产品经理与产品运营的区别和联系
一、两者的职责区别
产品经理的目的:是创造有价值的产品
产品运营的目的:是让产品能有效的发挥出它应有的价值
二、两者的工作内容区别
产品经理的工作内容
产品的经理的目的是创造有价值的产品,因此产品经理的所有工作都是围绕着:
- 如何确定产品的价值;
- 如何将价值有效的体现在产品中;
- 如何保证产品价值不减分的上线;
如何确定产品的价值
创造有价值的产品第一步就是:寻找和确定产品的价值。
决定一个产品的价值主要因素是行业趋势、用户诉求、公司战略。因此,如果产品经理想要做好产品价值确定这件事,就必须做好以下三件事情:
1、常常关注行业动态以及趋势,同时还需要具有敏锐的预测和前瞻能力,尽量让自己的产品能成为“风口上的猪”;
2、了解用户。通过各种用户调研、数据分析、用户访问等方式深入了解和挖掘用户诉求,要让自己的产品能真正为用户带来价值;
3、产品除了需要用户价值之外,还需要给公司带来价值。因此在我们确定一个产品价值的时候需要跟公司本来的战略结合在一起考虑,这样才能保证产品价值的完整性。
如何将价值有效的体现在产品中
当确定好产品价值之后(也就是我们俗称的产品定位和需求分析),接下来就到了规划阶段:如何将价值有效体现在产品中。
这个时候就需要产品经理将产品价值合理的分配在产品功能上。
为了让产品价值分配更合理,产品经理需要定义需求优先级,需要进行需求筛选。
为了让产品价值更高效的体现,产品经理需要对产品进行功能或者信息架构,需要研究用户体验,需要懂得一些交互技巧。
如何保证产品价值不减分上线
当定义好产品之后,产品经理需要保证产品价值加减分上线。因此在此过程产品经理需要做好以下几件事情:
- 产品经理需要借助需求文档、产品原型等工具来向合作部门完整传递产品信息,避免产品价值的在流传中流失。但是需要说明,原型和需求文档永远只是工具,不是产品信息传递的唯一途径。
- 为了保证产品实时上线,产品经理需要实时跟进各部门的进度,及时发现问题和解决问题。
- 在产品上线之前做好充分的测试。
产品运营工作内容
产品运营的主要目的是:是让产品能有效的发挥出它应有的价值
因此运营需要做的事情:
- 让产品获得用户量,将产品的价值带给更多的用户
- 保证用户活跃度,沉睡用户是没有多少商业价值的,若产品想要取得成功就必须要有活跃的用户
- 实现营收,一个好的产品不光能给用户带来价值,同时也能为公司带来价值。
结合上面的三点,我们又可以继续剖析出:
- 运营如果想获得更多的用户量,就必须了解用户,了解产品,能合理运用各种推广渠道和技巧。结合用户、产品、渠道三个方面做运营策划、媒介宣传等。
- 为了保证用户的活跃度,运营首先就必须要做好数据分析,了解用户个方面的数据,根据数据指定运营方案;同时根据用户使用情况及时向产品经理反馈优化建议,避免用户流失。
- 为了让产品实现营收,产品运营需要为产品找到合理且可持续发展的商业模式。同时也需策划各种活动刺激用户的消费,增加产品的营收。
通过上文的内容,可以看产品经理的工作重心赋予产品价值,而产品运营的工作重心是如何让产品发挥出价值。
三、产品经理和产品运营之间的联系
产品经理需要根据产品运营收集到的用户需求对产品进行优化;
产品运营需要根据产品经理对产品价值的定义来制定运营方案;
产品经理与产品运营都需要深入了解用户,产品经理需要通过了解用户来确定产品价值,提升用户体验;产品运营需要通过了解用户来确定符合用户痛点的运营方案。
相关文章:

产品经理与产品运营的区别和联系
一、两者的职责区别 产品经理的目的:是创造有价值的产品 产品运营的目的:是让产品能有效的发挥出它应有的价值 二、两者的工作内容区别产品经理的工作内容 产品的经理的目的是创造有价值的产品,因此产品经理的所有工作都是围绕着…...
CMU15-445-Spring-2023-分布式DBMS初探(lec21-24)
Lecture #21_ Introduction to Distributed Databases Distributed DBMSs 分布式 DBMS 将单个逻辑数据库划分为多个物理资源。应用程序(通常)并不知道数据被分割在不同的硬件上。系统依靠单节点 DBMS 的技术和算法来支持分布式环境中的事务处理和查询执…...

Arch linux 安装
Arch linux 安装 介绍下载制作iSO启动盘安装arch linux设置字体连接互联网 安装过程磁盘分区设置设置镜像源设置引导文件挂载点安装base等基础软件生成fatab文件更改时区更改编码、语言更改编码更改语言 用户管理设置root密码新建普通用户 安装grub启动网络服务/GDM查看系统网络…...
最新ChatGPT/GPT4科研应用与AI绘图及论文高效写作
详情点击链接:最新ChatGPT/GPT4科研应用与AI绘图及论文高效写作 一OpenAI 1.最新大模型GPT-4 Turbo 2.最新发布的高级数据分析,AI画图,图像识别,文档API 3.GPT Store 4.从0到1创建自己的GPT应用 5. 模型Gemini以及大模型Clau…...

【leetcode】移除元素
大家好,我是苏貝,本篇博客带大家刷题,如果你觉得我写的还不错的话,可以给我一个赞👍吗,感谢❤️ 目录 一.暴力求解法二.使用额外数组三.原地修改数组 点击查看题目 一.暴力求解法 若我们不考虑时间复杂度…...
Spring Boot整合Redis的高效数据缓存实践
引言 在现代Web应用开发中,数据缓存是提高系统性能和响应速度的关键。Redis作为一种高性能的缓存和数据存储解决方案,被广泛应用于各种场景。本文将研究如何使用Spring Boot整合Redis,通过这个强大的缓存工具提高应用的性能和可伸缩性。 整合…...
)
FastApi-参数接收的正确使用(2)
前言 本文是该专栏的第2篇,后面会持续分享FastApi以及项目实战的各种干货知识,值得关注。 本文重点介绍,在使用FastApi使用“参数接收”时遇到的三种类型“路径参数”,“查询参数”,“请求体”的相关问题以及相应的解决方案。 具体详细知识点,跟着笔者直接往下看正文。…...
)
三、需求规格说明书(软件工程示例)
1.引言 1.1编写目的 1.2项目背景 1.3定义 1.4参考资料 2.任务概述 2.1目标 2.2运行环境 2.3条件与限制 3.数据描述 3.1静态数据 3.2动态数据 3.3数据库介绍 3.4数据词典 3.5数据采集 4.功能需求 …...

Elasticsearch 查询语句概述
目录 1. Match Query 2. Term Query 3. Terms Query 4. Range Query 5. Bool Query 6. Wildcard Query 7. Fuzzy Query 8. Prefix Query 9. Aggregation Query Elasticsearch 是一个基于 Lucene 的搜索引擎,提供了丰富的查询DSL(Domain Specifi…...

kafka简单介绍和代码示例
“这是一篇理论文章,给大家讲一讲kafka” 简介 在大数据领域开发者常常会听到MQ这个术语,该术语便是消息队列的意思, Kafka是分布式的发布—订阅消息系统。它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年…...

一次解决ForkJoinPool日志追踪的辛酸经历
本文主要分享了一次解决ForkJoinPool日志追踪的辛酸经历。历时3个月终于找到通用的解决方案,以此文分享给有需要的你。 一、需求背景 1.某日,某同事根据日志ID排查生产环境问题过程中,发现日志不全 2.经排查发现中间有很多线程为ForkJoinP…...
VM使用教程--SDK取图 视频笔记
本笔记均由海康机器人官网的V学院视频中记录所得,属于省流大师了[doge] 图像采集 图像采集包括1图像源,2多图采集,3输出图像,4缓存图像,5光源 1图像源 图像源包括本地图像,相机采图,SDK 本…...
)
11.spring boot 启动源码(一)
目录 概述SpringApplication静态方法构造方法run 实例方法配置文件Actuator 工作原理*EndpointAutoConfigurationBeansEndpointAutoConfigurationShutdownEndpointAutoConfiguration结束概述 spring boot 版本 2.6.13 spring boot 启动源码(一) 涉及 SpringApplication 中静态…...
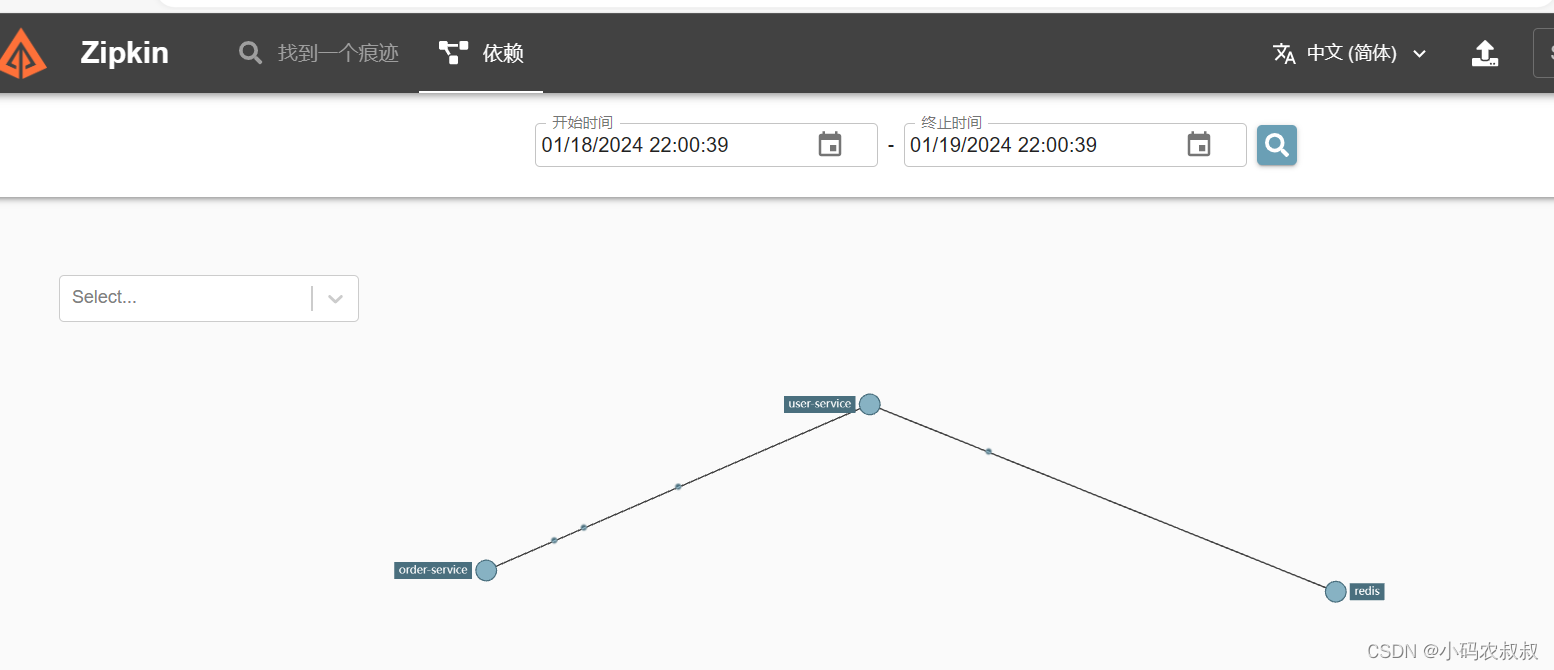
【微服务】springcloud集成sleuth与zipkin实现链路追踪
目录 一、前言 二、分布式链路调用问题 三、链路追踪中的几个概念 3.1 什么是链路追踪 3.2 常用的链路追踪技术 3.3 链路追踪的几个术语 3.3.1 span 编辑 3.3.2 trace 3.3.3 Annotation 四、sluth与zipkin概述 4.1 sluth介绍 4.1.1 sluth是什么 4.1.2 sluth核心…...

数学建模-预测人口数据
目录 中国09~18年人口数据 创建时间 绘制时间序列图 使用专家建模器 得到结果 预测结果 残差的白噪声检验 中国09~18年人口数据 创建时间 路径:数据-> 定义日期和时间 绘制时间序列图 使用专家建模器 看看spss最终判断是那个模型最佳的契合 得到结果 预…...

SpringBoot 集成 Canal 基于 MySQL 做数据同步
一、canal 组件关系 下载地址:https://github.com/alibaba/canal/releases/download/canal-1.1.7/ 这里面主要的有两个 canal.deployer-1.1.7.tar.gz 和 canal.adapter-1.1.7.tar.gz,canal.admin-1.1.7.tar.gz 是一个监控服务,可选…...

【CVE-2022-22733漏洞复现】
Apache ShardingSphere ElasticJob-UI漏洞 漏洞编号:CVE-2022-22733 文档说明 本文作者:SwBack 创作时间:2024/1/21 19:19:19 知乎:https://www.zhihu.com/people/back-88-87 CSDN:https://blog.csdn.net/qq_30817059 百度搜索: SwBack漏洞描述 Apache ShardingSphere Elast…...
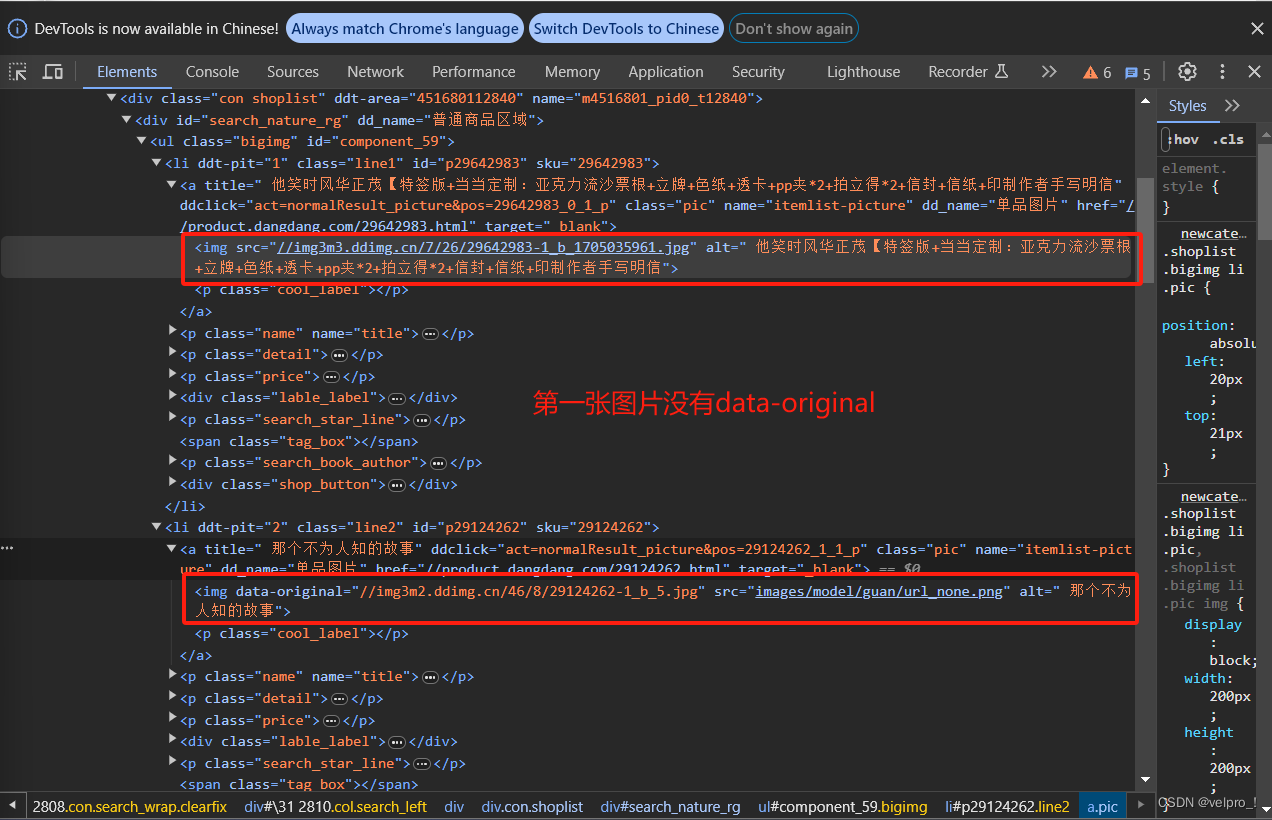
Python爬虫---scrapy框架---当当网管道封装
项目结构: dang.py文件:自己创建,实现爬虫核心功能的文件 import scrapy from scrapy_dangdang_20240113.items import ScrapyDangdang20240113Itemclass DangSpider(scrapy.Spider):name "dang" # 名字# 如果是多页下载的话, …...

【机器学习】机器学习四大类第01课
一、机器学习四大类 有监督学习 (Supervised Learning) 有监督学习是通过已知的输入-输出对(即标记过的训练数据)来学习函数关系的过程。在训练阶段,模型会根据这些示例调整参数以尽可能准确地预测新的、未见过的数据点的输出。 实例&#x…...

下述默认构造函数有什么问题?
12.4 // points to string allocated by new // holds length of string 独立的、相同的数据,而不会重叠。由于同样的原因,必须定义赋值操作符。对于每一种情况,最终目的 都是执行深度复制,也就是说,复制实际的数据,而不仅仅是复制指向数据的指针。 对象的存储持续性为自动或…...

RK3588/RK3568嵌入式开发:从通用镜像到定制分区镜像的完整实践指南
1. 项目概述:从“通用”到“专属”的镜像进化最近在折腾RK3588和RK3568平台时,我发现了一个挺有意思的升级点:开发板和核心板的镜像支持定制分区了。这听起来可能有点技术化,但说白了,就是以前我们拿到的系统镜像&…...

RTSP拉流播放器开发实战:用FFmpeg和SDL2解析H264 RTP流
RTSP拉流播放器开发实战:用FFmpeg和SDL2解析H264 RTP流 在实时视频监控、在线直播等场景中,RTSP协议因其低延迟和可靠性成为主流选择。本文将深入探讨如何从零构建一个RTSP客户端播放器,重点解决H264 RTP流的接收、解析与渲染难题。不同于简单…...

为什么顶级作曲家都在弃用Shazam转投Perplexity?——基于127万条音乐查询日志的权威对比报告
更多请点击: https://codechina.net 第一章:Perplexity音乐知识搜索的崛起背景与行业影响 近年来,音乐产业正经历从“内容分发”向“知识理解”的范式迁移。传统搜索引擎在处理音乐相关查询时,常受限于语义模糊性——例如用户输入…...
:解决专家坍缩的工业级方案)
DeepSeek MoE训练稳定性突破(动态负载均衡+梯度裁剪双保险):解决专家坍缩的工业级方案
更多请点击: https://kaifayun.com 第一章:DeepSeek MoE架构解析 DeepSeek MoE(Mixture of Experts)是一种面向大语言模型高效推理与训练的稀疏化架构设计,其核心思想是在保持模型总参数量庞大的前提下,仅…...

终极LXMusic音源配置指南:三步解决全网音乐播放难题
终极LXMusic音源配置指南:三步解决全网音乐播放难题 【免费下载链接】LXMusic音源 lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/guoyue2010/lxmusic- 你是否经常遇到音乐软件资源不全、音质不佳的问题ÿ…...

哔咔漫画下载器:构建个人离线漫画库的完整解决方案
哔咔漫画下载器:构建个人离线漫画库的完整解决方案 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.com/gh_mir…...

探索Harepacker复活版:打造你的MapleStory创意工坊
探索Harepacker复活版:打造你的MapleStory创意工坊 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾经梦想过亲手改造Map…...

终极指南:如何使用Harepacker复活版轻松打造你的MapleStory游戏世界
终极指南:如何使用Harepacker复活版轻松打造你的MapleStory游戏世界 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 想要个性化修…...

百度网盘Mac版SVIP破解终极指南:三步解锁高速下载限制
百度网盘Mac版SVIP破解终极指南:三步解锁高速下载限制 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的龟速下载而烦恼…...

【RK3588-AI-003】RK3588串口+SSH远程连接配置+文件互传实操
一、前言 很多刚入手RK3588开发板做AI部署、嵌入式开发的同学,都会遇到三大难题: ❌ 不知道怎么接线、看不懂串口打印日志,调试报错无从下手; ❌ 每次重启开发板IP都会变,频繁修改连接地址,开发极其麻烦&…...