2019年认证杯SPSSPRO杯数学建模B题(第二阶段)外星语词典全过程文档及程序
2019年认证杯SPSSPRO杯数学建模
基于统计和迭代匹配的未知语言文本片段提取模型
B题 外星语词典
原题再现:
我们发现了一种未知的语言,现只知道其文字是以 20 个字母构成的。我们已经获取了许多段由该语言写成的文本,但每段文本只是由字母组成的序列,没有标点符号和空格,无法理解其规律及含义。我们希望对这种语言开展研究,有一种思路是设法在不同段文本中搜索共同出现的字母序列的片段。语言学家猜测:如果有的序列片段在每段文本中都会出现,这些片段就很可能具备某种固定的含义 (类似词汇或词根),可以以此入手进行进一步的研究。在文本的获取过程中,由于我们记录技术的限制,可能有一些位置出现了记录错误。可能的错误分为如下三种:
1. 删失错误:丢失了某个字母;
2. 插入错误:新增了原本不存在的字母;
3. 替换错误:某个字母被篡改成了其他的字母。
第二阶段问题: 现假设我们已经获取了 30 段文本,每段文本的长度都在5000–8000 个字母之间。我们希望找到的片段的长度为 15 个字母。由于技术的限制,当我们在记录每个字母时,都可能有五分之一的概率发生错误。错误类型可能为删失错误、插入错误或替换错误,每个错误只涉及一个字母,且每个错误的发生是独立的。请你设计合理的数学模型,快速而尽可能多地找到符合要求的片段,并自行编撰算例来验证算法的效果。如果我们事先不知道所寻找的片段的长度,算法又应当进行什么改进呢?
整体求解过程概述(摘要)
任何自然语言系统都可看作是表达意义的符号系统,本文提出的模型的目标是如何有效且快速地从完全未知的语言文本中提取出可能具有某个固定含义的片段,并考虑了在记录文本过程中由于技术限制出现的错误,能够最大限度提取出可能由于记录错误导致出错的片段,并分析错误的类型(替换错误、删失错误、插入错误)。
针对问题一,本文假设希望获取到的片段长度固定的为 15 个字母,从时间上和空间上都简化了复杂度。首先我们按照要求模拟了 30 段长度在 5000~8000 个字母之间且含有错误的外星文本。具体做法是先构造一个每个字母呈 Gauss 分布的片段库,每个片段长度固定为 15个字母;再根据片段库里的片段构造出 30 段正确的文本,每个片段在文中也是呈 Gauss分布;接着又根据正确的文本构造出 30 段错误的文本,其特点是每个字母有 1/5 的出错概率,并且每个错误类型出现的概率皆为 1/3。然后,本文对外星文本进行大量统计和分析,寻找到截取出的每个片段的三个属性特征,由此建立三维坐标系。具体做法是首先以窗体形式截取出所有片段,固定窗体宽度为 15;然后基于马尔可夫(Markov)模型获取片段的概率;紧接着回到外星文本统计出每个字母的频率,观察其分布;最后统计出每个片段中不同符号(字母)的个数,作为片段的第三个特征量;经过这些工作,就可以建立三维坐标系。接着,对于上一步所得到的片段三维特征量进行减法聚类(subtrative clustering method,SCM)便得出中心点的三维坐标,根据中心点的坐标确定出中心片段,即我们的目标片段。最后将取得的目标片段与片段库 1 作比对,正确率为 73.3%。最后还对模型一做了扩展,在模型一的基础上,结合汉明距离(Hamming Distance)分析出错误片段的错误类型。分析结果表明错误片段的错误类型基本可以确定。
针对问题二,本文通过改进模型一,建立了模型二,改进内容最主要有以下四个方面:第一方面,将模型一的片段库里的定长片段改为长度在 15~21 字母之间的不定长片段,其中 15~21 这一片段长度是根据第一阶段的问题而假定的,在模型二中只是用来说明模型,长度的范围可以灵活改变。第二方面是建模的难点,不定长的片段应如何截取才能得到我们所需要的片段,我们丢弃了传统的方法(传统方法是将每个长度的片段都截取一遍),而本文通过对片段进行仔细研究找到这样一个特点:从文本的同一位置出发,非最短长度(这里指长度为16、17、18、19、20、21 的片段)必定已经包含最短长度的片段(这里指长度为 15 的片段),即最短长度的片段一定是非最短长度的片段的子串,此处忽略非最短片段间的相互包含关系(如:长度为 19 的片段是长度为 21 片段的子片段)。根据这一特点,本文只选取最短片段长度作为窗体大小截取子串,再根据后面的算法找出子串的“后半段”来确定目标片段。第三方面是建模的重点,前面只截取了片段的子串,那么如何找出连接在子串后的后半段是该步骤要解决的问题。解决方法是迭代匹配搜索算法,把中心子串带回外星文本按一定的概率标准和长度限制进行“首字母位置不变,尾字母右移 1 位”匹配搜索,直至确定出目标片段。最后将取得的目标片段与片段库 1 作比对,正确率为 83.3%。第四个方面,分析错误类型时,长短不一的两个片段先使用“-”进行补位后再进行汉明距离的计算。另外本文运用 Java、Matlab 语言,用 Excel 工具做辅助,对模型和问题进行了仿真实验,验证了模型的可行性。
最后本文还对模型进行了量化评价,总体来说通过对问题一的分析基本建立起了整体模型,通过问题二对模型一进行了改进,模型二的可靠性较强,有效性适中,但模型的使用灵活性大,范围广,还可用于自然语言处理(Natural Language Processing,NLP)、机器学习(Machine Learning)等方面,是一个应用性能比较强的模型。
问题分析:
解读未知文本的过程,第一步是寻找很可能具备某种固定的含义(类似词汇或词根)的片段。这些希望被找到的片段出现频率不一,从经验的角度出发,文本的基元出现频率一般服从 Gauss 分布,为此,我们假设各片段、各字母在文本中出现的频率大致服从Gauss 分布。
针对问题一
问题一的要求是:有 30 段长度为 5000~8000 的外星文本,片段长度固定为 15,每个字母有 20%的概率发生错误,考虑有三种错误(删失错误、插入错误、替换错误),每个错误只涉及一个字母,且错误是独立发生的。要求快而尽可能多地找到符合要求的片段。正对该问题本文的基本思路是首先构造外星文本,对文本截取片段、做一些基础统计,由此建立三维坐标系,然后通过减法聚类找到目标片段,到此,我们还要根据聚类中心点以及汉明距离分析出有可能出现错误的片段和错误类型。
针对问题二
问题二的要求是:在问题一的基础上假设事先不知道所寻找的片段的长度,要如何改进模型一。本文假设片段的长度在 15–21 个字母之间(参考第一阶段的问题要求),设想在截取片段的过程中,在同一个位置往后截取长度为 15 的片段S1和截取长度为18(可以为 16、17、18、19、20、21)的片段S2,那么S2必定包含S1,换句话说,S1是S2的子串。在模型一的基础上我们改进的部分是:
(1) 建立长度不固定的片段库;
(2) 先只截取最小字串长度(15)的所有片段;
(3) 减法聚类的结果其实就是我们要找的目标片段的子串,把子串带入外星文本搜索以这个子串为字串的更长片段,根据频率确定出本来该有的片段长度。
模型假设:
在求解过程中,假设:
(1) 文本中一共由 20 个不同的符号构成,符号的形状并不是主要研究对象,这里假设是英文字母表的前 20 个字母,(a~t);
(2) 文本没有空格,没有标点符号;
(3) 未知片段出现的频率服从 Gauss 分布;
(4) 由于人类技术限制,替换和插入的字母是随机的,并且每个错误只涉及一个字母,错误是独立发生的;
(5) 每个字母发生错误的概率是 1/5;
(6) 每种错误(删失错误、插入错误、替换错误)发生的概率都是 1/3;
(7) 对于问题一,片段长度为 15;对于问题二,希望找到的片段的长度在 15–21 个字母之间(参考第一阶段的问题要求)。
论文缩略图:



全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:(代码和文档not free)
import java.io.*;
import java.util.*;
public class dictionary {
public static void getStringRandom(String s,int leng) {
File file=new File(s);
String line=null;
String chars = "abcdefghijklmnopqrst";
Double[] p
={0.3,0.6,0.6,0.7,0.75,0.8,0.85,0.9,0.9,0.95,0.95,0.95,0.9,0.85,0.8,0.75,0.7,0.6,0.4,0.3};
String val = "";//片段字符串
char c='\0';
List<String> pd = new ArrayList<String>();//片段
List<Double> pr = new ArrayList<Double>();//概率
try{
BufferedReader buf = new BufferedReader(new FileReader(file));
while((line = buf.readLine())!=null){
for(int i = 0; i < leng; i++) {
int m = (int)(Math.random() * 20);
if (mingZhong(p[m])) {
c=chars.charAt(m);
}
val +=c;
}
pd.add(val);//片段
pr.add(Double.parseDouble(line)); //概率
val="";
if(pd.size()>=50){
break;
}
if(pd.size()>=50){
break;
}
}
buf.close();
for (int m=0;m<pr.size() ;m++ ) {
System.out.println(pd.get(m)+":"+pr.get(m));
}
StringBuilder sb = new StringBuilder();
File file_result = new File("AlienLang.txt");
PrintWriter output = new PrintWriter(file_result);//创建写对象
Random rand = new Random();
for (int k=0;k<30 ;k++ ) {
int zishu = rand.nextInt(3001)+5000;//生成 5000-8000 之间的随
机数,包括 8000
while (true) {
int ra = (int)(Math.random()*50);
if (mingZhong(pr.get(ra))) {
sb.append(pd.get(ra));
}
if (sb.length()>=(zishu-15) && sb.length()<=(zishu+15)) {
output.println(sb.toString());
sb.delete( 0, sb.length() );
break;
}
}
}
output.close();System.out.println("结束");
}catch(Exception e){
e.printStackTrace();
}
}
public static boolean mingZhong(double hr) {
Random r = new Random();
int a = r.nextInt(100);//随机产生[0,100)的整数,每个数字出现的概率为
1%
if(a<(int) (hr*100)){ //前 hr*100 个数字的区间,代表的几率
return true;
}else{
return false;
}
}
public static void main(String[] args) {
getStringRandom("pro.txt",15);
}
}
import java.io.*;
import java.util.*;
class ErrorText{
public static void main(String[] args) throws Exception{
File file_source = new File("AlienLang.txt");
File file_result = new File("AlienLang_err.txt");
InputStreamReader is = new InputStreamReader(new
FileInputStream(file_source));//将输入的字节流转换成字符流
BufferedReader br=new BufferedReader(is);//将字符流添加到缓冲流PrintWriter output = new PrintWriter(file_result);//创建写对象
String str=null;
String chars = "abcdefghijklmnopqrst";
try{
while ((str = br.readLine()) != null){
StringBuilder sb = new StringBuilder(str);
for (int i=0;i<sb.length() ;i++ ) {
if (mingZhong(0.2)) {
if (err_type()==1) {//插入
int ra2 = (int)(Math.random()*20);
String ch=String.valueOf(chars.charAt(ra2));
sb.replace(i,i+1,String.valueOf(str.charAt(i))+ch);//sb.append(str.charAt(i)+ch);
i++;//下一个字母
}else if (err_type()==2) {//替换
String ch=null;
while (true) {//不能替换成同一个字母。例如 b 不能
替换成 b
int ra2 = (int)(Math.random()*20);
ch=String.valueOf(chars.charAt(ra2));
if (!ch.equals(String.valueOf(str.charAt(i)))) {
break;
}
}
sb.replace(i,i+1,ch);//sb.append(ch);
}else {//缺失
sb.delete(i,i+1);//不包含 i+1
i--;
}
}
}
output.println(sb.toString());
}
}catch(FileNotFoundException e){
e.printStackTrace();
}br.close();
output.close();System.out.println("结束");
}
public static boolean mingZhong(double hr) {
Random r = new Random();
int a = r.nextInt(100);//随机产生[0,100)的整数,每个数字出现的概率为
1%
if(a<(int) (hr*100)){ //前 hr*100 个数字的区间,代表的几率
return true;
}else{
return false;
}
}
public static int err_type() {
Random r = new Random();
int flag;
int a = r.nextInt(100);//随机产生[0,100)的整数,每个数字出现的概率为
1%
if(a<33){
flag = 1;
}else if(a<66){
flag = 2;
}else {
flag = 3;
}
return flag;
}
}
全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2019年认证杯SPSSPRO杯数学建模B题(第二阶段)外星语词典全过程文档及程序
2019年认证杯SPSSPRO杯数学建模 基于统计和迭代匹配的未知语言文本片段提取模型 B题 外星语词典 原题再现: 我们发现了一种未知的语言,现只知道其文字是以 20 个字母构成的。我们已经获取了许多段由该语言写成的文本,但每段文本只是由字母…...
NFS的共享与挂载
一、NFS网络文件服务 1.1简介 NFS(Network File System 网络文件服务) 文件系统(软件)文件的权限 NFS 是一种基于 TCP/IP 传输的网络文件系统协议,最初由 Sun 公司开发。 通过使用 NFS 协议,客户机可以像访…...
函数式编程的Java编码实践:利用惰性写出高性能且抽象的代码
转载链接 本文会以惰性加载为例一步步介绍函数式编程中各种概念,所以读者不需要任何函数式编程的基础,只需要对 Java 8 有些许了解即可。 一 抽象一定会导致代码性能降低? 程序员的梦想就是能写出 “高内聚,低耦合”的代码&…...
2024年甘肃省职业院校技能大赛信息安全管理与评估 样题二 模块二
竞赛需要完成三个阶段的任务,分别完成三个模块,总分共计 1000分。三个模块内容和分值分别是: 1.第一阶段:模块一 网络平台搭建与设备安全防护(180 分钟,300 分)。 2.第二阶段:模块二…...

mysql 一对多 合并多个通过 逗号拼接展示
mysql 一对多 合并多个通过 逗号拼接展示 以上内容由chatgpt中文网 动态生成 SELECTuser_id,project_id,GROUP_CONCAT(project_specs_id) AS merged_specs_ids FROMzt_medication_specs_total WHEREspecs_num_total < 5 GROUP BYuser_id, project_id;laravel model 对应写…...
Java零基础教学文档第五篇:jQuery
今日新篇章 【jQuery】 【主要内容】 jQuery简介 jQuery安装 jQuery语法 jQuery选择器 jQuery事件处理 jQueryDOM操作 jQuery元素遍历 jQuery过滤 jQuery其它方法 【学习目标】 1.jQuery简介 1.1 jQuery简介 jQuery 库可以通过一行简单的标记被添加到网页中。 1.…...

samba
samba 文章目录 samba1. samba简介2. samba访问3. 示例 1. samba简介 Samba是在Linux和UNIX系统上实现SMB协议的一个免费软件,由服务器及客户端程序构成。 在此之前我们已经了解了NFS,NFS与samba一样,也是在网络中实现文件共享的一种实现&a…...

「云渲染科普」3dmax vray动画渲染参数如何设置
动画渲染一直都是占用时间最多的地方,动画帧数通常 1 秒在 25 帧或者以上,电脑通常需要对每一帧的画面分批渲染,通常本地电脑由于配置上的限制,往往无法在短时间内快速的完成渲染任务。这时“云渲染”则成为了动画渲染的主要方案&…...

【GCC】6 接收端实现:周期构造RTCP反馈包
基于m98代码。GCC涉及的代码,可能位于:webrtc/modules/remote_bitrate_estimator webrtc/modules/congestion_controller webrtc/modules/rtp_rtcp/source/rtcp_packet/transport_feedback.cc webrtc 之 RemoteEstimatorProxy 对 remote_bitrate_estimator 的 RemoteEstimato…...

【RTOS】快速体验FreeRTOS所有常用API(6)事件组
目录 六、事件组6.1 基本概念6.2 创建6.3 设置事件6.4 等待事件6.5 实例 六、事件组 该部分在上份代码基础上修改得来,代码下载链接: https://wwzr.lanzout.com/iihn01la39je 密码:dtr0 该代码尽量做到最简,不添加多余的、不规范的代码。 内容…...

Springboot开发的大学生寝室考勤系统刷脸进出宿舍系统论文
摘要 近年来随着社会科学技术的全面进步及高等教育的普及,以计算机与通信技术为基础的信息系统正处于蓬勃发展的时期,学生作为预备的高新技术人才数量也在急剧上升,随之而来的就是高校管理上的一系列问题,首当其冲的便是高校应对…...

2024年美赛数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...
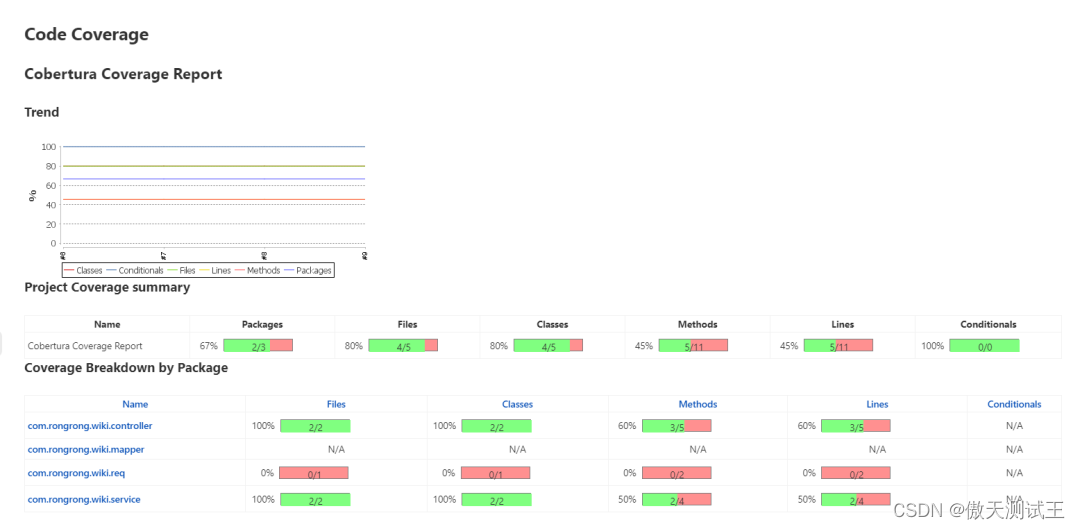
测试覆盖率 之 Cobertura的使用
什么是代码覆盖率? 代码覆盖率是对整个测试过程中被执行的代码的衡量,它能测量源代码中的哪些语句在测试中被执行,哪些语句尚未被执行。 为什么要测量代码覆盖率? 众所周知,测试可以提高软件版本的质量和可预测性。…...

vue表格插件vxe-table导出 excel
vxe-table 默认支持导出 CSV、HTML、XML、TXT格式的文件,不支持 xlsx 文件 要想导出 xlsx 文件,需要使用 vxe-table-plugin-export-xlsx 依赖 参考:https://cnpmjs.org/package/vxe-table-plugin-export-xlsx/v/2.1.0-beta 1.安装 npm inst…...
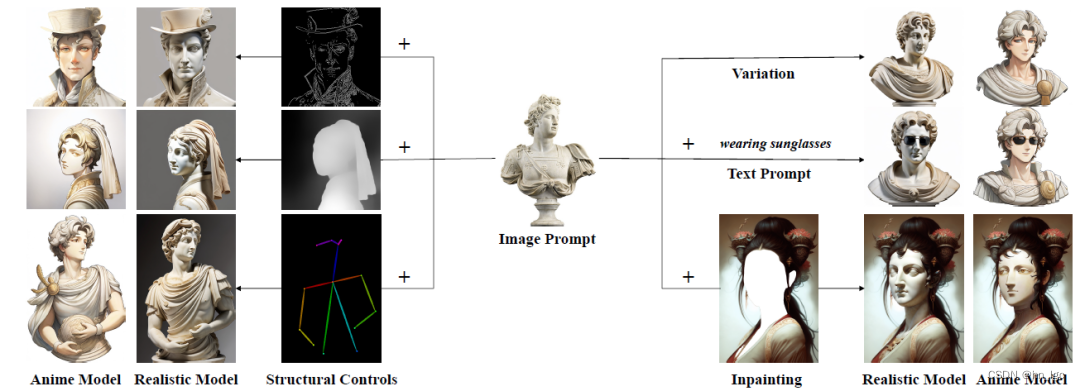
stable diffusion使用相关
IP Adapter,我愿称之它为SD垫图 IP Adapter是腾讯lab发布的一个新的Stable Diffusion适配器,它的作用是将你输入的图像作为图像提示词,本质上就像MJ的垫图。 IP Adapter比reference的效果要好,而且会快很多,适配于各种…...
)
Center项目创建——数据初始化(Linux/Windows版本)
本博客主要讲述Center的模块安装配置和数据初始化 1、定义安装Install函数,IP地址由makefile自动传入,也就是用户自动传入 bool Install(std::string ip); 2、编写Install函数 #define CENTER_CONF "ip bool XCenter::Install(std::string ip)…...

保送阿里云的云原生学习路线
近期好多人都有咨询学习云原生有什么资料。与其说提供资料不如先说一说应该如何学习云原生。 Linux基础知识:云原生技术通常在Linux环境中运行,因此建议首先掌握Linux的基础知识,包括命令行操作、文件系统、权限管理等。 容器化技术&#x…...

【昕宝爸爸小模块】深入浅出之JDK21 中的虚拟线程到底是怎么回事(二)
➡️博客首页 https://blog.csdn.net/Java_Yangxiaoyuan 欢迎优秀的你👍点赞、🗂️收藏、加❤️关注哦。 本文章CSDN首发,欢迎转载,要注明出处哦! 先感谢优秀的你能认真的看完本文&…...
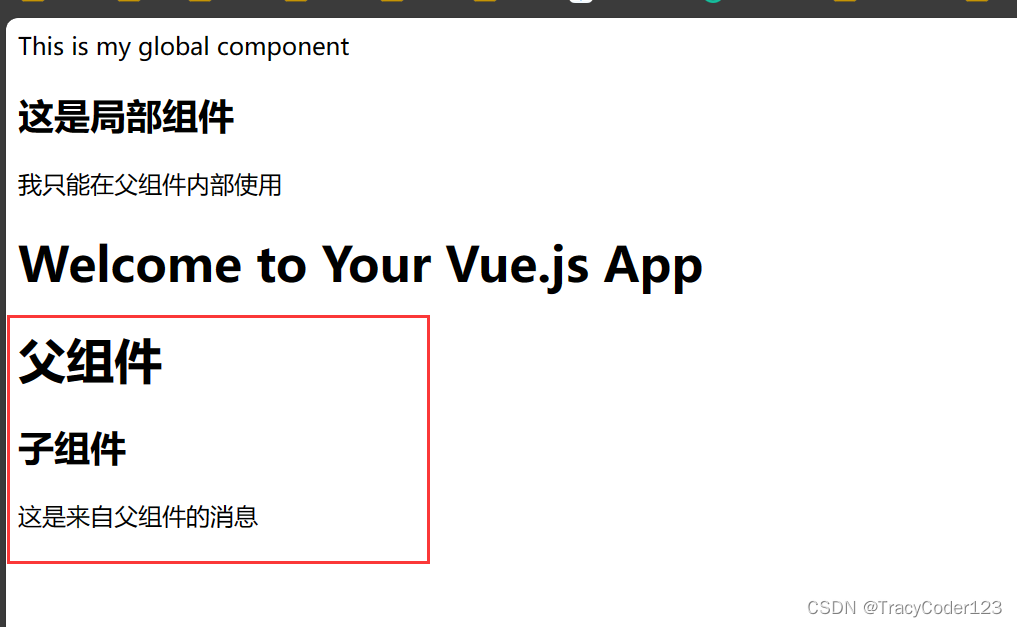
两周掌握Vue3(三):全局组件、局部组件、Props
文章目录 一、全局组件1.创建全局组件2.在main.js中注册全局组件3.使用全局组件 二、局部组件1.创建局部组件2.在另一个组件中注册、使用局部组件 三、Props1.定义一个子组件2.定义一个父组件3.效果 代码仓库:跳转 本博客对应分支:03 一、全局组件 Vue…...

Web前端篇——element-plus组件设置全局中文
背景:在使用el-date-picker组件时,发现组件中的文字默认都是英文。 设置全局中文的方法如下:(本文只介绍CDN方式) <script src"//unpkg.com/element-plus/dist/locale/zh-cn"></script> <s…...

别再折腾LibreOffice了!CentOS 7.9上老牌Apache OpenOffice 4.1.14的完整部署与避坑指南
企业级文档服务选型:Apache OpenOffice 4.1.14在CentOS 7.9的深度实践当我们需要在Linux服务器上搭建文档处理服务时,开源办公套件的选择往往令人纠结。Apache OpenOffice作为历经20年发展的老牌解决方案,在企业级环境中仍有一席之地。本文将…...

ContextMenuManager:重新定义Windows右键菜单的交互设计思维
ContextMenuManager:重新定义Windows右键菜单的交互设计思维 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 在数字工作流中,我们每天平均…...

Unity2022工业级数字孪生基座:OPC UA+Win11原生适配变电站系统
1. 这不是“换个贴图”的Demo,而是一套可交付的工业级数字孪生基座 你有没有遇到过这样的情况:客户在会议室白板上画了个变电站草图,说“我们要一个数字孪生系统”,然后技术团队翻出Unity Asset Store里买来的几个变压器模型&…...

[智能体-30]:curl、requests、Ollama、Ollama API、OpenAI API各种的作用和他们之间的关系
五者作用 层级关系极简梳理一、各自定义与作用curl 命令行 HTTP 请求工具,终端发请求、调试接口、测试连通性。requests Python 代码 HTTP 请求库,代码层面收发网络数据。OpenAI API云端官方大模型接口标准,规定请求格式、字段、交互协议。O…...

基于拓扑数据分析的脑电信号特征提取与癫痫样放电检测
1. 项目概述:从高维脑电信号到可解释的拓扑特征在神经科学和临床神经病学领域,脑电图(EEG)分析一直是诊断癫痫等神经系统疾病的核心手段。其中,发作间期癫痫样放电(Interictal Epileptic Discharges, IEDs&…...

昇腾CANN opbase 算子注册与分发调度:从 API 到 AI Core 的路径追踪
所有 CANN 算子都依赖 opbase——它不是写具体算子的地方,而是算子的"注册中心 调度器"。用户调用 torch.nn.functional.softmax(x) → PyTorch 转发到 CANN → CANN 查 opbase 的算子注册表 → 找到对应的 Ascend C kernel → 加载到 AI Core → 执行。…...

The Front 末日生存战争游戏专属服务器搭建教程
The Front 末日生存战争游戏专属服务器搭建教程 《The Front》(前线)是一款以末日废土为背景的多人生存建造游戏,玩家在充满战争气息的废土世界中采集资源、建造据点、研发科技、与其他玩家或 NPC 势力展开激烈对抗。自建专属服务器可以让你…...

神经网络辅助可变形匹配滤波器在光通信中的应用
1. 神经网络辅助可变形匹配滤波器技术解析在光通信系统中,匹配滤波器作为信号检测的关键组件,其性能直接影响整个通信链路的可靠性。传统固定匹配滤波器基于理想信道假设设计,当面对实际系统中的带宽限制、大气湍流等复杂信道条件时ÿ…...
)
【2024播客降本增效终极方案】:单人团队如何用开源TTS实现月产60期高保真节目(附实测MOS分对比表)
更多请点击: https://codechina.net 第一章:AI语音合成在播客制作中的应用 AI语音合成技术正深刻重塑播客内容的生产流程,从脚本转语音、多角色配音到个性化音色定制,已实现端到端自动化与高质量听感的统一。相比传统录音方式&am…...

从零入门 OpenAI Codex|登录、权限、终端、记忆配置全实操
我先来简单介绍一下Codex。 Codex是 OpenAI 推出的 AI 编程模型与工具系列。Codex 最初于 2021 年作为 OpenAI API 的一部分发布,基于 GPT 架构专门针对代码数据进行了训练。2024 至 2025 年间,OpenAI 推出了独立的 Codex CLI命令行工具,使其…...