SQL数据库语法
目录
1. 常用数据类型
2. 约束
4. 数据库操作
5. 数据表操作
1. 常用数据类型
- int 整型
- double 浮点数
- varchar 字符型
- data 年月日
- datetime 年月日 时分秒
2. 约束
- 主键 primary key : 物理上存储的顺序(存在真实排序), 主键都是非空/唯一的
- 非空 not null : 此字段不允许为空
- 唯一 unique : 此字段不允许重复
- 默认 default : 当不填写此字段时, 会使用默认值
- 外键 foreign key : 对关系数据进行约束, 当为关键字段填写值时, 会到关联的表中查询此值是否存在, 如果存在则填写成功, 如果不存在则填写失败并抛出异常
- 虽然外键可以保证数据的有效性, 但在进行数据的增删查改时, 都会降低数据库的性能, 故不推荐使用
4. 数据库操作
--查看数据库
show databases;--创建数据库
create database 数据库名;--删除数据库
drop database 数据库名;--选择数据库
use 数据库名;--查看当前使用的数据库
select database();5. 数据表操作
查看表:
--查看当前数据库中的所有表
show tables;--查看表结构
desc 表名;增添数据:
--创建表格示例
create table if not exists `test_01`(`id` int unsigned auto_increment comment '编号',`title` varchar(100) not null comment '标题',`author` varchar(40) not null comment '作者',`cdate` date comment '日期',primary key (`id`)
)engine=InnoDB default charset=utf8 comment='测试表格01';
-- if not exists 表名 : 表示若该表不存在则创建
-- auto_increment : 表示从上一条数据自增1
-- comment : 注释字段--新增字段
alter table 表名 add 字段名 字段数据类型及约束; --系统默认值为null
--设置的默认值要与数据类型匹配--写入数据
insert into 表名(字段名1,字段名2
)value(内容1, 内容2, ...);--批量写入
insert into 表名(字段名1,字段名2
)value(内容1, 内容2, ...),(内容1, 内容2, ...),...(内容1, 内容2, ...);删除数据:
--删除表格
drop table 表名;--删除数据
delete from 表名 where 条件;修改数据:
--修改字段名称
alter table 表名 change 原名 新名 类型及约束;--更新数据
update 表名
set字段1=...,字段1=...,...
where 条件;查询数据:
--查询数据
select * from 表名; --查询表里所有数据--限制查询数据条数
select * form 表名
limit 数据条数;--查找字段数据
select字段1,字段2,...
from 表名;--多表查询
select表1.字段x,表1.字段y,...表2.字段z,...
form 表1, 表2;--条件查询
select *
from 表名1, 表名2, ...
where 条件;select *
from 表名
where 条件1 --选定表格之后,选择数据之前
having 条件2; --数据全部计算完之后进行筛选--起别名
select本名1 as 别名1,本名2 as 别名2,...
from 表本名 as 表别名
limit 数据量;--按字段数据去重查询
select distinct字段1,字段2,...
from 表名;--模糊查询1
select *
from 表名
where 字段1 like '_est' --下划线可任意匹配一个字符
where 字段2 like '%e%'; --百分号可任意匹配多个字符, 可以匹配也可以不匹配--模糊查询2
select *
from 表名
where 字段名 in ('test1', 'test2',...);--模糊查询3
select *
from 表名
where 字段名 between x and y; --最好用于查询数字/日期, 返回x到y之间的模糊匹配结果--关联, 将两张表上下拼接
--两张表关联的字段名可以不相同, 但字段数量和字段类型要相同
--union distinct 关联时去重
select id,name
from table1
union
selectid,name
from table2;--排序
--默认是从小到大排序, 加上desc是从大到小排序
--每个字段后面的参数只代表这个字段的排序法则
select * from 表名
order by 字段1, 字段2 desc --哪个字段写在前面, 哪个字段优先排
limit 10;--聚合
--选择想要查询的信息
selectcount(0) --统计数据条数,max(字段名) --找最大值,min(字段名) --找最小值,avg(字段名) --求平均值...
from 表名
where 条件; --统计符合条件的数据条数--分组
select字段1,字段2,count(0) --统计每个分组的人数
from 表名
where 条件
group by 字段1, 字段2; --用group by去重比distinct效率高--分组统计
selectcoalesce(字段1, 'total'),coalesce(字段2, 'total')
from 表名
where 条件
group by 字段1, 字段2
with rollup;--链接查询
--可同时关联两张表或者多张表
--join默认为内连接 inner join
--内连接: 保留两个关联表的交集数据
select别名1.字段1,别名1.字段2,别名1.字段3,别名2.字段1,别名2.字段2...
from 表名1 (别名1) --主表
join 表名2 (别名2) --副表on 别名1.关联字段 = 别名2.关联字段and 副表条件...
where 主表条件条件
limit 数据量;--左连接 left join
--保留主表的全部数据和关联表的交集数据
with 别名1 as (select *from 表名1where 条件
)
,别名2 as (select *from 表名2where 条件
)
select 字段...
from 别名1 --主表
left join 别名2 --副表on 别名1.关联字段 = 别名2.关联字段
where 条件; --where里面的条件对应from后面的表(别名1)的条件--右连接 right join
--通过调换字段顺序可以将右关联的表改为左关联
with 别名1 as (select *from 表名1where 条件
)
,别名2 as (select *from 表名2where 条件
)
select 字段...
from 别名1 --副表
right join 别名2 --主表on 别名1.关联字段 = 别名2.关联字段
where 条件;--外连接 outer join
--将两张表关联, 没有数据的位置由null补充, 只要其中一个表存在数据则返回数据
--通过其他的关联操作实现外关联--自关联
create table if not exists `city` (`id` int not null comment '编号',`name` varchar(100) comment '城市名称',`pid` varchar(4) comment '父id',primary key (`id`)
)engine=InnoDB default charset=utf8 comment='城市表格';insert into city(id,name,pid) values
(1,'上海市',null),
(12,'闵行区',1),
(13,'浦东新区',1),
(2,'北京市',null),
(23,'朝阳区',2),
(24,'海淀区',2),
(25,'望京区',2),
(3,'广东省',null),
(31,'广州市',3),
(32,'东莞市',3),
(33,'珠海市',3),
(321,'莞城区',32);selecta.ID,a.name,b.ID,b.name,c.ID,c.name
from city a
left join city bon a.ID = b.PID
left join city con b.ID = c.PID
where a.PID is null;--子查询
select * from 表名
where 字段 >= (select avg(字段) from 表名);总结:
--代码格式
select distinct字段
from 表名
join
where
group by
having
order by
limit start, count--执行顺序
from 表名
join
where
group by
select distinct 字段
having
order by
limit start, count内置函数:
--日期 now
now(); --当前日期 时间
year(now()); --年
month(now()); --月
day(now()); --日select year(now());--字段长度 length
length(对象字段) from 表名;--设置返回值小数位数 round
select round(对象字段, 小数位数) from 表名;--反转字符串 reverse
select reverse(对象字符串);--截取字符串 substring
select substring(对象字符串, start, length);--判空 ifnull / nvl / coalesce
select ifnull(对象, 默认值); --如果对象为null, 则用默认值替换--条件判断 case when
select
case when 条件1 then ...when 条件2 then ...else ...end 新增字段
from 表名select emp_no,case when emp_no > 10020 then '大' --最优先when emp_no > 10010 then '中'else '小'end '编号等级'
from dept_emp
where emp_no < 10050
limit 30;--分组(维度)聚合 grouping sets
--开窗函数 partition by
--function(column) over(partiton by 字段1,字段2...) 新增字段
--function通常为聚合函数/排序函数--分类统计不同部门不同性别的人数
with a as (select a.emp_no,a.gender,b.dept_nofrom employees a join dept_emp b on a.emp_no = b.emp_no
)
select distinctdept_no,gender,count(emp_no) over (partition by dept_no, gender) dept_cnt
from a;--排序函数
--row_number() 排序名次累加, 即使数据相同也累加 1 2 3 4 5 6
--rank() 排序名次可能相同, 遇到数据相同则跳过该名次 1 1 3 4 4 6
--dense_rank() 排序名次可能相同, 遇到数据相同则从上一个名次累加 1 1 2 2 2 3 4
select row_number() over(order by 字段) 新增字段;
select rank() over(order by 字段) 新增字段;
select dense_rank() over(order by 字段) 新增字段;--查询写入 insert into select
--将查询到的数据写入到另一个表格中, 要求字段一一对应相关文章:

SQL数据库语法
目录 1. 常用数据类型 2. 约束 4. 数据库操作 5. 数据表操作 1. 常用数据类型 int 整型double 浮点数varchar 字符型data 年月日datetime 年月日 时分秒2. 约束 主键 primary key : 物理上存储的顺序(存在真实排序), 主键…...

人机界面艺术设计
人机界面艺术设计 2.1人机界面艺术设计思路 人们经常有意通过某种工具或创造来解决难题,然而这并不意味着人们乐于接受别人或其他事情,他们很难提出问题。在用户使用网页或软件的时候,他们有明确的目标,他们利用电脑来帮助自己达…...

【办公类-19-01-02】办公中的思考——Python,统计教职工的姓名中那些字最多?
背景需求:上一篇计算了教职工的姓氏谁最多,col[0]]这一篇统计教职工的(姓氏名字)里面哪些字出现最多。材料准备:1、下载所有员工名单写代码。py 包含”姓氏名字“的重字率统计from pandas import DataFrame, Series im…...
HCIP实验1
实验要求 1 R6为isp, 接口IP地址均为公有地址;该设备只能配置IP地址,之后不能冉对其进行其他任何配置; 2 R1-R5为局域网,私有IP地址192.168.1.0/24, 请合理分配; 3 R1, R2, R4,各有两个环回地址; R5; R6各有一个环回地址;所有路由器上环回均…...

一个Bug让人类科技倒退几十年?
大家好,我是良许。 前几天在直播的时候,问了直播间的小伙伴有没人知道「千年虫」这种神奇的「生物」的,居然没有一人能够答得上来的。 所以,今天就跟大家科普一下这个人类历史上最大的 Bug 。 1. 全世界的恐慌 一个Bug会让人类…...
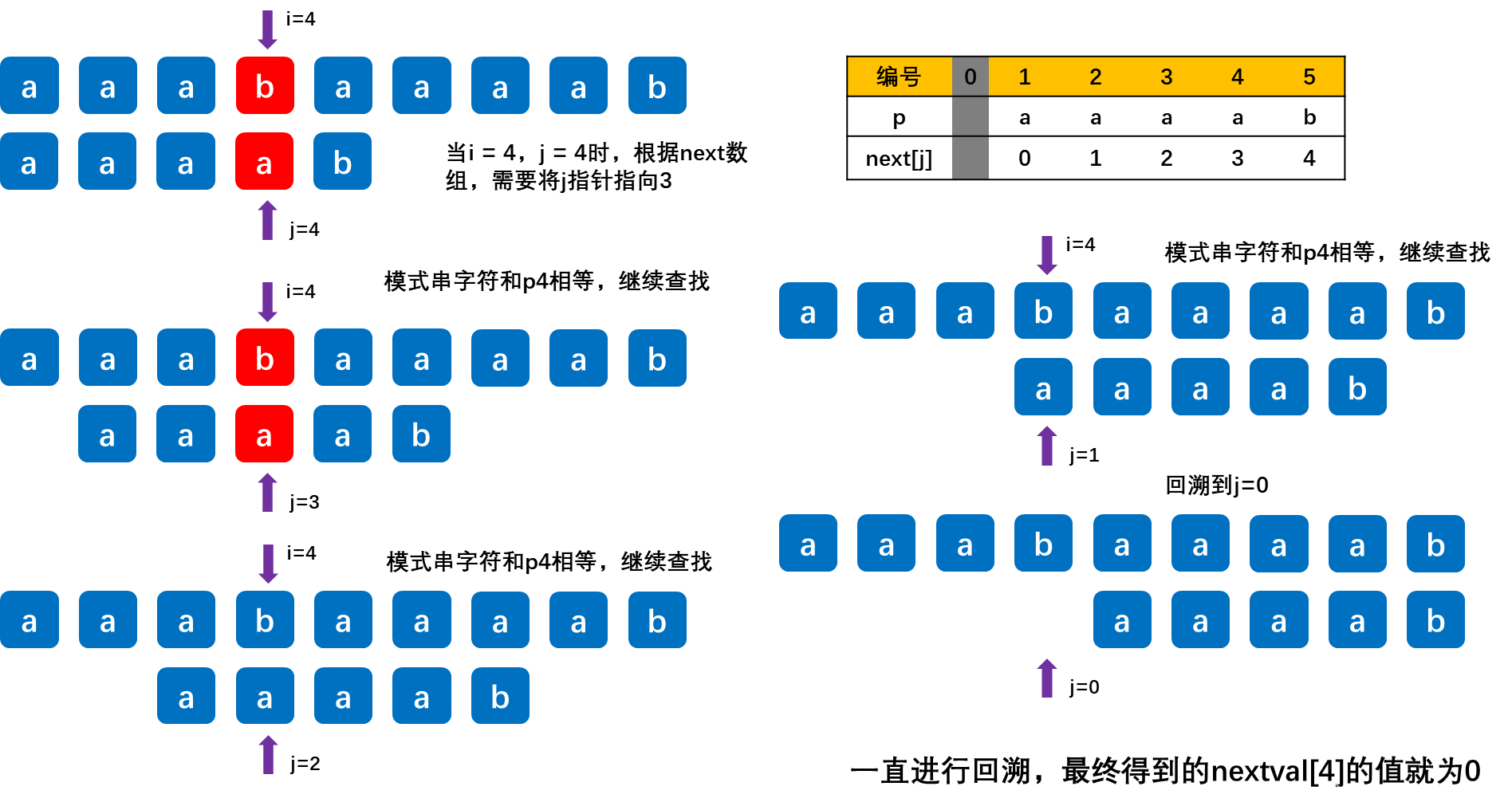
2023王道考研数据结构笔记第四章串
第四章 串 4.1 串的定义 4.1.1 串的相关概念 串:即字符串(String)是由零个或多个字符组成的有限序列。一般记为S‘a1a2…an’ (n>0) 其中S是串名,单引号(注:有的地方用双引号,如Java、C&am…...

【AI绘图学习笔记】深度学习相关数学原理总结(持续更新)
如题,这是一篇深度学习相关数学原理总结文,由于深度学习中涉及到较多的概率论知识(包括随机过程,信息论,概率与统计啥啥啥的),而笔者概率知识储备属实不行,因此特意开一章来总结(大部…...

CSGO服务器配置全贴纸插件方法教程
CSGO服务器配置全贴纸插件方法教程 关于插件的警告 一定要了解V社对于CSGO社区服务器的规定,全皮肤插件/全手套插件等,在设置了GSLT的情况下,是有可能被封禁GSLT账号的(所以慎用) 配置好服务器之后呢,想安…...
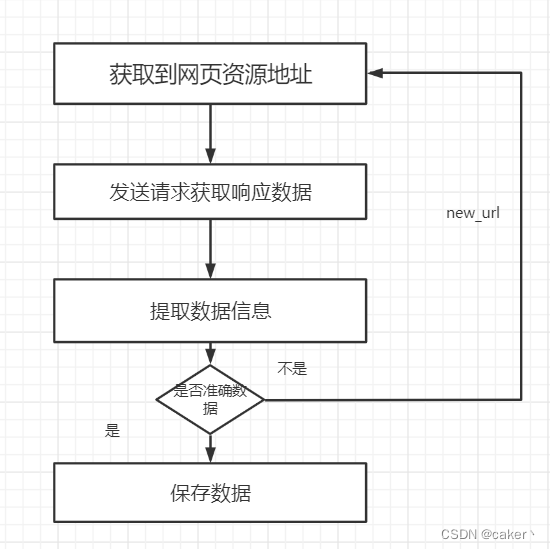
Python爬虫——使用socket模块进行图片下载
Python爬虫——使用socket模块进行图片下载什么是socket爬虫的工作流程socket爬取图片为什么能用socket能下载图片socket下载图片和request下载图片的区别使用socket下载一张图片使用socket下载多张图片方法1方法2什么是socket Socket 是一种通信机制,用于实现网络…...
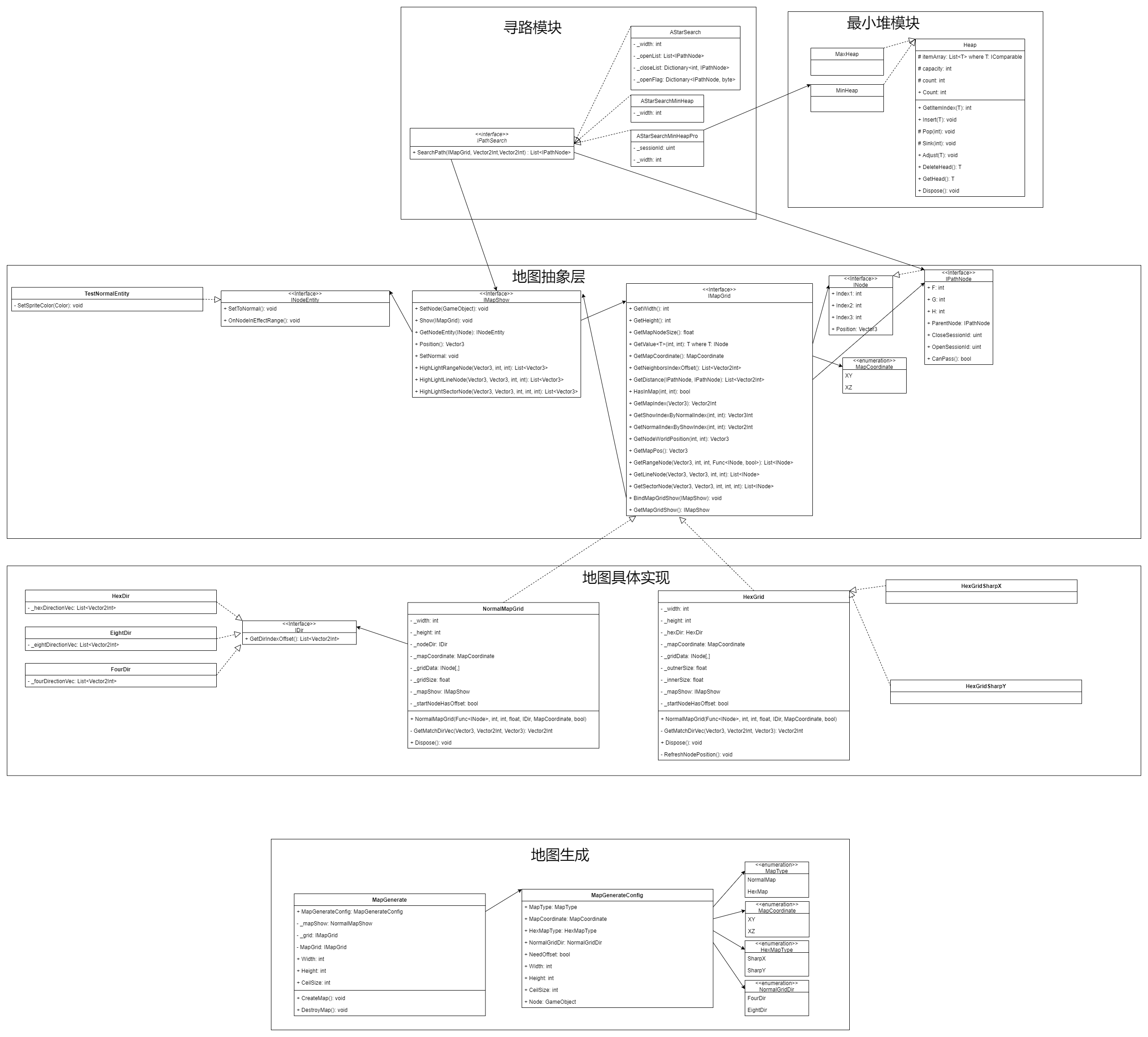
通用游戏地图解决方案设计解析
前言: 在软件开发过程中,我们都希望能设计出一个稳健的,可维护的系统,为了实现这个目的,人们总结出了很多相关的设计原则,比如SOLID原则, KISS原则等等。SOLID每个字母代表了一种设计原则&…...

java @Autowired @Resource @Inject 三个注解的区别
javax.annotation.Resourcejdk 内置的,JSR-250 中的注解。依赖注入通过 org.springframework.context.annotation.CommonAnnotationBeanPostProcessor 来处理。org.springframework.beans.factory.annotation.Autowired org.springframework.beans.factory.annotati…...

「媒体分流直播」媒体直播和传统直播的区别,以及媒体直播的特点
传媒如春雨,润物细无声,大家好直播毋庸置疑已经融入到了我们生活的方方面面,小到才艺,游戏,大到政策的发布,许多企业和机构也越来越重视直播,那么一场活动怎么最大化的进行传播,一是…...

数据是如何在计算机中存储的
我们普通人对于数据存储的认识恐怕大多数都是从自己使用的电脑来的。现在几乎人手一台电脑,而我们的电脑存储着各种各样的文件,比如视频文件、音频文件和Word文档等。这些文件从计算机术语的角度都可以称为数据。 如图1-1所示是Windows 10 “我的电脑”的截图。通过该截图我…...

Day907.分区表 -MySQL实战
分区表 Hi,我是阿昌,今天学习记录的是关于分区表的内容。 经常被问到这样一个问题: 分区表有什么问题,为什么公司规范不让使用分区表呢? 一、分区表是什么? 为了说明分区表的组织形式,先创建…...
C++概览:工具链、基础知识、进阶及总结
本篇写给C初学者,作为概览,文中仅包含各方面基础知识,无深入分析。 C基础概念简介 C编译过程示意图 关键词:源文件、预编译、编译、汇编、链接 C工具链总结 cmake项目工程文件是一种中介工程文件,可以转化成其他…...
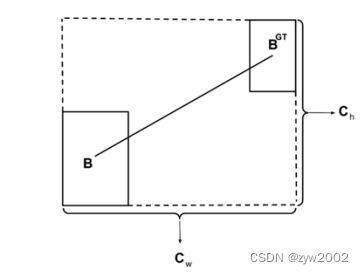
目标检测中回归损失函数(L1Loss,L2Loss,Smooth L1Loss,IOU,GIOU,DIOU,CIOU,EIOU,αIOU ,SIOU)
文章目录L-norm Loss 系列L1 LossL2 LossSmooth L1 LossIOU系列IOU (2016)GIOU (2019)DIOU (2020)CIOU (2020)EIOU (2022)αIOU (2021)SIOU (2022…...
JOSN数据转换和解析
文章目录JOSN数据转换和解析内容回顾Map 集合转成 JSON 字符串List 集合转换成 JSON 字符串Ajax 异步和同步异步概念同步概念异步和同步区别异步请求案例同步请求时间格式化旧时间 api 格式化格式化和解析的工具类JSTL 时间格式化JSTL 使用JOSN数据转换和解析 内容回顾 ajax …...

浅析Linux内核中进程完全公平CFS调度
一、前序 目前Linux支持三种进程调度策略,分别是SCHED_FIFO 、 SCHED_RR和SCHED_NORMAL;而Linux支持两种类型的进程,实时进程和普通进程。实时进程可以采用SCHED_FIFO 和SCHED_RR调度策略;普通进程则采用SCHED_NORMAL调度策略。从…...
)
安装 RustDesk 服务器 (适用 Rocky Linux, CentOS, RHEL 系列发行版)
环境:Rocky Linux 9.1 1. 安装 Docker Engine 可以参考 [[linux-docker-rocky-install]] https://cc01cc.com/2023/03/02/linux-docker-rocky-install/英文可以参考官方文档 Install Docker Engine on RHEL https://docs.docker.com/engine/install/rhel/ 2. 安装…...

23种设计模式-策略模式
策略模式是一种设计模式,它允许在运行时选择算法的行为。它定义了算法家族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户端。在本文中,我们将深入探讨策略模式的概念和实际应用&#…...

STM32温室智能监控系统开发实战
1. 项目概述这个温室培育系统项目是我去年为一个农业科技公司开发的实战案例。整套系统基于STM32F103RCT6主控,整合了12种硬件模块,实现了温室环境的全自动化监控与调控。最让我自豪的是,系统上线后客户反馈作物产量提升了23%,水电…...

TCP/IP协议族与网络体系结构实战解析
1. 计算机网络体系结构解析计算机网络体系结构是理解整个互联网通信的基础框架。目前主流的体系结构有三种:OSI七层模型、TCP/IP四层模型和教学用的五层模型。作为一名从业十年的网络工程师,我发现在实际工作中TCP/IP四层模型的应用最为广泛。OSI七层模型…...
Word2Vec扩充+TF-IDF)
上市公司数字化转型指数(2007-2024)Word2Vec扩充+TF-IDF
上市公司数字化转型指数(2007-2024)Word2Vec扩充TF-IDF数据名称:A股上市公司数字化转型指数 时间跨度:2007年-2024年 数据格式:Excel表格(dta可直接导入) 包含指标:股票代码、年份、…...

利用快马平台快速构建b站a8直播观看页面原型
利用快马平台快速构建B站A8直播观看页面原型 最近想尝试开发一个B站A8直播的观看页面原型,主要想验证一下直播相关的技术方案。作为一个前端开发者,我深知从头开始搭建这样一个页面需要花费不少时间,特别是在处理视频流、弹幕互动和响应式设…...

TouchGal终极指南:打造纯净Galgame社区的完整解决方案
TouchGal终极指南:打造纯净Galgame社区的完整解决方案 【免费下载链接】kun-touchgal-next TouchGAL是立足于分享快乐的一站式Galgame文化社区, 为Gal爱好者提供一片净土! 项目地址: https://gitcode.com/gh_mirrors/ku/kun-touchgal-next TouchGal是一个专为…...

如何设计高效的Emscripten与WebAssembly接口:平衡简洁与完整的终极指南
如何设计高效的Emscripten与WebAssembly接口:平衡简洁与完整的终极指南 【免费下载链接】emscripten Emscripten: An LLVM-to-WebAssembly Compiler 项目地址: https://gitcode.com/gh_mirrors/em/emscripten Emscripten作为一款强大的LLVM-to-WebAssembly编…...

代码随想录 300.最长递增子序列
思路:根据题意得,子序列是由数组派生而来的序列,删除(或不删除)数组中的元素不改变其余元素的顺序。动规五部曲:1.dp[i]的定义:dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度。2.确…...
)
告别编译报错!Ubuntu 22.04 LTS下x264库的保姆级安装指南(含configure参数详解)
告别编译报错!Ubuntu 22.04 LTS下x264库的保姆级安装指南(含configure参数详解) 在视频处理领域,x264作为开源的H.264编码器实现,因其出色的压缩效率和画质表现,成为FFmpeg等多媒体工具链的核心组件。然而对…...

别再死记硬背了!用FFmpeg实战拆解H.264码流,手把手教你读懂NALU头
从字节到画面:FFmpeg实战解析H.264码流中的NALU奥秘 当你用手机观看一段高清视频时,每秒25帧的画面流畅切换背后,是H.264编码算法在默默工作。但你是否好奇过,这些压缩后的数据究竟如何组织?今天我们将用FFmpeg这把&qu…...

从采购到回款:拆解华为IFS如何用PTP/OTC流程优化缩短30天账期
华为IFS流程再造实战:如何通过PTP/OTC优化实现账期缩短30天 在供应链金融和财务运营领域,账期管理一直是企业现金流健康的关键指标。全球领先企业华为通过其集成财务服务(IFS)变革,特别是在采购到付款(PTP&…...