数据操作——缺失值处理
缺失值处理
缺失值的处理思路
如果想探究如何处理无效值, 首先要知道无效值从哪来, 从而分析可能产生的无效值有哪些类型, 在分别去看如何处理无效值
-
什么是缺失值
一个值本身的含义是这个值不存在则称之为缺失值, 也就是说这个值本身代表着缺失, 或者这个值本身无意义, 比如说 null, 比如说空字符串
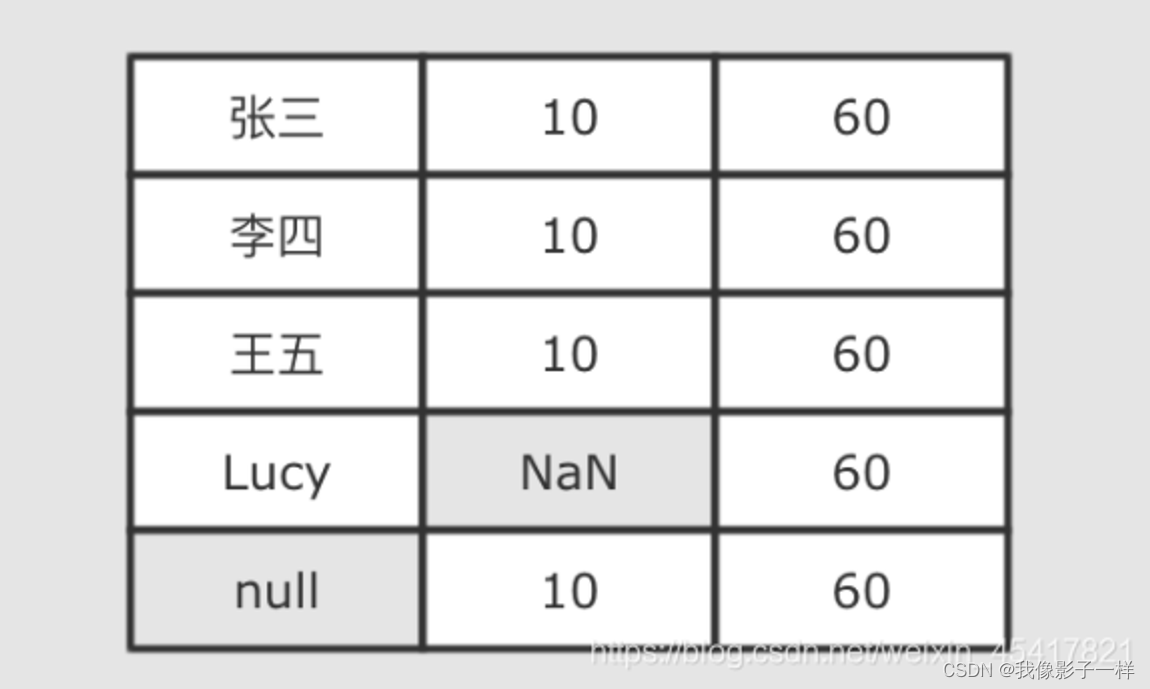
关于数据的分析其实就是统计分析的概念, 如果这样的话, 当数据集中存在缺失值, 则无法进行统计和分析, 对很多操作都有影响
-
缺失值如何产生的
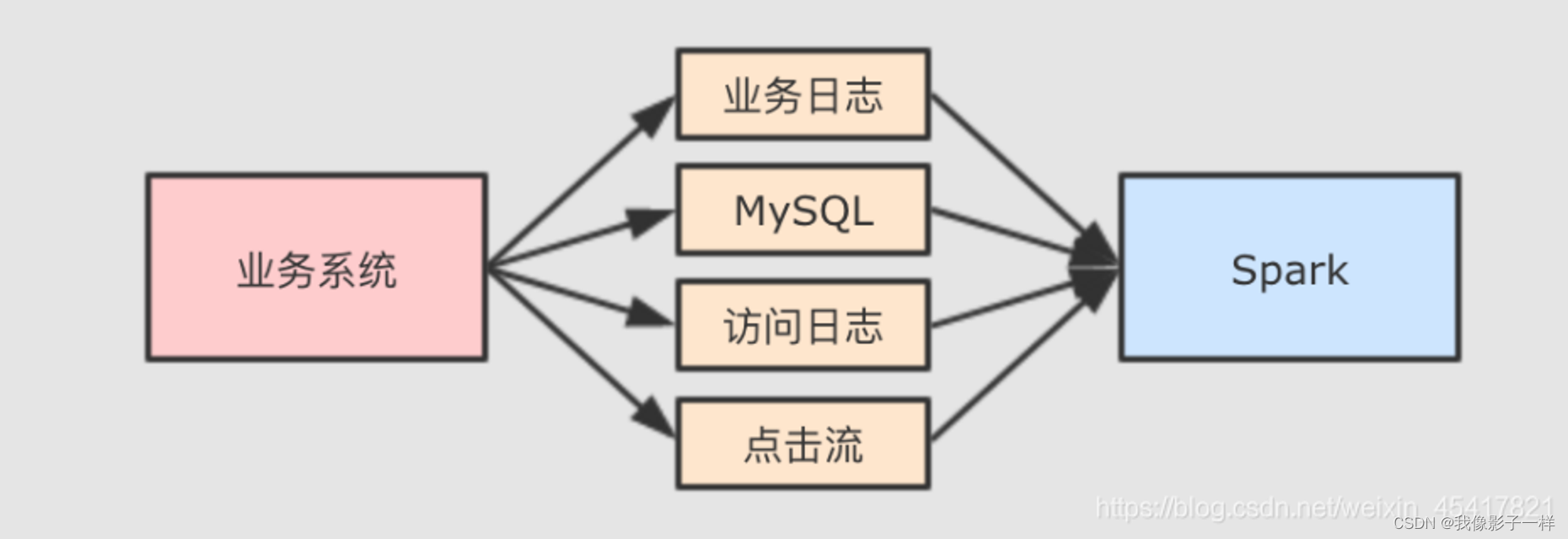
Spark 大多时候处理的数据来自于业务系统中, 业务系统中可能会因为各种原因, 产生一些异常的数据
例如说 因为前后端的判断失误, 提交了一些非法参数. 再例如说因为业务系统修改 MySQL 表结构产生的一些空值数据等. 总之在业务系统中出现缺失值其实是非常常见的一件事, 所以大数据系统就一定要考虑这件事.
-
缺失值的类型
常见的缺失值有两种
-
null, NaN 等特殊类型的值, 某些语言中 null 可以理解是一个对象, 但是代表没有对象, NaN 是一个数字, 可以代表不是数字
针对这一类的缺失值, Spark 提供了一个名为 DataFrameNaFunctions 特殊类型来操作和处理
-
“Null”, “NA”, " " 等解析为字符串的类型, 但是其实并不是常规字符串数据
针对这类字符串, 需要对数据集进行采样, 观察异常数据, 总结经验, 各个击破
-
-
DataFrameNaFunctions
DataFrameNaFunctions 使用 Dataset 的 na 函数来获取
val df = ... val naFunc: DataFrameNaFunctions = df.na当数据集中出现缺失值的时候, 大致有两种处理方式, 一个是丢弃, 一个是替换为某值, DataFrameNaFunctions 中包含一系列针对空值数据的方案
- DataFrameNaFunctions.drop 可以在当某行中包含 null 或 NaN 的时候丢弃此行
- DataFrameNaFunctions.fill 可以在将 null 和 NaN 充为其它值
- DataFrameNaFunctions.replace 可以把 null 或 NaN 替换为其它值, 但是和 fill 略有一些不同, 这个方法针对值来进行替换
-
如何使用 SparkSQL 处理 null 和 NaN(Double.NaN → Not a number) ?
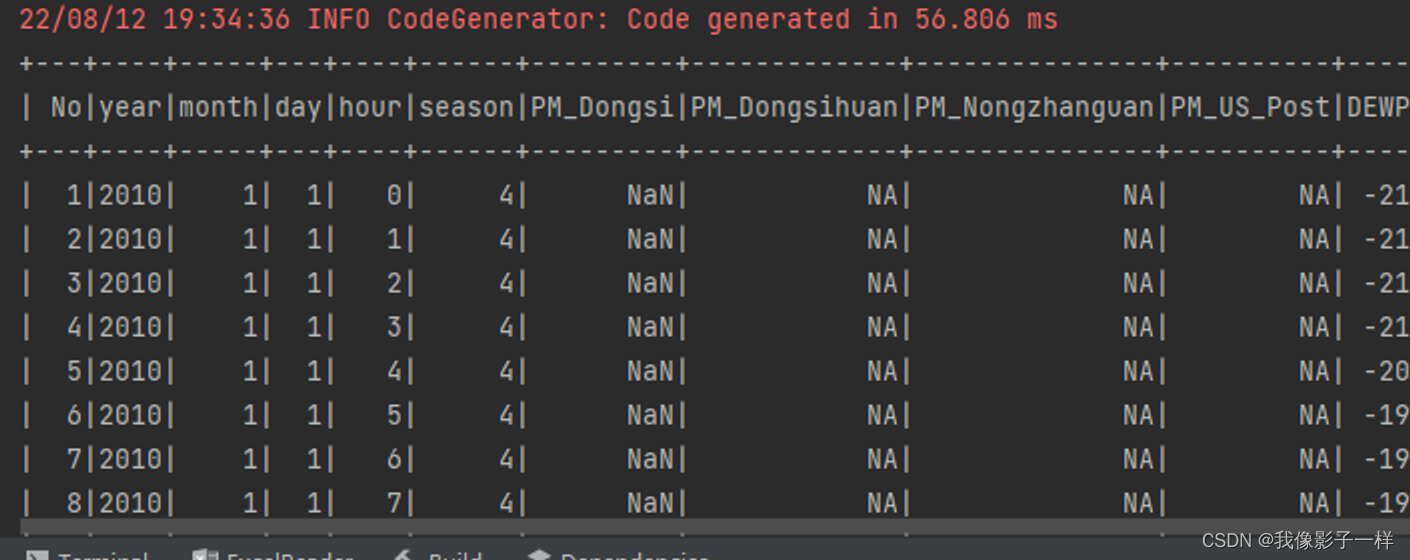
首先要将数据读取出来, 此次使用的数据集直接存在 NaN, 在指定 Schema 后, 可直接被转为 Double.NaN
@Test def nullAndNaN():Unit ={// 2. 导入数据集// 3. 读取数据集// 1.通过Spark-csv自动的推断类型来读取,推断数字的时候会将NaN推断为字符串 // spark.read // .option("header",true) // .option("inferSchema",true) // .csv(....)// 2. 直接读取字符串,在后续的操作中使用 map 算子转类型 // spark.read.csv().map(row => row....)// 3. 指定 Schema ,不要自动推断// 创建 Schemaval schema = StructType(List(StructField("id", LongType),StructField("year", IntegerType),StructField("month", IntegerType),StructField("day", IntegerType),StructField("session", IntegerType),StructField("pm", DoubleType)))// Double.NaNval sourceDF = spark.read.option("header",true).schema(schema).csv("./dataset/beijingpm_with_nan.csv") // pm下的NaN 自动转为 Double.NaNsourceDF.show() }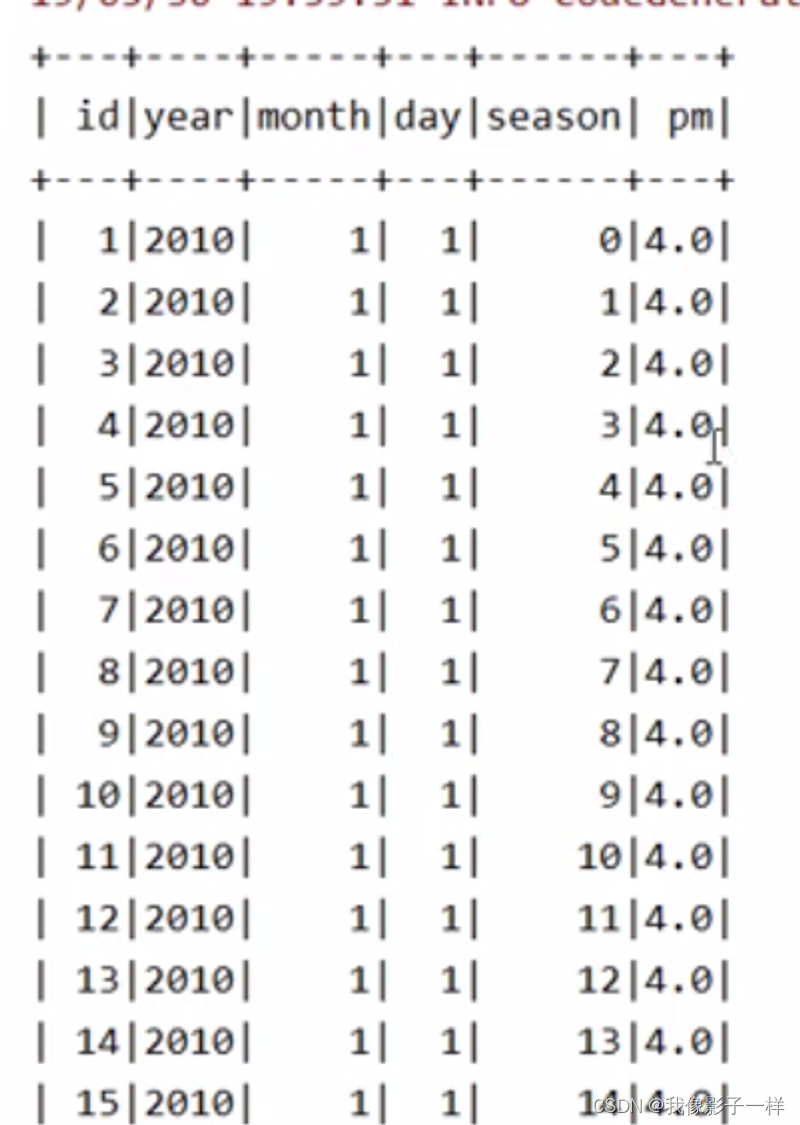
对于缺失值的处理一般就是丢弃和填充
-
丢弃包含 null 和 NaN 的行
// 4.丢弃 // 2019,12,12,Nam // 规则: // 1. any, 只要有一个 NaN 的行就丢弃 sourceDF.na.drop("any").show() // sourceDF.na.drop().show() 默认 any // 2. all, 所有数据都是 NaN 的行才丢弃 sourceDF.na.drop("all").show() // 3. 某些列的规则 sourceDF.na.drop("any",List("year","month","day")).show()** -
填充包含 null 和 NaN 的列
**// 5.填充// 规则:// 1. 针对所有列数据进行默认值填充sourceDF.na.fill(0).show()// 2. 针对特定列填充sourceDF.na.fill(0, List("year", "month")).show() }**
-
-
如何使用 SparkSQL 处理异常字符串 ?
读取数据集, 这次读取的是最原始的那个 PM 数据集
**val df = spark.read.option("header", value = true).csv("./dataset/BeijingPM20100101_20151231.csv")**使用函数直接转换非法的字符串
**// 1. 替换// select name, age, case// when .. then...// elseimport org.apache.spark.sql.functions._ // 使用when 需要导入sourceDF.select('No as "id", 'year, 'month, 'day, 'hour, 'season,when('PM_Dongsi === "NA", Double.NaN) // 当 PM_Donsi 里的数据 等于 NA 时,变为 Double.NaN.otherwise('PM_Dongsi cast DoubleType) // 如果不是上面的条件,要将它的正常值转换成对应的Double类型.as("pm") // 起别名).show()// replace 注意:原类型和转换过后的类型,必须一致 sourceDF.na.replace("PM_Dongsi", Map("NA" -> "NaN")).show() // sourceDF.na.replace("PM_Dongsi", Map("NA" -> "NaN", "NULL" -> "null")).show()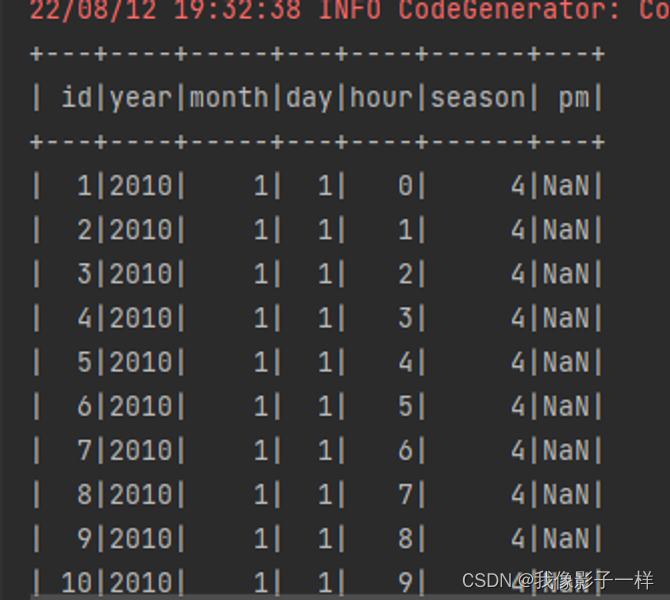
使用 where 直接过滤
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season, 'PM_Dongsi).where('PM_Dongsi =!= "NA") // =!= 不等于.show()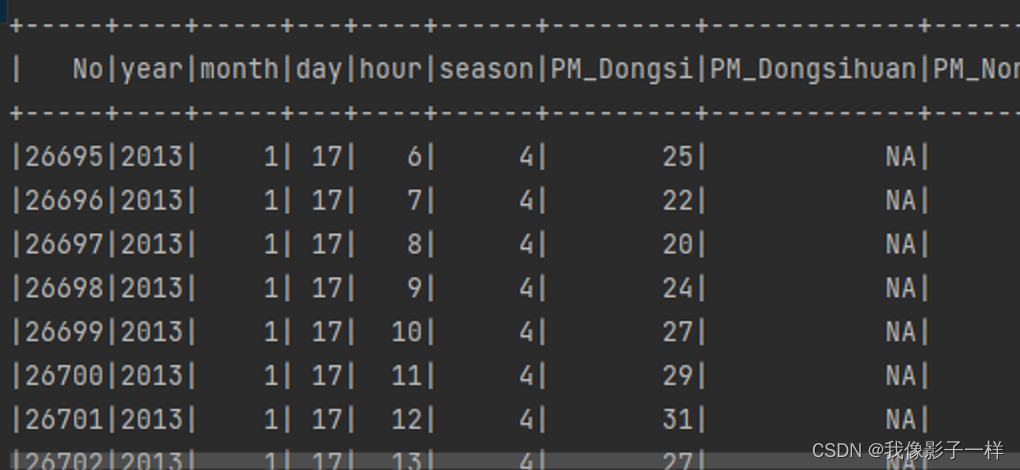
-
所用文件
[beijingpm_with_nan.rar]
[BeijingPM20100101_20151231.rar](前面已上传,自己根据名称去资源下载)
-
以上代码的前置条件
// 1. 创建SparkSession对象 val spark = SparkSession.builder().appName("column").master("local[6]").getOrCreate()import spark.implicits._case class Person(name: String, age: Int)
相关文章:
数据操作——缺失值处理
缺失值处理 缺失值的处理思路 如果想探究如何处理无效值, 首先要知道无效值从哪来, 从而分析可能产生的无效值有哪些类型, 在分别去看如何处理无效值 什么是缺失值 一个值本身的含义是这个值不存在则称之为缺失值, 也就是说这个值本身代表着缺失, 或者这个值本身无意义, 比如…...
【刷题笔记4】
动态规划题目汇总 斐波那契数列:1,1,2,3,5,8,13…… 递归一把解决三类问题:1.数据定义是按照递归的(斐波那契数列)。2.问题解法是按递归算法实现的。 3.数据…...
cuda二进制文件中到底有些什么
大家好。今天我们来讨论一下,相比gcc编译器编译的二进制elf文件,包含有 cuda kernel 的源文件编译出来的 elf 文件有什么不同呢? 之前研究过一点 tvm。从 BYOC 的框架中可以得知,前端将模型 partition 成 host 和 accel(accel 表…...

怎么从视频中提取动图?一个方法快速提取gif
视频以连续的方式播放一系列图像帧,通过每秒播放的帧数(帧率)来创做,由于GIF动图则以循环播放一系列静态图像帧的方式展现动画效果。由于视频的优势在于流畅的动画、丰富的细节和长时间播放,因此常用于电影、电视节目、…...

String字符串的比较和hash函数减少哈希冲突
1.为什么比较字符串通过hash值比通过字符串本身效率更高 比较两个字符串的哈希值相对于比较两个字符串本身的效率更高,原因如下: 哈希函数具有快速计算的特性:哈希函数可以将一个字符串转换为一个固定长度的哈希值。这个转换过程通常是非常…...

【数据库原理】(38)数据仓库
数据仓库(Data Warehouse, DW)是为了满足企业决策分析需求而设计的数据环境,它与传统数据库有明显的不同。 一.数据库仓库概述 定义: 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持企业管理和…...
已有标准库的拓展和修改)
C++17新特性(四)已有标准库的拓展和修改
这一部分介绍C17对已有标准库组件的拓展和修改。 1. 类型特征拓展 1.1 类型特征后缀_v 自从C17起,对所有返回值的类型特征使用后缀_v,例如: std::is_const_v<T>; // C17 std::is_const<T>::value; // C11这适用于所有返回值的…...
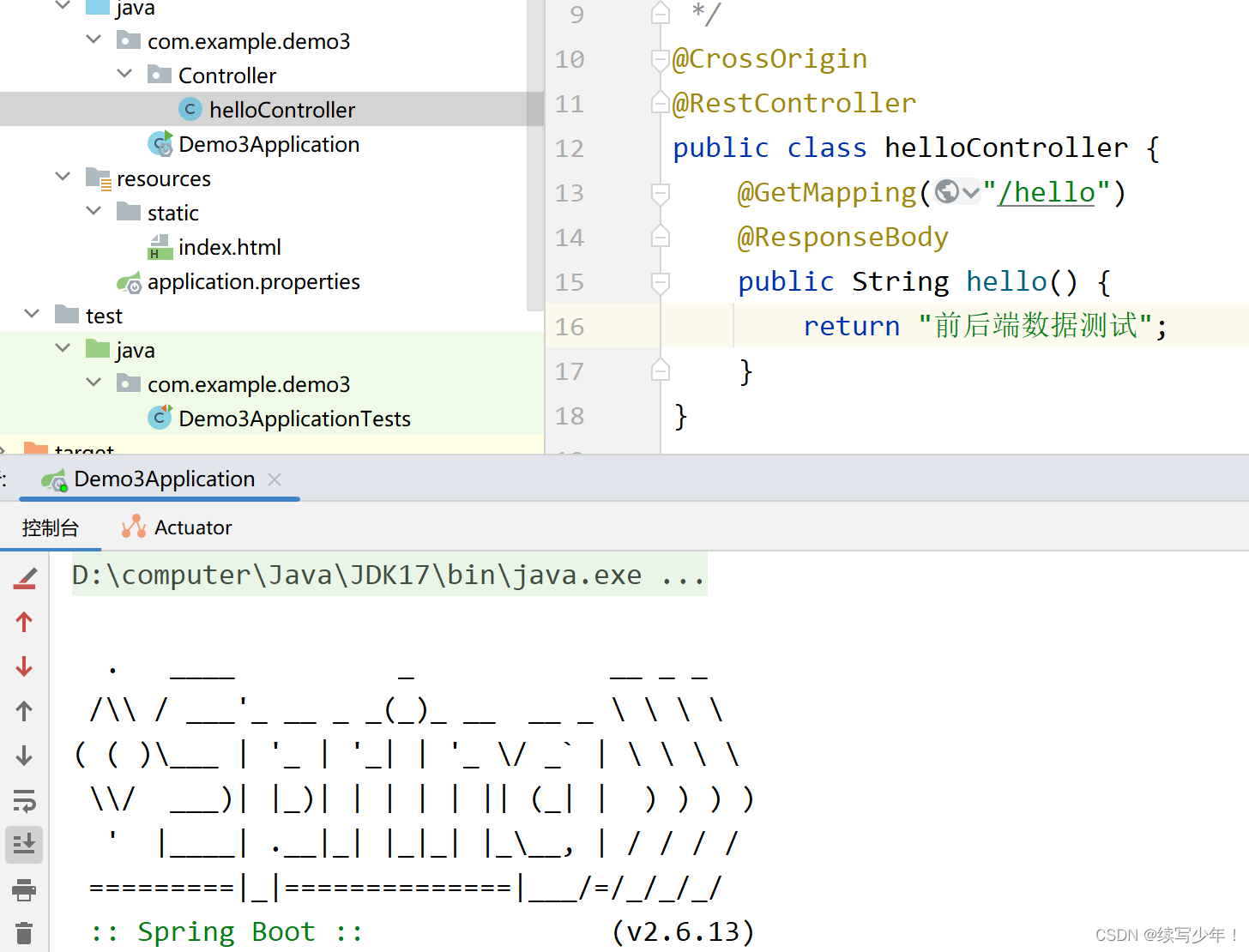
软件是什么?前端,后端,数据库
软件是什么? 由于很多东西没有实际接触,很难理解,对于软件的定义也是各种各样。但是我还是不理解,软件开发中的前端,后端,数据库到底有什么关系呢! 这个问题足足困扰了三年半,练习时…...
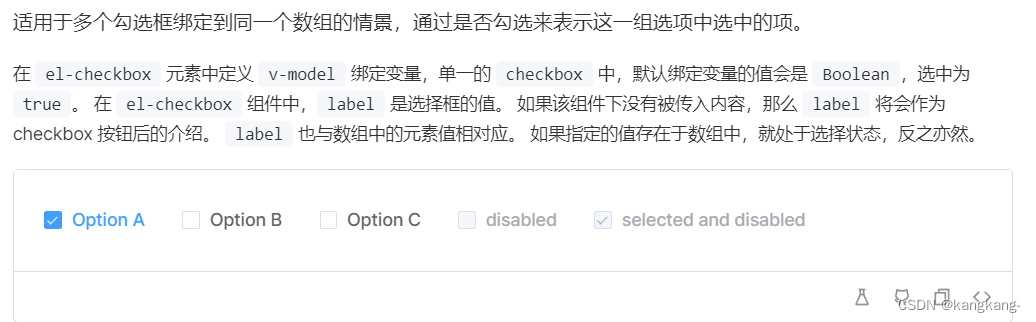
Vue3+ElementUI 多选框中复选框和名字点击方法效果分离
现在的需求为 比如我点击了Option A ,触发点击Option A的方法,并且复选框不会取消勾选,分离的方法。 <el-checkbox-group v-model"mapWork.model_checkArray.value"> <div class"naipTypeDom" v-for"item …...

设计模式篇章(4)——十一种行为型模式
这个设计模式主要思考的是如何分配对象的职责和将对象之间相互协作完成单个对象无法完成的任务,这个与结构型模式有点像,结构型可以理解为静态的组合,例如将不同的组件拼起来成为一个更大的组件;而行为型更是一种动态或者具有某个…...
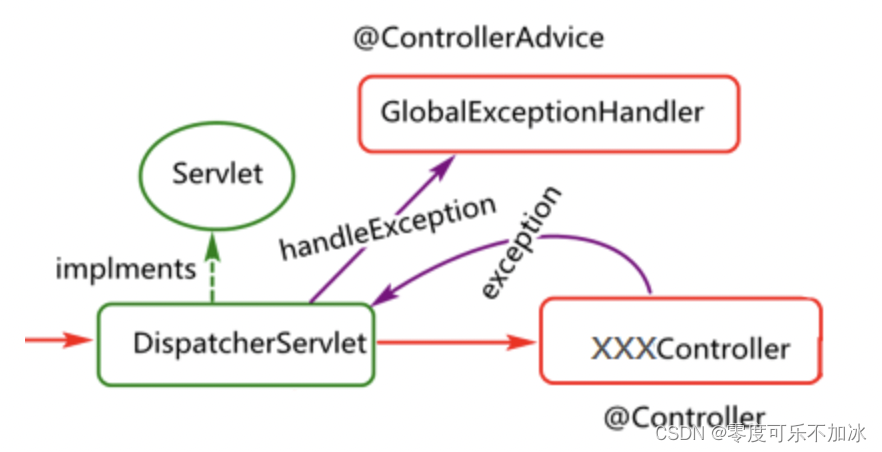
Spring成长之路—Spring MVC
在分享SpringMVC之前,我们先对MVC有个基本的了解。MVC(Model-View-Controller)指的是一种软件思想,它将软件分为三层:模型层、视图层、控制层 模型层即Model:负责处理具体的业务和封装实体类,我们所知的service层、poj…...
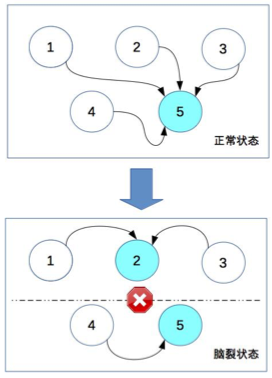
架构篇05-复杂度来源:高可用
文章目录 计算高可用存储高可用高可用状态决策小结 今天,我们聊聊复杂度的第二个来源高可用。 参考维基百科,先来看看高可用的定义。 系统无中断地执行其功能的能力,代表系统的可用性程度,是进行系统设计时的准则之一。 这个定义…...

C#调用Newtonsoft.Json将bool序列化为int
使用Newtonsoft.Json将数据对象序列化为Json字符串时,如果有布尔类型的属性值时,一般会将bool类型序列化为字符串,true值序列化为true,false值序列化为false。如下面的类型序列化后的结果如下: public class UserInfo…...

【Linux系统编程】环境变量详解
文章目录 1. 环境变量的基本概念2. 如何理解呢?(测试PATH)2.1 切入点1查看具体的环境变量原因剖析常见环境变量 2.2 切入点2给PATH环境变量添加新路径将我们自己的命令拷贝到PATH已有路径里面 2.3 切入点3 3. 显示所有环境变量4. 测试HOME5. …...

智能合约介绍
莫道儒冠误此生,从来诗书不负人 目录 一、什么是区块链智能合约? 二、智能合约的发展背景 三、智能合约的优势 四、智能合约的劣势 五、一些关于智能合约的应用 总结 一、什么是区块链智能合约? 智能合约,是一段写在区块链上的代码,一…...
Python自动化实战之接口请求的实现
在前文说过,如果想要更好的做接口测试,我们要利用自己的代码基础与代码优势,所以该章节不会再介绍商业化的、通用的接口测试工具,重点介绍如何通过 python 编码来实现我们的接口测试以及通过 Pycharm 的实际应用编写一个简单接口测…...

react和vue的区别
一、核心思想不同 Vue的核心思想是尽可能的降低前端开发的门槛,是一个灵活易用的渐进式双向绑定的MVVM框架。 React的核心思想是声明式渲染和组件化、单向数据流,React既不属于MVC也不属于MVVM架构。 如何理解React的单向数据流? React的单…...

Spring 中有哪些方式可以把 Bean 注入到 IOC 容器?
目录 1、xml方式2、CompontScan Component3、使用 Bean方式4、使用Import 注解5、FactoryBean 工厂 bean6、使用 ImportBeanDefinitionRegistrar 向容器中注入Bean7、实现 ImportSelector 接口 1、xml方式 使用 xml 的方式来声明 Bean 的定义,Spring 容器在启动的…...

客户需求,就是项目管理中最难管的事情
对于需求控制和管理 个人的观点是:首先要向客户传递开发流程,第二必须制作原型,需求确认时确认的是原型,而不是需求文档,第三,开发阶段要快速迭代,与客户互动。管人方面我想对于项目经理来讲&am…...

条款28:避免返回 handles 指向对象的内部成分
创建一个矩形的类(Rectangle),为保持Rectangle对象较小,可以只在其对象中保存一个指针,用于指向辅助的结构体,定义其范围的点数据存放在辅助的结构体中: class Point { // 表示点的类 public:P…...

在macOS上轻松运行Windows应用:Whisky完整使用指南
在macOS上轻松运行Windows应用:Whisky完整使用指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在Apple Silicon Mac上直接运行Windows软件和游戏,又不想…...
在临床疾病中的作用机制与靶向治疗研究进展)
白细胞介素-6(IL-6)在临床疾病中的作用机制与靶向治疗研究进展
白细胞介素-6(Interleukin-6, IL-6)是一种由多种细胞(如单核/巨噬细胞、T细胞、成纤维细胞等)分泌的多效性细胞因子,参与免疫调节、炎症反应、代谢稳态及组织修复等生理过程。在病理状态下,IL-6过度表达与感…...
)
告别C盘焦虑!保姆级教程:在D盘为VS2013安个家(附阿里云/百度网盘下载)
告别C盘焦虑!VS2013高效安装与磁盘管理全指南 对于刚接触编程的新手来说,Visual Studio 2013(简称VS2013)是一个功能强大且友好的开发环境。然而,许多用户在安装过程中常常忽略了一个关键问题——安装路径的选择。本文…...

华为鸿蒙与欧拉操作系统:全场景战略下的技术架构与生态构建
1. 从“备胎”到“主干”:华为操作系统的战略突围之路 最近科技圈里关于华为的消息,大家讨论得最多的,除了孟晚舟女士的归国,可能就是华为在软件领域接连放出的几个“大招”了。作为一名在ICT行业摸爬滚打了十几年的老兵ÿ…...

第八章:AI产品的技术尽调——如何评估AI供应商
本章难度:★★★★☆ | 预计阅读时间:10分钟 你将学到:AI供应商评估的八大维度、安全认证与AI特有风险、2026年合规框架(EU AI Act/ISO 42001/GDPR)、数据隐私条款、模型能力评估方法、以及PM可操作的技术尽调清单 引言:为什么AI供应商需要"特殊体检" 老板说:…...

如何高效设计无刷直流电机控制器:Simscape Electrical完整解决方案指南
如何高效设计无刷直流电机控制器:Simscape Electrical完整解决方案指南 【免费下载链接】Design-motor-controllers-with-Simscape-Electrical This repository contains MATLAB and Simulink files used in the "How to design motor controllers using Simsc…...

从仿真到真车:如何用CARLA+Autoware搭建你的自动驾驶算法快速迭代工作流?
从仿真到真车:构建CARLAAutoware自动驾驶算法高效迭代体系 自动驾驶算法的开发如同在刀锋上行走——既要保证安全性,又要追求创新速度。当特斯拉的工程师们每天通过影子模式收集数百万英里的真实数据时,大多数团队却受限于路测成本与安全风险…...

Scandit Barcode Scanner:这家瑞士公司的SDK,如何让淘宝、京东的扫码快人一步?
Scandit Barcode Scanner:解码瑞士技术如何重塑全球扫码体验 在移动互联网时代,扫码已成为连接物理世界与数字世界的无形桥梁。从超市收银台到物流仓库,从零售门店到电商平台,条码扫描技术默默支撑着现代商业的高效运转。而在这背…...

从数据备份到模型部署:深入理解Numpy的.npy/.npz文件在机器学习流水线中的角色
从数据备份到模型部署:深入理解Numpy的.npy/.npz文件在机器学习流水线中的角色 在机器学习项目的完整生命周期中,数据的高效存储与快速读取往往是决定工程效率的关键因素之一。当我们谈论数据处理工具时,Numpy无疑是Python生态中不可忽视的核…...

8B模型榨出极限战力!本地LLM胜率狂飙86%
今天我们要讲的是一个工程方法,通过这个Forge框架来增强本地运行的8B模型,让这个小模型可以在复杂的agent任务上面有更好的表现。Q:本地小模型在做这些复杂任务的时候,经常会出现哪些让人抓狂的问题? A:在本…...