解析Transformer模型
原文地址:https://zhanghan.xyz/posts/17281/
进入Transformer
RNN很难处理冗长的文本序列,且很容易受到所谓梯度消失/爆炸的问题。RNN是按顺序处理单词的,所以很难并行化。
用一句话总结Transformer:当一个扩展性极佳的模型和一个巨大的数据集邂逅,结果可能会让你大吃一惊。
Transformer是如何工作的?
1.位置编码(Positional Encodings)
RNN中按照顺序处理单词,很难并行化。
位置编码的思路:将输入序列中的所有单词后面加上一个数字,表明它的顺序。
[("Dala",1),("say",1),("hello",1),("world",1)]
原文中使用正弦函数进行位置编码
要点:将语序存储作为数据,而不是靠网络结构,这样你的神经网络就更容易训练了。
2.注意力机制(Attention)
注意力是一种机制,它允许文本模型在决定如何翻译输出句子中的单词时“查看”原始句子中的每个单词。
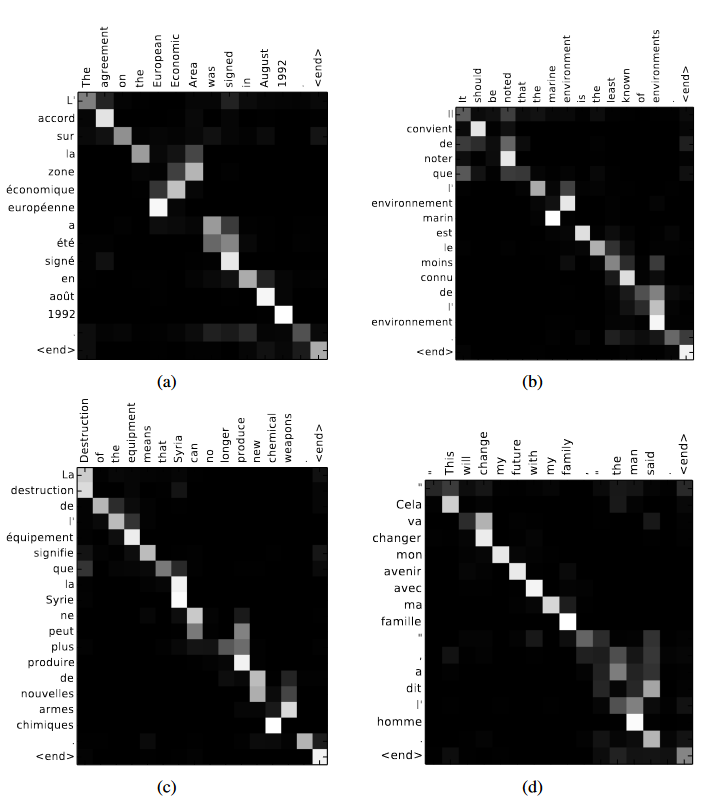
图源:[1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate (arxiv.org)
模型如何知道在每个时间步长中应该注意哪些单词:就是从训练数据中学到的东西,通过观察成千上万的法语和英语句子,学会了什么类型的单词是相互依赖的。
3.自注意力机制(Self-Attention)
如何不是试图翻译单词,而是建立一个理解语言中的基本含义和模式的模型——一种可以用来做任何数量的语言任务的模型,怎么办?
自注意力帮助神经网络消除单词歧义,做词性标注,命名实体识别,学习语义角色等等。
以上仅为读【解析 Transformer 模型:理解 GPT-3、BERT 和 T5 背后的模型】
的笔记,以下是我对Transformer进行的详细理解和技术解析。
Transformer技术解析
1.位置编码Positional Encoding
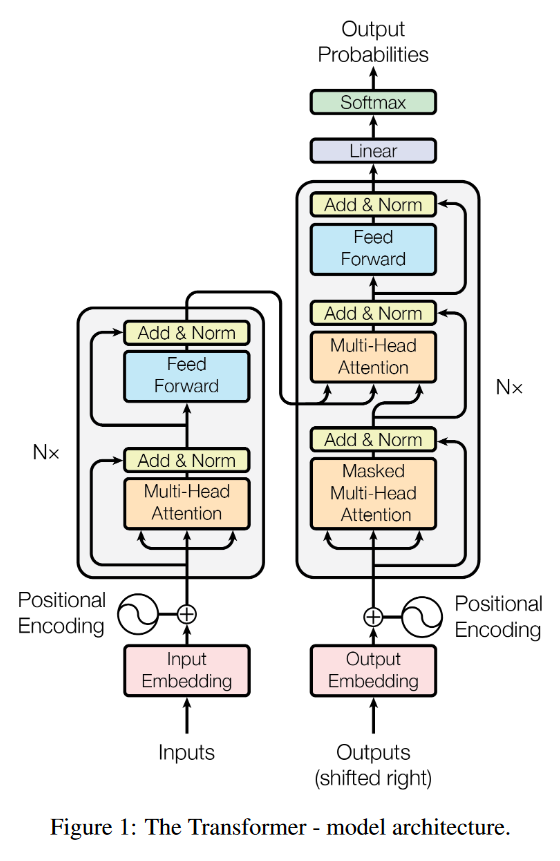
从上面的整体框架图可以看出,Transformer中的Encoder和Decoder都是通过堆叠多头自注意力和全连接层得到的,不管是Encoder还是Decoder的输入,都进行了Positional Encoding,对于位置编码的作用,在原文是这样解释的:
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add “positional encodings” to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed
由于我们的模型不包含递归和卷积,为了使模型能够利用序列的顺序,我们必须在序列中注入一些关于token的相对或绝对位置的信息。为此,我们在编码器和解码器堆栈底部的输入嵌入中加入位置编码。位置编码与embeddings具有相同的维数d,因此可以将两者求和。位置编码有多种选择,有学习的,也有固定的。
Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
理想状态下,编码方式应该要满足以下几个条件,
- 对于每个位置的词语,它都能提供一个独一无二的编码
- 词语之间的间隔对于不同长度的句子来说,含义应该是一致的
- 能够随意延伸到任意长度的句子
以下是Transformer中使用的位置编码的公式:

PE将正弦函数用于偶数嵌入索引i,余弦函数用于奇数嵌入索引i。
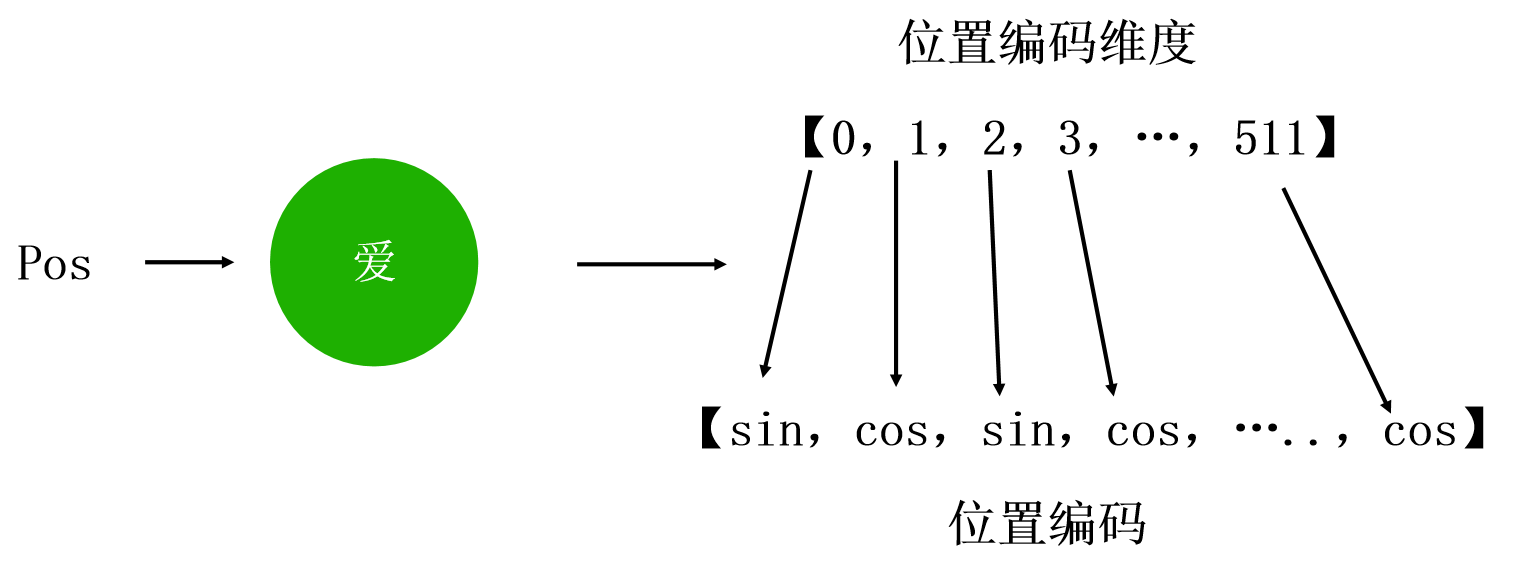
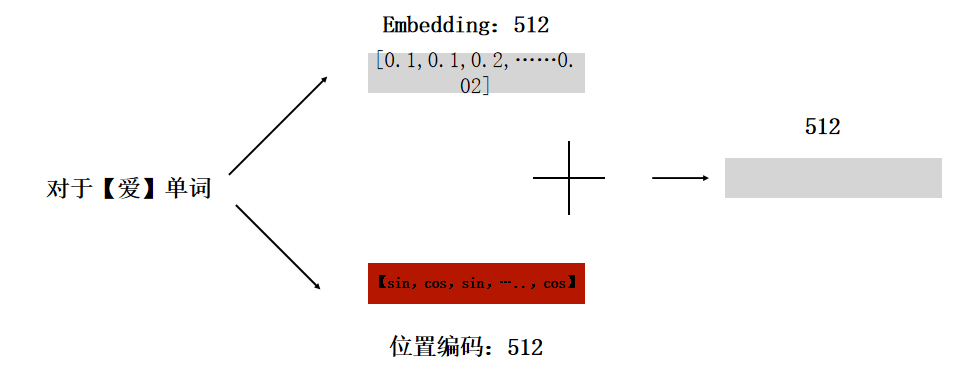
代码实现:
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__() # 初始化位置编码矩阵 pe = torch.zeros(max_len, d_model)# 计算位置编码position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)# 将位置编码矩阵转换为张量pe = pe.unsqueeze(0).transpose(0, 1)#pe.requires_grad = Falseself.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(0), :]
这里再引申一下为什么位置嵌入会有用:

得出一个结论: P E p o s + k PE~pos+k~ PE pos+k 可以被 P E p o s PE~pos~ PE pos 线性表示。从这一点来说,位置编码是可以反应一定的相对位置信息。
但是这种相对位置信息会在注意力机制那里消失。
2.多头注意力机制
为什么Transformer 需要进行 Multi-head Attention?
最终的原因可以通过两句话来概括:
①为了解决模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身位置的问题;
②一定程度上ℎ越大整个模型的表达能力越强,越能提高模型对于注意力权重的合理分配。
self-Attention自注意力机制
所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。最终,Transformer架构就是基于这种的自注意力机制而构建的Encoder-Decoder模型。
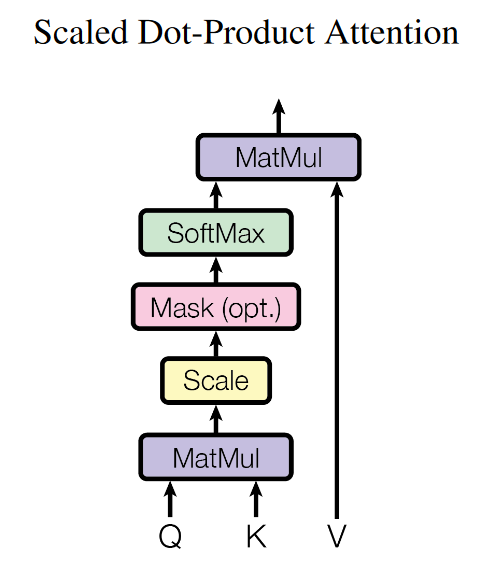
从上图可以看出,自注意力机制的核心过程就是通过Q和K计算得到注意力权重;然后再作用于V得到整个权重和输出。具体的,对于输入Q、K和V来说,其输出向量的计算公式为:
q i = W q ⋅ a i k i = W k ⋅ a i v i = W v ⋅ a i α i , j = q i ⋅ k j A = softmax ( Q K T d k ) Attention ( Q , K , V ) = A V \\\begin{align*}q^{i} &= W^{q} \cdot a^{i} \\k^{i} &= W^{k} \cdot a^{i} \\v^{i} &= W^{v} \cdot a^{i} \\\alpha_{i,j} &= q^{i} \cdot k^{j} \\A &= \text{softmax}\left(\frac{QK^{T}}{\sqrt{d_k}}\right) \\\text{Attention}(Q, K, V) &= AV\\\end{align*} qikiviαi,jAAttention(Q,K,V)=Wq⋅ai=Wk⋅ai=Wv⋅ai=qi⋅kj=softmax(dkQKT)=AV
- 首先,对于输入序列中的每个元素,我们计算查询向量(Query)、键向量(Key)和值向量(Value),其中,Wq、Wk和Wv是需要学习的参数矩阵,ai是输入序列的第i个元素。
- 然后,我们利用查询向量和键向量来计算注意力得分(Attention Score),这里,αi,j表示第i个元素和第j个元素之间的注意力得分。
- 接着,我们对注意力得分进行缩放处理并应用softmax函数,以得到注意力权重。其中,Q和K分别是所有查询向量和键向量构成的矩阵,dk是键向量的维度。
- 最后,我们利用注意力权重和值向量来计算自注意力机制的输出。其中,V是所有值向量构成的矩阵,A是注意力权重矩阵。
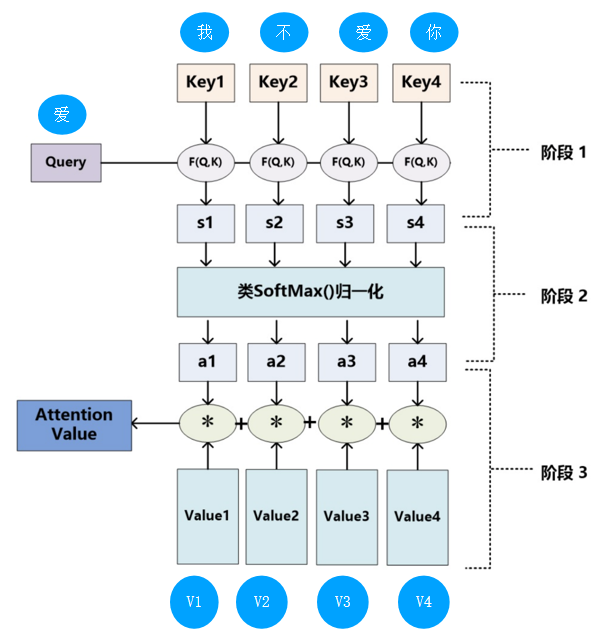
通过这种自注意力机制的方式确实解决了“传统序列模型在编码过程中都需顺序进行的弊端”的问题,有了自注意力机制后,仅仅只需要对原始输入进行几次矩阵变换便能够得到最终包含有不同位置注意力信息的编码向量。
MultiHeadAttention
模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,因此提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
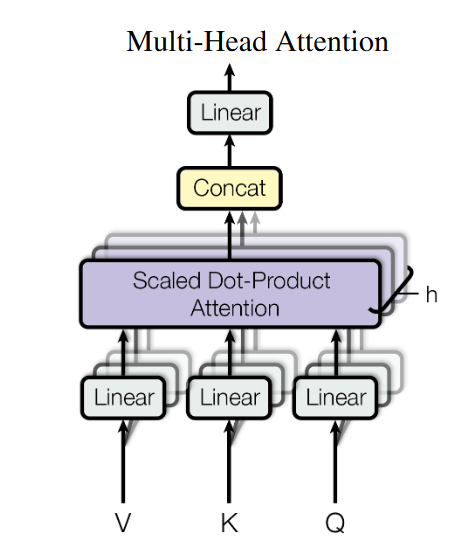
所谓的多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理过程;然后再将每一组自注意力的结果拼接起来进行一次线性变换得到最终的输出结果。
Q i = W i Q ⋅ X K i = W i K ⋅ X V i = W i V ⋅ X α i , j = Q i ⋅ K j d k A i = softmax ( α i , j ) head i = A i ⋅ V i MultiHead ( Q , K , V ) = Concat ( head 1 , . . . , head H ) ⋅ W O \begin{align*}Q_i &= W_i^Q \cdot X \\K_i &= W_i^K \cdot X \\V_i &= W_i^V \cdot X \\\alpha_{i,j} &= \frac{Q_i \cdot K_j}{\sqrt{d_k}} \\A_i &= \text{softmax}(\alpha_{i,j}) \\\text{head}_i &= A_i \cdot V_i \\\text{MultiHead}(Q, K, V) &= \text{Concat}(\text{head}_1, ..., \text{head}_H) \cdot W^O\end{align*} QiKiViαi,jAiheadiMultiHead(Q,K,V)=WiQ⋅X=WiK⋅X=WiV⋅X=dkQi⋅Kj=softmax(αi,j)=Ai⋅Vi=Concat(head1,...,headH)⋅WO
为什么要使用多头
根据下图多头注意力计算方式我们可以发现,在dm固定的情况下,不管是使用单头还是多头的方式,在实际的处理过程中直到进行注意力权重矩阵计算前,两者之前没有任何区别。当进行进行注意力权重矩阵计算时,ℎ越大那么Q,K,V就会被切分得越小,进而得到的注意力权重分配方式越多。图源:
This post is all you need(上卷)——层层剥开Transformer
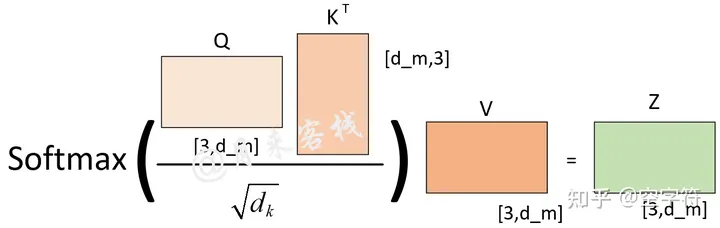



从上图可以看出,如果ℎ=1,那么最终可能得到的就是一个各个位置只集中于自身位置的注意力权重矩阵;如果ℎ=2,那么就还可能得到另外一个注意力权重稍微分配合理的权重矩阵;ℎ=3同理如此。因而多头这一做法也恰好是论文作者提出用于克服模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置的问题。这里再插入一张真实场景下同一层的不同注意力权重矩阵可视化结果图:

同时,当ℎ不一样时,dk的取值也不一样,进而使得对权重矩阵的scale的程度不一样。例如,如果dm=768,那么当ℎ=12时,则dk=64;当ℎ=1时,则dk=768。
所以,当模型的维度dm确定时,一定程度上ℎ越大整个模型的表达能力越强,越能提高模型对于注意力权重的合理分配。
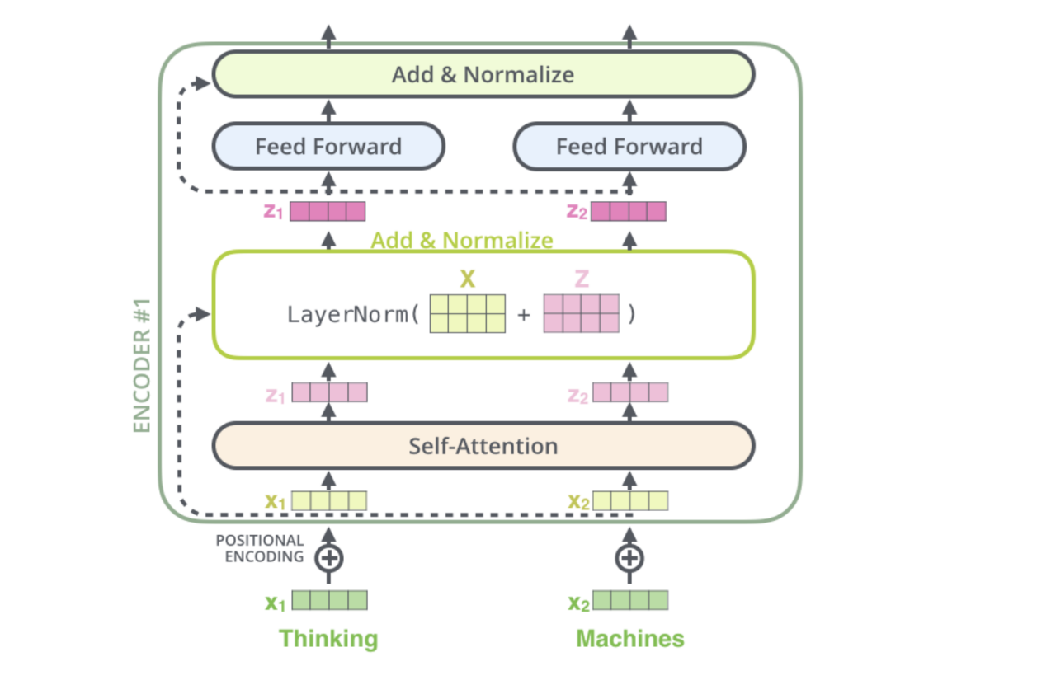
3.Encoder层
对于Encoder部分来说其内部主要由两部分网络所构成:多头注意力机制和两层前馈神经网络。同时,对于这两部分网络来说,都加入了残差连接,并且在残差连接后还进行了层归一化操作。这样,对于每个部分来说其输出均为LayerNorm(x+Sublayer(x)),并且在都加入了Dropout操作。对于第2部分的两层全连接网络来说,其具体计算过程为:
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0, xW1 + b1)W2 + b2 FFN(x)=max(0,xW1+b1)W2+b2
4.Decoder层
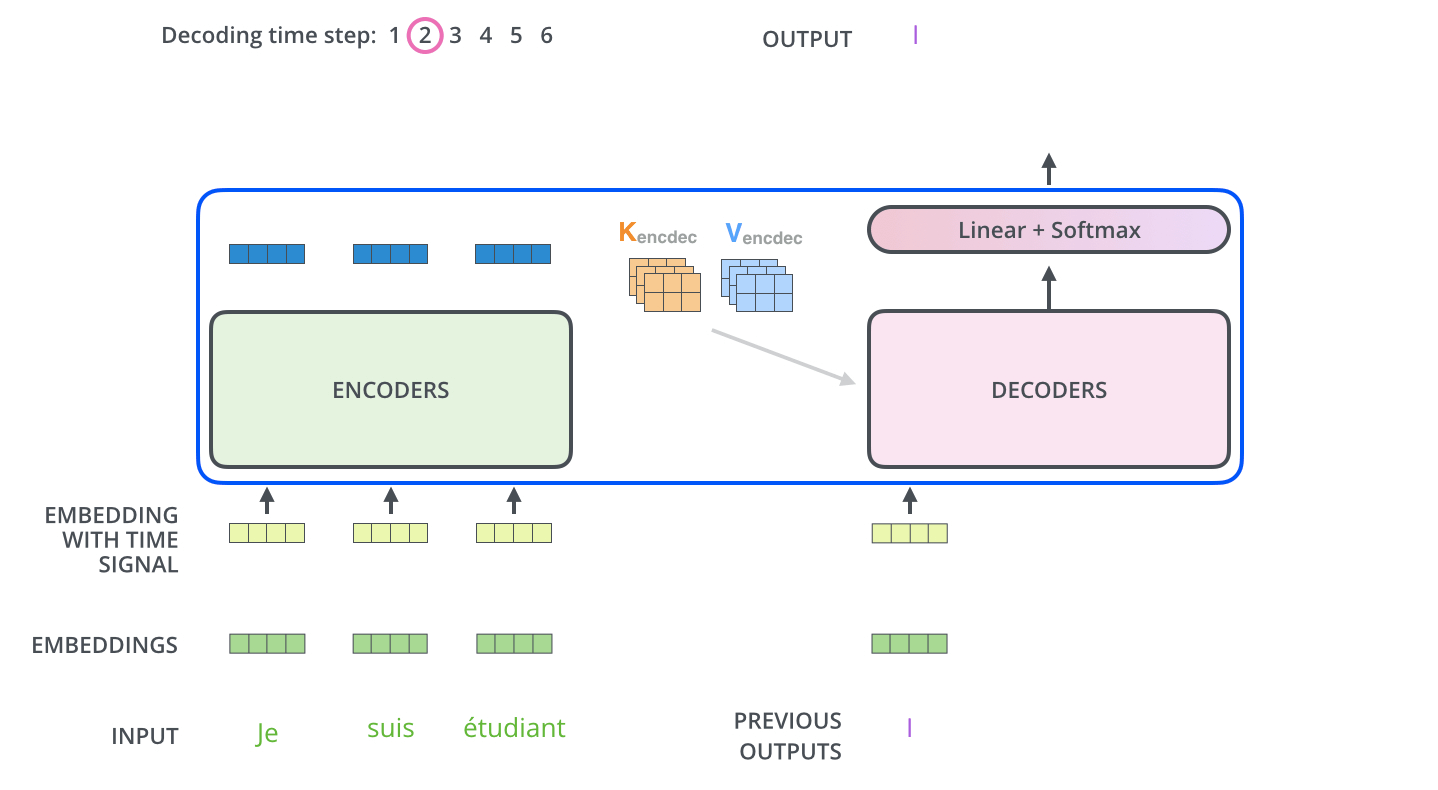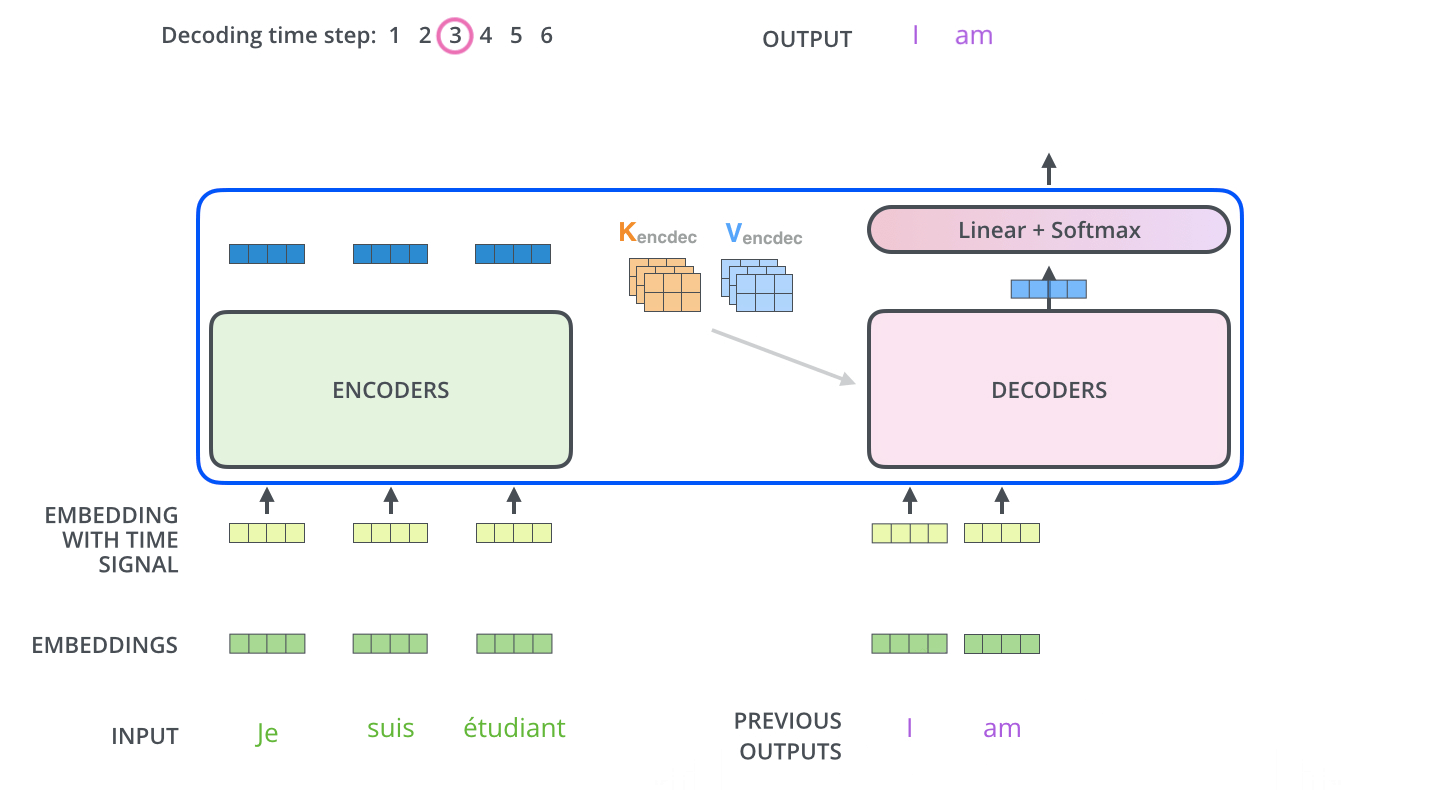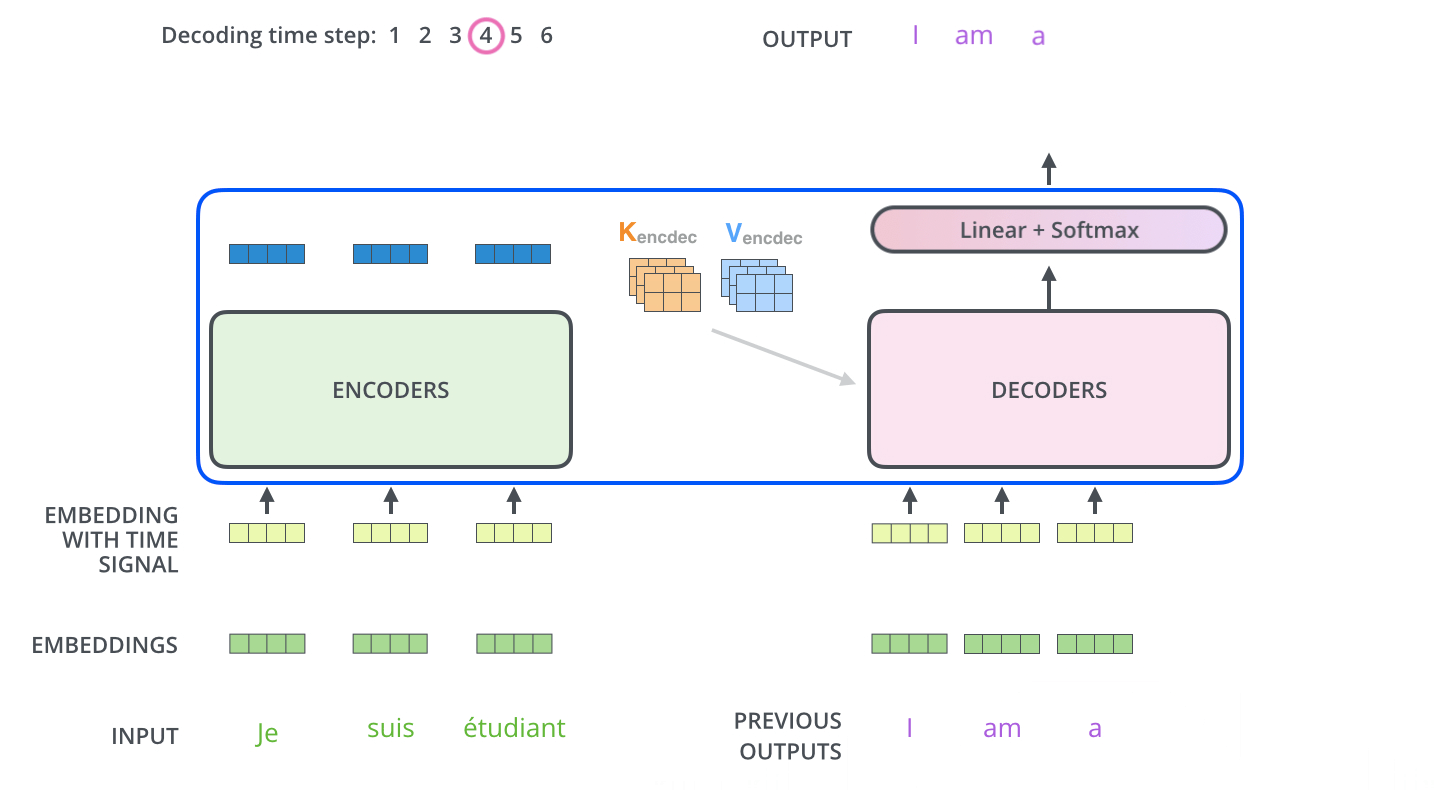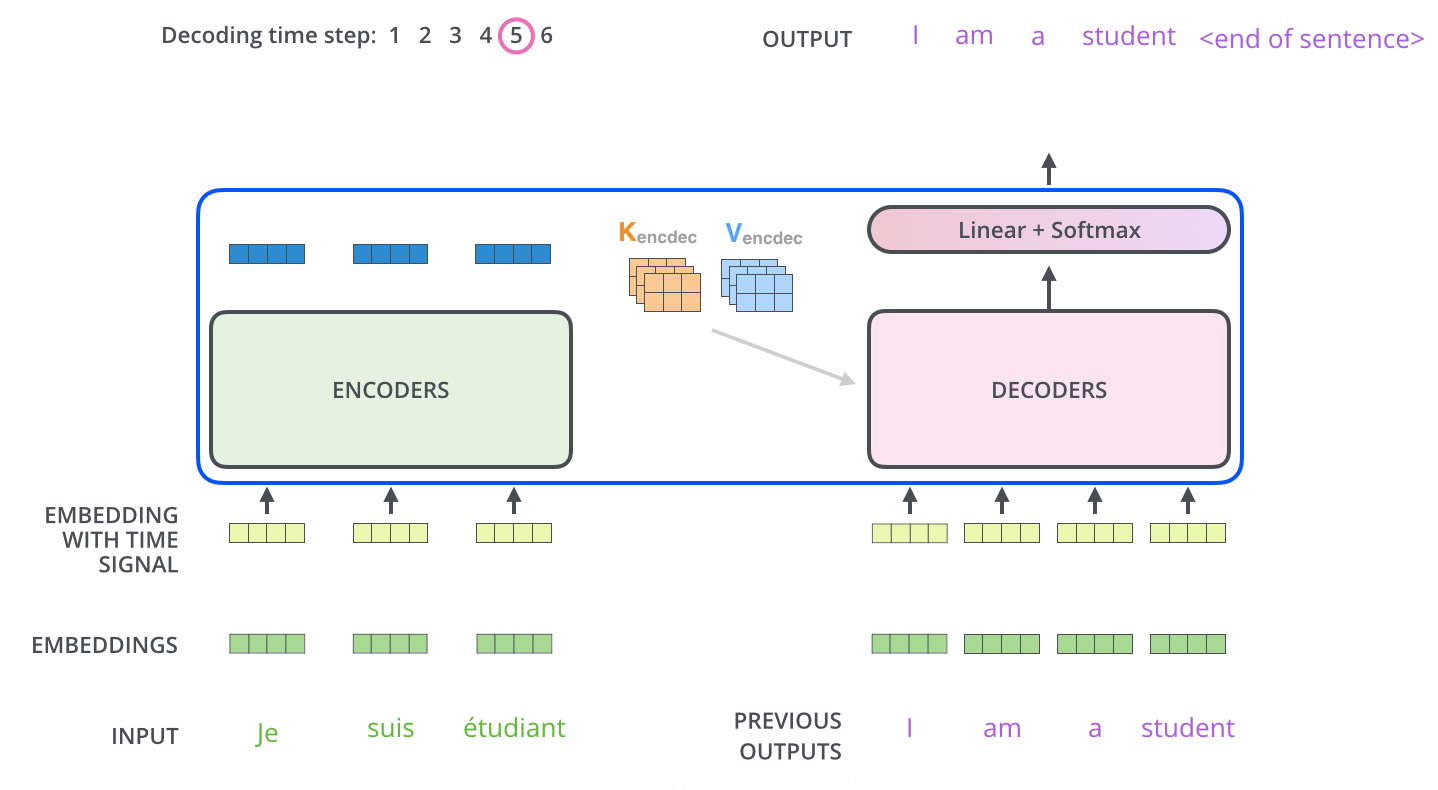
对于Decoder部分来说,其整体上与Encoder类似,只是多了一个用于与Encoder输出进行交互的多头注意力机制。

不同于Encoder部分,在Decoder中一共包含有3个部分的网络结构。最上面的和最下面的部分(暂时忽略Mask)与Encoder相同,只是多了中间这个与Encoder输出(Memory)进行交互的部分,作者称之为“Encoder-Decoder attention”。对于这部分的输入,Q来自于下面多头注意力机制的输出,K和V均是Encoder部分的输出(Memory)经过线性变换后得到。
在Decoder对每一个时刻进行解码时,首先需要做的便是通过Q与 K进行交互(query查询),并计算得到注意力权重矩阵;然后再通过注意力权重与V进行计算得到一个权重向量,该权重向量所表示的含义就是在解码时如何将注意力分配到Memory的各个位置上。
Decoder解码预测过程

Decoder训练解码过程
在介绍完预测时Decoder的解码过程后,下面就继续来看在网络在训练过程中是如何进行解码的。在真实预测时解码器需要将上一个时刻的输出作为下一个时刻解码的输入,然后一个时刻一个时刻的进行解码操作。显然,如果训练时也采用同样的方法那将是十分费时的。因此,在训练过程中,解码器也同编码器一样,一次接收解码时所有时刻的输入进行计算。这样做的好处,一是通过多样本并行计算能够加快网络的训练速度;二是在训练过程中直接喂入解码器正确的结果而不是上一时刻的预测值(因为训练时上一时刻的预测值可能是错误的)能够更好的训练网络。
例如在用平行预料"我 是 谁"<==>"who am i"对网络进行训练时,编码器的输入便是"我 是 谁",而解码器的输入则是"<s> who am i",对应的正确标签则是"who am i <e>"
但是,模型在实际的预测过程中只是将当前时刻之前(包括当前时刻)的所有时刻作为输入来预测下一个时刻,也就是说模型在预测时是看不到当前时刻之后的信息。因此,Transformer中的Decoder通过加入注意力掩码机制来解决了这一问题。
左边依旧是通过Q和K计算得到了注意力权重矩阵(此时还未进行softmax操作),而中间的就是所谓的注意力掩码矩阵,两者在相加之后再乘上矩阵V便得到了整个自注意力机制的输出。

5.残差和LayerNorm
残差
在Transformer中,数据过Attention层和FFN层后,都会经过一个Add & Norm处理。其中,Add为residule block(残差模块),数据在这里进行residule connection(残差连接)。
在transformer的encoder和decoder中,各用到了6层的attention模块,每一个attention模块又和一个FeedForward层(简称FFN)相接。对每一层的attention和FFN,都采用了一次残差连接,即把每一个位置的输入数据和输出数据相加,使得Transformer能够有效训练更深的网络。在残差连接过后,再采取Layer Nomalization的方式。具体的操作过程见下图:
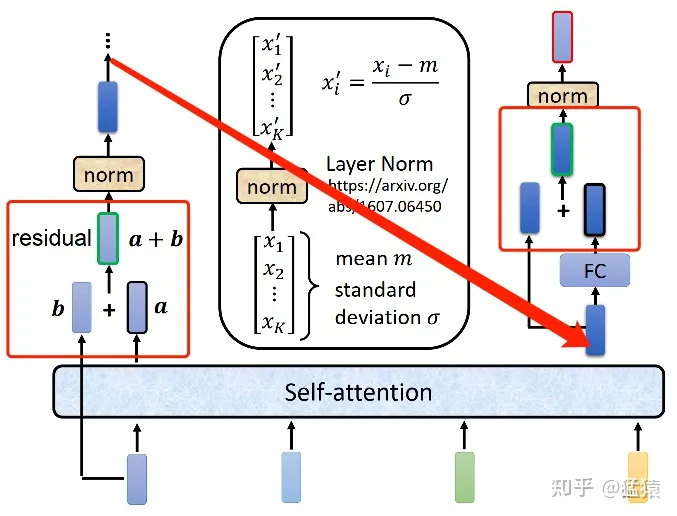
LayerNorm
为什么在NLP任务中(Transformer),使用LayerNorm而不是BatchNorm。
首先,BN不适合RNN这种动态文本模型,有一个原因是因为batch中的长度不一致,导致有的靠后的特征的均值和方差不能估算。
但是这个问题不是大问题,可以在处理数据的适合,使句子的长度相近的在一个batch,所以这不是NLP中不用BN的核心原因。
BN是对每个特征的batch_size上求得均值和方差,就是对每个特征,这些特征都有明确得含义,比如身高、体重等。但是想象以下,如果BN应用到NLP任务,就变成了对每个单词,也就是默认了在同一个位置得单词对应的是同一个特征,比如:“我/期待/全新/AGI”和“今天/天气/真/不错“,使用BN代表着”我“和”今天“是对应同一个维度的特征,才能做BN。
LayNorm做的事针对每一个样本,做特征的缩放。也就是,它认为“我/期待/全新/AGI”这四个词在同一个特征下,基于此做归一化。这样做和BN的区别在于,一句话中的每个单词都可以归到这句话的”语义信息“这个特征中。所以这里不再对应batch_size,而是文本长度。
引申-为什么BN在CNN中可以而在NLP中不行
浅浅理解:BN在NLP中是对词向量进行缩放,词向量是我们学习出来的参数来表示词语语义的参数,不是真实存在的。而图像像素是真实存在的,像素中包含固有的信息。
6.问题解析
Transformer的并行化
Decoder不用多说,没有并行,只能一个一个解码,很类似于RNN,这个时刻的输入依赖于上一个时刻的输出。
Encoder:首先,6个大的模块之间是串行的,一个模块的计算结果作为下一个模块的输入,互相之间有依赖关系。对于每个模块,注意力层和前馈神经网络这两个子模块单独看都是可以并行的,不同的单词之间是没有依赖关系的,当然对于注意力层在做attention时会依赖别的时刻的输入。然后注意力层和前馈网络之间时串行的,必须先完成注意力层计算再做前馈网络。
为什么Q和K使用不同的权重矩阵生成,不能使用同一个值进行自身的点乘
简单回答:使用QKV不相同可以保证在不同空间进行投影,增强了表达能力,提高泛化能力。
详细解释:
transformer中为什么使用不同的K 和 Q, 为什么不能使用同一个值? - 知乎
Transformer计算attention时候为什么选择点乘而不是加法,在计算复杂度和效果上有什么区别
实验分析,时间复杂度相似;效果上,和dk相关,dk越大,加法效果越显著。
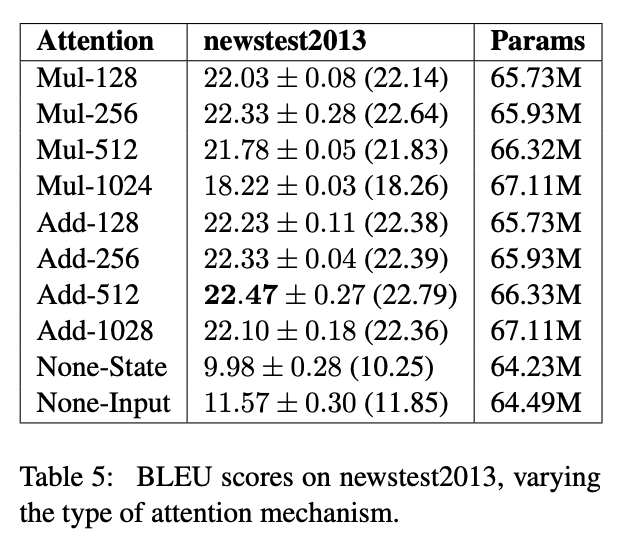
transformer中的attention为什么scaled
根据上一个问题,在dk(即 attention-dim)较小的时候,两者的效果接近。但是随着dk增大,Add 开始显著超越 Mul。作者分析 Mul 性能不佳的原因,认为是极大的点积值将整个 softmax 推向梯度平缓区,使得收敛困难。
这才有了 scaled。所以,Add 是天然地不需要 scaled,Mul 在dk较大的时候必须要做 scaled。个人认为,Add 中的矩阵乘法,和 Mul 中的矩阵乘法不同。前者中只有随机变量 X 和参数矩阵W 相乘,但是后者中包含随机变量 X 和随机变量 X 之间的乘法。
下面附上在知乎看到的代码数值实验就很清楚:
from scipy.special import softmax
import numpy as npdef test_gradient(dim, time_steps=50, scale=1.0):# Assume components of the query and keys are drawn from N(0, 1) independentlyq = np.random.randn(dim)ks = np.random.randn(time_steps, dim)x = np.sum(q * ks, axis=1) / scale # x.shape = (time_steps,) y = softmax(x)grad = np.diag(y) - np.outer(y, y)return np.max(np.abs(grad)) # the maximum component of gradientsNUMBER_OF_EXPERIMENTS = 5
# results of 5 random runs without scaling
print([test_gradient(100) for _ in range(NUMBER_OF_EXPERIMENTS)])
print([test_gradient(1000) for _ in range(NUMBER_OF_EXPERIMENTS)])# results of 5 random runs with scaling
print([test_gradient(100, scale=np.sqrt(100)) for _ in range(NUMBER_OF_EXPERIMENTS)])
print([test_gradient(1000, scale=np.sqrt(1000)) for _ in range(NUMBER_OF_EXPERIMENTS)])
# 不带 scaling 的两组(可以看到 dim=1000 时很容易发生梯度消失):
[1.123056543761436e-06, 0.14117211040878508, 0.24896212285554725, 0.000861296669097178, 0.24717750591081689]
[1.2388028380883043e-09, 3.630249703743676e-18, 1.4210854715202004e-14, 1.1652900866465643e-12, 5.045026175709566e-07]
# 带 scaling 的两组(dim=1000 时梯度流依然稳定):
[0.11292476415310426, 0.08650727907448993, 0.11307320939056421, 0.2039260641245917, 0.11422935801305531]
[0.12367058336991178, 0.15990586501130605, 0.1701746604359328, 0.10761820500367032, 0.07591586878293968]
相关文章:
解析Transformer模型
原文地址:https://zhanghan.xyz/posts/17281/ 进入Transformer RNN很难处理冗长的文本序列,且很容易受到所谓梯度消失/爆炸的问题。RNN是按顺序处理单词的,所以很难并行化。 用一句话总结Transformer:当一个扩展性极佳的模型和一…...
【深度学习】RTX2060 2080如何安装CUDA,如何使用onnx runtime
文章目录 如何在Python环境下配置RTX 2060与CUDA 101. 安装最新的NVIDIA显卡驱动2. 使用conda安装CUDA Toolkit3. 验证onnxruntime与CUDA版本4. 验证ONNX需求版本5. 安装ONNX与onnxruntime6. 编写ONNX推理代码 如何在Python环境下配置RTX 2060与CUDA 10 RTX 2060虽然是一款较早…...
力扣刷MySQL-第二弹(详细解析)
🎉欢迎您来到我的MySQL基础复习专栏 ☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹 ✨博客主页:小小恶斯法克的博客 🎈该系列文章专栏:力扣刷题讲解-MySQL 🍹文章作者技术和水平很有限,如果文中出…...

LiveGBS流媒体平台GB/T28181功能-基础配置接入控制白名单黑名单配置控制设备安全接入设备单独配置接入密码
LiveGBS基础配置接入控制白名单黑名单配置控制设备安全接入设备单独配置接入密码 1、白名单配置应用场景2、接入控制2.1、白名单2.2、黑名单 3、搭建GB28181视频直播平台 1、白名单配置应用场景 LiveGBS国标流媒体服务,支持白名单配置。 可在设备注册前࿰…...

企业网站建站源码系统:Thinkphp5内核企业网站建站模板源码 带完整的安装代码包以及搭建教程
随着互联网的快速发展,企业对于网站的需求日益增强。为了满足这一市场需求,小编给大家分享一款基于Thinkphp5内核的企业网站建站源码系统。该系统旨在为企业提供一套功能强大、易于使用的网站建设解决方案,帮助企业快速搭建自己的官方网站&am…...

SC20-EVB ubuntu14.04 Andriod 5.1 SDK编译下载
1.ubuntu14.04安装环境配置 vi /etc/profile to add export JAVA_HOME/usr/lib/jvm/java-7-openjdk-amd64 export JRE_HOME J A V A H O M E / j r e e x p o r t C L A S S P A T H . : {JAVA_HOME}/jre export CLASSPATH.: JAVAHOME/jreexportCLASSPATH.:{JAVA_HOME}/lib…...
OpenCV——图像按位运算
目录 一、算法概述1、逻辑运算2、函数解析3、用途 二、代码实现三、结果展示 OpenCV——图像按位运算由CSDN点云侠原创,爬虫自重。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、算法概述 1、逻辑运算 OpenCV4 针对两个图像之…...

5 个被低估的开源项目
文章目录 1.集算器 -数据处理2. Firecamp - 邮递员替代方案3.Keploy——后端 测试4. Hanko - 密钥验证5. Zrok - Ngrok 类固醇 长话短说 本文列出了五个不太受欢迎的优秀项目,您应该尝试一下。🔥 这些工具旨在改进数据处理、API 开发、后端测试、身份验…...
go语言初探(一)
package mainimport ("fmt""time" )func main() {fmt.Print("hello go!")time.Sleep(1 * time.Second)}运行后,结果如下: 1、golang表达式中,加;和不加;都可以 2、函数的{和函数名一…...
跟着cherno手搓游戏引擎【7】Input轮询
在引擎程序中任何时间,任何位置都能知道按键是否按下、鼠标的位置等等信息。 与事件系统的区别:事件系统是在按下时调用并传递按键状态;轮询是每时每刻都能获取按键状态 创建基类: YOTO/Input.h:名如其意 #pragma …...

stm32 - GPIO高级用法
stm32 - GPIO高级用法 PWMPWM / LEDPWM / 电机 PWM PWM / LED PWM波通过改变占空比可以改变LED的亮度 PWM信号调节LED亮度时,信号频率保持不变,即一个周期时间不变,改变的是脉冲的高电平的时间,即LED的导通时间,占空比…...
CMake TcpServer项目 生成静态库.a / 动态库.so
CMake 实战构建TcpServer项目 静态库/动态库-CSDN博客https://blog.csdn.net/weixin_41987016/article/details/135608829?spm1001.2014.3001.5501 在这篇博客的基础上,我们把头文件放在include里边,把源文件放在src里边,重新构建 hehedali…...

为什么光刻要用黄光
光刻是集成电路(IC或芯片)制造中的重要工艺之一。简单来说,它是通过使用光掩膜和光刻胶在基板上复制电路图案的过程。 基板将涂覆硅二氧化层绝缘层和光刻胶。光刻胶在被紫外光照射后可以容易地用显影剂溶解,然后在腐蚀后…...

Python 两种多值参数
有时可能需要一个函数中处理的参数的个数是不确定的,就需要使用多值参数 参数名前加上*,代表可以接收元组参数名前加上**,代表可以接收字典 代码: def demo(*args, **kwargs):print(args)print(kwargs)demo(1, 2, 3, 4, 5, nam…...

【Python学习】Python学习19- 异常处理
目录 【Python学习】Python学习19- 异常处理 前言python标准异常异常处理带异常类型语法不带异常类型语法使用except而带多种异常类型try-finally 语句触发异常 参考 文章所属专区 Python学习 前言 本章节主要说明Python的异常处理。 python标准异常 BaseException 所有异常…...

《A++ 敏捷开发》- 4 三点估算
估算是一个范围,不是一个数 唐工:你估计完成开发用户登录模块要多少天?小李:3天。唐工:能在3天完成的可能性有多高?小李:可能性很高。唐工:可否量化一点?小李:可能性为5…...

cesiumlab切片通过arcgisjs加载
cesiumlab切片通过arcgisjs加载 需要注意2个地方,一个是tileInfo,一个是getTileUrl, 在tileInfo中定义好cesiumlab切片的相关信息。 getTileUrl 格式化url的格式。 注意设置编辑,避免超出范围报404。 <html lang"en"…...

React16源码: React中调度之scheduleWork的源码实现
scheduleWork 1 ) 概述 在 ReactDOM.render, setState, forceUpdate 这几个方法最终都调用了 scheduleWork 这个方法 在 scheduleWork 当中,它需要去找到更新对应的 FiberRoot 节点 在使用 ReactDOM.render 的时候,传给 scheduleWork 的就是…...

【STM32】| 02——常用外设 | I2C
系列文章目录 【STM32】| 01——常用外设 | USART 【STM32】| 02——常用外设 | I2C 失败了也挺可爱,成功了就超帅。 文章目录 前言1. 简介2. I2C协议2.1 I2C物理连接2.2 I2C通信协议2.2.1 起始和停止信号2.2.2 数据有效性2.2.3 数据传输格式2.2.4 从机地址/数据方…...
微服务架构设计核心理论:掌握微服务设计精髓
文章目录 一、微服务与服务治理1、概述2、Two Pizza原则和微服务团队3、主链路规划4、服务治理和微服务生命周期5、微服务架构的网络层搭建6、微服务架构的部署结构7、面试题 二、配置中心1、为什么要配置中心2、配置中心高可用思考 三、服务监控1、业务埋点的技术选型2、用户行…...

暗黑破坏神2存档编辑器完整指南:三步轻松修改D2/D2R角色与装备
暗黑破坏神2存档编辑器完整指南:三步轻松修改D2/D2R角色与装备 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否厌倦了在暗黑破坏神2中反复刷装备却一无所获?是否因为早期加点失误导致角色后期无法应…...

实力入选丨全知科技荣登嘶吼2026网络安全产业图谱
近日,嘶吼安全产业研究院正式发布《嘶吼2026网络安全产业图谱》。全知科技凭借在数据安全赛道的长期深耕积淀、持续技术创新能力与规模化行业落地实践,成功入选图谱数据安全核心板块,强势入围开发与应用安全、数据安全两大核心板块࿰…...

【论文阅读】ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training
快速了解部分 基础信息(英文): 1.题目: ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training 2.时间: 2025.09 3.机构: University of Washington, UC San Diego, Nvidia, Allen Institute for AI 4.3个关键词: Fl…...

后端开发必知的数据库优化技巧:这5个方法让你的系统性能提升10倍
对于软件测试从业者来说,理解数据库优化逻辑不仅能帮我们更快定位性能瓶颈,还能让我们在测试阶段就提前发现潜在的数据库设计问题,避免上线后出现大规模性能故障。很多测试同学往往把注意力放在接口逻辑、功能正确性上,却忽略了数…...

iOS系统更新策略解析:从安全补丁到版本选择,如何理性应对系统升级
1. 从iOS 17.6.1看苹果的系统更新策略:一次“小修小补”背后的深意最近关于iOS 18和iOS 18.1的讨论铺天盖地,各种AI功能、界面大改的传闻让人眼花缭乱。但如果你像我一样,日常接触大量不同型号的iPhone用户,就会发现一个有趣的现象…...
)
保姆级教程:用vsomeip实现一个简单的车内服务发现与通信(附C++代码)
车载通信实战:基于vsomeip的服务发现与消息交互全流程解析 在智能座舱与自动驾驶技术快速迭代的今天,车载电子控制单元(ECU)间的可靠通信成为系统设计的核心挑战。SOME/IP作为汽车电子领域广泛采用的通信协议,其开源实…...

UE4SS终极指南:掌握虚幻引擎游戏修改的核心技术
UE4SS终极指南:掌握虚幻引擎游戏修改的核心技术 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE…...

3分钟搞定!Windows性能优化神器CPUDoc零基础上手指南
3分钟搞定!Windows性能优化神器CPUDoc零基础上手指南 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 你有没有遇到过这样的情况?明明电脑配置不错,玩游戏时帧数却忽高忽低;多开几个软件就感…...

百度网盘提取码智能查询工具:3分钟掌握资源密码自动获取技巧
百度网盘提取码智能查询工具:3分钟掌握资源密码自动获取技巧 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次找到心仪的资源却卡在密码输入环节࿰…...
:零服务器搭建个人/团队通用大模型API驱动的论文阅读与推荐平台)
AI Daily Paper Reader(ADPR):零服务器搭建个人/团队通用大模型API驱动的论文阅读与推荐平台
一、背景 AI领域论文每日增长数量惊人,arXiv 上仅计算机科学相关的新论文每天就有上百篇。对于科研人员、研究生或AI从业者来说,如何高效筛选、阅读并跟踪与自己研究方向相关的论文,已成为日常工作中最耗时的一环。 传统的解决方案…...