【Digester解析XML文件的三种方式】
Digester解析XML文件的三种方式
- 1. Digester解析XML文件的三种方式
- 1.1 作用及依赖jar包
- 2. 重点和难点
- 3. XML文件
- 4. 通过不同的方式解析这个xml文件
- 4.1 通过java编码方式解析(javabean存储)
- 4.2 通过java编码方式解析(list和map存储)
- 4.3 通过xml配置方式解析
- 4.3.1 OrderConfigRule.xml 配置文件
- 4.3.2 Java解析
- 5.总结
1. Digester解析XML文件的三种方式
1.1 作用及依赖jar包
首先明白Digester是干什么的?它是apache开源项目Commons中的一个子项目,用于解析XML文档的工具。Digester底层采用的是SAX解析方式,通过遍历XML文档规则来进行处理。项目中有需要将XML文件中的信息解析为我们需要的内容时(如java类),使用Digester是非常方便的。话不多说,本案例使用的jdk版本是1.6。简单的jar包依赖如下:
- commons-digester-1.8.jar
- commons-logging.jar
- commons-collections-3.2.1.jar
- commons-beanutils-1.7.0.jar
2. 重点和难点
- 重点:理解栈的概念
- 难点:当使用addObjectCreate()方法时,会创建一个对象进栈,许多重要的方法都是相对于栈顶元素或次栈顶元素来进行的。如:
- addCallMethod(pattern, methodName):调用栈顶元素的指定方法
- addCallMethod(pattern, methodName, paramCount):调用栈顶元素的指定方法,可指定方法的参数个数
- addCallMethod(pattern, methodName, paramCount, paramTypes):调用栈顶元素的指定方法,可指定方法的参数个数,类型
3. XML文件
<?xml version="1.0" encoding="UTF-8" ?>
<Orders><Order user="张三" date="2008-11-14" price="12279"><goods id="1"><name>IBM笔记本</name><price>8999</price><count>1</count><total_price>8999</total_price></goods><goods id="2"><name>雅戈尔西服</name><price>1300</price><count>2</count><total_price>2600</total_price></goods></Order>
</Orders>
4. 通过不同的方式解析这个xml文件
4.1 通过java编码方式解析(javabean存储)
根据这个xml文件的各个节点得出,我们可以创建两个javabean来存储解析信息。分别为Order.java和good.java。
// 订单类
package cn.com.bean;import java.util.ArrayList;
/*** Order.java:订单类* @author ypykip**/
public class Order {private String user; //对应<Order>标签中的user属性private String date; //对应<Order>标签中的date属性private String price; //对应<Order>标签中的price属性//对应<Order>标签下的所有<good>标签private ArrayList<Goods> goodsList = new ArrayList<Goods>();//省略getter和setter...// 添加商品到订单public void add(Goods goods){this.getGoodsList().add(goods);}// 重写toString()方法,方便于观察结果@Overridepublic String toString() {return "Order [user=" + user + ", date=" + date + ", price=" + price+ ", goodsList=" + goodsList.toString() + "]";}}
// 商品类
package cn.com.bean;package cn.com.bean;/*** Goods.java:商品类* @author ypykip**/
public class Goods {private String id;private String name;private String price;private String count;private String total_price;//省略getter和setter...@Overridepublic String toString() {return "Goods [id=" + id + ", name=" + name + ", price=" + price+ ", count=" + count + ", total_price=" + total_price +"]";}
}// 解析类
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;import org.apache.commons.digester.Digester;
import org.xml.sax.SAXException;import cn.com.bean.Goods;
import cn.com.bean.Order;/*** title:通过digester的方式来解析Order.xml* @author grk* 重点:理解栈的概念* 当使用addObjectCreate()方法时,创建一个对象进栈* 以下的所有操作(有一种情况除外,表明调用的方法)都是对栈顶元素来讲的,除非调用* addSetNext()方法,移除栈顶元素并执行次栈顶元素的指定方法* * addCallMethod(pattern, methodName):调用栈顶元素的指定方法* addCallMethod(pattern, methodName, paramCount):调用栈顶元素的指定方法,可指定方法的* 参数个数addCallMethod(pattern, methodName, paramCount, paramTypes):调用栈顶元素的* 指定方法,可指定方法的参数个数,类型* * addCallParam(pattern, paramIndex):默认设置指定paramIndex参数为标签内容* addCallParam(pattern, paramIndex, fromStack):设置指定paramIndex参数为栈顶元素* addCallParam(pattern, paramIndex, stackIndex):设置指定paramIndex参数为?* addCallParam(pattern, paramIndex, attributeName):设置指定paramIndex参数为标签属性* attributeName的值 addObjectParam(pattern, paramIndex, paramObj):设置指定paramIndex* 参数为paramObj** addSetNext(pattern, methodName):调用次栈顶元素的methodName方法,一般为有一个参数的方法,* 将栈顶元素作为入参,如list的add方法* */
public class ParseOrder {public static void main(String[] args) {parseByJavaBean();}/*** 使用javaBean进行存储*/public static void parseByJavaBean(){// 1.初始化Digester实例对象Digester digester = new Digester();// 2.解析<Order>标签节点//list进栈,栈顶元素的list对象digester.addObjectCreate("Orders", ArrayList.class);//Order实例进栈,栈顶元素时Order实例对象digester.addObjectCreate("Orders/Order", Order.class);//设置<Order>标签的属性digester.addSetProperties("Orders/Order");// 3.解析<goods>标签节点//Goods实例对象进栈digester.addObjectCreate("Orders/Order/goods", Goods.class);digester.addSetProperties("Orders/Order/goods");//设置<goods>下的其他标签内容digester.addBeanPropertySetter("Orders/Order/goods/name");digester.addBeanPropertySetter("Orders/Order/goods/price");digester.addBeanPropertySetter("Orders/Order/goods/count");digester.addBeanPropertySetter("Orders/Order/goods/total_price");//Goods对象实例出栈digester.addSetNext("Orders/Order/goods", "add");//Order对象实例出栈digester.addSetNext("Orders/Order", "add");// 4.加载配置文件String filePath = "";filePath = System.getProperty("user.dir")+"/bin/config/Order.xml";File file = new File(filePath);// 5.解析try {ArrayList list = (ArrayList) digester.parse(file);System.out.println(list.toString());} catch (IOException e) {e.printStackTrace();} catch (SAXException e) {e.printStackTrace();}}
}
运行结果
[Order [user=张三, date=2008-11-14, price=12279, goodsList=[Goods [id=1, name=IBM笔记本, price=8999, count=1, total_price=8999], Goods [id=2, name=雅戈尔西服, price=1300, count=2, total_price=2600]]]]
4.2 通过java编码方式解析(list和map存储)
/*** 使用list和map进行存储(过程复杂,不建议使用)*/public static void parseByMap(){Digester digester = new Digester();// 1.定义Orders节点规则,创建一个List集合digester.addObjectCreate("Orders", ArrayList.class);// 2.定义Orders/Order节点规则,创建一个Map集合用来存储属性和内容,并将此Map放在上一节点中的Listdigester.addObjectCreate("Orders/Order", HashMap.class);digester.addSetNext("Orders/Order", "add");// 3.定义Orders/Order节点的属性digester.addCallMethod("Orders/Order", "put", 2);//调用栈顶元素map的put方法digester.addObjectParam("Orders/Order", 0, "name");//设置keydigester.addCallParam("Orders/Order", 1, "name");//设置valuedigester.addCallMethod("Orders/Order", "put", 2);digester.addObjectParam("Orders/Order", 0, "date");digester.addCallParam("Orders/Order", 1, "date");digester.addCallMethod("Orders/Order", "put", 2);digester.addObjectParam("Orders/Order", 0, "price");digester.addCallParam("Orders/Order", 1, "price");// 4.定义一个List集合,用来存储Orders/Order节点下的标签digester.addCallMethod("Orders/Order", "put", 2);digester.addObjectCreate("Orders/Order", ArrayList.class);digester.addObjectParam("Orders/Order", 0, "goodsList");digester.addCallParam("Orders/Order", 1, true);// 5.定义Orders/Order/goods节点规则,分别存储id,name,price,count,total_price属性或标签digester.addObjectCreate("Orders/Order/goods", HashMap.class);digester.addSetNext("Orders/Order/goods", "add");digester.addCallMethod("Orders/Order/goods", "put", 2);digester.addObjectParam("Orders/Order/goods", 0, "id");digester.addCallParam("Orders/Order/goods", 1, "id");digester.addCallMethod("Orders/Order/goods/name", "put", 2);digester.addObjectParam("Orders/Order/goods/name", 0, "name");digester.addCallParam("Orders/Order/goods/name", 1);digester.addCallMethod("Orders/Order/goods/price", "put", 2);digester.addObjectParam("Orders/Order/goods/price", 0, "price");digester.addCallParam("Orders/Order/goods/price", 1);digester.addCallMethod("Orders/Order/goods/count", "put", 2);digester.addObjectParam("Orders/Order/goods/count", 0, "count");digester.addCallParam("Orders/Order/goods/count", 1);digester.addCallMethod("Orders/Order/goods/total_price", "put", 2);digester.addObjectParam("Orders/Order/goods/total_price", 0, "total_price");digester.addCallParam("Orders/Order/goods/total_price", 1);String filePath = System.getProperty("user.dir")+"/bin/config/Order.xml";System.out.println(filePath);File file = new File(filePath);System.out.println(file.getAbsolutePath());try {ArrayList list = (ArrayList) digester.parse(file);System.out.println(list.toString());} catch (IOException e) {e.printStackTrace();} catch (SAXException e) {e.printStackTrace();}}
4.3 通过xml配置方式解析
4.3.1 OrderConfigRule.xml 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<digester-rules><pattern value="Orders"><object-create-rule classname="java.util.ArrayList" /> <!-- 配置<Order>标签 --><pattern value="Order"><object-create-rule classname="cn.com.bean.Order" /><set-properties-rule/><!-- 配置<goods>标签 --><pattern value="goods"><object-create-rule classname="cn.com.bean.Goods" /><set-properties-rule><alias attr-name="id" prop-name="id" /><!-- id属性对应javabean的id --></set-properties-rule><bean-property-setter-rule pattern="name" propertyname="name" /><!-- name属性对应javabean的name --><bean-property-setter-rule pattern="price" propertyname="price" /><!-- price标签对应javabean的price --><bean-property-setter-rule pattern="count" propertyname="count" /><!-- count标签对应javabean的count --><bean-property-setter-rule pattern="total_price" propertyname="total_price" /><!-- total_price标签对应javabean的total_price --><set-next-rule methodname="add" paramtype="cn.com.bean.Goods"/></pattern><set-next-rule methodname="add" paramtype="cn.com.bean.Order"/></pattern></pattern>
</digester-rules>
4.3.2 Java解析
public static void parseByXmlConfig() throws IOException, SAXException, URISyntaxException{// 1.加载规则配置文件URL rule = Thread.currentThread().getContextClassLoader().getResource("config/OrderConfigRules.xml");// 2.加载待解析的配置文件Order.xmlReader reader = null;try {reader = new InputStreamReader(new FileInputStream(new File(System.getProperty("user.dir") + "/bin/config/Order.xml")), "utf-8");} catch (FileNotFoundException e) {e.printStackTrace();}// 3.根据规则配置文件创建Digester实例对象InputSource in = new InputSource(new InputStreamReader(new FileInputStream(new File(rule.toURI()))));Digester digester = DigesterLoader.createDigester(in);// 4.进行解析并打印结果List list = (List) digester.parse(reader);System.out.println(list.toString());try {if(reader != null){reader.close();}} catch (Exception e) {e.printStackTrace();}}
结果
[Order [user=张三, date=2008-11-14, price=12279, goodsList=[Goods [id=1, name=IBM笔记本, price=8999, count=1, total_price=8999], Goods [id=2, name=雅戈尔西服, price=1300, count=2, total_price=2600]]]]
5.总结
- 如果需要调用addSetNext()方法时,addObjectCreate()方法和addSetNext()方法最好成对出现
- 首先要知道addSetNext()方法是调用次栈顶元素的方法,一般以栈顶元素为参数。如上例中使用list和map的方式进行存储时,创建顺序分别是Orders—>Order—>goods,对应的list和map分别是list(Orders)—>map(Order)—>list(goodsList)—>map(goods)。当遇到Orders/Order节点时,分别创建了一个map和一个list,分别表示订单和商品集合。当遇到 < /order> 结束标签时需要调用list(Orders)的add()方法,即需要此时的栈顶元素是map(Order)和次栈顶元素是list(Orders)。如果addSetNext()写在了list(goodsList)创建之后,此时的栈顶元素和次栈顶元素分别是list(goodsList),map(Order),而map是没有add方法的,所以会报错:
java.lang.NoSuchMethodException: No such accessible method: add() on object: java.util.HashMap
- 通过使用java编码和配置规则两种方式都可以实现解析,其实两者看上去十分相似熟练了其中一种,另一种也就无师自通了
相关文章:

【Digester解析XML文件的三种方式】
Digester解析XML文件的三种方式 1. Digester解析XML文件的三种方式1.1 作用及依赖jar包 2. 重点和难点3. XML文件4. 通过不同的方式解析这个xml文件4.1 通过java编码方式解析(javabean存储)4.2 通过java编码方式解析(list和map存储࿰…...
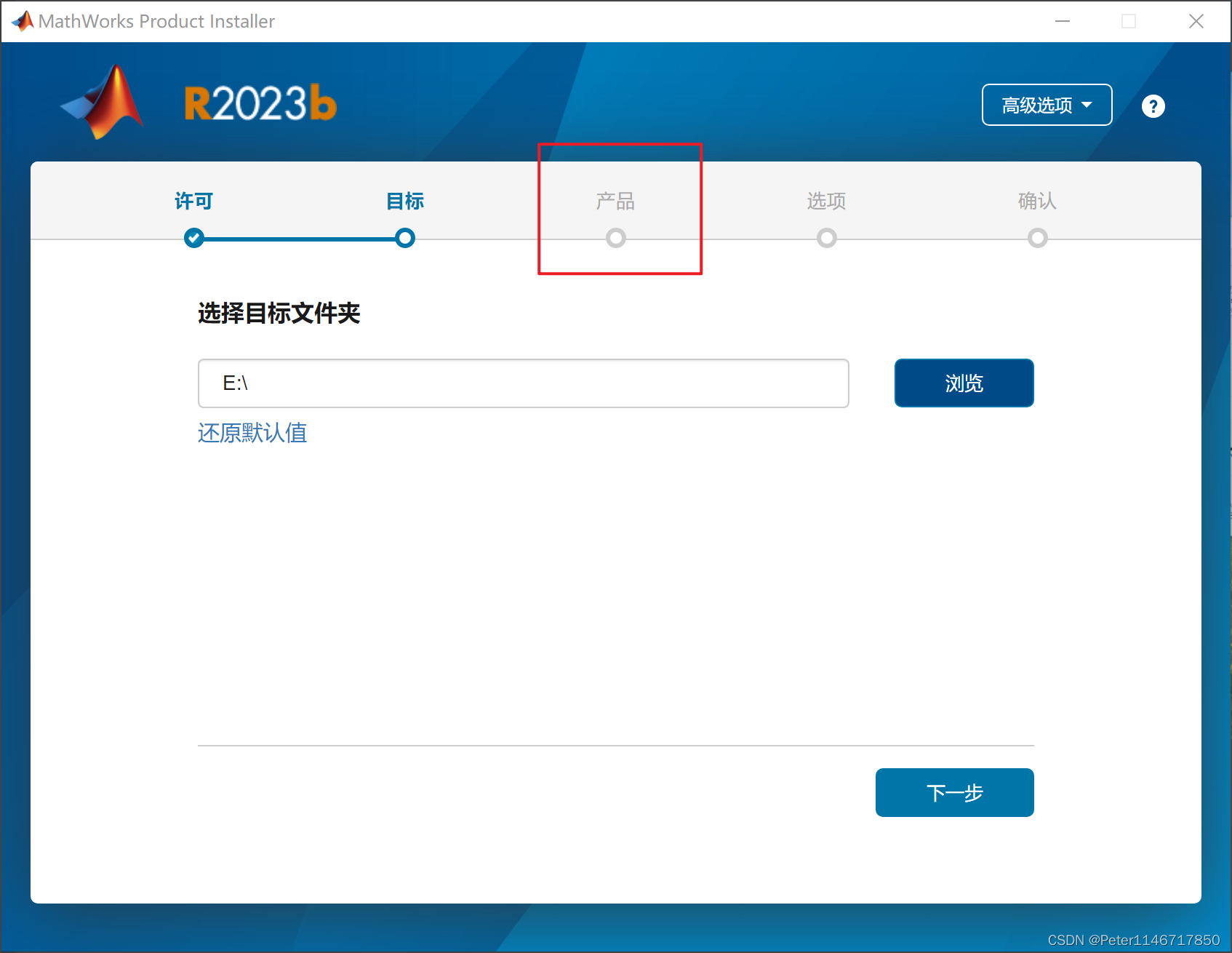
MATLAB curve fitting toolbox没有怎么办?
版本:MATLAB R2023b 如果在安装MATLAB时仅仅选择了安装MATLAB,而并未选择其他选项,则在进入MATLAB后会发现顶部的APP栏中无法找到曲线拟合工具箱。 本人跟随MATLAB中的教程进行下载时,出现了如下报错: 最终解决方案&a…...

Linux之快速入门(CentOS 7)
文章目录 一、Linux目录结构二、常用命令2.1 切换用户2.2查看ip地址2.3 cd2.4 目录查看2.5 查看文件内容2.6 创建目录及文件2.7 复制和移动2.8 其他2.9 tar3.0 which3.1 whereis3.2 find(这个命令尽量在少量用户使用此软件时运行,因为此命令是真的读磁盘…...

Spring框架中的设计模式
🎉欢迎来到Spring专栏:Spring框架中的设计模式 📜其他专栏:java面试 数据结构 源码解读 故障分析 🎬作者简介:大家好,我是小徐🥇☁️博客首页:CSDN主页小徐的博客&#x…...

Java数据结构与算法:邻接矩阵和邻接表
Java数据结构与算法:邻接矩阵和邻接表 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 什么是邻接矩阵和邻接表? 在图的表示中,…...

【温故而知新】JavaScript类、类继承、静态方法
文章目录 前言一、类二、类继承三、静态方法四、热门文章 前言 JavaScript是一种广泛使用的编程语言,主要用于Web开发。它是一种脚本语言,这意味着它不需要像编译语言那样预先编译,而是在运行时解释和执行。JavaScript可以直接在浏览器中运行…...

小黑艰难的前端啃bug之路:内联元素之间的间隙问题
今天开始学习前端项目,遇到了一个Bug调了好久,即使margin为0,但还是有空格。 小黑整理,用四种方法解决了空白问题 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></tit…...

Ubuntu 申请 SSL证书并搭建邮件服务器
文章目录 Log 一、域名连接到泰坦(Titan)电子邮件二、NameSilo Hosting 避坑三、Ubuntu 搭建邮件服务器1. 环境准备2. 域名配置3. 配置 Postfix 和 Dovecot① 安装 Nginx② 安装 Tomcat③ 申请 SSL 证书(Lets Encrypt)④ 配置 pos…...
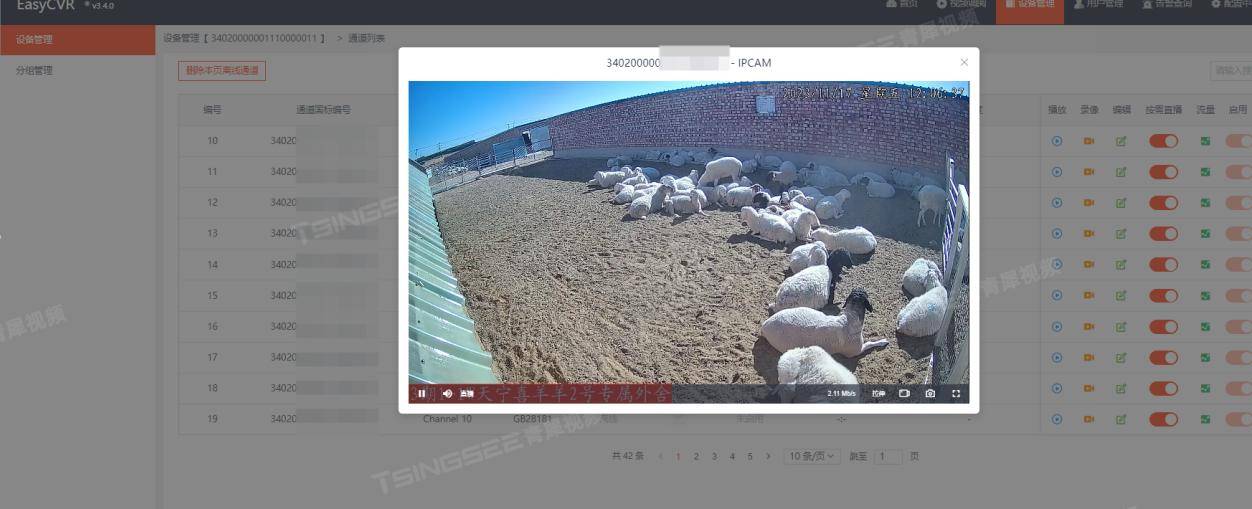
视频监控方案设计:EasyCVR视频智能监管系统方案技术特点与应用
随着科技的发展,视频监控平台在各个领域的应用越来越广泛。然而,当前的视频监控平台仍存在一些问题,如视频质量不高、监控范围有限、智能化程度不够等。这些问题不仅影响了监控效果,也制约了视频监控平台的发展。 为了解决这些问…...

pyspark.sql.types 中的类型有哪些
对 pyspark.sql.types 中的类型做个记录 1、首先正常使用的时候,我们需要引用他们: from pyspark.sql.types import MapType,StringType # 或者 from pyspark.sql.types import *PySpark SQL TYPES是PySpark模型中的一个类,用于定义PySpark数…...
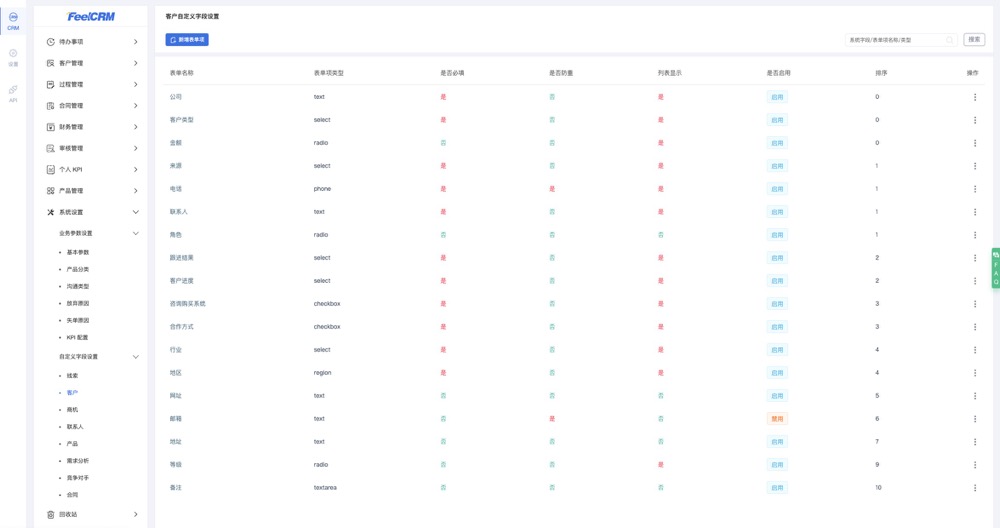
开源CRM客户管理系统-FeelCRM
FeelCRM客户管理系统 开源项目介绍 FeelCRM客户管理系统,符合中小企业业务流程;支持线索管理、客户管理、商机管理、合同管理、审核管理等多个模块;希望能为广大中小企业以及开发者们提供一个更多的可能性;本版本是我公司跨语言…...

Linux创建新分区挂载后普通用户没有读写权限
Linux创建新分区挂载后普通用户没有读写权限 为了使用更大的空间,楼主按照 ubuntu 16.04 硬盘分区,挂载,硬盘分区方案 这个教程新建硬盘分区给普通用户挂载后,发现普通用户没有权限对挂载的文件夹进行读写。 导致无论是创建文…...

清越 peropure·AI 国内版ChatGP新功能介绍
当OpenAI发布ChatGPT的时候,没有人会意识到,新一代人工智能浪潮将给人类社会带来一场眩晕式变革。其中以ChatGPT为代表的AIGC技术加速成为AI领域的热门发展方向,推动着AI时代的前行发展。面对技术浪潮,清越科技(PeroPure)立足多样化生活场景、精准把握用户实际需求,持续精确Fin…...

力扣1027. 最长等差数列
动态规划 思路: 可以参考力扣1218. 最长定差子序列目前不清楚公差,可以将序列最大最小值找到,公差的范围是 [-(max - min), (max - min)],按公差递增迭代遍历求出最长等差数列; class Solution { public:int longest…...
)
GraphicsMagick 的 OpenCL 开发记录(二十三)
文章目录 ImageMagick和GraphicsMagick函数及宏对照表 <2022-04-14 周四> ImageMagick和GraphicsMagick函数及宏对照表 在开发过程中收集了这两个项目中的一些相同或相似功能的函数或者宏定义,希望对大家有所帮助,如下: TypeImageMa…...
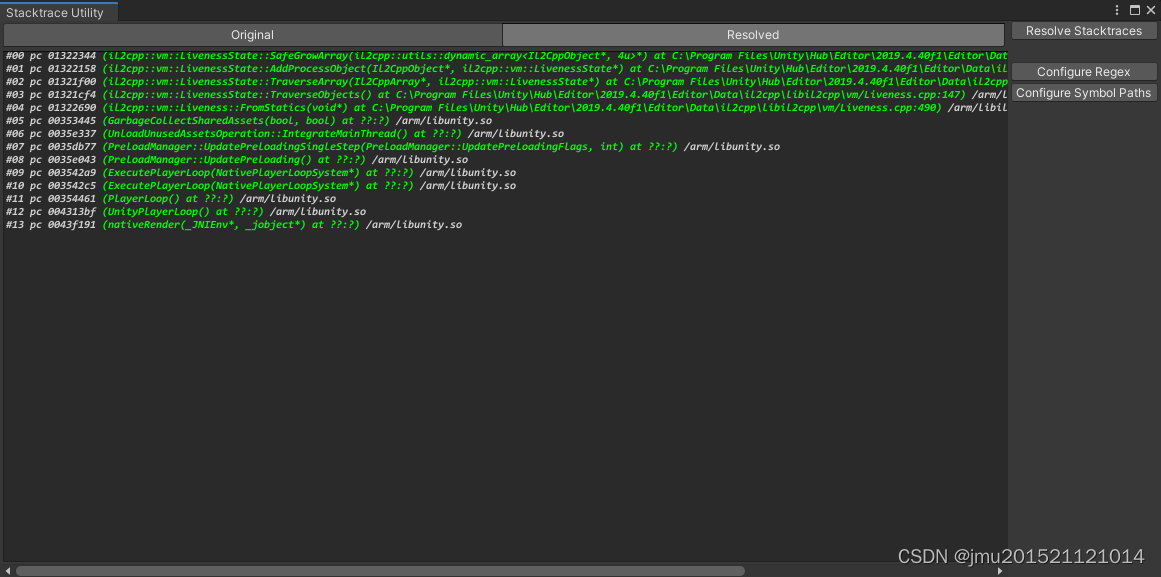
通过Android Logcat分析firebase崩溃
参考:UnityIL2CPP包Crash闪退利用Android Logcat还原符号表堆栈日志 - 简书 一、安装Android Logcat插件 1、新建空白unity工程,打开PackageManager窗口,菜单栏Window/PackageManager 2、PackageManager中安装Android Logcat日志工具 3、安…...

【AI大模型】WikiChat超越GPT-4:在模拟对话中事实准确率提升55%终极秘密
WikiChat,这个名字仿佛蕴含了无尽的智慧和奥秘。它不仅是一个基于人工智能和自然语言处理技术的聊天机器人,更是一个能够与用户进行深度交流的智能伙伴。它的五个突出特点:高度准确、减少幻觉、对话性强、适应性强和高效性能,使得…...
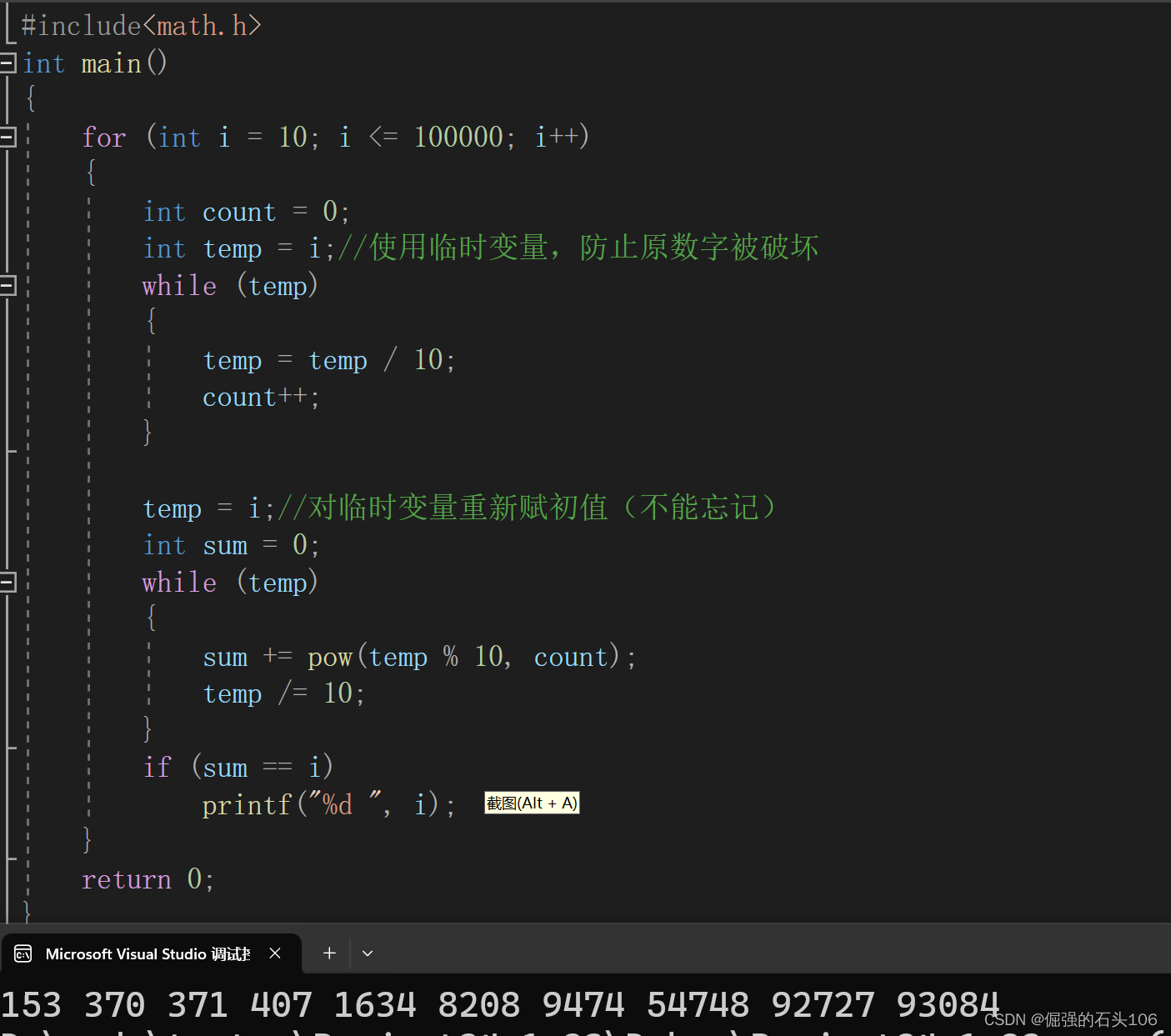
【C语言刷题系列】水仙花数的打印及进阶
1.水仙花数问题 水仙花数(Narcissistic number)也被称为超完全数字不变数(pluperfect digital invariant, PPDI)、自恋数、自幂数、阿姆斯壮数或阿姆斯特朗数(Armstrong number) 水仙花数是指一个 3 位数&a…...
ICSpector:一款功能强大的微软开源工业PLC安全取证框架
关于ICSpector ICSpector是一款功能强大的开源工业PLC安全取证框架,该工具由微软的研究人员负责开发和维护,可以帮助广大研究人员轻松分析工业PLC元数据和项目文件。 ICSpector提供了方便的方式来扫描PLC并识别ICS环境中的可疑痕迹,可以用于…...

HCIA——29HTTP、万维网、HTML、PPP、ICMP;万维网的工作过程;HTTP 的特点HTTP 的报文结构的选择、解答
学习目标: 计算机网络 1.掌握计算机网络的基本概念、基本原理和基本方法。 2.掌握计算机网络的体系结构和典型网络协议,了解典型网络设备的组成和特点,理解典型网络设备的工作原理。 3.能够运用计算机网络的基本概念、基本原理和基本方法进行…...

微信消息自动转发终极指南:5分钟实现跨群智能消息同步
微信消息自动转发终极指南:5分钟实现跨群智能消息同步 【免费下载链接】wechat-forwarding 在微信群之间转发消息 项目地址: https://gitcode.com/gh_mirrors/we/wechat-forwarding 在微信群管理和协作场景中,消息的自动转发与同步是提升效率的关…...

音频变压器关键参数深度解析:Z值与最大电流的工程实践
音频变压器关键参数深度解析:Z值与最大电流的工程实践引言在专业音频系统、高保真音响以及工业信号隔离场景中,音频变压器始终扮演着不可替代的角色。它的核心使命是在保持信号完整性的同时,完成阻抗匹配、地环路隔离和信号平衡转换三大任务。…...

终极窗口调整神器:WindowResizer完整使用指南
终极窗口调整神器:WindowResizer完整使用指南 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的Windows窗口而烦恼吗?无论你是遇到老旧软件界…...
)
Python+OpenCV+PyQt5+SVM实现车牌识别系统(源码)
目录 一、项目背景 二、技术介绍 三、功能介绍 四、 代码设计 五、系统实现 一、项目背景 随着我国城市化进程的不断加快,机动车保有量呈现持续快速增长态势。据公安部统计,2024年全国机动车保有量已突破4.5亿辆,其中汽车占比超过80%。…...

构建个人技能库:从代码片段到可复用技能单元的设计与实践
1. 项目概述:当代码遇上魔法,技能库的构建哲学在软件开发的日常里,我们常常会羡慕那些“魔法师”般的同事:他们似乎总能信手拈来一段代码,优雅地解决一个棘手问题;或者拥有一个私人的“百宝箱”,…...

软银携手DeltaX建储能基地,2027年量产应对AI算力电力挑战
软银与DeltaX合作:储能系统建设的新布局品玩5月12日消息,据The Elec报道,软银集团选定韩国初创公司DeltaX,负责在日本大阪建设数据中心储能系统(ESS)的开发与制造。双方计划于今年下半年在大阪堺市原夏普工…...

从零到一:基于C#与ArcGIS二次开发构建迎风面指数计算插件实战
1. 环境准备与工具搭建 第一次接触ArcGIS二次开发时,我被官方文档里密密麻麻的API吓得不轻。后来发现只要配好环境,开发插件比想象中简单得多。你需要准备三样东西:Visual Studio(建议2019或2022社区版)、ArcGIS Desk…...

DreamBooth实战案例:从人物肖像到艺术风格的完整训练过程
DreamBooth实战案例:从人物肖像到艺术风格的完整训练过程 【免费下载链接】sd_dreambooth_extension 项目地址: https://gitcode.com/gh_mirrors/sd/sd_dreambooth_extension DreamBooth是一款强大的AI模型训练工具,能够让你通过少量图片快速定制…...

Claw-ED:基于教学风格学习的AI助教,一键生成个性化教学包
1. 项目概述:一个为教师而生的AI教学助手 如果你是一位一线教师,每天被备课、写教案、做课件、设计学生活动、准备分层材料这些繁琐工作压得喘不过气,同时又对市面上那些“通用”的AI工具生成的、充满“AI腔”的教案感到失望,那么…...
)
思科路由器远程管理保姆级教程:从IP配置到Telnet/SSH登录全流程(避坑line vty和密码设置)
思科路由器远程管理全流程实战指南:从基础配置到安全登录 刚接触思科设备时,最让人头疼的莫过于那一连串看似晦涩的命令行操作。记得我第一次尝试配置路由器远程访问时,明明按照教程一步步操作,却始终无法通过Telnet连接ÿ…...