使用Spring Boot集成中间件:Elasticsearch基础->提高篇
使用Spring Boot集成中间件:Elasticsearch基础->提高篇
导言
Elasticsearch是一个开源的分布式搜索和分析引擎,广泛用于构建实时的搜索和分析应用。在本篇博客中,我们将深入讲解如何使用Spring Boot集成Elasticsearch,实现数据的索引、搜索和分析。
一、 Elasticsearch一些基本操作和配置
1. 准备工作
在开始之前,确保已经完成以下准备工作:
- 安装并启动Elasticsearch集群
- 创建Elasticsearch索引和映射(Mapping)
2. 添加依赖
首先,需要在Spring Boot项目中添加Elasticsearch的依赖。在pom.xml文件中加入以下依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
3. 配置Elasticsearch连接
在application.properties或application.yml中配置Elasticsearch的连接信息:
spring.data.elasticsearch.cluster-nodes=localhost:9200
4. 创建实体类
创建一个Java实体类,用于映射Elasticsearch中的文档。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;@Document(indexName = "blog", type = "article")
public class Article {@Idprivate String id;private String title;private String content;// Getters and setters
}
在上述代码中,我们使用了@Document注解定义了Elasticsearch中的索引名和文档类型。
5. 创建Repository接口
使用Spring Data Elasticsearch提供的ElasticsearchRepository接口来定义对Elasticsearch的操作。
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;public interface ArticleRepository extends ElasticsearchRepository<Article, String> {List<Article> findByTitle(String title);List<Article> findByContent(String content);
}
通过继承ElasticsearchRepository,我们可以直接使用Spring Data提供的方法进行数据的CRUD操作。
6. 编写Service
创建一个Service类,封装业务逻辑,调用Repository进行数据操作。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.List;@Service
public class ArticleService {private final ArticleRepository articleRepository;@Autowiredpublic ArticleService(ArticleRepository articleRepository) {this.articleRepository = articleRepository;}public List<Article> searchByTitle(String title) {return articleRepository.findByTitle(title);}public List<Article> searchByContent(String content) {return articleRepository.findByContent(content);}
}
7. 使用示例
在Controller层使用我们创建的Service进行数据的操作。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;import java.util.List;@RestController
@RequestMapping("/articles")
public class ArticleController {private final ArticleService articleService;@Autowiredpublic ArticleController(ArticleService articleService) {this.articleService = articleService;}@GetMapping("/searchByTitle")public List<Article> searchByTitle(@RequestParam String title) {return articleService.searchByTitle(title);}@GetMapping("/searchByContent")public List<Article> searchByContent(@RequestParam String content) {return articleService.searchByContent(content);}
}
8. 运行和测试
通过访问Controller提供的接口,我们可以进行数据的索引、搜索等操作:
curl -X GET http://localhost:8080/articles/searchByTitle?title=Elasticsearch
二、 Elasticsearch 保存实体类在表中的映射
Elasticsearch 与传统的关系型数据库不同,它采用的是文档型数据库的思想,数据以文档的形式存储。在 Elasticsearch 中,我们不再创建表,而是创建索引(Index),每个索引包含多个文档(Document),每个文档包含多个字段。
以下是 Elasticsearch 中建立索引和实体类的映射的基本步骤:
1. 创建索引
在 Elasticsearch 中,索引是存储相关文档的地方。我们可以通过 RESTful API 或者在 Spring Boot 项目中使用 Elasticsearch 的 Java 客户端创建索引。以下是通过 RESTful API 创建索引的示例:
PUT /my_index
上述命令创建了一个名为 my_index 的索引。在 Spring Boot 项目中,可以使用 IndexOperations 类来创建索引,示例如下:
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;public void createIndex() {elasticsearchRestTemplate.indexOps(MyEntity.class).create();
}
2. 定义实体类
实体类用于映射 Elasticsearch 中的文档结构。每个实体类的实例对应于一个文档。在实体类中,我们可以使用注解来定义字段的映射关系。以下是一个简单的实体类示例:
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Document(indexName = "my_index", type = "my_entity")
public class MyEntity {@Idprivate String id;@Field(type = FieldType.Text)private String name;@Field(type = FieldType.Keyword)private String category;// 其他字段和方法
}
上述示例中,通过 @Document 注解定义了索引名为 my_index,类型名为 my_entity。通过 @Field 注解定义了字段的映射关系,例如 name 字段映射为 Text 类型,category 字段映射为 Keyword 类型。
3. 保存文档
保存文档是将实体类的实例存储到 Elasticsearch 中的过程。在 Spring Boot 项目中,可以使用 ElasticsearchTemplate 或者 ElasticsearchRepository 进行文档的保存。以下是使用 ElasticsearchRepository 的示例:
public interface MyEntityRepository extends ElasticsearchRepository<MyEntity, String> {
}
在上述示例中,MyEntityRepository 继承了 ElasticsearchRepository 接口,泛型参数为实体类类型和 ID 类型。Spring Data Elasticsearch 将根据实体类的结构自动生成相应的 CRUD 方法。通过调用 save 方法,可以保存实体类的实例到 Elasticsearch 中。
@Autowired
private MyEntityRepository myEntityRepository;public void saveDocument() {MyEntity entity = new MyEntity();entity.setName("Document Name");entity.setCategory("Document Category");myEntityRepository.save(entity);
}
上述代码示例中,我们创建了一个 MyEntity 类的实例,并使用 save 方法将其保存到 Elasticsearch 中。
提高篇
一 实际案例:使用Spring Boot集成Elasticsearch的深度提高篇
在这个实际案例中,我们将以一个图书搜索引擎为例,详细讲解如何使用Spring Boot集成Elasticsearch进行深度提高,包括性能调优、复杂查询、分页和聚合等方面。
1. 准备工作
首先,确保你已经搭建好Elasticsearch集群,并且在Spring Boot项目中添加了Elasticsearch的依赖。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2. 配置文件
在application.properties或application.yml中配置Elasticsearch的连接信息:
spring.data.elasticsearch.cluster-nodes=localhost:9200
3. 实体类
创建一个图书实体类,用于映射Elasticsearch中的文档。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;@Document(indexName = "books", type = "book")
public class Book {@Idprivate String id;private String title;private String author;private String genre;// Getters and setters
}
4. Repository 接口
创建一个Elasticsearch Repository接口,继承自ElasticsearchRepository,用于对图书文档进行操作。
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;import java.util.List;public interface BookRepository extends ElasticsearchRepository<Book, String> {List<Book> findByTitleLike(String title);List<Book> findByAuthorAndGenre(String author, String genre);// 更多自定义查询方法
}
5. 服务类
创建一个服务类,用于处理业务逻辑,调用Repository进行图书文档的操作。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.List;@Service
public class BookService {private final BookRepository bookRepository;@Autowiredpublic BookService(BookRepository bookRepository) {this.bookRepository = bookRepository;}public List<Book> searchBooksByTitle(String title) {return bookRepository.findByTitleLike(title);}public List<Book> searchBooksByAuthorAndGenre(String author, String genre) {return bookRepository.findByAuthorAndGenre(author, genre);}// 更多业务逻辑和自定义查询方法
}
6. 性能调优
6.1 配置文件调优
在application.properties中配置Elasticsearch的连接池大小和相关参数:
spring.data.elasticsearch.properties.http.max_content_length=100mb
spring.data.elasticsearch.properties.http.max_initial_line_length=100kb
spring.data.elasticsearch.properties.http.max_header_size=3kb
spring.data.elasticsearch.properties.transport.tcp.compress=true
spring.data.elasticsearch.properties.transport.tcp.connect_timeout=5s
spring.data.elasticsearch.properties.transport.tcp.keep_alive=true
spring.data.elasticsearch.properties.transport.tcp.no_delay=true
spring.data.elasticsearch.properties.transport.tcp.socket_timeout=5s
6.2 JVM调优
修改jvm.options文件,调整堆内存大小:
-Xms2g
-Xmx2g
7. 复杂查询
通过服务类提供的自定义查询方法实现复杂查询,例如按标题模糊查询和按作者、类别查询:
@RestController
@RequestMapping("/books")
public class BookController {private final BookService bookService;@Autowiredpublic BookController(BookService bookService) {this.bookService = bookService;}@GetMapping("/searchByTitle")public List<Book> searchByTitle(@RequestParam String title) {return bookService.searchBooksByTitle(title);}@GetMapping("/searchByAuthorAndGenre")public List<Book> searchByAuthorAndGenre(@RequestParam String author, @RequestParam String genre) {return bookService.searchBooksByAuthorAndGenre(author, genre);}
}
8. 分页和聚合
在Controller中添加分页和聚合的方法:
@GetMapping("/searchWithPagination")
public List<Book> searchWithPagination(@RequestParam String title, @RequestParam int page, @RequestParam int size) {PageRequest pageRequest = PageRequest.of(page, size);return bookService.searchBooksByTitleWithPagination(title, pageRequest);
}@GetMapping("/aggregateByGenre")
public Map<String, Long> aggregateByGenre() {return bookService.aggregateBooksByGenre();
}
在服务类中实现分页和聚合的方法:
public List<Book> searchBooksByTitleWithPagination(String title, Pageable pageable) {SearchHits<Book> searchHits = bookRepository.search(QueryBuilders.matchQuery("title", title), pageable);return searchHits.stream().map(SearchHit::getContent).collect(Collectors.toList());
}public Map<String, Long> aggregateBooksByGenre() {TermsAggregationBuilder aggregation = AggregationBuilders.terms("genres").field("genre").size(10);SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().aggregation(aggregation);SearchHits<Book> searchHits = bookRepository.search(sourceBuilder.build());return searchHits.getAggregations().asMap().entrySet().stream().collect(Collectors.toMap(Map.Entry::getKey, e -> ((ParsedLongTerms) e.getValue()).getBuckets().size()));
}
9. 运行与测试
二 使用Spring Boot集成Elasticsearch的更多进阶特性
1. 文档数据处理
在实际应用中,对文档数据的处理常常需要更多的灵活性。我们将学习如何在实体类中使用注解进行更高级的字段映射和设置:
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Document(indexName = "books", type = "book")
public class Book {@Idprivate String id;@Field(type = FieldType.Text, analyzer = "standard", fielddata = true)private String title;@Field(type = FieldType.Keyword)private String author;@Field(type = FieldType.Keyword)private String genre;// 其他字段和方法
}
在上述例子中,我们使用了@Field注解进行更精细的字段类型设置和分词配置。
2. 脚本查询
Elasticsearch允许使用脚本进行查询,这在某些复杂的业务逻辑下非常有用。我们将学习如何使用脚本进行查询:
@GetMapping("/searchWithScript")
public List<Book> searchWithScript(@RequestParam String script) {NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.scriptQuery(new Script(script))).build();return elasticsearchRestTemplate.search(searchQuery, Book.class).stream().map(SearchHit::getContent).collect(Collectors.toList());
}
在上述例子中,我们通过Script对象构建了一个脚本查询,并使用NativeSearchQuery进行执行。
3. 性能优化 - Bulk 操作
当需要批量操作大量文档时,使用Bulk操作可以显著提高性能。我们将学习如何使用Bulk操作:
public void bulkIndexBooks(List<Book> books) {List<IndexQuery> indexQueries = books.stream().map(book -> new IndexQueryBuilder().withObject(book).build()).collect(Collectors.toList());elasticsearchRestTemplate.bulkIndex(indexQueries);elasticsearchRestTemplate.refresh(Book.class);
}
在上述例子中,我们通过bulkIndex方法批量索引图书,并使用refresh方法刷新索引。
4. 高级用法 - Highlight
在搜索结果中高亮显示关键字是提高用户体验的一种方式。我们将学习如何在查询中使用Highlight:
public List<Book> searchBooksWithHighlight(String keyword) {QueryStringQueryBuilder query = QueryBuilders.queryStringQuery(keyword);HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title").preTags("<span style='background-color:yellow'>").postTags("</span>");NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(query).withHighlightFields(highlightTitle).build();SearchHits<Book> searchHits = elasticsearchRestTemplate.search(searchQuery, Book.class);return searchHits.stream().map(searchHit -> {Book book = searchHit.getContent();Map<String, List<String>> highlightFields = searchHit.getHighlightFields();if (highlightFields.containsKey("title")) {book.setTitle(String.join(" ", highlightFields.get("title")));}return book;}).collect(Collectors.toList());
}
在上述例子中,我们通过HighlightBuilder设置了对title字段的高亮显示,然后在查询中使用了withHighlightFields方法。
5. 进阶用法 - SearchTemplate
Elasticsearch提供了SearchTemplate功能,允许使用模板进行更灵活的查询。我们将学习如何使用SearchTemplate:
public List<Book> searchBooksWithTemplate(String genre) {Map<String, Object> params = Collections.singletonMap("genre", genre);String script = "{\"query\":{\"match\":{\"genre\":\"{{genre}}\"}}}";SearchResponse response = elasticsearchRestTemplate.query(searchRequest -> {searchRequest.setScript(new Script(ScriptType.INLINE, "mustache", script, params)).setIndices("books").setTypes("book");}, SearchResponse.class);return Arrays.stream(response.getHits().getHits()).map(hit -> elasticsearchRestTemplate.getConverter().read(Book.class, hit)).collect(Collectors.toList());
}
在上述例子中,我们通过SearchTemplate使用了一个简单的Mustache模板进行查询。
高级使用篇
Elasticsearch常见的高级使用篇
在一部分中,我们将深入讨论Elasticsearch的一些常见的高级使用技巧,包括聚合、地理空间搜索、模糊查询、索引别名等。
1. 聚合(Aggregation)
聚合是Elasticsearch中一项强大的功能,它允许对数据集进行复杂的数据分析和汇总。以下是一些常见的聚合类型:
1.1 桶聚合(Bucket Aggregation)
桶聚合将文档分配到不同的桶中,然后对每个桶进行聚合计算。
GET /my_index/_search
{"size": 0,"aggs": {"categories": {"terms": {"field": "category.keyword"}}}
}
上述例子中,通过桶聚合统计了每个类别的文档数量。
1.2 指标聚合(Metric Aggregation)
指标聚合计算某个字段的统计指标,比如平均值、最大值、最小值等。
GET /my_index/_search
{"size": 0,"aggs": {"average_price": {"avg": {"field": "price"}}}
}
上述例子中,通过指标聚合计算了字段"price"的平均值。
2. 地理空间搜索
Elasticsearch提供了强大的地理空间搜索功能,支持地理点、地理形状等多种地理数据类型。
2.1 地理点搜索
GET /my_geo_index/_search
{"query": {"geo_distance": {"distance": "10km","location": {"lat": 40,"lon": -70}}}
}
上述例子中,通过地理点搜索找到距离指定坐标(纬度40,经度-70)10公里范围内的文档。
2.2 地理形状搜索
GET /my_geo_shape_index/_search
{"query": {"geo_shape": {"location": {"shape": {"type": "envelope","coordinates": [[-74.1,40.73], [-73.9,40.85]]},"relation": "within"}}}
}
上述例子中,通过地理形状搜索找到在指定矩形区域内的文档。
3. 模糊查询
Elasticsearch支持多种模糊查询,包括通配符查询、模糊查询、近似查询等。
3.1 通配符查询
GET /my_index/_search
{"query": {"wildcard": {"name": "el*"}}
}
上述例子中,通过通配符查询找到名字以"el"开头的文档。
3.2 模糊查询
GET /my_index/_search
{"query": {"fuzzy": {"name": {"value": "elastic","fuzziness": "AUTO"}}}
}
上述例子中,通过模糊查询找到与"elastic"相似的文档。
4. 索引别名
索引别名是一个指向一个或多个索引的虚拟索引名称,它可以用于简化查询、切换索引版本、重命名索引等操作。
POST /_aliases
{"actions": [{"add": {"index": "new_index","alias": "my_alias"}}]
}
上述例子中,创建了一个别名"my_alias"指向索引"new_index"。
5. 深度分页
当需要深度分页时,常规的from和size可能会导致性能问题。这时可以使用search_after进行优化。
GET /my_index/_search
{"size": 10,"query": {"match_all": {}},"sort": [{"date": {"order": "asc"}}]
}
上述例子中,通过search_after分页查询,可以避免使用from和size导致的性能问题。
结语
通过这篇高级使用篇博客,我们详细介绍了如何使用Spring Boot集成Elasticsearch,包括添加依赖、配置连接、创建实体类和Repository接口、编写Service以及使用示例。我们深入了解了Elasticsearch的一些高级功能,包括聚合、地理空间搜索、模糊查询、索引别名等。这些技巧将有助于你更灵活、高效地处理各种复杂的数据查询和分析任务。希望这些内容对你在实际项目中的应用有所帮助。感谢阅读!
相关文章:

使用Spring Boot集成中间件:Elasticsearch基础->提高篇
使用Spring Boot集成中间件:Elasticsearch基础->提高篇 导言 Elasticsearch是一个开源的分布式搜索和分析引擎,广泛用于构建实时的搜索和分析应用。在本篇博客中,我们将深入讲解如何使用Spring Boot集成Elasticsearch,实现数…...

【Docker】Dockerfile构建最小镜像
🥳🥳Welcome 的Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于Docker的相关操作吧 目录 🥳🥳Welcome 的Huihuis Code World ! !🥳🥳 前言 一.Dockerfile是什么 二.Dock…...

【严重】GitLab 以其他用户身份执行 Slack 命令
漏洞描述 GitLab 是由GitLab公司开发的、基于Git的集成软件开发平台。使用 Slack 命令在 Slack 聊天环境中运行常见的 GitLab 操作。 GitLab 受影响版本中,由于配置Slack/Mattermost 集成时,未正确验证用户身份信息,导致攻击者可以使用其他…...

【卡梅德生物】纳米抗体文库构建
纳米抗体文库构建服务是一项提供定制化纳米抗体文库的服务,旨在满足研究者和生物制药公司对高质量抗体的需求。这项服务通常包括以下主要步骤: 1.抗原设计和制备: -客户提供目标抗原信息,或由服务提供商协助设计抗原。 -抗原制…...

MySQL修炼手册6:子查询入门:在查询中嵌套查询
目录 写在开头1 子查询基础概念1.1 了解子查询的基本概念1.2 子查询与主查询的关系 2 标量子查询详细展开2.1 学会使用标量子查询2.1.1 在SELECT语句中使用2.1.2 在WHERE子句中使用2.1.3 在ORDER BY子句中使用 2.2 标量子查询在条件判断中的应用2.2.1 使用比较运算符2.2.2 使用…...
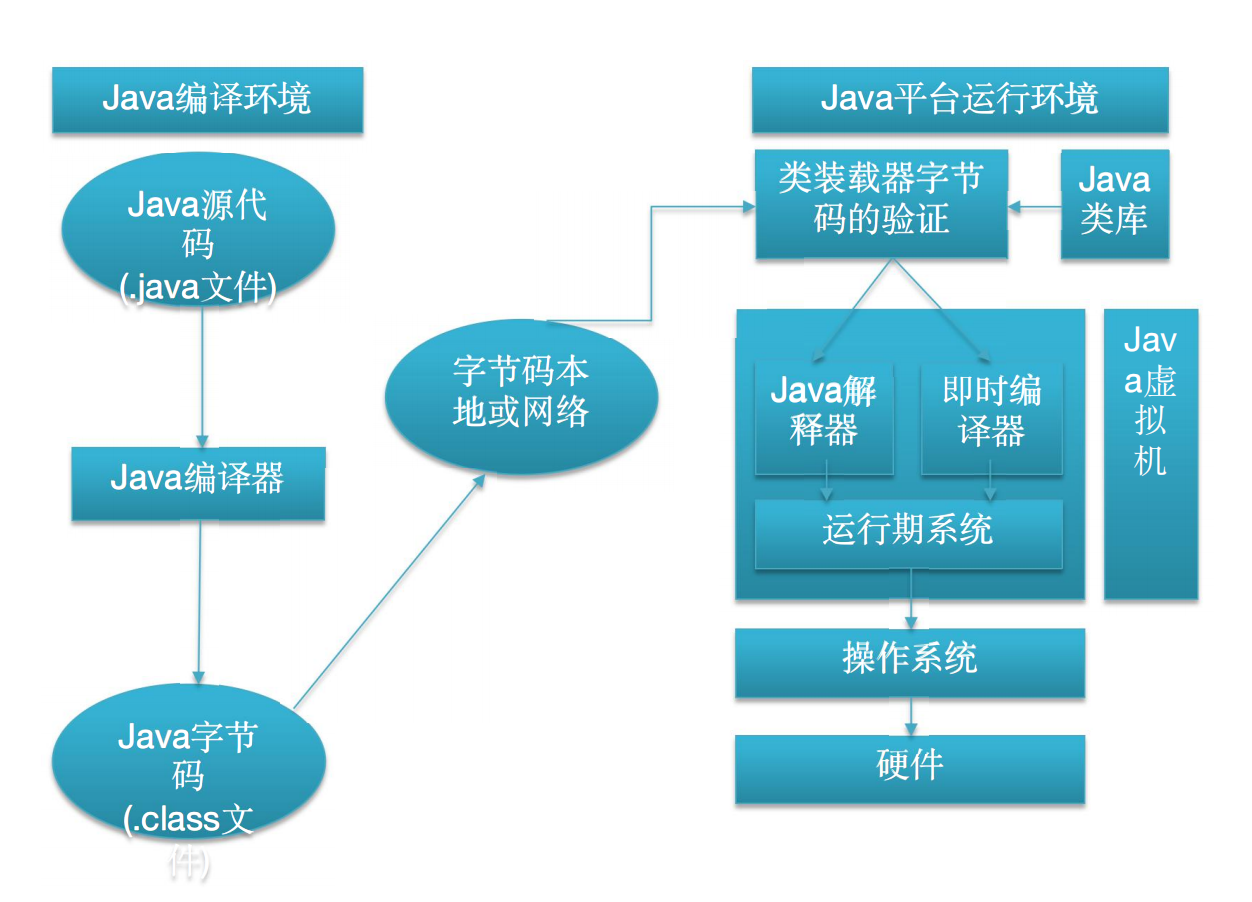
01章【JAVA开发入门】
计算机基本概念 计算机组成原理 计算机组装 计算机:电子计算机,俗称电脑。是一种能够按照程序运行,自动、高速处理海量数据的现代化智能电子设备。由硬件和软件所组成,没有安装任何软件的计算机称为裸机。常见的形式有台式计算机、…...
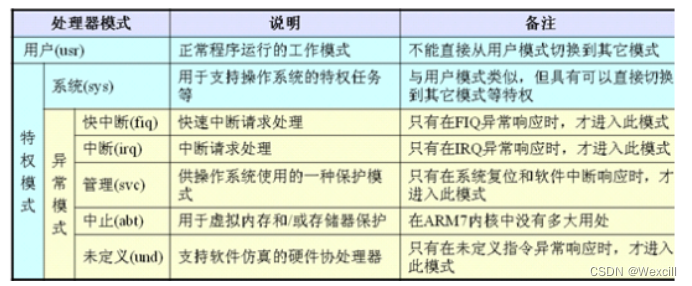
ARM day1
一、概念 ARM可以工作的七种模式用户、系统、快中断、中断、管理、终止、未定义ARM核的寄存器个数 37个32位长的寄存器,当前处理器的模式决定着哪组寄存器可操作,且任何模式都可以存取: PC(program counter程序计数器) CPSR(current program…...
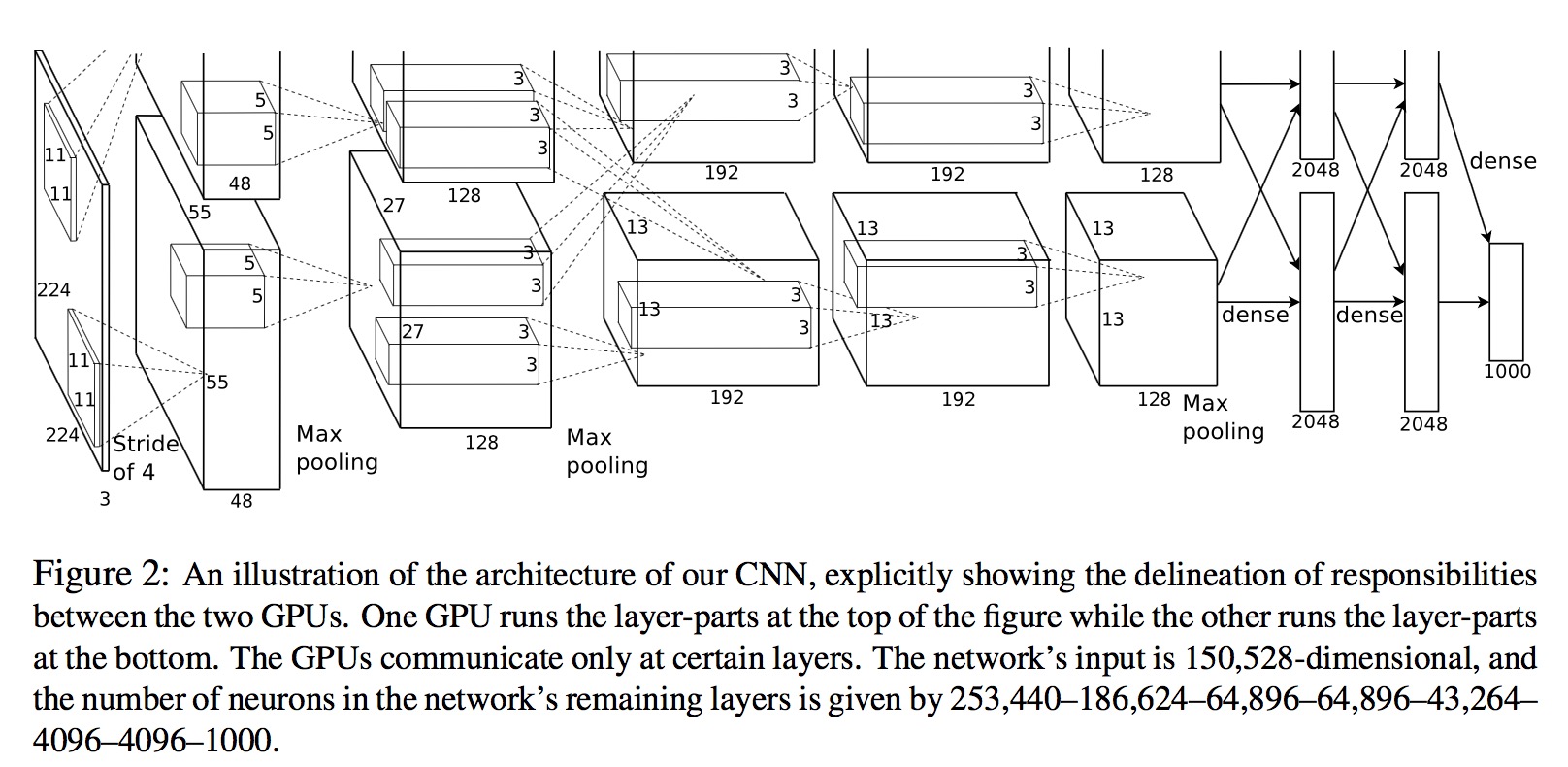
ImageNet Classification with Deep Convolutional 论文笔记
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...
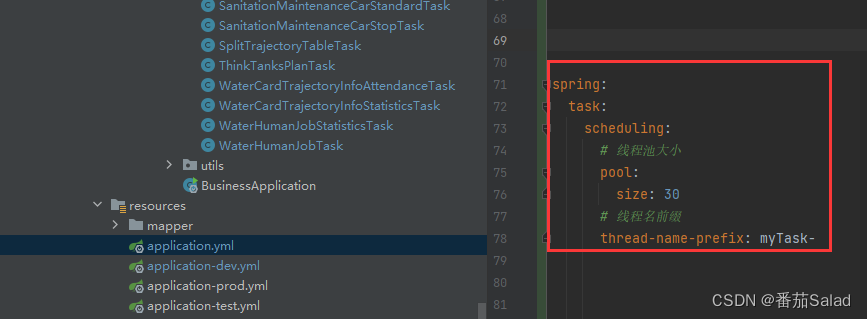
Spring Boot中加@Async和不加@Async有什么区别?设置核心线程数、设置最大线程数、设置队列容量是什么意思?直接在yml中配置线程池
在 Spring 中,Async 注解用于将方法标记为异步执行的方法。当使用 Async 注解时,该方法将在单独的线程中执行,而不会阻塞当前线程。这使得方法可以在后台执行,而不会影响主线程的执行。 在您提供的代码示例中,a1() 和…...
—开发语言之Python)
自动化理论基础(2)—开发语言之Python
一、知识汇总 掌握 Python 编程语言需要具备一定的基础知识和技能,特别是对于从事自动化测试等领域的工程师。以下是掌握 Python 的一些关键方面: 基本语法: 理解 Python 的基本语法,包括变量、数据类型、运算符、条件语句、循环…...
超细致讲解)
Spark算子(RDD)超细致讲解
SPARK算子(RDD)超细致讲解 map,flatmap,sortBykey, reduceBykey,groupBykey,Mapvalues,filter,distinct,sortBy,groupBy共10个转换算子 (一)转换算子 1、map from pyspark import SparkContext# 创建SparkContext对象 sc Spark…...
C卷 (JavaPythonC++Node.jsC语言))
转盘寿司(100%用例)C卷 (JavaPythonC++Node.jsC语言)
寿司店周年庆,正在举办优惠活动回馈新老客户。 寿司转盘上总共有n盘寿司,prices[i]是第i盘寿司的价格,如果客户选择了第i盘寿司,寿司店免费赠送客户距离,第i盘寿司最近的下一盘寿司i,前提是prices[j]< prices[i],如果没有满足条件的j,则不赠送寿司。 每个价格的寿司都…...

【python】搭配Miniconda使用VSCode
现在的spyder总是运行出错,启动不了,尝试使用VSCode。 一、在VSCode中使用Miniconda管理的Python环境,可以按照以下步骤进行: a. 确保Miniconda环境已经安装并且正确配置。 b. 打开VSCode,安装Python扩展。 打开VS…...
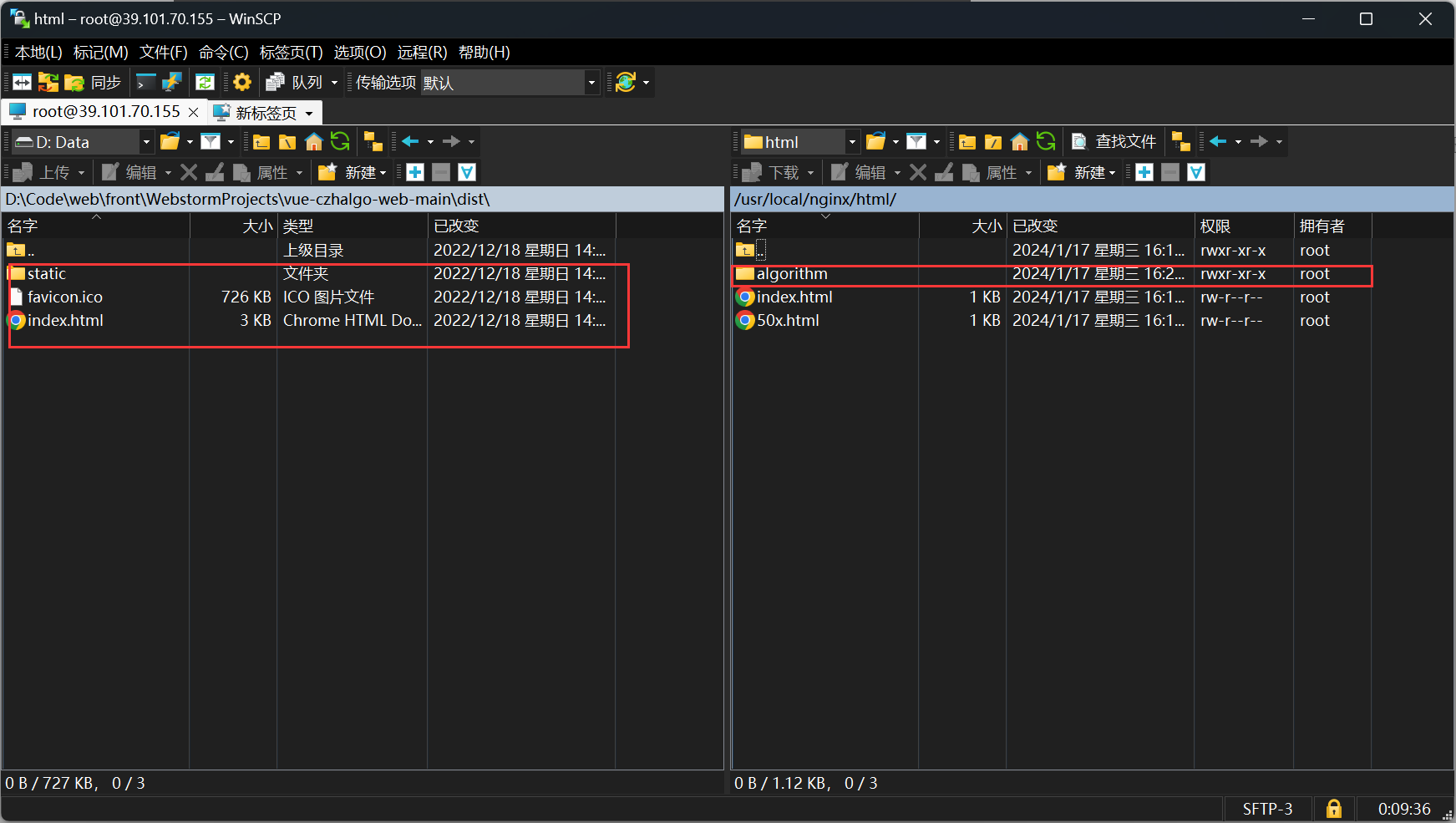
从购买服务器到部署前端VUE项目
购买 选择阿里云服务器,地址:https://ecs.console.aliyun.com/home。学生会送一个300的满减券,我买了一个400多一年的,用券之后100多点。 使用SSH连接服务器 我选择的是vscode 中SSH工具。 安装一个插件 找到配置文件配置一下…...

python中print函数的用法
在 Python 中,print() 函数是用于输出信息到控制台的内置函数。它可以将文本、变量、表达式等内容打印出来,方便程序员进行调试和查看结果。print() 函数的基本语法如下: ``` print(*objects, sep= , end=\n, file=sys.stdout, flush=False) ``` 其中,objects 是要打印…...

SpringBoot整合MyBatis项目进行CRUD操作项目示例
文章目录 SpringBoot整合MyBatis项目进行CRUD操作项目示例1.1.需求分析1.2.创建工程1.3.pom.xml1.4.application.properties1.5.启动类 2.添加用户2.1.数据表设计2.2.pojo2.3.mapper2.4.service2.5.junit2.6.controller2.7.thymeleaf2.8.测试 3.查询用户3.1.mapper3.2.service3…...
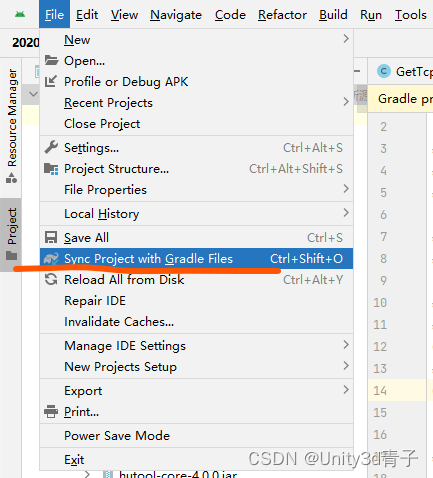
Android Studio下载gradle反复失败
我的版本:gradle-5.1.1 首先检查设置路径是否正确,参考我的修改! 解决方案 1.手动下载Gradle.bin Gradle Distributions 下载地址 注意根据编译器提示下载,我这要求下载的是bin 而不是all 2.把下载好的整个压缩包放在C:\Users\…...
【HTML5】 canvas 绘制图形
文章目录 一、基本用法二、用法详见2.0、方法属性2.1、绘制线条2.2、绘制矩形2.3、绘制圆形2.4、绘制文本2.5、填充图像 一、基本用法 canvas 标签:可用于在网页上绘制图形(使用 JavaScript 在网页上绘制图像)画布是一个矩形区域,…...
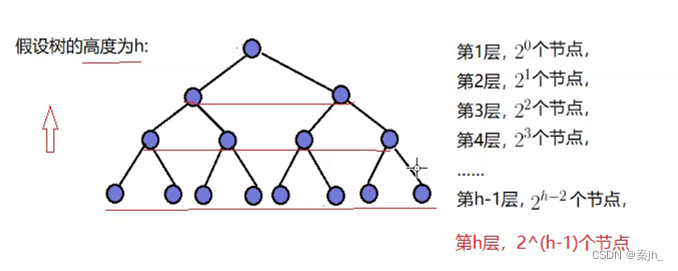
【数据结构】二叉树-堆(top-k问题,堆排序,时间复杂度)
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343🔥 系列专栏:《数据结构》https://blog.csdn.net/qinjh_/category_12536791.html?spm1001.2014.3001.5482 目录 堆排序 第一种 编辑 第二种 …...

通过浏览器判断是否安装APP
场景 求在分享出来的h5页面中,有一个立即打开的按钮,如果本地安装了我们的app,那么点击就直接唤本地app,如果没有安装,则跳转到下载。 移动端 判断本地是否安装了app 首先我们可以确认的是,在浏览器中无…...

AI绘画的三重危机:颜料、像素与剽窃
1. 这不是技术讨论,而是一场正在发生的行业地震“Paint, Pixels, and Plagiarism”——光看这个标题,你就能闻到火药味。它没说“AI绘画工具使用指南”,也没写“Stable Diffusion参数调优手册”,而是把颜料(Paint&…...

观察Taotoken在多模型聚合调用时的路由与容错表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用时的路由与容错表现 在构建依赖大模型能力的应用时,服务的稳定性是开发者关心的核心问题…...

2026终极测评:16款降AIGC工具横评,论文降重降ai率终极答案!
随着AI写作技术的迅猛发展,越来越多的学术创作者开始依赖各类生成工具提升效率。然而,2026年各大高校与科研机构对AIGC内容的检测标准愈发严格,论文中的一丝AI痕迹都可能成为被质疑的导火索。面对日益严峻的查重与AIGC检测压力,如…...

Steam Deck多系统引导终极指南:3步完成图形化配置
Steam Deck多系统引导终极指南:3步完成图形化配置 【免费下载链接】SteamDeck_rEFInd Simple rEFInd install script for the Steam Deck (with GUI customization) 项目地址: https://gitcode.com/gh_mirrors/st/SteamDeck_rEFInd SteamDeck_rEFInd是一款专…...

从Linux内核list.h到用户态:侵入式单向链表的设计与实现
1. 项目概述:从内核到应用,list.h的降维打击如果你在Linux内核源码里泡过,或者看过一些高性能的开源项目,一定对list.h这个文件不陌生。它位于内核源码的include/linux/目录下,是一个用C语言实现的、精巧绝伦的通用双向…...

东南大学论文模板:告别格式烦恼,专注学术创新的8倍效率解决方案
东南大学论文模板:告别格式烦恼,专注学术创新的8倍效率解决方案 【免费下载链接】SEUThesis 东南大学论文模板 项目地址: https://gitcode.com/gh_mirrors/seu/SEUThesis 东南大学SEUThesis论文模板库是专为东大学子设计的学术写作利器࿰…...

如何用Python自动化脚本高效抢购热门演出门票?智能抢票解决方案揭秘
如何用Python自动化脚本高效抢购热门演出门票?智能抢票解决方案揭秘 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 还在为热门演唱会门票秒光而烦恼吗࿱…...

抖音无水印下载器全解析:从零构建你的个人视频收藏库
抖音无水印下载器全解析:从零构建你的个人视频收藏库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

MoE稀疏激活:大模型推理效率革命的核心原理与工程实践
1. 这不是参数堆砌,而是“动态稀疏激活”的工程革命你可能已经看到过那条刷屏的推文:“GPT-4有1.8万亿参数,但每生成一个token只用其中2%。”——这句话像一道闪电劈开了大模型圈的认知惯性。它背后根本不是在炫耀数字有多吓人,而…...

Logisim-evolution数字电路设计实战:从图形化设计到FPGA实现的完整工作流
Logisim-evolution数字电路设计实战:从图形化设计到FPGA实现的完整工作流 【免费下载链接】logisim-evolution Digital logic design tool and simulator 项目地址: https://gitcode.com/gh_mirrors/lo/logisim-evolution Logisim-evolution作为一款功能强大…...