【AI大模型】WikiChat超越GPT-4:在模拟对话中事实准确率提升55%终极秘密
WikiChat,这个名字仿佛蕴含了无尽的智慧和奥秘。它不仅是一个基于人工智能和自然语言处理技术的聊天机器人,更是一个能够与用户进行深度交流的智能伙伴。它的五个突出特点:高度准确、减少幻觉、对话性强、适应性强和高效性能,使得它在众多聊天机器人中脱颖而出,成为用户心中的明星。
Wikichat论文中写道:
WikiChat,这是第一个基于少量提示的LLM聊天机器人,它在模拟对话中的事实准确率几乎可以达到100%,且具有高度的对话性和低延迟。WikiChat建立在英语维基百科上,这是最大的 curated free-text 语料库。WikiChat从一个LLM中生成响应,保留只有被事实证明的事实,并将它们与从语料中检索的附加信息结合起来,形成事实性和吸引人的响应。作者通过实验表明,该系统在模拟对话中的事实准确率达到了97.3%,在最近的谈话主题中的事实准确率达到了97.9%,这比GPT-4的事实准确率提高了55.0%。此外,WikiChat的响应时间短,且成本低,可以适用于需要高事实性和高度对话性的应用场景。
这是一个大模型的突破,也是一个人类迈向更智能,信息渠道更放心,更精确的一个开始!

一、高度准确
WikiChat就像一位学识渊博的学者,它的知识来源于维基百科这座世界级的知识宝库。维基百科的权威性和准确性为WikiChat提供了坚实的基础,使得它能够为用户提供高度准确的信息。WikiChat利用先进的检索算法和自然语言处理技术,如同一位精通多国语言的翻译家,能够准确地理解和解析用户的问题,并从维基百科中检索相关的权威信息来回答问题。同时,WikiChat不断优化其技术架构,采用深度学习等先进技术来训练模型,使其能够更加深入地理解用户问题,并给出更加精确的答案。

二、减少幻觉
WikiChat在减少幻觉方面有着独特的优势。它结合了维基百科的数据和大型语言模型(LLM),如同一位严谨的历史学家,不断挖掘和验证信息的真实性。在讨论最新事件或不太流行的话题时,大型语言模型往往会因为缺乏最新的信息而产生错误信息,而WikiChat则能够利用维基百科这一频繁更新的信息源,为大型语言模型提供最新、最准确的信息。此外,WikiChat还采用了事实核查机制,对生成的回答进行验证和筛选,进一步确保信息的准确性,让用户可以信赖它的每一个答案。

在减少幻觉方面,结合维基百科和大型语言模型(LLM)可以通过以下步骤实现:
数据获取:首先,需要从维基百科获取相关的数据。维基百科提供了丰富的结构化数据,包括文章、元数据以及相关的链接信息。你可以使用Python中的网络爬虫库(如BeautifulSoup或Scrapy)来从维基百科网站爬取所需的数据。
数据预处理:获取到的维基百科数据通常需要进行预处理,以便与大型语言模型结合使用。这包括数据清洗、格式化、去除噪声等步骤。你可以使用Python中的数据处理库(如pandas)来处理这些数据,并将其转换为适合LLM输入的格式。
结合LLM:将预处理后的维基百科数据与大型语言模型结合,可以采用多种方法。一种常见的方法是将维基百科数据作为LLM的额外输入或上下文信息。你可以将维基百科的相关文章或摘要与LLM的输入序列进行拼接,作为模型的输入。另一种方法是将维基百科的数据用作LLM的知识库或外部记忆,通过在LLM中引入注意力机制或记忆网络来实现对维基百科数据的访问和利用。
训练与推理:在结合了维基百科数据和LLM之后,你可以使用适当的训练算法对模型进行训练,以使其能够理解和利用维基百科的知识。在推理阶段,你可以将用户的问题或输入提供给训练好的模型,并获取其生成的回答或响应。
以下Python代码,展示了如何使用维基百科数据和LLM结合来减少幻觉:
import requests
from bs4 import BeautifulSoup
from transformers import AutoTokenizer, AutoModelForSequenceClassification# 从维基百科获取数据
url = "https://en.wikipedia.org/wiki/Example_Article"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
wikipedia_text = soup.find("div", {"class": "mw-parser-output"}).text# 数据预处理
# 在这里可以对wikipedia_text进行清洗、格式化等操作# 加载预训练的大型语言模型(LLM)和分词器
model_name = "path/to/your/llm/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)# 将维基百科数据与LLM结合
input_text = "Question: " + user_question + " Context: " + wikipedia_text
encoded_input = tokenizer(input_text, return_tensors="pt")
output = model(**encoded_input)
answer = tokenizer.decode(output.logits.argmax(dim=-1))print("Answer:", answer)
三、对话性强
WikiChat的对话性强体现在其流畅、自然的对话风格上。它不仅仅是一个简单的问答系统,更是一个能够理解用户意图并生成恰当回应的智能对话平台。WikiChat使用大型语言模型生成对话历史的回应,如同一位贴心的朋友,能够根据对话的上下文生成恰当的回应,让用户感受到真正的对话体验。同时,WikiChat还能利用自然语言处理技术理解用户的意图和情绪,如同一位心理咨询师,能够提供更加智能、个性化的对话体验。

四、适应性强
WikiChat的适应性强体现在它能够轻松应对各种类型的查询和对话场景。无论是简单的知识问答还是需要深入思考的观点讨论,WikiChat都能游刃有余地应对。这得益于其基于维基百科的丰富知识库和强大的自然语言处理能力。WikiChat能够处理各种类型的知识问答并处理复杂的观点讨论,如同一位全能的辩论家,能够应对各种挑战。此外,它还具备识别用户查询意图的能力提高了用户的满意度。
模型的高适应性主要来源于以下几个方面:
参数化表示:模型通过参数化的方式表示数据中的规律。当面对新的任务或数据时,只需要调整模型的参数,就可以适应新的情况。这种参数化的表示方式使得模型具有很强的灵活性。
from transformers import AutoTokenizer, AutoModelForSequenceClassification# 加载预训练模型和分词器
model_name = "path/to/your/llm/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)# 输入文本
input_text = "Hello, WikiChat! How are you today?"# 对输入文本进行编码
encoded_input = tokenizer(input_text, return_tensors="pt")# 获取模型的输出
output = model(**encoded_input)# 处理输出,例如获取分类结果或生成文本等
answer = output.logits.argmax(dim=-1)# 输出结果
print("Answer:", answer)
学习能力:
模型具备从数据中学习的能力,能够根据已有的知识调整自身的结构或参数以适应新的环境或任务。这种学习能力使得模型能够不断地优化自身,提高适应性。
import torch
from torch.utils.data import DataLoader
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments# 加载预训练模型和分词器
model_name = "path/to/your/llm/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)# 准备数据集
train_dataset = ... # 这里需要准备训练数据集
train_dataloader = DataLoader(train_dataset, batch_size=16)# 设置训练参数
training_args = TrainingArguments(output_dir="./results",num_train_epochs=3,per_device_train_batch_size=16,warmup_steps=500,weight_decay=0.01,logging_dir="./logs",
)# 设置训练器并进行训练
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,
)
trainer.train()
泛化能力:
模型在训练过程中不仅拟合了训练数据,还学习到了数据的内在规律和结构。这使得模型在面对与训练数据分布相似的新数据时,能够做出合理的预测和决策。
调优技巧:
针对不同的应用场景,可以使用各种调优技巧来优化模型的性能,如选择合适的模型架构、调整超参数、使用正则化方法等。这些技巧可以帮助模型更好地适应特定的任务和数据。
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification# 加载预训练模型和分词器(这里使用之前训练好的模型)
model_name = "path/to/your/trained/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)# 输入新文本并进行编码
new_text = "Who is the president of the United States?"
encoded_input = tokenizer(new_text, return_tensors="pt")# 获取模型的输出并进行预测
output = model(**encoded_input)
prediction = output.logits.argmax(dim=-1).item()
answer = tokenizer.decode([prediction]) # 将预测结果解码为可读的文本答案
核心集成模型介绍:
通过将多个模型进行组合或集成,可以充分利用各个模型的优点,提高整体模型的适应性。例如,使用集成学习方法(如随机森林、梯度提升等)可以将多个弱模型组合成一个强模型,从而提高模型的预测精度和稳定性。
下面我们从中提取当中最典型的2个模型进行详细的说明:
模型一:提高精度的模型WikiChat L
LLaMA(Large Language Model Family of AI)是一种大型语言模型,具有出色的性能和效率。在WikiChat中,为了提高速度和效率,使用了LLaMA模型对WikiChat进行了蒸馏,得到了一个具有7B参数的LLaMA模型,称为WikiChat L。
蒸馏是一种常用的模型压缩技术,它通过将一个大型的教师模型(Teacher Model)的知识蒸馏到一个较小的学生模型(Student Model)中,从而在保持较高性能的同时减小模型的大小和计算复杂度。在WikiChat中,原始的WikiChat模型作为教师模型,而LLaMA模型作为学生模型进行蒸馏。
具体的蒸馏过程包括以下几个步骤:
准备数据:使用WikiChat模型的输出作为教师模型的标签,将输入数据作为教师模型的输入。
训练学生模型:使用教师模型的输入和输出数据对学生模型进行训练。在训练过程中,通过最小化学生模型的输出与教师模型的输出之间的差异来优化学生模型的参数。
蒸馏损失函数:为了使学生模型能够更好地学习到教师模型的知识,可以使用蒸馏损失函数来衡量学生模型与教师模型之间的差异。常见的蒸馏损失函数包括均方误差(MSE)和交叉熵损失(Cross-Entropy Loss)等。
模型评估:在训练完成后,使用验证集或测试集对学生模型进行评估,以验证其性能和效果。
import torch
import torch.nn as nn
from transformers import LlamaForMaskedLM, LlamaTokenizer# 加载预训练的WikiChat教师和LLaMA学生模型
teacher_model = WikiChatModel.from_pretrained("wikichat_teacher_model")
student_model = LlamaForMaskedLM.from_pretrained("llama_student_model")
tokenizer = LlamaTokenizer.from_pretrained("llama_student_model")# 准备输入数据
input_text = "Hello, WikiChat! How are you today?"
input_ids = tokenizer.encode(input_text, return_tensors="pt")# 获取教师模型的输出
with torch.no_grad():teacher_outputs = teacher_model(input_ids)# 计算学生模型的输出
student_outputs = student_model(input_ids)# 计算蒸馏损失
loss_fn = nn.MSELoss()
loss = loss_fn(student_outputs.logits, teacher_outputs.logits)# 反向传播和优化
optimizer = torch.optim.Adam(student_model.parameters(), lr=0.001)
optimizer.zero_grad()
loss.backward()
optimizer.step()# 输出蒸馏损失和学生模型的预测结果
print("Distillation Loss:", loss.item())
print("Student Model Prediction:", tokenizer.decode(student_outputs.logits.argmax(dim=-1).squeeze()))
模型二:事实检查模型
是用于检查大型语言模型(LLM)生成内容的事实准确性的重要工具。基于prompt的链式思维模型是一种有效的事实检查方法。下面我将介绍这种模型的工作原理,并配合源代码进行说明。
基于prompt的链式思维模型通过构建一系列的问题提示(prompts),引导LLM进行逐步深入的思考和推理,从而检查生成内容的事实准确性。这个过程可以分为以下几个步骤:
构建问题提示(prompts):根据待检查的内容,设计一系列有针对性的问题提示。这些问题提示应该能够引导LLM关注关键的事实细节,并进行相应的思考和推理。
生成回答:将问题提示逐一输入到LLM中,让其生成对应的回答。LLM会根据问题提示进行推理和分析,并给出相应的回答。
事实验证:对LLM生成的回答进行事实验证。这可以通过与已知的事实数据库进行对比,或者利用其他可靠的信息源进行验证。如果LLM的回答与事实不符,可以认为其生成的内容存在事实错误。
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification# 加载预训练的LLM模型和分词器
model_name = "path/to/your/llm/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)# 定义问题提示和待检查的内容
prompts = ["问题1:", "问题2:", "问题3:"]
content = "待检查的内容"# 对每个问题提示进行推理和回答生成
answers = []
for prompt in prompts:input_text = prompt + contentencoded_input = tokenizer(input_text, return_tensors="pt")output = model(**encoded_input)answer = output.logits.argmax(dim=-1).item()answers.append(answer)# 进行事实验证
# 假设facts是一个包含已知事实的列表
facts = ["事实1", "事实2", "事实3"]
is_factually_correct = all(answer in facts for answer in answers)if is_factually_correct:print("内容事实准确")
else:print("内容存在事实错误")
五、高效性能
WikiChat的高效性能体现在其快速响应和低运行成本这两个方面。它能够在短时间内准确回答用户的问题提供及时的帮助和信息。为了实现这一目标WikiChat采用了一系列先进的算法设计和优化措施以及知识图谱技术和机器学习技术如同一位高效的计算机科学家不断优化程序的运行效率。同时WikiChat的运行成本也相对较低这得益于其高效的计算资源利用如分布式计算架构和缓存技术等使得它能够以更低的成本为用户提供优质的服务。

WikiChat不仅仅是一个聊天机器人更是一个智慧的象征它利用了人工智能和自然语言处理技术的力量将科技与人类的生活紧密相连。它的高度准确性、减少幻觉的能力、强大的对话性、广泛的适应性以及高效性能都让我们对未来充满了期待。WikiChat的发展将会进一步推动人工智能技术的进步并为人类的生活带来更多便利和乐趣。
相关文章:
【AI大模型】WikiChat超越GPT-4:在模拟对话中事实准确率提升55%终极秘密
WikiChat,这个名字仿佛蕴含了无尽的智慧和奥秘。它不仅是一个基于人工智能和自然语言处理技术的聊天机器人,更是一个能够与用户进行深度交流的智能伙伴。它的五个突出特点:高度准确、减少幻觉、对话性强、适应性强和高效性能,使得…...
【C语言刷题系列】水仙花数的打印及进阶
1.水仙花数问题 水仙花数(Narcissistic number)也被称为超完全数字不变数(pluperfect digital invariant, PPDI)、自恋数、自幂数、阿姆斯壮数或阿姆斯特朗数(Armstrong number) 水仙花数是指一个 3 位数&a…...
ICSpector:一款功能强大的微软开源工业PLC安全取证框架
关于ICSpector ICSpector是一款功能强大的开源工业PLC安全取证框架,该工具由微软的研究人员负责开发和维护,可以帮助广大研究人员轻松分析工业PLC元数据和项目文件。 ICSpector提供了方便的方式来扫描PLC并识别ICS环境中的可疑痕迹,可以用于…...

HCIA——29HTTP、万维网、HTML、PPP、ICMP;万维网的工作过程;HTTP 的特点HTTP 的报文结构的选择、解答
学习目标: 计算机网络 1.掌握计算机网络的基本概念、基本原理和基本方法。 2.掌握计算机网络的体系结构和典型网络协议,了解典型网络设备的组成和特点,理解典型网络设备的工作原理。 3.能够运用计算机网络的基本概念、基本原理和基本方法进行…...

面试经典题---3.无重复字符的最长子串
3.无重复字符的最长子串 我的解法: 滑动窗口: 维护一个[left, right)的滑动窗口,其中[left, right - 1]都是不重复子串;每轮while循环都计算一个滑动窗口的无重复子串长度len,每轮也让right后移一步; 内部…...

使用Robot Framework实现多平台自动化测试
基于Robot Framework、Jenkins、Appium、Selenium、Requests、AutoIt等开源框架和技术,成功打造了通用自动化测试持续集成管理平台(以下简称“平台”),显著提高了测试质量和测试用例的执行效率。 01、设计目标 平台通用且支持不…...
Java基础进阶02-xml
目录 一、XML(可拓展标记语言) 1.学习网站: 2.作用 3.XML标签 4.XML语法 5.解析XML (1)常见解析思想DOM 6.常见的解析工具 7.DOM4j的使用 8.文档约束 (1)概述 (2…...

《开始使用PyQT》 第01章 PyQT入门 03 用户界面介绍
03 用户界面介绍 《开始使用PyQT》 第01章 PyQT入门 03 用户界面介绍 The user interface (UI) has become a key part of our everyday lives, becoming the intermediary between us and our ever-growing number of machines. A UI is designed to facilitate in human-co…...

HTML-列表
列表 abbr: li : list item ol : orderd list ul : unordered list dl : definition list dt : definition title dd : definition description 1.有序列表(order list) 概念:有顺序或侧重顺序的列表 <h2>要把大象放冰箱总共分几步</h2> &…...
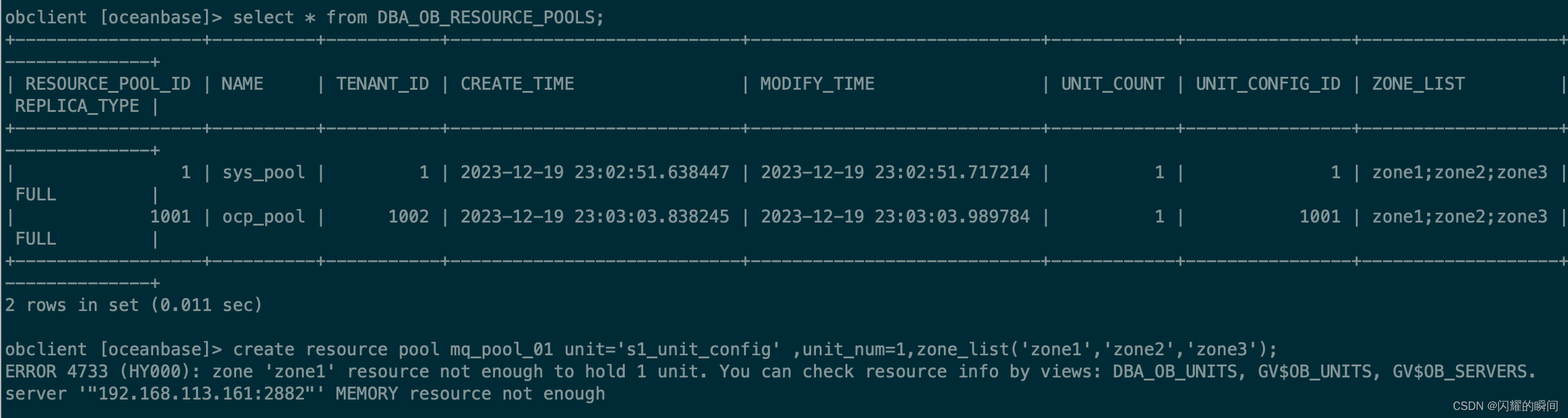
OceanBase创建租户
租户是集群之上的递进概念,OceanBase 数据库采用了多租户架构。 集群偏部署层面的物理概念,是 Zone 和节点的集合,租户则偏向于资源层面的逻辑概念,是在物理节点上划分的资源单元,可以指定其资源规格,包括…...
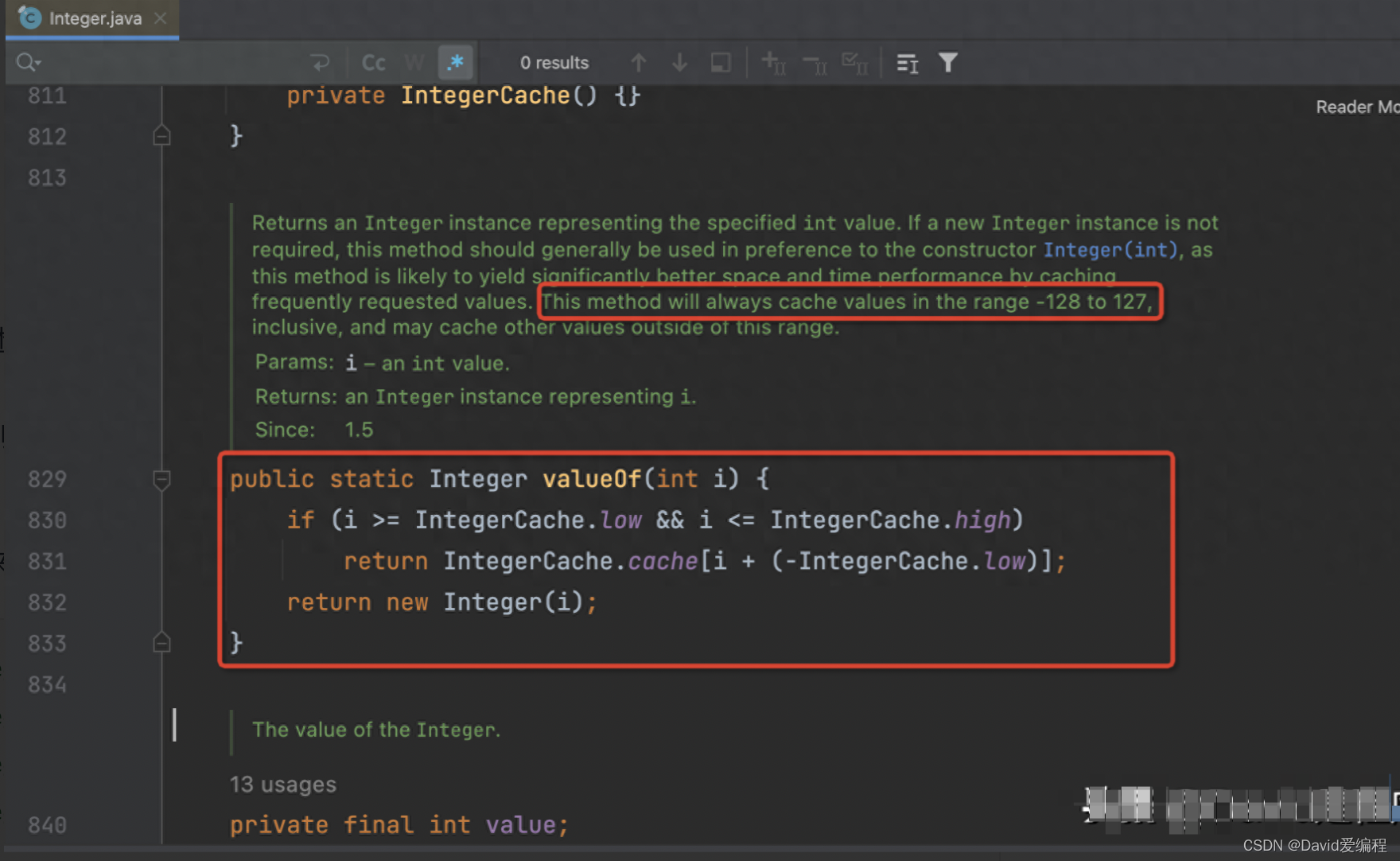
Java中Integer(127)==Integer(127)为True,Integer(128)==Integer(128)却为False,这是为什么?
文章目录 1.前言2. 源码解析3.总结 1.前言 相信大家职业生涯中或多或少的碰到过Java比较变态的笔试题,下面这道题目大家应该不陌生: Integer i 127; Integer j 127;Integer m 128; Integer n 128;System.out.println(i j); // 输出为 true System.o…...
【Unity】粒子贴图异常白边问题
从PS制作的黑底,白光的贴图。放入Unity粒子中,拉远看会有很严重的白边,像马赛克一样。 材质使用:Mobile/Particles/Additive 经测试只使用一张黑色的图片,也会有白边。 解决方案: 关闭黑色底…...

bxCAN接收处理
接收处理 为了接收 CAN 消息,提供了构成 FIFO(First Input First Output) 的三个邮箱。为了节约 CPU 负载,简化软件并保证数据一致性,FIFO 完全由硬件进行管理。应用程序通过 FIFO 输出邮箱访问 FIFO 中所存储的消息。 有效消息 当消息依据…...
前端面试题-(浏览器内核,CSS选择器优先级,盒子模型,CSS硬件加速,CSS扩展)
前端面试题-(浏览器内核,CSS选择器优先级,盒子模型,CSS硬件加速,CSS扩展) 常见的浏览器内核CSS选择器优先级盒子模型CSS硬件加速CSS扩展 常见的浏览器内核 内核描述Trident(IE内核)主要用在window系统中的IE浏览器中&…...

WEB前端标签的使用
图片标签 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><!-- img标签就是用来将图片显示在页面上的标签 --><img src"图片路径"><!-- 可用路径&#…...

739. 每日温度
提示给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。 示例 1: 输入: tempe…...
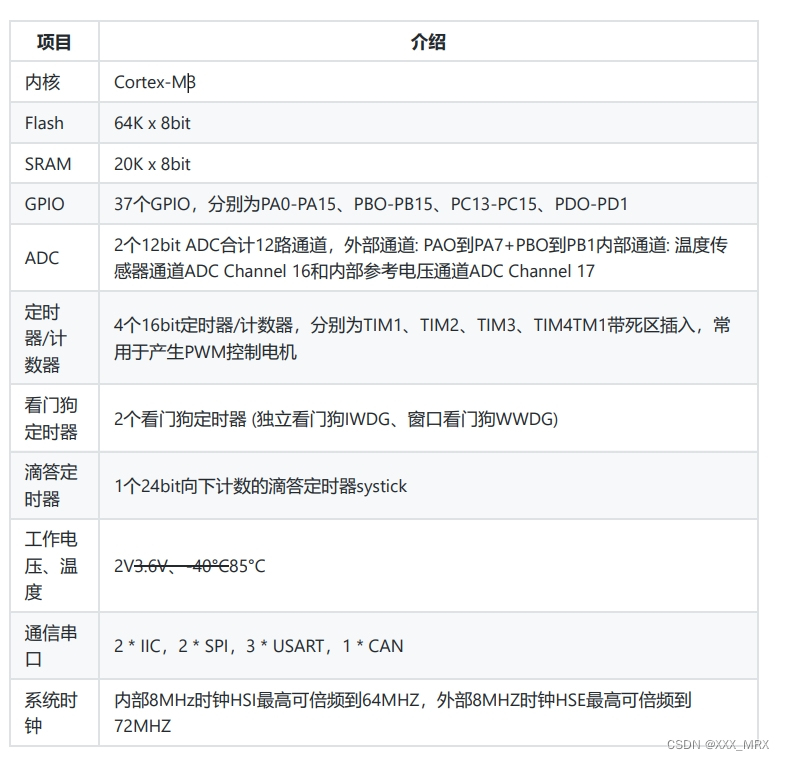
stm32F103C8T6简介及标准库和HAL库的区别
什么是单片机 单片机是一种集成电路芯片,把具有数据处理能力的中央处理器CPU、随机存储器RAM、只读存储器ROM、多种I/O和中断系统、定时器/计数器等功能(可能还包括显示驱动电路、脉宽调制电路、模拟多路转换电路、A\D转换器等电路)集成到一…...

操作系统(3)---操作系统引导
在安装操作系统后,磁盘的分布如下: C盘是这个磁盘的活动分区(又称主分区),安装了操作系统 开机过程如下: 1.计算机的主存由RAM和ROM组成,RAM关机数据消失,而ROM(Basic In…...

Vue3+Ts:实现paypal按钮
Vue3Ts:实现paypal按钮 一、前端页面按钮实现第一步:下载paypal.js依赖第二步:引入要使用的vue页面,并调用。 二、实现逻辑研究第一点:了解下Buttons自带的style属性第二点:了解下Buttons自带的处理方法第三…...

.[Decipher@mailfence.com].faust 勒索病毒数据怎么处理|数据解密恢复
尊敬的读者: 随着网络技术的发展,勒索病毒已经成为数字时代中一种极具破坏性的威胁。[support2022cock.li].faust [tsai.shenmailfence.com].faust [Encrypteddmailfence.com].faust[Deciphermailfence.com].faust 勒索病毒是其中的一种,它以…...

PheroPath:自定义代谢通路构建与可视化工具在组学数据分析中的应用
1. 项目概述与核心价值最近在生物信息学和计算生物学领域,一个名为“PheroPath”的项目引起了我的注意。这个项目由用户starpig1129托管,从名字上就能嗅到一丝“信息素”和“路径”结合的味道。作为一名长期在组学数据分析、特别是代谢通路研究一线摸爬滚…...

用Python和MATLAB复现DMD算法:从COVID-19死亡数据预测到动态模态分解实战
用Python和MATLAB复现DMD算法:从COVID-19死亡数据预测到动态模态分解实战 动态模态分解(Dynamic Mode Decomposition, DMD)作为一种数据驱动的建模方法,近年来在复杂系统分析、流体力学和流行病预测等领域展现出强大潜力。本文将带…...

技术生态依赖的实质与破局:从Android到自主可控的实践路径
1. 项目背景与核心议题解析最近在整理行业资料时,翻到一篇2013年的旧文,讨论的是当时中国工信部对国内移动产业过度依赖Android系统的担忧。虽然时过境迁,但文中提到的“技术自主可控”与“全球生态融入”之间的张力,在今天看来依…...

订阅Token Plan套餐后在长期项目中的成本节约效果分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 订阅Token Plan套餐后在长期项目中的成本节约效果分析 对于需要持续、稳定调用大模型的个人开发者或团队而言,成本控制…...

2026年搜索引擎大变革:生成式优化服务如何引领未来趋势
随着AI技术的不断进步,搜索引擎领域正在经历一场前所未有的变革。2026年,我们见证了从传统SEO到生成式引擎优化(GEO)的重大转变。这场变革不仅改变了用户获取信息的方式,也为企业带来了全新的营销机遇。本文将深入探讨…...

混元图像3.0:多模态联合表征驱动的视觉逻辑引擎
1. 项目概述:这不是又一个“图生图”玩具,而是一次底层能力的重新定义“混元:发布图像3.0图生图模型,总参数量80亿”——这个标题里藏着三个被多数人忽略的关键信号:“图像3.0”不是版本号,是代际跃迁的命名…...

从格式混乱到工作流重构:Cloud Document Converter如何重塑飞书文档迁移体验
从格式混乱到工作流重构:Cloud Document Converter如何重塑飞书文档迁移体验 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 你是否曾花费数小时手动复制飞…...

Namespace 为什么不够用了:容器逃逸的技术原理与真实攻击链
Namespace 为什么不够用了:容器逃逸的技术原理与真实攻击链 一、共享内核的致命假设 Docker 容器的核心隔离机制是 Linux Namespace cgroups。Namespace 让进程误以为自己独占 PID、网络和文件系统,cgroups 限制 CPU、内存、IO 的使用上限。这套机制将部…...

Windows系统清理神器:DriverStore Explorer深度使用教程
Windows系统清理神器:DriverStore Explorer深度使用教程 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾经遇到过Windows系统盘空间莫名减少的情况?是否…...

SIGTRAN协议:电信网络IP化的关键技术解析
1. SIGTRAN:下一代电信网络的信令传输基石2003年全球电信业寒冬中,一个技术决策正在悄然改变行业格局。当运营商们紧缩资本开支时,AT&T、Verizon等巨头却不约而同地加大了对IP网络的投入。这背后隐藏着一个关键技术转折——传统TDM网络向…...