StarRocks 生成列:百倍提速半结构化数据分析
半结构化分析主要是指对 MAP,STRUCT,JSON,ARRAY 等复杂数据类型的查询分析。这些数据类型表达能力强,因此被广泛应用到 OLAP 分析的各种场景中,但由于其实现的复杂性,对这些复杂类型分析将会比一般简单类型要更困难和耗时,例如:
-
需要对 MAP,STRUCT,JSON 等数据类型中的某个字段进行查询分析。由于这些复杂类型会被存储为一个整体,因此需要先将整个半结构化类型的字段先从存储层读取上来,然后再对其中的某些字段进行分析,IO效率较低。 -
对复杂类型进行较为耗时的分析计算(聚合,排序等等),查询的实时CPU 开销可能也是一个不可忽略的性能影响因素。
面对上述的挑战,StarRocks在3.1 版本正式推出生成列(Generated Column)特性,提供一种透明加速的解决方案,能有效提升半结构化数据的分析效率,令用户拥有更极速的分析体验。
生成列介绍
生成列是一种特殊的列,可以在建表语句或 Schema Change 语句中指定,生成列绑定到一个标量表达式上,当数据导入时,会自动根据表达式定义进行计算,并且将其计算结果写入到生成列中。
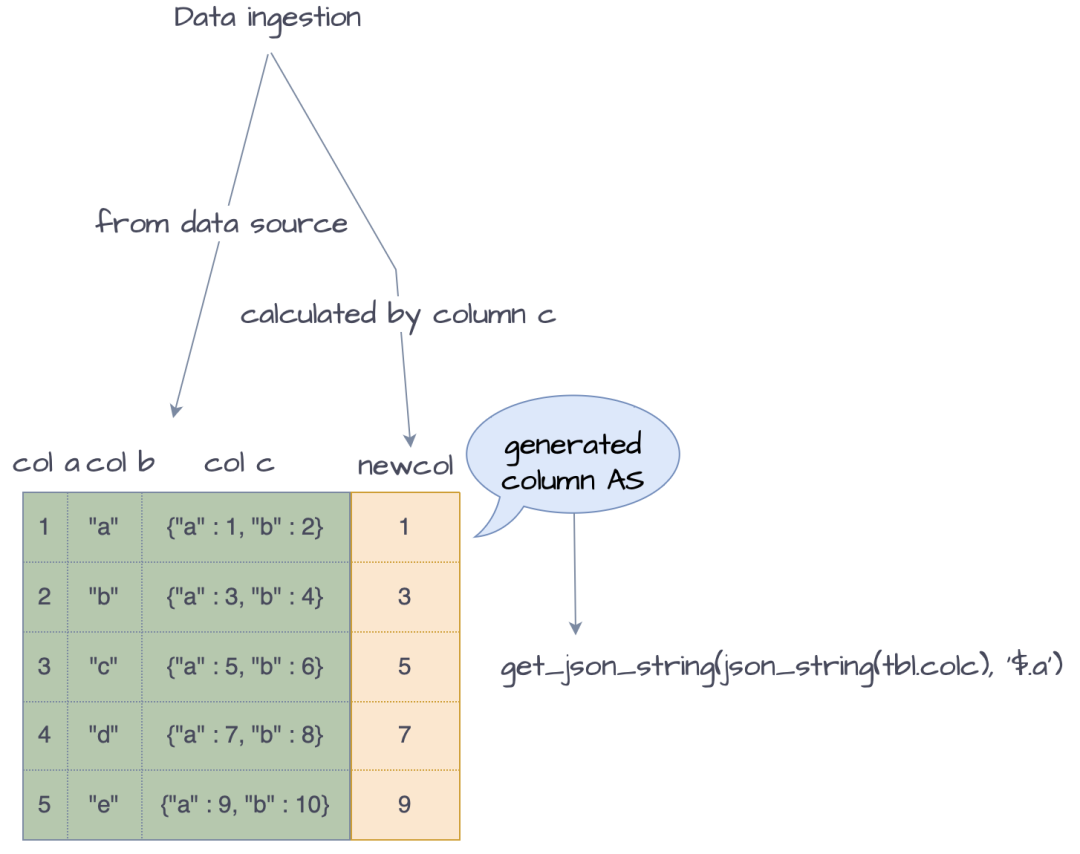
在半结构化分析的场景中,可以将复杂耗时的标量表达式绑定在某个生成列上,在数据导入阶段提前将结果计算好并且持久化到磁盘中。当需要进行查询分析时,即可马上获得表达式计算的结果。
生成列的查询改写
当希望查询生成列保存的表达式计算结果时,可以直接在 SQL 中指定生成列的列名,但是这种方法意味着需要调整已有业务 SQL,很难完全做到无缝对接。
为了进一步提升功能的使用体验,简化使用流程,StarRocks 支持生成列自动查询改写。在生成执行计划时,SQL 优化器将会检查 SQL 中所有的表达式,并且将那些已经绑定到生成列上的表达式,改写成查询生成列列值。
例如,上述例子中,如果在某个查询中需要获取 colc 中的 a 字段,则执行查询SELECT get_json_string(json_string(tbl.colc), '$.a') FROM tbl,执行过程大致如下:
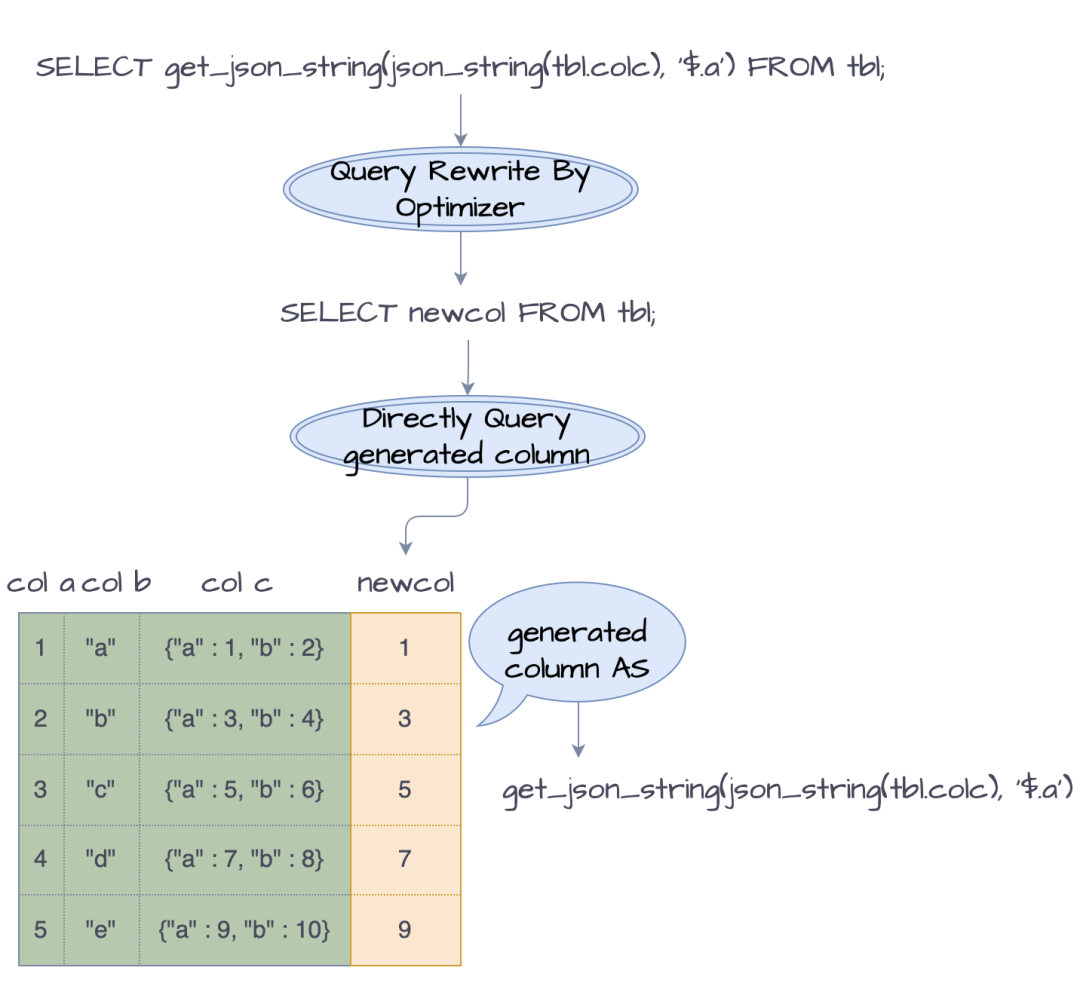
可见,优化器自动将表达式改写为查询生成列的值,实现透明加速。
高效的生成列加列
在实际应用生成列的使用场景中,在已有的表添加生成列可能是一个高频操作。例如,可能在任意时间点发现某个表达式计算存在性能瓶颈,因此希望添加生成列以进行查询加速。
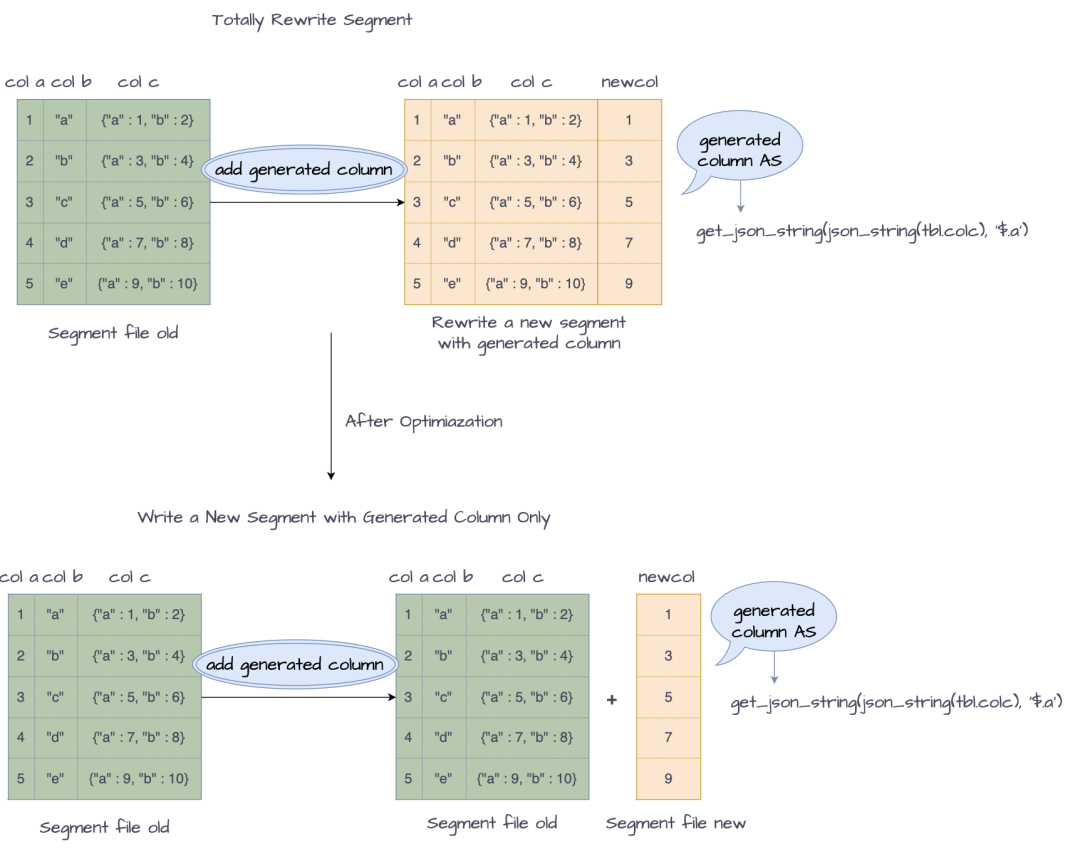
StarRocks 支持高效的加列操作,对于添加普通列,存储引擎并不会真正重写物理文件,而只是将物理文件重新 link 到新 Tablet 的路径下,修改元数据,完成加列操作。但是,如 MODIFY COLUMN 这类 Schema Change 操作,由于需要改变存量数据的内容,因此会重写所有物理文件。类似地,对于生成列加列来说,由于需要存储新增的生成列表达式的计算结果,重写数据似乎也是不可避免的。但是,如果仍然采用全量重写物理文件的方案,将无法很好适应频繁加列的场景,加列的代价太大。
为了进一步提高生成列加列的效率,StarRocks 针对生成列加列进行了专门的优化。当添加一个生成列时,不会改写存量的物理文件,而是为每一个存量的 segment 生成一个只包含生成列值的 cols 文件(物理格式和 segment 文件一样,但只包含生成列一列数据),当需要查询这些存量数据时,StarRocks 会自动将 segment 和 cols 文件的内容进行合并,获得正确的查询结果。
总的来说,生成列加列优化后,读 I/O 只涉及到生成列表达式的引用列,写 I/O 只涉及到生成列本身的表达式结果,整个 Schema Change 的 I/O 效率相比完全重写有大幅提高,更好支持实时动态生成列加列的用户需求。
效果验证
为了更好验证生成列对半结构化分析的加速效果,我们进行了简单的测试验证。
集群信息:StarRocks v3.1 1FE1BE ,104C376GB
创建一张如下的数据表,
CREATE TABLE `t` (
`id` bigint(20) NOT NULL COMMENT "",
`array_int` ARRAY<int(11)> NOT NULL COMMENT "",
`json_data` json NOT NULL COMMENT "",
`gc_1` double NULL AS array_avg(`test`.`t`.`array_int`) COMMENT "",
`gc_2` ARRAY<int(11)> NULL AS array_sort(`test`.`t`.`array_int`) COMMENT "",
`gc_3` varchar(65533) NULL AS get_json_string(json_string(`test`.`t`.`json_data`), '$.a') COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`) BUCKETS 48
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"replicated_storage" = "true",
"compression" = "LZ4"
)
普通列数据创建方式: id,作为 primary key 列保证唯一。
array_int,长度为 10000 的 ARRAY ,保存的都是随机数。
json_data,包含两个 key,key "a" 对应的 value 为整型 1,key "b" 对应的value 是长度为 100 个 uuid 构成的字符串 性能测试使用下面的 query:
q1:SELECT get_json_string(json_string(json_data), '$.a') FROM A
q2:SELECT array_avg(array_int) FROM A;
测试结果:

从上述的测试结果可知:
q1:使用生成列提取大 JSON 字段中的某个子字段,在查询阶段大幅节省了读取 JSON 字段的 I/O 消耗,查询性能提升达 4 倍以上。
q2:使用生成列对大 ARRAY 字段进行聚合计算(计算平均值),在查询阶段不仅节省读取该半结构化数据字段的 I/O 消耗,同时也大幅节省了 ARRAY 聚合计算所带来的 CPU 消耗,获得百倍的性能提升。
总结
生成列功能是一种加速半结构化分析的有效手段,当面对复杂的半结构化表达式计算时,可以为其添加对应的生成列,在导入阶段自动完成表达式计算,并将结果持久化。在查询阶段通过优化器的自动改写,直接从生成列中获得表达式计算结果,避免实时的表达式计算,实现透明加速。 通过使用生成列,用户能大幅减少查询时复杂表达式的 I/O,CPU 等资源消耗,在不同的场景下获得数倍甚至百倍的性能提升。
本文由 mdnice 多平台发布
相关文章:
StarRocks 生成列:百倍提速半结构化数据分析
半结构化分析主要是指对 MAP,STRUCT,JSON,ARRAY 等复杂数据类型的查询分析。这些数据类型表达能力强,因此被广泛应用到 OLAP 分析的各种场景中,但由于其实现的复杂性,对这些复杂类型分析将会比一般简单类型…...

数据结构---数组
一、基本概念 1. 存放一组相同数据类型的集合 2.在内存中,分配连续的空间,数组创建时要指定大小 3. 定义 数据类型 [] 数组名 // 1.定义一个数组,里面的元素包含10, 20, 24, 17, 35, 58, 45, 74 int arr[] {10, 20, 24, 17, 35, 58, 45, 74}; 4. 获取数组的长度 int lengt…...
———链式语句中fetchSql和force和bind用法)
知识笔记(八十四)———链式语句中fetchSql和force和bind用法
fetchSql: fetchSql用于直接返回SQL而不是执行查询,适用于任何的CURD操作方法。 例如: $result Db::table(think_user)->fetchSql(true)->find(1);输出result结果为: SELECT * FROM think_user where id 1 force&#…...

为什么要用B+树
B树的优势 支持范围查询:B树在进行范围查询时,只需要从根节点一直遍历到叶子节点,因为数据都存储在叶子节点上,而且叶子节点之间有指针连接,可以很方便的进行范围查询 支持排序:B树的叶子节点按照关键字顺…...

Android 通过adb命令查看应用流量
一. 获取应用pid号 通过adb shell ps -A | grep 包名 来获取app的 pid号 二. 查看应用流量情况 使用adb shell cat /proc/#pid#/net/dev 命令 来获取流量数据 备注: Recevice: 表示收包 Transmit: 表示发包 bytes: 表示收发的字节数 packets: 表示收发正确的…...

超全的测试类型详解,再也不怕面试答不出来了!
在软件测试工作过程中或者在面试过程中经常会被问到一些看起来简单但是总是有些回答不上的问题,比如你说说“黑盒测试和白盒测试的区别?”,“你们公司做灰度测试么?", ”α测试和β测试有什么不一样?“࿰…...
【Linux】
Linux零基础入门 列出文件/文件夹新建/切换路径查看当前路径重命名或者移动文件夹拷贝文件/文件夹删除文件夹设置环境变量编辑文本文件压缩和解压查看cpu的信息查看/杀死进程查看进程的CPU和内存占用重定向日志场景一场景二场景三场景四 列出文件/文件夹 命令:Ls(L…...
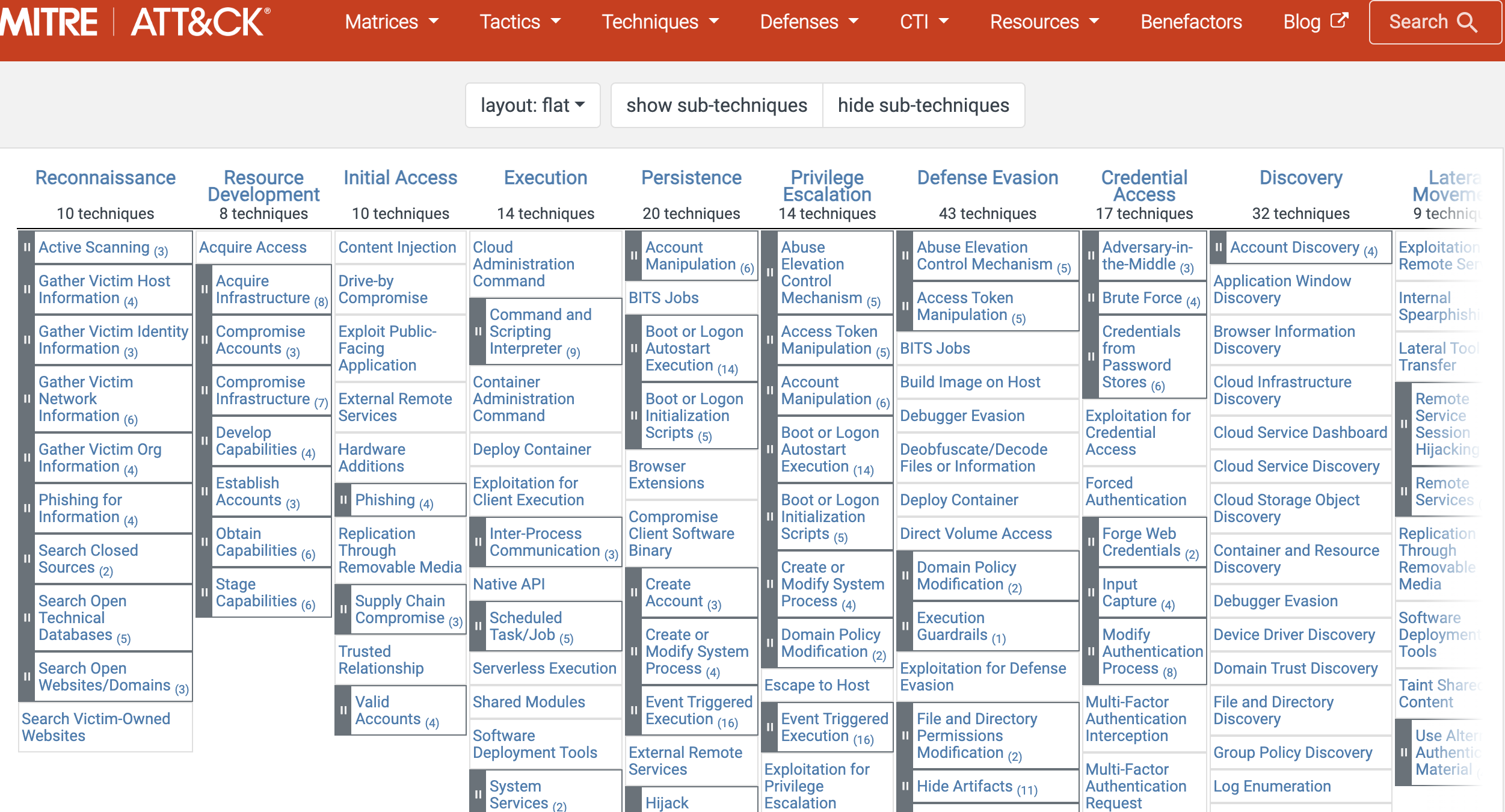
「 网络安全常用术语解读 」网络攻击者的战术、技术和常识知识库ATTCK详解
引言:随着网络攻击手段的不断升级和多样化,网络安全领域面临着越来越严峻的挑战。为了帮助网络安全专业人员更好地识别和防御网络攻击,MITRE公司创建了ATT&CK框架,以提供一个统一且结构化的方法来描述网络攻击者的行为和技巧。…...

Java.lang.Integer类详解
Java.lang.Integer类详解 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!在今天的文章中,我们将深度解析Java中的一个重要类——java.lang.Integer&…...

GitFlow工作流
基于 Git 这一版本控制系统,通过定义不同的分支,探索合适的工作流程来完成开发、测试、修改等方面的需求。 例如:在开发阶段,创建 feature 分支,完成需求后,将此分支合并到 develop 分支上;在发…...

GitHub Copilot 与 OpenAI ChatGPT 的区别及应用领域比较
GitHub Copilot 和 OpenAI ChatGPT 都是近年来颇受关注的人工智能项目,它们在不同领域中的应用继续引发热议。本文旨在分析和比较这两个项目的区别,从技术原理、应用场景、能力和限制、输出结果、能力与限制和发展前景等方面进行综合评估,帮助…...

【C++】类和对象(上篇)
文章目录 🛟一、面向过程和面向对象初步认识🛟二、类的引入🛟三、类的定义📝1、类的两种定义方式📝2、成员变量命名规则的建议 🛟四、类的访问限定符及封装🍩1、访问限定符🍩2、封装…...

甜蜜而简洁——深入了解Pytest插件pytest-sugar
在日常的软件开发中,测试是确保代码质量的关键步骤之一。然而,对于测试报告的生成和测试结果的可读性,一直以来都是开发者关注的焦点。Pytest插件 pytest-sugar 以其清晰而美观的输出,为我们提供了一种愉悦的测试体验。本文将深入介绍 pytest-sugar 插件的基本用法和实际案…...

SpringBoot3整合OpenAPI3(Swagger3)
文章目录 一、引入依赖二、使用1. OpenAPIDefinition Info2. Tag3. Operation4. Parameter5. Schema6. ApiResponse swagger2更新到3后,再使用方法上发生了很大的变化,名称也变为OpenAPI3。 官方文档 一、引入依赖 <dependency><groupId>…...

2023美赛各题分析,2024美赛数学建模思路解析2.2日第一时间更新
目录 2024美赛数学建模各题思路模型代码:开赛后第一时间更新,更新见文末 一、2023题目重述 拟解决的问题 我们的工作: 二、模型和计算 1.数据预处理 2.报告数量区间预测模型 3.猜词结果分布预测模型 2024美赛数学建模交流࿰…...
分享一个学习git的网站
Learn Git Branching...

用户拉新的4大关键策略,照着做就对了!
今天给大家分享用户拉新的4个关键策略,掌握了这些策略,不仅有助于增加用户数量,还能让对方成为你忠实的粉丝。 1、制定明确的目标:在开始拉新之前,你需要明确自己的目标。你想要吸引什么样的用户?你希望他…...
如何用“VMware安装Ubuntu”win11系统?
一、 下载Ubuntu 企业开源和 Linux |Ubuntu的 二、 安装 三、 启动虚拟机 选中Try or Install Ubuntu Server,按回车...

ZJOI2009 对称的正方形
P2601 [ZJOI2009] 对称的正方形 题目大意 给定一个 n m n\times m nm的矩阵,求这个矩阵中满足上下对称且左右对称的正方形子矩阵的个数。 1 ≤ n , m ≤ 1000 1\leq n,m\leq 1000 1≤n,m≤1000 题解 首先,我们对原矩阵、左右翻转后的矩阵、上下翻转后…...
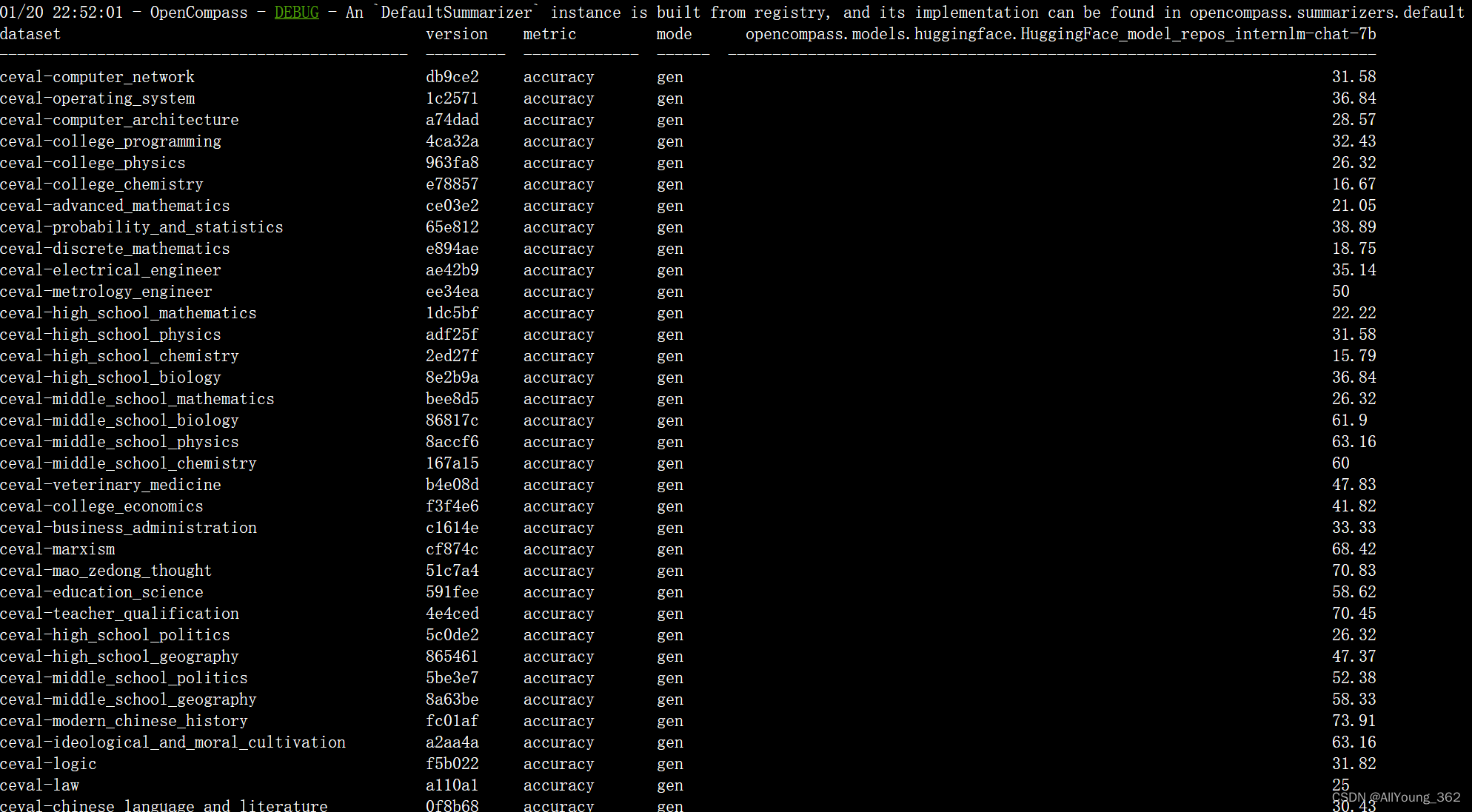
大模型学习与实践笔记(十一)
一、使用OpenCompass 对模型进行测评 1.环境安装: git clone https://github.com/open-compass/opencompass cd opencompass pip install -e . 当github超时无法访问时,可以在原命令基础上加上地址: https://mirror.ghproxy.com git clon…...

STM32 HAL库实战:用CD74HC4067扩展模拟输入通道,附完整工程代码
STM32 HAL库实战:用CD74HC4067扩展模拟输入通道,附完整工程代码 在嵌入式开发中,模拟信号采集是常见需求,但MCU内置ADC通道数量往往有限。当面对多路传感器信号采集时,如何经济高效地扩展输入通道成为开发者必须解决的…...

转行对谈:转向AI是破茧成蝶还是折翼未来?
01前言|AI时代下的土建人 一、AI浪潮:开启一个崭新的时代 人工智能(AI)已经从学术前沿走向产业中心,成为当前时代最具颠覆性的技术之一。从最早“出圈”的对话式模型ChatGPT的火爆到AI绘画、AI写作等AIGC(生…...

AI 高性能笔记本电脑高效紧凑型功率 MOSFET 完整选型方案
随着 AI 算力在笔记本电脑中的爆发式增长(如本地大模型、智能温控、性能调度),电源架构对功率 MOSFET 提出严苛要求:超高电流密度、极低损耗、超小封装、逻辑电平驱动。微碧半导体(VBsemi)基于先进的 Trenc…...

保姆级教程:用QGIS 3.22.16给火星遥感影像‘抠图’,从创建矢量图层到GDAL裁剪一步到位
火星地质勘探实战:用QGIS精准提取毅力号影像的五大核心技巧 当第一缕阳光掠过火星杰泽罗陨石坑的悬崖,毅力号传回的遥感影像中藏着无数科学秘密。作为太空数据分析师,我们常需要从广袤的火星地表影像中精确"抠"出目标区域——就像地…...

3步实现B站缓存视频智能转换:高效保存珍贵学习资源
3步实现B站缓存视频智能转换:高效保存珍贵学习资源 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他…...

Simscape Electrical电机控制器设计实战:5大核心技术深度解析与性能优化
Simscape Electrical电机控制器设计实战:5大核心技术深度解析与性能优化 【免费下载链接】Design-motor-controllers-with-Simscape-Electrical This repository contains MATLAB and Simulink files used in the "How to design motor controllers using Sims…...

MASA模组中文汉化包:让技术模组真正为你所用
MASA模组中文汉化包:让技术模组真正为你所用 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft技术模组的英文界面而头疼吗?当你在使用Litematica进…...

【亲测免费】 Zynq平台网络芯片RTL8211FD配置资源推荐
Zynq平台网络芯片RTL8211FD配置资源推荐 【下载地址】Zynq使用网络芯片RTL8211FD资源文件 本仓库提供了一个用于Zynq平台使用网络芯片RTL8211FD的资源文件。由于Xilinx的源代码默认不支持RTL8211FD,本资源文件中的程序可以替代Xilinx的默认配置,使得Zynq…...

完整指南:如何通过JiYuTrainer高效解除极域电子教室限制
完整指南:如何通过JiYuTrainer高效解除极域电子教室限制 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer JiYuTrainer是一款专业级的极域电子教室破解工具,…...

别再只用BLAST了!试试MAFFT+HMMER这套组合拳,挖掘基因家族新成员更精准
基因家族分析进阶指南:MAFFT与HMMER的高效组合策略 在基因组学研究领域,识别基因家族成员是一项基础而关键的工作。传统方法如BLAST虽然广为人知,但在面对远缘同源基因或高度分化的基因家族时,其灵敏度往往不尽如人意。这时&#…...