深入探讨生产环境中秒杀接口并发量剧增、负载过高的情况该如何应对?
目录
引言
1. 实施限流措施
1.1 令牌桶算法:
1.2 漏桶算法:
1.3 使用限流框架:
2. 优化数据库操作
2.1. 索引优化
2.2. 批量操作减少交互次数:
2.3. 避免全表扫描:
2.4使用InnoDB引擎:
2.5优化事务范围:
3. 使用缓存技术
3.1. 选择合适的缓存系统:
3.2. 缓存热门商品信息:
3.3. 缓存热门商品列表:
3.4. 使用缓存刷新策略:
3.5. 使用缓存预热:
4. 异步处理订单
4.1. 选择合适的消息队列系统:
4.2. 订单生成异步化:
4.3. 异步处理订单消息监听:
4.4. 保证消息的可靠性:
4.5. 处理失败消息的重试和补偿:
5. 水平扩展
5.1. 负载均衡:
5.2. 横向添加服务器节点:
5.3. 数据库水平分片:
5.4. 服务的横向拆分:
5.5. 监控和自动化:
5.6. 弹性计算和容灾:
6、 灰度发布和回滚
7、总结
引言
在生产环境中,秒杀活动通常是一项高并发的任务,因为大量用户在同一时刻竞相购买限量商品。这种高并发可能导致服务器压力剧增,造成系统崩溃或响应缓慢。为了解决这一问题,我们可以采用一系列优化措施,下面详细介绍一下
1. 实施限流措施
实施限流措施是在高并发场景下保护系统稳定性的关键步骤。限流可以控制请求的并发访问量,避免系统因瞬时高并发而崩溃。以下是一些实施限流措施的方法:
1.1 令牌桶算法:
令牌桶算法是一种常用的限流算法,它基于令牌桶的概念,系统以固定的速率往令牌桶中放入令牌,而接口访问时需要获取令牌,没有令牌的请求将被拒绝。
public class TokenBucket {private int capacity; // 桶的容量private int tokens; // 当前令牌数量private long lastRefillTime; // 上次令牌刷新时间public TokenBucket(int capacity, int tokensPerSecond) {this.capacity = capacity;this.tokens = capacity;this.lastRefillTime = System.currentTimeMillis();scheduleRefill(tokensPerSecond);}public synchronized boolean tryConsume() {refill();if (tokens > 0) {tokens--;return true;} else {return false;}}private void refill() {long now = System.currentTimeMillis();if (now > lastRefillTime) {long elapsedTime = now - lastRefillTime;int tokensToAdd = (int) (elapsedTime / 1000); // 每秒放入令牌tokens = Math.min(capacity, tokens + tokensToAdd);lastRefillTime = now;}}private void scheduleRefill(int tokensPerSecond) {ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);scheduler.scheduleAtFixedRate(() -> refill(), 1, 1, TimeUnit.SECONDS);}
}
1.2 漏桶算法:
漏桶算法是另一种常用的限流算法,它模拟一个漏桶,请求以恒定的速度流入漏桶,漏桶以固定的速度漏水。如果桶满了,多余的请求将被丢弃或排队。
public class LeakyBucket {private int capacity; // 桶的容量private int water; // 当前水量private long lastLeakTime; // 上次漏水时间public LeakyBucket(int capacity, int leaksPerSecond) {this.capacity = capacity;this.water = 0;this.lastLeakTime = System.currentTimeMillis();scheduleLeak(leaksPerSecond);}public synchronized boolean tryConsume() {leak();if (water > 0) {water--;return true;} else {return false;}}private void leak() {long now = System.currentTimeMillis();if (now > lastLeakTime) {long elapsedTime = now - lastLeakTime;int leaks = (int) (elapsedTime / 1000); // 每秒漏水water = Math.max(0, water - leaks);lastLeakTime = now;}}private void scheduleLeak(int leaksPerSecond) {ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);scheduler.scheduleAtFixedRate(() -> leak(), 1, 1, TimeUnit.SECONDS);}
}
1.3 使用限流框架:
除了手动实现限流算法外,也可以使用一些成熟的限流框架,如Guava RateLimiter、Spring Cloud Gateway等,它们提供了简便的接口和配置,可以快速实施限流措施。
// 使用Guava RateLimiter
RateLimiter rateLimiter = RateLimiter.create(10.0); // 每秒放入10个令牌
if (rateLimiter.tryAcquire()) {// 执行业务逻辑
} else {// 请求被限流
}
限流的选择要根据系统的实际情况、业务需求和性能测试来确定。限流是保护系统稳定性的有效手段,但需要注意的是,过于严格的限流可能影响到用户体验,因此需要在系统性能和用户体验之间找到平衡。
2. 优化数据库操作
优化数据库操作是提高系统性能的重要一环,尤其在高并发的秒杀场景下,数据库操作的效率直接影响系统的响应速度。以下是一些优化数据库操作的方法:
2.1. 索引优化
确保数据库表的关键字段上建立了适当的索引,特别是在经常用于查询和更新的字段上。索引可以加速查询操作。
-- 为product表的id和stock字段创建索引
CREATE INDEX idx_product_id ON product(id);
CREATE INDEX idx_product_stock ON product(stock);
2.2. 批量操作减少交互次数:
减少与数据库的交互次数,使用批量操作来提高性能,特别是在更新库存等操作时。
// 批量更新库存
public class ProductService {public void updateProductStockBatch(List<Integer> productIds) {try (Connection connection = dataSource.getConnection();PreparedStatement statement = connection.prepareStatement("UPDATE product SET stock = stock - 1 WHERE id = ?")) {for (int productId : productIds) {statement.setInt(1, productId);statement.addBatch();}statement.executeBatch();} catch (SQLException e) {// 异常处理...}}
}
2.3. 避免全表扫描:
使用合适的查询条件和索引,避免全表扫描,提高查询效率。
// 使用索引进行查询和更新
public class ProductService {public Product getSeckillProductInfo(int productId) {String sql = "SELECT * FROM product WHERE id = ? FOR UPDATE";// 执行查询...}public boolean updateProductStock(int productId) {String sql = "UPDATE product SET stock = stock - 1 WHERE id = ?";// 执行更新...}
}
2.4使用InnoDB引擎:
InnoDB引擎支持行级锁和事务,适合高并发的秒杀场景。
-- 将商品表的引擎设置为InnoDB
ALTER TABLE product ENGINE=InnoDB;
2.5优化事务范围:
减小事务的范围,尽量在生成订单等操作之前提交事务,减少锁的持有时间。
// 代码示例(优化事务范围)
public class SeckillService {@Transactionalpublic void handleSeckillRequest() {// 处理秒杀请求逻辑// ...// 生成订单数据OrderData orderData = generateOrderData();// 提交事务orderService.createOrder(orderData);}
}
以上是在数据库层面进行秒杀接口的深度优化的一些建议。这些建议包括索引优化、数据库引擎选择、事务控制、查询优化等方面(这只是数据库优化其中的几点),通过合理的配置和优化,可以提高系统的并发处理能力,确保秒杀活动的顺利进行。
3. 使用缓存技术
增加缓存层,将热门数据缓存起来,减轻数据库压力,提高读取速度。
3.1. 选择合适的缓存系统:
选择适合自己业务场景的缓存系统,常见的包括:
- Redis: 支持多种数据结构,适用于缓存和计数器等场景。
- Memcached: 简单高效,适用于简单的键值缓存。
- Ehcache: Java本地缓存库,适用于单节点缓存。
3.2. 缓存热门商品信息:
将热门商品信息缓存在缓存中,避免每次请求都访问数据库。
// 商品信息缓存
public class ProductCache {private static final Cache<Integer, Product> productCache = Caffeine.newBuilder().maximumSize(1000) // 缓存容量.expireAfterWrite(10, TimeUnit.MINUTES) // 缓存过期时间.build();public Product getSeckillProductInfo(int productId) {Product product = productCache.get(productId, key -> ProductDAO.get(productId));return product;}
}
3.3. 缓存热门商品列表:
缓存热门商品列表,避免频繁查询数据库。
// 热门商品列表缓存
public class PopularProductCache {private static final Cache<String, List<Product>> popularProductCache = Caffeine.newBuilder().maximumSize(10) // 缓存容量.expireAfterWrite(5, TimeUnit.MINUTES) // 缓存过期时间.build();public List<Product> getPopularProducts() {return popularProductCache.get("popular", key -> ProductDAO.getPopularProducts());}
}
3.4. 使用缓存刷新策略:
设置合适的缓存刷新策略,确保缓存中的数据保持与数据库一致。
// 商品信息缓存刷新策略
public class ProductCache {private static final Cache<Integer, Product> productCache = Caffeine.newBuilder().maximumSize(1000) // 缓存容量.expireAfterWrite(10, TimeUnit.MINUTES) // 缓存过期时间.refreshAfterWrite(1, TimeUnit.MINUTES) // 刷新间隔.build();public Product getSeckillProductInfo(int productId) {return productCache.get(productId, key -> refreshProductInfo(productId));}private Product refreshProductInfo(int productId) {// 从数据库中重新加载商品信息return ProductDAO.get(productId);}
}
3.5. 使用缓存预热:
在系统启动时,预先加载热门数据到缓存中,提高系统初始性能。
// 缓存预热
public class CacheWarmUp {@PostConstructpublic void warmUpCache() {// 预先加载热门商品信息到缓存中List<Integer> popularProductIds = ProductDAO.getPopularProductIds();for (int productId : popularProductIds) {ProductCache.getSeckillProductInfo(productId);}}
}
以上是一些使用缓存技术的具体建议,通过合理选择缓存系统、缓存热门数据、设置刷新策略和预热缓存,可以显著提高系统的读取速度,降低对数据库的压力,特别在高并发的秒杀场景下,是确保系统稳定性和性能的重要手段。
4. 异步处理订单
在高并发的秒杀场景下,异步处理订单是一种有效的策略,可以降低同步处理的压力,提高系统的吞吐量。以下是一些关于如何异步处理订单的具体建议:
4.1. 选择合适的消息队列系统:
选择适合业务需求的消息队列系统,常见的包括:
- RabbitMQ: 稳定可靠,支持多种消息模型。
- Kafka: 高吞吐量,适用于分布式系统。
- ActiveMQ: 开源的JMS消息队列,支持多种传输协议。
4.2. 订单生成异步化:
将订单生成过程异步化,将订单信息发送到消息队列,由后台异步处理。
// 订单生成异步化
public class OrderService {@Autowiredprivate RabbitTemplate rabbitTemplate;public void createOrderAsync(OrderData orderData) {rabbitTemplate.convertAndSend("order-exchange", "order.create", orderData);}
}
4.3. 异步处理订单消息监听:
设置订单处理的消息监听器,监听消息队列中的订单消息,并进行处理。
// 异步处理订单消息监听
@Component
public class OrderMessageListener {@RabbitListener(queues = "order.create.queue")public void handleMessage(OrderData orderData) {// 处理订单逻辑// ...}
}
4.4. 保证消息的可靠性:
设置消息队列的确认机制,保证消息的可靠性投递。
// RabbitMQ消息确认机制配置
@Configuration
public class RabbitMQConfig {@Beanpublic RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {if (!ack) {// 消息发送失败的处理逻辑}});return rabbitTemplate;}
}
4.5. 处理失败消息的重试和补偿:
设置消息队列的重试机制和补偿机制,确保订单处理失败时能够及时重试或进行补偿。
// RabbitMQ消息重试和补偿配置
@Configuration
public class RabbitMQConfig {@Beanpublic SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();factory.setConnectionFactory(connectionFactory);factory.setConcurrentConsumers(3); // 并发消费者数量factory.setMaxConcurrentConsumers(10); // 最大并发消费者数量factory.setAcknowledgeMode(AcknowledgeMode.MANUAL); // 手动确认模式factory.setDefaultRequeueRejected(false); // 不重新入队列factory.setErrorHandler(new ConditionalRejectingErrorHandler(new CustomFatalExceptionStrategy())); // 自定义异常处理策略factory.setRetryTemplate(new RetryTemplate()); // 重试模板return factory;}
}
通过异步处理订单,可以将订单生成和处理过程解耦,提高系统的吞吐量和性能。选择合适的消息队列系统、确保消息的可靠性、设置消息的监听器和确认机制,以及处理失败消息的重试和补偿,都是确保异步处理订单稳定可靠的关键步骤。
5. 水平扩展
考虑对系统进行水平扩展,通过增加服务器节点来分担负载。
5.1. 负载均衡:
使用负载均衡器,将流量均匀分发到多个服务器节点上,避免单一节点负载过重。
- 硬件负载均衡器: 使用专门的硬件设备,如F5、Citrix等。
- 软件负载均衡器: 使用软件实现,如Nginx、HAProxy等。
5.2. 横向添加服务器节点:
逐步增加服务器节点,将请求分发到不同的节点上,实现水平扩展。
- 云服务提供商: 使用云服务提供商的弹性伸缩功能,根据需求动态增加或减少节点。
- 容器化: 使用容器化技术,如Docker、Kubernetes等,方便快速部署和扩展。
5.3. 数据库水平分片:
对于数据库,考虑水平分片,将数据分布在不同的数据库节点上,减轻数据库压力。
- 分库分表: 将数据按照一定规则划分到不同的数据库或表中。
- 数据库读写分离: 将读和写分布在不同的数据库节点上,提高数据库并发能力。
5.4. 服务的横向拆分:
将系统中的服务进行横向拆分,拆分成多个微服务,每个微服务可以独立部署和扩展。
- 微服务架构: 使用微服务架构,如Spring Cloud、Dubbo等,将系统拆分成多个小服务。
- API网关: 使用API网关来统一管理和分发请求到不同的微服务。
5.5. 监控和自动化:
确保系统的监控和自动化机制,及时发现节点故障和负载情况,自动进行水平扩展。
- 监控工具: 使用监控工具,如Prometheus、Grafana等,实时监测系统的状态。
- 自动化脚本: 编写自动化脚本,根据负载情况自动进行节点的增加或减少。
5.6. 弹性计算和容灾:
考虑系统的弹性计算和容灾能力,确保在节点故障时系统依然可用。
- 弹性伸缩: 根据负载情况动态调整节点数量,确保系统弹性。
- 容灾方案: 设计容灾方案,保证系统在某个节点或区域发生故障时能够继续提供服务。
通过以上水平扩展的方法,可以有效应对系统负载的增加,提高系统的可用性、性能和弹性。在实际应用中,根据具体业务需求和系统特点选择和实施这些扩展方法。
6、 灰度发布和回滚
在采取一些重要的优化或改动时,通过灰度发布逐步验证新的方案,并建立回滚机制,确保在出现问题时能够迅速回退。
7、总结
这些方案的选择取决于具体的业务场景、系统架构和实际问题的症结。通常需要进行系统性能测试,综合考虑系统的可伸缩性、容错性和稳定性,寻找出一个最适合当前情况的综合性解决方案。
祝屏幕前的帅哥美女们,每天都好运爆棚!笑口常开!
相关文章:

深入探讨生产环境中秒杀接口并发量剧增、负载过高的情况该如何应对?
目录 引言 1. 实施限流措施 1.1 令牌桶算法: 1.2 漏桶算法: 1.3 使用限流框架: 2. 优化数据库操作 2.1. 索引优化 2.2. 批量操作减少交互次数: 2.3. 避免全表扫描: 2.4使用InnoDB引擎: 2.5优化事…...

C语言再学习 -- C语言搭建TCP服务器/客户端
TCP/UDP讲过~ 参看:UNIX再学习 – TCP/UDP 客户机/服务器 这里记录一下可用的TCP服务器和客户端代码。 参看:用C语言搭建TCP服务器/客户端 一、TCP服务器 #include <stdio.h> #include <sys/socket.h> #include <sys/types.h> #inc…...
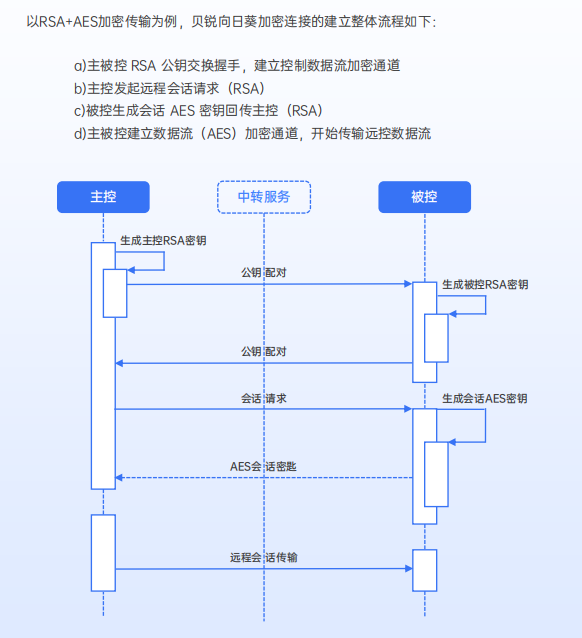
企业远程控制如何保障安全?向日葵“全流程安全远控闭环”解析
远程控制为企业带来的便利与业务上的赋能是显而易见的,但很多企业依然对广泛的使用远程控制持一个观望的态度,其中最主要的原因,就是安全。 由于远程控制的原理和特性,它天然地会成为一个企业信息安全敏感领域,企业在…...
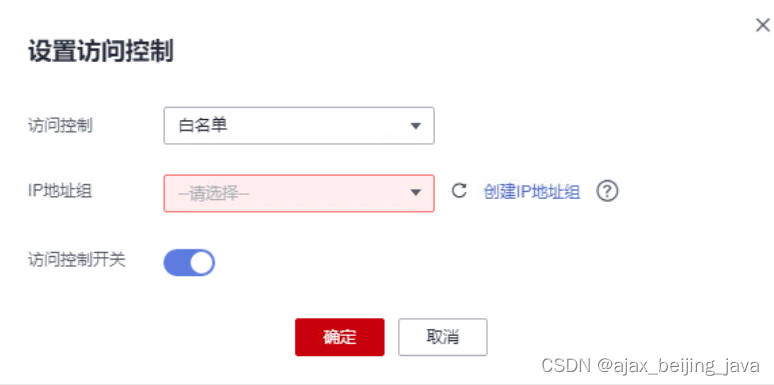
为什么需要放行回源IP
为什么需要放行回源IP 网站以“独享模式”成功接入WAF后,所有网站访问请求将先经过独享引擎配置的ELB然后流转到独享引擎实例进行监控,经独享引擎实例过滤后再返回到源站服务器,流量经独享引擎实例返回源站的过程称为回源。在服务器看来&…...
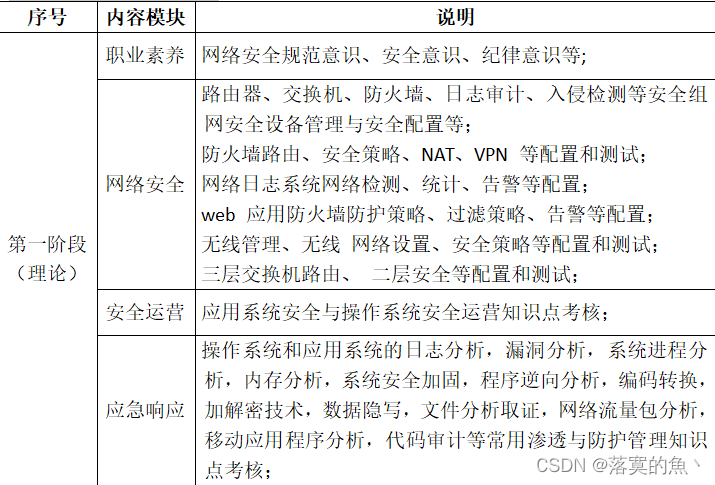
2023一带一路暨金砖国家技能发展与技术创新大赛“网络安全”赛项省选拔赛样题卷②
2023金砖国家职业技能竞赛"网络安全" 赛项省赛选拔赛样题 2023金砖国家职业技能竞赛 省赛选拔赛样题第一阶段:职业素养与理论技能项目1. 职业素养项目1. 职业素养项目2. 网络安全项目3. 安全运营 第二阶段:安全运营项目1. 操作系统安全配置与加…...
C语言:预处理详解
创作不易,来个三连呗! 一、预定义符号 C语⾔设置了⼀些预定义符号,可以直接使⽤,预定义符号也是在预处理期间处理的。 __FILE__ //进⾏编译的源⽂件 __LINE__ //⽂件当前的⾏号 __DATE__ //⽂件被编译的⽇期 __TIME__ //⽂件被编…...
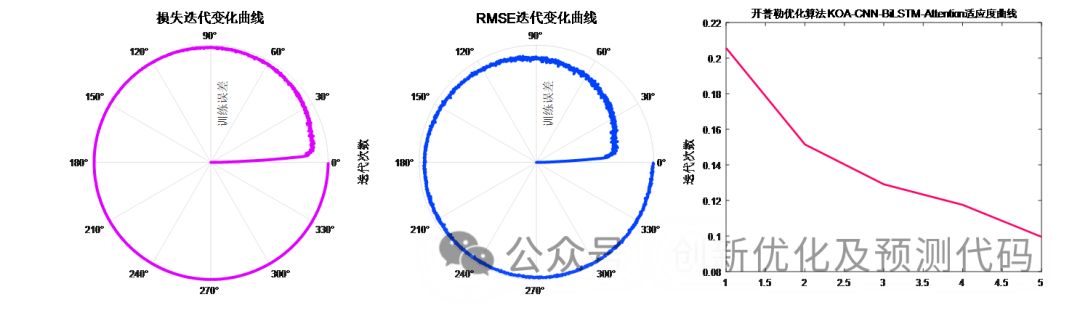
一区优化直接写:KOA-CNN-BiLSTM-Attention开普勒优化卷积、长短期记忆网络融合注意力机制的多变量回归预测程序!
适用平台:Matlab 2023版及以上 KOA开普勒优化算法,于2023年5月发表在SCI、中科院1区Top顶级期刊《Knowledge-Based Systems》上。 该算法提出时间很短,目前还没有套用这个算法的文献。 同样的,我们利用该新鲜出炉的算法对我们的…...

高防IP如何有效应对网站DDOS攻击
高防IP如何有效应对网站DDOS攻击?随着互联网的发展,网站安全问题变得越来越重要。DDoS攻击作为一种常见的网络攻击方式,给网站的稳定性和可用性带来了巨大威胁。而高防IP作为一种专业的网络安全解决方案,能够有效地应对DDoS攻击&a…...

1.6 面试经典150题 - 跳跃游戏
跳跃游戏 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 class Solution…...
Apache安全及优化
配置第一台虚拟机 VM1网卡 yum仓库 挂载磁盘 上传3个软件包到/目录 到/目录下进行解压缩 tar xf apr-1.6.2.tar.gz tar xf apr-util-1.6.0.tar.gz tar -xjf httpd-2.4.29.tar.bz2 mv apr-1.6.2 httpd-2.4.29/srclib/apr mv apr-util-1.6…...

【话题】边缘计算的挑战和机遇
边缘计算是一种新的计算范式,其核心是在网络边缘处理数据,而不是传统的中心式云计算模式。这种计算方式的兴起得益于物联网(IoT)的普及和丰富的云服务的成功。 机遇: 响应时间优化:由于数据处理更接近数据…...

react之unpkg.com前端资源加载慢、加载不出
文章目录 react之unpkg.com前端资源加载慢什么是unpkg.com加载慢原因解决方案替换国内cdn在 package.json 中打包进来 react之unpkg.com前端资源加载慢 什么是unpkg.com unpkg 是一个内容源自 npm 的全球快速 CDN。 作为前端开发者,我们对 unpkg 都不陌生&#x…...

C++类与对象【对象模型和this指针】
🌈个人主页:godspeed_lucip 🔥 系列专栏:C从基础到进阶 🎄1 C对象模型和this指针🌶️1.1 成员变量和成员函数分开存储🌶️1.2 this指针概念🌶️1.3 空指针访问成员函数🌶…...

策略模式在工作中的运用
前言 在不同的场景下,执行不同的业务逻辑,在日常工作中是很寻常的事情。比如,订阅系统。在收到阿里云的回调事件、与收到AWS的回调事件,无论是收到的参数,还是执行的逻辑都可能是不同的。为了避免,每次新增…...

【go】依赖倒置demo
文章目录 前言1 项目目录结构:2 初始化函数3 router4 api5 service6 dao7 Reference 前言 为降低代码耦合性,采用依赖注入的设计模式。原始请求路径:router -> api -> service -> dao。请求的为实际方法,具有层层依赖的…...

C++ //练习 2.5 指出下述字面值的数据类型并说明每一组内几种字面值的区别:
C Primer(第5版) 练习 2.5 练习 2.5 指出下述字面值的数据类型并说明每一组内几种字面值的区别: ( a ) ‘a’, L’a’, “a”, L"a" ( b ) 10, 10u, 10L, 10uL, 012, 0xC ( c ) 3.14, 3.14f, 3.14L ( d ) 10, 10u, 10., 10e-2…...

必示科技助力中国联通智网创新中心通过智能化运维(AIOps)通用能力成熟度3级评估
2023年12月15日,中国信息通信研究院隆重公布了智能化运维AIOps系列标准最新批次评估结果。 必示科技与中国联通智网创新中心合作的“智能IT故障监控定位分析能力建设项目”通过了中国信息通信研究院开展的《智能化运维能力成熟度系列标准 第1部分:通用能…...
python数字图像处理基础(九)——特征匹配
目录 蛮力匹配(ORB匹配)RANSAC算法全景图像拼接 蛮力匹配(ORB匹配) Brute-Force匹配非常简单,首先在第一幅图像中选取一个关键点然后依次与第二幅图像的每个关键点进行(描述符)距离测试&#x…...

k8s的对外服务ingress
1、service的作用体现在两个方面 (1)集群内部:不断跟踪pod的变化,更新deployment中的pod对象,基于pod的ip地址不断变化的一种服务发现机制 (2)集群外部:类似于负载均衡器ÿ…...

[足式机器人]Part2 Dr. CAN学习笔记- Kalman Filter卡尔曼滤波器Ch05-3+4
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记 - Kalman Filter卡尔曼滤波器 Ch05-34 3. Step by step : Deriation of Kalmen Gain 卡尔曼增益/因数 详细推导4. Priori/Posterrori error Covariance Martix 误差协方差矩阵 3. Step by step :…...
)
protobufjs 编译命令选错就报错?一文搞懂 pbjs 的 -w 参数(es6 vs commonjs 实战解析)
ProtobufJS编译模块类型选型指南:ES6与CommonJS的深度对比与实战避坑 最近在Vite项目中集成Protobuf时,编译后的模块导入总是抛出The requested module does not provide an export named错误。这个问题困扰了我整整两天,最终发现根源在于pbj…...

为汉语辩护,彰显中华文字的生命力与优越性
为汉语辩护,彰显中华文字的生命力与优越性上世纪初,一批所谓“新文化人”竟提出废除汉字的主张,他们盲目推崇拉丁文,认为汉语是落后的语言,却不知这是对中华文字深厚底蕴的无知与曲解。如今回望,汉字的独特…...
)
别再死记硬背公式了!用VHDL和Quartus II手把手教你玩转一位全加器(附完整源码与仿真)
从零实现数字逻辑:用VHDL在Quartus II中构建全加器的完整指南 当第一次接触数字逻辑设计时,那些抽象的真值表和逻辑表达式常常让人望而生畏。作为一名曾经同样困惑的工程师,我深刻理解初学者面对理论知识与实际工程实现之间的鸿沟。本文将带你…...

告别桌面混乱!用Utools的「本地文件启动」功能,5分钟打造你的专属文件启动器
告别桌面混乱!用Utools的「本地文件启动」功能,5分钟打造你的专属文件启动器 每次打开电脑,看到满屏的文件图标和杂乱无章的文件夹,是不是感觉工作效率瞬间降了一半?作为一名长期与文件打交道的专业人士,我…...

微信聊天记录完整导出指南:无需越狱的本地化解决方案
微信聊天记录完整导出指南:无需越狱的本地化解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 在数字时代,微信聊天记录承载着珍贵的工作沟…...
)
别再手动算考勤了!我用Python+企业微信API写了个自动统计脚本(附源码)
告别手工考勤:Python企业微信API自动化统计实战指南 每次月底统计考勤时,行政同事总要加班到深夜,手动核对上百条打卡记录。迟到、早退、外勤打卡...各种状态让人眼花缭乱。作为技术团队的一员,我决定用Python企业微信API打造一个…...
)
华为云Stack网络排障实战:用ovs-appctl命令追踪VXLAN隧道里的数据包(附详细命令解析)
华为云Stack网络排障实战:VXLAN隧道数据包追踪与流表解析 在云计算的复杂网络环境中,VXLAN技术已经成为构建大规模虚拟网络的核心方案。作为华为云Stack的运维工程师或网络管理员,掌握VXLAN隧道中的数据包追踪技术至关重要。本文将深入探讨如…...

Perplexity搜索效率提升73%的6个隐藏技巧:资深AI分析师亲测有效
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索效率提升73%的底层动因解析 Perplexity 作为新一代语义优先的AI搜索引擎,其搜索延迟中位数从 1.84s 降至 0.50s(实测提升 73%),这一突破并…...

英雄联盟LCU工具集LeagueAkari:终极自动化游戏助手完整指南
英雄联盟LCU工具集LeagueAkari:终极自动化游戏助手完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基于…...

LeetCode 重新安排行程题解
LeetCode 重新安排行程题解 题目描述 给定一个机票列表,从起点出发,重新安排行程。 示例: 输入:tickets [["MUC","LHR"],["JFK","MUC"],["SFO","SJC"],["LHR&…...