C语言:预处理详解
创作不易,来个三连呗!

一、预定义符号
C语⾔设置了⼀些预定义符号,可以直接使⽤,预定义符号也是在预处理期间处理的。
__FILE__ //进⾏编译的源⽂件
__LINE__ //⽂件当前的⾏号
__DATE__ //⽂件被编译的⽇期
__TIME__ //⽂件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义

VS不支持ANSI C,但是gcc是支持的。
二、#define定义常量
基本语法:
#define name stuff //name代表符号名,stuff代表内容
本质:将内容在符号名处原原本本地替换。
使用举例:
1、定义一个常量的标识符。
#define MAX 10002、给较长的关键字(比如register)创建一个简短的名字
#define reg register//为register这个关键字创建一个简短的名字
3、用更形象的符号来替换一种实现。
如果在我们书写程序时想写一个无限循环,我们可以这样写
int main()
{for ( ; ; ) //for循环什么判断都不写的时候表示恒成立;return 0;
}而我们可以#define定义一个符号来方便我们完成这种实现
#define do_forever for(;;) 程序就可以这样写:
#define do_forever for(;;)
int main()
{do_forever;return 0;
}4、在写case语句时自动把break写上
我们知道在使用switch时,如果步骤特别繁琐,那么每次都得加个break,很麻烦,所以我们想了一种方式。
#define CASE break;case利用这个#define定义的符号,我们可以这样使用。

5、如果定义的stuff过长,可以分成几行写,除了最后一行外,每行的后面都要加一个反斜杠(续航符)
#define DEBUG_PRINT printf("file:%s\tline:%d\t \date:%s\ttime:%s\n" ,\__FILE__,__LINE__ , \__DATE__,__TIME__ ) 
注意:define定义标识符的时候尽量不要往后加 ; 这样容易导致问题
三、#define定义宏
#define 机制包括了⼀个规定,允许把参数替换到⽂本中,这种实现通常称为宏(macro)或定义宏 (define macro)。
计算机科学里的宏是一种抽象(Abstraction),它根据一系列预定义的规则替换一定的文本模式。解释器或编译器在遇到宏时会自动进行这一模式替换。对于编译语言,宏展开在编译时发生,进行宏展开的工具常被称为宏展开器。
下⾯是宏的申明⽅式:
#define name( parament-list ) stuff//parement-list 即参数表注意:参数列表的左括号必须与name紧贴,如果两者之间有任何空白存在,参数列表就会呗解释为stuff的一部分。
使用举例:
1、利用#define定义宏求一个数的平方
#define SQUARE( x ) x * x这个宏接收⼀个参数 x .如果在上述声明之后,你把 SQUARE( 5 ); 置于程序中,预处理器就会⽤ 下⾯这个表达式替换上⾯的表达式: 5 * 5

观察第54行的语句,关于SQUARE(a+1),按道理应该打印36,为什么打印的时11??
我们发现替换之后,参数x被替换成了a+1,所以这条语句实际上变成了
printf ("%d\n",a + 1 * a + 1 );这就说明,通过替换产生的表达式并没有按照我们希望的次序去执行
要怎么解决呢?? 加括号就可以解决!!通过括号来保证计算顺序
#define SQUARE(x) (x) * (x)
这样该行的语句被替换为
printf ("%d\n",(a + 1) * (a + 1) );2、利用#define定义宏求一个数的两倍
吸取上次的经验,我们给宏定义的参数加上括号,因此我们会这样写
#define DOUBLE(x) (x) + (x)

这时又出现了问题,第62行代码按道理应该输出100,但是却输出了55。
我们发现替换之后:
printf("%d\n", 10*(5)+(5));说明此时乘法运算优先于宏定义的加法,导致了计算不达预期。
要怎么解决呢?? 再外部再加一个大括号,来保证宏定义的加法在乘法运算之前!
#define DOUBLE( x) ( ( x ) + ( x ) )此时语句被替换为
printf("%d\n", 10*((5)+(5)));总结:
1、#define定义宏并不具备计算能力,他只负责将文本内容原原本本地替换!!
2、⽤于对数值表达式进⾏求值的宏定义都应该⽤这种⽅式加上括号,避免在使⽤宏时由于参数中的 操作符或邻近操作符之间不可预料的相互作⽤。
四、带有副作用的宏参数
当宏参数在宏的定义中出现超过⼀次的时候,如果参数带有副作⽤,那么你在使⽤这个宏的时候就可 能出现危险,导致不可预测的后果。副作⽤就是表达式求值的时候出现的永久性效果。
例如:
x+1;//不带副作⽤
x++;//带有副作⽤通过下面代码来证明具有副作用参数所引起的问题。

我们发现第70行代码经过预处理后是这样的
int z = ( (x++) > (y++) ? (x++) : (y++));参数带有副作用会导致参数本身也被改变!
我们发现最后x加了1,y加了2,如果我交换原先x和y的值

发现x加了2,y加了1。这说明我们传入的参数产生了无法预料的结果!
结论:因为参数是完全不加替换带进去的,所以如果传入带有副作用的参数,可能会存在一些潜在的风险,无法预期后果,所以我们平时要尽量避免使用带有副作用的宏参数。
五、宏替换的规则
在程序中扩展#define定义符号和宏时,需要涉及⼏个步骤。
1. 在调⽤宏时,首先先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们⾸先被替换。
2. 替换⽂本随后被插⼊到程序中原来⽂本的位置。对于宏,参数名被他们的值所替换。
3. 最后,再次对结果⽂件进⾏扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上 述处理过程
注意:
1. 宏参数和#define 定义中可以出现其他#define定义的符号。但是对于宏,不能出现递归。
#define M 10
#define MAX(M,3+5) 2. 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。
#define M 10
printf("M");//M在字符串内部,不会被搜索六、宏和函数的区别
宏通常被应⽤于执⾏简单的运算。
⽐如在两个数中找出较⼤的⼀个时,写成下⾯的宏,更有优势⼀些。
#define MAX(a, b) ((a)>(b)?(a):(b))那为什么不⽤函数来完成这个任务?
6.1 宏的优势
1. ⽤于调⽤函数和从函数返回的代码可能⽐实际执⾏这个⼩型计算⼯作所需要的时间更多。所以宏⽐ 函数在程序的规模和速度方面更胜⼀筹。

我们发现这两种方法达到了一致的效果,但是我们可以观察一下反汇编就可以知道效率。
这是定义宏的方法计算a+b需要的步骤

这是函数的方法计算a+b需要的步骤

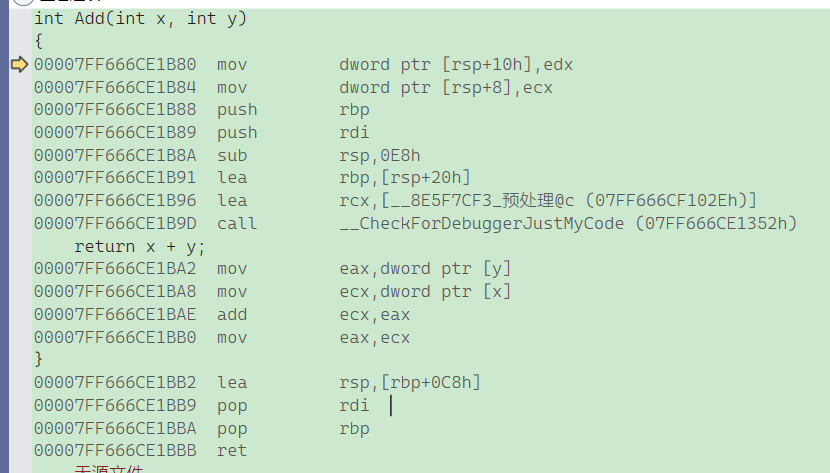
函数调用时还需要给函数创建函数栈帧,所以相比宏效率更低点。
2. 更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使⽤。反之 这个宏怎可以适⽤于整形、⻓整型、浮点型等可以⽤于 > 来⽐较的类型。宏是类型⽆关的。
6.2 宏的劣势
1. 每次使⽤宏的时候,⼀份宏定义的代码将插⼊到程序中。除⾮宏⽐较短,否则可能⼤幅度增加程序 的⻓度。
2. 宏是没法调试的。
3. 宏由于类型⽆关,也就不够严谨。
4. 宏可能会带来运算符优先级的问题,导致程容易出现错。
6.3 宏有时可以做到函数做不到的事情
宏的参数可以出现类型,但是函数做不到!!
假设我们需要频繁使用malloc,但是malloc书写较为繁琐,我们可以这样:
#define MALLOC(num, type)\(type*)malloc(num*sizeof(type))...
//使⽤MALLOC(10, int);//类型作为参数
//预处理器替换之后:(int*)malloc(10*sizeof(int));
6.4 宏和函数的全面对比

七、#define和typedef的区别
#define与typedef大体功能都是使用时给一个对象取一个别名,增强程序的可读性,但它们在使用时有以下几点区别:
1、原理不同
#define是C语言中定义的语法,是预处理指令,在预处理时进行简单而机械的字符串替换,不作正确性检查,只有在编译已被展开的源程序时才会发现可能的错误并报错。
typedef是关键字,在编译时处理,有类型检查功能。它在自己的作用域内给一个已经存在的类型一个别名,但不能在一个函数定义里面使用typedef。用typedef定义数组、指针、结构等类型会带来很大的方便,不仅使程序书写简单,也使意义明确,增强可读性。
2、功能不同
typedef用来定义类型的别名,起到类型易于记忆的功能。另一个功能是定义机器无关的类型。如定义一个REAL的浮点类型,在目标机器上它可以获得最高的精度:typedef long double REAL, 在不支持long double的机器上,看起来是这样的,typedef double REAL,在不支持double的机器上,是这样的,typedef float REAL
#define不只是可以为类型取别名,还可以定义常量、变量、编译开关等。
3、作用域不同
#define没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用,而typedef有自己的作用域。
4、对指针的操作不同
#define INTPTR1 int*typedef int* INTPTR2;INTPTR1 p1, p2; //int *p1,p2INTPTR2 p3, p4; //int*p3,p4含义分别为:
声明一个指针变量p1和一个整型变量p2
声明两个指针变量p3、p4
#define INTPTR1 int*typedef int* INTPTR2;int a = 1;int b = 2;int c = 3;const INTPTR1 p1 = &a;//const int*p1=&aconst INTPTR2 p2 = &b;//int*const p2=&b 因为int*这个类型是一个整体不能分开 INTPTR2 const p3 = &c;//int*const p3=&c 因为int*这个类型是一个整体不能分开上述代码中,
const INTPTR1 p1是一个常量指针,即不可以通过p1去修改p1指向的内容,但是p1可以指向其他内容。
const INTPTR2 p2是一个指针常量,不可使p2再指向其他内容。因为INTPTR2表示一个指针类型,因此用const限定,表示封锁了这个指针类型。
INTPTR2 const p3是一个指针常量
八、#和##
8.1 #
#运算符将宏的⼀个参数转换为字符串字⾯量。它仅允许出现在带参数的宏的替换列表中。 #运算符所执⾏的操作可以理解为”字符串化“。
当我们有⼀个变量 int a = 10; 的时候,我们想打印出: the value of a is 10 .
我们可以这样:
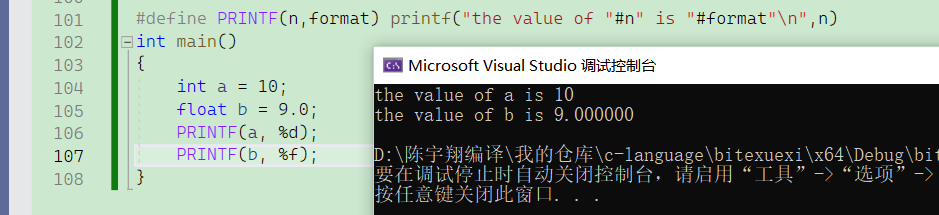
当我们把n和format替换到宏体内时,就会出现#n和#format,他的意义就是将n和format分别转换成“n”和“format”。
8.2 ##
## 可以把位于它两边的符号合成⼀个符号,它允许宏定义从分离的文本⽚段创建标识符。 ## 被称 为记号粘合
这样的连接必须产⽣⼀个合法的标识符。否则其结果就是未定义的。
这⾥我们想想,写⼀个函数求2个数的较⼤值的时候,不同的数据类型就得写不同的函数。
比如:
int int_max(int x, int y)
{return x>y?x:y;
}
float float_max(float x, float y)
{return x>yx:y;
}
但是这样写起来确实很繁琐,所以我们可以使用宏,去定义一个通用的定义函数模板
#define GENERIC_MAX(type)\
type type##_max(type x, type y)\
{ \return (x>y?x:y); \
}
//GENERIC泛型使用这个宏去定义不同的函数并使用
GENERIC_MAX(int) //替换到宏体内后int##_max ⽣成了新的符号 int_max做函数名
GENERIC_MAX(float) //替换到宏体内后float##_max ⽣成了新的符号 float_max做函数名
int main()
{//调⽤函数int m = int_max(2, 3);printf("%d\n", m);float fm = float_max(3.5f, 4.5f);printf("%f\n", fm);return 0;
}运行结果:3 4.500000
在实际开发过程中##使⽤的很少
九、命名约定
⼀般来讲函数的宏的使⽤语法很相似。
所以语⾔本⾝没法帮我们区分⼆者。
那我们平时的⼀个习惯是:
把宏名全部大写
函数名不要全部大写
十、#undef
这条指令⽤于移除⼀个宏定义。
#undef NAME
//如果现存的⼀个名字需要被重新定义,那么它的旧名字⾸先要被移除。十一、命令行定义
许多C 的编译器提供了⼀种能⼒,允许在命令⾏中定义符号。⽤于启动编译过程。 例如:当我们根据同⼀个源⽂件要编译出⼀个程序的不同版本的时候,这个特性有点⽤处。(假定某 个程序中声明了⼀个某个⻓度的数组,如果机器内存有限,我们需要⼀个很⼩的数组,但是另外⼀个 机器内存⼤些,我们需要⼀个数组能够⼤些。)
#include <stdio.h>
int main()
{int array [ARRAY_SIZE];int i = 0;for(i = 0; i< ARRAY_SIZE; i ++){array[i] = i;}for(i = 0; i< ARRAY_SIZE; i ++){printf("%d " ,array[i]);}printf("\n" );return 0;
}编译指令:
//linux 环境演⽰
gcc -D ARRAY_SIZE=10 programe.c十二、条件编译
在编译⼀个程序的时候我们如果要将⼀条语句(⼀组语句)编译或者放弃是很⽅便的。因为我们有条 件编译指令。
比如说:
调试性的代码,删除可惜,保留⼜碍事,所以我们可以选择性的编译。
常见的条件编译指令:
1.
#if 常量表达式 //为真编译,为假不编译//...
#endif
//常量表达式由预处理器求值。
如:
#define __DEBUG__ 1
#if __DEBUG__//..
#endif
2.多个分⽀的条件编译 //只编译满足条件的一条
#if 常量表达式//...
#elif 常量表达式 //...
#else//...
#endif
3.判断是否被定义
#if defined(symbol) //定义过编译,没定义过不编译
#ifdef symbol
#if !defined(symbol) //没定义过编译,定义过不编译
#ifndef symbol
4.嵌套指令 //嵌套指令下,一个条件是否编译可能需要判断2次以上
#if defined(OS_UNIX)#ifdef OPTION1unix_version_option1();
#endif#ifdef OPTION2unix_version_option2(); #endif
#elif defined(OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif
#endif举例:
#include <stdio.h>
#define __DEBUG__
int main()
{
int i = 0;int arr[10] = {0};for(i=0; i<10; i++){arr[i] = i;#ifdef __DEBUG__printf("%d\n", arr[i]);//为了观察数组是否赋值成功。 #endif //__DEBUG__}return 0;
}
易错点:

a==10,明明是真的,为什么还是不编译??
因为条件编译的语句在预处理的时候就已经做出判断了!而参数a是在执行程序的过程中才出现的!所以对于条件编译来说,他并不认识a!
结论:使用条件编译时,给的条件一定不要用参数,最好使用常量
十三、头文件的包含
13.1 头文件的包含方式
13.1.1 本地文件包含
1 #include "filename"
查找策略:先在源文件所在⽬录下查找,如果该头文件未找到,编译器就像查找库函数头⽂件⼀样在 标准位置查找头文件。 如果找不到就提示编译错误。
Linux环境的标准头⽂件的路径:
/usr/includeVS2022环境的标准头⽂件的路径:
C:\Program Files (x86)\Windows Kits\10\Include\10.0.22621.0\ucrt
//vs2022默认路径13.1.2 库文件包含
#include <filename.h>查找头文件直接去库文件标准路径下去查找,如果找不到就提示编译错误。
这样是不是可以说,对于库⽂件也可以使⽤ “ ” 的形式包含?
答案是可以的,但是这样做会有两个问题:
1、对于库文件来说,用< >可以直接到库文件路径去寻找,但是如果改成“ ”,会先在源文件所在目录下查找,然后才去库文件路径查找,但我们知道库文件在源文件目录是不可能找得到的,所以这样是没有意义的,还会导致查找效率降低。
2、在未来书写大量代码时,我们经常需要写多个头文件,如果不加以区分,就难以很快地判断出哪些文件是库文件哪些文件是本地文件。
13.2 嵌套文件包含
我们已经知道, #include 指令可以使另外⼀个⽂件被编译。就像它实际出现于 #include 指令的地⽅⼀样。
这种替换的⽅式很简单:预处理器先删除这条指令,并⽤包含⽂件的内容替换。
⼀个头⽂件被包含10次,那就实际被编译10次,如果重复包含,对编译的压⼒就⽐较⼤。
test.c
#include "test.h"
#include "test.h"
#include "test.h"
#include "test.h"
#include "test.h"
int main()
{return 0;
}
test.h
void test();
struct Stu
{int id;char name[20];
};如果直接这样写,test.c⽂件中将test.h包含5次,那么test.h⽂件的内容将会被拷⻉5份在test.c中。 如果test.h ⽂件⽐较⼤,这样预处理后代码量会剧增。如果⼯程⽐较⼤,有公共使⽤的头⽂件,被⼤家 都能使⽤,⼜不做任何的处理,那么后果真的不堪设想。
未来当我们的代码量增大时,重复包含的情况很容易就发生,所以我们就得采取措施。
方法就是条件编译。
在每个头文件的开头这样写
#ifndef __TEST_H__
#define __TEST_H__
//头⽂件的内容
#endif //__TEST_H__
//解析:第一次检索的时候,该头文件还没定义,所以条件判断为假,输出了头文件的内容
//第二次检索同类型文件的时候,因为头文件已经定义了,所以条件判断永远真!
//因此该方法可以保证头文件只被包含一次。或者
#pragma once
//保证头文件只被编译一次就可以避免头⽂件的重复引入。
13.3 头文件的本质作用
头文件的本质作用就是:当其他源文件包含该头文件时,在预处理时就会先删除这条指令,然后用包含文件的内容替换。这种方法可以使得不同源文件之间的函数和声明可以互相使用。
如果你想在一个源文件中使用该工程下另一个源文件的函数,那么有两种方法:
1、包含一个头文件,这个头文件有函数的声明。
add.h
#include<stdo.h>
int add(int x,int y);add.c
int add(int x, int y)
{
return x+y;
}test.c
#include"add.h"
int main()
{
int a=10;
int b=10;
printf("%d",add(a,b));
}2、使用extern声明外部函数。
add.c
int add(int x, int y)
{
return x+y;
}test.c
#include<stdio.h>
extern int add(int x,int y);//外部声明函数
int main()
{
int a=10;
int b=10;
printf("%d",add(a,b));
}13.4 两道经典笔试题
出自《⾼质量C/C++编程指南》
1. 头⽂件中的 ifndef/define/endif是⼲什?
答:防止头文件被重复包含
2. #include <filename.h>和 #include"filename.h"有什么区别?
答:< >是针对标准库文件的包含,查找策略是直接去标准库所在路径下查找,而“ ”是针对自定义头文件的包含,查找策略是先去当前工程的源目录底下查找,找不到再去标准库文件所在的路径查找。一般我们写代码时习惯用< >包含库文件,“ ”包含自定义的本地头文件,这样方便我们区分文件类型。
十四、其他预处理指令
#error //当预处理器预处理遇到#error命令时停止编译并输出用户自定义的错误消息
#pragma//用于指示编译器完成一些特定的动作
//(1) #pragma message 用于自定义编译信息
//(2)#pragma once 用于保证头文件只被编译一次
//(3)#pragama pack用于指定内存对齐(一般用在结构体)struct占用内存大小
#line// 指令指示预处理器将编译器的行号和文件名报告值设置为给定行号和文件名。参考书籍:《C语言深度解剖》
相关文章:
C语言:预处理详解
创作不易,来个三连呗! 一、预定义符号 C语⾔设置了⼀些预定义符号,可以直接使⽤,预定义符号也是在预处理期间处理的。 __FILE__ //进⾏编译的源⽂件 __LINE__ //⽂件当前的⾏号 __DATE__ //⽂件被编译的⽇期 __TIME__ //⽂件被编…...
一区优化直接写:KOA-CNN-BiLSTM-Attention开普勒优化卷积、长短期记忆网络融合注意力机制的多变量回归预测程序!
适用平台:Matlab 2023版及以上 KOA开普勒优化算法,于2023年5月发表在SCI、中科院1区Top顶级期刊《Knowledge-Based Systems》上。 该算法提出时间很短,目前还没有套用这个算法的文献。 同样的,我们利用该新鲜出炉的算法对我们的…...

高防IP如何有效应对网站DDOS攻击
高防IP如何有效应对网站DDOS攻击?随着互联网的发展,网站安全问题变得越来越重要。DDoS攻击作为一种常见的网络攻击方式,给网站的稳定性和可用性带来了巨大威胁。而高防IP作为一种专业的网络安全解决方案,能够有效地应对DDoS攻击&a…...

1.6 面试经典150题 - 跳跃游戏
跳跃游戏 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 class Solution…...
Apache安全及优化
配置第一台虚拟机 VM1网卡 yum仓库 挂载磁盘 上传3个软件包到/目录 到/目录下进行解压缩 tar xf apr-1.6.2.tar.gz tar xf apr-util-1.6.0.tar.gz tar -xjf httpd-2.4.29.tar.bz2 mv apr-1.6.2 httpd-2.4.29/srclib/apr mv apr-util-1.6…...

【话题】边缘计算的挑战和机遇
边缘计算是一种新的计算范式,其核心是在网络边缘处理数据,而不是传统的中心式云计算模式。这种计算方式的兴起得益于物联网(IoT)的普及和丰富的云服务的成功。 机遇: 响应时间优化:由于数据处理更接近数据…...

react之unpkg.com前端资源加载慢、加载不出
文章目录 react之unpkg.com前端资源加载慢什么是unpkg.com加载慢原因解决方案替换国内cdn在 package.json 中打包进来 react之unpkg.com前端资源加载慢 什么是unpkg.com unpkg 是一个内容源自 npm 的全球快速 CDN。 作为前端开发者,我们对 unpkg 都不陌生&#x…...

C++类与对象【对象模型和this指针】
🌈个人主页:godspeed_lucip 🔥 系列专栏:C从基础到进阶 🎄1 C对象模型和this指针🌶️1.1 成员变量和成员函数分开存储🌶️1.2 this指针概念🌶️1.3 空指针访问成员函数🌶…...

策略模式在工作中的运用
前言 在不同的场景下,执行不同的业务逻辑,在日常工作中是很寻常的事情。比如,订阅系统。在收到阿里云的回调事件、与收到AWS的回调事件,无论是收到的参数,还是执行的逻辑都可能是不同的。为了避免,每次新增…...

【go】依赖倒置demo
文章目录 前言1 项目目录结构:2 初始化函数3 router4 api5 service6 dao7 Reference 前言 为降低代码耦合性,采用依赖注入的设计模式。原始请求路径:router -> api -> service -> dao。请求的为实际方法,具有层层依赖的…...

C++ //练习 2.5 指出下述字面值的数据类型并说明每一组内几种字面值的区别:
C Primer(第5版) 练习 2.5 练习 2.5 指出下述字面值的数据类型并说明每一组内几种字面值的区别: ( a ) ‘a’, L’a’, “a”, L"a" ( b ) 10, 10u, 10L, 10uL, 012, 0xC ( c ) 3.14, 3.14f, 3.14L ( d ) 10, 10u, 10., 10e-2…...

必示科技助力中国联通智网创新中心通过智能化运维(AIOps)通用能力成熟度3级评估
2023年12月15日,中国信息通信研究院隆重公布了智能化运维AIOps系列标准最新批次评估结果。 必示科技与中国联通智网创新中心合作的“智能IT故障监控定位分析能力建设项目”通过了中国信息通信研究院开展的《智能化运维能力成熟度系列标准 第1部分:通用能…...
python数字图像处理基础(九)——特征匹配
目录 蛮力匹配(ORB匹配)RANSAC算法全景图像拼接 蛮力匹配(ORB匹配) Brute-Force匹配非常简单,首先在第一幅图像中选取一个关键点然后依次与第二幅图像的每个关键点进行(描述符)距离测试&#x…...

k8s的对外服务ingress
1、service的作用体现在两个方面 (1)集群内部:不断跟踪pod的变化,更新deployment中的pod对象,基于pod的ip地址不断变化的一种服务发现机制 (2)集群外部:类似于负载均衡器ÿ…...

[足式机器人]Part2 Dr. CAN学习笔记- Kalman Filter卡尔曼滤波器Ch05-3+4
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记 - Kalman Filter卡尔曼滤波器 Ch05-34 3. Step by step : Deriation of Kalmen Gain 卡尔曼增益/因数 详细推导4. Priori/Posterrori error Covariance Martix 误差协方差矩阵 3. Step by step :…...
关于前端面试中forEach方法的灵魂7问?
目录 前言 一、forEach方法支持处理异步函数吗? 二、forEach方法在循环过程中能中断吗? 三、forEach 在删除自己的元素后能重置索引吗? 四、forEach 的性能相比for循环哪个好? 五、使用 forEach 会不会改变原来的数组&#…...

AI小程序添加深度合成类目解决办法
基于文言一心和gpt等大模型做了一个ai助理小程序,在提交“一点AI助理”小程序时,审核如下: 失败原因1 审核失败原因 你好,你的小程序涉及提供提供文本深度合成技术 (如: AI问答) 等相关服务,请补充选择:深度…...

C/C++ BM6判断链表中是否有环
文章目录 前言题目解决方案一1.1 思路阐述1.2 源码 解决方案二2.1 思路阐述2.2 源码 总结 前言 做了一堆单链表单指针的题目,这次是个双指针题,这里双指针的作用非常明显。 题目 判断给定的链表中是否有环。如果有环则返回true,否则返回fal…...

【Java 设计模式】结构型之适配器模式
文章目录 1. 定义2. 应用场景3. 代码实现结语 适配器模式(Adapter Pattern)是一种结构型设计模式,用于将一个类的接口转换成客户端期望的另一个接口。这种模式使得原本由于接口不兼容而不能一起工作的类可以一起工作。在本文中,我…...
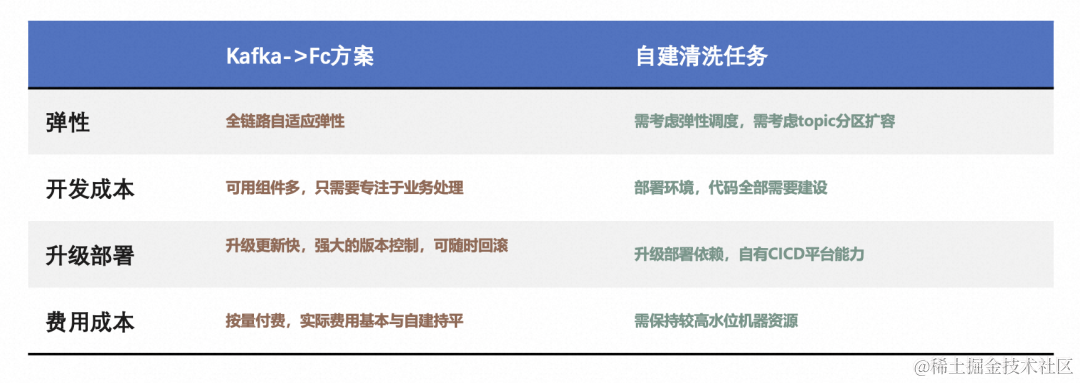
使用函数计算,数禾如何实现高效的数据处理?
作者:邱鑫鑫,王彬,牟柏旭 公司背景和业务 数禾科技以大数据和技术为驱动,为金融机构提供高效的智能零售金融解决方案,服务银行、信托、消费金融公司、保险、小贷公司等持牌金融机构,业务涵盖消费信贷、小…...

使用Taotoken聚合端点一个月,我的API调用延迟与稳定性观察记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken聚合端点一个月,我的API调用延迟与稳定性观察记录 1. 项目背景与接入动机 我最近的一个个人项目需要持续…...

从零部署SAM自动标注工具链:模型转换、交互标注与格式实战
1. 环境准备与项目部署 第一次接触SAM自动标注工具时,我被它强大的零样本分割能力震撼到了。这个由Meta开源的Segment Anything Model(SAM)确实改变了传统标注工作的游戏规则。下面我就带大家从零开始搭建整套工具链,过程中会分享…...

区块链跨链桥接:原理与实现
区块链跨链桥接:原理与实现 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊区块链跨链桥接这个重要话题。作为一个Web3探索者,跨链技术是连接不同区块链生态的关键。今天就来分享一下跨链桥接的原理和实现方式。 什…...
的时序数据分解与重构)
Python实战:基于奇异谱分析(SSA)的时序数据分解与重构
1. 奇异谱分析(SSA)入门指南 第一次接触奇异谱分析(SSA)时,我被它优雅的数学结构和强大的分析能力所吸引。SSA本质上是一种将时间序列分解为趋势、周期和噪声成分的非参数方法,特别适合处理那些传统方法难以应对的非线性、非平稳时序数据。 SSA的核心思想…...

手把手教你搞定KEIL4.74社区版激活:从注册到填问卷拿License的全流程避坑
KEIL 4.74社区版激活全流程实战指南:从零开始到成功获取License的完整攻略 作为一名嵌入式开发新手,第一次接触KEIL这个强大的开发环境时,难免会被其复杂的激活流程搞得晕头转向。特别是社区版的KEIL 4.74,虽然免费,但…...

Python随机密码生成器实战
求赞 求关注 当然写的不怎么好,因为我才刚初一,更新速度也慢。 如果想下载这里有链接 https://download.csdn.net/download/mc54321/91240180 正文开始 在编写这个程序我们需要导入random模块。 import random random 模块是 Python 标准库中的一个…...
添加远程桌面控制功能)
libvncserver实战:给你的嵌入式Linux设备(如树莓派)添加远程桌面控制功能
libvncserver嵌入式实战:为树莓派等设备构建轻量级远程桌面方案 在工业控制、智能家居和边缘计算场景中,嵌入式设备的远程可视化操作需求日益增长。传统方案如SSH仅能提供命令行交互,而完整的桌面环境又过于臃肿。本文将展示如何利用libvncse…...

Formation:macOS前端开发环境一键配置终极指南
Formation:macOS前端开发环境一键配置终极指南 【免费下载链接】formation 💻 macOS setup script for front-end development 项目地址: https://gitcode.com/gh_mirrors/fo/formation Formation是一款专为macOS设计的前端开发环境配置脚本&…...

解决Keil MDK中STM32 I2C驱动编译错误
1. 问题现象与背景分析最近在使用Keil MDK开发STM32项目时,遇到一个典型的编译错误。具体表现为:当使用STM32CubeMX生成项目并导入Keil MDK后,编译过程中CMSIS I2C驱动报出以下错误:error: use of undeclared identifier MX_I2C1_…...

ARM Trace Buffer架构与调试优化实践
1. ARM Trace Buffer架构解析Trace Buffer是ARM处理器中用于实时捕获指令执行轨迹的专用硬件模块,它通过独立的缓冲区和控制逻辑实现低开销的程序流监控。在ARMv8/v9架构中,Trace Buffer Extension(TRBE)作为可选的硬件扩展&#…...