大数据开发之Hadoop(优化新特征)
第 1 章:HDFS-故障排除
注意:采用三台服务器即可,恢复到Yarn开始的服务器快照。
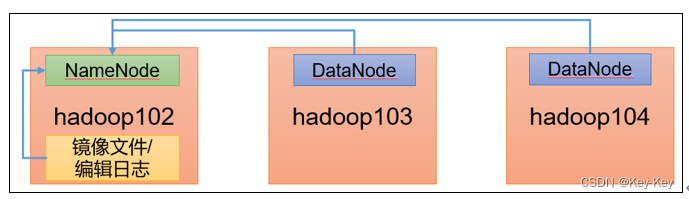
1.1 集群安全模块
1、安全模式:文件系统只接收读数据请求,而不接收删除、修改等变更请求
2、进入安全模式场景
1)NameNode在加载镜像文件和编辑日志期间处于安全模式
2)NameNode再接收DataNode注册时,处于安全模式
3)退出安全模式条件
dfs.namenode.safemode.min.datanodes:最小可用datanode数量,默认0
dfs.namenode.safemode.threshold-pct:副本数达到最小要求的block占系统总block数的百分比,默认0.999f
dfs.namenode.safemode.extension:稳定时间,默认30000毫秒,即30秒
4)基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)1.2 NameNode故障处理
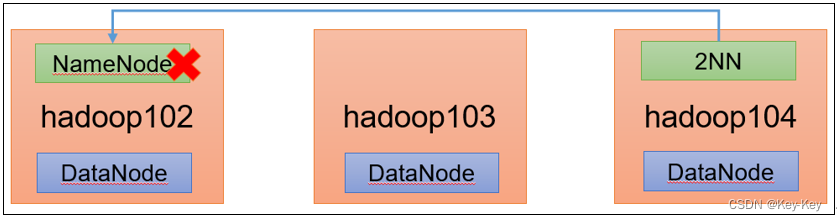
1、需求:
NameNode进程挂了并且存储的数据也丢失了,如何恢复NameNode
2、故障模拟
1)kill -9 NameNode进程
[atguigu@hadoop102 current]$ kill -9 NameNode的进程号
2)删除NameNode存储的数据
[atguigu@hadoop102 hadoop-3.1.3]$ rm -rf /opt/module/hadoop-3.1.3/data/dfs/name/*
3、问题解决
1)拷贝SecondaryNameNode中数据到原NameNode存储数据据目录
[atguigu@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-3.1.3/data/dfs/namesecondary/* ./name/
2)重新启动NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs --daemon start namenode
3)向集群上传一个文件
1.3 磁盘修复
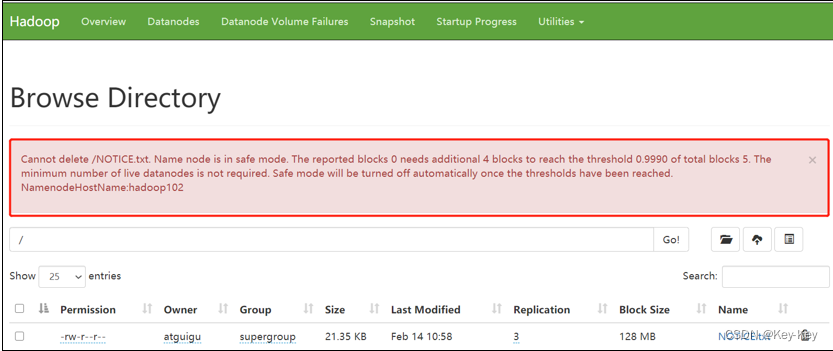
案例1:启动集群进入安全模式
1、重新启动集群
[atguigu@hadoop102 subdir0]$ myhadoop.sh stop
[atguigu@hadoop102 subdir0]$ myhadoop.sh start2、集群启动后,立即来到集群上删除数据,提示集群处理安全模式
案例2:磁盘修复
需求:数据库损失,进入安全模式,如何处理
1、分别进入hadoop102、103、104的/opt/module/hadoop-3.1.3/data/dfs/data/current/BP~/subdir0目录,统一删除某2个块信息
[atguigu@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1015489500-192.168.10.102-1611909480872/current/finalized/subdir0/subdir0[atguigu@hadoop102 subdir0]$ rm -rf blk_1073741847 blk_1073741847_1023.meta
[atguigu@hadoop102 subdir0]$ rm -rf blk_1073741865 blk_1073741865_1042.meta说明:hadoop103/hadoop104重复执行以上命令
2、重新启动集群
[atguigu@hadoop102 subdir0]$ myhadoop.sh stop
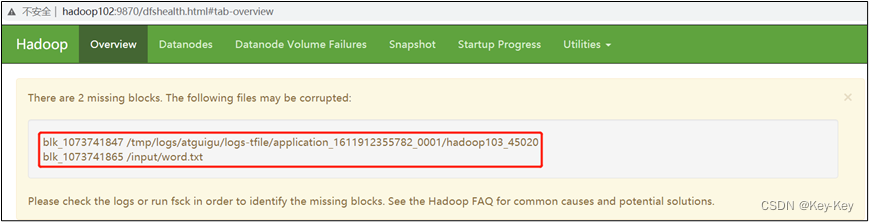
[atguigu@hadoop102 subdir0]$ myhadoop.sh start3、观察http://hadoop102:9870/dfshealth.html#tab-overview

说明:安全模式已经打开,块的数量没有达到要求
4、离开安全模式
[atguigu@hadoop102 subdir0]$ hdfs dfsadmin -safemode get
Safe mode is ON
[atguigu@hadoop102 subdir0]$ hdfs dfsadmin -safemode leave
Safe mode is OFF5、观察http://hadoop102:9870/dfshealth.html#tab-overview
6、将元数据删除
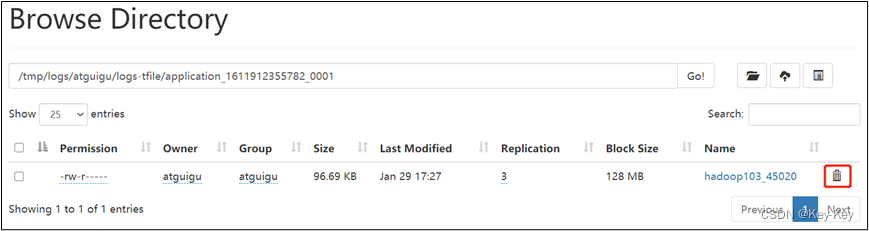
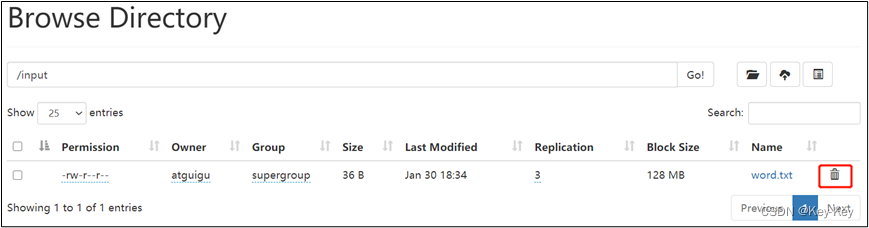
7、观察http://hadoop102:9870/dfshealth.html#tab-overview,集群已经正常
案例3:
需求:模拟等待安全模式
1、查看当前模式
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -safemode get
Safe mode is OFF2、先进入安全模式
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs dfsadmin -safemode enter
3、创建并执行下面的脚本
在opt/module/hadoop-3.1.3路径上,编辑一个脚本safemode.sh
[atguigu@hadoop102 hadoop-3.1.3]$ vim safemode.sh#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-3.1.3/README.txt /[atguigu@hadoop102 hadoop-3.1.3]$ chmod 777 safemode.sh[atguigu@hadoop102 hadoop-3.1.3]$ ./safemode.sh 4、再打开一个窗口,执行
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs dfsadmin -safemode leave
5、再观察上一个窗口
Safe mode is OFF
6、HDFS集群上已经有上传的数据了

第 2 章:HDFS-多目录
2.1 DataNode多目录配置
1、DataNode可用配置成多个目录,每个目录存储的数据不一样(数据不是副本)

2、具体配置如下:
在hdfs-site.xml文件中添加如下内容:
<property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>3、查看结果
[atguigu@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data1
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data2
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name24、向集群上传一个文件,再次观察两个文件夹里面的内容发现不一致(一个有数一个没数)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /
2.2 集群数据均衡之磁盘间数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可用执行磁盘均衡命令。

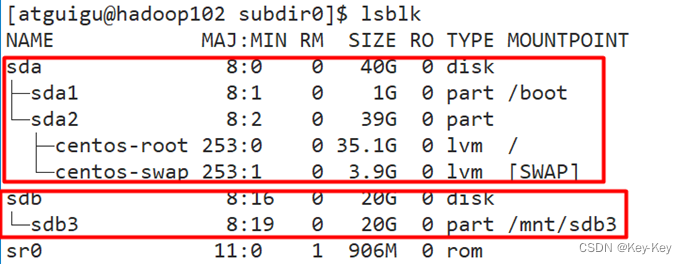
1、生产均衡计划(只有一块磁盘,不会生成计划)

2、执行均衡计划
hdfs diskbalancer -execute hadoop102.plan.json
3、查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop102
4、取消均衡任务
hdfs diskbalancer -cancel hadoop102.plan.json
第 3 章:HDFS-集群扩容及缩容
3.1 服役新服务器
1、需求
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点
2、环境准备
1)在hadoop100主机上再克隆一台hadoop105主机
2)修改IP地址和主机名称
[root@hadoop105 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop105 ~]# vim /etc/hostname3)拷贝hadoop102的/opt/module目录和/etc/profile.d/my_env.sh到hadoop105
[atguigu@hadoop102 opt]$ scp -r module/* atguigu@hadoop105:/opt/module/[atguigu@hadoop102 opt]$ sudo scp /etc/profile.d/my_env.sh root@hadoop105:/etc/profile.d/my_env.sh[atguigu@hadoop105 hadoop-3.1.3]$ source /etc/profile4)删除hadoop105上Hadoop的历史数据,data和log数据
[atguigu@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
5)配置hadoop102和hadoop103到hadoop105的ssh无密登录
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop105
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop1053、服役新节点具体步骤
1)直接启动DataNode,即可关联到集群
[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon start nodemanager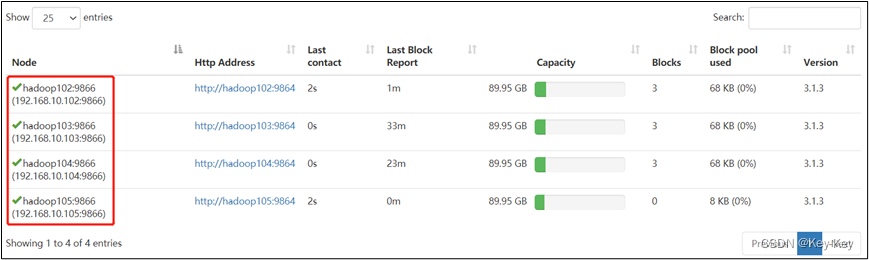
4、在白名单中增加新服役的服务器
1)在白名单whitelist中增加hadoop104、105,并重启集群
[atguigu@hadoop102 hadoop]$ vim whitelist
修改如下内容:
hadoop102
hadoop103
hadoop104
hadoop1052)分发
[atguigu@hadoop102 hadoop]$ xsync whitelist
3)刷新NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful5、在hadoop105上上传文件
[atguigu@hadoop105 hadoop-3.1.3]$ hadoop fs -put /opt/module/hadoop-3.1.3/LICENSE.txt /
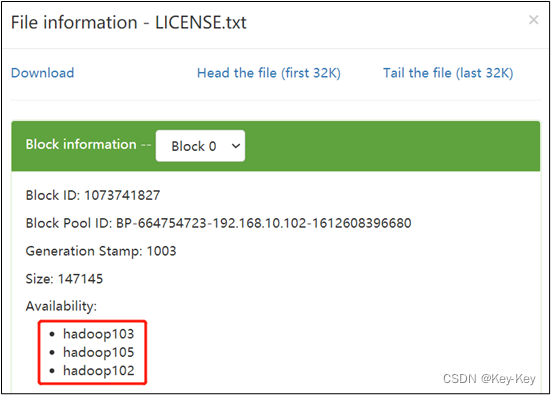
思考:如果数据不均衡(hadoop105数据少,其它节点数据多),怎么处理?
3.2 服务器间数据均衡
1、企业经验:
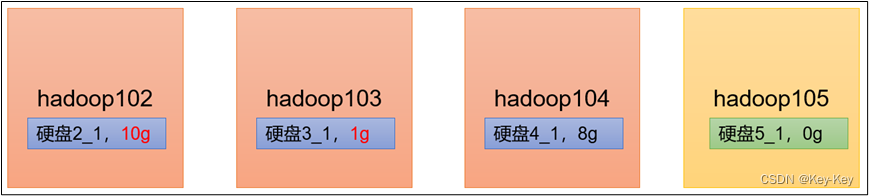
在企业开发中,如果经常在hadoop102和hadoop104上提交任务,且副本数为2,由于数据本地性原则,就会导致102和104数据过多,103存储的数据量小。
另一种情况,就是新服役的服务器数据量比较少,需要执行集群均衡命令。
2、开启数据均衡命令:
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
3、停止数据均衡命令
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/stop-balancer.sh
注意:由于HDFS需要启动单独的Rebalance Server来执行Rebalance操作,所以经量不要在NameNode上执行start-balancer.sh,而是找一台比较空闲的机器。
3.3 添加白名单
白名单:表示在白名单的主机IP地址可用,用来存储数据。
企业中:配置白名单,可用尽量防止黑客恶意访问攻击。
配置白名单步骤如下:
1、在NameNode节点的/opt/~/hadoop目录下创建whitelist和blacklist文件
1)创建白名单
[atguigu@hadoop102 hadoop]$ vim whitelist
在whitelist中添加如下主机名称,加入集群正常工作的节点为102 103
hadoop102
hadoop1032)创建黑名单
[atguigu@hadoop102 hadoop]$ touch blacklist
保持空的就可用
2、在hdfs-site.xml配置文件中增加dfs.hosts配置参数
<!-- 白名单 -->
<property><name>dfs.hosts</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property><!-- 黑名单 -->
<property><name>dfs.hosts.exclude</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>3、分发配置文件whitelist、hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml whitelist
4、第一次添加白名单必须重启集群,不是第一次,只需要刷新NameNode节点即可
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh start5、在web浏览器上查看DN,http://hadoop102:9870/dfshealth.html#tab-datanode
6、二次修改白名单,增加hadoop104
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容
hadoop102
hadoop103
hadoop104
hadoop1057、刷新NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
8、在web浏览器上查看DN,http://hadoop102:9870/dfshealth.html#tab-datanode
3.4 黑名单退役服务器
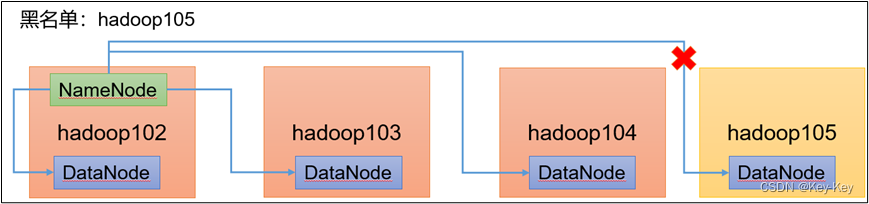
黑名单:表示在黑名单的主机IP地址不可以,用来存储数据
企业中:配置黑名单,用来退役服务器
黑名单配置步骤如下:
1、编辑/opt/module/had~/hadoop目录下的blacklist文件
[atguigu@hadoop102 hadoop] vim blacklist
添加如下主机名称(要退役的节点)
hadoop105
注意:如果白名单中没有配置,需要在hdfs-site.xml配置文件中增加dfs.hosts配置参数
<!-- 黑名单 -->
<property><name>dfs.hosts.exclude</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>2、分发配置文件blacklist,hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml blacklist
3、第一次添加黑名单必须重启集群,不是第一次,只需要刷新NameNode节点即可
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful4、检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其它节点


5、等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役

[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanode
stopping datanode
[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon stop nodemanager
stopping nodemanager
6、如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10
第 4 章:Hadoop企业优化
4.1 MapReduce优化方法
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
4.1.1 数据输入
1、合并小文件:在执行MR任务前将小文件进行合并,大量的小文件会产生大量的Map任务,增大Map任务装载次数,而任务的装载比较耗时,从而导致MR运行较慢。
2、采用CombineTextInputFormat来作为输入,解决输入端大量小文件场景。
4.1.2 Map阶段
1、减少溢出(Spill)次数:通过调整mapreduce.task.io.sort.mb及mapreduce.map.sort.spill.percent参数值,增大触发Spill的内存上限,减少Spill次数,从而减少IO。
2、减少合并(Merge)次数:通过调整mapreduce.task.io.sort.factor参数,增大Merge的文件数目,减少Merge的次数,从而缩短MR处理时间。
3、在Map之后,不影响业务逻辑前提下,先进行Combine处理,减少I/O。
4.1.3 Reduce阶段
1、合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致Map、Reduce任务间竞争资源,造成处理超时等错误。
2、设置Map、Reduce共存:
调整mapreduce.job.reduce.slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
3、规避使用Reduce:因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
4、合理设置Reduce端的Buffer:默认情况下,数据达到一个阈值的时候,Buffer中的数据就会写入磁盘,然后Reduce会从磁盘中获得所有的数据。也就是说,Buffer和Reduce是没有直接关联的,中间多次写磁盘-》读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得Buffer中的一部分数据直接输送到Reducec,从而减少IO开销:mapreduce.reduce.input.buffer.percent,默认为0.0。当值大于0的时候,会保留指定比例的内存读Buffer中的数据直接拿给Reduce使用。这样一来,设置Buffer需要内存,读取数据需要内存,Reduce计算也要内存,所以要根据作业的运行情况进行调整。
4.1.4 I/O传输
1、采用数据压缩的方式,减少网络IO的时间。安装Snappy和LZO压缩编码器。
2、使用SequenceFile二进制文件。
4.1.5 数据倾斜问题
1、数据倾斜现象
数据频率倾斜-某一个区域的数据量要远远大于其它区域
数据大小倾斜-部分记录的大小远远大于平均值
2、减少数据倾斜的方法
方法1:抽样和范围分区
可以通过对原始数据进行抽样得到的结果集来预设分区边界值。
方法2:自定义分区
基于输出键的背景知识进行自定义分区。例如,如果Map输出键的单词来源于一本书。且其中某几个专业词汇较多。那么就可以自定义分区将这些专业词汇发送给固定的一部分Reduce实例。而将其它的都发送给剩余的Reduce实例。
方法3:Combiner
使用Combiner可以大量地减少数据倾斜。在可能地情况下,Combine的目的就是聚合并精简数据。
方法4:采用Map Join,尽量避免Reduce Join。
4.2 常用的调优参数
1、资源相关参数
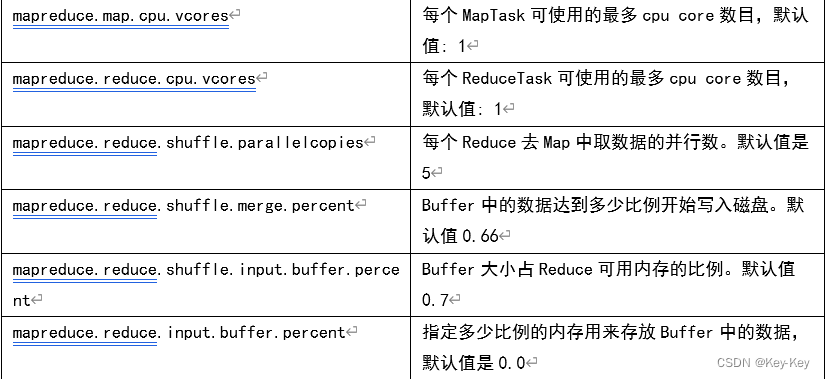
1)以下参数是在用户自己的MR应用程序徐中配置就可以生效(mapred-default.xml)

2)应该在YARN启动之前就配置在服务器的配置文件中才能生效(yarn-default.xml)
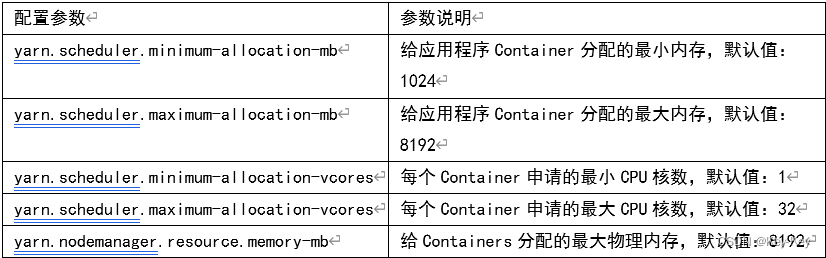
3)Shuffle性能优化的关键参数,应在YARN启动之前就配置好(mapred-default.xml)

2、容错相关参数(MapReduce性能优化)

4.4 Hadoop小文件优化方法
4.4.1 Hadoop小文件弊端
HDFS上每个文件都要在NameNode上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
小文件过多,在进行MR计算时,会生成过多切片,需要启动过多的MapTask。每个MapTask处理的数据量小,导致MapTask的处理时间比启动时间还小,白白浪费资源。
4.4.2 Hadoop小文件解决方案
1、小文件优化的方向:
1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。
4)开启uber模式,实现jvm重用。
2、Hadoop Archive
是一个高效的将小文件放入HDFS块中的文件存档工具,能够将小文件打包成一个HAR文件,从而达到减少NameNode的内存使用。
3、CombineTextInputFormat
CombineTextInputFormat用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片。
4、开启uber模式,实现JVM重用。
默认情况下,每个Task任务都需要启动一个JVM来运行,如果Task任务计算的数据量很小,我们可以让同一个Job的多个Task运行在一个JVM中,不必为每个Task都开启一个JVM。
开启uber模式,在mapred-site.xml中添加如下配置:
<!-- 开启uber模式 -->
<property><name>mapreduce.job.ubertask.enable</name><value>true</value>
</property><!-- uber模式中最大的mapTask数量,可向下修改 -->
<property><name>mapreduce.job.ubertask.maxmaps</name><value>9</value>
</property>
<!-- uber模式中最大的reduce数量,可向下修改 -->
<property><name>mapreduce.job.ubertask.maxreduces</name><value>1</value>
</property>
<!-- uber模式中最大的输入数据量,默认使用dfs.blocksize 的值,可向下修改 -->
<property><name>mapreduce.job.ubertask.maxbytes</name><value></value>
</property>第 5 章:Hadoop扩展
5.1 集群间数据拷贝
1、scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt // 推 pushscp -r root@hadoop103:/user/atguigu/hello.txt hello.txt // 拉 pullscp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。2、采用distcp命令实现两个Hadoop集群之间的递归数据复制
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hadoop distcp hdfs://hadoop102:8020/user/atguigu/hello.txt hdfs://hadoop105:8020/user/atguigu/hello.txt
5.2 小文件存档
1、HDFS存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会消耗NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据库的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
2、解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体来说,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
1、实例
1)需要启动YARN进程
[atguigu@hadoop102 hadoop-3.1.3]$ start-yarn.sh
2)归档文件
把/user/atguigu/input目录里面的所有文件归档成一个交input.har的归档文件,并把归档后文件存储到/user/atguigu/output路径下
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop archive -archiveName input.har -p /user/atguigu/input /user/atguigu/output
3)查看归档
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls har:///user/atguigu/output/input.har
4)解归档文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:/// user/atguigu/output/input.har/* /user/atguigu
5.3 回收站
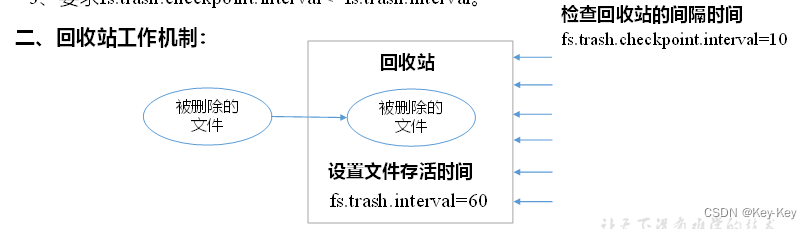
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
1、回收站参数设置及工作机制
1)开启回收站功能参数说明
(1)默认值fs.trash.interval=0,0表示禁用回收站;其他值表示设置文件的存活时间
(2)默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相同。
(3)要求fs.trash.checkpoint.interval<=fs.trash.interval。
2、启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟
<property><name>fs.trash.interval</name><value>1</value>
</property>3、查看回收站
回收站目录在hdfs集群的路径:/user/atguigu/.Trash/…
4、通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Configuration conf = new Configuration();
//设置HDFS的地址
conf.set("fs.defaultFS","hdfs://hadoop102:8020");
//因为本地的客户端拿不到集群的配置信息 所以需要自己手动设置一下回收站
conf.set("fs.trash.interval","1");
conf.set("fs.trash.checkpoint.interval","1");
//创建一个回收站对象
Trash trash = new Trash(conf);
//将HDFS上的/input/wc.txt移动到回收站
trash.moveToTrash(new Path("/input/wc.txt"));5、同故宫网页上直接删除的文件也不会走回收站。
6、只有在命令行利用hadoop fs -rm命令删除的文件才会走回收站
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /user/atguigu/input
7、恢复回收站数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv
/user/atguigu/.Trash/Current/user/atguigu/input /user/atguigu/input相关文章:
大数据开发之Hadoop(优化新特征)
第 1 章:HDFS-故障排除 注意:采用三台服务器即可,恢复到Yarn开始的服务器快照。 1.1 集群安全模块 1、安全模式:文件系统只接收读数据请求,而不接收删除、修改等变更请求 2、进入安全模式场景 1)NameNod…...

在使用go语言开发的时候,程序启动后如何获取程序pid
在Go语言中,标准库并没有直接提供获取进程ID(PID)的函数。通常,你可以使用os包和syscall包来调用底层的操作系统函数来获取PID。 以下是一个获取程序PID的示例代码: package mainimport ("fmt""os&qu…...
HFSS笔记/信号完整性分析(二)——软件仿真设置大全
文章目录 1、多核运算设置1.1 如何设置1.2 如何查看自己电脑的core呢?1.3 查看求解的频点 2、求解模式设置Driven Terminal vs Driven modal 3、Design settings4、自适应网格划分5、更改字体设置 仅做笔记整理与分享。 1、多核运算设置 多核运算只对扫频才有效果&…...

mysql主从报错:Last_IO_Error: Error connecting to source解决方法
目录 报错 处理方法 1.从库停止同步 2.主库修改my.cnf 生效配置default-authentication-pluginmysql_native_password 3.重启服务重新创建复制用户 4.重新同步 5.测试主从 报错 Last_IO_Error: Error connecting to source repl_user192.168.213.15:3306. This was atte…...

AOI与AVI:在视觉检测中的不同点和相似点
AOI(关注区域)和AVI(视觉感兴趣区域)是视觉检测中常用的两个概念,主要用于识别和分析图像或视频中的特定区域。虽然这两个概念都涉及到注视行为和注意力分配,但它们在定义和实际应用等方面有一些差异。 AOI…...

Python爬虫 - 网易云音乐下载
爬取网易云音乐实战,仅供学习,不可商用,出现问题,概不负责! 分为爬取网易云歌单和排行榜单两部分。 因为网页中,只能显示出歌单的前20首歌曲,所以仅支持下载前20首歌曲(非VIP音乐&…...
yarn包管理器在添加、更新、删除模块时,在项目中是如何体现的
技术很久不用,就变得生疏起来。对npm深受其害,决定对yarn再整理一遍。 yarn包管理器 介绍安装yarn帮助信息最常用命令 介绍 yarn官网:https://yarn.bootcss.com,学任何技术的最新知识,都可以通过其对应的网站了解。无…...
)
React实现Intro效果(基础简单)
下载:利用Intro.js实现简单的新手引导 npm install intro.js --save yarn add intro.js 第一步:在我们需要引导的页面引入 import introJs from intro.js; import intro.js/introjs.css; //css是下载成功后就有的 第二步:在组件页面 c…...

HBuilderx发布苹果的包需要注意什么
在HBuilderX中发布苹果的包,需要注意以下几点: 开发者账号注册:在发布应用到App Store之前,需要先注册一个苹果开发者账号。注册过程较为繁琐,需要提供个人信息并支付年费。应用标识和证书:在发布iOS应用之…...
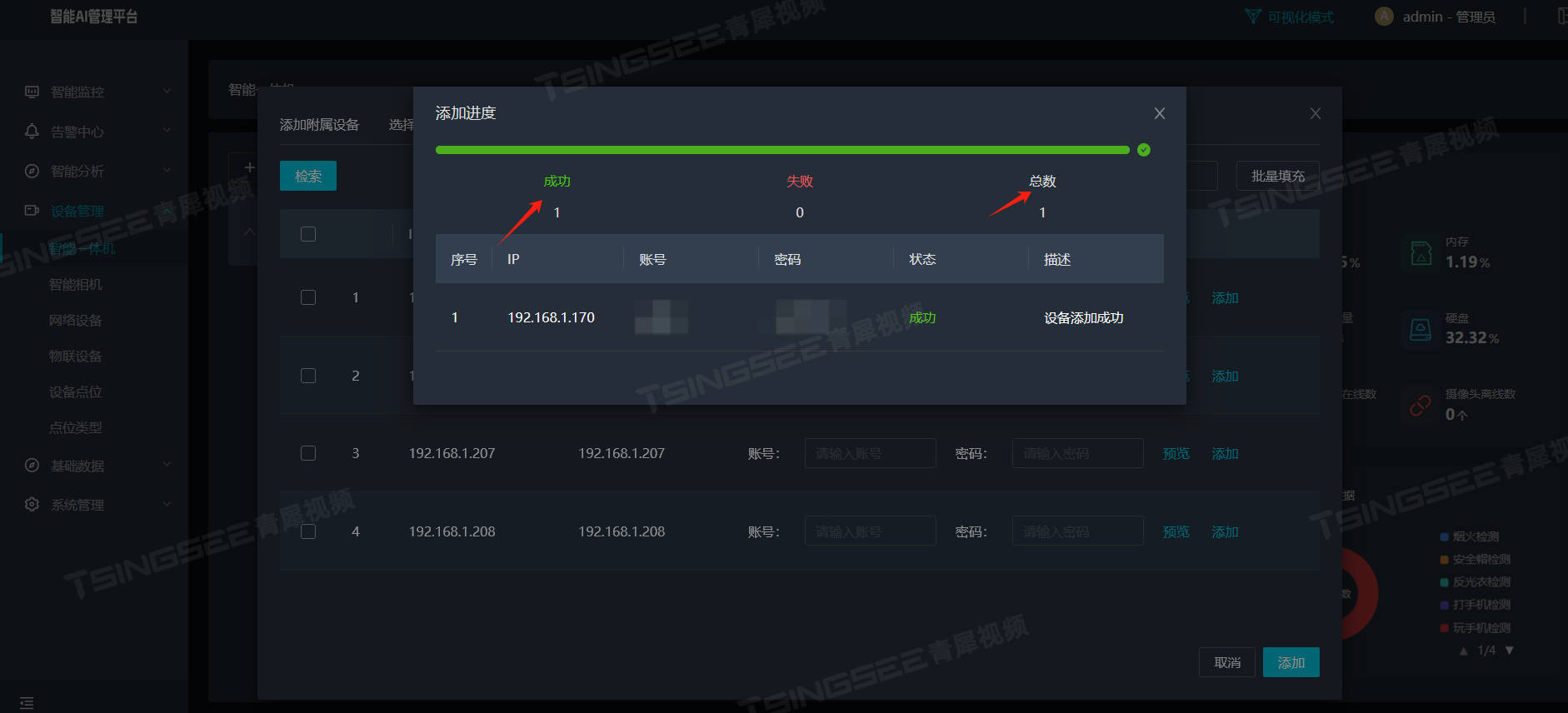
烟火检测/周界入侵/视频智能识别AI智能分析网关V4如何配置ONVIF摄像机接入
AI边缘计算智能分析网关V4性能高、功耗低、检测速度快,易安装、易维护,硬件内置了近40种AI算法模型,支持对接入的视频图像进行人、车、物、行为等实时检测分析,上报识别结果,并能进行语音告警播放。算法可按需组合、按…...

C++ 内联函数
C 内联函数是通常与类一起使用。如果一个函数是内联的,那么在编译时,编译器会把该函数的代码副本放置在每个调用该函数的地方。 对内联函数进行任何修改,都需要重新编译函数的所有客户端,因为编译器需要重新更换一次所有的代码&a…...

微信小程序带参数分享界面、打开界面加载分享内容
分享功能是微信小程序常用功能之一,带参分享和加载可以让分享对象打开界面时看到和分享内容。 带参分享 用户点击微信小程序右上角自带分享,或者点击自定义分享按钮进行分享时,可在onShareAppMessage函数定义分享行为。 分享界面路径可带参…...

中小企业选择CRM系统有哪些注意事项?如何高效实施CRM
阅读本文,你将了解:一、中小型企业对CRM系统的主要需求;二、CRM系统实施策略和优秀实践。 在快速变化的商业环境中,中小型企业面临着独特的挑战:如何在有限的资源下高效地管理客户关系、提升销售效率,保持…...
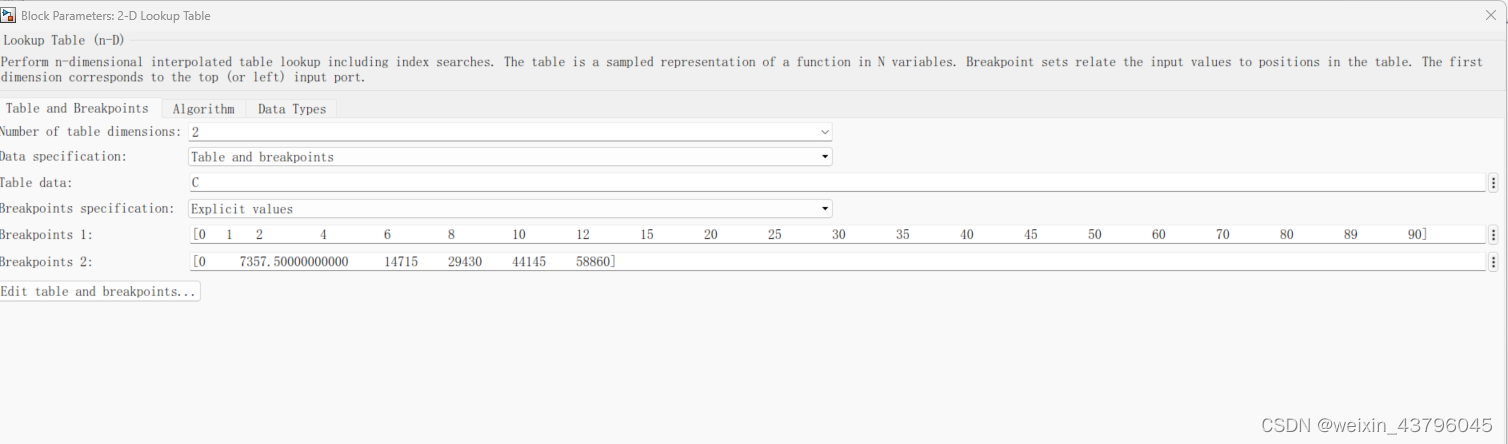
轮胎侧偏刚度线性插值方法
一、trucksim取数据 步骤一 步骤二 二、数据导入到matlab中 利用simulink的look up table模块 1是侧偏角;2是垂直载荷;输出是侧向力。 侧向力除以侧偏角就是实时的侧偏刚度。...

前端JS代码中Object类型数据的相关知识
获取Object类型数据的方式有两种: 方括号获取:Object["arg1"]点获取:Object.arg1 前端遍历Object类型数据的方式 遍历JavaScript中的对象有几种方法,包括使用for…in循环、Object.keys()方法、Object.values()方法和…...
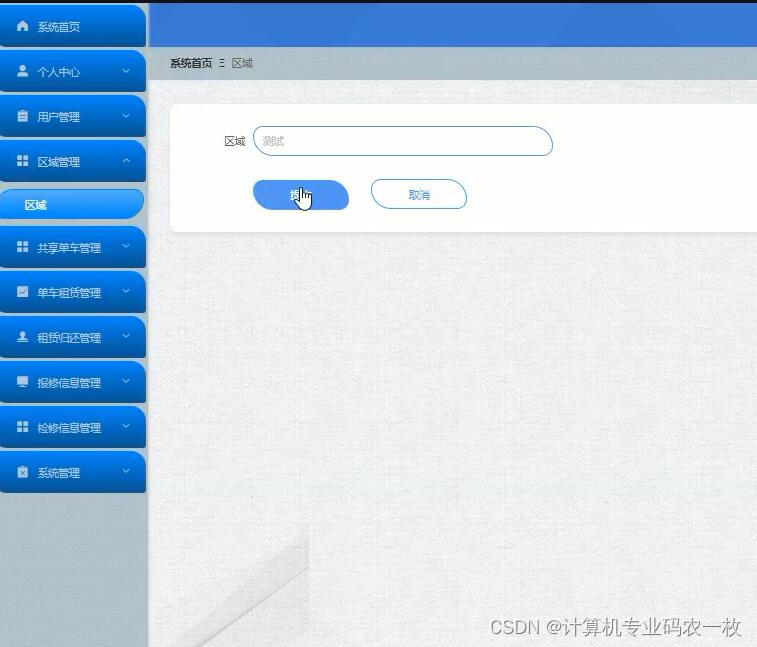
vue基于Spring Boot共享单车租赁报修信息系统
共享单车信息系统分为二个部分,即管理员和用户。该系统是根据用户的实际需求开发的,贴近生活。从管理员处获得的指定账号和密码可用于进入系统和使用相关的系统应用程序。管理员拥有最大的权限,其次是用户。管理员一般负责整个系统的运行维护…...
CentOS 6.10 安装图解
特特特别的说明 CentOS发行版已经不再适合应用于生产环境,客观条件不得不用的话,优选7.9版本,8.5版本次之,最次6.10版本(比如说Oracle 11GR2就建议在6版本上部署)! 引导和开始安装 选择倒计时结…...

Web自动化测试中的接口测试
1、背景 1.1 Web程序中的接口 1.1.1 典型的Web设计架构 web是实现了基于网络通信的浏览器客户端与远程服务器进行交互的应用,通常包括两部分:web服务器和web客户端。web客户端的应用有html,JavaScript,ajax,flash等&am…...

轻松识别Midjourney等AI生成图片,开源GenImage
AIGC时代,人人都可以使用Midjourney、Stable Diffusion等AI产品生成高质量图片,其逼真程度肉眼难以区分真假。这种虚假照片有时会对社会产生不良影响,例如,生成公众人物不雅图片用于散播谣言;合成虚假图片用于金融欺诈…...
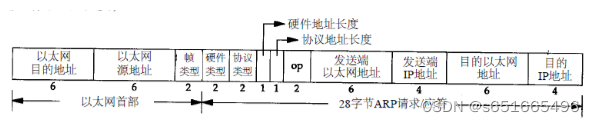
ARP相关
ARP报文格式: 目的以太网地址,48bit,发送ARP请求时,目的以太网地址为广播MAC地址,即0xFF.FF.FF.FF.FF.FF。 源以太网地址,48bit。 帧类型,对于ARP请求或者应答,该字段的值都为0x08…...

毫米波雷达开发者必看:双级联方案如何用DDMA波形实现300米精准测距?
毫米波雷达双级联方案实战:DDMA波形设计如何突破300米测距极限? 当特斯拉HW4.0的雷达模块在暴雨中依然稳定输出300米外的障碍物坐标时,背后的技术密码正是双级联架构与DDMA波形的完美融合。作为L3级自动驾驶系统的"全天候之眼"&am…...

AI辅助开发新思路:让快马平台生成风车动漫智能推荐与摘要代码
用AI辅助开发提升动漫网站体验 最近在做一个动漫网站项目,需要实现智能推荐和内容摘要功能。传统开发方式需要自己写复杂的算法,但借助InsCode(快马)平台的AI辅助功能,可以快速生成代码框架,大大提升开发效率。下面分享我的实现思…...

Halcon点云拼接实战:如何用特征模板搞定3D扫描缺失问题?
Halcon点云拼接实战:特征模板技术在工业3D扫描中的应用 在工业检测和逆向工程领域,3D扫描常常面临一个棘手问题——单次扫描无法完整捕获复杂物体的所有表面细节。想象一下,当您需要检测一个汽车发动机缸体的内部结构,或者重建一…...

5个核心特性让嵌入式设备实现高效安全加密:tiny-AES-c轻量级加密库深度解析
5个核心特性让嵌入式设备实现高效安全加密:tiny-AES-c轻量级加密库深度解析 【免费下载链接】tiny-AES-c Small portable AES128/192/256 in C 项目地址: https://gitcode.com/gh_mirrors/ti/tiny-AES-c 在物联网设备和嵌入式系统的资源受限环境中࿰…...
translategemma-27b-it部署案例:个人开发者用RTX4060实现本地化翻译服务
translategemma-27b-it部署案例:个人开发者用RTX4060实现本地化翻译服务 1. 为什么这个模型值得你花10分钟试试? 你有没有过这样的时刻: 看到一篇技术文档的截图,但图片里的中文说明没法直接复制翻译;收到朋友发来的…...

OpenClaw+Qwen2.5-VL-7B:自动化生成图文报告
OpenClawQwen2.5-VL-7B:自动化生成图文报告 1. 为什么需要自动化图文报告 作为一名数据分析师,我每天都要处理大量数据并生成报告。传统的工作流程是:先整理Excel表格,然后手动截图插入PPT,最后撰写分析文字。这个过…...
)
项目7-5 单表数据记录查询—— 任务7.6.6 查询结果不重复、7.6.7 范围查询、7.6.8 字符匹配查询(二)
项目7-4 单表数据记录查询—— 任务7.6.6 查询结果不重复、7.6.7 范围查询、7.6.8 字符匹配查询(二) 一、教学目标【2分钟】 **二、课程导入【4分钟】** **三、核心内容讲解** **【第一部分:概念讲解】用大白话理解三个关键字** **【第二部分:实操演示】** **四、课堂小结与…...
)
别再为OpenGL窗口发愁了!用Clion+Freeglut 3.4.0快速搭建你的第一个3D立方体(Windows 11环境)
用ClionFreeglut快速搭建3D立方体的完整指南 为什么选择Freeglut而不是GLFW? 对于刚接触OpenGL的开发者来说,第一个拦路虎往往不是图形学原理本身,而是如何快速搭建一个可运行的开发环境。市面上有GLFW、SDL、GLUT等多种窗口管理库…...

用Multisim复刻经典24秒篮球计时器:从555时钟到数码管显示的保姆级仿真教程
用Multisim复刻经典24秒篮球计时器:从555时钟到数码管显示的保姆级仿真教程 篮球比赛中那令人窒息的最后24秒倒计时,不仅是球员的决胜时刻,也是电子爱好者眼中完美的数字电路实践案例。本文将带你用Multisim从零搭建一个完整的24秒计时系统&a…...

千问3.5-2B开源可部署实践:本地GPU环境一键启用,无云服务依赖
千问3.5-2B开源可部署实践:本地GPU环境一键启用,无云服务依赖 1. 模型介绍与核心能力 千问3.5-2B是Qwen系列中的小型视觉语言模型,专为图片理解与文本生成任务设计。这个开源模型最大的特点是能够同时处理视觉和语言信息,实现真…...