的特殊声明1.3 结构的自引用 二、 结构体内存对齐2.1 对齐规则2.2 为什么存在内存对齐2.3 修改默认对齐数 三、结构体传参四、 结构体实现位段4.1 什么是位段4.2 位段…...
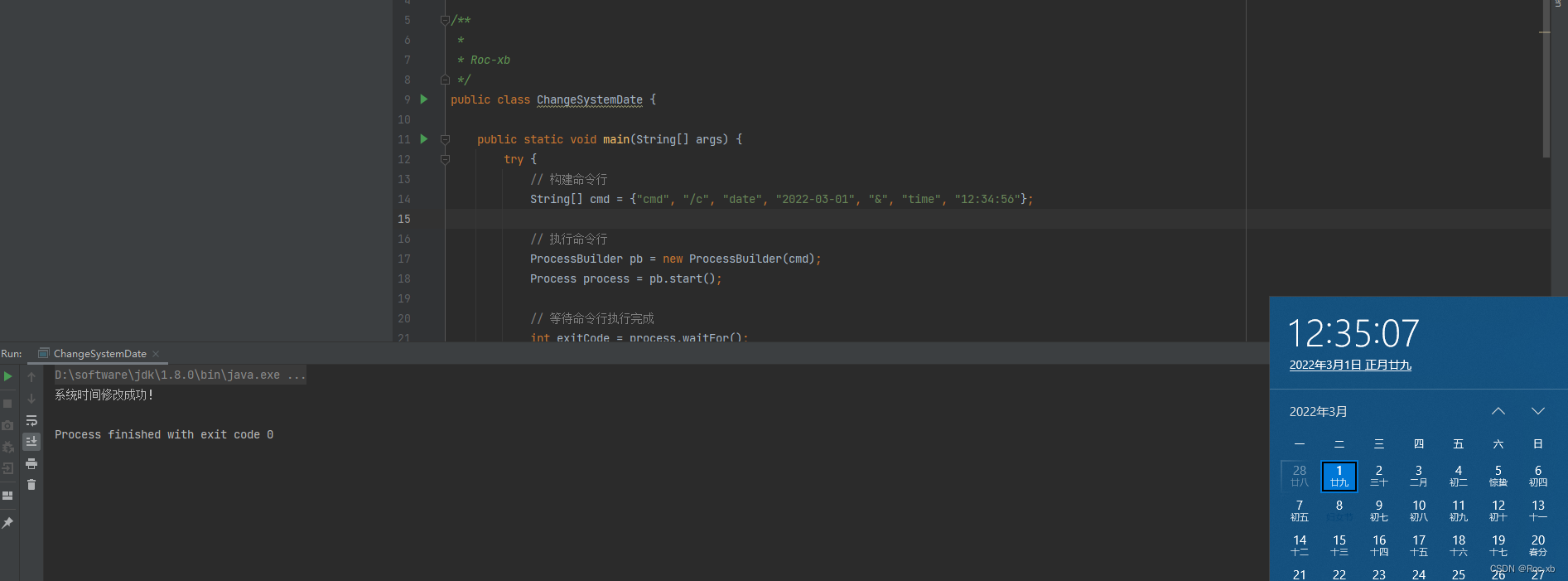
java如何修改windows计算机本地日期和时间?
本文教程,主要介绍,在java中如何修改windows计算机本地日期和时间。 目录 一、程序代码 二、运行结果 一、程序代码 package com;import java.io.IOException;/**** Roc-xb*/ public class ChangeSystemDate {public static void main(String[] args)…...

flink中的row类型详解
在Apache Flink中,Row 是一个通用的数据结构,用于表示一行数据。它是 Flink Table API 和 Flink DataSet API 中的基本数据类型之一。Row 可以看作是一个类似于元组的结构,其中包含按顺序排列的字段。 Row 的字段可以是各种基本数据类型&…...
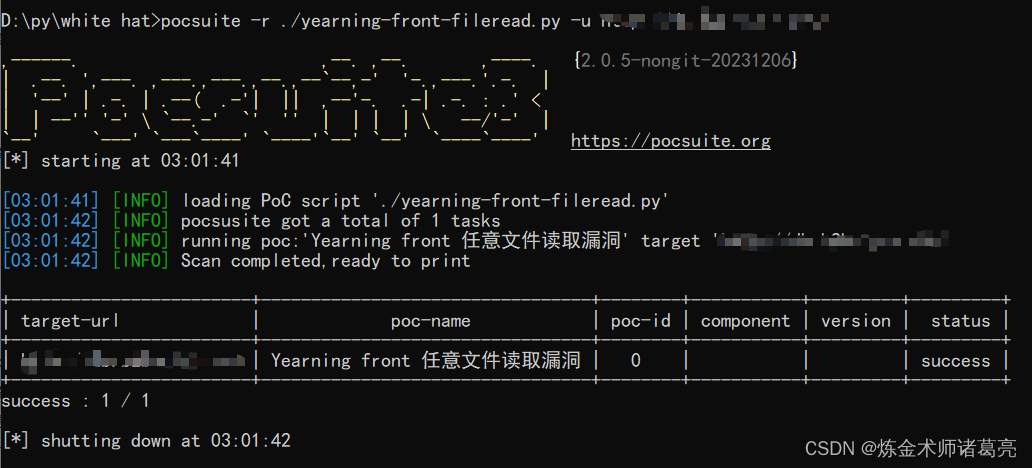
漏洞复现-Yearning front 任意文件读取漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...
K8S中SC、PV、PVC的理解
存储类(StorageClass)定义了持久卷声明(PersistentVolumeClaim)所需的属性和行为,而持久卷(PersistentVolume)是实际的存储资源,持久卷声明(PersistentVolumeClaim&#…...
Agisoft Metashape 基于影像的外部点云着色
Agisoft Metashape 基于影像的外部点云着色 文章目录 Agisoft Metashape 基于影像的外部点云着色前言一、添加照片二、对齐照片三、导入外部点云四、为点云着色五、导出彩色点云前言 本教程介绍了在Agisoft Metashape Professional中,将照片中的真实颜色应用于从不同源获取的…...
图解结算平台:准确高效给商户结款
这是《百图解码支付系统设计与实现》专栏系列文章中的第(4)篇。 本章主要讲清楚支付系统中商户结算涉及的基本概念,产品架构、系统架构,以及一些核心的流程和相关领域模型、状态机设计等。 1. 前言 收单结算是支付系统最重要的子…...

修改和调试 onnx 模型
1. onnx 底层实现原理 1.1 onnx 的存储格式 ONNX 在底层是用 Protobuf 定义的。Protobuf,全称 Protocol Buffer,是 Google 提出的一套表示和序列化数据的机制。使用 Protobuf 时,用户需要先写一份数据定义文件,再根据这份定义文…...

不同整数的最少数目和单词直接最短距离
写是为了更好的思考,坚持写作,力争更好的思考。 今天分享两个关于“最小、最短”的算法题,废话少说,show me your code! 一、不同整数的最少数目 给你一个整数数组arr和一个整数k。现需要从数组中恰好移除k个元素&…...
 (64 位) 更新失败解决方案)
【Microsoft Edge】版本 109.0.1518.55 (正式版本) (64 位) 更新失败解决方案
Microsoft Edge 版本号 109.0.1518.55(正式版本)(64位) 更新直接报错 检查更新时出错: 无法创建该组件(错误代码 3: 0x80040154 – system level) 问题出现之前 之前电脑日常硬盘百分百(删文件和移动文件都慢得像…...

深度学习笔记(四)——使用TF2构建基础网络的常用函数+简单ML分类实现
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 TF2基础常用函数 1、张量处理类 强制数据类型转换: a1 tf.constant([1,2,3], dtypetf.floa…...
:初识大模型)
大模型学习篇(一):初识大模型
目录 一、大模型的定义 二、大模型的基本原理与特点 三、大模型的分类 四、大模型的相关落地产品 五、总结 一、大模型的定义 大模型是指具有数千万甚至数亿参数的深度学习模型。大模型具有以下特点: 参数规模庞大:大模型的一个关键特征是其包含了…...
)
MacBook新手福音:用Final Cut Pro 10.6.5搞定你的第一门视频课(附保姆级设置与导出指南)
MacBook新手福音:Final Cut Pro 10.6.5视频课制作全流程精解第一次打开Final Cut Pro时,那个布满陌生术语的界面是否让你望而却步?作为Mac用户专属的视频剪辑利器,它其实远比想象中友好。本文将带你用最直接的方式,从零…...

告别卡顿:用微PE给旧电脑无损重装Win11,顺便教你用分区工具合理分配C盘空间
旧电脑焕新指南:用微PE无损重装Win11与智能分区实战 当你的旧电脑开始频繁卡顿、开机时间超过两分钟,甚至打开浏览器都要等待十几秒时,先别急着换新机。很多情况下,这只是系统长期使用积累的"垃圾"和不当分区导致的性能…...

用PyTorch和TD3教AI玩赛车:从像素输入到稳定驾驶的保姆级调参指南
用PyTorch和TD3构建赛车AI:视觉输入下的强化学习调参实战当游戏画面从单纯的娱乐载体转变为强化学习的训练场时,每一个像素都承载着决策信息。CarRacing-v2环境将这种挑战具象化——96x96的彩色图像输入需要转化为精确的转向、油门和刹车控制。不同于传统…...

https://pypi.tuna.tsinghua.edu.cn/simple/
清华镜像源 https://pypi.tuna.tsinghua.edu.cn/simple/...
)
保姆级教程:在Deepin V23 Beta3上彻底禁用Nouveau并安装指定版本NVIDIA驱动(附卸载残留清理指南)
Deepin V23 Beta3系统NVIDIA驱动深度管理指南:从禁用Nouveau到版本精准控制在Linux系统上进行深度学习开发或高性能计算时,显卡驱动的稳定性和版本兼容性往往成为关键因素。Deepin V23 Beta3作为国内用户友好的发行版,其NVIDIA驱动管理有着独…...
)
逆向分析第一步:手把手教你搭建WinDbg+VMware双机调试环境(含问题排查)
逆向工程实战:从零构建WinDbg与VMware双机调试环境调试器与虚拟机的组合是安全研究人员分析软件行为、挖掘漏洞的必备工具链。想象一下,当你需要观察一个可疑驱动程序如何与操作系统内核交互,或是追踪某个恶意样本在系统底层的活动轨迹时&…...

李白的思乡诗 / 山水诗 / 豪放诗有哪些?诗词在线app手工整理
"酒入豪肠,七分酿成了月光,余下的三分啸成剑气,绣口一吐就半个盛唐。" 李白的诗,是盛唐最耀眼的星,既有 "天生我材必有用" 的豪放,也有 "低头思故乡" 的柔情,更有…...
)
用Python手把手复现GRO淘金优化算法(附完整代码与CEC2005测试)
用Python手把手复现GRO淘金优化算法(附完整代码与CEC2005测试)当算法工程师第一次接触GRO淘金优化算法时,往往会被其独特的生物启发式设计所吸引。这种模拟19世纪淘金者行为的元启发式算法,在解决复杂优化问题时展现出令人惊讶的效…...
)
给Llama-3-8B-Instruct加个‘垫片’:手把手教你安全添加Pad Token并微调(附完整代码)
为Llama-3-8B-Instruct安全添加Pad Token的工程实践指南当你在微调Llama-3-8B-Instruct时,是否遇到过这样的困扰:模型没有提供Pad Token,导致数据处理和训练过程中出现各种不便?这个问题看似简单,实则暗藏玄机。本文将…...
)
【AI问答/前端】前端满天过海局(一)
Axios感觉就像一堆ajax函数,再高深我就不懂了,Pinia可以当成是各组件之间的变量主动响应?这边改了,那边用到这个变量的也变了?跟vue插件传参不一样吧,感觉,vue还要写插槽传值(好像是这样,太久我忘了)。router这个路由我就蛋疼了,他上面的url是真变了呀,他是客户端…...