《动手学深度学习(PyTorch版)》笔记3.2
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。
Chapter3 Linear Neural Networks
3.2 Implementations of Linear Regression from Scratch
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import random
import torch
from d2l import torch as d2ldef synthetic_data(w, b, num_examples): #@save"""Generate y = Xw + b + noise."""#generates a random matrix X with dimensions (num_examples, len(w)) using a normal distribution with a mean of 0 and standard deviation of 1.X = torch.normal(0, 1, (num_examples, len(w)),dtype=torch.float32) #calculates the target values y by multiplying the input matrix X with the weight vector w and adding the bias term b. y = torch.matmul(X, w) + b #And then adds some random noise to the target values y. The noise is generated from a normal distribution with mean 0 and standard deviation 0.01. y += torch.normal(0, 0.01, y.shape) return X, y.reshape((-1, 1)) #The -1 in the first dimension means that PyTorch should automatically infer the size of that dimension based on the total number of elements. In other words, it is used to ensure that the reshaped tensor has the same total number of elements as the original tensor.true_w=torch.tensor([2,-3.4],dtype=torch.float32)
true_b=4.2
features,labels=synthetic_data(true_w,true_b,1000)
print('features:',features[0],'\nlabel:',labels[0])d2l.set_figsize()
d2l.plt.scatter(features[:,(1)].detach().numpy(),labels.detach().numpy(),1)
#plt.show()#显示散点图
#"features[:, 1]" selects the second column of the features tensor.
#The detach() method is used to create a new tensor that shares no memory with the original tensor, and numpy() is then called to convert it to a NumPy array.
#"1" is the size of the markers in the scatter plot.def data_iter(batch_size,features,labels):num_examples=len(features)indices=list(range(num_examples))#随机读取文本random.shuffle(indices)#"Shuffle the indices"意为打乱索引 for i in range(0,num_examples,batch_size):batch_indices=torch.tensor(indices[i:min(i+batch_size,num_examples)])#"min(i + batch_size, num_examples)" is used to handle the last batch, which might have fewer examples than batch_size.yield features[batch_indices],labels[batch_indices]#初始化参数。从均值为0,标准差为0.01的正态分布中抽取随机数来初始化权重,并将偏置量置为0
w=torch.normal(0,0.01,size=(2,1),requires_grad=True)
b=torch.zeros(1,requires_grad=True)#定义线性回归模型
def linreg(X,w,b): #@savereturn torch.matmul(X,w)+b #广播机制:用一个向量加一个标量时,标量会加到向量的每一个分量上#定义均方损失函数
def squared_loss(y_hat,y): #@savereturn (y_hat-y.reshape(y_hat.shape))**2/2#定义优化算法:小批量随机梯度下降
def sgd(params,lr,batch_size): #@savewith torch.no_grad():for param in params:param-=lr*param.grad/batch_sizeparam.grad.zero_()#轮数num_epochs和学习率lr都是超参数,先分别设为3和0.03,具体方法后续讲解
lr=0.03
num_epochs=3
batch_size=10for epoch in range(num_epochs):for X,y in data_iter(batch_size,features,labels):l=squared_loss(linreg(X,w,b),y)l.sum().backward()#因为l是一个向量而不是标量,因此需要把l的所有元素加到一起来计算关于(w,b)的梯度sgd([w,b],lr,batch_size)with torch.no_grad():train_l=squared_loss(linreg(features,w,b),labels)print(f'epoch {epoch+1}:squared_loss {float(train_l.mean()):f}')
print(f'w的估计误差:{true_w-w.reshape(true_w.shape)}')
#结果中的grad_fn=<SubBackward0>表示这个tensor是由一个正向减法操作生成的
print(f'b的估计误差:{true_b-b}')#<RsubBackward1>表示由一个反向减法操作生成
相关文章:
》笔记3.2)
《动手学深度学习(PyTorch版)》笔记3.2
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...
elasticsearch8.x版本docker部署说明
前提,当前部署没有涉及证书和https访问 1、环境说明,我采用三个节点,每个节点启动两个es,用端口区分 主机角色ip和端口服务器Amaster192.168.2.223:9200服务器Adata192.168.2.223:9201服务器Bdata,master192.168.2.224:9200服务器Bdata192.1…...

使用scyllaDb 或者cassandra存储聊天记录
一、使用scyllaDb的原因 目前开源的聊天软件主要还是使用mysql存储数据,数据量大的时候比较麻烦; 我打算使用scyllaDB存储用户的聊天记录,主要考虑的优点是: 1)方便后期线性扩展服务器; 2)p…...
Visual Studio如何修改成英文版
1、打开 Visual Studio Installer 2、点击修改 3、找到语言包,选择需要的语言包,而后点击修改 4、等待下载 5、 安装完成后启动Visual Studio 6、在工具-->选项-->环境-->区域设置-->English并确定 7、重启 Visual Studio,配置…...
gin中使用swagger生成接口文档
想要使用gin-swagger为你的代码自动生成接口文档,一般需要下面三个步骤: 按照swagger要求给接口代码添加声明式注释,具体参照声明式注释格式。使用swag工具扫描代码自动生成API接口文档数据使用gin-swagger渲染在线接口文档页面 第一步&…...
最新AI创作系统ChatGPT网站系统源码,Midjourney绘画V6 ALPHA绘画模型,ChatFile文档对话总结+DALL-E3文生图
一、前言 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…...

解析dapp:从底层区块链看DApp的脆弱性和挑战
每天五分钟讲解一个互联网只是,大家好我是啊浩说模式Zeropan_HH 在Web3时代,去中心化应用程序(DApps)已成为数字经济的重要组成部分。它们的同生性,即与底层区块链网络紧密相连、共存亡的特性,为DApps带来…...

机器学习整理
绪论 什么是机器学习? 机器学习研究能够从经验中自动提升自身性能的计算机算法。 机器学习经历了哪几个阶段? 推理期:赋予机器逻辑推理能力 知识期:使机器拥有知识 学习期:让机器自己学习 什么是有监督学习和无监…...
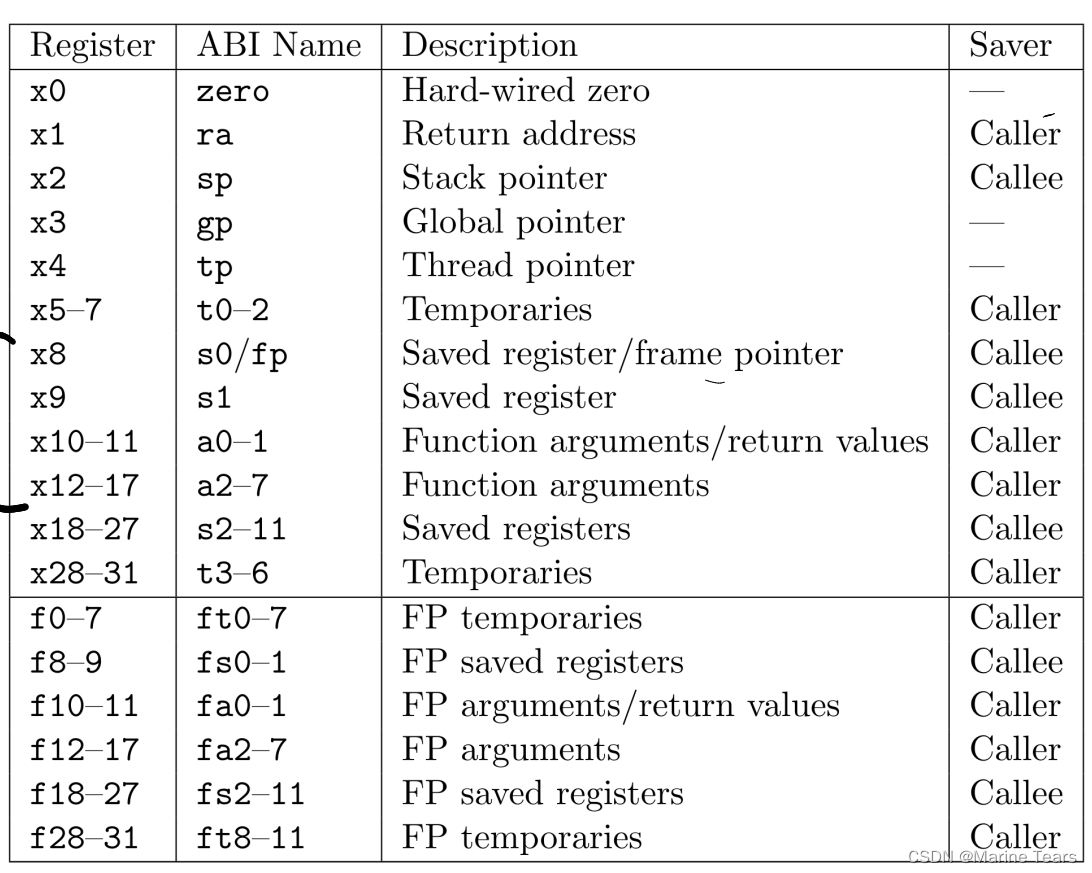
RISC-V常用汇编指令
RISC-V寄存器表: RISC-V和常用的x86汇编语言存在许多的不同之处,下面将列出其中部分指令作用: 指令语法描述addiaddi rd,rs1,imm将寄存器rs1的值与立即数imm相加并存入寄存器rdldld t0, 0(t1)将t1的值加上0,将这个值作为地址,取…...
第二篇:数据结构与算法-链表
概念 链表是线性表的链式存储方式,逻辑上相邻的数据在计算机内的存储位置不必须相邻, 可以给每个元素附加一个指针域,指向下一个元素的存储位 置。 每个结点包含两个域:数据域和指针域,指针域存储下一个结点的地址&…...

低代码配置-小程序配置
数据结构 {"data": {"layout": {"api":{"pageApi":{//api详情}},"config":{"title":"页面标题",},"listLayout": {"fields": [{"componentCode": "grid…...

第十八讲_HarmonyOS应用开发实战(实现电商首页)
HarmonyOS应用开发实战(实现电商首页) 1. 项目涉及知识点罗列2. 项目目录结构介绍3. 最终的效果图4. 部分源码展示 1. 项目涉及知识点罗列 掌握HUAWEI DevEco Studio开发工具掌握创建HarmonyOS应用工程掌握ArkUI自定义组件掌握Entry、Component、Builde…...

OJAC近屿智能张立赛博士揭秘GPT Store:技术创新、商业模式与未来趋势
Look!👀我们的大模型商业化落地产品📖更多AI资讯请👉🏾关注Free三天集训营助教在线为您火热答疑👩🏼🏫 亲爱的伙伴们: 1月31日晚上8:30,由哈尔滨工业大学的…...

Java接收curl发出的中文请求无法解析
最近做项目遇到了这种情况,Java接收curl发出的中文请求无法解析,英文请求一切正常,中文请求则对方服务器无法解析,可以猜测是中文导致的编码问题,但是奇怪的是,本地输出json也没有乱码,编解码正…...

Java设计模式-外观模式(11)
大家好,我是馆长!今天开始我们讲的是结构型模式中的外观模式。老规矩,讲解之前再次熟悉下结构型模式包含:代理模式、适配器模式、桥接模式、装饰器模式、外观模式、享元模式、组合模式,共7种设计模式。。 外观模式(Decorator Pattern) 定义 外观(Facade)模式一种通…...
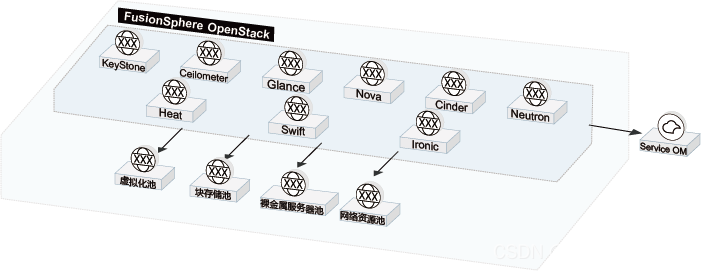
HCS-华为云Stack-FusionSphere
HCS-华为云Stack-FusionSphere FusionSphere是华为面向多行业客户推出的云操作系统解决方案。 FusionSphere基于开放的OpenStack架构,并针对企业云计算数据中心场景进行设计和优化,提供了强大的虚拟化功能和资源池管理能力、丰富的云基础服务组件和工具…...

C++类模板实现顺序表SeqList
main函数 #include<iostream> #include<stdlib.h> #include"SeqList.cpp"using namespace std;typedef int ElementType; int main(void) {SeqList< ElementType, 10> SeqList(1);cout << SeqList.ListLength() << endl;bool result;…...
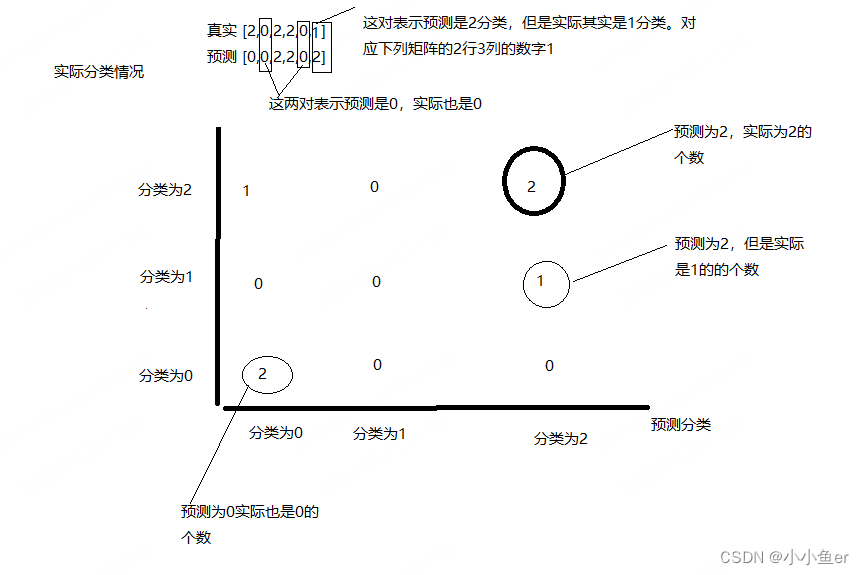
sklearn 学习-混淆矩阵 Confusion matrix
混淆矩阵Confusion matrix:也称为误差矩阵,通过计算得出矩阵的结果用来表示分类器的精度。其每一列代表预测值,每一行代表的是实际的类别。 from sklearn.metrics import confusion_matrixy_true [2, 0, 2, 2, 0, 1] y_pred [0, 0, 2, 2, 0…...
C#,数据检索算法之跳跃搜索(Jump Search)的源代码
数据检索算法是指从数据集合(数组、表、哈希表等)中检索指定的数据项。 数据检索算法是所有算法的基础算法之一。 本文提供跳跃搜索的源代码。 1 文本格式 using System; namespace Legalsoft.Truffer.Algorithm { public static class ArraySe…...
——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH)
ElasticSearch 开发总结(九)——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH
ElasticSearch 开发总结(九)——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH-CSDN博客 1.SearchType ES的搜索类型 有一个类SearchType(如下图示),关于该类的描述: Search type repre…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...

5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库
5个场景深度解析:如何用bili2text将B站视频变成你的私人知识库 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 凌晨两点,小林还在为明…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

碧蓝航线自动化脚本:让游戏管理变得轻松高效
碧蓝航线自动化脚本:让游戏管理变得轻松高效 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每天重…...

Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题!
Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统越用越慢而烦恼吗&…...

英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化
英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟排位赛中,你是否曾因错过接受对局而懊恼不已&a…...

别再只盯着CSI-2了!用示波器实测MIPI D-PHY波形,手把手教你排查Camera不通的硬件问题
别再只盯着CSI-2了!用示波器实测MIPI D-PHY波形,手把手教你排查Camera不通的硬件问题 调试Camera模块时,MIPI信号问题往往是硬件工程师最头疼的挑战之一。当系统出现图像异常、花屏或无法识别时,大多数工程师的第一反应是检查CSI-…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...

基于双线性插值的AMG8833热成像分辨率提升方案与嵌入式实现
1. 项目概述:从8x8到15x15,一次软件驱动的热成像分辨率革命如果你玩过基于AMG8833这类低成本红外热成像传感器的项目,大概率会对它那8x8的“马赛克”图像印象深刻——64个像素点,勉强能看出个温度轮廓,但细节ÿ…...