大型语言模型 (LLM)全解读
一、大型语言模型(Large Language Model)定义
大型语言模型 是一种深度学习算法,可以执行各种自然语言处理 (NLP) 任务。
大型语言模型底层使用多个转换器模型, 底层转换器是一组神经网络。
大型语言模型是使用海量数据集进行训练的超大型深度学习模型。
这也是它们能够识别、翻译、预测或生成文本或其他内容的强大基础所在。
因此大型语言模型也称为神经网络 (NN),是受人类大脑启发而开发出的计算系统。这些神经网络利用分层的节点网络工作,就像神经元一样。这些神经网络由具有自注意力功能的编码器和解码器组成。编码器和解码器从一系列文本中提取含义,并理解其中的单词和短语之间的关系。转换器 LLM 能够进行无监督的训练,但更精确的解释是转换器可以执行自主学习。
通过此过程,转换器可学会理解基本的语法、语言和知识。与早期按顺序处理输入的循环神经网络(RNN)不同,转换器并行处理整个序列。这可让数据科学家使用 GPU 训练基于转换器的 LLM,从而大幅度缩短训练时间。
除了向人工智能 (AI) 应用程序教授人类语言外,还可以训练大型语言模型来执行各种任务,如理解蛋白质结构、编写软件代码等。像人类大脑一样,大型语言模型必须经过预先训练,然后再进行微调,这样它们才能解决文本分类、问题解答、文档摘要和文本生成等问题。它们这些解决问题的能力可应用于医疗保健、金融和娱乐等多种领域;在这些领域中,大型语言模型用于支持各种 NLP 应用程序,例如翻译、聊天机器人、AI 助手等。
大型语言模型也具有大量的参数,类似于模型从训练中学习时收集的各种记忆。我们可以将这些参数视为模型的知识库。

Generative Pre-trained Transformer 3 (GPT-3) is a large language model released by OpenAI in 2020
模型包括训练和推理两个阶段,训练的时候包含了前向传播和反向传播,推理只包含前向传播,所以预测时候的速度更重要。
二、大型语言模型如何运作?
LLM 运作原理的一个关键因素是它们表示单词的方式。早期的机器学习使用数字表来表示每个单词。但是,这种表示形式无法识别单词之间的关系,例如具有相似含义的单词。人们采用如下方式克服此限制:使用多维向量(通常称为单词嵌入)来表示单词,从而使具有相似上下文含义或其他关系的单词在向量空间中彼此接近。
使用单词嵌入,转换器可以通过编码器将文本预处理为数字表示,并理解含义相似的单词和短语的上下文以及单词之间的其他关系,例如语音部分。然后,LLM 就可以通过解码器应用这些语言知识来生成独特的输出。
即大型语言模型以转换器模型为基础,**其工作原理是:接收输入,对输入进行编码,然后解码以生成输出预测。**但是,在大型语言模型能够接收文本输入并生成输出预测之前,需要先对它进行训练,以便执行一些常规功能,然后再进行微调后才能执行特定任务。
训练:大型语言模型会使用维基百科、GitHub 或其他网站的大型文本数据集进行预先训练。这些数据集包含数以万亿计的字词,它们的质量会影响语言模型的性能。在这个阶段,大型语言模型主要进行无监督学习,这意味着它会在没有特定指令的情况下处理输入的数据集。在这个过程中,LLM 的 AI 算法可以学习字词的意思,以及字词之间的关系。此外,它还会根据上下文学习分辨字词。例如,它将学习理解“right”是“正确”的意思,还是“左”的反义词。
微调:为了让大型语言模型执行诸如翻译等特定任务,则必须针对特定活动对它进行微调。微调可优化特定任务的性能。
提示调优的作用与微调类似,也就是通过少样本提示或零样本提示来训练模型执行特定任务。提示是提供给 LLM 的指令。少样本提示会通过使用示例来教模型预测输出。例如,在这个情绪分析练习中,少样本提示将如下所示:
Customer review: This plant is so beautiful!
Customer sentiment: positive
Customer review: This plant is so hideous!
Customer sentiment: negative
语言模型通过“hideous”的语义,并基于提供的一个相反示例,理解第二个示例中的客户情感是“negative”。
另外,零样本提示不会使用示例来教语言模型如何对输入做出响应。相反,它会将问题表述为“The sentiment in ‘This plant is so hideous’ is….”(“‘这种植物太丑了’中的情感是……” 它会明确指出语言模型应执行的任务,但没有提供解决问题的示例。
三、如何训练大型语言模型?
基于转换器的神经网络非常庞大。这些网络包含多个节点和层。层中的每个节点都有指向后续层中所有节点的连接,并且每个节点都有权重和偏差。权重和偏差以及嵌入称为模型参数。基于转换器的大型神经网络可以有数十亿个参数。模型的大小通常由模型大小、参数数量和训练数据规模之间的经验关系决定。
使用大量高质量数据执行训练。在训练过程中,模型会迭代调整参数值,直到模型可根据前一个输入令牌序列正确预测下一个令牌。为此,模型使用自学技术,这些技术教导模型调整参数,以最大限度地提高训练示例中正确预测下一个令牌的可能性。
经过训练,LLM 可以很容易地适应使用相对较小的有监督数据集执行多项任务,这一过程称为微调。
训练语言模型需要向其提供大量的文本数据,模型利用这些数据来学习人类语言的结构、语法和语义。这个过程通常是通过无监督学习完成的,使用一种叫做自我监督学习的技术。在自我监督学习中,模型通过预测序列中的下一个词或标记,为输入的数据生成自己的标签,并给出之前的词。
训练过程包括两个主要步骤:预训练(pre-training)和微调(fine-tuning):
- 在预训练阶段,模型从一个巨大的、多样化的数据集中学习,通常包含来自不同来源的数十亿词汇,如网站、书籍和文章。这个阶段允许模型学习一般的语言模式和表征。
- 在微调阶段,模型在与目标任务或领域相关的更具体、更小的数据集上进一步训练。这有助于模型微调其理解,并适应任务的特殊要求。
存在三种常见的学习模型:
1)零样本学习;Base LLM 无需明确训练即可响应各种请求,通常是通过提示,但是答案的准确性各不相同。
2)少量样本学习:通过提供一些相关的训练示例,基础模型在该特定领域的表现显著提升。
3)微调:这是少量样本学习的扩展,其中数据科学家训练基础模型,使模型使用与特定应用相关的其他数据来调整其参数。
四、什么是自然语言处理 (NLP)?
自然语言处理会通过多种不同方式工作。
1)基于 AI 的 NLP 涉及使用 Machine Learning 算法和技巧来处理、理解和生成人类语言。
2)基于规则的 NLP 涉及创建一个可用来分析和生成语言数据的规则或模式的集合。
3)统计学 NLP 涉及使用从大型数据集中获得的统计模型来分析语言并做出语言方面的预测。
混合 NLP 将上述三种方法结合到一起。
基于 AI 的 NLP 方法当今最为热门。与任何其他数据驱动型学习方法一样,开发 NLP 模型需要对文本数据进行预处理并精心选择学习算法。
-
第 1 步:数据预处理
这是指清理并准备文本的过程,以便 NLP 算法能够对其进行分析。部分常见的数据预处理技巧包括文本挖掘(指使用大量文本并将文本拆分为数据)或词汇切分(指将文本拆分成单独的单元)。这些单独的单元可以是标点、单词或词组。停用词删除是一项工具,可移除对话中通常不太有助于分析的常用词和冠词。词干提取和词形还原会将单词拆分成其基本词根形式,以便更轻松地识别它们的意思。词性标注可识别一句话中的名词、动词、形容词和其他词性的词。语法分析会分析句子结构以及不同单词之间的关系。 -
第 2 步:算法开发
这是向预处理数据应用 NLP 算法的过程。它会从文本中提取有用信息。下面是一些最常见的自然语言处理任务:
情感分析确定一段文本中的情绪基调或者情感。情感分析会将单词、词组和表达标注为积极、消极或中立。
命名实体识别会识别命名实体并对其进行分类,例如人、位置、日期和组织。
主题建模会将相似的单词和词组分组到一起,以识别一系列文档或文本的主要话题或主题。
机器翻译会使用 Machine Learning 将文本自动从一种语言翻译成另一种语言。语言建模会预测特定上下文中单词序列的可能性。
语言建模用于自动完成、自动更正应用程序,还用于语音转文本系统。
需要注意的两个 NLP 分支是自然语言理解 (NLU) 和 自然语言生成 (NLG)。
- 1.NLU 专注于让计算机使用与人类所用工具类似的工具来理解人类语言。它的目的是让计算机理解人类语言的细微之处,包括上下文、意向、情感和模糊性。NLG 专注于基于数据库或规则集创建与人类语言类似的语言。
- 2.NLG 的目标是生成可被人类轻松理解的文本。
五、什么是转换器模型呢?
转换器模型是大型语言模型中最常见的架构。它由一个编码器和一个解码器组成。转换器模型通过将输入信息转换为词元来处理数据,然后同时进行数学运算来发现词元之间的关系。这样,计算机就能够看到人类在面对同样查询时所看到的模式。
转换器模型使用自注意力机制工作,与长短期记忆模型等这类传统模型相比,这种模型的学习速度更快。自注意力让转换器模型能够考虑序列的不同部分或句子的整个上下文,从而生成预测。
六、大型语言模型的关键组件
大型语言模型由多个神经网络层组成。递归层、前馈层、嵌入层和注意力层协同工作,对输入文本进行处理并生成输出内容。
- 1.递归层会按顺序解读输入文本中的字词,并获取句子中字词之间的关系。
- 2.前馈层 (FFN) 由多个完全互联的层组成,用于转换基于输入文本生成的嵌入。这样,这些层就能够使模型收集更高层级的抽象概念,也就是理解用户输入文本的意图。
- 3.嵌入层会基于输入文本创建嵌入。大型语言模型的这一部分会获取输入内容的语义和句法含义,从而让模型能够理解上下文。
- 4.注意力层能够让语言模型专注于输入文本中与当前任务相关的各个部分。通过这一层,可让模型生成最准确的输出。
在您的搜索应用程序中应用转换器
大型语言模型主要有三种:
- 1)通用或原始语言模型会根据训练数据中的语言预测下一个字词。这些语言模型可执行信息检索任务。
- 2)指令调优的语言模型经过训练后,可预测输入中所给指令的响应。这可使用它们执行情感分析,或者生成文本或代码。
- 3)对话调优的语言模型经过训练后,可通过预测下一个响应来进行对话。例如,聊天机器人或对话 AI。
七、大型语言模型与生成式 AI 之间的区别?
生成式 AI 是一个总称,是指有能力生成内容的人工智能模型。生成式 AI 可以生成文本、代码、图像、视频和音乐。例如,生成式 AI 有 Midjourney、DALL-E 和 ChatGPT。
大型语言模型是一种生成式 AI,它基于文本进行训练并生成文本内容。ChatGPT 就是一个广为流行的文本生成式 AI 示例。
所有大型语言模型都是生成式 AI1。
八、常用大型语言模型示例
很多常用的大型语言模型已经风靡全球。其中有许多已经被各行各业的人们所采用。您一定听说过 ChatGPT 这种生成式 AI 聊天机器人。
其他常用 LLM 模型还包括:
PaLM:Google 的 Pathways Language Model (PaLM) 是一种转换器语言模型,能够进行常识和算术推理、笑话解释、代码生成和翻译。
BERT:基于转换器的双向编码器表示 (BERT) 语言模型也是在 Google 开发的。它是一个基于转换器的模型,可以理解自然语言并回答问题。
XLNet:XLNet 是一种排列语言模型,以随机顺序生成输出预测,这是它与 BERT 的不同之处。它会先评估编码词元的模式,然后以随机顺序预测词元,而不是按顺序进行预测。
GPT:生成式预训练的转换器可能是最著名的大型语言模型。由 OpenAI 开发的 GPT 是一种热门基础模型,其带编号的迭代都是对前代(GPT-3、GPT-4 等)的改进。它可以进行微调以在下游执行特定任务。这方面的示例包括:Salesforce 开发的用于 CRM 的 EinsteinGPT,以及 Bloomberg 开发的用于金融的 BloombergGPT。
多模态与单模态
2021开年,推出两个跨越文本与图像次元的模型:DALL·E和CLIP,前者可以基于文本生成图像,后者可以基于文本对图片分类,两者都意在打破自然语言处理和计算机视觉两大门派“泾渭分明”的界限,实现多模态AI系统。CLIP是一个预训练模型,就像BERT、GPT、ViT等预训练模型一样。首先使用大量无标签数据训练这些模型,然后训练好得模型就能实现,输入一段文本(或者一张图像),输出文本(图像)的向量表示。CLIP和BERT,GPT,ViT的区别在于,CLIP是多模态的,包含图像处理以及文本处理两个方面的内容,而BERT,GPT是单模态的,VIT是单模态图像的。
**扫描二维码进行NFT抽奖**

相关文章:
大型语言模型 (LLM)全解读
一、大型语言模型(Large Language Model)定义 大型语言模型 是一种深度学习算法,可以执行各种自然语言处理 (NLP) 任务。 大型语言模型底层使用多个转换器模型, 底层转换器是一组神经网络。 大型语言模型是使用海量数据集进行训练…...
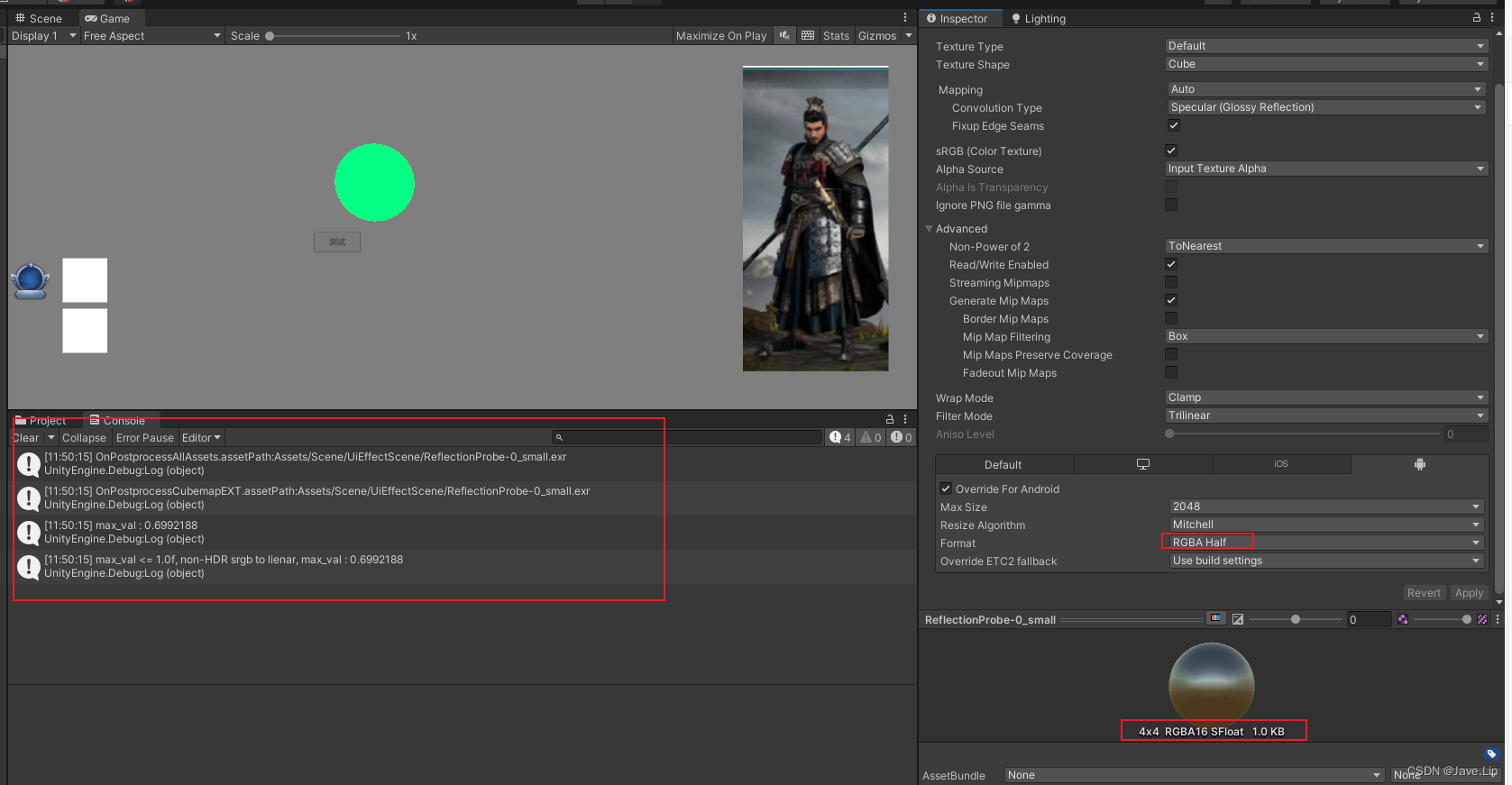
Unity - gamma space下还原linear space效果
文章目录 环境目的环境问题实践结果处理要点处理细节【OnPostProcessTexture 实现 sRGB 2 Linear 编码】 - 预处理【封装个简单的 *.cginc】 - shader runtime【shader需要gamma space下还原记得 #define _RECOVERY_LINEAR_IN_GAMMA】【颜色参数应用前 和 颜色贴图采样后】【灯…...

Rabbitmq调用FeignClient接口失败
文章目录 一、框架及逻辑介绍1.背景服务介绍2.问题逻辑介绍 二、代码1.A服务2.B服务3.C服务 三、解决思路1.确认B调用C服务接口是否能正常调通2.确认B服务是否能正常调用A服务3.确认消息能否正常消费4.总结 四、修改代码验证1.B服务异步调用C服务接口——失败2.将消费消息放到C…...

专业120+总分400+海南大学838信号与系统考研高分经验海大电子信息与通信
今年专业838信号与系统120,总分400,顺利上岸海南大学,这一年的复习起起伏伏,但是最后还是坚持下来的,吃过的苦都是值得,总结一下自己的复习经历,希望对大家复习有帮助。首先我想先强调一下专业课…...

如何区分 html 和 html5?
HTML(超文本标记语言)和HTML5在很多方面都存在显著的区别。HTML5是HTML的最新版本,引入了许多新的特性和元素,以支持更丰富的网页内容和更复杂的交互。以下是一些区分HTML和HTML5的关键点: 新特性与元素:H…...

Ps:将文件载入堆栈
Ps菜单:文件/脚本/将文件载入堆栈 Scripts/Load Files into Stack 将文件载入堆栈 Load Files into Stack脚本命令可用于将两个及以上的文件载入到同一个 Photoshop 新文档中。 载入的每个文件都将成为独立的图层,并使用其原始文件名作为图层名。 Photos…...
【格密码基础】:补充LWE问题
目录 一. LWE问题的鲁棒性 二. LWE其他分布选择 三. 推荐文献 四. 附密码学人心中的顶会 一. LWE问题的鲁棒性 robustness,翻译为鲁棒性 已有的论文表明,及时敌手获取到部分关于秘密和error的信息,LWE问题依旧是困难的,这能…...

【C++入门到精通】特殊类的设计 |只能在堆 ( 栈 ) 上创建对象的类 |禁止拷贝和继承的类 [ C++入门 ]
阅读导航 引言一、特殊类 --- 不能被拷贝的类1. C98方式:2. C11方式: 二、特殊类 --- 只能在堆上创建对象的类三、特殊类 --- 只能在栈上创建对象的类四、特殊类 --- 不能被继承的类1. C98方式2. C11方法 总结温馨提示 引言 在面向对象编程中࿰…...
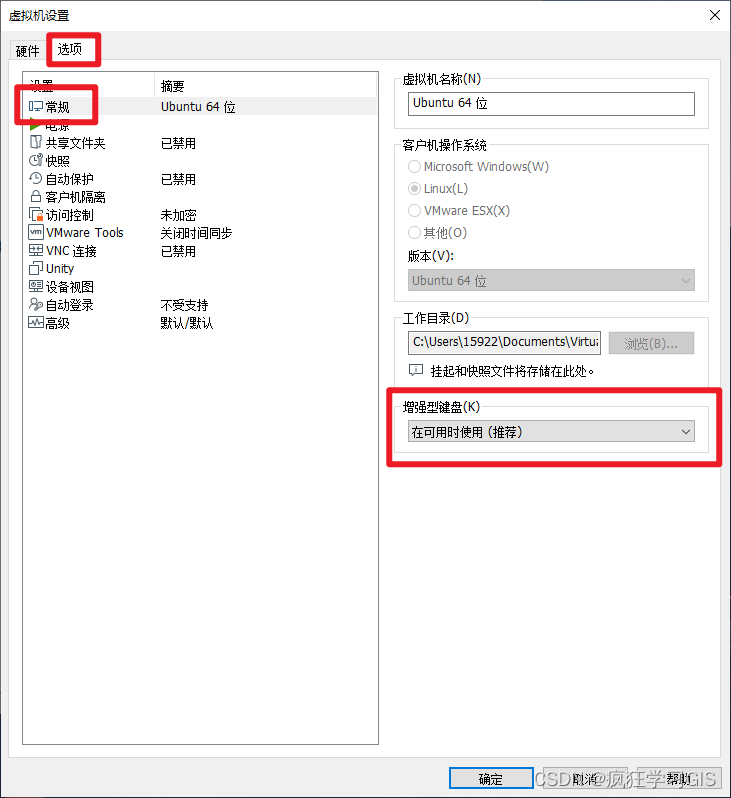
VMware虚拟机部署Linux Ubuntu系统
本文介绍基于VMware Workstation Pro虚拟机软件,配置Linux Ubuntu操作系统环境的方法。 首先,我们需要进行VMware Workstation Pro虚拟机软件的下载与安装。需要注意的是,VMware Workstation Pro软件是一个收费软件,而互联网中有很…...

RFID标签:数字时代的智能身份
在数字时代,RFID标签(Radio-Frequency Identification)成为物联网(IoT)中不可或缺的一环。作为一种小巧却功能强大的设备,RFID标签在各个领域的应用不断扩展,为我们的生活和工作带来了新的可能性…...
》笔记3.2)
《动手学深度学习(PyTorch版)》笔记3.2
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...
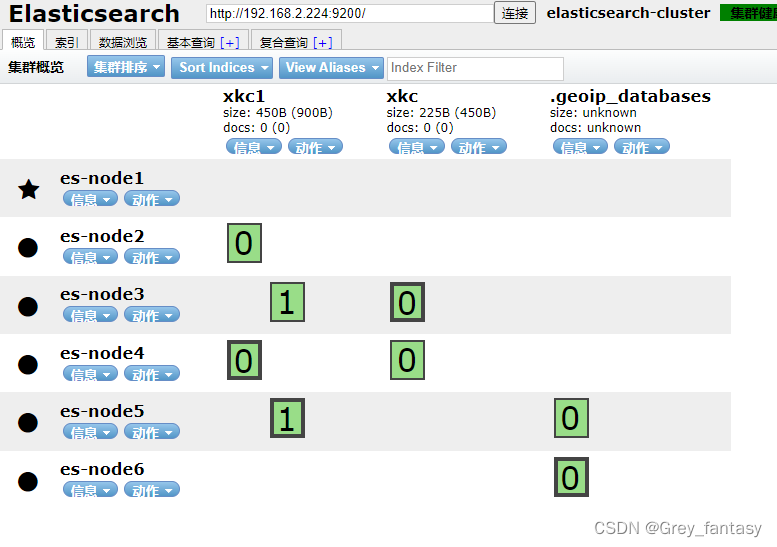
elasticsearch8.x版本docker部署说明
前提,当前部署没有涉及证书和https访问 1、环境说明,我采用三个节点,每个节点启动两个es,用端口区分 主机角色ip和端口服务器Amaster192.168.2.223:9200服务器Adata192.168.2.223:9201服务器Bdata,master192.168.2.224:9200服务器Bdata192.1…...

使用scyllaDb 或者cassandra存储聊天记录
一、使用scyllaDb的原因 目前开源的聊天软件主要还是使用mysql存储数据,数据量大的时候比较麻烦; 我打算使用scyllaDB存储用户的聊天记录,主要考虑的优点是: 1)方便后期线性扩展服务器; 2)p…...
Visual Studio如何修改成英文版
1、打开 Visual Studio Installer 2、点击修改 3、找到语言包,选择需要的语言包,而后点击修改 4、等待下载 5、 安装完成后启动Visual Studio 6、在工具-->选项-->环境-->区域设置-->English并确定 7、重启 Visual Studio,配置…...
gin中使用swagger生成接口文档
想要使用gin-swagger为你的代码自动生成接口文档,一般需要下面三个步骤: 按照swagger要求给接口代码添加声明式注释,具体参照声明式注释格式。使用swag工具扫描代码自动生成API接口文档数据使用gin-swagger渲染在线接口文档页面 第一步&…...
最新AI创作系统ChatGPT网站系统源码,Midjourney绘画V6 ALPHA绘画模型,ChatFile文档对话总结+DALL-E3文生图
一、前言 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…...

解析dapp:从底层区块链看DApp的脆弱性和挑战
每天五分钟讲解一个互联网只是,大家好我是啊浩说模式Zeropan_HH 在Web3时代,去中心化应用程序(DApps)已成为数字经济的重要组成部分。它们的同生性,即与底层区块链网络紧密相连、共存亡的特性,为DApps带来…...

机器学习整理
绪论 什么是机器学习? 机器学习研究能够从经验中自动提升自身性能的计算机算法。 机器学习经历了哪几个阶段? 推理期:赋予机器逻辑推理能力 知识期:使机器拥有知识 学习期:让机器自己学习 什么是有监督学习和无监…...
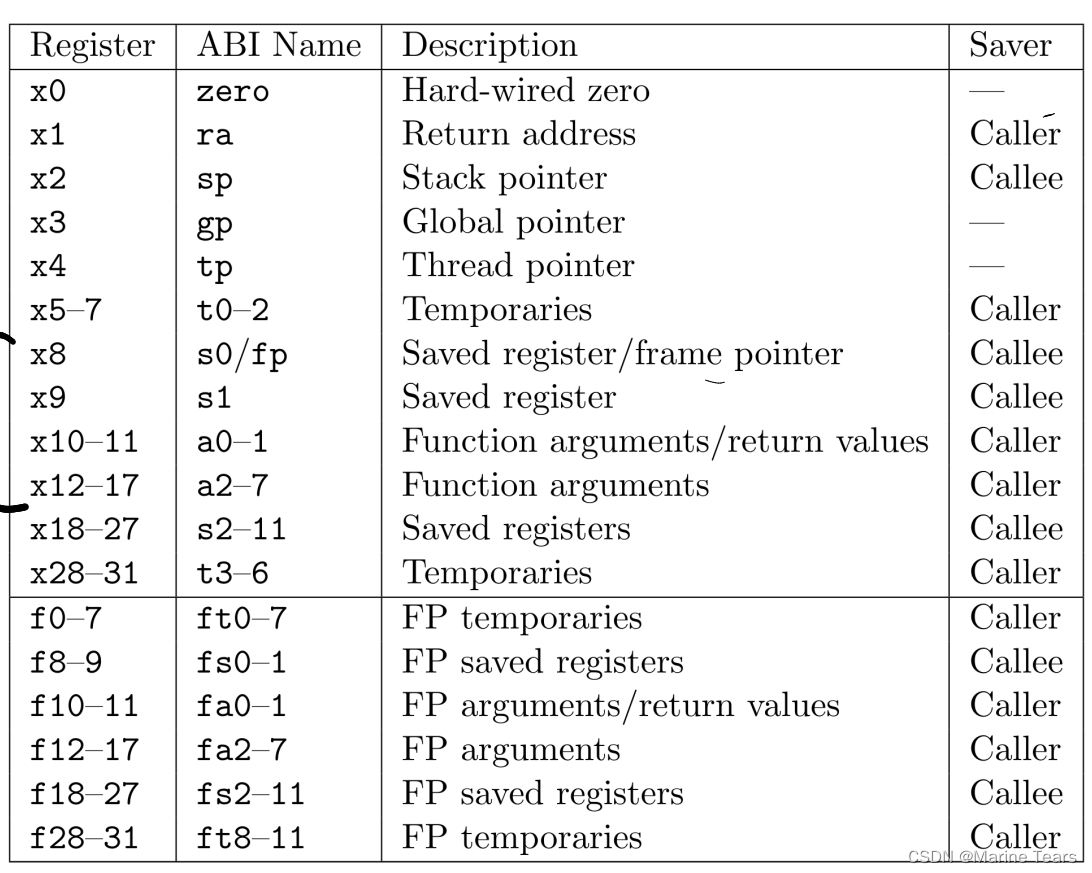
RISC-V常用汇编指令
RISC-V寄存器表: RISC-V和常用的x86汇编语言存在许多的不同之处,下面将列出其中部分指令作用: 指令语法描述addiaddi rd,rs1,imm将寄存器rs1的值与立即数imm相加并存入寄存器rdldld t0, 0(t1)将t1的值加上0,将这个值作为地址,取…...
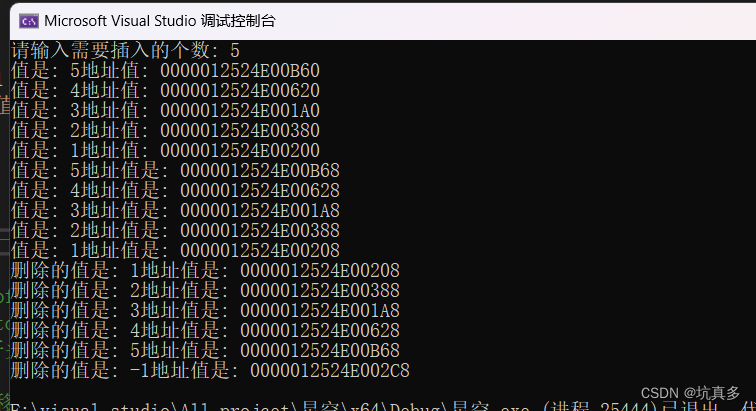
第二篇:数据结构与算法-链表
概念 链表是线性表的链式存储方式,逻辑上相邻的数据在计算机内的存储位置不必须相邻, 可以给每个元素附加一个指针域,指向下一个元素的存储位 置。 每个结点包含两个域:数据域和指针域,指针域存储下一个结点的地址&…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...

编程统计公司内部资料查阅使用数据,优化资料分类存储方式。提升职场员工工作查阅办事效率。
构建一个公司内部资料查阅使用统计与资料分类存储优化的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在中大型企业中,内部资料(制度、流程文档、技术手册、项目档案)数量庞大&a…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

通用框架操作系统:统一异构应用框架的运行时与治理平台
1. 项目概述:一个面向未来的通用框架操作系统最近在开源社区里,一个名为TELLEBO/universal-framework-os的项目引起了我的注意。乍一看这个标题,可能会觉得有点“大词”堆砌的感觉——“通用”、“框架”、“操作系统”,每一个词单…...

Claude API企业准入最后窗口期:2024Q3起强制启用OAuth 2.1+硬件级密钥绑定,现在不升级将无法续签
更多请点击: https://intelliparadigm.com 第一章:Claude API企业准入政策的演进与合规紧迫性 随着Anthropic对Claude模型商用边界的持续收束,企业级API接入正从“技术可用性”转向“治理可验证性”。2024年Q2起,所有新注册企业账…...

去中心化AI市场BloomBee:技术架构、挑战与开发者实践指南
1. 项目概述:当AI遇见去中心化,BloomBee想解决什么?最近在AI和Web3的交叉领域,一个名为BloomBee的项目引起了我的注意。它的名字很有意思,“Bloom”是开花、繁荣的意思,“Bee”是蜜蜂,合起来像是…...

C# AI开发实战:BotSharp框架构建企业级NLP应用指南
1. 项目概述:当C#开发者遇上AI应用开发如果你是一名长期深耕.NET生态的开发者,最近看着Python在AI领域风生水起,心里是不是有点痒,又有点不甘?总觉得为了跑个模型、搭个智能对话,就得切到另一个完全不同的技…...

DOM 浏览器
DOM 浏览器 引言 DOM(文档对象模型)是浏览器中处理HTML和XML文档的标准方式。它允许开发人员通过编程方式访问和操作网页内容。本文将详细介绍DOM的概念、其在浏览器中的运用以及相关的编程技巧。 DOM简介 什么是DOM? DOM(Document Object Model)是一种跨平台和语言独…...
做WiFi遥控小车,我踩过的那些坑)
保姆级避坑指南:用STM32F103C8T6+ESP8266(AT指令)做WiFi遥控小车,我踩过的那些坑
STM32F103C8T6ESP8266 WiFi遥控小车避坑实战手册 1. 硬件选型与连接:那些容易被忽视的细节 在开始任何代码编写之前,硬件连接的正确性往往决定了项目的成败。使用STM32F103C8T6(俗称"蓝莓板")与ESP8266模块组合时&#…...