NLP预训练模型
Models Corpus
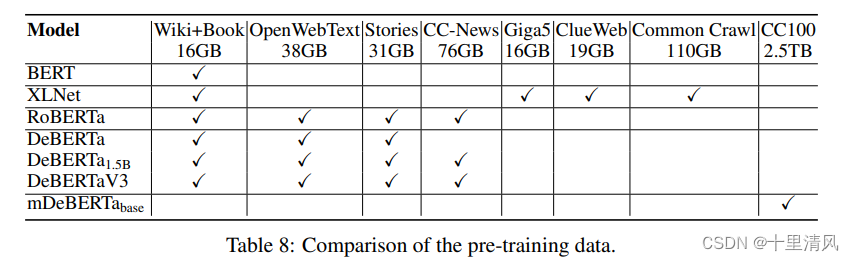
RoBERTa: A Robustly Optimized BERT Pretraining Approach
与BERT主要区别在于:
- large mini-batches 保持总训练tokens数一致,使用更大的学习率、更大的batch size,adam β2=0.98\beta_2=0.98β2=0.98;
- dynamic masking 动态掩盖,同一份样本重复10次;
- FULL-SENTENCES without NSP 做了四种输入格式实验,验证了NSP任务的无效性,
DOC-SENTENCES方式最优:SEGMENT-PAIR+NSP:BERT输入类型,以一对文本段做了输入,文本段包含多句输入,总token数小于512;SENTENCE-PAIR+NSP:以句对作为输入,总长度可能远小于512,增加batch size使得单批次总tokens数接近其它方法;FULL-SENTENCES:从单篇文章或多篇文章采样的连续句子,不同文章句采用特殊标记拼接,总长度最多512;DOC-SENTENCES:从单篇文章采样的连续句子,总长度可能不足512,增加batch_size保持单批次总tokens数接近其它方法;
- larger byte-level BPE 词表大小从30K提升至50K,无预处理步骤,无unknown token;
Byte-Pair Encoding (BPE)
A hybrid between character- and word-level representations that allows handling the large vocabularies common in natural language corpora.
Instead of full words, BPE relies on subwords units, which are extracted by performing statistical analysis of the training corpus.
Radford et al. (2019) introduce a clever implementation of BPE that uses bytes instead of unicode characters as the base subword units. Using bytes makes it possible to learn a subword vocabulary of a modest size (50K units) that can still encode any input text without introducing any “unknown” tokens.
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS

给定一个mask的序列,对于各掩码位置,生成器预测:

判别器判别生成器预测序列中各token是否与原始token一致(Replaced Token Detection,RTD):

与GAN的区别在于,生成器以极大似然估计方式训练,不需要欺骗判别器。判别器梯度不反向传播至生成器,下游任务仅使用判别器。
生成器生成的token与原始token的语义接近,使用生成器预测序列作为判别器输入(更难区分),比随机替换token的方式更有效。
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
DISENTANGLED SELF-ATTENTION
改进自注意力机制,将不同位置的内容向量和相对位置向量的cross attention分数作为自注意力分数:

标准自注意力机制:

引入相对位置的分散自注意力机制:

上述矩阵各行对应各位置的向量表示,其中:
- H,Ho∈RN×dH,H_o\in\R^{N\times d}H,Ho∈RN×d,表示注意力层输入、输出隐状态;
- Qc,Kc,VcQ_c,K_c,V_cQc,Kc,Vc,表示经投影矩阵Wq,c,Wk,c,Wv,c∈Rd×dW_{q,c}, W_{k,c}, W_{v,c}\in\R^{d\times d}Wq,c,Wk,c,Wv,c∈Rd×d,投影后的内容向量;
- P∈R2k×dP\in\R^{2k\times d}P∈R2k×d,表示相对位置嵌入,所有层共享;
- Qr,KrQ_r,K_rQr,Kr,表示经投影矩阵Wq,r,Wk,r∈Rd×dW_{q,r},W_{k,r}\in\R^{d\times d}Wq,r,Wk,r∈Rd×d,投影后的相对位置向量;
- softmax\text{softmax}softmax,表示做行向量归一化,输出矩阵行向量为单位向量;
ENHANCED MASK DECODER ACCOUNTS FOR ABSOLUTE WORD POSITIONS
Given a sentence “a new store opened beside the new mall” with the words “store” and “mall” masked for prediction. Using only the local context (e.g., relative positions and surrounding words) is insufficient for the model to distinguish store and mall in this sentence, since both follow the word new with the same relative positions. For example, the subject of the sentence is “store” not “mall”. These syntactical nuances depend, to a large degree, upon the words’ absolute positions in the sentence.
语法上的细微差别,很大程度上取决于单词在句子中的绝对位置。
In DeBERTa, we incorporate them right after all the Transformer layers but before the softmax layer for masked token prediction, as shown in Figure 2. In this way, DeBERTa captures the relative positions in all the Transformer layers and only uses absolute positions as complementary information when decoding the masked words. Thus, we call DeBERTa’s decoding component an Enhanced Mask Decoder (EMD).
在所有transformers层之后、softmax之前,合并绝对位置信息,预测掩盖的token。

SCALE INVARIANT FINE-TUNING,SiFT
向标准化的word embeddings增加扰动,增强模型泛化性。
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
- 使用ELECTRA架构训练,以RTD代替MLM;
- 提出词向量梯度分散共享,优化生成器和判别器词向量共享,避免发生“tug-of-war”(激烈竞争);
DeBERTa with RTD
Replacing the MLM objective used in DeBERTa with the RTD objective.
Token Embedding Sharing in ELECTRA
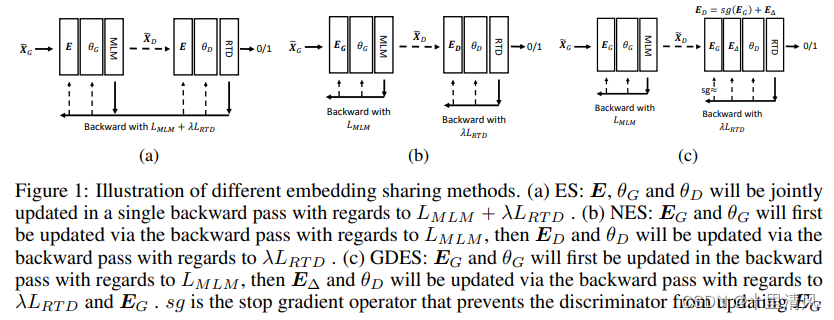
The tasks of MLM and RTD pull token embeddings into very different directions. MLM tries to map the tokens that are semantically similar to the embedding vectors that are close to each other. RTD, on the other hand, tries to discriminate semantically similar tokens, pulling their embeddings as far as possible to optimize the classification accuracy.
使用不同词向量共享和梯度传播方式,词向量平均余弦相似度比较:

Gradient-Disentangled Embedding Sharing
The training of GDES follows that of NES. EΔE_\DeltaEΔ is initialized as a zero matrix. In each training pass:
- Run a forward pass with the generator to generate the inputs for the discriminator, and then run a backward pass with respect to the MLM loss to update EGE_GEG, which is shared by both the generator and the discriminator.
- Run a forward pass for the discriminator using the inputs produced by the generator, and run a backward pass with respect to the RTD loss to update ED by propagating gradients only through EΔE_\DeltaEΔ.
- After model training, EΔE_\DeltaEΔ is added to EGE_GEG and the sum is saved as EDE_DED in the discriminator.
相关文章:
NLP预训练模型
Models Corpus RoBERTa: A Robustly Optimized BERT Pretraining Approach 与BERT主要区别在于: large mini-batches 保持总训练tokens数一致,使用更大的学习率、更大的batch size,adam β20.98\beta_20.98β20.98;dynamic ma…...
Typora上传文档图片链接失效的问题+PicGo布置图床在Github
文章目录typora图片链接失效原因PicGO开源图床布置先配置Github2.1先创建新仓库、用于存放图片2.2生成一个token,用picGo访问github3.下载picGo,并进行配置3.1 配置v4.1typora图片链接失效原因 因为你是保存在本地的,因此图片是不能访问,可以…...
win10安装oracle
文件放到最后。我的电脑是win11的,因为老师让写下安装笔记,在11上安装的时候没有截屏,所以在虚拟机上重新安装下吧。室友说要把文件夹放到c盘才能打开。我试了下,具体的是要把Oracle11g文件夹放到c盘根目录下。如果解压后不是这个…...
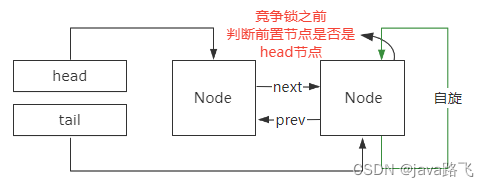
AQS为什么用双向链表?
首先,在AQS中,等待队列是通过Node类来表示的,每个Node节点包含了等待线程的信息以及等待状态。下面是Node类的部分源码:static final class Node {// 等待状态volatile int waitStatus;// 前驱节点volatile Node prev;// 后继节点…...

AtCoder Beginner Contest 292——A-E题讲解
蒟蒻来讲题,还望大家喜。若哪有问题,大家尽可提! Hello, 大家好哇!本初中生蒟蒻讲解一下AtCoder Beginner Contest 292这场比赛的A-E题! A题 原题 Problem Statement You are given a string SSS consisting of lo…...

(蓝桥真题)最长不下降子序列(权值线段树)
样例输入: 5 1 1 4 2 8 5 样例输出: 4 分析:看到这种对其中连续k个数进行修改的我们就应该想到答案是由三部分组成,因为求的是最长不下降子序列,那么我们可以找到一个最合适的断点i,使得答案是由区间[1…...

数据类型及参数传递
1.数据类型 java中的基本数据类型: 数值型: 整数型:byte short long int 浮点型:float double 布尔型: boolean字符串: char java中的引用数据类型: 数组(array) 类(class…...

永春堂1300系统开发|解析永春堂1300模式商城的五大奖项
电商平台竞争越来越激烈,各种营销方式也是层出不穷,其中永春堂1300营销模式,以其无泡沫和自驱动性强等特点风靡一时。在这套模式中,虽然单型价格差异较大,但各种奖励的设计,巧妙的兼顾了平台和所有会员的利…...

最近一年我都干了什么——反思!!
过去一年不管是学习方式还是心态上都和以往有了许多不同的地方,比较昏昏沉沉。最近慢慢找到状态了,就想赶紧记录下来。 学习 在学习新技术的过程中开始飘了,总感觉有了一些开发经验后就觉得什么都不用记,知道思路就行遇到了现场百…...
save 和 export 命令的区别)
Docker学习(十七)save 和 export 命令的区别
Docker 中有两个命令可以将镜像导出为本地文件系统中的 tar 文件:docker save 和 docker export。尽管它们的作用类似,但它们之间有一个重要的区别。 1.使用方式的不同: docker save 的使用示例: docker save -o test.tar image…...
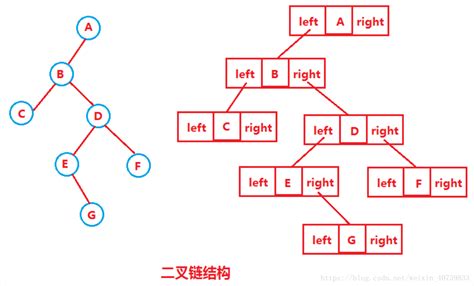
【数据结构初阶】详解“树”
目录 前言 1.树概念及结构 (1)树的概念 (2)树的名词介绍 (3)树的表示 编辑 2.二叉树概念及结构 (1)概念 (2)特殊的二叉树 (3࿰…...

20230304 CF855 div3 vp
Dashboard - Codeforces Round 855 (Div. 3) - Codeforces呃呃,评价是,毫无进步呃呃呃呃呃呃呃呃呃呃呃呃呃呃呃呃呃该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训了该加训…...
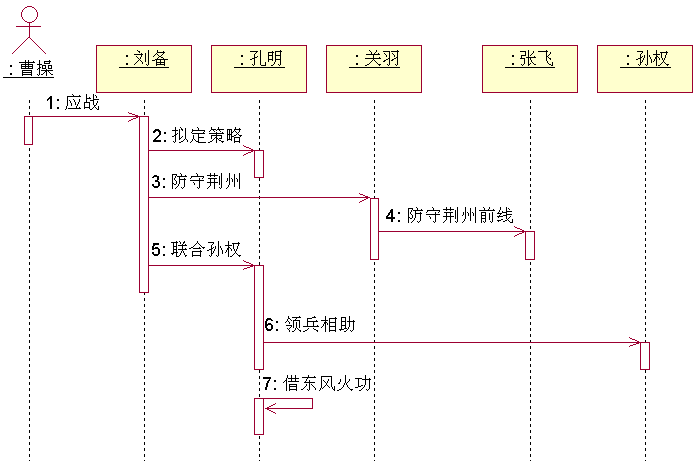
UML 时序图
时序图(Sequence Diagram)是显示对象之间交互的图,是按时间顺序排列的。 时序图中显示的是参与交互的对象及其对象之间消息交互的顺序。 时序图包括的建模元素主要有:对象(Actor)、生命线(Lif…...
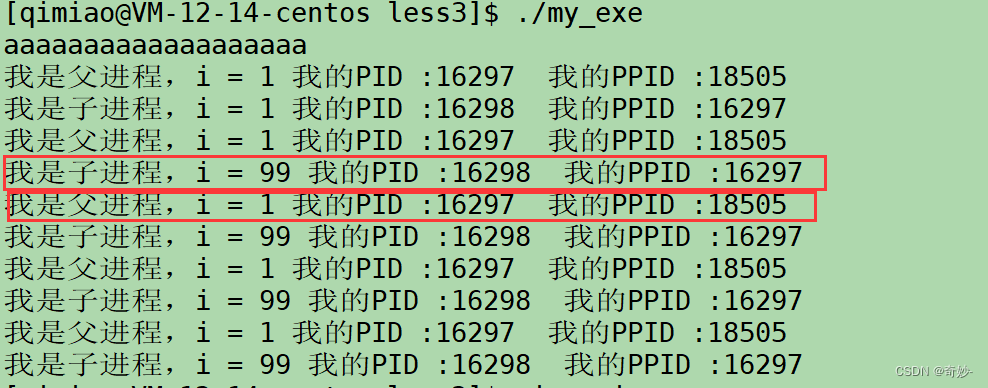
详解进程 及 探查进程
进程的概念PCB是什么task_struct的作用如何执行进程进程的探查什么是bashps命令的使用(查看进程)创建进程探究父子进程进程的概念 简而言之,进程就是正在在执行的程序 之前说过,程序执行的第一步Windows是双击程序Linux是 ./ &a…...
汇编相关问题
汇编语言期末复习题DX:单项选择题 DU:多项选择题 TK:填空题 MC:名词解释 v JD:简答题 CXFX:程序分析题 CXTK:程序填空题 BC:编程题第1章:基础知识1、在汇编语言程序的开发…...

华为OD机试Golang解题 - 火星文计算 2 | 包含思路
华为Od必看系列 华为OD机试 全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典文章目录 华为Od必看系列使用说明本期题目…...

成功解决configure: error: the HTTP rewrite module requires the PCRE library
文章目录 前言问题复现问题解决思考环节总结前言 大家好,我是沐风晓月,本专栏是记录日常实验中的所有疑难杂症,教程的安装,程序的bug,甚至各类报错,如果你也遇到了困惑和问题,欢迎与我一起交流学习。 另外不要解决完问题就结束了,思考环节也要好好看看哦。 问题复现…...

UNIX--GDB调试
通常,在为调试而编译时,我们会关掉编译器优化选项(-O),并打开调试选项(-g)。另外,-Wall 在尽量不影响程序行为的情况下选项打开所有 warning,也可以发现许多问题,避免一些不必要的 BUG。 GDB 命令-启动、退…...

孤单数算法
1.背景 腾讯终面:孤单的QQ号码怎么找? 问题一:有n个QQ号码,除1个孤单的QQ号码外,其余的QQ号码都是成双成对的,求这个孤单的QQ号码,要求:时间复杂度为O(n), 空间复杂度为O(1). 问题…...

triangulate_object_model_3d算子总结
目录 1.去掉固定方向的点云干扰 2.增加八叉树深度,实现更高细节级别的三角测量 3.腐蚀和膨胀,得到更平滑的点云 1.去掉固定方向的点云干扰 例程:triangulate_object_model_3d_xyz_mapping.hdev...

GT New Horizons材质包精选:10款提升沉浸体验的视觉升级方案
GT New Horizons材质包精选:10款提升沉浸体验的视觉升级方案 【免费下载链接】GT-New-Horizons-Modpack A big progressive questing modpack for Minecraft 1.7.10 balanced around the mod GregTech. 项目地址: https://gitcode.com/GitHub_Trending/gt/GT-New-…...

4款降AI率工具实测横评:最便宜和最贵的效果差多少?
花了几百块,测了一圈,现在把结果告诉你。 降AI率工具、降AI工具保姆级测评2026、降AI这个需求,不同工具之间差距其实挺明显的,不是"随便用一个都一样"。 我的结论:嘎嘎降AI(www.aigcleaner.com…...

Atmosphere:重新定义Nintendo Switch自制固件的革命性框架
Atmosphere:重新定义Nintendo Switch自制固件的革命性框架 【免费下载链接】Atmosphere Atmosphre is a work-in-progress customized firmware for the Nintendo Switch. 项目地址: https://gitcode.com/GitHub_Trending/at/Atmosphere 你是否曾想过&#x…...

火山引擎语音合成SDK实战:从快速调用到高级参数调优
1. 火山引擎语音合成SDK初体验 第一次接触火山引擎的语音合成SDK时,我正为一个智能客服项目发愁。客户要求系统能够用不同音色、不同情感的语音播报订单状态,而市面上大多数TTS服务要么太贵,要么效果生硬。直到同事推荐了火山引擎的解决方案&…...

Z-Image-Turbo-rinaiqiao-huiyewunv实战落地:高校动漫社AI辅助创作工作流搭建
Z-Image-Turbo-rinaiqiao-huiyewunv实战落地:高校动漫社AI辅助创作工作流搭建 1. 项目背景与核心价值 高校动漫社团经常面临创作效率低、人手不足的问题。传统手绘方式需要大量时间,而通用AI绘图工具又难以保持角色一致性。Z-Image Turbo (辉夜大小姐-…...

STM32F4读写SD卡:填一填ST官方HAL库的坑
使用STM32读写SD卡在低功耗存储中的应用是比较常见的,但是网上大多数资料都是基于标准库或者基于寄存器的开发。随着嵌入式设备越来越复杂,使用HAL库能够大大降低开发者的学习成本,从而提高开发效率。近年来,ST官方主推以STM32Cub…...
)
SpringBoot项目实战:用Java海康SDK搞定摄像头录像与门禁人脸下发(附完整代码)
SpringBoot企业级实战:海康威视SDK深度集成与智能安防系统开发 1. 企业级安防系统架构设计 在智能园区和现代化办公环境中,视频监控与门禁管理的无缝集成已成为刚需。海康威视作为全球领先的安防解决方案提供商,其设备SDK的深度集成能够为Jav…...

Windows系统效能优化指南:基于Win11Debloat的系统调校方案
Windows系统效能优化指南:基于Win11Debloat的系统调校方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...
)
Windows系统SID全解析:从查看到修改的5种实用方法(附工具推荐)
Windows系统SID全解析:从查看到修改的5种实用方法(附工具推荐) 在Windows系统管理中,安全标识符(SID)是一个至关重要的概念,它如同每个用户、组和计算机账户的"身份证号码"。想象一下…...

Kandinsky-5.0-I2V-Lite-5s开源模型部署:无需代码基础的图形化AI视频工具
Kandinsky-5.0-I2V-Lite-5s开源模型部署:无需代码基础的图形化AI视频工具 1. 产品介绍 Kandinsky-5.0-I2V-Lite-5s是一款革命性的图生视频AI工具,它将复杂的视频制作过程简化为几个简单的点击操作。不同于传统需要专业剪辑软件和技能的视频制作方式&am…...